Before understanding what Convolutional neural Network is all about , we should first understand how a human brain works. We have probably been through hundreds of situations in our life where we looked at something instantaneously, made it out to be something, and then after looking at it more thoroughly, we realize that it is actually something completely different. What happens there is that our brain detects the object for the first time, but because the look was brief, our brain does not get to process enough of the object's features so as to categorize it correctly. For example when we take optical illusion image such as:

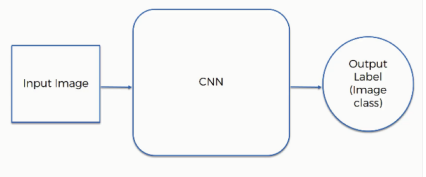
We can carefully see this image as two interpretations; either an old lady looking down or a young woman staring away. Such interpretation tells our brain to classify objects in an image based on the features that it detects first and so we see them depending on the line and the angle that our brain decides to begin its "feature detection" expedition from. Convolutional Neural Network (CNN) also behaves in the same way. It is a type of artificial neural network used in image recognition and processing that is specifically designed to process pixel data. It uses three elements for operation which are input, CNN and output label
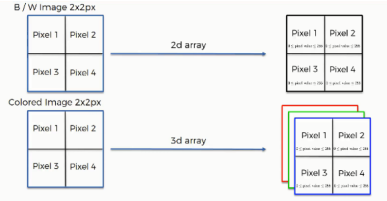
● Each pixel contains 8 bits (1 byte) of information.
● Colors are represented on a scale from 0 to 255. The reason for this is that bits are binary units, and since we have 8 of these per byte, a byte can have any of 256 (2^8) possible values. Since we count 0 as the first possible value, we can go up to 255.
● In this model, 0 is pitch black and 255 is pure white, and in between are the various (definitely more than 50!) shades of gray.
● The network does not actually learn colors. Since computers understand nothing but 1's and 0's, the colors' numerical values are represented to the network in binary terms.
Black & white images are two-dimensional, whereas colored images are three-dimensional. The difference this makes is in the value assigned to each pixel when presented to the neural network. In the case of two-dimensional black & white images, each pixel is assigned one number between 0 and 255 to represent its shade.
On the other hand, each pixel inside a colored image is represented on three levels. Since any color is a combination of red, green, and blue at different levels of concentration, a single pixel in a colored image is assigned a separate value for each of these layers.
That means that the red layer is represented with a number between 0 and 255, and so are the blue and the green layers. They are then presented in an RGB format. For example, a "hot pink" pixel would be presented to the neural network as (255, 105, 180).
- Convolution
- ReLU Layer
- Pooling
- Flattening
- Full connection
Convolution is a function derived from two given functions by integration which expresses how the shape of one is modified by the other
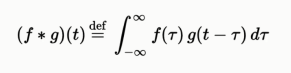
Let us take an example
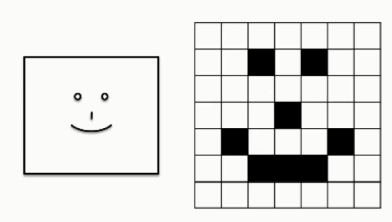
Here, the grid table on the far right shows all of the pixels valued at 0's while only the parts where the smiley face appears are valued at 1.
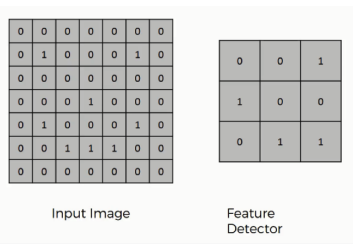
There are three elements in the convolution operation:
Input image Feature detector Feature map
How does the operation work?
● Place the feature detector over the input image beginning from the top-left corner within the borders, and then count the number of cells in which the feature detector matches the input image.
● The number of matching cells is then inserted in the top-left cell of the feature map.
● Then move the feature detector one cell to the right and do the same thing. This movement is called a and since we are moving the feature detector one cell at time, that would be called a stride of one pixel.
● From our example we can see that the feature detector's middle-left cell with the number 1 inside it matches the cell that it is standing over inside the input image. That's the only matching cell, and so you write "1" in the next cell in the feature map, and so on and so forth.
● After going through the whole first row, move it over to the next row and go through the same process.
The cells of the feature map can contain any digit, not only 1's and 0's. After going over every pixel in the input image in the example above, we would end up with these results:

So, what is the point from the convolution operation? There are several uses that we gain from deriving a feature map. These are the most important of them: Reducing the size of the input image, and we should know that the larger your strides (the movements across pixels), the smaller the feature map
The rectified linear activation function is a simple calculation that returns the value provided as input directly, or the value 0.0 if the input is 0.0 or less. We can describe this using a simple if-statement: if input > 0: return input else: return 0 We can describe this function g() mathematically using the max() function over the set of 0.0 and the input z; for example: g(z) = max{0, z} The function is linear for values greater than zero, meaning it has a lot of the desirable properties of a linear activation function when training a neural network using backpropagation. Yet, it is a nonlinear function as negative values are always output as zero.
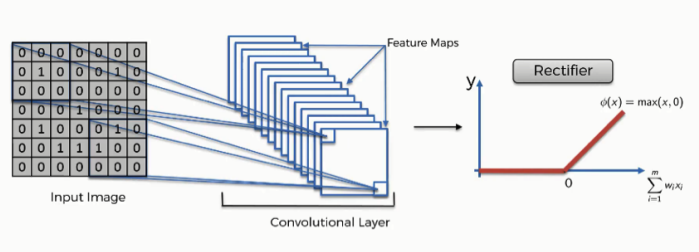
The purpose of applying the rectifier function is to increase the non-linearity in our images so that images are naturally non-linear. Generally when we look at the image, we can find a lot of non-linear features (e.g. the transition between pixels, the borders, the colors, etc.). The rectifier serves to break up the linearity even further in order to make up for the linearity that we might impose on an image when we put it through the convolution operation.
A pooling layer is a new layer added after the convolutional layer. Specifically, after a nonlinearity (e.g. ReLU) has been applied to the feature maps output by a convolutional layer. Types of pooling are
● Mean pooling
● Max pooling
● Sum pooling
For our project we have used Max pooling. Max pooling returns the maximum value from the portion of the image covered by the feature map.

The reason we extract the maximum value is to account for distortions. Let's say we have three cheetah images, and in each image the cheetah's tear lines are taking a different angle. The feature after it has been pooled will be detected by the network despite the differences in its appearance between the three images.
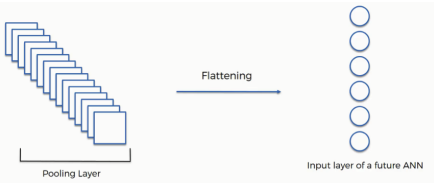
After getting a pooled featured map, the pooled featured map is flattened into a column.

The reason we do this is that we're going to need to insert this data into an artificial neural network later on
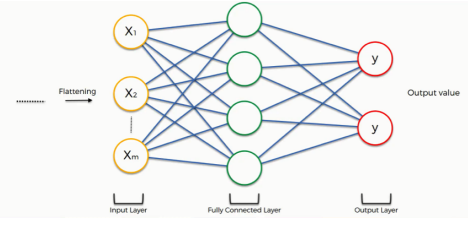
It is a layer in which all the inputs from one layer to every activation unit of the next layer. There are three layers in the full connection step:
● Input layer
● Fully-connected layer
● Output layer
So the aim of the step is to take data and combine the features into a wider variety of attributes .
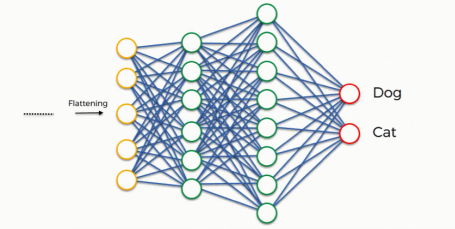
If for example, the network predicts the figure in the image to be a dog by a probability of 80%, yet the image actually turns out to be of a cat. An error has to be calculated in this case. In the context of artificial neural networks, this calculation is a "cost function" or a mean squared error, but as we deal with convolutional neural networks, it is more commonly referred to as a "loss function."
We use the cross-entropy function in order to achieve that. The Cross-entropy function is used to achieve the minimalized loss function. So the loss function informs us of how accurate our network is, which we then use in optimizing our network in order to increase its effectiveness. That requires certain things to be altered in our network which includes weights (the blue lines connecting the neurons, which are basically the synapses), and the feature detector since the network often turns out to be looking for the wrong features and has to be reviewed multiple times for the sake of optimization. As we work to optimize the network, the information keeps flowing back and forth over and over until the network reaches the desired state.
Let's first look at the "dog" class.
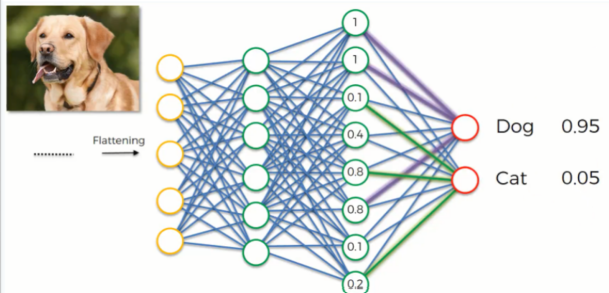
This full connection process practically works as follows: ● The neuron in the fully-connected layer detects a certain feature (lets say a nose).
● It preserves it value.
● It communicates this value to both the “dog” and the “cat” classes.
● Both classes checks out the feature and decides whether it’s relevant to them.
● The weight placed on the nose-dog synapse is high(1.0) which means that the network is confident that this is a dog’s nose.
This project proves to be a successful implementation of CONVOLUTIONAL NEURAL NETWORKS in order to predict the class of an image that’s been given as an input. This project shall aid the user to get a birds eye view of the neural connections as well as help technologies to build upon it. As a further improvement this can be integrated with various datasets in the future.
REFERENCES