Postgres Pagination Strategy for List Endpoints #281
Description
Postgres Pagination Strategy for List Endpoints
Background
The list* endpoints in Marquez v0.1 have (or will have soon)
implemented result pagination to bound the response sizes. To ensure
Marquez Core's scalability, and to enable a low-latency UI, we should
standardize pagination strategy which will scale with Marquez's data
volume.
Assumptions
list*endpoint results should always be sorted by the same table column(s)- Clients do not require random access into the list of objects
Goals
- Simple to implement within the application and the database
- Performance and database load should be constant regardless of
cardinality of underlying table
Strategy
Keyset Pagination
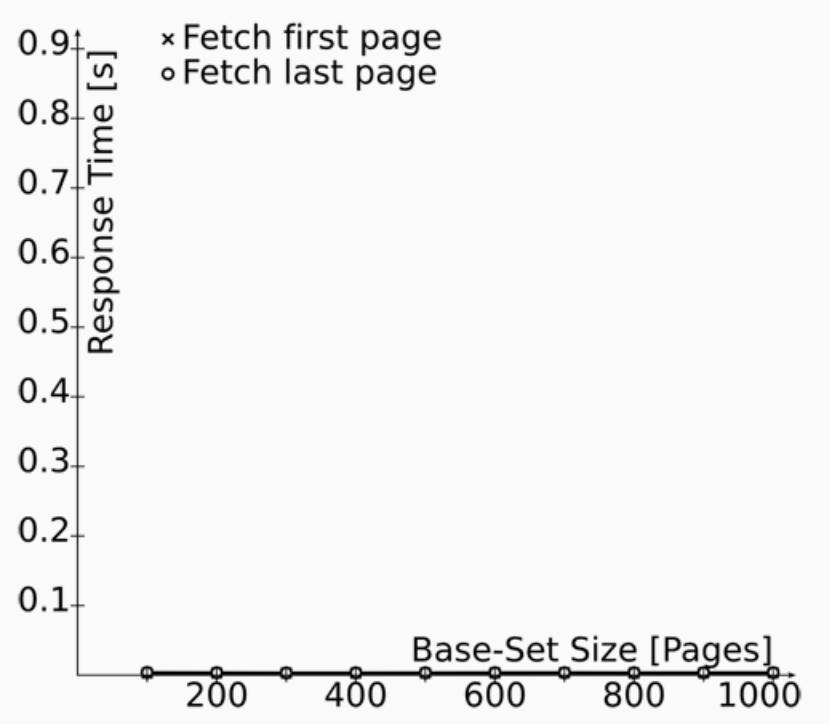
The Keyset Pagination approach is simplest method for both the Marquez application and Postgres database to implement. It requires an index on the column used to sort the data. The application should be passed two values: after and n:
nis the number of results to returnafteris the value that the nextnresults should follow in the sort
order
There are a few benefits to this approach: Btree indexes can fulfill this query easily with a range scan, regardless of the indexed column cardinality. It also can be combined with filtering in the WHERE clause, which could be desirable client-side. However, the requirement of an after value requires the client to track the last value (or first value if paging backwards) from the previous page and pass it back to the server to fetch another set of results. It also means that the client cannot arbitrarily jump to a page which is not immediately before or after the last page fetched.
 1
1
Alternatives Considered
Limit/Offset
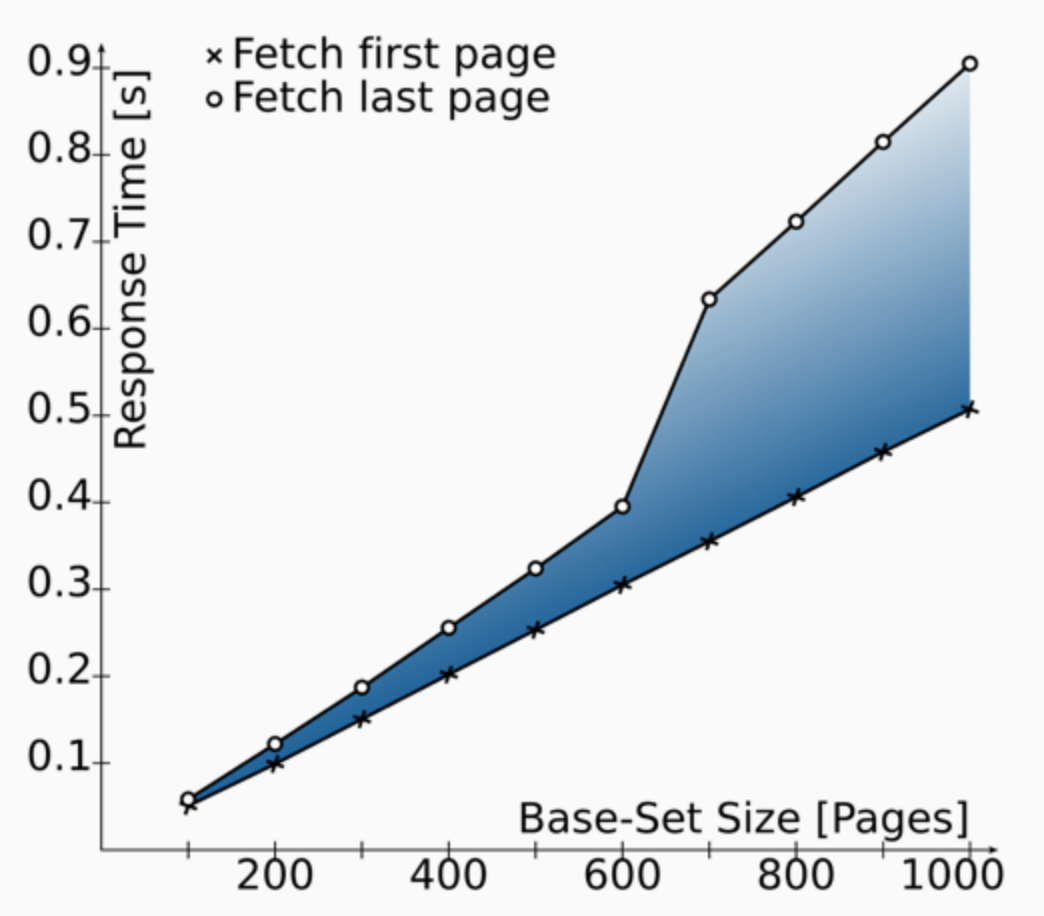
The initial Marquez pagination implementation utilized the LIMIT, OFFSET features in Postgres. This works for rapid testing and development with small data volume, but querying fetching large OFFSETs is increasingly expensive on the database2.
 1
1
Internal CTIDs
Postgres tracks an internal ID for each row in a table which corresponds to the physical ordering of the data in the table. For append-only data, the CTID will increase monotonically for new rows and could potentially be used for random access to pages. However, this will cause issues for
tables where data is deleted since Postgres will fill the CTID gaps with new rows. At the moment, Marquez Core is actually append-only and never deletes any data, so this could potentially work. However, paginating with CTIDs cannot be combined with filtering3 which will block useful UI feature for filtering on potentially large lists.