[TOC]
↗ Probability Theory & Statistics ↗ Statistical (Data-Driven) Learning & Machine Learning (ML)
↗ Mathematical Tools & Scientific Computing
↗ R Language ↗ Python
🔗 https://www.math.pku.edu.cn/teachers/lidf/docs/Rbook/html/_Rbook/stat-learn-intro.html
统计学习(statistical learning), 也有数据挖掘(data mining),机器学习(machine learning)等称呼。(真的吗老师?) 主要目的是用一些计算机算法从大量数据中发现知识。 方兴未艾的数据科学就以统计学习为重要支柱。 方法分为有监督(supervised)学习与无监督(unsupervised)学习。
无监督学习方法如聚类问题、主成分分析、异常点识别、购物篮问题等。
有监督学习即统计中回归分析和判别分析解决的问题, 现在又有回归判别数、随机森林、lasso、梯度提升法、支持向量机、 神经网络、贝叶斯网络、排序算法等许多方法。
无监督学习在给了数据之后, 直接从数据中发现规律, 比如聚类分析是发现数据中的聚集和分组现象, 购物篮分析是从数据中找到更多的共同出现的条目 (比如购买啤酒的用户也有较大可能购买火腿肠)。
有监督学习方法众多。 通常,需要把数据分为训练样本(training sample)和测试样本(testing sample), 训练样本的因变量(数值型或分类型)是已知的, 根据训练样本中自变量和因变量的关系训练出一个回归函数, 此函数以自变量为输入, 可以输出因变量的预测值。
训练出的函数有可能是有简单表达式的(例如,logistic回归)、 有参数众多的表达式的(如神经网络), 也有可能是依赖于所有训练样本而无法写出表达式的(例如k近邻分类)。
大多数人会将统计学描述为数学的一个分支,用于仅使用样本对总体进行推断。
- 例如,我们可能想了解美国青少年的平均身高。衡量所有美国青少年是不切实际的。相反,我们可以随机选择全国的几所学校,并测量每所学校十名青少年。这样,我们就会得到一个身高样本,其平均值告诉我们整个青少年人口的平均值。
- 同样,我们可能有兴趣了解温度如何影响工业过程或公寓中的房间数量如何影响其销售价格。
- 统计学发展了回答这些问题的方法。这样做是非常正式的。它的所有工具,如假设检验和描述性统计,都带有性能的数学证明。例如,我们知道围绕样本均值构建的
置信区间保证捕获时间的实际总体均值
。然而,这些证据依赖于在现实中可能不成立的假设。例如,常见的假设是样本元素的统计独立性和数据的正态性。
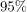
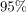
为什么机器学习是统计学?
- 支持这种观点的研究人员认为,从数据中诱导(任何形式的)预测规则无非是对产生这些数据的过程进行推断。例如,ML为我们预测公寓价格的方程也是对整个公寓“人口”遵循销售的一般规则的推断。同样,推断有关统计信息中数据生成过程的一般规则可以预测新数据。
- 为了支持这一论点,人们还说,一些核心的ML模型(如线性回归)最初是在统计学中开发和研究的。他们更进一步,断言所有ML模型都是统计工具。唯一的区别是前者的可解释性较低,计算要求更高。更重要的是,一些研究人员表示担心ML是统计数据做错了。原因是自动化建模缺乏适当的严谨性,只有通过人类的参与才能实现。
为什么机器学习不是统计学?
- 但是,许多ML研究人员强烈反对这些说法。他们会争辩说,对预测的关注使ML与统计学不同。大多数时候,尤其是在行业中,性能指标才是最重要的。因此,具有数百个内层的深度神经网络是完全可以接受的 ML 产品,如果它的预测是准确的,即使它本身是不可解释的,并且不允许任何推理。另一方面,统计学家使用这样的黑盒模型会非常不舒服。
- 此外,由于 ML 专注于预测性能,因此它会在保留的测试数据上验证其模型,以检查其泛化能力。但是,统计信息不会将样本拆分为训练集和测试集。
- 此外,ML似乎比统计数据更关注训练其模型和处理大型数据集的工程和计算方面。原因是统计学家开发了他们的工具,精确地处理小样本,以避免处理大量数据。相比之下,ML工具起源于计算机科学和AI领域,因此科学家们从一开始就考虑了算法及其实现方面。因此,ML方法取代了统计方法,因为它解决了传统统计学无法解决的任务。
数据挖掘源于商业应用中的数据库管理。其目标是发现大数据中的有价值的模式,并为业务利益相关者提供可操作的信息。数据挖掘将结果优先于方法。