speeding up the transform command #92
Description
Description
Transforming a set of haplotypes can take a while, especially if you have many haplotypes. A quick benchmark via the bench_transform.py script seems to indicate that it scales linearly with the number of samples, the max number of alleles in each haplotype, and the number of haplotypes.
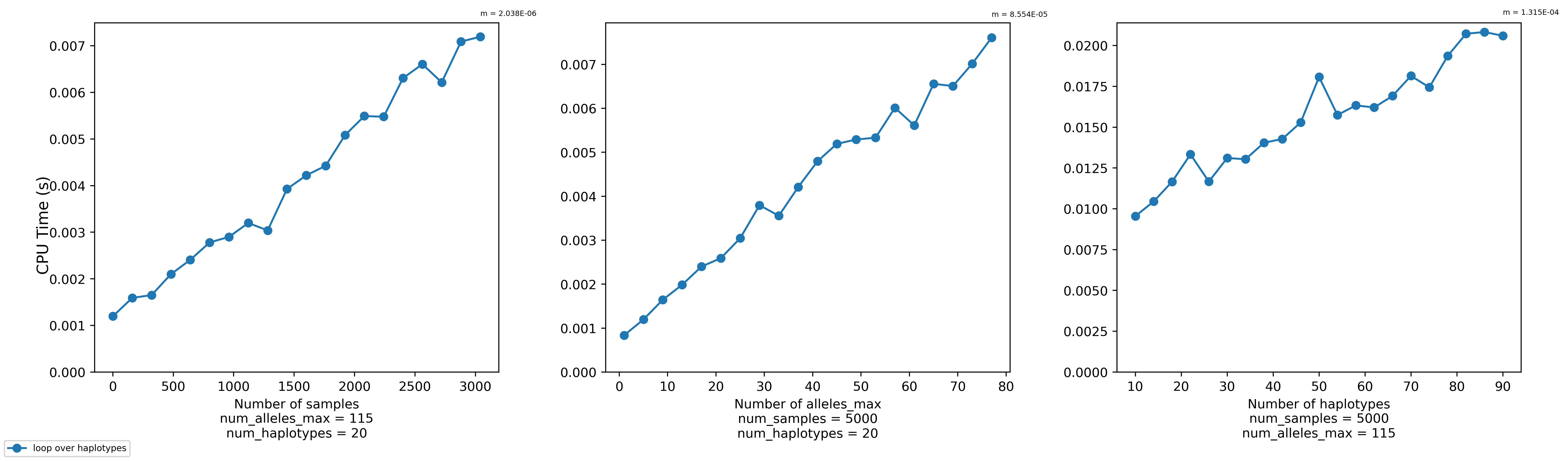
@s041629 wants to transform roughly 21,000 haplotypes for 500,000 samples where the max number of alleles in a haplotype is 115. Currently (as of f45742f), the Haplotypes.transform() function takes about 10-25 real minutes to accomplish this task. (It varies based on the willingness of the kernel to prioritize our job on the node.)
For now, I think this will be fast enough. But we might want to brainstorm some ideas for the future. In any case, I don't really think I can justify spending a lot more time to improve this right now (since I've already spent quite a bit), so I'm gonna take a break and solicit suggestions until I feel energized enough to tackle this again.
Details
The vast majority of the time seems to be spent in this for-loop.
haptools/haptools/data/haplotypes.py
Lines 1054 to 1055 in 639985e
Unfortunately, I can't use broadcasting to speed up this loop because the size of idxs[i] might vary on each iteration. And I can't pad the array to make broadcasting work because I quickly run out of memory for arrays of that shape. Ideally, I would like to find a solution that doesn't require multi-threading or the installation of new dependencies besides those we have already.
Steps to reproduce
A basic test
This test uses just 5 samples, 4 variants, and 3 haplotypes. It's a sanity check to make sure the Haplotypes.transform() function works and that none of the code will fail.
pytest -sx tests/test_data.py::TestHaplotypes::test_haps_transformA benchmarking test
To benchmark the function and see how it scales with the number of samples, max number of alleles in each haplotype, and the number of haplotypes in each allele, you can use the bench_transform.py script as so. It will create a plot like the one I've included above.
haptools/tests/bench_transform.py
Lines 19 to 21 in 639985e
A pure numpy-based test of the for-loop
The tests above require that you install the dev setup for haptools. If you'd like to reproduce just the problematic for-loop for @s041629's situation in pure numpy you can do something like this:
import numpy as np
num_samps, num_alleles, num_haps, max_alleles = 500000, 6200, 21000, 115
idxs = [np.random.randint(0, num_alleles, np.random.randint(0, max_alleles)) for j in range(num_haps)]
arr = np.random.choice([True, False], size=num_samps*num_alleles*2).reshape((num_samps, num_alleles, 2))
output = np.empty((num_samps, num_haps, 2), dtype=np.bool_)
for i in range(num_haps):
output[:, i] = np.all(arr[:, idxs[i]], axis=1)A full, long-running test
If requested, I can provide files that reproduce the entire setup so that you can execute the transform command with them. The files are a bit too large to attach here.
Some things I've already tried
- Adding a dimension to
arr(akaequality_arr) of size equal to the number of haplotypes and then performingnp.all()on the other dimension. This takes longer and requires too much more memory. See fac79b0. - Using numba to compile the for-loop to C. This took longer for some reason. Still not sure why. Also, I'm averse to installing new dependencies. See 5afcf81.
- Looping over the allele dimension instead of the haplotype dimension (since
num_alleles < num_haps, at least in this situation). This was a clever strategy from Ryan Eveloff. Strangely, this also took longer than looping over the haplotypes. I'm not sure why. See 335e5f7.
Potential ideas
- Try taking advantage of the fact that some of the haplotypes share alleles (ie some of the haplotypes are subsets of other haplotypes). So I could try to construct some sort of tree and then iterate through that via a dynamic programming approach, instead. In theory, this should reduce the time complexity by a log factor somewhere. A back-of-the-envelope analysis of the
.hapfile Matteo gave me indicates that there would be at least 1,000 leaves in such a tree. - Talk to Tara! She might have had a similar issue.