正则匹配功能的问题 #1
Description
现在的正则匹配功能是在抓取新链接时进行正则匹配从而过滤掉不符合要求的链接,但是这个逻辑似乎不太对,这可能会导致无法获取到期望的结果。
如需要爬取我博客下的所有文章,以首页为 seed,仅能爬取到首页存在的文章以及文章与文章之间有跳转才能到达的文章。而其他该 seed 下不可达但经过两次或者更多次跳转得到的文章就无法爬到。
例:
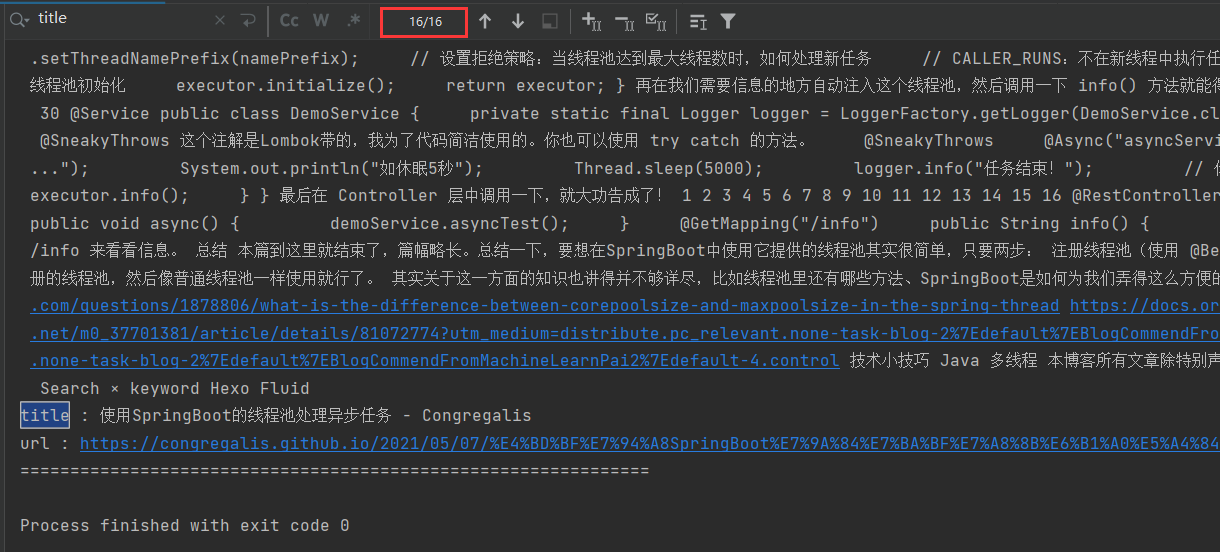
爬取结果为 16 条,实际我的博客目前有 20 篇文章。
爬取我博客下的文章代码:
// 种子url
String seed = "https://congregalis.github.io/";
// 匹配任何“年月日”形式的日期,连接符可以没有或是 . / - 之一
String dateRegex = "(?:(?!0000)[0-9]{4}([-/.]?)(?:(?:0?[1-9]|1[0-2])\\1(?:0?[1-9]|1[0-9]|2[0-8])|(?:0?[13-9]|1[0-2])\\1(?:29|30)|(?:0?[13578]|1[02])\\1(?:31))|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)([-/.]?)0?2\\2(?:29))";
Crawler.build().addSeed(seed).addRule("https://congregalis.github.io/" + dateRegex + "/.*/").run();