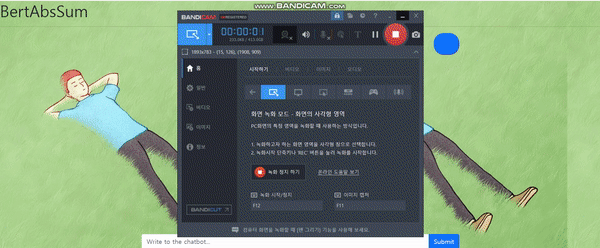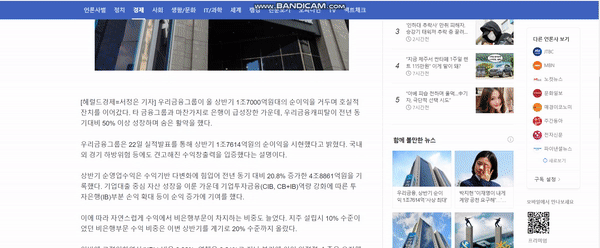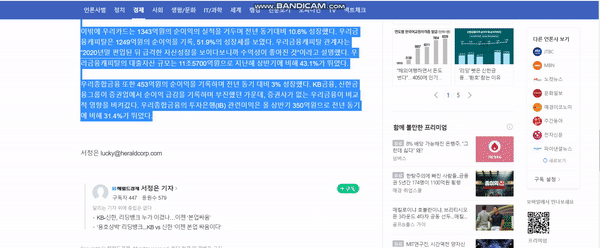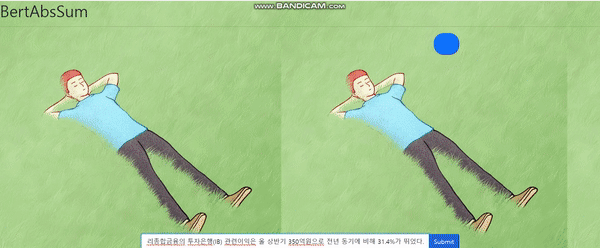
This code is for EMNLP 2019 paper Text Summarization with Pretrained Encoders
-
Using SKT KoBert
-
Kobertsum의 생성요약을 구현하여 소스코드 및 프로젝트를 오픈한 사례가 없어 참고하기에 어려움이 있었습니다.
-
처음으로 오픈소스를 수정하며 프로젝트를 진행하였고, 배운 점이 많았습니다.
- Dacon 대회에서 우수한 성적을 거둔 이야기연구소 주식회사의 raw data 전처리를 진행하는 코드를 가져와 사용하였고, 이를 검증해보았는데 문제점을 발견할 수 있었습니다. 이것을 통해 무작정 가져다 쓰는 것이 아닌 코드를 훑어보고, 이를 검증하는 것에 대한 중요성을 깨닫는 계기가 되었습니다.
- padding의 길이값을 정해놓는 것이 아닌 이야기연구소 주식회사의 방식처럼 문장에 맞춰 padding의 길이를 맞추는 방식을 사용했으면 학습시간의 단축에 도움이 되었을 것이라고 예상합니다.
- 컴퓨팅 자원이 부족해 10%의 데이터만을 이용해 프로젝트를 진행했습니다. 전체의 데이터 셋을 사용할 수 있었으면 더 좋은 결과가 나왔을 것 같아 아쉬움이 남습니다.
- train 및 test를 위한 lib, 해당 lib에 맞춰 data를 전처리하여 실행
- 위 과정에서 오류가 나는 부분만 수정
- project 구현을 위해 기존의 lib을 대폭 수정해야했기 때문에 프로젝트에 맞춰 수정했습니다.