|
| 1 | +# How Kimi K2 Achieves Efficient RL Parameter Updates |
| 2 | + |
| 3 | +In the [Kimi K2](https://github.com/MoonshotAI/Kimi-K2) model released in July this year, we achieved RL parameter updates for 1T parameter models in approximately 20 seconds, significantly optimizing a key efficiency bottleneck in RL end-to-end training time. Along the way to implementing efficient parameter updates, we encountered many challenges, and we'd like to share some of the problems we faced and the solutions we tried. |
| 4 | + |
| 5 | +## Our Scenario |
| 6 | + |
| 7 | +Currently, LLM reinforcement learning training mainly consists of two architectures: colocate and disaggregation. Colocate means training and inference share GPU resources and alternate GPU usage; disaggregation means training and inference are separated, each occupying different GPU devices. In both architectures, a crucial phase is parameter updates - after each training round ends, parameters need to be synchronized to the inference framework before rollout begins. If this phase takes too long, it causes GPUs to idle, preventing improved overall GPU utilization and resulting in significant losses to end-to-end training performance. Therefore, efficient parameter updates are a worthwhile optimization direction in RL training. |
| 8 | + |
| 9 | +In our internal experiments, we use the colocate scenario more frequently, so we focused our optimizations on colocate. Our colocate RL differs from most open-source community frameworks - we don't use general solutions like Ray, but instead deploy training and inference in two different containers sharing one machine. This approach allows training and inference to be completely decoupled, with independent feature development that don't affect each other, and their environments and images are also completely decoupled. This solution enables smooth internal training and inference development, and this deployment method is similar to our online Kimi deployment, allowing us to reuse some online service infrastructure. Of course, it also brings a problem - training and inference have difficulty interacting with each other's Process Groups, creating certain difficulties for parameter updates. Therefore, in our design, we hoped to provide a lightweight intermediate layer to connect training and inference, without modifying training and inference Process Group logic as much as possible, so we began designing **checkpoint-engine**, hoping to build a bridge between training and inference to achieve parameter updates. |
| 10 | + |
| 11 | +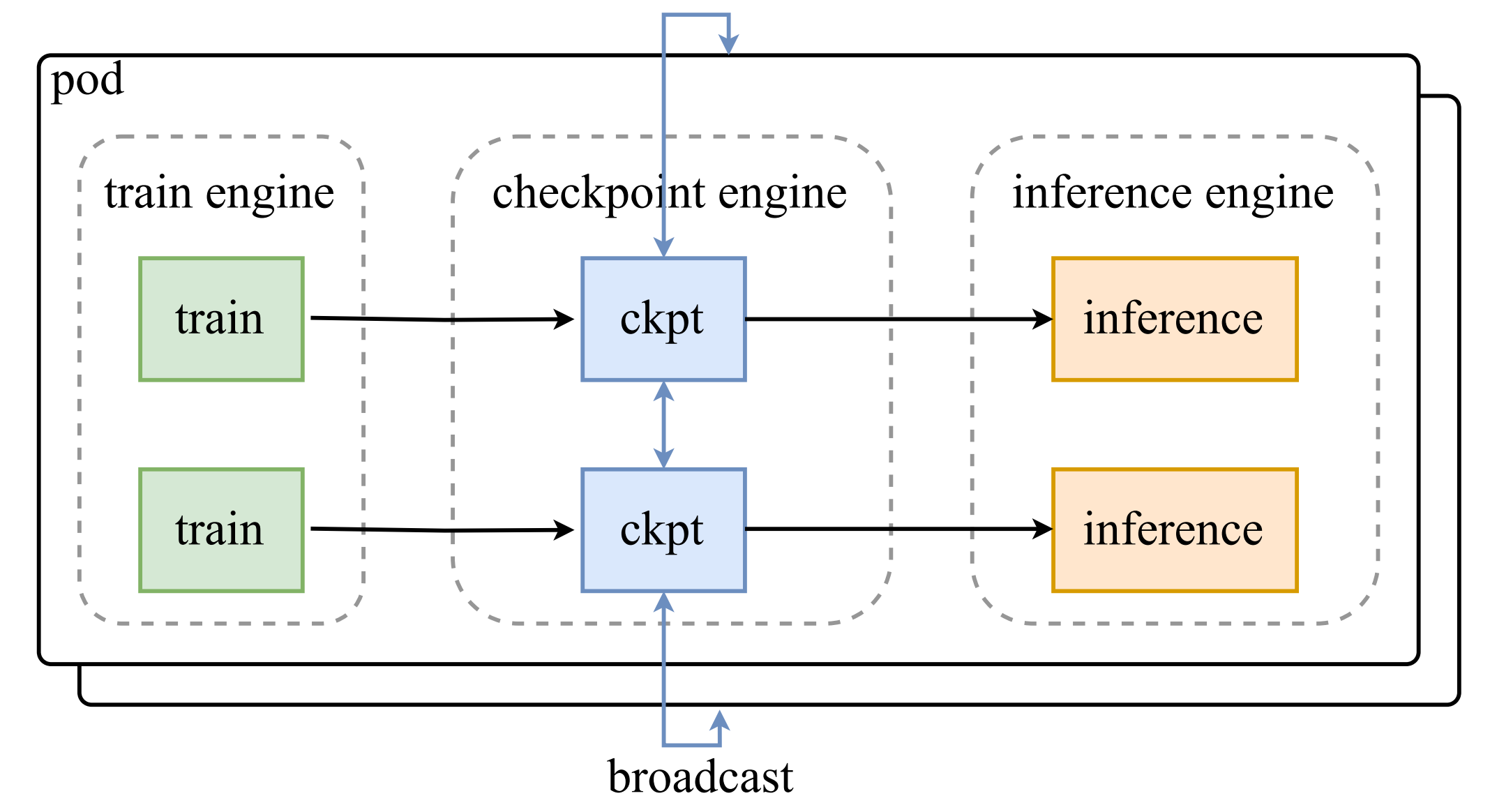 |
| 12 | + |
| 13 | +It's worth noting that our choice of this solution was also based on some considerations and trade-offs. Theoretically, the optimal performance solution would be for the RL framework to be aware of training and inference parallelism, then have a unified controller perform reshard to achieve parameter updates - this would definitely achieve the fastest parameter updates without redundant data transmission. However, from an engineering perspective, we didn't want to intrude too much logic into the training and inference engines, so we made a trade-off by designing checkpoint-engine so that each device would receive full weights. This would certainly result in data redundancy when inference is already split into TP or EP, but from a RDMA network device and NVLink bandwidth perspective, machines like H800 can provide at least 100GiB/s performance between machines or within machines, so using 10s for full 1TiB model weight communication across all machines was an acceptable range for us, so we adopted this most decoupled solution from an engineering perspective. |
| 14 | + |
| 15 | +## Initial Logic |
| 16 | + |
| 17 | +In the initial development of [k1.5](https://arxiv.org/abs/2501.12599), we implemented checkpoint-engine parameter update logic, with the idea of transmitting tensor data through CUDA IPC, providing an interface in inference to accept CUDA IPC tensors, and each rank in training would correspond to a checkpoint-engine. After each training session, weights would be passed to the corresponding checkpoint-engine, which would first broadcast parameters to each rank through network or NVLink, then package each tensor into IPC handles through CUDA IPC and share them with inference to achieve parameter updates. The general process is shown in the figure below. During transmission, since GPU memory couldn't hold all weights, we will onload tensors from CPU to GPU by group in per layer and per EP, which basically met our needs at the time. |
| 18 | + |
| 19 | +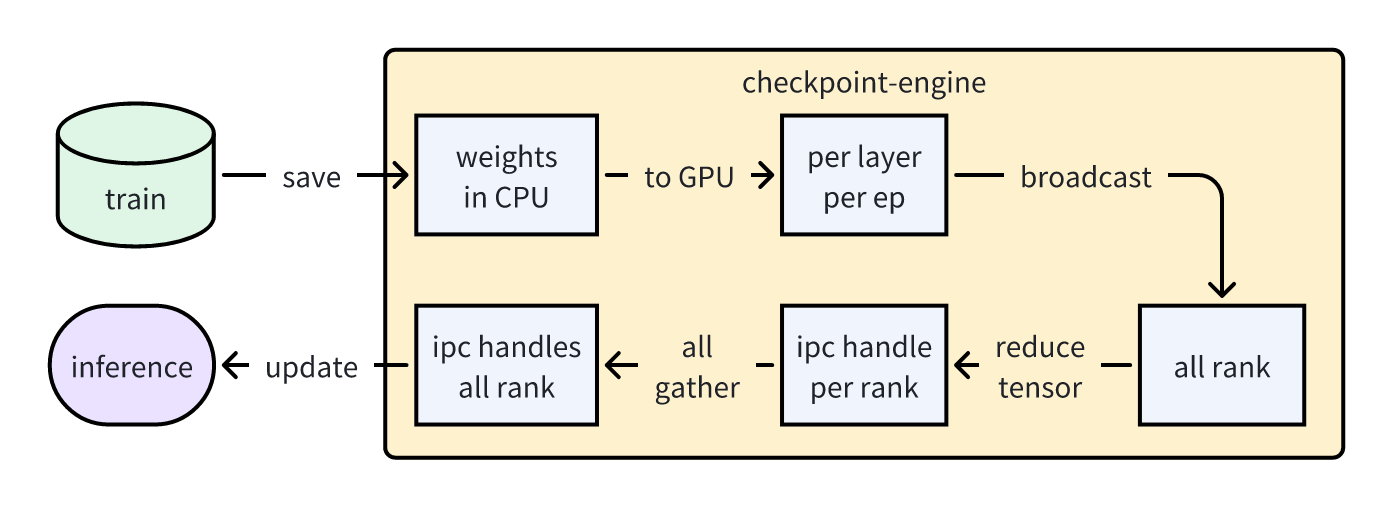 |
| 20 | +*Initial checkpoint-engine parameter update solution* |
| 21 | + |
| 22 | +## Pitfalls and Solutions |
| 23 | + |
| 24 | +As model sizes further increased, we found that this per layer per EP approach and packaging each tensor into IPC handles created significant overhead. When running Kimi K2 RL on a large-scale of H800s, we encountered major performance bottlenecks, with parameter update times reaching up to 10 minutes, forcing us to undertake deep optimization. |
| 25 | + |
| 26 | +### Shared Buffer and Two-Stage Pipeline Implementation |
| 27 | + |
| 28 | +After profiling, we discovered several issues: |
| 29 | + |
| 30 | +- The per layer per EP pattern caused unstable GPU memory usage, sometimes leading to CUDA OOM during parameter updates |
| 31 | +- Per layer per EP sent async broadcasts for each tensor individually, waiting until all were sent before updating weights, potentially creating many fragmented small communications |
| 32 | +- The pattern of one IPC handle per tensor caused very long serialization and deserialization times in vLLM, with the initial implementation gathering all ranks' ipc handles together and passing them to vLLM, which would transmit full data when passing to each TP or EP from vLLM |
| 33 | +- Communication operations in Checkpoint-engine and update weights operations in vLLM were serial |
| 34 | + |
| 35 | +Therefore, based on the above problems, our solutions were relatively clear - adopt a bucket approach to batch accumulation, putting fragmented tensors into fixed bucket size buffers |
| 36 | + |
| 37 | +1. Only broadcast this buffer each time, eliminating overhead from small communications and stabilizing GPU memory usage |
| 38 | +2. Share this buffer with vLLM from the beginning, using the buffer as a channel for data transmission, avoiding overhead from transmitting ipc handles with each request - only the first request has ipc handle transmission overhead, subsequent transmissions are tensor meta information, greatly reducing vLLM serialization and deserialization overhead |
| 39 | +3. We also optimized the ipc handle gather logic |
| 40 | + 1. No need to gather ipc handles with each request, only before the first request, reducing communication operations |
| 41 | + 2. No need for all ranks to all_gather ipc handles, since each vLLM instance will only have one rank's checkpoint-engine initiating requests, so just gather ipc_handles to it, no need for global all_gather |
| 42 | +4. To overlap broadcast and update weights operations in vLLM, we need to use double buffers to implement a two-stage pipeline |
| 43 | + |
| 44 | +The overall implementation is as follows: |
| 45 | + |
| 46 | +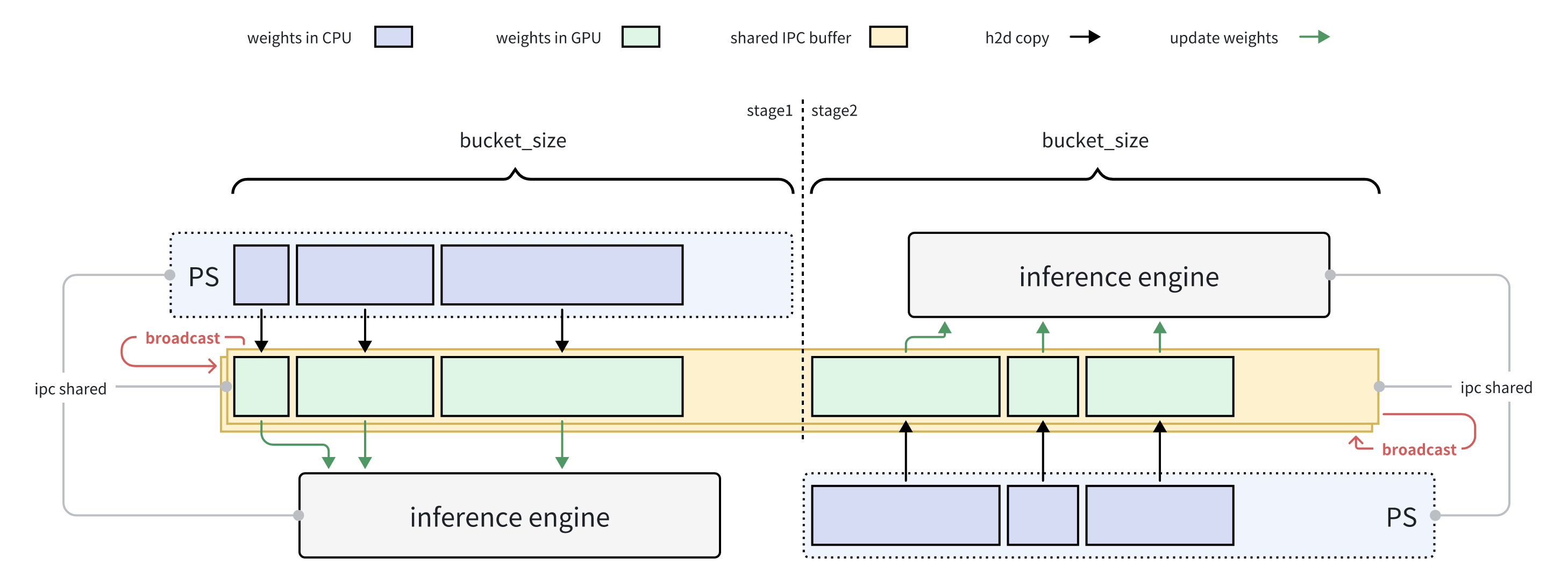 |
| 47 | +*Double buffer implementation of two-stage pipeline* |
| 48 | + |
| 49 | +Through the above 4 optimizations, we successfully reduced parameter update time from 10 minutes to 2 minutes on a large-scale of H800s, basically meeting our internal RL training needs. |
| 50 | + |
| 51 | +### Improving H2D Speed and Optimizing Inference Engine Parameter Update Performance |
| 52 | + |
| 53 | +However, theoretically, there should be room for improvement in this speed - the broadcast bandwidth of interconnected networks between H800 or H20 GPU machines should reach at least 100GiB/s, so the theoretically optimal time for synchronizing Kimi K2 1TiB weight files once should be under 10s, so there must be more optimization here. |
| 54 | + |
| 55 | +We found several problems in the above solution: |
| 56 | + |
| 57 | +- checkpoint-engine needs to wait for a single rank to complete H2D (Host To Device) before each Broadcast, but H2D speed on machines basically only reaches 40-50GiB/s, causing bandwidth to be bound to single H2D, unable to utilize full network performance |
| 58 | +- vLLM has some overhead during update weights, specifically: |
| 59 | + - [Each request needs to calculate dict(self.named_parameters())](https://github.com/vllm-project/vllm/blob/v0.10.2rc1/vllm/model_executor/models/deepseek_v2.py#L939), requiring Python to perform CPU-bound operations each time |
| 60 | + - During expert weight updates, [using .item frequently triggers GPU -> CPU synchronization](https://github.com/vllm-project/vllm/blob/v0.10.2rc1/vllm/model_executor/layers/fused_moe/layer.py#L1151), making update weights speed very unstable, sometimes fast, sometimes slow |
| 61 | + |
| 62 | +So we made 3 more optimizations: |
| 63 | + |
| 64 | +1. Try to overlap H2D and Broadcast |
| 65 | +2. Cache `dict(self.named_parameters())` |
| 66 | +3. Cache `expert_map` on CPU to avoid frequent CUDA synchronization |
| 67 | + |
| 68 | +Optimization 2 and 3 is easy to implemente. For optimization 1, we think it was perfect, believing it could achieve perfect overlap as shown below: |
| 69 | + |
| 70 | +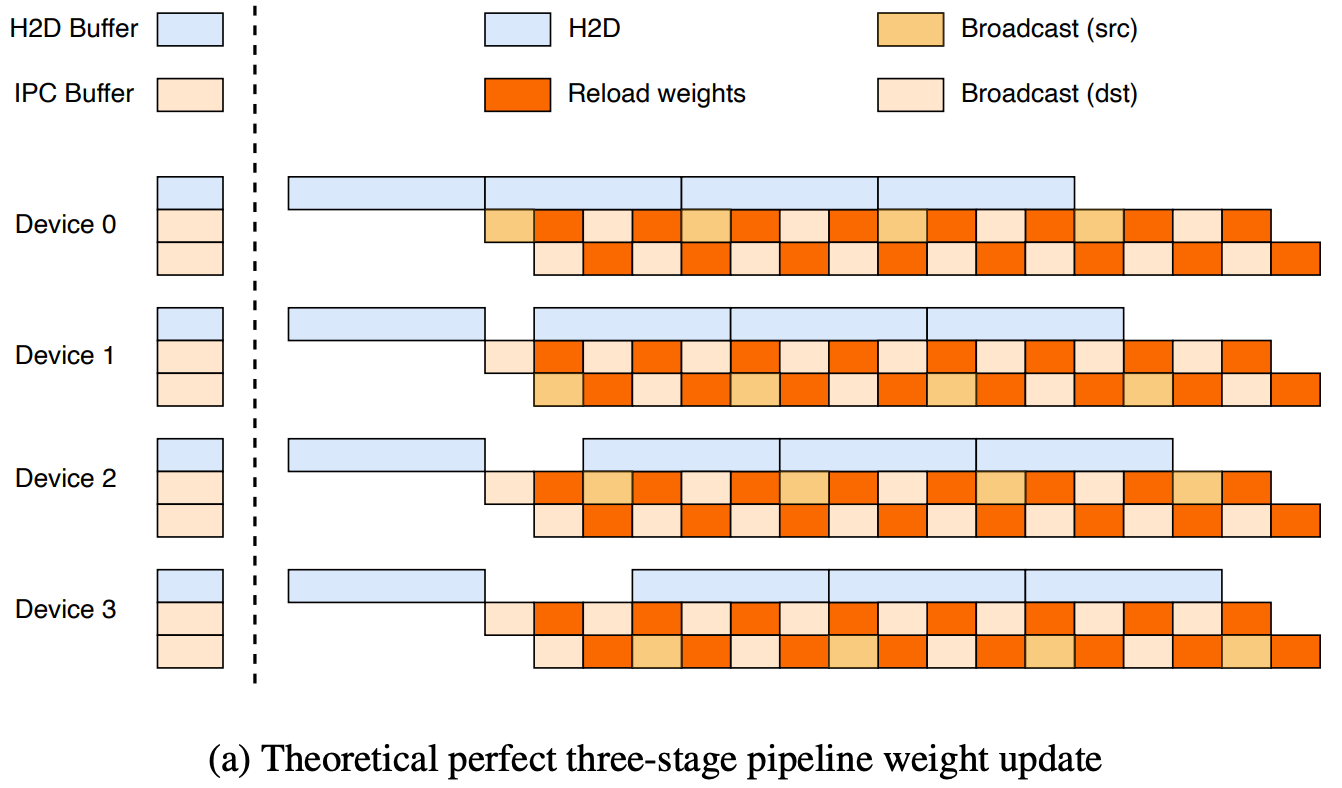 |
| 71 | + |
| 72 | +But actual testing found that on H800 and H20 machines, Broadcast and H2D compete for PCIE bandwidth, causing both to slow down, resulting in this: |
| 73 | + |
| 74 | +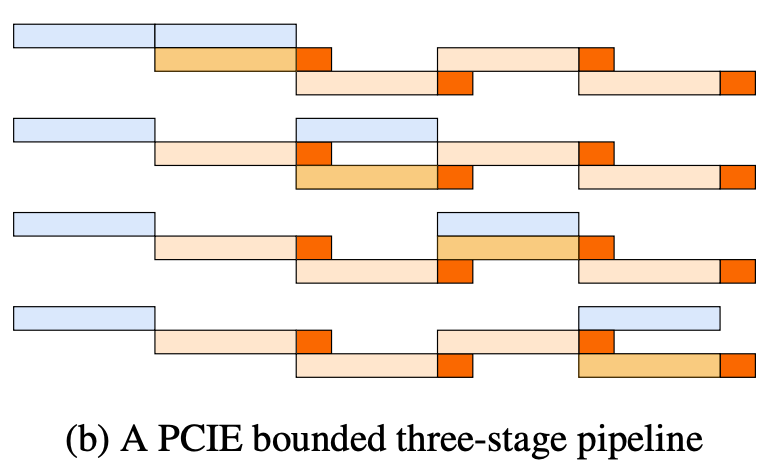 |
| 75 | + |
| 76 | +So does a solution exist that isn't bound by single PCIE speed? We found that each node can perform H2D simultaneously first, achieving larger aggregated H2D bandwidth instead of everyone waiting for one rank to do H2D. When broadcast is needed, a quick D2D (Device To Device) from already H2D data can put data into broadcast buffer for broadcasting, since D2D speed is very fast, its overhead can be ignored. With this solution, we can utilize all machines' PCIE during H2D, improving overall throughput. The final implemented pipeline is as follows: |
| 77 | + |
| 78 | +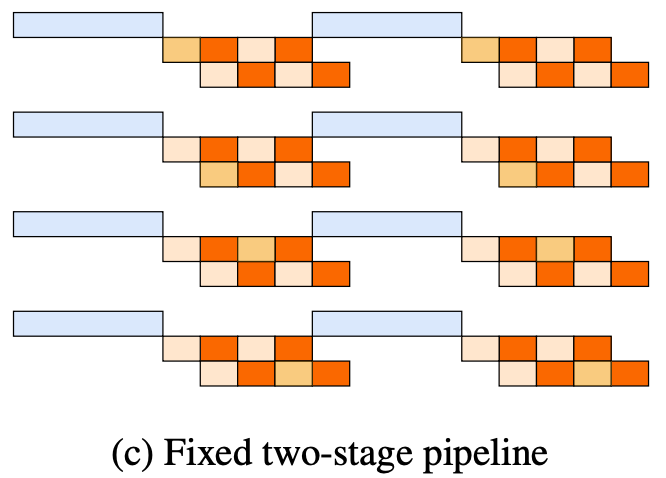 |
| 79 | + |
| 80 | +After these optimizations, our internal testing shows that **parameter updates for Kimi K2 models can be achieved in just 20s under a large-scale of H800s**, with stable speed and basically no occurrences of slow parameter updates. |
| 81 | + |
| 82 | +## Inference Engine Fault Self-Healing |
| 83 | + |
| 84 | +After implementing efficient parameter update logic, we found another problem in reinforcement learning - inference engines occasionally fail, causing RL training crashes. Of course, a simple solution comes to mind - when an inference engine fails, don't let the entire task hang, just restart it. However, note that in RL processes, we directly transmit weights from training to inference without disk storage. If inference wants to restart, it appears to need to reconvert from training's checkpoint, causing longer IO waits and slower restart speed. The best approach is to hope checkpoint-engine can achieve online weight updates for restarted inference instances. |
| 85 | + |
| 86 | +In our design at the time, we couldn't achieve this functionality because all inference engine parameter update logic was synchronous, unable to update weights for only some inference instances. Blindly triggering parameter update processes for all inference engines, while trying to let running instances not update weights but only broadcast, would cause them to need additional GPU memory allocation, which is unacceptable for memory-sensitive RL tasks. Therefore, we needed a transmission framework that could directly read weights from running instances' CPU RDMA to failed instances' GPUs. Coincidentally, [mooncake-transfer-engine](https://github.com/kvcache-ai/Mooncake) perfectly meets this requirement. |
| 87 | + |
| 88 | +So we worked with Mooncake to integrate `mooncake-transfer-engine` into our system, implementing a simple solution where failed machines' rank0 reads data from remote CPU RDMA P2P to rank0's GPU according to bucket_size, then broadcasts to other ranks of failed instances, then triggers parameter updates. This elegantly achieves parameter updates for only some instances, implementing efficient fault self-healing. This solution can update failed instance weights in 40s, completely sufficient for single-point fault recovery. |
| 89 | + |
| 90 | +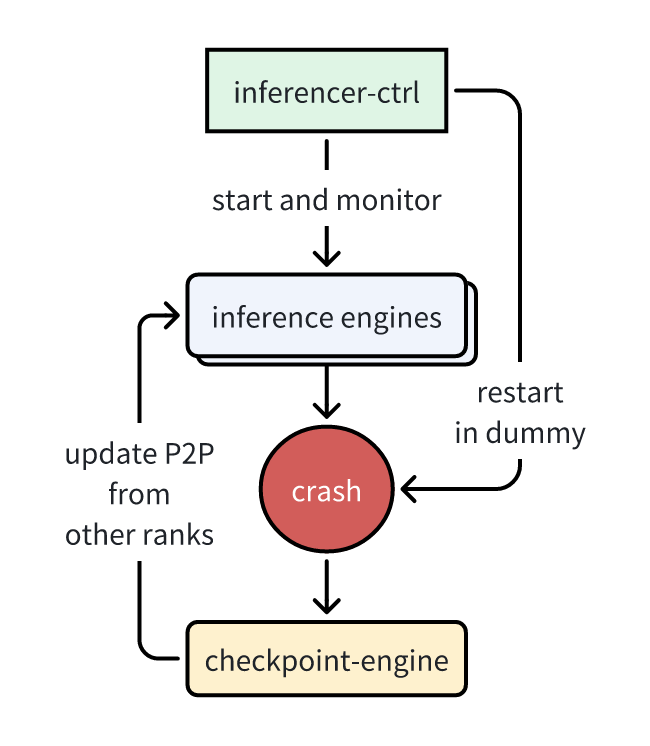 |
| 91 | + |
| 92 | +*Inference Engine Fault Self-Healing* |
| 93 | + |
| 94 | +## Inference Startup Acceleration |
| 95 | + |
| 96 | +In our internal non-RL scenarios, there are usually requirements to start batches of inference services. For this scenario, we have already made some optimizations internally, preheating weights to `/dev/shm` for inference engines to read, which is much faster than reading directly from distributed file systems. However, the cost is occupying more memory space, and waiting for preheating also takes time. |
| 97 | + |
| 98 | +But when we optimized Kimi K2 parameter synchronization overhead to the 20s level, we found this speed was much faster than inference engines reading weights directly from disk or even `/dev/shm`. We also found that checkpoint-engine registering checkpoints from disk can completely overlap with vLLM startup - vLLM startup also has operations like `torch.compile` and Capture CUDA Graph, so there's no need to serially wait for vLLM to finish reading weights before these operations. |
| 99 | + |
| 100 | +So we let vLLM start dummy first, while starting checkpoint engine to register checkpoints in a sidecar. After vLLM is ready, directly trigger update weights for all instances. In practice, we can start all vLLM instances within time close to vLLM dummy startup, greatly improving startup speed. A considerable portion of our internal inference services already use this function, greatly improving user experience. |
| 101 | + |
| 102 | +## Open Source |
| 103 | + |
| 104 | +Over the next two months, this high-performance parameter update solution stably supported our RL training. We gradually realized it has good scalability and flexibility, so we had the idea to open source it for community use. However, our internal checkpoint-engine has two layers - one coupled with some of our RL business logic, responsible for Convert checkpoint, managing vLLM lifecycle, automatic fault recovery, etc.; the other is the core parameter update logic, namely `ParameterServer`. We hoped to decouple `ParameterServer` to provide convenient and flexible interfaces, allowing everyone to use our optimizations better and faster. On the other hand, we also hoped to discuss a high-performance update weights interface with the vLLM community. |
| 105 | + |
| 106 | +So we submitted our internal vLLM update weights approach [to vLLM official](https://github.com/vllm-project/vllm/issues/24163). In discussions with Kaichao You, he also gave us some ideas, finally leading us to finalize a relatively elegant interface, changing control plane interaction with vLLM from HTTP requests to [zmq](https://zeromq.org/) queues, ultimately merging into [vLLM official examples](https://github.com/vllm-project/vllm/pull/24295). |
| 107 | + |
| 108 | +Finally, we separated `ParameterServer` individually and open sourced [checkpoint-engine](https://github.com/MoonshotAI/checkpoint-engine), providing flexible and easy-to-use interfaces while achieving efficient parameter updates. Testing shows efficient parameter update speeds across major models: |
| 109 | + |
| 110 | +| Model | Device Info | GatherMetas | Update (Broadcast) | Update (P2P) | |
| 111 | +| ------------------------------------ | ------------ | ----------- | ------------------ | ----------------- | |
| 112 | +| GLM-4.5-Air (BF16) | 8xH800 TP8 | 0.17s | 3.94s (1.42GiB) | 8.83s (4.77GiB) | |
| 113 | +| Qwen3-235B-A22B-Instruct-2507 (BF16) | 8xH800 TP8 | 0.46s | 6.75s (2.69GiB) | 16.47s (4.05GiB) | |
| 114 | +| DeepSeek-V3.1 (FP8) | 16xH20 TP16 | 1.44s | 12.22s (2.38GiB) | 25.77s (3.61GiB) | |
| 115 | +| Kimi-K2-Instruct (FP8) | 16xH20 TP16 | 1.81s | 15.45s (2.93GiB) | 36.24s (4.46GiB) | |
| 116 | +| DeepSeek-V3.1 (FP8) | 256xH20 TP16 | 1.40s | 13.88s (2.54GiB) | 33.30s (3.86 GiB) | |
| 117 | +| Kimi-K2-Instruct (FP8) | 256xH20 TP16 | 1.88s | 21.50s (2.99GiB) | 34.49s (4.57 GiB) | |
| 118 | + |
| 119 | +The open source version of checkpoint-engine isn't coupled with inference frameworks, but allows users to provide a custom `req_func` when updating weights to decide how to interact with inference engines, making it very convenient to connect with various inference engines. Inference engines can also decide some quantization logic according to their needs. |
| 120 | + |
| 121 | +Through our interface, everyone can easily implement weight update logic using the following code: |
| 122 | + |
| 123 | +```python3 |
| 124 | +ps = ParameterServer(auto_pg=True) |
| 125 | +ps.register_checkpoint(name, files=files, named_tensors=named_tensors) |
| 126 | +ps.gather_metas() |
| 127 | +ps.update(name, req_func) |
| 128 | +``` |
| 129 | + |
| 130 | +The above code will handle NCCL Group creation and destruction for you. If you want to manage NCCL yourself, **you can also not configure `auto_pg=True`, allowing you to manage NCCL Group yourself.** |
| 131 | + |
| 132 | +On the other hand, checkpoint-engine also supports various usage patterns: |
| 133 | + |
| 134 | +- Supports **Fully Broadcast** and **P2P** parameter update methods. The former is our fastest implementation, capable of updating inference engine weights across a large-scale of GPU devices simultaneously. The latter is more flexible, suitable for **fault self-healing, disaggregation** scenarios, capable of dynamically pulling weights from existing checkpoint-engine RDMA without additionally occupying running inference instances' video memory for rapid new instance parameter updates. |
| 135 | +- **Supports registering multiple checkpoints**, allowing flexible switching between multiple checkpoints. Just call register_checkpoint multiple times to register different name checkpoints into ps, specify checkpoint_name during update to use this checkpoint to update inference engines, making checkpoint-engine a parameter service. Both online and offline inference engines can conveniently switch between different model versions for testing. |
| 136 | + |
| 137 | +Note that the current P2P implementation is still relatively naive, with rank0 serially reading weights and broadcasting to other ranks each time. Overlap is actually possible here, such as letting other ranks simultaneously read weights to achieve effects similar to Fixed two-stage pipeline. We will continue optimizing this in the future, and welcome interested friends from the community to implement it together. |
| 138 | + |
| 139 | +Finally, Thanks to vLLM community member [Kaichao You](https://github.com/youkaichao) for providing a scientific inference engine interface. Some related technical solutions in this article can also be found in the [Kimi K2 Technical Report](https://arxiv.org/abs/2507.20534). We hope everyone will try [checkpoint-engine](https://github.com/MoonshotAI/checkpoint-engine). If you find any problems, please submit Issues or PRs. We look forward to continuously developing and optimizing with the community to improve parameter update speed and experience! |
0 commit comments