Redis 是单线程应用程序, 占用较少的内存. 它通过在数据中心和云供应商的多核处理器上运行多个实例达到持久性和可伸缩性. 多台 Redis 组成的主从复制及正式发布的Redis 集群, 让运行多个 Redis 实例在内存和 CPU 需求方面的运营成本相对低廉. 这就允许在兼顾伸缩性的同时, 增强大型应用程序的持久性.
在基于 SQL 的关系型数据库中, 开发者和数据库管理员通过将数据规范化为列, 行和表, 并通过外键关系建立关联的方式创建数据库模式.
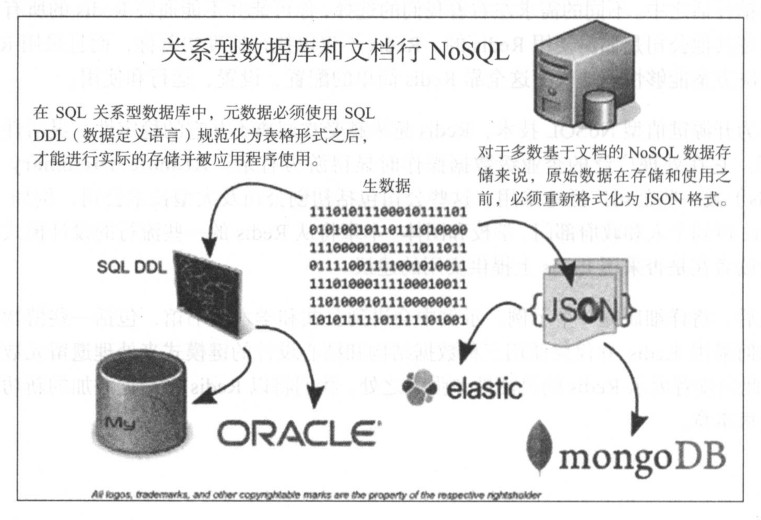
其他像 MongoDB 和 ElasticSearch 这样的 NoSQL 数据存储技术需要在数据装载到实际存储之前转换为 JSON 文档数据格式. 虽然 Redis 跳过了这种中间转换, 但是在其他技术方面更进一步, 为特定的数据结构提供了一系列命令. 这些数据结构包括字符串, 列表, 哈希表, 集合及有序集合. 这样的设计使得你可以通过算法和数据进行交互, 以数据在 Redis 中的存储方式及可用的命令直接构造解决方案, 同时能以更直接的方式对目标操作系统的内存和磁盘空间进行调优和监控.

思考诸如列表, 啥希表和集合等基础计算数据结构是如何表达和管理的, 有助于你以一种更基本的, 更数学化的方式掌握数据及其结构正反两面的特性. 仔细思考中间结构化流程, 例如将数据规范化为关系型数据库, 或者为了使用 MongoDB 或 ElasticSearch 将数据转换为 JSON 文档. 这样做虽然有价值, 但是会强制使用固定的数据结构, 而 Redis 则没有这方面的要求. 在构建解决方案时, 你可能会发现你更需要那些非 Redis 技术支持的持久性和结构特性. 即便在这种情况下,你对 Redis 中数据属性和结构的探索的经验, 也有助于信息的处理和问题的解决.
当你拥有大量不经常使用的数据且无须立即存取时, Redis 可能不是佳技术方案. 基于 SQL 的关系型数据库或者文档存储型的 NoSQL 技术, 例如 CouchDB 或者 MongoDB, 相较 Redis 而言可能是更好的选择. 但是, 随着第三版 Redis 完全支持集群, 在 Redis 中的大型数据集可以作为分布式键值数据存储. 越来越多的组织和个体从使用 Redis 集群中获取经验, 期望会有更多的项目选择使用 Redis.

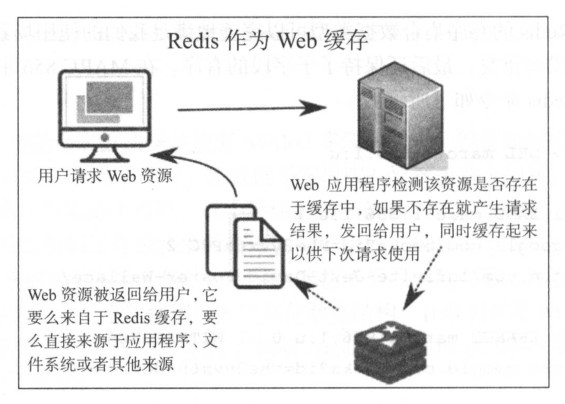
对 Redis 来说, 一种非常受欢迎的使用模式是作为 Web 应用程序的内存缓存. 对诸如 Django, Ruby-on-Rails, Node.js 和 Flask 等流行的 Web 框架来说, Redis 都可以作为其缓存的选项. 作为受欢迎的缓存技术, Redis 在 Web 应用程序方面擅长在存储新数据的同时驱逐(evict)老旧的数据. 对于 Web 应用程序来说, 缓存的数据内容可以是 HTML 页面字符串, 窗口小部件, 元素, 以及所有网页和整个站点.
通过利用 Redis 为键设置过期时间的功能, 流行的 Redis 缓存策略之一--最近较少使用(Less Recently Used, LRU) 策略变得非常健壮, 足以应对最大的网站. 它将最受欢迎的内容保存在缓存中, 同时将陈旧的, 较少使用的数据驱逐出数据存储. 这种缓存的使用场景并不假定原始的 Web 元素或者页面是由 Redis 中的数据产生. 最常见的使用模式是由其他来源的数据动态生成 Web 内容, 而将 Redis 作为 Web 缓存层.
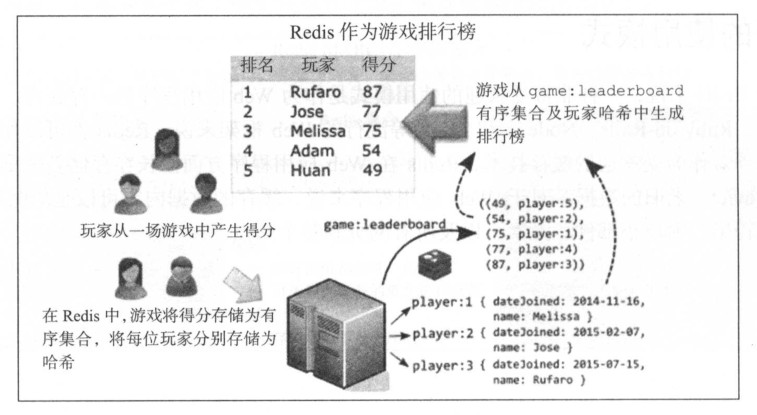
第二种流行的使用模式是将 Redis 用作 Web 页面使用情况和玩家排行榜上的用户行为等定量数据的指标存储. 通过在字符串上进行位操作, Redis 可以非常高效地将二进制信息存储于特定的字符上. 就拿网站使用来说, 有个从日期构造的键page-usage:2016-11-01, 它对应一个字符串, 当该页面被用户访问时, 就将其中的一位设置成 1.
网站在11月1日的每日使用情况可以通过在 page-usage:2016-11-01 键上调用简单的 Redis 的 BITCOUNT 命令获取. 在 2011 年的博客中, 初创公司 Spool 中的几位员工详细讲解了他们是如何采用这种设计模式, 使用位图及 Redis 的位操作来存储网站用户的活动的.
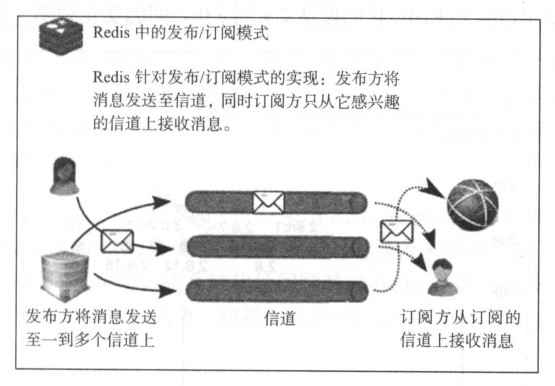
第三种流行的 Redis 使用模式是通过发布/订阅(简称 pub/sub)模型作为不同系统之间的通信层. 在这种模型中, 消息的发布方将消息发送至一到多个信道(channel)上, 这些消息会被订阅或者监听信道上发来消息的其他系统处理.
通常, 消息发布方无须知道具体的订阅方就能将消息发送给他们(相对点对点消息通信模式来说), 发布方仅需知道消息内容和用于发送消息的信道即可. 同样, 订阅方也无须知道每个发送方, 只需关注信道接收消息即可. 发布/订阅非常棒, 因为它扩展起来非常容易, 同时消息的发布方和订阅方可以是几乎完全不同的程序和系统.
应用程序中将 Redis 用作数据存储需要先考虑以下两点: 键和其对应的数据结构. 制定一套良好的键模式, 语法和命名约定是高效稳定的解决方案和技术混乱的分水岭. Redis 允许绝大多数的字符串经序列化后作为键, 这种灵活性值得我们在设计基于 Redis 的项目时仔细斟酌与精心设计. 对采用 Redis 构建的应用来说, 为键选用合适的数据结构将对系统的可用性和功能性产生直接影响. 本章包含以下内容:
- 设计并管理 Redis 的键模式和关联的数据结构.
- 使用 Redis 客户端对象映射器(Object Mapper). 使用不同的策略隐藏具体的键模式和数据结构.
- 使用 Javascript 的 Redis 对象映射器创建一个简单的应用, 并分析对象映射器是如何使用 Redis 命令和数据结构的, 以此作为 Redis 键模式的示例.
- 介绍大 O 标记, 以及最坏情况的算法效率是如何应用在评估 Redis 命令的性能上的, 还有性能是如何直接影响到 Redis 底层数据结构的.
对 Redis 官方文档中大 O 标记的理解, 为估算基于 Redis 的应用程序的时间复杂度提供了一种方法, 并有助于评估基于 Redis 的应用程序的性能. Redis 键值对应当作为解决方案的补充与加强, 对于应用程序的设计者, 开发者和终端用户来讲, 需要权衡是为了内存效率选择较短的键, 还是为了解释清楚值的用途选择较长的键.
运行 32 位还是 64 位版本的 Redis 将决定 Redis 键大小的实际限制. 对 32 位版本来说, 任何长于 32 位的键名需要更多的字节空间, 因此增加了 Redis 的内存使用. 使用 64 位版本的 Redis 允许更长的键长度, 但是对于短小的键来说, 也会分配完整的 64 位空间, 从而导致额外的空间浪费.
键值对是 Redis 数据库中的最小存储单位, Redis 性能和可维护性的优劣取决于 Redis 数据库键的设计与构造, 存储在不同键上的信息可以通过键值命名来关联, 也可以通过创建单独的关联键值对来关联.
我们强烈建议不要在生产环境的应用中使用 KEYS 命令. 这是因为 Redis 需要遍历数据库中每一个键. 采用一致的命名约定及诸如集合, 哈希或者有序集合这样的数据结构, 应用程序理应无须使用 KEYS 命令获取数据. 虽然 SCAN 命令可以用来获取 Redis 数据, 但不应被视为 KEYS 命令的替代品. SCAN 命令抽取一个随机的键片段, 然后将提供的模式和 MATCH 选项应用到此随机片段上.
对象映射器用来将对象直接转化为特殊的键模式和数据结构. 对于 node.js 来说, Redis 的对象映射器称为 Nohm.
Nohm 在基础命名模式中使用冒号作为键分隔符.