存储容量与 IO 速度之间的矛盾, 数据越来越多, 但是硬盘的 IO 速度提升有限. 可能解决方法是从多个设备上并行读取, 那么有两个问题需要解决:
-
如何解决单个设备失效导致的数据丢失(replication).
-
如何合并多个设备上读取到的文件片段.
Hadoop 是一个生态系统:
-
MapReduce 本质上是一个类批处理系统, 但是因为响应时间较长, 并不适用于强调实时性的交互性分析.
-
HBase 用来存放 key-value 格式的数据, 使用 HDFS(Hadoop Distributed Filesystem) 作为底层文件系统.HBase 既支持单行的 读写, 也支持大块数据的批处理读写.
-
YARN(Yet Another Resource Negotiator), 集群资源管理系统, 用来调度所有的分布式程序(包括 MapReduce), 使其可以基于 Hadoop 集群中的数据来运行.
- Interactive SQL(交互式 SQL)
Hadoop上的SQL查询可以实现低延迟响应
- Iterative processing(迭代处理)
机器学习算法, Spark 代替 MapReduce
- Stream processing(流处理)
像 Storm, Spark Streaming 或 Samza 等流媒体系统可以运行实时分布式计算, 并将结果发送到 Hadoop 存储或外部系统
- Search
Solr 搜索平台可以在 Hadoop 集群上运行, 索引 HDFS 中的文档, 并基于 HDFS 中的索引中提供搜索服务.
| Traditional RDBMS | MapReduce | |
|---|---|---|
| Data size | Gigabytes | Petabytes |
| Access | Interactive and batch | Batch |
| Updates | Read and write many times | Write once, read many times |
| Transactions | ACID | None |
| Structure | Schema-on-write | Schema-on-read |
| Integrity | High | Low |
| Scaling | Nonlinear | Linear |
关于传统关系数据库(RDBMS) 与 Hadoop 的区别, 这里提到了关键的四点:
-
为什么需要 Hadoop, 为什么不能在传统数据库中加入更多硬盘来实现大数据分析? 因为硬盘的 IO 响应速度受寻道时间限制, 传统关系数据库读取大量数据的速度远远小于 MapReduce. MapReduce 流式读写的读取速度仅仅受传输速率的限制.
-
MapReduce is a good fit for problems that need to analyze the whole dataset.in a batch fashion, particularly for ad hoc analysis. An RDBMS is good for point queries or updates, where the dataset has been indexed to deliver low-latency retrieval and update times of a relatively small amount of data.
-
MapReduce suits applications where the data is written once and read many times, whereas a relational database is good for datasets that are continually updated.
-
Hadoop 和 RDBMS 之间的另一个区别在于其操作的数据集. 在 RDBMS 中, 结构化数据被组织成定义好的格式, 例如 XML 文档或数据库表. 另一方面, 半结构化数据则比较松散, 虽然可能有格式, 但经常被忽略, 可能仅作为数据结构的指导: 例如 spreadsheet, 其结构是 cells 组成的网格, 虽然 cells 本身可以保存任何形式的数据. 非结构化数据没有任何特定的内部结构: 例如普通文本或图像数据. Hadoop 在非结构化或半结构化数据上工作良好, 因为它被设计成在处理阶段才解释数据(所谓的模式读取 schema-on-read). 这种机制提供了灵活性并避开了 RDBMS 耗时的数据加载阶段, 因为在 Hadoop 中数据加载只是一个文件复制操作.
关系数据通常被标准化(normalized)以保持其完整性并消除冗余. 但是规范化通常会给 Hadoop 处理带来问题, 因为它会将读取记录变为一个一个非本地操作, 而本地操作是 Hadoop 能够执行(高速)流式读写的一个重要假设.
Web 服务器日志是一个未规范化的记录集合(例如, 即使客户端是同一个客户端, 每次都记录完整的客户端主机名), 这就是各种日志文件特别适合用 Hadoop 进行分析的原因之一. 请注意, Hadoop 可以执行 join 操作; 只是并没有关系数据库中用的那么频繁.
MapReduce 和 Hadoop 中的其他处理模型, 处理时间随数据量大小线性变化. 数据是分区的, 功能原语(如 map 和 reduce)可以在所有的分区上并行工作. 这意味着如果你输入的数据量翻倍, 分析需要的时间也将会是原来的两倍. 但是, 如果你同时还将集群的大小加倍, 那么分析工作将会像原来一样快. 而 RDBMS 中的 SQL 查询通常不是这样.
高性能计算(HPC high-performance computing)和网格计算社区已经使用 API 作为消息传递接口(MPI Message Passing Interface), 进行了多年的大规模数据处理. 大体上, HPC 的方法是将工作分配到机器集群中, 集群中的机器通过存储区域网络(SAN storage area network)访问共享文件系统. HPC 主要适用于计算密集型作业, 但是当节点需要访问大量数据时, 问题出现了, 此时网络带宽变成了瓶颈, 导致计算节点闲置. Hadoop 试图将数据与计算节点放在一起, 因为数据都在本地, 所以访问速度很快. 这个功能称为数据本地化(data locality), 是 Hadoop 数据处理的核心, 也是其性能良好的原因. 意识到网络带宽是数据中心环境中最宝贵的资源, Hadoop 通过网络拓扑建模来竭尽全力的保护它. 注意这个安排并不妨碍 Hadoop 中的 CPU 密集型的分析任务. MPI 不仅要求程序员显式的控制底层的数据流, 也要求程序员熟悉顶层的分析算法. 但是在 Hadoop 中, 程序要只需要考虑数据模型, 底层的数据流是不可见的. 协调大规模分布式计算中的任务是一个挑战. 最难的地方是优雅地处理部分任务失败 (此时你不知道一个远程任务是否失败), 同时其他的计算过程还在继续运行(暗示不可能全部重来). MapReduce 这样的分布式处理框架让程序员不必考虑失败, 因为框架会检测到失败任务并在健康的机器上重新调度. MapReduce 之所以能够做到这一点, 是因为它是一个无共享(shared-nothing)架构, 这意味着任务之间没有相互依赖. (这里有轻微的简化, 因为 mappers 的输出是reducer 的输入, reducer 对 mapper 有依赖, 但是这仍然在 MapReduce 系统的控制下; 重新运行一个失败的 reducer 要比重新运行一个失败的 map 更小心, 因为 reducer 必须能获取到必要的 map 输出, 如果不能, 则通过再次调度相关的 map 来重新生成) 所以从程序员的角度来看, 任务运行的先后顺序并不重要. 相比之下, MPI 程序必须明确地管理自己的检查点并恢复(遇到部分任务失败时), 程序员拥有更多的控制权, 却使程序更难写.
志愿者计算项目将他们正在尝试的问题分解成工作单位(work units), 然后发送到世界各地的电脑进行分析. 例如, 一个 SETI@home 工作单位包含 0.35 MB 的射电望远镜数据, 并在一台典型的家用电脑上花几个小时或几天的时间来分析. 分析完成后, 结果被发送回服务器, 然后客户端获取另一个工作单元. 为了防止作弊, 每个工作单位都被送到三台不同的机器, 至少其中的两个结果一致才能被接受.
SETI@home 项目要解决的问题是 CPU 密集型的, 适合在分布于世界各地的数十万台电脑上运行, 因为传输工作单位的时间是相当短的. 志愿者捐献的是 CPU 周期, 而不是带宽.
MapReduce 旨在在一个由可信的硬件组成的高带宽数据中心上运行持续几分钟或几小时的作业. 相比之下, SETI@home 在不受控互联网的不可信机器上运行不间断的计算, 而且没有本地化数据.
MapReduce 是关于数据处理的 编程模型. Hadoop 支持运行多种语言写的 MapReduce 程序, 包括 Java, Ruby, 和 Python. 更重要的是, Most MapReduce 程序天生就是并行的.
MapReduce 任务分为两个阶段: map 阶段和 reduce 阶段. 每个阶段输入和输出的格式都是键值对; 键和值的类型可以由程序员自行指定. 程序员还实现了两个函数: map 函数和reduce 函数.
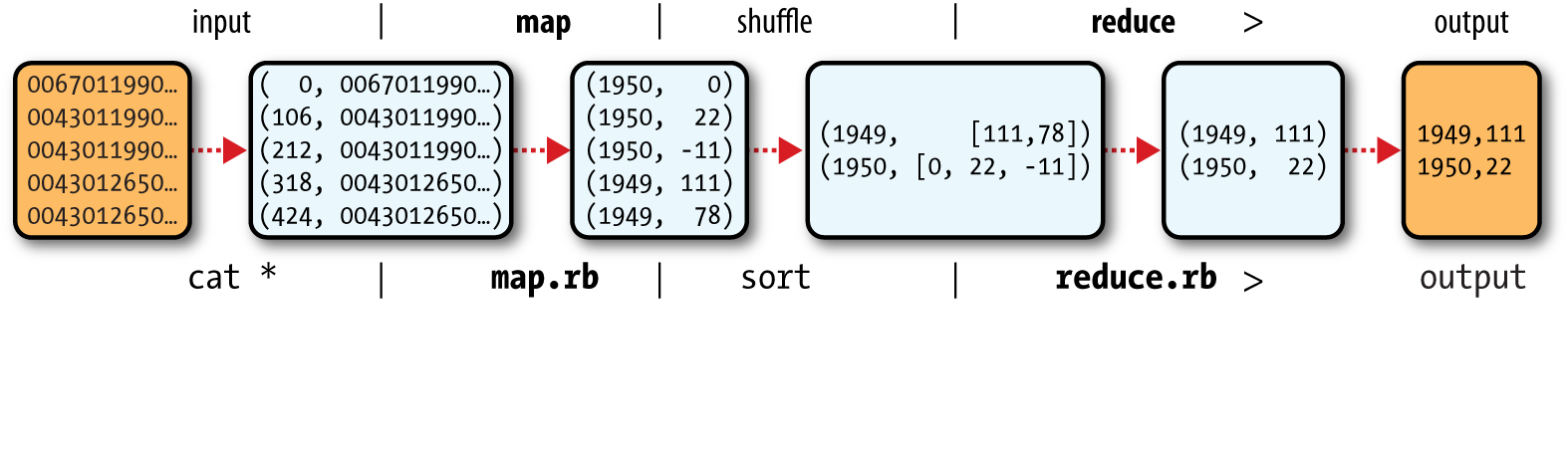
Figure 2-1. MapReduce logical data flow
- map function
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MaxTemperatureMapper
extends Mapper<LongWritable, Text, Text, IntWritable> {
private static final int MISSING = 9999;
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String year = line.substring(15, 19);
int airTemperature;
if (line.charAt(87) == '+') { // parseInt doesn't like leading plus signs
airTemperature = Integer.parseInt(line.substring(88, 92));
} else {
airTemperature = Integer.parseInt(line.substring(87, 92));
}
String quality = line.substring(92, 93);
if (airTemperature != MISSING && quality.matches("[01459]")) {
context.write(new Text(year), new IntWritable(airTemperature));
}
}
}Example 2-3. Mapper for the maximum temperature example
Mapper 类包括四个参数: input key, input value, output key, output value types
为了针对网络序列化场景进行优化, Hadoop 提供了一组自己的基本类型, 用于替换原生 Java 类型. 这些类型可以在 org.apache.hadoop.io 包中找到. 这里我们使用的 LongWritable, 它对应于 Java 中的 Long 类型, Text 对应 Java 中的 字符串, 和 IntWritable 对应 Java 中的 Integer.
- reduce function
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MaxTemperatureReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
}
context.write(key, new IntWritable(maxValue));
}
}Example 2-4. Reducer for the maximum temperature example
- some code to run the job
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MaxTemperature {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: MaxTemperature <input path> <output path>");
System.exit(-1);
}
Job job = new Job();
job.setJarByClass(MaxTemperature.class);
job.setJobName("Max temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}Example 2-5. Application to find the maximum temperature in the weather dataset
在 Hadoop 集群上运行任务时, 我们将把代码打包成 jar 包, 然后通过方法 setJarByClass() 指定需要加载的类名
构造 Job 对象后, 我们指定 input 和 output 路径.
接下来, 我们通过 setMapperClass() 和 setReducerClass() 方法指定 mapper 类和 reduce 类的类型.
setOutputKeyClass() 和 setOutputValueClass() 方法设置 reduce 函数输出结果的类型, 并且必须与 reduce 类生成的内容相匹配. map 函数的输出类型默认和 reduce 是相同的, 所以通常情况下不需要单独设置. 但是, 如果输出类型不同的话, 必须使用 setMapOutputKeyClass() 和 setMapOutputValueClass() 方法来设置 map 输出类型.
首先做一些术语解释. MapReduce job 是客户希望执行的某项工作: 它由输入数据, MapReduce 程序和配置信息组成. Hadoop 通过将 job 分成多个任务来执行, 这些任务分为两种类型: map 任务和 reduce 任务. 这些任务使用 YARN 进行调度, 在集群中的节点上运行. 如果某个任务失败, 它将被自动调度到其他节点上再次运行.
Hadoop 将输入分成固定大小的片段, 然后提交给 MapReduce 任务. 我们将这些片段称之为 input splits 或是 splits. Hadoop 为每个片段创建一个 map 任务, 该任务基于片段中的每条记录运行用户定义的 map 函数.
对数据进行分片意味着相对于处理整个输入数据集, 处理每个分片所需时间会比较少. 假设我们并行的处理这些分片, 那么在分片越小的情况下, 更容易达成服务器之间的负载均衡, 因为在任务运行过程中, 机器越快, 处理的分片将越多. 即使这些机器没有差异, 考虑到进程可能失败或存在其他正在运行的作业, 负载均衡也是可取的, 而且分割的粒度越细, 负载平衡的质量越好.
另一方面, 如果分片太小, 则管理分片和创建 map 任务的开销开始主宰整个 job 的执行时间. 对于大多数 job 来说, 分片大小设置为 HDFS 块的大小将是比较合适的, 默认情况下为 128 MB, 当然, HDFS 块的大小可以基于集群(所有新创建的文件)进行更改, 或者在文件创建时进行指定.
Hadoop 尽量在输入数据所在的 HDFS 节点上运行 map 任务, 这样可以不占用宝贵的集群带宽. 该特性被称为数据本地优化(data locality optimization). 然而有些时候, 所有存储任务所需分片及其副本的 HDFS 块所在的节点都在满负载运行 map 任务, 此时作业调度程序将尝试在同一个机架的其他节点上运行任务. 如果同一机架上没有空闲的节点, 尽管这种情况非常少见甚至是不可能的, 此时会使用机架外节点, 这将导致机架间的网络传输. 图 2-2 描述了这三种情况.
现在应该清楚为什么最佳分片的大小就是 HDFS 文件系统块的大小: 它是能够确认存储在单个节点上的最大大小. 如果分片跨越两个或更多的块, 任何 HDFS 节点都不太可能同时存储这两个块(HDFS 文件系统的特性), 一些分片将不得不通过网络传输到正在运行 map 任务的节点上, 这显然比数据全部在本地运行效率要低.
Map 任务将其输出写入本地磁盘, 而不是 HDFS. 为什么会这样?因为 Map 的输出是中间输出: 它们随后将交给 reduce 任务处理并生成最终输出, 并且一旦 job 完成后, map 任务的输出可以丢弃. 因此, 将它存储在 HDFS 上是一种浪费. 如果节点运行 map 任务失败, 没有生成中间结果, 然后又被 reduce 任务占用, 那么 Hadoop 将自动在另一个节点上重新运行 map 任务.
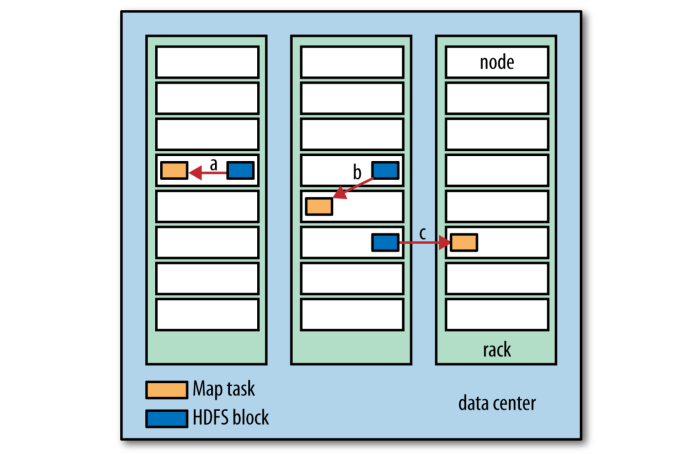
Figure 2-2. Data-local (a), rack-local (b), and off-rack (c) map tasks
对于 Reduce 任务来说, 并不存在本地处理数据优势; 单个 reduce 任务的输入通常是所有 mappers 的输出. 在当前的例子中, 我们使用一个 reduce 任务处理所有 map 任务的输出. 因此, 排序后的 map 输出必须通过网络传输到 reduce 任务运行的节点上, 它们在那里被合并, 然后传递给用户定义的 reduce 函数. reduce 任务的输出通常存储在 HDFS 中以保证可靠性. 正如第3章所解释的那样 HDFS, 对于每一个存储 reduce 输出的 HDFS 块, 通过把第一个副本存储在本地节点上, 其他副本存储在机架外节点上, 来保证可靠性. 因此, 在 HDFS 上写入 reduce 任务的输出确实消耗了网络带宽, 但属于正常的 HDFS 写入消耗(并没有引入性能损失).
图 2-3 描述了单个 reduce 任务的整个数据流. 虚线框表示节点, 虚线箭头表示节点上的数据传输, 实线箭头显示节点之间的数据传输.
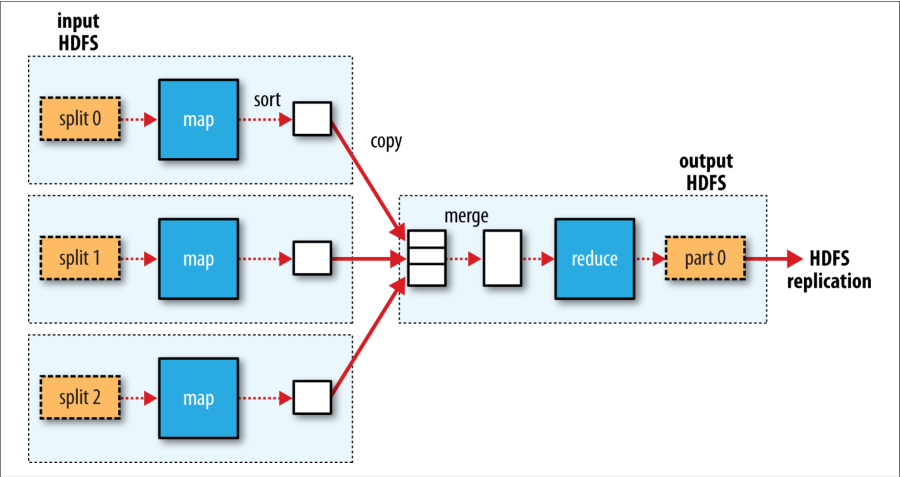
Figure 2-3. MapReduce data flow with a single reduce task
reduce 任务的数量不受输入大小的控制, 而是单独指定的. 在 214 页的 "The Default MapReduce Job" 中, 你将看到如何为特定作业选择 reduce 任务的数量.
当有多个 reducers 时, map 任务将对其输出进行分区, 每个 map 任务都会为每个 reduce 任务创建一个分区. 分区中可以有许多键(和它们的相关值), 但任何给定 key 的记录都全部在某个分区中(key 一定对应一个分区, 一个分区对应多个 key). 分区可以由用户定义的分区函数来控制, 但通常情况下, 使用默认分区程序(使用 hash 函数对 keys 进行存储)就已经很好了.
图 2-4 说明了多个 reduce 任务通常情况下的数据流. 该图清楚地说明了为什么 map 和 reduce 任务之间的数据流被称为"洗牌(the shuffle)", 因为每个 reduce 任务都由许多 map 任务提供. 实际的洗牌比图表中描述的更加复杂, 调整它对 job 执行时间有巨大影响, 你将在 197 页中的"Shuffle and Sort 随机排序"中看到.
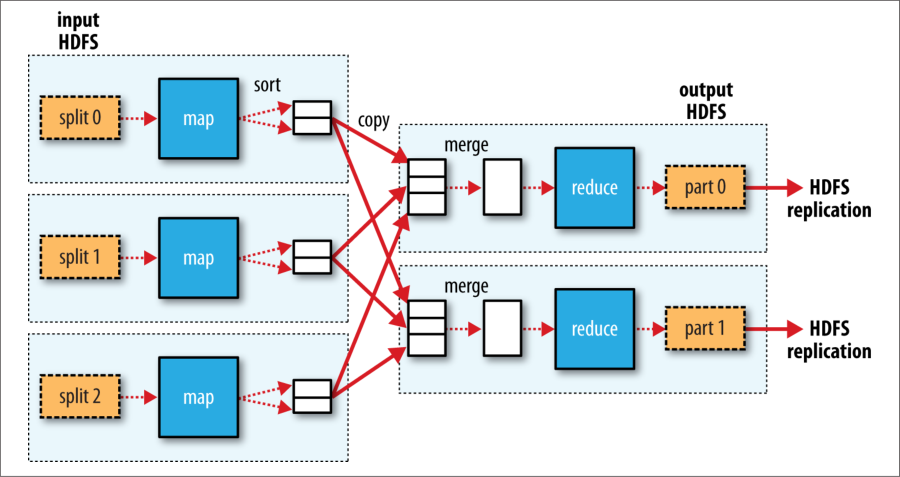
Figure 2-4. MapReduce data flow with multiple reduce tasks
最后提一下, 我们也可以不需要 reduce 任务. 此时因为处理流程可以完全并行进行而不需要洗牌(234 页的 "NLineInputFormat" 中讨论了一些例子). 在这种情况下, 唯一的节点间数据传输是 map 任务将输出写入 HDFS 文件系统(参见图 2-5).
许多 MapReduce job 受到集群上可用带宽的限制, 因此在最小化 map 任务和 reduce 任务间的数据传输上耗费了不少精力. Hadoop 允许用户指定一个 combiner 函数, 运行在 map 任务的输出上, combiner 函数的输出作为 reduce 函数的输入. 因为 combiner 函数只是一个优化, Hadoop 不会保证它会调用combiner 函数多少次. 换句话说, 无论调用 combiner 函数零次, 单次还是多次, reducer 的输出结果都应该是一致的.
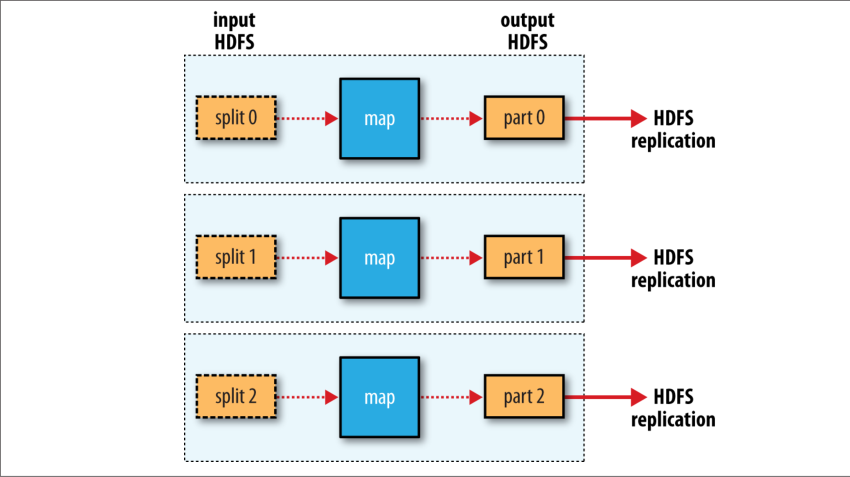
Figure 2-5. MapReduce data flow with no reduce tasks
public class MaxTemperatureWithCombiner {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: MaxTemperatureWithCombiner <input path> " + "<output path>");
System.exit(-1);
}
Job job = new Job();
job.setJarByClass(MaxTemperatureWithCombiner.class);
job.setJobName("Max temperature");
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(MaxTemperatureMapper.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}Example 2-6. Application to find the maximum temperature, using a combiner function for efficiency
Hadoop Streaming 使用 Unix 标准流作为 Hadoop 和你的程序之间的接口, 所以你可以使用任何支持读取标准输入和写入标准输出语言的来编写你的 MapReduce 程序. 对于 C ++程序员, 可以使用 Hadoop Pipes.
Hadoop Distributed Filesystem(HDFS)
对于分布式文件系统, 挑战之一就是在节点故障时而不丢失数据. Hadoop 实际上有一个通用文件系统抽象.
-
Very large files
-
Streaming data access
最有效的数据处理模式是一次写入, 多次读取, HDFS 基于这个理念来构建. 数据集通常从数据源生成或复制, 随后基于数据集进行各种分析. 每次分析都会涉及很大一部分(如果不是全部)数据集, 那么读取整个数据集花费的时间比读取数据集中第一条记录的延迟更重要(言下之意是吞吐量比单个文件的寻道时间更重要).
-
Commodity hardware
-
Low-latency data access
需要低延迟访问数据的应用程序, 例如数十毫秒范围, 不适合用 HDFS 存储. 请记住, HDFS 已针对吞吐量进行了优化, 这是以高延迟为代价的. HBase(参见第 20 章) 是低延迟访问的更好选择.
- Lots of small files
由于 namenode 在内存中保存文件系统元数据, 因此文件系统中的文件数量由 namenode 的内存量决定.
- Multiple writers, arbitrary file modifications
HDFS 中的文件写入操作是互斥的. 文件写入操作总是在文件的结尾添加数据. 不支持同时写入或修改文件中的任意偏移量.(未来可能会被支持, 但会相对低效)
- Blocks
Block 是磁盘能够读取或写入的最小单位.
HDFS 也有块的概念, 但它是一个更大的单位 - 默认情况下为128 MB. 就像单个磁盘上的文件系统, HDFS 中的文件也是以数据块的方式来存放. 与之不同的是, 当文件大小小于块大小时, 不占用块中的所有空间.
HDFS 中的块设置的比较大, 是为了减少寻道时间.
MapReduce 中的 map 任务一次只操作一个块.
对分布式文件系统进行块抽象带来了一些好处.
首先文件可以大于网络中的任何单个磁盘, 不要求将文件中的块存储在同一个磁盘上, 所以大型文件可以利用群集中的任何磁盘.
其次, 选择块作为抽象单元而不是文件可以简化存储子系统. 简单是所有系统的目标, 但对于分布式系统来说尤其重要, 因为分布式系统失效模式实在是太多了.
存储子系统处理块, 简化存储管理(因为块都是固定大小, 很容易计算出在给定的磁盘上可以存储多少)并消除元数据问题(因为块中只有数据, 文件元数据, 如权限信息不需要与块一起存储, 由另一个独立的系统单独处理).
此外, 分布式文件系统使用复制以提供容错和可用性, 块很适合这样的场景. 为了在块数据丢失, 磁盘和机器故障等场景下保证数据可用, 每个块都会复制到少量物理独立的机器上(通常是三个). 如果一个块不可用, 可以在客户不感知的情况下读取副本. 由于以为物理原因导致块永久性损失, 那么文件系统会读取副本并复制到其他机器上, 使复制因子回到正常水平. (更多信息请参阅 97 页的"数据完整性") 同样, 一些应用程序可能会针对经常读取的文件设置较高的复制因子, 从而使集群更好的支持读取操作.
% hdfs fsck / -files -blocks列出所有文件与块的对应关系
- Namenodes and Datanodes
HDFS 集群有两种类型的节点: namenode(the master) 和一些 datanode(workers). namenode 管理文件系统命名空间. 它维护文件系统树和所有文件的元数据. 这些信息永久的存储在本地磁盘上, 它分为两个文件: 命名空间图像(namespace image)和编辑日志(edit log). namenode 知道文件的每个块都在哪个的 datanode 上; 但是它不会持久化这些数据, 因为系统启动时会重建这些信息.
为了防止 namenode 单点故障, 一种解决方法是把文件元数据同步到其他远程文件系统
另一种方法是对 namenode 做热备.
- Block Caching
通常情况下, datanode 会从磁盘读取数据块, 但对于频繁访问的文件, 则会将数据块缓存在内存中, 这块内存被称为堆外块缓存(off-heap block cache).
- HDFS Federation
namenode 在内存中保存文件系统中每个文件和块的引用, 这意味着在存储很多文件的超大群集上, 内存成为限制存储集群扩展的原因(请参阅 294 页的 "Namenode 需要多少内存").
2.x 发行版中引入的 HDFS Federation 允许通过添加 来扩展集群, 每个 namenode 管理文件系统名称空间的一部分. 例如, 一个 namenode 可能会管理所有 /user 目录下的文件, 第二个节点管理 /share 目录下的文件.
HDFS federation 中的每个 namenode 管理一个名字空间卷, 它由名字空间元数据和包含空间中所有文件块的 block pool 组成. 名字空间卷彼此独立, 这意味着 namenodes 之间不会相互通信, 而且单个 namenode 的失效不会影响其他 namenode 管理的名字空间的可用性. block pool 并不分区存储, 因此 datanodes 会向每个 namenode 注册, 并存储来自多个 block pool 的块.
要访问 HDFS federation 集群, 客户使用客户侧加载表将文件路径映射到 namenodes, 配置时使用 ViewFileSystem 和 viewfs:// 格式的 URI.
- HDFS High Availability
通过把 namenode 上的元数据复制到多个文件系统, 同时在次要 namenode 上创建检查点可以防止数据丢失, 但它不能提供文件系统的高可用性. 所有的文件系统元数据都在 namenode 上, 如果 namenode 失效, 所有客户端(包括 MapReduce 作业)都将无法读取, 写入或列出文件, 仍然会触发单点故障 single point of failure (SPOF). 因为 namenode 是唯一存储元数据和文件-块的映射的地方. 在这种情况下, 整个 Hadoop 系统将会停止服务, 直到新的名称节点可用.
在这种情况下, 要在 namenode 失效的情况下恢复, 管理员将启动一个新的 namenode, 将文件系统元数据复制过来, 并配置 datanode 和客户端使用这个新的 namenode. 新的 namenode 在完成下列步骤前无法响应请求:
- 将 namespace image 加载到内存.
- 重放 edit log
- 从 datanode 接收足够的块报告, 离开安全模式.
在大型集群上, namenode 冷启动需要 30 分钟或更多时间.
恢复时间长也是日常维护的一个问题. 实际环境中, 因为 namenode 故障非常罕见, 计划停机的情况在实践中更重要.
Hadoop 2 通过添加对 HDFS 高可用性 (HA) 的支持弥补了这种情况. 通过配置一对主备 namenode, 在主 namenode 节点失效的情况下, 备 namenode 接管其职责 继续为客户提供服务, 从而不造成重大中断. 该方案涉及几个架构层面的修改:
-
namenodes 必须使用高可用共享存储来共享 edit log. 当备节点升为主节点时, 它通过读取共享 edit log, 使其状态与主节点同步, 然后继续读取之前主节点写入的新条目.
-
数据节点必须将块报告发送到主备名称节点, 因为文件与块的映射关系存放在 namenode 节点的内存中, 而不是磁盘上.
-
必须为客户端配置一种机制来处理 namenode 故障恢复, 使其对用户透明.
-
备用名称节点需要定期基于主 namenode 名称空间创建检查点.
高可用性共享存储有两种选择:NFS 文件管理器或 quorum journal manager (QJM). QJM 是一个专用的 HDFS 实现, 唯一目就是提供高可用的 edit log, 是 HDFS 部署的推荐选择. QJM 作为一组日志节点运行, 每次编辑必须写入大多数日志节点. 通常情况下会配置三个日志节点, 所以系统可以容忍其中一个节点的丢失. 这种安排与 ZooKeeper 的工作方式类似, 但是 QJM 并没有使用 ZooKeeper. (但是请注意, HDFS HA 确实使用 ZooKeeper 用于选择主 namenode, 如下一节所述.)
如果主 namenode 失败, 备用可以很快接管 (几十秒内), 因为备节点的内存中已经有最新状态: 包括最新的 edit log 条目和最新的文件-块映射. 实际观察到的故障恢复时间将会慢一些 (大约一分钟左右), 因为系统需要谨慎的确认 主 namenode 节点是否失败.
如果主节点失败时备节点也同时出现故障, 尽管这种情况不太可能, 管理员仍然可以对备节点实施冷启动. 这并不比没有 HA 的情况更糟, 并且从操作的角度来看, 这是一个改进, 因为这个过程是一个标准的 Hadoop 内置操作流程.
从主节点到备节点的转换由一个新的实体管理, 该系统称为故障转移控制器(failover controller). 有很多种故障切换控制器, 默认实现使用 ZooKeeper 来确保只有一个名称节点处于活动状态. 每个 namenode 都运行一个轻量级故障转移控制器进程, 该进程将监视其工作状态 (使用简单的心跳机制), 一旦失败则触发故障恢复.
故障转移也可以由管理员手动触发, 例如, 在例行维护时. 因为这是故障恢复控制器主动命令主备节点切换角色, 这被称为优雅故障恢复.
如果倒换属于非优雅故障恢复, 则不能确定失败的 namenode 是否真的停止运行. 例如, 即使主名称节点仍然存在并正常运行, 低速网络或网络分区也会触发故障恢复. HA 的实现尽全力确保在这种情况下, 先前的主节点不会造成任何损坏, 这被称为围栏(fencing).
QJM 在同一时刻只允许一个 namenode 写入 edit log; 但是, 在双主情况下, 先前的主 namenode 仍然可以为客户端提供陈旧的读取请求, 因此发送一个可以终止 namenode 进程的SSH fencing 命令是一个不错的想法. 使用 NFS 文件系统共享 edit log 时, 则需要更强大的防护方法, 因为没法保证同一时间只有一个 namenode 编辑 edit log(这就是为什么建议使用 QJM). 围栏机制的职责包括撤销名称节点访问共享存储目录的权限 (通常使用特定于供应商的NFS命令) , 并通过远程管理命令禁用其网络端口. 作为最后的手段, 还有另一种称为 STONITH 的方法, 或者叫做 "对节点进行爆头", 它使用专门的配电单元强制关闭前主 namenode 节点所在的主机.
客户端的故障转移适配由客户端库自行处理. 最简单的实现是使用客户端配置来控制故障转移. HDFS URI 将逻辑主机名映射到一对 namenode 地址 (在配置文件中), 客户端库依次尝试每个namenode地址, 直到操作成功.
hadoop fs -help -- 帮助
hadoop fs -copyFromLocal input/docs/quangle.txt hdfs://localhost/user/tom/quangle.txt -- 复制
hadoop fs -mkdir books -- 创建目录, 目录保存在 namenode
hadoop fs -ls . -- 列出文件
hadoop fs -ls file:/// -- 查看本地文件系统类型| Filesystem | URI scheme | Java implementation | Description |
|---|---|---|---|
| Local | file | fs.LocalFileSystem | A filesystem for a locally connected disk with client-side checksums. Use RawLocal FileSystem for a local filesystem with no checksums. See "LocalFileSystem" on page 99. |
| HDFS | hdfs | hdfs.DistributedFileSystem | Hadoop’s distributed filesystem. HDFS is designed to work efficiently in conjunction with MapReduce. |
| WebHDFS | webhdfs | hdfs.web.WebHdfsFileSystem | A filesystem providing authenticated read/write access to HDFS over HTTP. See "HTTP" on page 54. |
| Secure WebHDFS | swebhdfs | hdfs.web.SWebHdfsFileSystem | The HTTPS version of WebHDFS. |
| HAR | har | fs.HarFileSystem | A filesystem layered on another filesystem for archiving files. Hadoop Archives are used for packing lots of files in HDFS into a single archive file to reduce the namenode’s memory usage. Use the hadoop archive command to create HAR files. |
| View | viewfs | viewfs.ViewFileSystem | A client-side mount table for other Hadoop filesystems. Commonly used to create mount points for federated namenodes (see “HDFS Federation” on page 48). |
| FTP | ftp | fs.ftp.FTPFileSystem | A filesystem backed by an FTP server. |
| S3 | s3a | fs.s3a.S3AFileSystem | A filesystem backed by Amazon S3. Replaces the older s3n (S3 native) implementation. |
| Azure | wasb | fs.azure.NativeAzureFileSystem | A filesystem backed by Microsoft Azure. |
| Swift | swift | fs.swift.snative.SwiftNativeFile System | A filesystem backed by OpenStack Swift. |
Table 3-1. Hadoop filesystems
- HTTP
Hadoop 通过将其文件系统接口公开为 Java API, 来支持 Java 应用程序访问 HDFS. 而对于非 java 语言, 则需要通过 WebHDFS 协议与 HTTP REST API 交互. 要注意的是,HTTP 接口比本地 Java 客户端慢, 因此如果使用 HTTP 接口, 应该尽可能的避免转移非常大的数据.
有两种方法可以通过 HTTP 访问 HDFS: 直接访问 HDFS, HDFS 守护进程向客户端提供 HTTP 服务; 通过访问 HDFS 的代理客户端代表使用通常的 DistributedFileSystem API. 这两种方式是如图 3-1 所示. 两者都使用 WebHDFS 协议.
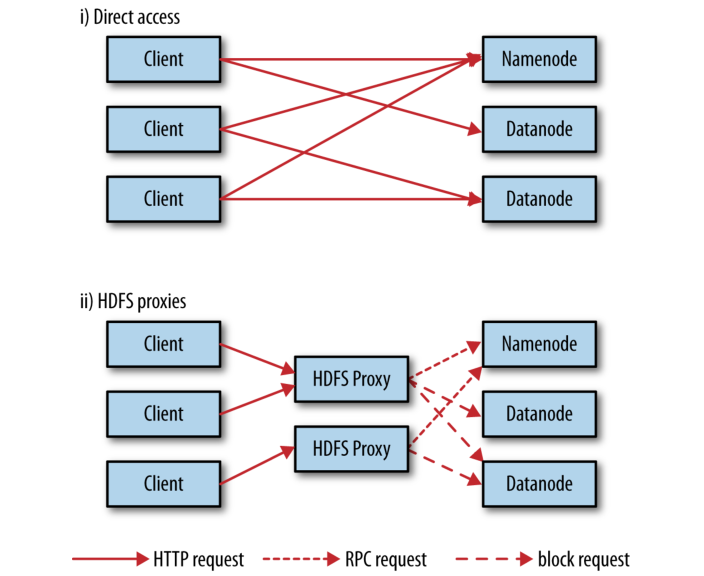
Figure 3-1. Accessing HDFS over HTTP directly and via a bank of HDFS proxies
在第一种情况下, namenode 和 datanodes 中的嵌入式 web 服务器充当 WebHDFS 端点.(WebHDFS 默认是使能的, 因为 dfs.webhdfs.enabled 默认值为 true). 文件元数据操作由 namenode 处理, 而文件读取 (还有写入) 操作首先发送到 namenode, 它将 HTTP 重定向报文发送给客户端, 指示应该从/到哪个 datanode 获取/写入数据.
通过 HTTP 访问 HDFS 的第二种方式依赖于一个或多个独立的代理服务器.(这些代理是无状态的, 所以它们可以在标准负载均衡器后面运行.)所有到集群的流量都通过代理, 所以客户端永远不会直接访问 namenode 或 datanode, 这需要配套更严格的防火墙和带宽限制策略. 通常在位于不同的数据中心 Hadoop 集群之间使用代理进行传输, 或者从外部网络访问部署在云上的 Hadoop 集群.
HttpFS 代理公开了与 WebHDFS 相同的 HTTP(和 HTTPS)接口, 因此客户端可以使用 webhdfs(或 swebhdfs)URI 访问这两者. HttpFS 代理独立于 namenode 和 datanode 守护进程, 使用 httpfs.sh 脚本启动, 默认情况下监听 14000 端口号.
-
C
-
NFS
可以使用 Hadoop 的 NFSv3 网关在本地客户端的文件系统上挂载 HDFS. 支持在一个文件尾部添加数据, 但不支持随机修改文件, 因为 HDFS 只能写入文件的末尾.
- FUSE(Filesystem in Userspace)
public class URLCat {
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[] args) throws Exception {
InputStream in = null;
try {
in = new URL(args[0]).openStream();
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}Example 3-1. Displaying files from a Hadoop filesystem on standard output using a URLStreamHandler
public class FileSystemCat {
public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
InputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}Example 3-2. Displaying files from a Hadoop filesystem on standard output by using the FileSystem directly
public class FileSystemDoubleCat {
public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
InputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
in.seek(0); // go back to the start of the file
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}Example 3-3. Displaying files from a Hadoop filesystem on standard output twice, by using seek()
Figure 3-2. A client reading data from HDFS
这种设计的一个重要方面是客户直接从 datanodes 检索数据, 并且由 namenode 引导到最优的 datanode. 这个设计允许 HDFS 支持大量的并发客户端, 因为数据流量分散到集群中的所有数据节点上. 同时, namenode 只提供数据块位置(它们存储在内存中, 使得查询操作非常高效), 如果不这样做, 随着客户数量的增长, 大量的数据读取很快就会让系统遇到瓶颈.
- Network Topology and Hadoop
两个节点间距离的大小用带宽来衡量.
Figure 3-4. A client writing data to HDFS
YARN 是 Hadoop 的集群资源管理系统.
YARN 提供了一组 API 用于集群资源管理, 但这些 API 通常不会由用户直接调用. 相反, 用户调用更高级别的分布式计算框架提供的 API, 分布式计算框架是基于 YARN 构建, 并隐藏了底层的资源管理细节. 情况如图所示 图 4-1 显示了一些分布式计算框架 (MapReduce, Spark,等等), 它们使用 YARN 作为集群计算层, 使用 HDFS 和 HBase 作为集群存储层
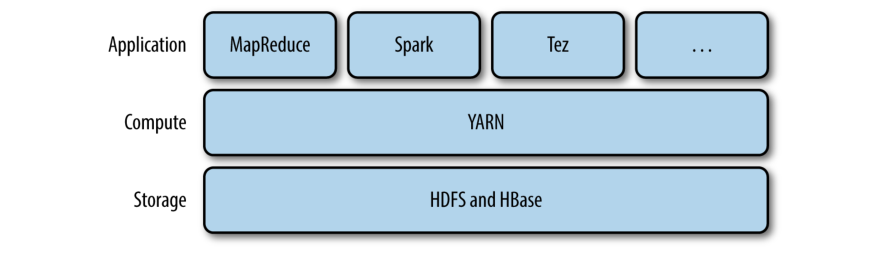
Figure 4-1. YARN applications
图 4-1 所示的框架上还可以有一个应用层, Pig, Hive 和 Crunch 都是基于 MapReduce, Spark 或 Tez(或者全部三个)的处理框架, 并且它们不直接与YARN交互.
YARN 通过两种长时间运行的守护进程提供核心服务: 资源管理器(每个群集一个)管理集群中资源的使用, 节点管理器在集群中的所有节点上运行, 用来启动和监视容器. 容器使用一组指定的资源(内存, CPU 等)执行应用程序下发的进程. 取决于 YARN 的配置方式(参见 300 页), 容器可以是一个 Unix 进程或 Linux cgroup. 图 4-2 说明了 YARN 如何上运行一个应用.
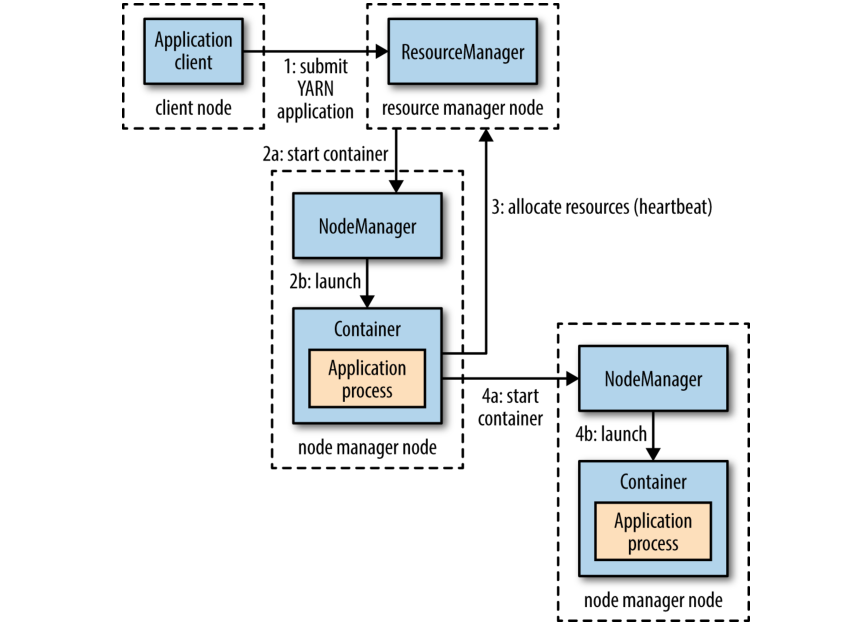
Figure 4-2. How YARN runs an application
要在 YARN 上运行应用程序, 客户端会联系资源管理器并要求它运行应用程序主进程(图 4-2 中的步骤 1). 资源管理器然后找到一个可以在容器中启动应用程序主进程的节点(步骤 2a 和 2b). 应用程序主程序在启动后会执行什么操作取决于应用. 它可以只是运行简单的运算, 然后将结果返回给客户端. 它也可以从资源管理器请求更多的容器(步骤 3), 并使用它们来运行分布式计算(步骤 4a 和 4b). 后者是 MapReduce YARN 应用程序的作法, 我们将在后面 185 页 "MapReduce 作业运行剖析" 进一步讨论.
从图 4-2 中注意到, YARN 本身并没有提供任何机制来处理应用(客户端, 主进程, 进程)之间的相互通信. 大部分 YARN 应用使用某种形式的远程通信(例如 Hadoop 的 RPC 层) 将状态更新和结果返回给客户端, 但这些与 YARN 无关.
YARN 具有灵活的资源请求模式. 请求一组容器可以细化为每个容器所需的计算机资源量(内存和CPU), 当然也可以注明容器的本地约束.
本地化对于确保分布式数据处理算法有效的使用集群带宽至关重要, 因此 YARN 允许应用对正在请求的容器指定本地约束. 无论在指定节点或机架, 甚至集群上的任何位置(机架外)申请容器, 都可以设置本地约束.
有时候 YARN 分配容器时不能满足本地约束, 这种情况下可以分配失败, 也选择忽略约束强制分配. 例如, 如果某个特定的节点被请求但是无法启动一个容器(因为已经启动了其他容器), 那么 YARN 会优先尝试在同一个机架的其他节点上启动容器, 如果再次失败, 则选择在集群中其他机架的任何节点上进行第三次尝试.
通常情况下, 在加载容器并处理 HDFS 块(运行 MapReduce 中的 map 任务)时, 应用程序将在块的三个副本其中之一所在的节点上请求容器, 或者在三副本之一所在的机架上请求容器, 如果都失败, 那么就在集群中的其他节点上加载容器.
基于 YARN 的应用程序可以在运行的任意时刻发出资源请求. 例如, 应用程序可以预先完成所有请求, 也可以采取更灵活的方法, 动态地请求更多的资源来满足变化的需求.
Spark 采用第一种方法, 在集群上预先启动固定数量的 executors (请参阅 571 页 "Spark on YARN" ). MapReduce 使用第二种方法, 并且分为两个阶段: 预先请求 map 任务容器, reduce 任务容器后面再申请. 另外, 如果任何任务失败, 则会请求新的容器, 以便失败任务可以重新运行.
YARN 应用程序的生命周期有很大差异: 从短至几秒钟到长到几天甚至是几个月. 相较于关注应用程序的运行时间, 另一种更合适的分类方法是它们映射用户作业的方式. 最简单的情况, 就是一个应用程序对应一个用户 job, 这就是 MapReduce 采用的方法.
第二种模式是一个应用程序对应一个工作流或一个用户会话. 因为容器可以在作业之间复用, 这种方法比第一种方法效率更高, 并且这种方法还可以缓存 job 之间的中间数据. Spark是使用该模型的一个例子.
第三种模式是多用户共享长期运行的应用程序. 这样的应用程序通常以某种协调角色行事. 例如, Apache Slider 有一个长期运行的应用程序 master 以启动集群上的其他应用程序. Impala 也使用此方法(请参阅 484 页 "SQL-on-Hadoop Alternatives")提供 Impala 守护进程与集群资源请求之间的代理. "永远在线" 的应用程序 master 意味着用户拥有非常低的查询响应延迟, 因为没有启动新的应用程序 master 的开销.
虽然从头开始编写基于 YARN 的应用程序是相当重要的, 但在很多情况下并不需要, 因为现有的应用程序已经可以满足大部分要求. 例如, 如果你有兴趣运行一个有向无环图(DAG)的 jobs, 那么 Spark 或 Tez 是合适的; 如果用于流处理, Spark, Samza 或 Storm 可以胜任.
有几个项目简化了构建 YARN 应用程序的过程. 前面提到的 Apache Slider 可以在 YARN 上运行现有的分布式应用程序. 用户可以在集群上独立的运行自己的应用程序实例(如 HBase), 这意味着不同的用户可以运行同一个应用程序的不同版本. Apache Slider 支持更改应用程序运行所需的节点, 暂停应用运行然后随后恢复.
Apache Twill 与 Slider 类似, 但是增加了一个简单的编程模型, 用于在 YARN 上开发分布式应用程序. Twill 允许您通过继承 Java Runnable 类来定义集群处理流程, 然后在 YARN 容器上运行. 除此之外, Twill 还支持实时日志(日志事件会回传给客户端)和命令消息(从客户端发送到 runnables).
如果这些实现都不满足我们的需求(例如应用程序有复杂的调度需求), 那么请参考 YARN 的分布式壳应用, YARN 项目本身就是一个关于如何编写 YARN 应用程序的例子. 它演示了如何使用 YARN 的客户端 API 来处理客户端或应用程序 master 与 YARN 守护进程之间的通信.
MapReduce 在 Hadoop 原始版本中的分布式实现(version 1 及更早版本)被称为 "MapReduce 1", MapReduce 2 则不同, 它基于 YARN 实现(Hadoop 2及后续版本中).
在 MapReduce 1 中, 有两种类型的守护进程控制 job 执行过程: 一个 jobtracker 和至少一个 tasktrackers. 通过把任务调度到 tasktracker 上执行, jobtracker 协调系统中所有 job 的正常运行. Tasktrackers 运行任务并将进度报告发送给 jobtracker 以记录整体进度. 如果任务失败, jobtracker 可以在不同的 tasktracker 上重新调度.
The jobtracker is also responsible for storing job history for completed jobs, although it is possible to run a job history server as a separate daemon to take the load off the jobtracker.
在 MapReduce 1 中,jobtracker 负责 job 调度(将 tasktrackers 与任务匹配) 和任务进度监控(持续跟踪任务执行, 重启失败或缓慢的任务, 并做任务簿记, 如维护计数器的总数). 而在YARN中, 这些职责由不同的实体处理: 资源管理员和应用程序 master(每个 MapReduce job 一个). jobtracker 也负责存储已完成作业的历史记录, 尽管可以以守护进程的方式运行一个作业历史记录服务器来减少 jobtracker 的负担. 在 YARN 中, timeline 服务器承担了相同的角色.
The YARN equivalent of a tasktracker is a node manager. The mapping is summarized in Table 4-1.
YARN 中的 node manager 与 tasktracker 对应. 表 4-1 列出了映射关系.
| MapReduce 1 | YARN |
|---|---|
| Jobtracker | Resource manager, application master, timeline server |
| Tasktracker | Node manager |
| Slot | Container |
Table 4-1. A comparison of MapReduce 1 and YARN components
YARN 旨在解决 MapReduce 1 中的许多短板. 使用 YARN 的好处包括以下内容:
- Scalability
YARN 支持更大的集群. MapReduce 1 在 4,000 个节点和 40,000 个任务会遇到伸缩性瓶颈, 因为 jobtracker 必须同时管理 job 和任务. YARN 凭借其分离的资源管理器/应用程序 master 架构克服了这些限制: 它旨在扩展到 10,000 个节点和 100,000 个任务.
与 jobtracker 不同的是, 应用程序的每个实例都有一个专用的应用程序 master. 这个模型实际上更接近原来的 Google MapReduce 论文, 这篇论文描述了 master 进程如何协调 map 和 reduce 任务在一组 workers 上运行.
- Availability
当服务守护进程失败时, 另一个守护进程将复制所需的状态并继续提供服务, 这就是高可用性(HA) 的实现方式. 但是, jobtracker 的内存中保存了大量迅速变化的复杂状态 (每个任务状态几秒钟就会更新一次), 使得 jobtracker 支持 HA 非常困难.
随着 jobarcker 的职责在 YARN 中分解为资源管理器和应用程序 master, 使得服务高用可以用分而治之的方法来解决: 为资源管理器提供 HA, 然后为每个基于 YARN 的应用程序提供(基于每个独立应用的层次). 实际上, Hadoop 2 支持资源管理器 HA 和 应用程序 master HA. YARN 中的故障恢复在第193页的 "“Failures”" 中有更详细的讨论.
- Utilization
在 MapReduce 1 中, 每个 tasktracker 都配置了固定大小, 静态分配 "插槽", 它们在配置时分为 map 插槽和 reduce 插槽. 一个 map 插槽只能用于运行 map 任务,而 reduce 插槽只能用于 reduce 任务.
在 YARN 中, 节点管理器管理一个资源池, 而不是一个固定大小的指定插槽. 因为集群上仅有 map 插槽, 所以 reduce 任务不得不等待, 这种情况在基于 YARN 的 MapReduce 上是不会出现的. 只要有集群上有足够的资源运行任务, 那么任务就不用等待.
此外, YARN 中的资源管理是非常细粒度的, 因此应用程序可以按需获取资源, 而不是被不可拆分的插槽限制, 对于一个任务来说, 插槽既有可能太大(浪费资源), 也有可能太小(这可能导致分配失败).
- Multitenancy
从某种意义上来讲,YARN 最大的好处是使得 Hadoop 对其他除了 MapReduce 以外的分布式应用开放. MapReduce 只是 YARN 支持的众多分布式应用之一.
用户甚至可以在同一个 YARN 集群上运行不同版本的 MapReduce, 这使得升级 MapReduce 的过程更加可控.(但是请注意, MapReduce 的某些部分, 例如 job 历史记录服务器, 洗牌(shuffle)处理程序以及 YARN 本身, 仍然需要升级.)
由于 Hadoop 2 已经被广泛使用, 并且是最新的稳定版本, 除非另有说明, 本书其余部分的术语 "MapReduce" 指的都是 MapReduce 2. 第 7 章将详细介绍 MapReduce 如何基于 YARN 运行.
在理想的世界中,YARN 应用程序所提出的请求将立即得到响应. 然而, 在现实世界中资源是有限的, 并且在繁忙的集群中, 应用程序在请求完成前通常需要等待. YARN 调度器的工作就是依据某些定义好的策略为应用程序分配资源. 通常来说调度是一个难题, 并且没有一个通用的 "最佳" 策略, 这就是 YARN 提供可选择的调度器和可配置策略的原因.
YARN 提供三种调度器: FIFO, 和公平调度器. FIFO 调度器将应用程序放入队列中, 并按照提交顺序运行它们(先入先出). 首先为队列中第一个应用程序分配资源; 一旦它的请求已经满足, 接着为队列中的下一个应用程序提供服务, 依此类推.
FIFO 调度器具有易于理解和不需要配置的优点, 但它不适用于集群共享场景. 大型应用程序会耗光集群中的所有资源, 因此队列后面的应用都必须等待. 在共享群集上最好使用 Capacity Scheduler 或 Fair Scheduler. 这两种调度器都在保证长时间运行的作业及时完成的同时, 也允许其他用户的查询能够在合理的时间内得到响应.
调度程序之间的区别如图 4-3 所示, 其中显示了在 FIFO (i)的调度下小作业在大作业完成前被阻塞.
容量优先调度器(图 4-3 中的 ii) 使用一个独立的专用队列存放小型作业, 这样小型作业一旦提交就可以开始运行, 虽然这是以牺牲集群的利用率为代价的, 因为必须为该队列中的作业保留一部分的容量. 这意味着大型作业的运行时间会比使用 FIFO 调度器时要长.
公平调度器(图 4-3 中的 iii) 不需要保留一定数量的容量, 因为它将在所有正在运行的作业之间动态平衡资源. 一个(大型)作业开始, 这是此时系统上唯一的工作, 所以它获得了所有的集群资源. 当第二个(小型)作业启动时, 它将得到集群资源的一半, 以便每个作业公平的使用集群资源.
请注意, 从第二个作业开始到获取资源之间存在滞后, 因为它必须等待前一个作业完成容器的释放. 在小型作业完成后, 大型作业可以重新获取全部容器. 总体效果是较高的集群利用率和小型工作及时完成(避免了被大型作业阻塞).
图 4-3 对比了三个调度程序的基本操作. 在接下来的两节中,我们将研究 Capacity 调度器和 Fair 调度器的一些高级配置项.
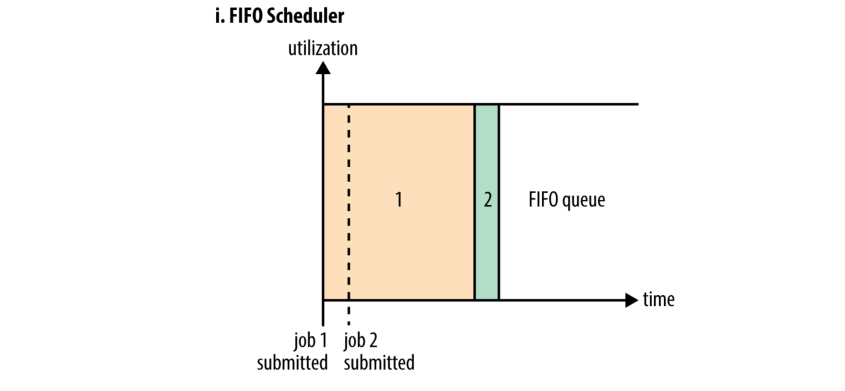
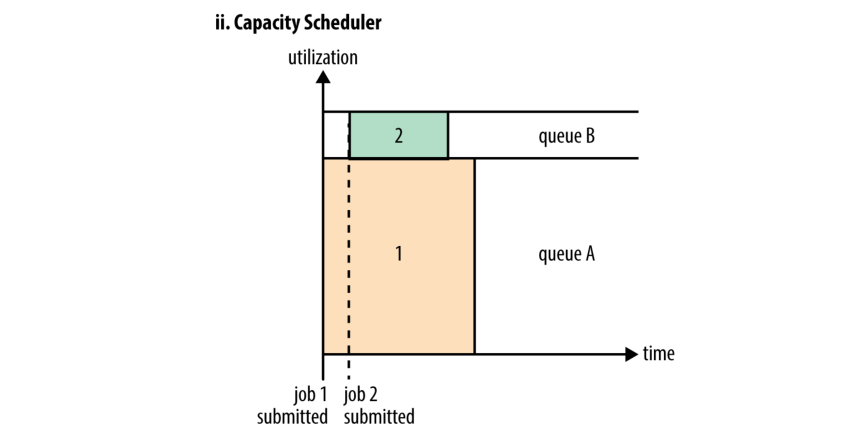
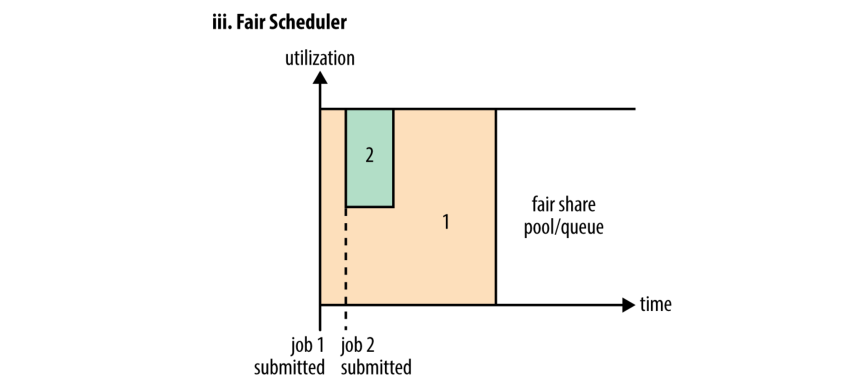
Figure 4-3. Cluster utilization over time when running a large job and a small job under the FIFO Scheduler (i), Capacity Scheduler (ii), and Fair Scheduler (iii)
容量优先调度器允许在组织层面共享 Hadoop 集群, 为每个组织在集群分配一定的容量. 每个组织拥有一个专用的队列, 限定使用一定百分比的系统容量. 队列可以继续进行层次分割, 允许组织为不同的用户组配置容量. 在单个队列中, 应用程序使用 FIFO 的方式调度.
正如我们在图 4-3 中看到的, 单个作业用到的资源不会超出队列容量的限制. 但是, 如果队列中有多个作业而系统中又有空闲资源, 那么 Capacity Scheduler 可能会将空闲资源分配给队列中的其他作业, 即使这会导致作业所在队列实际使用的容量越限. 这种操作被称为队列弹性(queue elasticity).
在正常操作中, 容量优先调度器不会通过杀掉容器来强行抢占, 因此, 如果队列由于缺乏作业而导致分配的资源空闲, 然后作业数量又增长了, 则只有当容器资源从其他地方释放, 队列中的作业才能开始运行. 通过给队列配置一个最大容量可以缓解这种情况, 以便他们不会吃掉太多其他队列的资源. 当然, 这是以排队弹性为代价的, 所以应该通过反复试错找到一个合理的取舍.
想象一个如下图所示的队列层次结构:
root ├── prod └── dev ├── eng └── science
示例 4-1 中的清单显示了一个名为 capacity-scheduler.xml 的容量优先调度器配置文件, 与上面列出的层次结构匹配. 它在 root 队列下定义了两个队列, prod 和 dev, 分别分配 40% 和 60% 的容量. 注意, 指定队列通过设置配置文件的 yarn.scheduler.capacity.. 属性进行配置, 其中 是队列的分层(虚线)路径, 如 root.prod.
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>prod,dev</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.queues</name>
<value>eng,science</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.prod.capacity</name>
<value>40</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>60</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.maximum-capacity</name>
<value>75</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.eng.capacity</name>
<value>50</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.science.capacity</name>
<value>50</value>
</property>
</configuration>Example 4-1. A basic configuration file for the Capacity Scheduler
正如你所看到的, dev 队列容量被进一步平分给 eng 和 science 队列(各占 50%). 这样, dev 队列的最大容量设置为 75%, 所以当 prod 队列空闲时, dev 队列不会用完所有集群资源. 换句话说, prod 队列总是有 25% 的集群可供随时使用. 由于其他队列没有设置最大容量, 这可能会导致 eng 队列和 science 队列用掉 dev 队列的所有资源(集群资源的 75%), 或者导致 prod 队列用掉整个集群的资源.
除了配置队列层次结构和容量外, 还有一些设置可以控制单个用户或应用程序能够分到的最大资源, 有多少个应用程序可以同时运行, 为队列配置 ACL. 详情见参考页面.
- Queue placement
我们可以为应用程序指明放入哪个队列. 例如, 在 MapReduce 中, 您可以通过设置属性 mapreduce.job.queue 来指定要使用的队列的名称. 如果队列不存在, 那么在提交时会返回错误. 如果没有指定队列, 应用程序将被放入一个名为 default 的队列.
对于容量优先调度器, 因为完整的层级名称不能被识别, 队列名应该是完整名称的最后一部分. 因此, 对于前面的示例配置, prod 和 eng 没问题, 但 root.dev.eng 和 dev.eng 不起作用(无法).
公平调度器试图让所有正在运行的应用程序都能获得相同的资源份额. 图 4-3 显示了在同一队列中的应用如何实现公平分享; 然而, 像我们即将看到的一样, 公平分享实际上也适用于队列之间.
对于公平调度器来说, queue 和 pool 是一回事
为了理解资源如何在队列之间共享, 假设有两个用户 A 和 B, 每个都有自己的队列(图 4-4). A 启动了一项作业, 并获取了所有的集群资源, 因为当前 B 没有作业. 然后 B 开始工作, 而 A 的作业仍然是运行, 过了一段时间, 每个作业都使用一半资源. 现在, 如果 B 在其他作业仍在运行时启动第二项作业, 它将与 B 的其他作业共享其资源, 所以 B 的每个工作将有占有系统资源的四分之一, 而 A 将继续占有一半. 结果就是在用户之间公平分享资源.
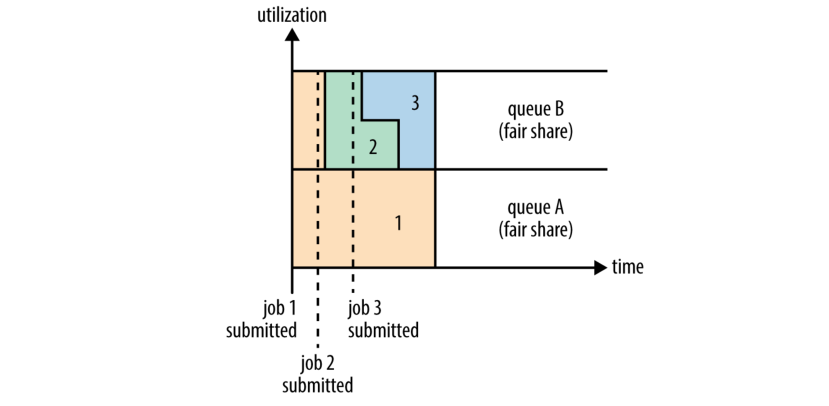
Figure 4-4. Fair sharing between user queues
- Enabling the Fair Scheduler
调度器通过 yarn.resourcemanager.scheduler.class 来设置. 默认使用容量优先调度器 (虽然某些 Hadoop 发行版默认使用公平调度器,例如 CDH), 但是这可以通过将 yarn-site.xml 中的 yarn.resourcemanager.scheduler.class 设置为调度程序的完整类名来改变, 如 org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler.
- Queue configuration
公平调度器使用类路径下名为 fair-scheduler.xml 的文件来配置.(配置文件的名称可以通过设置属性 yarn.scheduler.fair.allocation.file 进行更改). 在没有配置文件的情况下, 公平调度器如前所述工作: 所有应用程序都放置在一个的队列, 这个队列是在用户提交第一个应用后动态创建的.
配置文件支持按队列进行配置. 这允许配置容量优先调度器支持的分层队列. 例如, 我们可以使用例 4-2 中的配置文件, 像我们为容量调度器所做的那样, 单独定义定义 prod 和 dev 队列.
<?xml version="1.0"?>
<allocations>
<defaultQueueSchedulingPolicy>fair</defaultQueueSchedulingPolicy>
<queue name="prod">
<weight>40</weight>
<schedulingPolicy>fifo</schedulingPolicy>
</queue>
<queue name="dev">
<weight>60</weight>
<queue name="eng" />
<queue name="science" />
</queue>
<queuePlacementPolicy>
<rule name="specified" create="false" />
<rule name="primaryGroup" create="false" />
<rule name="default" queue="dev.eng" />
</queuePlacementPolicy>
</allocations>Example 4-2. An allocation file for the Fair Scheduler
配置文件中使用嵌套的队列元素定义队列层次. 所有队列都是 root 队列的后代, 即使 root 队列并没有在配置文件中列出来. 在这里我们将 dev 队列细分为 eng 队列和 science 队列.
队列可以有权重, 用于公平分配的份额计算. 在上面的例子中, 当 prod 和 dev 之间的比例划分为40:60时, 集群分配被认为是公平的. eng 和 science 队列没有指定权重, 所以他们平分资源. 但是权重与百分比不同, 为了便于理解, 示例中使用和为 100 的数字. 但我们也可以为 prod 和 dev 队列分别指定 2 和 3 的权重以实现相同的分配.
在设置权重时, 别忘了考虑默认队列和动态创建的队列(例如以用户命名的队列). 这些没有在分配文件中指定, 但它们的权重仍然为 1.
队列之间的调度策略是可以选择的. 全局的默认策略可以在顶层元素 defaultQueueSchedulingPolicy 中设置; 如果省略, 将会使用公平调度器. 尽管它的名字是公平, Fair Scheduler 也支持在队列内部实行 FIFO 策略, 以及本章后面所述的主导资源公平(Dominant Resource Fairness).
可以在队列元素中设置 schedulingPolicy 元素来覆盖全局配置, 为指定队列设置策略. 在这个例子中, 因为我们需要生产性作业串行运行并在最短的时间完成, prod 队列选择使用 FIFO 调度. 请注意, prod 队列和 dev 队列之间依然公平分配资源, eng 和 science 队列之间也是一样.
尽管在此配置文件中未显示, 队列支持最少资源配置, 最大资源配置, 以及配置同时运行应用的最大数量. 最低资源设置不是硬性限制, 而是供调度器决定资源分配的优先权. 假设同时有两个队列当前资源低于分配资源, 那么低于其最低资源设置更多的队列优先获得资源. 最少资源设置也用于抢占.
- Queue placement
公平调度器使用基于规则的系统来确定应用程序应该放到哪个队列. 在例 4-2 中, queuePlacementPolicy 元素包含一系列规则, 调度器依次尝试其中的每一个, 直到匹配成功. 第一条规则是将应用程序放到它指定的队列中; 如果没有指定队列, 或者指定的队列不存在, 则规则匹配失败, 继续尝试下一个规则. primaryGroup 规则尝试将应用程序放在以用户所在 unix 组命名的队列中; 如果没有这样的队列, 将尝试匹配下一个规则. 默认规则是一个万能的规则(肯定能匹配上), 总是将应用程序放在 dev.eng 队列.
queuePlacementPolicy 可以完全省略, 在这种情况下默认行为如下:
<queuePlacementPolicy>
<rule name="specified" />
<rule name="user" />
</queuePlacementPolicy>换句话说, 除非明确指定队列, 否则放在以用户名命名的队列, 如有该队列不存在则创建它.
另一个简单的队列放置策略是所有应用程序都放在相同(默认)队列. 这允许资源在应用程序之间公平分享, 而不是用户之间. 定义等同于:
<queuePlacementPolicy>
<rule name="default" />
</queuePlacementPolicy>也可以不使用配置文件, 通过设置 yarn.scheduler.fair.user-as-default-queue 为 false, 应用程序将放置在默认队列中而不是按用户命名的队列. 此外, yarn.scheduler.fair.allow-undeclared-pools 应设置为 false, 以便用户不能即时创建队列.
- Preemption
当作业提交到繁忙集群上的空队列时, 在资源从集群上已经运行的作业中释放出来之前, 作业无法启动. 为了使工作开始的时间更加可确定, 公平调度器支持抢占.
抢占允许调度程序杀死占用超限资源队列所属的容器, 以便将资源分配给当前资源低于其分配资源的队列. 请注意, 抢占会降低整体集群的整体效率, 因为被终止的容器需要重新运行.
通过将 yarn.scheduler.fair.preemption 设置为 true 来启用全局抢占. 有两个抢占相关的超时设置: 一个用于最小共享, 一个用于公平共享, 都以秒为单位. 默认情况下不设置超时, 所以为了开启容器抢占, 你至少要设置其中的一个.
如果一个队列在最小共享时间超时后, 仍未收到满足其最小份额的资源, 则调度器可以抢占其他容器. 通过配置文件中的顶层元素 defaultMinSharePreemptionTimeout 为所有队列设置默认超时, 通过配置队列元素下的 minSharePreemptionTimeout 为每个队列设置超时.
同样, 当公平共享超时时, 如果一个队列实际占有的资源低于应得资源的一半, 那么调度器可以抢占其他容器. 默认超时值通过 defaultFairSharePreemptionTimeout 来设置, 这个配置是全局生效的, 如果要对指定队列设置超时值, 请修改队列配置项 fairSharePreemptionTimeout. 阈值也可以通过设置 defaultFairSharePreemptionThreshold 和 fairSharePreemptionThreshold (基于单个队列)来修改, 默认值是 0.5.
所有 YARN 调度器都试图将任务本地化(任务调度到离数据最近的节点). 在繁忙的集群上, 如果调度程序打算在一个特定的节点运行任务时, 很有可能其他容器正在节点上运行. 显而易见的行动是立即在同一机架上分配容器. 但是, 我们在实践中观察到, 等待一小段时间(仅仅几秒钟)可以大大增加按原要求分配到容器的机会, 并因此提高集群的效率. 这个特性被称为延迟调度, 容量调度器和公平调度器都支持它.
YARN 集群中的每个 node manager 周期性地向资源管理器发送心跳请求 - 默认情况下每秒一个. 心跳报文包含 node manager 所在节点的当前运行容器和空闲资源信息, 每次心跳都是应用程序启动容器的潜在调度机会.
使用延迟调度时, 调度程序不会简单地在一有机会就启动调度, 而是等待调度机会达到给定的最大数量后再开始调度, 放松本地约束, 分配资源, 然后等待下一次调度的机会.
对于容量优先调度器, 延迟调度需要将 yarn.scheduler.capacity.node-locality-delay 设置为一个正整数, 表示它在放松本地约束, 在同一机架上选择其他节点之前打算放弃多少次调度机会.
公平调度器也使用调度机会的数量来决定延迟, 虽然这里的数量表示为集群的占比. 例如, yarn.scheduler.fair.locality.threshold.node 设置为 0.5 , 意味着只有等到集群中的一半节点出现调度机会后, 调度器才会选择同一机架中的其他节点. 有一个相应的属性, yarn.scheduler.fair.locality.threshold.rack, 用于设置选择另一个机架而不是数据所在机架所需要的阈值.
假设只调度一种类型的资源, 比如说内存, 那么容量或公平的概念很容易界定. 如果两个用户在运行应用, 您可以测量两个应用程序使用的内存并进行比较. 但是, 当调度多种类型的资源时, 情况会变得复杂. 假设某个用户的应用需要大量 CPU 和很少内存, 另一个则需要很少的 CPU 和大量的内存, 此时这两个应用如何比较?
YARN 中的调度器解决这个问题的方式是查看每个用户的主导资源并将其用来衡量集群使用情况. 这种方法被称为优势资源公平, 简称 DRF. 这个想法最好用一个简单的例子来说明.
想象一下集群中共有 100 个 CPU 和 10 TB 内存. 应用程序 A 请求 (2 个 CPU, 300 GB 内存) 的容器, 应用程序 B 请求容器 (6 个 CPU, 100 GB 内存). A 的请求占比是集群的(2%, 3%), 所以内存占据了优势地位, 因为它内存占比(3%) 大于 CPU占比 (2%). B 的请求是(6%, 1%), 所以 CPU 占优势地位. 因为 B 优势资源请求比 A 要大一倍(6% 比 3%), 它将基于公平分享下比 A 多分配一倍的容器.
默认情况下不使用 DRF, 所以在资源计算时只考虑内存并且忽略 CPU . Capacity Scheduler 可以通过将 capacity-scheduler.xml 中的 yarn.scheduler.capacity.resource-calculator 配置为 org.apache.hadoop.yarn.util.resource.DominantResourceCalculator, 来启用 DRF.
对于 Fair Scheduler, 可以通过设置顶层元素 QueueSchedulingPolicy 设置为 drf 来启用 DRF.
Hadoop 带有一组用于数据 I/O 的原型. 其中一些是比 Hadoop 更通用的技术, 例如数据完整性和压缩, 但在处理多 TB 数据集时需要特别考虑. 其他的是 Hadoop 工具或 API, 它们构成了用于开发分布式系统的构建块, 例如序列化框架和磁盘上的数据结构.
Hadoop 的用户期望在数据存储和处理期间不会遇到数据丢失或损坏. 但是, 因为磁盘或网络上的每个 I/O 操作都有很小的可能会引入错误, 当流经系统的数据量与 Hadoop 的处理能力一样大时, 发生数据损坏的可能性会变得很高.
检测损坏数据的常用方法是在数据进入系统时计算校验和, 然后通过不可靠通道传输后再次计算, 如果新生成的校验和原始值不完全匹配, 数据被认为已经损坏. 这种技术没有提供任何修复数据的方法 - 它仅仅是错误检测. (这也是一个不使用低端硬件原因; 特别是一定要使用 ECC 内存.)注意不仅仅是数据, 校验和也可能损坏, 但这是不太可能的, 因为校验和比数据小得多.
常用的错误检测码是 CRC-32(32位循环冗余校验), 它为任意大小的输入计算出一个32位整数校验和. Hadoop 的 ChecksumFileSystem 中使用 CRC-32 做校验, 而 HDFS 使用更高效被称为 CRC-32C 的变种.
HDFS 透明地校验所有写入的数据, 默认情况下在读取数据时也进行校验. 每个 dfs.bytes-per-checksum 大小的数据都会创建一个独立的校验和. dfs.bytes-per-checksum 的默认值是512字节, 因为 CRC-32C 校验和长度是4个字节, 存储开销小于 1%.
Datanodes 负责在存储数据之前验证接收数据的一致性. 包括从客户端收到的数据和从其他 datanodes 复制过来的数据. 客户端通过将数据其发送到 datanodes 管道来进行写入(如第3章所述), 管道中的最后一个 datanode 负责验证校验和. 如果 datanode 检测到错误, 客户端会收到 IOException 的子类构成的异常, 然后决定该如何处理(例如重试).
当客户端从 datanodes 读取数据时, 他们也会验证校验和, 并将它们与那些存储在 datanode 中的校验和进行比较. 每次验证校验和, datanode 都会记录一条日志, 所以它知道每个块的最后一次验证发生在何时. 当一个客户成功验证某个块, 它会通知 datanode 更新其日志. 保持记录对于检测磁盘错误非常有用.
除了在客户端读取时进行块验证之外, 每个 datanode 还会在后台线程中运行 DataBlockScanner, 定期验证 datanode 中存储的所有数据块. 这是为了防止因为物理存储介质中的 "位元腐烂" 而造成的数据损坏. 有关如何访问扫描日报的详细信息, 请参阅 328 页的 "Datanode 块扫描器".
由于 HDFS 存储块的副本, 因此可以通过复制一个没有损坏的副本来 "修复" 损坏的块. 具体的工作方式是, 如果客户端在读取块时检测到错误, 会在抛出 ChecksumException 异常前将坏块所在 datanode 报告给 namenode. namenode 将块标记为已损坏, 此后它不会将更多客户端请求指向它, 也不会尝试将损坏的块复制到另一个 datanode. 然后它会在其他 datanode 上新建一个该块的副本, 这样使得损坏块的复制因子恢复到期望值. 一旦发生这种情况, 损坏的块将被删除.
在调用 open() 方法读取文件之前, 可以通过将 false 参数传递给 setVerifyChecksum() 来禁用校验. 你也可以在 shell 上执行命令来获得相同的效果, 命令写作 -get 或 -copyToLocal, 记得带上参数 -ignoreCrc. 如果你发现文件损坏, 决定如何自行处理它时, 此功能很有用. 比如, 你可能会想查看损坏的文件在删除前是否能进行修复.
你可以用 hadoop fs -checksum 查看文件的校验和. 这个命令可以有效检查 HDFS 中的两个文件是否具有相同的内容 - 这正是 distcp 所做的工作(请参阅 76 页上的 "使用 distcp 进行并行复制").
Hadoop LocalFileSystem 用于客户端的校验. 这意味着当你写入一个文件时, 它会在你不感知的情况下, 在文件的同一目录中创建一个隐藏文件文件 .filename.crc, 这个隐藏文件包含文件中每个块的校验. 块的大小由 file.bytes-per-checksum 属性来控制, 默认为 512 字节. 块大小作为元数据存储在 .crc 文件中, 因此即使块大小设置做了更改, 文件也可以可以正确读回. 读取文件时也会进行校验, 如果检测到错误, 则 LocalFileSystem 抛出一个 ChecksumException 异常.
校验和计算效率比较高(Java 中它们是用 native 代码实现), 在读取或写入文件时仅增加几个百分比的开销. 对于大多数应用程序来说, 为了保证数据完整性, 这点代价是能够接受的. 但我们也可以禁用校验和, 这通常是因为底层文件系统本身就支持文件校验. 这种情况下使用 RawLocalFileSystem 代替 LocalFileSystem. 要在应用程序中全局使能此操作, 只需通过将属性 fs.file.impl 设置为 org.apache.hadoop.fs.RawLocalFileSystem 来重新映射文件 URIs 即可. 或者, 你只需要在读取场景下禁用校验和, 可以直接创建一个 RawLocalFileSystem 实例, 例如:
Configuration conf = ...
FileSystem fs = new RawLocalFileSystem();
fs.initialize(null, conf);LocalFileSystem 使用 ChecksumFileSystem 来完成它的工作(LocalFileSystem 继承了抽象类 ChecksumFileSystem), 而这个类使得将校验功能添加到其他(不支持校验)文件系统变得容易, 如 ChecksumFileSystem 只是 FileSystem 的一个包装. 示例代码如下:
FileSystem rawFs = ...
FileSystem checksummedFs = new ChecksumFileSystem(rawFs);底层文件系统被称为 raw filesystem, 可以使用 ChecksumFileSystem 类中的 getRawFileSystem() 方法获取. ChecksumFileSystem 有许多有用的方法, 例如调用 getChecksumFile() 获取文件对应的校验和文件的路径.
如果 ChecksumFileSystem 在读取文件时检测到错误, 则会调用类方法 reportChecksumFailure(). 该函数的默认实现是什么都不做, 但是 LocalFileSystem 类会将有问题的文件及其校验和移动到相同的设备上的 bad_files 目录. 管理员应定期检查这些损坏的文件并采取对应措施.
文件压缩带来两大好处: 它减少了存储文件所需的空间, 加速了数据的传输, 数据的写入及读出. 在处理大量的数据时带来的效率提升是显著的, 所以请仔细考虑如何在 Hadoop 中使用压缩.
有许多不同的压缩格式, 工具和算法, 每种都有不同的特点. 表 5-1 列出了 Hadoop 支持的一些常见算法.
Table 5-1. A summary of compression formats
| Compression format | Tool | Algorithm | Filename extension | Splittable? |
|---|---|---|---|---|
| DEFLATE | N/A | DEFLATE | .deflate | No |
| gzip | gzip | DEFLATE | .gz | No |
| bzip2 | bzip2 | bzip2 | .bz2 | Yes |
| LZO | lzop | LZO | .lzo | No |
| LZ4 | N/A | N/A | .lz4 | No |
| Snappy | N/A | Snappy | .snappy | No |
所有的压缩算法都是出空间效率/时间效率的折衷: 更快的压缩和解压缩速度通常以较大的空间为代价. 表 5-1 中列出的工具通过提供九种不同的选项, 在压缩时提供一些控制方式: -1 表示压缩速度最优, -9 表示空间占用最优. 例如, 以下命令使用最快的压缩方法创建一个压缩文件 file.gz:
% gzip -1 file不同的工具有非常不同的压缩特性. gzip 是一个通用的压缩器, 算法的空间/时间效率相对来说比较均衡. bzip2 压缩比比 gzip 更有效, 但速度更慢. bzip2 的解压速度比压缩速度快, 但仍然比其他格式慢. LZO, LZ4 和 Snappy, 这些算法的压缩速度都比 gzip 快一个数量级, 但文件压缩比较低. Snappy 和 LZ4 的解压速度也显着快于 LZO.
表 5-1 中的 "可拆分" 列表示压缩格式是否支持拆分 (也就是说,你是否可以在流中查找任意一点并开始读取). 可拆分的压缩格式特别适用于 MapReduce; 进一步的讨论请参阅 105 页的 "压缩和输入拆分".
编解码器是压缩 - 解压缩算法的实现. 在 Hadoop 中, 编解码器由 CompressionCodec 接口的实现来表示. 例如, GzipCodec 封装了 gzip 的压缩和解压缩算法. 表 5-2 列出了可用于 Hadoop 的编解码器.
Table 5-2. Hadoop compression codecs
| Compression format | Hadoop CompressionCodec |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| LZ4 | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
LZO 库是基于 GPL 开源协议的, 可能不包含在 Apache 发行版中, 出于这个原因, Hadoop 依赖的编解码器必须在 Google 上单独下载(或 GitHub, 包括错误修复和更多工具). 你通常需要 LzopCodec, 兼容 lzop 工具, 实质上是 LZO 格式用了额外的标. 还有一个用于纯 LZO 格式的 LzoCodec 编解码器, 它支持 .lzo_deflate 扩展名的文件.
- Compressing and decompressing streams with CompressionCodec
要将数据压缩并写入输出流, 请使用 createOutputStream(OutputStream out) 方法创建一个 CompressionOutputStream 指向已经写入的未压缩数据, 并将其以压缩形式写入底层流. 相反的, 为了解压缩从输入流读取的数据, 请调用函数 createInputStream(InputStream in) 以获取 CompressionInputStream, 它允许您从底层流中读取到解压后的数据.
CompressionOutputStream 和 CompressionInputStream 类似于 java.util.zip.DeflaterOutputStream 和 java.util.zip.DeflaterInputStream, 不同的是前者支持重置其底层的压缩器和解压器. 这对于将数据流压缩成许多独立块的应用程序来说非常重要, 如 127 页的 "SequenceFile" 中所述的 SequenceFile 中的单独块.
Example 5-1. A program to compress data read from standard input and write it to standard output
public class StreamCompressor {
public static void main(String[] args) throws Exception {
String codecClassname = args[0];
Class<?> codecClass = Class.forName(codecClassname);
Configuration conf = new Configuration();
CompressionCodec codec = (CompressionCodec)ReflectionUtils.newInstance(codecClass, conf);
CompressionOutputStream out = codec.createOutputStream(System.out);
IOUtils.copyBytes(System.in, out, 4096, false);
out.finish();
}
}- Inferring CompressionCodecs using CompressionCodecFactory
CompressionCodecFactory 通过 getCodec() 方法将文件扩展名映射到 CompressionCodec.
Example 5-2. A program to decompress a compressed file using a codec inferred from the file’s extension
public class FileDecompressor {
public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path inputPath = new Path(uri);
CompressionCodecFactory factory = new CompressionCodecFactory(conf);
CompressionCodec codec = factory.getCodec(inputPath);
if (codec == null) {
System.err.println("No codec found for " + uri);
System.exit(1);
}
String outputUri = CompressionCodecFactory.removeSuffix(uri, codec.getDefaultExtension());
InputStream in = null;
OutputStream out = null;
try {
in = codec.createInputStream(fs.open(inputPath));
out = fs.create(new Path(outputUri));
IOUtils.copyBytes(in, out, conf);
} finally {
IOUtils.closeStream(in);
IOUtils.closeStream(out);
}
}
}- Native libraries Java 中的 Native 代码是为了提升性能.
表 5-4 显示了每种压缩格式的 Java 实现和 native 的实现. 所有格式都有 native 实现, 但并非全部都有 Java 实现(例如 LZO).
Table 5-4. Compression library implementations
| Compression format | Java implementation? | Native implementation? |
|---|---|---|
| DEFLATE | Yes | Yes |
| gzip | Yes | Yes |
| bzip2 | Yes | Yes |
| LZO | No | Yes |
| LZ4 | No | Yes |
| Snappy | No | Yes |
CodecPool. 如果您正在使用 native 库, 并且你的应用正在进行大量压缩或解压缩操作, 考虑使用 CodecPool, 它允许你重用压缩器和解压缩器, 从而摊销创建这些对象的成本.
Example 5-3. A program to compress data read from standard input and write it to standard output using a pooled compressor
public class PooledStreamCompressor {
public static void main(String[] args) throws Exception {
String codecClassname = args[0];
Class<?> codecClass = Class.forName(codecClassname);
Configuration conf = new Configuration();
CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(codecClass, conf);
Compressor compressor = null;
try {
compressor = CodecPool.getCompressor(codec);
CompressionOutputStream out = codec.createOutputStream(System.out, compressor);
IOUtils.copyBytes(System.in, out, 4096, false);
out.finish();
} finally {
CodecPool.returnCompressor(compressor);
}
}
}在考虑如何压缩将由 MapReduce 处理的数据时, 重要的是要了解压缩格式是否支持分割. 假设有一个大小为 1 GB的未压缩文件文件存储在 HDFS 中. HDFS 块大小为 128 MB, 该文件将被存储为 8 个块, 一个使用该文件的 MapReduce 作业将创建 8 个分片, 每个分片对应一个 map 任务.
现在想象一下, 有一个压缩后的 gzip 文件, 大小为 1 GB. 跟之前一样, HDFS 会用 8 个块存储该文件. 但是, 这种情况下应用程序将无法工作, 因为 map 任务无法读取单个块中解压出的数据(对于 gzip 来说, 它认为压缩后输出的是单个文件, 当多个 map 任务同时处理压缩后的分块时, 会导致无法识别, 因为无法得知). gzip 格式使用 DEFLATE 存储压缩后的数据, 并使用 DEFLATE 将数据存储为一系列压缩块. 问题在于, 这些 DEFLATE 压缩块的头部没有保留任何可以用来在文件流中定位的信息, 使得读取数据能够一直读取到下一个块, 从而与流进行同步. 正因为这个原因, gzip 压缩文件不支持框架对其进行分片.
在这种情况下, MapReduce 不会尝试分割 gzip 文件, 因为它知道输入是 gzip 格式 (通过查看文件扩展名). 同时, MapReduce 作业为了能够运行, 不得不牺牲本地性: 框架将调度唯一的 map 任务处理所有 8 个 HDFS 块, 而其中大多数块不在 map 任务运行的服务器上. 此外, 因为 map 任务数量较少, 作业细化程度较低, 运行时间会较长.
如果我们假设的例子中的文件是 LZO 文件, 我们会遇到同样的问题, 因为底层的压缩格式不能为读取者提供与流同步的方式. 但是, 可以使用 Hadoop LZO 库附带的索引器工具 LZO 文件进行预处理, 该工具可以从 101 页上 "编解码器" 中列出的 Google 和 GitHub 站点中获取. 该工具为分片点构建索引, 有效地使得在遇到类似格式的输入时可进行分片.
另一方面, bzip2 文件在块之间提供了同步标记(pi 的 48 位近似值), 所以支持分片. (表 5-1 列出了每个压缩格式是否支持分片.)
如果您的输入文件是压缩后的, MapReduce 读取时将自动解压, 解压前通过文件扩展名来确定使用哪个编解码器.
为了压缩 MapReduce 作业的输出, 请在作业配置中将 mapreduce.output.fileoutputformat.compress 属性设置为 true, 并设置 mapreduce.output.fileoutputformat.compress.codec 属性的类名为你想使用的压缩编解码器. 或者, 您可以在代码中调用静态方法 FileOutputFormat 来设置这些属性.
Example 5-4. Application to run the maximum temperature job producing compressed output
public class MaxTemperatureWithCompression {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: MaxTemperatureWithCompression <input path> " + "<output path>");
System.exit(-1);
}
Job job = new Job();
job.setJarByClass(MaxTemperature.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileOutputFormat.setCompressOutput(job, true);
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
job.setMapperClass(MaxTemperatureMapper.class);
job.setCombinerClass(MaxTemperatureReducer.class);
job.setReducerClass(MaxTemperatureReducer.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}- Compressing map output
即使您的 MapReduce 应用程序读取和写入都是未压缩的数据, 通过压缩 map 阶段的中间输出, 它也可能会受益. map 输出被写入磁盘并通过网络传输到 reducer 节点, 所以通过使用一个快速的压缩器如 LZO, LZ4 或 Snappy, 你可以获得性能提升, 因为压缩后传输的数据量会减少. 配置属性启用 map 输出压缩和设置压缩格式, 如表 5-6 所示.
Table 5-6. Map output compression properties
| Property name | Type | Default value | Description |
|---|---|---|---|
| mapreduce.map.output.compress | boolean | false | Whether to compress map outputs |
| mapreduce.map.output.compress.codec | Class | org.apache.hadoop.io.compress.DefaultCodec | The compression codec to use for map outputs |
序列化是将结构化对象转换为字节流的过程, 字节流通过网络传输或写入永久存储. 反过来将字节流转换回一系列结构化对象的过程被称为反序列化.
序列化用于两个截然不同的分布式数据处理领域: 进程间通信和持久存储.
在 Hadoop 中, 系统中节点之间的进程间通信通过远程调用(RPC)实现. RPC 协议使用序列化将消息转换为二进制流并发送到远端节点, 然后远端节点对其进行反序列化还原为原始消息. 通常来说, RPC 序列化格式应该达成下面的目标:
Compact 紧凑的格式可以充分利用稀缺的网络带宽资源.
Fast 进程间通信形成分布式系统的主干, 所以序列化和反序列化过程中的开销应该尽可能少.
Extensible 协议会不断变化以满足新的需求, 所以它应该以可控的方式为客户端和服务器轻松的演进协议. 例如, 可以为方法添加一个新参数, 同时新服务器也可以兼容旧格式的消息.
Interoperable 对于某些系统, 希望能够支持客户端与服务器用不同的语言实现, 所以需要设计格式来满足这一点.
表面上看, 序列化框架对数据格式的要求与持久化对数据格式的要求会有所不同. 毕竟, RPC 的生命周期不超过一秒, 而数据可能写入数年后才会被读取. 从这些差异可以看出, RPC 序列化格式的四个理想属性对于持久化存储格式同样重要. 我们希望存储格式紧凑 (以提高存储空间使用效率), 速度快(因此读取或写入 TB 级数据的开销最小), 可扩展 (所以我们可以透明地读取以旧格式写入的数据), 和 可交互 (所以我们可以使用不同的语言读取或写入数据).
Hadoop 使用自己的序列化格式 Writables, 紧凑而且速度快, 但并不容易被 Java 以外的语言扩展或使用. 因为 Writables 是 Hadoop 的核心(大多数 MapReduce 程序都将其作为 key 和 value 的类型), 我们会在接下来的三节中深入研究它们, 然后再看一些 Hadoop 支持的其他序列化框架. 比如 12 章的Avro(这是为了解决 Writables的 一些限制而设计的序列化系统).
Writable 接口定义了两个方法 : 一个用于将其状态写入 DataOutput 二进制流, 另一个从 DataInput 二进制流中读取其状态:
package org.apache.hadoop.io;
import java.io.DataOutput;
import java.io.DataInput;
import java.io.IOException;
public interface Writable {
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}让我们来看看一个特定的 Writable, 看看我们可以用它做些什么. 我们将使用 IntWritable, 一个Java int的包装器. 我们可以创建一个并使用 set() 方法来设置它的值:
IntWritable writable = new IntWritable();
writable.set(163);等价地, 我们可以使用带有整数值的构造函数:
IntWritable writable = new IntWritable(163);为了检查 IntWritable 序列化后的格式, 我们写了一个 helper 方法将 java.io.ByteArrayOutputStream 封装在 java.io.DataOutputStream (java.io.DataOutput 的一个实现) 来捕获序列化流中的字节:
public static byte[] serialize(Writable writable) throws IOException {
ByteArrayOutputStream out = new ByteArrayOutputStream();
DataOutputStream dataOut = new DataOutputStream(out);
writable.write(dataOut);
dataOut.close();
return out.toByteArray();
}写入一个整数, 占用四个字节:
byte[] bytes = serialize(writable);
assertThat(bytes.length, is(4));字节以 big-endian 顺序写入, 我们可以通过调用 Hadoop StringUtils 中的方法来查看其 16 进制表示:
assertThat(StringUtils.byteToHexString(bytes), is("000000a3"));让我们尝试反序列化. 同样, 我们创建一个 helper 方法从字节数组中读取一个 Writable 对象:
public static byte[] deserialize(Writable writable, byte[] bytes)
throws IOException {
ByteArrayInputStream in = new ByteArrayInputStream(bytes);
DataInputStream dataIn = new DataInputStream(in);
writable.readFields(dataIn);
dataIn.close();
return bytes;
}我们构造一个新的没有值的 IntWritable, 然后调用 deserialize() 读取我们刚才写入的输出数据. 然后我们使用 get() 方法检查读取到的值, 是原始值 163:
IntWritable newWritable = new IntWritable();
deserialize(newWritable, bytes);
assertThat(newWritable.get(), is(163));- WritableComparable and comparators
IntWritable 实现了 WritableComparable 接口, WritableComparable 是 Writable 和 java.lang.Comparable 接口的子接口
package org.apache.hadoop.io;
public interface WritableComparable<T> extends Writable, Comparable<T> {
}类型比较对于 MapReduce 来说至关重要, 因为 MapReduce 中有一个排序阶段会对键进行比较. Hadoop 提供的一项优化是继承了 Java 比较器的 RawComparator 接口:
package org.apache.hadoop.io;
import java.util.Comparator;
public interface RawComparator<T> extends Comparator<T> {
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
}这个接口允许实现类在反序列化为对象之前比较流中的记录, 从而避免了创建对象的开销. 例如, IntWritable 的比较器是这样实现 raw compare() 方法的, 从两个字节数组 b1 和 b2 中分别读取一个整数并直接从给定的开始位置 (s1 和 s2) 和长度 (l1 和 l2)进行比较.
WritableComparator 是 WritableComparable 类对 RawComparator 接口的通用实现. 它提供了两个主要函数. 首先, 它提供了 raw compare() 方法的默认实现, 将流中的数据反序列化为对象并调用对象的 compare() 方法. 其次, 它充当一个 RawComparator 实例工厂(Writable 实现已注册). 例如, 要获得 IntWritable 的比较器, 我们只需使用:
RawComparator<IntWritable> comparator = WritableComparator.get(IntWritable.class);comparator 可用于比较两个 IntWritable 对象:
IntWritable w1 = new IntWritable(163);
IntWritable w2 = new IntWritable(67);
assertThat(comparator.compare(w1, w2), greaterThan(0));或比较他们的序列化表示:
byte[] b1 = serialize(w1);
byte[] b2 = serialize(w2);
assertThat(comparator.compare(b1, 0, b1.length, b2, 0, b2.length), greaterThan(0));- Writable wrappers for Java primitives
除 char 之外(可以存储在 IntWritable 中), 所有 Java 基本类型都有 Writable wrappers (请参阅表 5-7). 所有类都有 get() 和 set() 方法用来获取和存储包装值.
Table 5-7. Writable wrapper classes for Java primitives
| Java primitive | Writable implementation | Serialized size (bytes) | | ------| ------ | ------ | ------ | | boolean | BooleanWritable | 1 | | byte | ByteWritable | 1 | | short | ShortWritable | 2 | | int | IntWritable | 4 | | | VIntWritable | 1-5 | | float | FloatWritable | 4 | | long | LongWritable | 8 | | | VLongWritable | 1-9 | | double | DoubleWritable | 8 |
谈到整数的编码, 可以选择固定长度格式 (IntWritable 和 LongWritable) 或可变长度格式 (VIntWritable 和 VLongWritable). 可变长度格式在值足够小时 (介于 -112 和 127 之间), 只使用一个字节来对该值进行编码; 否则, 他们用第一个字节表示该值是正值还是负值, 以及后面有多少字节. 例如, 163 需要两个字节来表示:
byte[] data = serialize(new VIntWritable(163));
assertThat(StringUtils.byteToHexString(data), is("8fa3"));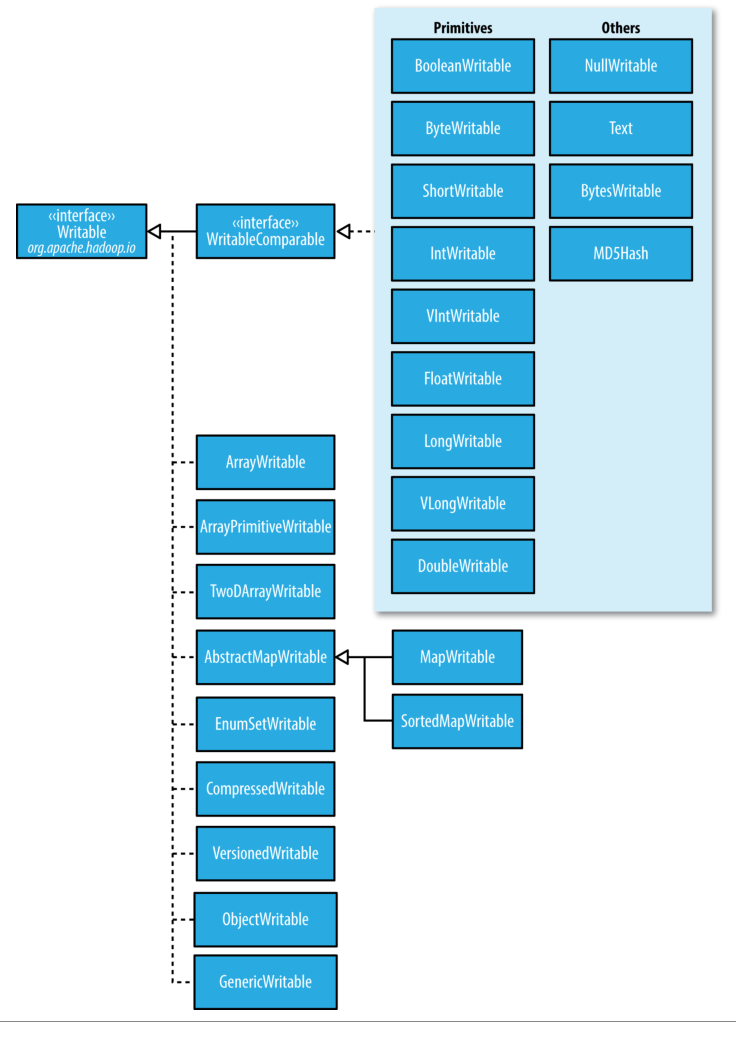
Figure 5-1. Writable class hierarchy
如何选择固定长度编码和可变长度编码? 当值在整个值空间均匀分布时, 固定长度编码是很好的, 例如散列函数的输出值. 大多数数字变量趋于不均匀的分布, 并且平均而言, 可变长度编码将节省空间. 可变长度编码的另一个优点是你可以从 VIntWritable 切换到 VLongWritable, 因为它们的编码实际上是一样的. 所以, 通过选择一个可变长度的表示, 可以为以后的扩展提供空间.
- Text
文本是可写入的 UTF-8 序列. 它可以被认为是能够 Writable 的 java.lang.String.
Text 类使用 int(可变长度编码) 来存储字符串编码中的字节数, 因此最大值为2 GB. 此外, Text 使用标准的 UTF-8, 这使得与其他支持 UTF-8 的工具进行交互更加容易.
代码点(Code Point): Unicode 所做的事情就是将我们需要表示的字符表中的每个字符映射成一个数字, 这个数字被称为相应字符的码点(code point). 例如 "严" 字在 Unicode 中对应的码点是 U+0x4E25.
代码单元(Code Unit): 是指一个已编码的文本中具有最短的比特组合的单元. 对于 UTF-8 来说, 代码单元是 8 比特长; 对于 UTF-16 来说, 代码单元是 16 比特长. 换一种说法就是 UTF-8 的是以一个字节为最小单位的, UTF-16 是以两个字节为最小单位的.
Indexing. 由于强调使用标准的 UTF-8 编码, 因此 Text 和 Java String 类有一些区别. Text 类在索引时是查找字符在编码后的字节序列中的位置, 而不是字符串中的 Unicode 字符或 Java char 中的代码单元(与 String 相同). 对于 ASCII 字符串, 这三个索引位置的概念是重合的. 下面是一个演示 charAt() 方法使用的例子:
Text t = new Text("hadoop");
assertThat(t.getLength(), is(6));
assertThat(t.getBytes().length, is(6));
assertThat(t.charAt(2), is((int) 'd'));
assertThat("Out of bounds", t.charAt(100), is(-1));请注意, charAt() 返回一个表示 Unicode 代码点的 int, 而不像 String 变量一样返回 char. Text 也有一个 find() 方法, 类似于 String 的 indexOf().
Text t = new Text("hadoop");
assertThat("Find a substring", t.find("do"), is(2));
assertThat("Finds first 'o'", t.find("o"), is(3));
assertThat("Finds 'o' from position 4 or later", t.find("o", 4), is(4));
assertThat("No match", t.find("pig"), is(-1));Unicode. 当我们使用编码大于一个字节的字符时, Text 和 String 之间的区别就变得清晰了. 考虑表 5-8 中显示的 Unicode 字符.
Table 5-8. Unicode characters
| Unicode code point | U+0041 | U+00DF | U+6771 | U+10400 |
|---|---|---|---|---|
| Name | LATIN CAPITAL LETTER A | LATIN SMALL LETTER SHARP S | N/A (a unified Han ideograph) | DESERET CAPITAL LETTER LONG I |
| UTF-8 code units | 41 | c3 9f | e6 9d b1 | f0 90 90 80 |
| Java representation | \u0041 | \u00DF | \u6771 | \uD801\uDC00 |
表中的除了字符 U+10400 外都可以用一个 Java char 表示. U+10400 是一个补充字符, 由两个 Java char 代码单元表示, 称为 surrogate pair. 例 5-5 中的测试显示了在处理表 5-8 中包含四个字符的字符串时, String 和 Text 的差异.
Example 5-5. Tests showing the differences between the String and Text classes
public class StringTextComparisonTest {
@Test
public void string() throws UnsupportedEncodingException {
String s = "\u0041\u00DF\u6771\uD801\uDC00";
assertThat(s.length(), is(5));
assertThat(s.getBytes("UTF-8").length, is(10));
assertThat(s.indexOf("\u0041"), is(0));
assertThat(s.indexOf("\u00DF"), is(1));
assertThat(s.indexOf("\u6771"), is(2));
assertThat(s.indexOf("\uD801\uDC00"), is(3));
assertThat(s.charAt(0), is('\u0041'));
assertThat(s.charAt(1), is('\u00DF'));
assertThat(s.charAt(2), is('\u6771'));
assertThat(s.charAt(3), is('\uD801'));
assertThat(s.charAt(4), is('\uDC00'));
assertThat(s.codePointAt(0), is(0x0041));
assertThat(s.codePointAt(1), is(0x00DF));
assertThat(s.codePointAt(2), is(0x6771));
assertThat(s.codePointAt(3), is(0x10400));
}
@Test
public void text() {
Text t = new Text("\u0041\u00DF\u6771\uD801\uDC00");
assertThat(t.getLength(), is(10));
assertThat(t.find("\u0041"), is(0));
assertThat(t.find("\u00DF"), is(1));
assertThat(t.find("\u6771"), is(3));
assertThat(t.find("\uD801\uDC00"), is(6));
assertThat(t.charAt(0), is(0x0041));
assertThat(t.charAt(1), is(0x00DF));
assertThat(t.charAt(3), is(0x6771));
assertThat(t.charAt(6), is(0x10400));
}
}测试确认了字符串的长度是它包含的代码单元的数量 (五个, 由字符串中前三个字符和最后一个替代对组成), 而 Text 对象的长度是 UTF-8 编码后的字节数 (10 = 1 + 2 + 3 + 4). 同样, String 类的 indexOf() 方法以 char 代码单元为单位返回一个索引, Text 的 find() 方法返回的是则是字节偏移量.
注:Java 标准库实现中, 对 char 与 String 的序列化规定使用 UTF-8 作为外码. Java 的 Class 文件中的字符串常量与符号名字也都规定用 UTF-8 编码. 这大概是当时设计者为了平衡运行时的时间效率(采用定长编码的 UTF-16)与外部存储的空间效率(采用变长的 UTF-8 编码)而做的取舍.
不考虑 String 中存在 surrogate pair(两个代码单元表示一个字符) 时, String 中的 charAt() 方法返回给定索引的 char 代码单元. codePointAt() 方法用 char 代码单元来检索, 返回用 int 表示的单个 Unicode 字符. 事实上, Text 中的 charAt() 方法更像是 codePointAt() 方法, 而不是 String 中的同名方法. 唯一的区别是前者是按字节偏移索引的.
注:Java 的 char 类型不一定能表示一个 UTF-16 的 "字符", 只有只需 1 个 code unit 的 code point 才可以完整的存在 char 里. 但 String 作为 char 的序列, 可以包含由两个 code unit 组成的 "surrogate pair" 来表示需要 2 个 code unit 表示的 UTF-16 code point.
Iteration. 因为 Text 使用字节偏移进行索引, 所以在 Text 中遍历 Unicode 字符会比较复杂, 你不能只是简单的增加索引(字符对应的代码单元不是定长的). 迭代实现方式是(参见例 5-6): 将 Text 对象转换为 java.nio.ByteBuffer, 然后重复调用静态方法 byteToCodePoint(). 此方法将下一个代码点提取为 int, 并更新缓冲区中指针的位置. 当 bytesToCodePoint() 返回 -1 时, 意味着遍历已经结束.
Example 5-6. Iterating over the characters in a Text object
public class TextIterator {
public static void main(String[] args) {
Text t = new Text("\u0041\u00DF\u6771\uD801\uDC00");
ByteBuffer buf = ByteBuffer.wrap(t.getBytes(), 0, t.getLength());
int cp;
while (buf.hasRemaining() && (cp = Text.bytesToCodePoint(buf)) != -1) {
System.out.println(Integer.toHexString(cp));
}
}
}可变性. 与 Strin g的另一个区别是 Text 是可变的(Hadoop 中所有 Writable 的实现都是这样, 除了 NullWritable, 它是一个单例). 您可以通过调用 set() 方法来重用 Text 实例. 例如:
Text t = new Text("hadoop");
t.set("pig");
assertThat(t.getLength(), is(3));
assertThat(t.getBytes().length, is(3));诉诸字符串. Text 没有像 java.lang.String 那样丰富的用于处理字符串的 API, 所以在许多情况下, 您需要将 Text 对象转换为 String. 以常规方式使用 toString() 方法完成此操作:
assertThat(new Text("hadoop").toString(), is("hadoop"));- BytesWritable
BytesWritable 是一个二进制数组的包装. 它的序列化格式包括一个 4 字节的整数字段, 用来指定跟随的字节数, 随后是字节本身. 例如, 长度为 2 且值为 3 和 5 的字节数组被序列化为 4 字节整数(00000002), 然后是数组(03 和 05)中的两个字节:
BytesWritable b = new BytesWritable(new byte[] { 3, 5 });
byte[] bytes = serialize(b);
assertThat(StringUtils.byteToHexString(bytes), is("000000020305"));BytesWritable 是可变的, 它的值可以通过调用 set() 方法来改变. 与 Text 一样, getBytes() 方法返回的字节数组大小反映的可能不是 BytesWritable 中存储数据的实际大小. 您可以通过调用 getLength() 来获取 BytesWritable 的实际大小. 示例如下:
b.setCapacity(11);
assertThat(b.getLength(), is(2));
assertThat(b.getBytes().length, is(11));- NullWritable
NullWritable 是一种特殊类型的 Writable, 因为它序列化后长度为零. 没有字节被写入流或从流中读取. 它通常被用作占位符; 例如, 在 MapReduce 中, 当您不需要使用该位置时, 可以将键或值声明为 NullWritable, 从而有效地存储常量空值. 当你想存储一个值列表时, NullWritable 也可以用作 SequenceFile 中的一个键, 而不是用很多个键值对. 它是一个不可变的单例, 可以通过调用 NullWritable.get() 来获取实例.
- ObjectWritable and GenericWritable
ObjectWritable 是以下类的通用包装器: Java 原生类型, String, 枚举, Writable, null 或这些类型构成的数组. 它在 Hadoop RPC 中用于编组和解组方法参数和返回类型.
ObjectWritable 在字段可能是多种类型时非常有用. 例如, 如果 SequenceFile 中的值具有多个类型, 则可以将值类型声明为 ObjectWritable, 并将每个类型包裹在 ObjectWritable 中. 作为一个通用机制, 它浪费了大量的空间, 因为它每次被序列化时都会写入被包装类型的类名. 在要支持的类型较少并且事先已知的情况下, 可以通过静态数组保存类型, 在序列化引用数组中的类型. 这就是 GenericWritable 所采用的方法, 您必须对其进行继承以指定要支持的类型.
- Writable collections
org.apache.hadoop.io 包包含六种 Writable 集合类型: ArrayWritable, ArrayPrimitiveWritable, TwoDArrayWritable, MapWritable, SortedMapWritable 和 EnumSetWritable.
ArrayWritable 和 TwoDArrayWritable 是数组和二维数组 (阵列数组) 的 Writable 实现. ArrayWritable 或 TwoDArrayWritable 中的所有元素必须是同一个类的实例, 在构造中指定的实例如下:
ArrayWritable writable = new ArrayWritable(Text.class);In contexts where the Writable is defined by type, such as in SequenceFile keys or values or as input to MapReduce in general, you need to subclass ArrayWritable (or TwoDArrayWritable , as appropriate) to set the type statically. For example:
在 Writable 的上下文中, 如 SequenceFile 键或值, 以及 MapReduce 的输入, 需要继承 ArrayWritable(或 TwoDArrayWritable) 来静态设置类型. 例如:
public class TextArrayWritable extends ArrayWritable {
public TextArrayWritable() {
super(Text.class);
}
}ArrayWritable 和 TwoDArrayWritable 都有 get() 和 set() 方法, 还有一个 toArray() 方法, 该方法创建数组(或二维数组) 的浅拷贝副本.
ArrayPrimitiveWritable 是 Java 原生类型数组的封装器. 调用 set() 方法时会检测组件类型, 因此不需要通过子类来指定类型.
MapWritable 是 java.util.Map <Writable, Writable> 的实现, SortedMapWritable 是 java.util.SortedMap <WritableComparable, Writable> 的实现. 每个键和值字段的类型是该字段序列化格式的一部分. 该类型被存储为一个单字节, 充当一个类型数组的索引. 该数组在 org.apache.hadoop.io 包中使用标准类型进行填充, 但通过编写用于为非标准类型编码类型数组的头部, 也可以加入自定义的 Writable 类型. 在实现它们时, MapWritable 和 SortedMapWritable 对自定义类型使用正字节值, 因此在任何特定的 MapWritable 或 SortedMapWritable 实例中最多可以使用 127 个不同的非标准 Writable 类. 下面是使用 MapWritable 时设置键和值为不同类型的演示:
MapWritable src = new MapWritable();
src.put(new IntWritable(1), new Text("cat"));
src.put(new VIntWritable(2), new LongWritable(163));
MapWritable dest = new MapWritable();
WritableUtils.cloneInto(dest, src);
assertThat((Text) dest.get(new IntWritable(1)), is(new Text("cat")));
assertThat((LongWritable) dest.get(new VIntWritable(2)), is(new LongWritable(163)));很明显类似 sets 和 lists 的 Writable 集合实现是缺位的. 通用 set 可以通过将 MapWritable (或 SortedMapWritable 作为有序 set) 的值设置为 NullWritable 来模拟. 还有 EnumSetWritable 用于枚举类型的 sets. 对于单一 Writable 类型的 lists, ArrayWritable 已经足够, 但要将不同类型的 Writable 存储在单个 list 中, 可以使用 GenericWritable 将元素包装在 ArrayWritable 中. 或者, 您可以借鉴 MapWritable 的想法编写一个通用的 ListWritable.
Hadoop 附带一组有用的 Writable 实现, 可满足大部分需求; 但是, 有时候, 您可能需要编写自己的自定义实现. 使用自定义 Writable, 您可以完全控制二进制表示和排序. 由于 Writable 是 MapReduce 数据路径的核心, 因此调整二进制表示可能会对性能产生重大影响. Hadoop 附带的 Writable 实现已经很好地调整, 但对于更复杂的结构, 创建新的 Writable 类型通常比组合已有类型更好.
为了演示如何创建自定义的 Writable, 我们将编写一个字符串对的实现, 称为 TextPair. 基本实现如例 5-7 所示.
Example 5-7. A Writable implementation that stores a pair of Text objects
import java.io.*;
import org.apache.hadoop.io.*;
public class TextPair implements WritableComparable<TextPair> {
private Text first;
private Text second;
public TextPair() {
set(new Text(), new Text());
}
public TextPair(String first, String second) {
set(new Text(first), new Text(second));
}
public TextPair(Text first, Text second) {
set(first, second);
}
public void set(Text first, Text second) {
this.first = first;
this.second = second;
}
public Text getFirst() {
return first;
}
public Text getSecond() {
return second;
}
@Override
public void write(DataOutput out) throws IOException {
first.write(out);
second.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
first.readFields(in);
second.readFields(in);
}
@Override
public int hashCode() {
return first.hashCode() * 163 + second.hashCode();
}
@Override
public boolean equals(Object o) {
if (o instanceof TextPair) {
TextPair tp = (TextPair) o;
return first.equals(tp.first) && second.equals(tp.second);
}
return false;
}
@Override
public String toString() {
return first + "\t" + second;
}
@Override
public int compareTo(TextPair tp) {
int cmp = first.compareTo(tp.first);
if (cmp != 0) {
return cmp;
}
return second.compareTo(tp.second);
}
}实现的第一部分很简单: 有两个 Text 实例变量, 第一个和第二个, 以及相关的构造函数, getter 和 setter. 所有 Writable 实现都必须有默认构造函数, 以便MapReduce 框架可以实例化它们, 然后调用 readFields() 方法来填充它们的字段. Writable 实例是可变的并且经常重用, 所以您应该避免在 write() 或 readFields() 方法中分配对象.
TextPair 的 write() 方法通过委托给 Text 对象将每个 Text 对象依次序列化为输出流. 同样, readFields() 通过委托给每个 Text 对象来反序列化输入流中的字节. DataOutput 和 DataInput 接口拥有一组用于序列化和反序列化 Java 原生类型的方法, 因此, 通常, 您可以完全控制您的 Writable 对象的传输格式.
就像使用 Java 编写的任何值对象一样, 您应该覆盖java.lang.Object中的 hashCode(), equals() 和 toString() 方法. HashPartitioner(MapReduce 中的默认分区程器) 使用 hashCode() 方法来选择 reduce 分区, 所以您应该确保您编写的散列函数混合良好, 从而确保 reduce 分区具有相似的大小.
TextPair 是 WritableComparable 的一个实现, 因此它提供了一个 compareTo() 方法的实现, 该方法实现您期望的排序: 它先按第一个字符串排序, 然后是第二个字符. 请注意, 除了可以存储的 Text 对象的数量之外, TextPair 与 TextArrayWritable 是不同的, 因为 TextArrayWritable 只是可写的, 而不是可写同时可比较的.
- Implementing a RawComparator for speed
示例 5-7 中TextPair的代码将按预期工作; 然而, 我们可以进一步优化. 如第 112 页的 "WritableComparable 和 Comparators" 中描述的, 当 TextPair 被用作 MapReduce 中的键时, 必须将其反序列化为一个对象, 以便调用 compareTo() 方法. 如果仅仅通过查看它们的序列化表示就可以比较两个 TextPair 对象呢?
事实证明这样做是可行的的, 因为 TextPair 是两个 Text 对象的连接, 而 Text 对象的二进制表示是一个可变长度的整数, 里面包含字符串的 UTF-8 表示占用的字节数, 随后是 UTF-8 字节本身. 诀窍是读取初始长度, 以便知道第一个 Text 对象的字节表示有多长; 然后我们可以委托给 Text 的 RawComparator , 并用第一个或第二个字符串在数据中的偏移量作为参数. 示例 5-8 给出了详细实现 (请注意该代码嵌套在 TextPair 类中).
Example 5-8. A RawComparator for comparing TextPair byte representations
public static class Comparator extends WritableComparator {
private static final Text.Comparator TEXT_COMPARATOR = new Text.Comparator();
public Comparator() {
super(TextPair.class);
}
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
int firstL1 = WritableUtils.decodeVIntSize(b1[s1]) + readVInt(b1, s1);
int firstL2 = WritableUtils.decodeVIntSize(b2[s2]) + readVInt(b2, s2);
int cmp = TEXT_COMPARATOR.compare(b1, s1, firstL1, b2, s2, firstL2);
if (cmp != 0) {
return cmp;
}
return TEXT_COMPARATOR.compare(b1, s1 + firstL1, l1 - firstL1, b2, s2 + firstL2, l2 - firstL2);
} catch (IOException e) {
throw new IllegalArgumentException(e);
}
}
}
static{
WritableComparator.define(TextPair.class,new Comparator());
}实际上, 我们继承了 WritableComparator 类, 而不是直接实现 RawComparator, 因为它已经提供了一些便利方法和默认实现. 该代码的细微部分是计算 firstL1 和 firstL2, 即每个字节流中第一个 Text 字段的长度. 每个 Text 字段的长度由可变长度整数 (由 WritableUtils 类的 decodeVIntSize() 方法返回) 和它编码的值 (由 readVInt() 返回) 的长度组成.
静态代码块注册 raw comparator, 以便 MapReduce 一旦发现 TextPair 类, 它都知道使用 raw comparator 作为其默认比较器.
- Custom comparators
正如您在 TextPair 中看到的那样, 编写 raw comparator 时需要小心, 因为您必须在字节级别进行处理. 如果您一定要编写自己的实现, 那么请参考org.apache.hadoop.io 包中的一些 Writable 实现. 另外 WritableUtils 上的实用方法也非常有价值.
如果可能的话, 自定义比较器也应该写成 RawComparator. 这些比较器的排序结果与默认的比较器不同. 例 5-9 显示了一个名为 FirstComparator 的 TextPair 比较器, 它仅考虑对 TextPair 中的第一个字符串进行排序. 请注意, 我们重载了对象的 compare() 方法, 因此两个 compare() 方法具有相同的语义.
当我们学习 MapReduce 中的 joins 和二级排序时, 我们将在第 9 章中使用这个比较器(请参阅第 267 页的 "联接").
Example 5-9. A custom RawComparator for comparing the first field of TextPair byte representations
public static class FirstComparator extends WritableComparator {
private static final Text.Comparator TEXT_COMPARATOR = new Text.Comparator();
public FirstComparator() {
super(TextPair.class);
}
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
try {
int firstL1 = WritableUtils.decodeVIntSize(b1[s1]) + readVInt(b1, s1);
int firstL2 = WritableUtils.decodeVIntSize(b2[s2]) + readVInt(b2, s2);
return TEXT_COMPARATOR.compare(b1, s1, firstL1, b2, s2, firstL2);
} catch (IOException e) {
throw new IllegalArgumentException(e);
}
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
if (a instanceof TextPair && b instanceof TextPair) {
return ((TextPair) a).first.compareTo(((TextPair) b).first);
}
return super.compare(a, b);
}
}尽管大多数 MapReduce 程序使用 Writable 类作为键和值类型, 但这并不是 MapReduce API 的强制要求. 事实上, 可以使用任何类型; 唯一的要求是每种类型都可以转换为二进制表示, 也可以从二进制表示中还原.
为了支持这一点, Hadoop 为可插入序列化框架提供了一个 API. 序列化框架是 Serialization 接口的实现(在 org.apache.hadoop.io.serializer 包中) 表示. 例如, WritableSerialization 用于序列化 Writable 类型.
序列化定义了从类型到 Serializer 实例 (用于将对象转换为字节流) 和 Deserializer 实例 (用于将字节流转换为对象) 的映射.
将 io.serializations 属性设置为逗号分隔的类名列表, 以注册序列化实现. 其默认值包括 org.apache.hadoop.io.serializer.WritableSerialization, Avro Specific 和 Reflect 序列化 (请参阅第346页上的 "Avro 数据类型和模式"), 这意味着只有 Writable 或 Avro 对象可以被序列化或反序列化.
Hadoop includes a class called JavaSerialization that uses Java Object Serialization. Although it makes it convenient to be able to use standard Java types such as Integer or String in MapReduce programs, Java Object Serialization is not as efficient as Writ‐ ables, so it’s not worth making this trade-off (see the following sidebar).
Hadoop 包含一个名为 JavaSerialization 的类, 该类使用 Java Object Serialization. 尽管它可以方便地在MapReduce程序中使用标准Java类型 (如Integer或String) , 但Java对象序列化并不像Writables那样高效, 所以不值得进行这种折衷 (参见下面的边栏) .
- Serialization IDL
There are a number of other serialization frameworks that approach the problem in a different way: rather than defining types through code, you define them in a language- neutral, declarative fashion, using an interface description language (IDL). The system can then generate types for different languages, which is good for interoperability. They also typically define versioning schemes that make type evolution straightforward.
还有一些其他序列化框架以不同的方式解决问题: 不是通过代码定义类型, 而是使用接口描述语言 (IDL) 以语言无关的声明方式定义它们. 然后系统可以为不同的语言生成类型, 这对互操作性是有利的. 他们通常也会定义版本控制方案, 使类型的演变变得简单明了.
Apache Thrift and Google Protocol Buffers are both popular serialization frameworks, and both are commonly used as a format for persistent binary data. There is limited support for these as MapReduce formats; 3 however, they are used internally in parts of Hadoop for RPC and data exchange.
Apache Thrift和Google协议缓冲区都是流行的序列化框架, 并且通常用作持久二进制数据的格式. 这些作为MapReduce格式的支持有限; 3然而, 它们在Hadoop的部分内部用于RPC和数据交换.
Avro is an IDL-based serialization framework designed to work well with large-scale data processing in Hadoop. It is covered in Chapter 12.
Avro是一个基于IDL的序列化框架, 旨在与Hadoop中的大规模数据处理很好地协作. 它在第12章中有介绍.
For some applications, you need a specialized data structure to hold your data. For doing MapReduce-based processing, putting each blob of binary data into its own file doesn’t scale, so Hadoop developed a number of higher-level containers for these situations.
对于某些应用程序, 您需要一个专门的数据结构来保存您的数据. 为了执行基于MapReduce的处理, 将每个二进制数据块放入其自己的文件不会扩展, 所以Hadoop为这些情况开发了许多更高级别的容器.
Imagine a logfile where each log record is a new line of text. If you want to log binary types, plain text isn’t a suitable format. Hadoop’s SequenceFile class fits the bill in this situation, providing a persistent data structure for binary key-value pairs. To use it as a logfile format, you would choose a key, such as timestamp represented by a LongWritable , and the value would be a Writable that represents the quantity being logged.
设想一个日志文件, 其中每个日志记录都是一行新文本. 如果您想记录二进制类型, 纯文本不是合适的格式. 在这种情况下, Hadoop的SequenceFile类适合账单, 为二元键值对提供持久的数据结构. 要将其用作日志文件格式, 您需要选择一个键, 例如由LongWritable表示的时间戳, 并且该值将是一个表示记录数量的Writable.
SequenceFile s also work well as containers for smaller files. HDFS and MapReduce are optimized for large files, so packing files into a SequenceFile makes storing and processing the smaller files more efficient (“Processing a whole file as a record” on page 228 contains a program to pack files into a SequenceFile ).
SequenceFile也适用于较小文件的容器. HDFS和MapReduce针对大文件进行了优化, 因此将文件打包到SequenceFile中可使存储和处理小文件的效率更高 (第228页上的“将整个文件作为记录处理”包含将文件打包到SequenceFile中的程序) .
- Writing a SequenceFile
To create a SequenceFile , use one of its createWriter() static methods, which return a SequenceFile.Writer instance. There are several overloaded versions, but they all require you to specify a stream to write to (either an FSDataOutputStream or a FileSystem and Path pairing), a Configuration object, and the key and value types. Optional arguments include the compression type and codec, a Progressable callback to be informed of write progress, and a Metadata instance to be stored in the Sequen ceFile header.
要创建SequenceFile, 请使用其一个 createWriter() 静态方法, 该方法返回一个SequenceFile.Writer实例. 有几个重载版本, 但它们都要求您指定要写入的流(FSDataOutputStream 或文件系统和路径配对), 配置对象以及键和值类型. 可选参数包括压缩类型和编解码器, 要通知写入进度的 Progressable 回调以及要存储在SequenceFile 标头中的 Metadata 实例.
The keys and values stored in a SequenceFile do not necessarily need to be Writables. Any types that can be serialized and deserialized by a Serialization may be used.
存储在SequenceFile中的键和值不一定需要是可写的. 可以使用任何可以通过序列化进行序列化和反序列化的类型.
Once you have a SequenceFile.Writer , you then write key-value pairs using the append() method. When you’ve finished, you call the close() method ( Sequence File.Writer implements java.io.Closeable ).
一旦你有了一个SequenceFile.Writer, 你就可以使用append () 方法编写键值对. 完成后, 调用close () 方法 (Sequence File.Writer实现java.io.Closeable) .
Example 5-10 shows a short program to write some key-value pairs to a Sequence File using the API just described. 例 5-10 显示了一个简短的程序, 用于使用刚刚描述的 API 将一些键值对写入序列文件.
Example 5-10. Writing a SequenceFile
public class SequenceFileWriteDemo {
private static final String[] DATA = { "One, two, buckle my shoe", "Three, four, shut the door",
"Five, six, pick up sticks", "Seven, eight, lay them straight", "Nine, ten, a big fat hen" };
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
SequenceFile.Writer writer = null;
try {
writer = SequenceFile.createWriter(fs, conf, path, key.getClass(), value.getClass());
for (int i = 0; i < 100; i++) {
key.set(100 - i);
value.set(DATA[i % DATA.length]);
System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);
writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}
}
}The keys in the sequence file are integers counting down from 100 to 1, represented as IntWritable objects. The values are Text objects. Before each record is appended to the SequenceFile.Writer , we call the getLength() method to discover the current position in the file. (We will use this information about record boundaries in the next section, when we read the file nonsequentially.) We write the position out to the console, along with the key and value pairs. The result of running it is shown here:
序列文件中的键是从100到1的整数, 表示为IntWritable对象. 这些值是Text对象. 在将每条记录追加到SequenceFile.Writer之前, 我们调用getLength () 方法来发现文件中的当前位置. (当我们以非连续的方式读取文件时, 我们将在下一节中使用关于记录边界的信息.) 我们将位置与键和值对一起写入控制台. 运行它的结果如下所示:
% hadoop SequenceFileWriteDemo numbers.seq
[128] 100 One, two, buckle my shoe
[173] 99 Three, four, shut the door
[220] 98 Five, six, pick up sticks
[264] 97 Seven, eight, lay them straight
[314] 96 Nine, ten, a big fat hen
[359] 95 One, two, buckle my shoe
[404] 94 Three, four, shut the door
[451] 93 Five, six, pick up sticks
[495] 92 Seven, eight, lay them straight
[545] 91 Nine, ten, a big fat hen
...
[1976] 60 One, two, buckle my shoe
[2021] 59 Three, four, shut the door
[2088] 58 Five, six, pick up sticks
[2132] 57 Seven, eight, lay them straight
[2182] 56 Nine, ten, a big fat hen
...
[4557] 5 One, two, buckle my shoe
[4602] 4 Three, four, shut the door
[4649] 3 Five, six, pick up sticks
[4693] 2 Seven, eight, lay them straight
[4743] 1 Nine, ten, a big fat hen- Reading a SequenceFile
Reading sequence files from beginning to end is a matter of creating an instance of SequenceFile.Reader and iterating over records by repeatedly invoking one of the next() methods. Which one you use depends on the serialization framework you are using. If you are using Writable types, you can use the next() method that takes a key and a value argument and reads the next key and value in the stream into these variables:
从头到尾读序列文件是创建 SequenceFile.Reader 实例并通过重复调用 next() 方法迭代记录的问题. 你使用哪一个取决于你正在使用的序列化框架. 如果您使用的是Writable 类型, 则可以使用带有 key 和 value 参数的 next() 方法, 并将流中的下一个键和值读入这些变量中:
public boolean next(Writable key, Writable val)The return value is true if a key-value pair was read and false if the end of the file has been reached.
如果已经读取了键值对, 返回值为true, 如果文件已到达, 则返回false.
For other, non-Writable serialization frameworks (such as Apache Thrift), you should use these two methods:
对于其他非可写序列化框架 (如Apache Thrift) , 您应该使用以下两种方法:
public Object next(Object key) throws IOException
public Object getCurrentValue(Object val) throws IOExceptionIn this case, you need to make sure that the serialization you want to use has been set in the io.serializations property; see “Serialization Frameworks” on page 126.
在这种情况下, 您需要确保您要使用的序列化已经在io.serializations属性中设置; 请参阅第126页上的“序列化框架”.
If the next() method returns a non- null object, a key-value pair was read from the stream, and the value can be retrieved using the getCurrentValue() method. Other‐ wise, if next() returns null , the end of the file has been reached.
如果next () 方法返回一个非空对象, 则从流中读取一个键值对, 并且可以使用getCurrentValue () 方法检索该值. 否则, 如果next () 返回null, 则已达到文件的结尾.
The program in Example 5-11 demonstrates how to read a sequence file that has Writable keys and values. Note how the types are discovered from the Sequence File.Reader via calls to getKeyClass() and getValueClass() , and then Reflectio nUtils is used to create an instance for the key and an instance for the value. This technique allows the program to be used with any sequence file that has Writable keys and values.
例5-11中的程序演示了如何读取具有Writable键和值的序列文件. 请注意, 如何通过调用getKeyClass () 和getValueClass () 从SequenceFile.Reader中发现类型, 然后使用ReflectionUtils为该键创建实例并为该值创建实例. 该技术允许程序与任何具有可写键和值的序列文件一起使用.
Example 5-11. Reading a SequenceFile
public class SequenceFileReadDemo {
public static void main(String[] args) throws IOException {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(fs, path, conf);
Writable key = (Writable) ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value = (Writable) ReflectionUtils.newInstance(reader.getValueClass(), conf);
long position = reader.getPosition();
while (reader.next(key, value)) {
String syncSeen = reader.syncSeen() ? "*" : "";
System.out.printf("[%s%s]\t%s\t%s\n", position, syncSeen, key, value);
position = reader.getPosition(); // beginning of next record
}
} finally {
IOUtils.closeStream(reader);
}
}
}Another feature of the program is that it displays the positions of the sync points in the sequence file. A sync point is a point in the stream that can be used to resynchronize with a record boundary if the reader is “lost”—for example, after seeking to an arbitrary position in the stream. Sync points are recorded by SequenceFile.Writer , which in‐ serts a special entry to mark the sync point every few records as a sequence file is being written. Such entries are small enough to incur only a modest storage overhead—less than 1%. Sync points always align with record boundaries.
该程序的另一个功能是显示序列文件中同步点的位置. 同步点是流中的一个点, 如果阅读器“丢失”, 例如在查找流中的任意位置之后, 该点可用于与记录边界重新同步. 同步点由SequenceFile.Writer记录, 该序列插入一个特殊条目, 以便在序列文件正在写入时为每个记录标记同步点. 这些条目足够小, 只会产生适度的存储开销 - 小于1%. 同步点始终与记录边界对齐.
Running the program in Example 5-11 shows the sync points in the sequence file as asterisks. The first one occurs at position 2021 (the second one occurs at position 4075, but is not shown in the output):
运行示例5-11中的程序将序列文件中的同步点显示为星号. 第一个发生在位置2021 (第二个发生在位置4075, 但未在输出中显示) :
% hadoop SequenceFileReadDemo numbers.seq
[128] 100 One, two, buckle my shoe
[173] 99 Three, four, shut the door
[220] 98 Five, six, pick up sticks
[264] 97 Seven, eight, lay them straight
[314] 96 Nine, ten, a big fat hen
[359] 95 One, two, buckle my shoe
[404] 94 Three, four, shut the door
[451] 93 Five, six, pick up sticks
[495] 92 Seven, eight, lay them straight
[545] 91 Nine, ten, a big fat hen
[590] 90 One, two, buckle my shoe
...
[1976] 60 One, two, buckle my shoe
[2021*] 59 Three, four, shut the door
[2088] 58 Five, six, pick up sticks
[2132] 57 Seven, eight, lay them straight
[2182] 56 Nine, ten, a big fat hen
...
[4557] 5 One, two, buckle my shoe
[4602] 4 Three, four, shut the door
[4649] 3 Five, six, pick up sticks
[4693] 2 Seven, eight, lay them straight
[4743] 1 Nine, ten, a big fat henThere are two ways to seek to a given position in a sequence file. The first is the seek() method, which positions the reader at the given point in the file. For example, seeking to a record boundary works as expected:
有两种方法可以查找序列文件中的给定位置. 第一种是seek () 方法, 它将读者定位在文件中的给定位置. 例如, 寻求创纪录的边界如预期的那样工作:
reader.seek(359);
assertThat(reader.next(key, value), is(true));
assertThat(((IntWritable) key).get(), is(95));But if the position in the file is not at a record boundary, the reader fails when the next() method is called:
但是, 如果文件中的位置不在记录边界上, 则在调用next () 方法时读取器将失败:
reader.seek(360);
reader.next(key, value); // fails with IOExceptionThe second way to find a record boundary makes use of sync points. The sync(long position) method on SequenceFile.Reader positions the reader at the next sync point after position . (If there are no sync points in the file after this position, then the reader will be positioned at the end of the file.) Thus, we can call sync() with any position in the stream—not necessarily a record boundary—and the reader will reestablish itself at the next sync point so reading can continue:
找到记录边界的第二种方法是使用同步点. SequenceFile.Reader上的同步 (长位置) 方法将阅读器置于位置之后的下一个同步点. (如果在该位置之后文件中没有同步点, 则阅读器将位于文件的末尾) .因此, 我们可以在流中的任何位置调用sync () (不一定是记录边界) , 并且 读者将在下一个同步点重新建立自己的阅读状态, 以便继续阅读:
reader.sync(360);
assertThat(reader.getPosition(), is(2021L));
assertThat(reader.next(key, value), is(true));
assertThat(((IntWritable) key).get(), is(59));SequenceFile.Writer has a method called sync() for inserting a sync point at the current position in the stream. This is not to be confused with the hsync() method defined by the Syncable inter‐ face for synchronizing buffers to the underlying device.
SequenceFile.Writer有一个名为sync () 的方法, 用于在流中当前位置插入一个同步点. 这不要与Syncable接口定义的hsync () 方法混淆, 以便将缓冲区同步到基础设备.
Sync points come into their own when using sequence files as input to MapReduce, since they permit the files to be split and different portions to be processed independ‐ ently by separate map tasks (see “SequenceFileInputFormat” on page 236).
当使用序列文件作为MapReduce的输入时, 同步点会自动生成, 因为它们允许将文件拆分并通过单独的映射任务独立处理不同的部分(请参见第 212 页的"SequenceFileInputFormat")
- Displaying a SequenceFile with the command-line interface
The hadoop fs command has a -text option to display sequence files in textual form. It looks at a file’s magic number so that it can attempt to detect the type of the file and appropriately convert it to text. It can recognize gzipped files, sequence files, and Avro datafiles; otherwise, it assumes the input is plain text.
hadoop fs命令有一个-text选项以文本形式显示序列文件. 它会查看文件的幻数, 以便它可以尝试检测文件的类型并将其适当地转换为文本. 它可以识别gzip文件, 序列文件和Avro数据文件; 否则, 它假定输入是纯文本.
For sequence files, this command is really useful only if the keys and values have mean‐ ingful string representations (as defined by the toString() method). Also, if you have your own key or value classes, you will need to make sure they are on Hadoop’s classpath.
对于序列文件, 仅当键和值具有有意义的字符串表示形式 (由toString () 方法定义) 时, 此命令才非常有用. 另外, 如果您有自己的键或值类, 则需要确保它们位于Hadoop的类路径中.
Running it on the sequence file we created in the previous section gives the following output:
在我们在前一节创建的序列文件上运行它会得到以下输出结果:
% hadoop fs -text numbers.seq | head
100 One, two, buckle my shoe
99 Three, four, shut the door
98 Five, six, pick up sticks
97 Seven, eight, lay them straight
96 Nine, ten, a big fat hen
95 One, two, buckle my shoe
94 Three, four, shut the door
93 Five, six, pick up sticks
92 Seven, eight, lay them straight
91 Nine, ten, a big fat hen- Sorting and merging SequenceFiles
The most powerful way of sorting (and merging) one or more sequence files is to use MapReduce. MapReduce is inherently parallel and will let you specify the number of reducers to use, which determines the number of output partitions. For example, by specifying one reducer, you get a single output file. We can use the sort example that comes with Hadoop by specifying that the input and output are sequence files and by setting the key and value types:
排序 (和合并) 一个或多个序列文件的最有效方式是使用MapReduce. MapReduce本质上是并行的, 可让您指定要使用的还原器的数量, 这决定了输出分区的数量. 例如, 通过指定一个reducer, 可以得到一个输出文件. 通过指定输入和输出是序列文件并通过设置键和值类型, 我们可以使用Hadoop附带的排序示例:
% hadoop jar \
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar \
sort -r 1 \
-inFormat org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat \
-outFormat org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat \
-outKey org.apache.hadoop.io.IntWritable \
-outValue org.apache.hadoop.io.Text \
numbers.seq sorted
% hadoop fs -text sorted/part-r-00000 | head
1 Nine, ten, a big fat hen
2 Seven, eight, lay them straight
3 Five, six, pick up sticks
4 Three, four, shut the door
5 One, two, buckle my shoe
6 Nine, ten, a big fat hen
7 Seven, eight, lay them straight
8 Five, six, pick up sticks
9 Three, four, shut the door
10 One, two, buckle my shoeAn alternative to using MapReduce for sort/merge is the SequenceFile.Sorter class, which has a number of sort() and merge() methods. These functions predate Map‐ Reduce and are lower-level functions than MapReduce (for example, to get parallelism, you need to partition your data manually), so in general MapReduce is the preferred approach to sort and merge sequence files.
使用MapReduce进行排序/合并的另一种方法是SequenceFile.Sorter类, 它有许多sort () 和merge () 方法. 这些函数在MapReduce之前, 是比MapReduce更低级别的函数 (例如, 为了获得并行性, 您需要手动划分数据) , 所以通常MapReduce是排序和合并序列文件的首选方法.
- The SequenceFile format
A sequence file consists of a header followed by one or more records (see Figure 5-2). The first three bytes of a sequence file are the bytes SEQ , which act as a magic number; these are followed by a single byte representing the version number. The header contains other fields, including the names of the key and value classes, compression details, user- defined metadata, and the sync marker. 5 Recall that the sync marker is used to allow a reader to synchronize to a record boundary from any position in the file. Each file has a randomly generated sync marker, whose value is stored in the header. Sync markers appear between records in the sequence file. They are designed to incur less than a 1% storage overhead, so they don’t necessarily appear between every pair of records (such is the case for short records).
一个序列文件由一个头部和一个或多个记录组成 (见图5-2) .序列文件的前三个字节是字节SEQ, 后者充当幻数;后面是一个单字节, 代表 版本号. 标题包含其他字段, 包括键和值类的名称, 压缩细节, 用户定义的元数据和同步标记. 5回想一下, 同步标记用于允许读者从文件中的任何位置同步到记录边界. 每个文件都有一个随机生成的同步标记, 其值存储在标题中. 同步标记出现在序列文件中的记录之间. 它们被设计为产生少于1%的存储开销, 所以它们不一定出现在每对记录之间 (对于短记录而言是这种情况) .
Figure 5-2. The internal structure of a sequence file with no compression and with record compression
The internal format of the records depends on whether compression is enabled, and if it is, whether it is record compression or block compression.
记录的内部格式取决于是否启用压缩, 如果是, 是记录压缩还是块压缩.
If no compression is enabled (the default), each record is made up of the record length (in bytes), the key length, the key, and then the value. The length fields are written as 4- byte integers adhering to the contract of the writeInt() method of java.io.DataOut put . Keys and values are serialized using the Serialization defined for the class being written to the sequence file.
如果未启用压缩 (默认) , 则每条记录都由记录长度 (以字节为单位) , 密钥长度, 密钥以及值组成. 长度字段被写为遵守java.io.DataOut put的writeInt () 方法的合约的4字节整数. 键和值使用为正在写入序列文件的类定义的序列化进行序列化.
The format for record compression is almost identical to that for no compression, except the value bytes are compressed using the codec defined in the header. Note that keys are not compressed.
记录压缩的格式与没有压缩的格式几乎相同, 只是值字节使用标头中定义的编解码器进行压缩. 请注意, 密钥未被压缩.
Block compression (Figure 5-3) compresses multiple records at once; it is therefore more compact than and should generally be preferred over record compression because it has the opportunity to take advantage of similarities between records. Records are added to a block until it reaches a minimum size in bytes, defined by the io.seqfile.compress.blocksize property; the default is one million bytes. A sync marker is written before the start of every block. The format of a block is a field indicating the number of records in the block, followed by four compressed fields: the key lengths, the keys, the value lengths, and the values.
数据块压缩(图 5-3)一次压缩多个记录; 因此它比记录压缩更紧凑, 通常应该优选, 因为它有机会利用记录之间的相似性. 记录被添加到一个块, 直到它达到由io.seqfile.compress.blocksize属性定义的最小字节大小; 默认值是一百万字节. 在每个块的开始之前写入同步标记. 块的格式是一个字段, 指示块中的记录数, 后跟四个压缩字段: 密钥长度, 密钥, 值长度和值.
Figure 5-3. The internal structure of a sequence file with block compression
A MapFile is a sorted SequenceFile with an index to permit lookups by key. The index is itself a SequenceFile that contains a fraction of the keys in the map (every 128th key, by default). The idea is that the index can be loaded into memory to provide fast lookups from the main data file, which is another SequenceFile containing all the map entries in sorted key order.
MapFile是一个有序索引的排序SequenceFile, 允许按键查找. 该索引本身就是一个SequenceFile, 它包含映射中的一小部分键 (默认情况下每128个键) . 这个想法是索引可以被加载到内存中以提供主数据文件的快速查找, 这是另一个SequenceFile, 它包含按排序键顺序排列的所有映射条目.
MapFile offers a very similar interface to SequenceFile for reading and writing—the main thing to be aware of is that when writing using MapFile.Writer , map entries must be added in order, otherwise an IOException will be thrown.
MapFile为SequenceFile提供了一个非常类似的接口来读写, 主要的一点是, 在使用MapFile.Writer编写时, 必须按顺序添加map条目, 否则会抛出IOException异常.
- MapFile variants
Hadoop comes with a few variants on the general key-value MapFile interface:
Hadoop在常规键值MapFile界面上提供了几个变体:
• SetFile is a specialization of MapFile for storing a set of Writable keys. The keys must be added in sorted order. SetFile是MapFile专用于存储一组Writable键. 密钥必须按排序顺序添加.
• ArrayFile is a MapFile where the key is an integer representing the index of the element in the array and the value is a Writable value. ArrayFile是一个MapFile, 其中的键是一个整数, 表示数组中元素的索引, 并且该值是一个Writable值.
• BloomMapFile is a MapFile that offers a fast version of the get() method, especially for sparsely populated files. The implementation uses a dynamic Bloom filter for testing whether a given key is in the map. The test is very fast because it is in- memory, and it has a nonzero probability of false positives. Only if the test passes (the key is present) is the regular get() method called.
BloomMapFile 是一个 MapFile, 它提供 get() 方法的快速版本, 特别是对于稀疏填充的文件. 该实现使用动态布隆过滤器来测试给定密钥是否在地图中. 测试非常快, 因为它在内存中, 并且具有非零概率的误报. 只有测试通过 (键存在) 才是调用的常规 get() 方法.
While sequence files and map files are the oldest binary file formats in Hadoop, they are not the only ones, and in fact there are better alternatives that should be considered for new projects.
虽然序列文件和映射文件是Hadoop中最早的二进制文件格式, 但它们并不是唯一的, 实际上, 有更好的替代方案应该在新项目中考虑.
Avro datafiles (covered in “Avro Datafiles” on page 352) are like sequence files in that they are designed for large-scale data processing—they are compact and splittable—but they are portable across different programming languages. Objects stored in Avro datafiles are described by a schema, rather than in the Java code of the implementation of a Writable object (as is the case for sequence files), making them very Java-centric. Avro datafiles are widely supported across components in the Hadoop ecosystem, so they are a good default choice for a binary format.
Avro数据文件 (在第352页的“Avro数据文件”中介绍) 与序列文件类似, 它们专为大规模数据处理而设计 - 它们是紧凑和可拆分的, 但它们可跨不同的编程语言移植. 存储在Avro数据文件中的对象由架构来描述, 而不是在可执行对象的Java代码中 (如序列文件的情况) , 这使得它们非常以Java为中心. Avro数据文件广泛支持Hadoop生态系统中的各个组件, 因此它们是二进制格式的一个很好的默认选择.
Sequence files, map files, and Avro datafiles are all row-oriented file formats, which means that the values for each row are stored contiguously in the file. In a column- oriented format, the rows in a file (or, equivalently, a table in Hive) are broken up into row splits, then each split is stored in column-oriented fashion: the values for each row in the first column are stored first, followed by the values for each row in the second column, and so on. This is shown diagrammatically in Figure 5-4.
序列文件, 映射文件和Avro数据文件都是面向行的文件格式, 这意味着每行的值都连续存储在文件中. 在面向列的格式中, 文件中的行 (或者相当于Hive中的表格) 被分解成行分割, 然后每个分割以列式方式存储: 第一列中每行的值是 先存储, 然后是第二列中每行的值, 依此类推. 这在图5-4中示意性地示出.
A column-oriented layout permits columns that are not accessed in a query to be skip‐ ped. Consider a query of the table in Figure 5-4 that processes only column 2. With row-oriented storage, like a sequence file, the whole row (stored in a sequence file re‐ cord) is loaded into memory, even though only the second column is actually read. Lazy deserialization saves some processing cycles by deserializing only the column fields that are accessed, but it can’t avoid the cost of reading each row’s bytes from disk.
面向列的布局允许在查询中不访问的列被跳过. 考虑图5-4中表格的查询, 该表格只处理第2列.对于面向行的存储, 就像序列文件一样, 整行 (存储在序列文件记录中) 被加载到内存中, 即使只有 第二列实际上是读取. 延迟反序列化通过反序列化只访问被访问的列字段来节省一些处理周期, 但它无法避免从磁盘读取每行字节的成本.
With column-oriented storage, only the column 2 parts of the file (highlighted in the figure) need to be read into memory. In general, column-oriented formats work well when queries access only a small number of columns in the table. Conversely, row- oriented formats are appropriate when a large number of columns of a single row are needed for processing at the same time.
使用面向列的存储时, 只需将文件的第2列部分 (图中突出显示) 读入内存. 通常, 当查询只访问表中的少量列时, 面向列的格式就可以很好地工作. 相反, 当需要同时处理大量单行的列时, 面向行的格式是合适的.
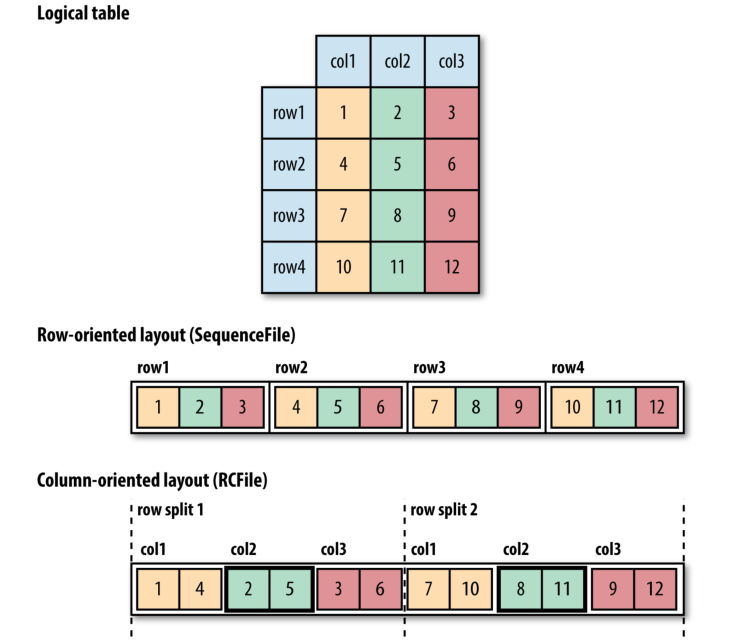
Figure 5-4. Row-oriented versus column-oriented storage
Column-oriented formats need more memory for reading and writing, since they have to buffer a row split in memory, rather than just a single row. Also, it’s not usually possible to control when writes occur (via flush or sync operations), so column-oriented formats are not suited to streaming writes, as the current file cannot be recovered if the writer process fails. On the other hand, row-oriented formats like sequence files and Avro datafiles can be read up to the last sync point after a writer failure. It is for this reason that Flume (see Chapter 14) uses row-oriented formats.
面向列的格式在读取和写入时需要更多的内存, 因为它们必须在内存中缓冲行分割, 而不仅仅是单行. 此外, 通常不可能控制何时发生写操作 (通过刷新或同步操作) , 因此面向列的格式不适合流写入, 因为如果写入器进程失败, 当前文件无法恢复. 另一方面, 序列文件和Avro数据文件等面向行的格式可以在写入器故障后读取到最后一个同步点. 正是由于这个原因, Flume (见第14章) 使用了面向行的格式.
The first column-oriented file format in Hadoop was Hive’s RCFile, short for Record Columnar File. It has since been superseded by Hive’s ORCFile (Optimized Record Col‐ umnar File), and Parquet (covered in Chapter 13). Parquet is a general-purpose column- oriented file format based on Google’s Dremel, and has wide support across Hadoop components. Avro also has a column-oriented format called Trevni.
Hadoop中第一个面向列的文件格式是Hive的RCFile, 即Record Columnar File的缩写. 它已被Hive的ORCFile (优化记录组文件) 和Parquet (第13章介绍) 取代. Parquet是基于Google Dremel的通用列式文件格式, 并且在Hadoop组件中得到广泛的支持. Avro还有一个名为Trevni的列式格式.
In Chapter 2, we introduced the MapReduce model. In this chapter, we look at the practical aspects of developing a MapReduce application in Hadoop.
在第2章中, 我们介绍了MapReduce模型. 在本章中, 我们将探讨在Hadoop中开发MapReduce应用程序的实际方面.
Writing a program in MapReduce follows a certain pattern. You start by writing your map and reduce functions, ideally with unit tests to make sure they do what you expect. Then you write a driver program to run a job, which can run from your IDE using a small subset of the data to check that it is working. If it fails, you can use your IDE’s debugger to find the source of the problem. With this information, you can expand your unit tests to cover this case and improve your mapper or reducer as appropriate to handle such input correctly.
在MapReduce中编写程序遵循一定的模式. 您首先编写地图并减少功能, 理想情况下使用单元测试来确保它们按照您的期望执行. 然后你编写一个驱动程序来运行一个作业, 该作业可以使用一小部分数据从IDE运行, 以检查它是否正常工作. 如果失败, 您可以使用IDE的调试器来查找问题的根源. 有了这些信息, 您可以扩展单元测试以涵盖这种情况, 并根据需要改进您的映射器或缩减器, 以正确处理此类输入.
When the program runs as expected against the small dataset, you are ready to unleash it on a cluster. Running against the full dataset is likely to expose some more issues, which you can fix as before, by expanding your tests and altering your mapper or reducer to handle the new cases. Debugging failing programs in the cluster is a challenge, so we’ll look at some common techniques to make it easier.
当程序按照预期针对小数据集运行时, 您已准备好将其释放到群集中. 针对完整数据集运行可能会暴露更多问题, 您可以像以前一样修复这些问题, 方法是扩展测试并更改映射器或缩减器以处理新案例. 在群集中调试失败的程序是一项挑战, 因此我们将看一些常用技术以使其更容易.
After the program is working, you may wish to do some tuning, first by running through some standard checks for making MapReduce programs faster and then by doing task profiling. Profiling distributed programs is not easy, but Hadoop has hooks to aid in the process.
程序运行后, 您可能希望进行一些调整, 首先通过执行一些标准检查来更快地创建MapReduce程序, 然后执行任务分析. 对分布式程序进行性能分析并不容易, 但Hadoop具有挂钩功能以帮助实现这一过程.
Before we start writing a MapReduce program, however, we need to set up and configure the development environment. And to do that, we need to learn a bit about how Hadoop does configuration.
然而, 在我们开始编写MapReduce程序之前, 我们需要设置和配置开发环境. 为此, 我们需要了解一些关于Hadoop如何配置的信息.
Components in Hadoop are configured using Hadoop’s own configuration API. An instance of the Configuration class (found in the org.apache.hadoop.conf package) represents a collection of configuration properties and their values. Each property is named by a String , and the type of a value may be one of several, including Java prim‐ itives such as boolean , int , long , and float ; other useful types such as String , Class , and java.io.File ; and collections of String s.
Hadoop中的组件使用Hadoop自己的配置API进行配置. 配置类的一个实例 (可在org.apache.hadoop.conf包中找到) 表示一组配置属性及其值. 每个属性都由一个字符串命名, 并且值的类型可以是几个之一, 包括Java基本类型, 如boolean, int, long和float; 其他有用的类型, 如String, Class和java.io.File; 和String的集合.
Configuration s read their properties from resources—XML files with a simple structure for defining name-value pairs. See Example 6-1.
配置从资源中读取它们的属性 - 具有用于定义名称 - 值对的简单结构的XML文件. 见例6-1.
Example 6-1. A simple configuration file, configuration-1.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>color</name>
<value>yellow</value>
<description>Color</description>
</property>
<property>
<name>size</name>
<value>10</value>
<description>Size</description>
</property>
<property>
<name>weight</name>
<value>heavy</value>
<final>true</final>
<description>Weight</description>
</property>
<property>
<name>size-weight</name>
<value>${size},${weight}</value>
<description>Size and weight</description>
</property>
</configuration>Assuming this Configuration is in a file called configuration-1.xml, we can access its properties using a piece of code like this:
假设这个Configuration在一个名为configuration-1.xml的文件中, 我们可以使用如下一段代码访问它的属性:
Configuration conf = new Configuration();
conf.addResource("configuration-1.xml");
assertThat(conf.get("color"), is("yellow"));
assertThat(conf.getInt("size", 0), is(10));
assertThat(conf.get("breadth", "wide"), is("wide"));There are a couple of things to note: type information is not stored in the XML file; instead, properties can be interpreted as a given type when they are read. Also, the get() methods allow you to specify a default value, which is used if the property is not defined in the XML file, as in the case of breadth here.
有几点需要注意: 类型信息不存储在 XML 文件中; 相反, 属性在读取时可以解释为给定的类型. 此外, get() 方法允许您指定一个默认值, 如果该属性未在 XML 文件中定义, 则使用该值, 如此处宽度的情况.
Things get interesting when more than one resource is used to define a Configura tion . This is used in Hadoop to separate out the default properties for the system, defined internally in a file called core-default.xml, from the site-specific overrides in core-site.xml. The file in Example 6-2 defines the size and weight properties.
当使用多个资源来定义配置时, 情况会变得很有趣. 这在Hadoop中用于从core-site.xml中的站点特定覆盖中分离出系统的默认属性, 这些属性在名为core-default.xml的文件内部定义. 例6-2中的文件定义了尺寸和重量属性.
Example 6-2. A second configuration file, configuration-2.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>size</name>
<value>12</value>
</property>
<property>
<name>weight</name>
<value>light</value>
</property>
</configurat>Resources are added to a Configuration in order: 资源按顺序添加到配置中:
Configuration conf = new Configuration();
conf.addResource("configuration-1.xml");
conf.addResource("configuration-2.xml");Properties defined in resources that are added later override the earlier definitions. So the size property takes its value from the second configuration file, configuration-2.xml:
在稍后添加的资源中定义的属性会覆盖较早的定义. 所以size属性取自第二个配置文件configuration-2.xml的值:
assertThat(conf.getInt("size", 0), is(12));However, properties that are marked as final cannot be overridden in later definitions. The weight property is final in the first configuration file, so the attempt to override it in the second fails, and it takes the value from the first:
但是, 标记为final的属性在以后的定义中不能被覆盖.weight属性在第一个配置文件中是final的, 因此在第二个配置文件中覆盖它的尝试失败, 它取自第一个值:
assertThat(conf.get("weight"), is("heavy"));Attempting to override final properties usually indicates a configuration error, so this results in a warning message being logged to aid diagnosis. Administrators mark prop‐ erties as final in the daemon’s site files that they don’t want users to change in their client-side configuration files or job submission parameters.
尝试覆盖最终属性通常会指示配置错误, 因此会导致记录警告消息以帮助诊断. 管理员在守护程序的站点文件中将属性标记为final, 并且不希望用户在其客户端配置文件或作业提交参数中进行更改.
Configuration properties can be defined in terms of other properties, or system prop‐ erties. For example, the property size-weight in the first configuration file is defined as ${size},${weight} , and these properties are expanded using the values found in the configuration:
配置属性可以用其他属性或系统属性来定义. 例如, 第一个配置文件中的属性大小权重定义为$ {size}, $ {weight}, 这些属性使用配置中找到的值进行扩展:
assertThat(conf.get("size-weight"), is("12,heavy"));System properties take priority over properties defined in resource files: 系统属性优先于资源文件中定义的属性:
System.setProperty("size", "14");
assertThat(conf.get("size-weight"), is("14,heavy"));This feature is useful for overriding properties on the command line by using -Dproperty=value JVM arguments. 通过使用-Dproperty = value JVM参数, 此功能对于重写命令行中的属性很有用.
Note that although configuration properties can be defined in terms of system proper‐ ties, unless system properties are redefined using configuration properties, they are not accessible through the configuration API. Hence:
请注意, 尽管可以根据系统属性定义配置属性, 但除非使用配置属性重新定义系统属性, 否则无法通过配置API访问它们.因此:
System.setProperty("length", "2");
assertThat(conf.get("length"), is((String) null));- Setting Up the Development Environment 省略