Aşağılayıcı söylemleri sınıflandırma görevi için literatürde çeşitli yaklaşımlar öneren birçok yayın bulunmaktadır. Bu problemi araştıran yazarlar yanlılık (bias) problemi üzerine yoğunlaşmış; bu durumun çözümü için farklı ön işleme ve yaklaşımlar uygulamışlardır. Aşağıda literatürdeki çalışmalar listelenmiştir.
- Aken B. V., Risch J. Krestel R. ve Löser A., (2018)
Other, Toxic, Obscene, Insult, Identity Hate, Severe ToxicveThreatsınıflarını tahmin etmek için yaptıkları çalışmada en iyi F1 skorunuBidirectional GRU Attention (FastText)modeli ile elde etmişlerdir. Ancak kullandıkları diğer modellerde de skorların benzer olduğu gözlemlenmiştir. - Duchêne C., Jamet H., Guillaume P. ve Dehak R., (2023)
Toxicity, Obscene, Sexual Explict, Identity Attack, InsultveThreatsınıflarının tahmini içinBERT, RNN, XLNETmimarilerini kullanan modeller ile denemeler yapmışlardır ve bütün bu modellerin benzer sonuçlar verdiğini vurgulamışlardır. Nihai olarak;Focall Lossile eğitilmişRoBERTamodeli AUROC ve F1 olarak en iyi sonucu veren model olmuştur. - Jhaveri M., Ramaiya D. ve Chadha H. S (2022)
AbusiveveNot Abusesınıflarını birden çok dil (multilingual) için tahmin ederkenBERTailesinden 18 farklı model kullanmışlardır.xlm-roberta-largeen iyi sonucu veren model olmuştur.
Yarışma süresince genellebilir bir model oluşturmak adına hem türkçe hem de diğer dillerden birçok açık veri kaynağını taradık. Kullandığımız veriler aşağıda listelenmiştir.
- Jigsaw Multilingual Toxic Comment Classification
- Jigsaw Unintended Bias in Toxicity Classification
- Toxic Comment Classification Challenge
- A corpus of Turkish offensive language
- Turkish Tweets Sentiment Analysis
- Türkçe Sosyal Medya Paylaşımı Veri Seti
Bu verilerin farklı kombinasyonlarını kullanarak ilk olarak pretraining amaçlı base modelimizi eğittik. Sonrasında birinci aşamadan gelen model ağırlıkları (weights) ile yarışma datasında fine-tune ettik. Bu yöntem ile modeldeki yanlılığı azalttık ve production ortamı için genellenebilir bir model oluşturduk.
Aşağıda tahminleme süreci boyunca denemiş olduğumuz embedding modeller ve final sınıflandırma katmanları listelenmiştir.
Aşama 1 olarak adlandırabileceğimiz bu kısım, bizlere iletilen df['text'] sütunundaki metinleri sayısal olarak N boyutunda bir vektörde temsil etmemizi sağlamaktadır. Böylece AŞama 2'de sınıflandırma görevi için modellere öznitelik (feature) sağlayabiliriz. Aşama 1'de oluşturulan vektörler probleme ne kadar uyumlu olursa, sınıflandırma aşaması sonuçlarının da o kadar iyileşmesi beklenmektedir. Bu nedenle farklı mimarileri (architecture) içeren geniş bir havuz oluşturmayı hedefledik ve aşağıdaki gibi listeledik.
3.1.1. TF-IDF - Referans
TF-IDF, bir belgedeki (corpus) her bir kelimenin değerlerini, belirli bir belgedeki kelimenin sıklığı ile kelimenin göründüğü belgelerin yüzdesinin tersiyle hesaplar. Temel olarak TF-IDF, belirli bir belgede kelimelerin göreceli sıklığını, bu kelimenin tüm veri seti üzerindeki tersine oranına göre belirleyerek çalışır. Sezgisel olarak, bu hesaplama, belirli bir kelimenin belirli bir belge ile ne kadar alakalı olduğunu belirler. Tek veya küçük bir belge grubunda ortak olan kelimeler genel kelimelerden daha yüksek TFIDF numaralarına sahip olma eğilimindedir.

TF-IDF için hem karakter bazlı hem de kelime bazlı yaklaşımlar denedik. Uygulama yöntemleri için: TfidfVectorizer
3.1.2. FastText - Referans
FastText 2016 yılında Facebook tarafından geliştirilen Word2Vec tabanlı bir modeldir. Bu yöntemin Word2Vec’ten farkı, kelimelerin ngramlara ayrılmasıdır. Böylece Word2Vec ile yakalanamayan anlam yakınlığı bu yöntemle yakalanabilir.
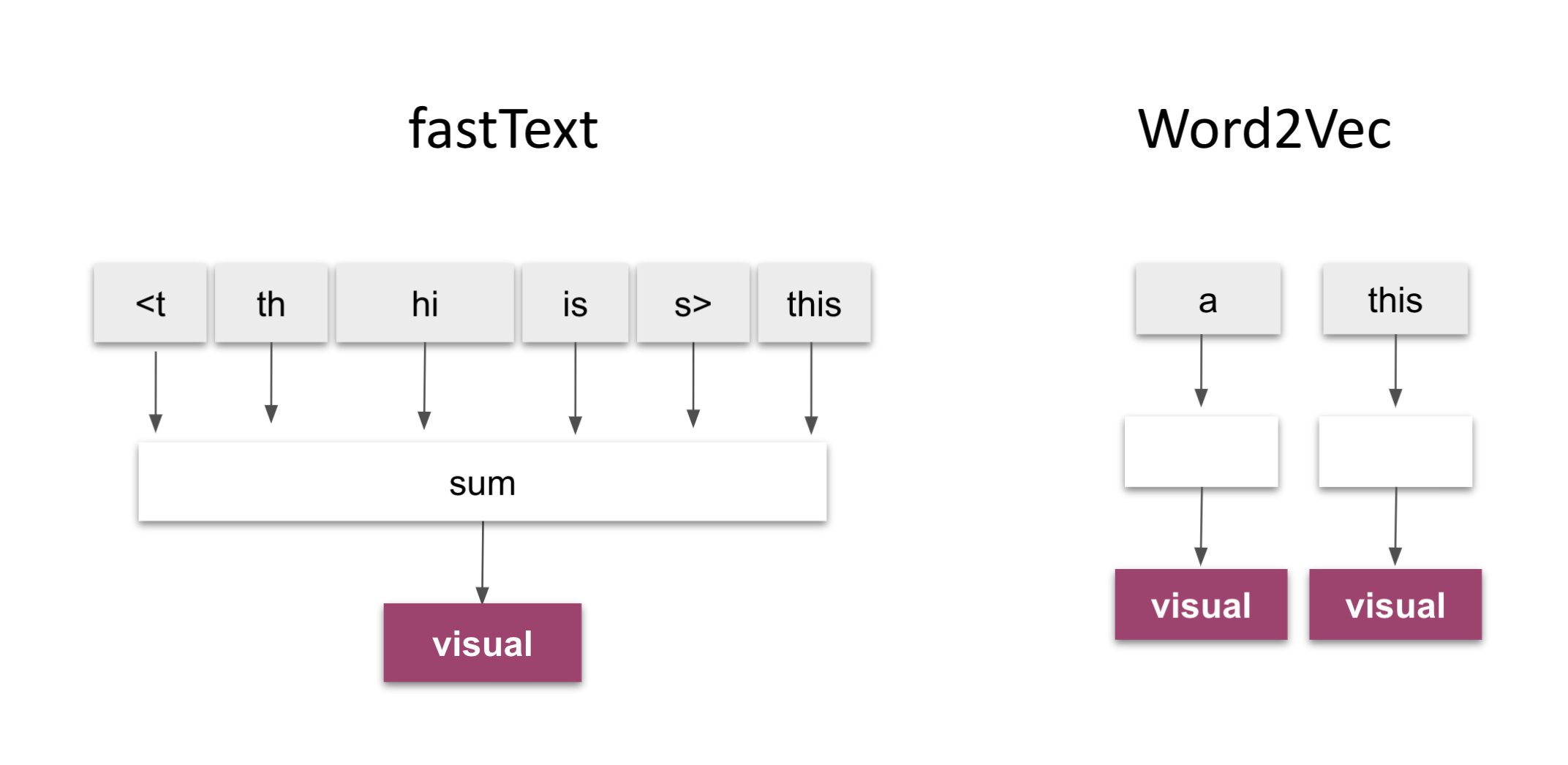
FastText için skipgram ve cbow mimarilerini denedik. Uygulama yöntemler için: train_unsupervised
3.1.3. BERT Backbone - Referans
BERT modeli, bir sorguyu ve bir dizi anahtar-değer çiftini bir çıktıya eşlemektedir. Burada sorgu, anahtarlar, değerler ve çıktının kendi aralarındaki korelasyonu ifade edecek vektörler oluşmaktadır. Çıktı, değerlerin ağırlıklı toplamı ile hesaplanmaktadır. Bir değere atanan ağırlık ise sorguya karşılık gelen anahtarla uyumluluk oranı ile hesaplanmaktadır.
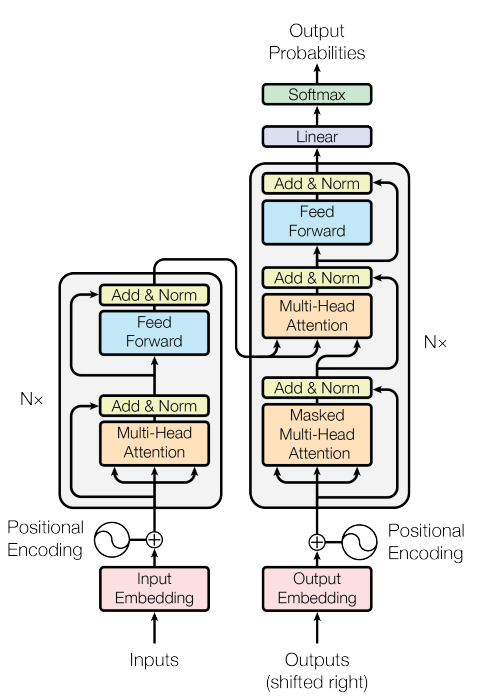
Daha iyi sonuçlar almak adına, MDZ Digital Library Team (dbmdz) tarafınca Türkçe kaynaklarla eğitilmiş BERT modellerine başvurduk. Bu modellerin boyutları kullanılan vocab büyüklüğüne göre değişmektedir ve şu veriler kullanılarak eğitilmiştir:
Model Listesi:
- dbmdz/bert-base-turkish-cased
- dbmdz/bert-base-turkish-uncased
- dbmdz/bert-base-turkish-128k-cased
- dbmdz/bert-base-turkish-128k-uncased
3.1.4. RoBERTa Backbone - Referans
roBERTa (Robustly Optimized BERT pre-training Approach) modellerinin BERT modellerinden ayrıştığı nokta maskingdir. BERT veri hazırlanma aşamasında yalnızca bir kere, statik bir masking yöntemi kullanırken; ROBERTA her bir epoch'da dynamic masking yapmaktadır ve bu nedenle robust olarak atfedilmektedir.
Model Listesi:
3.1.5. Sentence Transformers Backbone - Referans
Kullandığımız Sentence Transformerların hepsi BERT ailesine aittir. Sentence Transformerslar genellikle metin ve görsellerin belirli bir vektör uzayında benzerliklerini daha hızlı tespit edebilmek adına geliştirilmiş ve daha çok unsupervised görevlerde kullanılmaktadırlar.
Model Listesi:
- sentence-transformers/paraphrase-multilingual-mpnet-base-v2
- sentence-transformers/all-MiniLM-L12-v2
- sentence-transformers/all-MiniLM-L6-v2
Bu kısımda Aşama 1'de elde edilen vektörler/öznitelikler kullanılarak farklı mimarilerle sınıflandırma görevi gerçekleştirilmiştir.
3.2.1. LightGBM - Referans
LightGBM, histogram tabanlı çalışan bir boosting (ensemble) yöntemidir. Sürekli değerleri kesikli formata dönüştürerek hesaplama gücü gereksinimi azaltır ve hızı artırır.
LightGBM leaf-wise bölünme yöntemini kullanmaktadır:
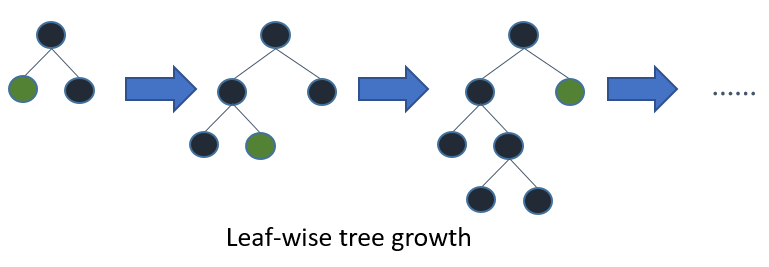
Leaf-wise yaklaşım veriseti küçük olduğunda overfit riski doğurmaktadır ancak doğru parametre seti ile bu tür riskler ortadan kaldırılabilir.
3.2.2. XGBoost - Referans
XGBoost'da (Extreme Gradient Boosting) decison-tree temelli ve gradient-boosting yöntemlerinden biridir. LightGBM'den farklı olarak level-wise yaklaşımı izlemektedir:
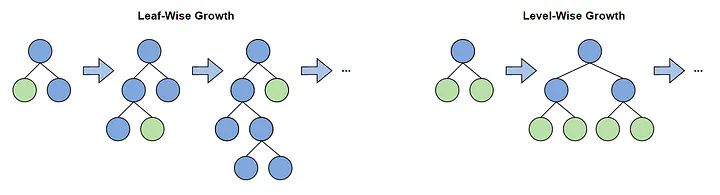
3.2.3. CatBoost - Referans
Catboost diğer Gradient Boosting algoritmalarından farklı olarak symmetric tree yöntemini izler:
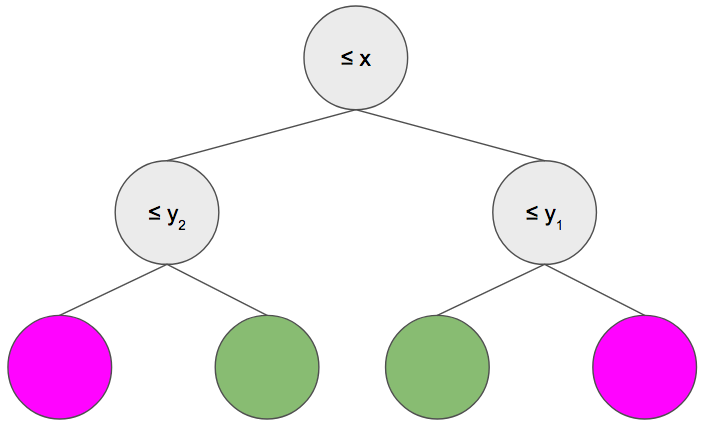
Ayrıca kategorik öznitelikleri daha farklı ele alarak one-hot-encoding dışına çıkar, farklı kategorik değerleri birleştirir ve daha iyi performans gösterir.
3.2.4. Support Vector Classifier (SVC) - Referans
Support Vector Machines (SVMs) sınıflandırma, regresyon ve aykırı değerlerin tespiti için kullanılan bir dizi denetimli öğrenme yöntemidir. Vektör boyutu fazla olduğunda avantaj sağlayan bir yöntemdir.
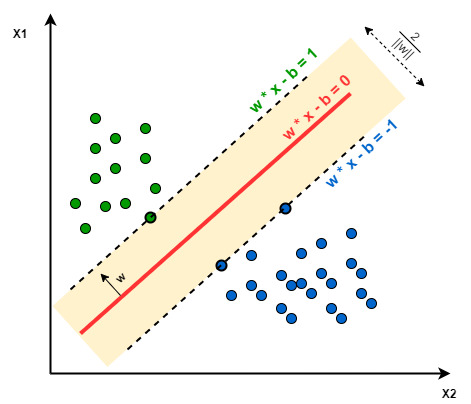
Multi-class sınıflandırma için ise one-versus-one yöntemi izlenerek tahminler oluşturulmaktadır.
3.2.5. Neural SoftMax Katmanı - Referans
Fine-tune ettiğimiz dil modellerinin son katmanına softmax yerleştirerek her bir class için olasılık dönmesini sağladık.
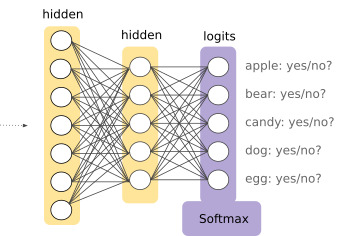
Böylece Aşama 2 aslında Aşama 1'in içinde yer almış oldu ve nihai çözümümüzde de hem mimari olarak kolaylık sağlamasından hem de başarısından ötürü bu yöntemi kullandık.
Yarışma boyunca birçok mimari ve yöntemi kombinasyonlarıyla denendi. Denemelerimize ve sonuçlarına aşağıdaki tabloda yer verilmiştir. NLP modellerinde hem ayrıklığı azaltmak hem de transformer modellerinin aynı boyutta sözlük dağarcığıyla daha fazla farklı kelimeyi temsil edebilmeleri adına küçük-harf dönüşümü kullanılmıştır. Verilmiş bütün mimari kombinasyonlar aynı split stratejisiyle RTX4090 üzerinde eğitilmiştir. Stratified 10 Fold ve OOF (Out-of-Fold) sonuçları raporlanmıştır.
| Model | F1-Macro | F1-OTHER | F1-INSULT | F1-RACIST | F1-SEXIST | F1-PROFANITY | Ortalama Fold Eğitim Süresi |
|---|---|---|---|---|---|---|---|
| toxic-dbmdz-bert-base-turkish-128k-uncased | 95.58 | 96.63 | 92.16 | 96.67 | 96.43 | 95.99 | 64.02 +- 0.4s |
| dbmdz-bert-base-turkish-128k-uncased (Fine-Tuned) Embeddings + svc | 95.54 | 96.59 | 92.14 | 96.71 | 96.28 | 95.98 | 77.96 +- 0.53s |
| dbmdz-bert-base-turkish-128k-uncased (Fine-Tuned) Embeddings + lgbm | 95.5 | 96.62 | 91.94 | 96.6 | 96.34 | 96.01 | 80.71 +- 0.42s |
| dbmdz-bert-base-turkish-128k-uncased (Fine-Tuned) Embeddings + xgb | 95.48 | 96.59 | 91.94 | 96.52 | 96.41 | 95.95 | 76.52 +- 0.33s |
| dbmdz-bert-base-turkish-128k-uncased (Fine-Tuned) Embeddings + catboost | 95.44 | 96.51 | 91.91 | 96.69 | 96.15 | 95.95 | 81.57 +- 0.31s |
| xlm-roberta-base (Fine-Tuned) Embeddings + lgbm | 92.92 | 94.35 | 87.27 | 94.37 | 94.66 | 93.96 | 102.41 +- 0.32s |
| xlm-roberta-base (Fine-Tuned) Embeddings + svc | 92.89 | 94.24 | 87.43 | 94.31 | 94.48 | 93.97 | 97.83 +- 0.5s |
| xlm-roberta-base (Fine-Tuned) Embeddings + xgb | 92.84 | 94.29 | 87.21 | 94.38 | 94.46 | 93.87 | 97.88 +- 0.31s |
| xlm-roberta-base (Fine-Tuned) Embeddings + catboost | 92.84 | 94.19 | 87.34 | 94.48 | 94.28 | 93.9 | 101.28 +- 0.35s |
| toxic-xlm-roberta-base | 92.56 | 93.92 | 86.71 | 94.16 | 94.21 | 93.78 | 80.63 +- 0.35s |
| dbmdz-bert-base-turkish-128k-uncased Embeddings + svc | 90.9 | 93.76 | 85.1 | 92.0 | 91.31 | 92.33 | 10.35 +- 1.0s |
| tfidf Embeddings + lgbm | 89.5 | 89.16 | 82.05 | 90.96 | 92.18 | 93.14 | 33.56 +- 0.37s |
| dbmdz-bert-base-turkish-128k-uncased Embeddings + catboost | 88.37 | 92.2 | 81.86 | 88.95 | 88.3 | 90.53 | 14.75 +- 0.12s |
| tfidf Embeddings + xgb | 87.61 | 87.04 | 78.67 | 89.5 | 90.63 | 92.19 | 55.15 +- 0.52s |
| dbmdz-bert-base-turkish-128k-uncased Embeddings + xgb | 87.42 | 91.74 | 80.7 | 87.7 | 87.16 | 89.81 | 11.97 +- 0.17s |
| dbmdz-bert-base-turkish-128k-uncased Embeddings + lgbm | 87.04 | 91.28 | 80.42 | 86.59 | 87.32 | 89.6 | 16.66 +- 0.15s |
| tfidf Embeddings + catboost | 86.39 | 85.45 | 77.06 | 88.36 | 90.1 | 90.98 | 279.94 +- 2.28s |
| xlm-roberta-large Embeddings + lgbm | 79.93 | 88.31 | 70.02 | 79.7 | 82.55 | 79.06 | 27.12 +- 0.66s |
| xlm-roberta-base Embeddings + catboost | 79.05 | 86.88 | 70.3 | 77.38 | 83.23 | 77.44 | 16.6 +- 0.14s |
| xlm-roberta-large (Fine-Tuned) Embeddings + lgbm | 78.95 | 84.29 | 72.2 | 80.22 | 80.29 | 77.77 | 186.16 +- 1.01s |
| fasttext Embeddings + catboost | 78.4 | 84.09 | 65.69 | 74.19 | 84.98 | 83.05 | 4.35 +- 0.05s |
| xlm-roberta-base Embeddings + xgb | 78.04 | 86.58 | 68.66 | 75.58 | 82.68 | 76.67 | 13.83 +- 0.14s |
| xlm-roberta-base Embeddings + lgbm | 77.64 | 86.41 | 67.47 | 75.69 | 82.46 | 76.15 | 18.06 +- 0.08s |
| fasttext Embeddings + xgb | 77.36 | 83.19 | 64.46 | 71.92 | 84.19 | 83.05 | 11.29 +- 0.13s |
| fasttext Embeddings + lgbm | 76.92 | 83.28 | 63.65 | 71.08 | 84.18 | 82.4 | 1.97 +- 0.06s |
| toxic-xlm-roberta-large | 72.01 | 79.11 | 73.34 | 64.36 | 65.67 | 77.59 | 151.79 +- 0.92s |
| xlm-roberta-base Embeddings + svc | 58.73 | 75.24 | 49.77 | 45.46 | 62.15 | 61.01 | 11.87 +- 0.19s |