本章的重点是简要概述较新的 Linux 故障排除工具和实用程序,以及在设计、开发和部署真实的 Linux 系统应用时应遵循的行业最佳实践。不过,我们希望非常明确地说明,这是一本关于 Linux 系统编程的书;这里描述的故障排除提示和最佳实践仅与 Linux 系统上的应用(通常用 C/C++编写)的系统级开发有关;我们不讨论 Linux 上的一般故障排除(例如网络或配置问题的故障排除、系统管理等主题
特别是对于本章(主要是因为它只顺便提到的内容的范围和大小),我们在 GitHub 存储库的进一步阅读部分提供了几篇有用的在线文章和书籍。 请务必浏览一下。
本章是本书的最后一章;在这里,关于 Linux 系统编程,读者将获得以下内容:
- (较新的)故障排除工具和技术概述
- 行业最佳实践概述-在设计、软件工程、编程实现和测试方面
在本节中,我们将提到几个工具和实用程序,它们可以帮助应用开发人员识别系统瓶颈和性能问题。 (注意,为了节省篇幅和时间,这里我们不深入研究几十个常见的可疑工具-Linux 上常见的系统监控实用程序,如ps、pstree、top、htop、pidstat、vmstat、dstat、sar、nagios、iotop、iostat、ionice、lsof、nmon、iftop、ethtool、pidstat、vmstat、dstat、sar、nagios、iotop、iostat、ionice、lsof、nmon、iftop、ethtool、。 netstat、tcpdump、wireshark-而不是提到较新的)。 在执行数据收集(或基准测试)以供以后分析时,需要记住一件重要的事情:不厌其烦地设置一个测试平台,并且在使用它时,对于给定的运行,一次只更改(尽可能)一个变量,这样您就可以看到它的影响。
性能测量和分析是一个巨大的主题;识别、分析和确定性能问题的根本原因绝非易事。 近年来,perf(1)和htop(1)实用程序已经成为 Linux 平台上性能测量和分析的基本工具。
有时,您所需要的只是查看消耗 CPU 最多的是什么;传统上,我们使用众所周知的top(1)实用程序来做到这一点。 相反,尝试非常有用的perf变体,如:sudo perf top。
此外,您还可以通过以下功能利用其中的一些功能:
sudo perf top -r 90 --sort pid,comm,dso,symbol
(-r 90 => collect data with SCHED_FIFO RT scheduling class and priority 90 [1-99]).本质上,这是perf工作流:记录会话(保存数据文件)并生成报告。 (请参阅有关 GitHub 存储库的进一步阅读部分中的链接。)
Brendan Gregg 博客上提供的优秀图表清楚地展示了可用于在 Linux 上执行观察、性能分析和动态跟踪的数十个工具:
- LINUX 性能工具:http://www.brendangregg.com/Perf/linux_perf_tools_full.png
- LINUX 性能可观测性工具:http://www.brendangregg.com/Perf/linux_observability_tools.png
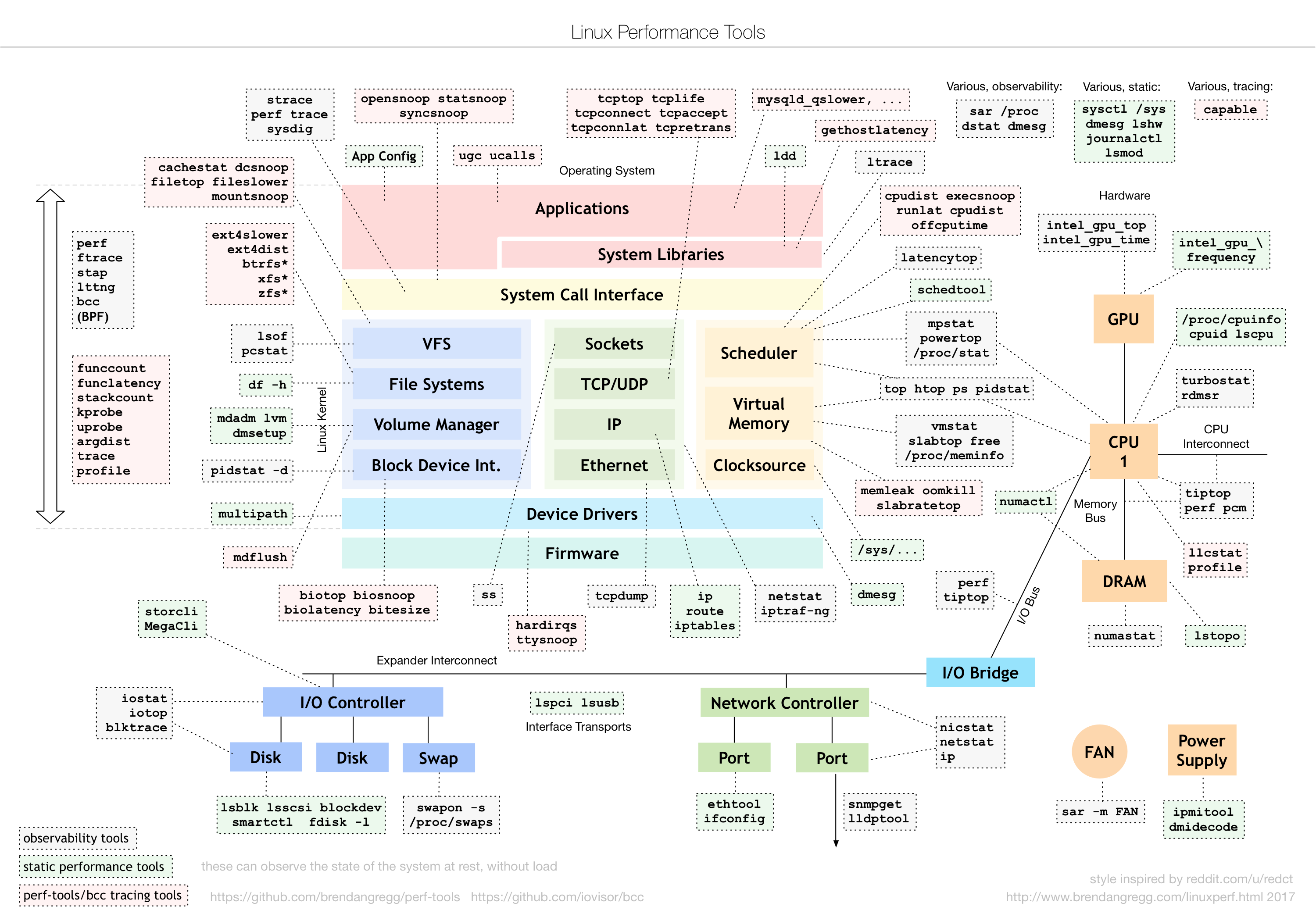{kind=link}
{kind=link}
由于其视觉效果,Brendan Gregg 的 Flame Graph 脚本也非常有趣;请查看 GitHub 存储库上的进一步阅读部分中的链接。
Brendan Gregg 还领导了一个名为 Perf-Tools 的项目的开发。 以下是该项目的一些内容:基于 Linuxperf_events*(*又名 perf)和 Ftrace 的性能分析工具。 几个非常有用的 shell 脚本包装器(在 Perf、Ftrace 和 JK 探测器上)组成了这些工具;一定要克隆 GitHub 存储库并试用它们。 (https://github.com/brendangregg/perf-tools。)
深入跟踪通常有一个令人向往的副作用,即让开发人员或测试人员发现性能瓶颈,以及调试系统级的延迟和问题。 Linux 有太多的框架和工具可用于跟踪,无论是在用户空间还是在内核级别;这里提到了一些更相关的框架和工具:
- 用户空间:
ltrace(1)(跟踪库 API)、strace(1)(跟踪系统调用;也可以尝试执行sudo perf trace)、LTTng-ust、uProbe。 - 内核空间:lttng,ftrace(加上几个前端,比如
tracecmd(1),kernelshark Guim),KProbe-(包括最高版本为 4.14 的内核),KretProbe;SystemTaprm)eBPF。
Linux 有一个非常丰富和强大的文件系统,称为进程procfs-proc。 它通常挂载在/proc下,并且包含伪文件和目录,这些伪文件和目录包含运行时生成的有关进程和内部信息的有价值的信息。 简而言之,cprofs 用作 UI 有两个关键目的:
- 它充当详细的进程、线程、操作系统和硬件信息的视口。
- 它用作查询和设置内核级可调参数(内核、调度、内存和网络参数的开关和值)的位置。
不厌其烦地学习和使用 Linux 的 nproc 文件系统是非常值得的。 几乎所有的用户空间监控和分析工具最终都是基于 procfs 的。 有关 GitHub 存储库的详细信息,请参阅进一步阅读部分中提供的链接。
在本节中,我们将简要列举我们认为是行业最佳实践的内容,尽管它们大多是通用的,因此范围很广;我们将特别从 Linux 系统程序员的角度来看待它们。
经验主义这个词(根据剑桥英语词典)的意思是基于亲身经历或看到的东西,而不是基于理论。 这可能是要遵循的关键原则。 古斯塔沃·杜阿尔特(Gustavo Duarte)的一篇引人入胜的文章(这里提到:https://www.infoq.com/news/2008/02/realitydrivendevelopment)写道:“*行动和实验是经验主义的基石。 没有人试图通过广泛的分析和丰富的文献来征服现实。 现实是通过实验被邀请进来的。 一家经验丰富的公司聘请实习生,并在一个夏天开发出一款产品,而不是苦恼于市场研究。 一家非经验型公司有 43 个人在计划一年的即兴设计。“*在整本书中,我们也一直试图有意识地遵循经验主义的方法;我们绝对敦促读者在设计和开发中培养和嵌入经验主义原则。
Frederick P Brooks 在 1975 年写了他著名的论文The Mythical Man-Month:Esays on Software Engineering,这本书被标榜为迄今为止关于软件项目管理最有影响力的书。 这并不奇怪:某些真理就是那样的真理。 以下是本书中的一些珍品:
- 计划扔掉一个;无论如何你都会扔掉的。
- 没有什么灵丹妙药。
- 好的烹饪需要时间。 如果让你等待,那是为了更好地服务你,取悦你。
- 不管分配了多少妇女,生育一个孩子都需要九个月的时间。
- 好的判断来自经验,经验来自错误的判断。
有趣的是,当然,历史悠久的 Unix 操作系统的设计哲学确实包含了伟大的设计原则,这些原则在 Linux 上至今仍然有效。 我们在第 1 章和Linux 系统体系结构的一节中介绍了这一点,Unix 哲学一言以蔽之。
现在让我们转到开发人员要牢记的更平凡但真正重要的事情。
我们建议七条规则如下:
- 规则 1:检查所有 API 的故障情况。
- 规则 2:使用(
-Wall -Wextra)上的警告进行编译,并尽可能消除所有警告。 - 规则 3:永远不要相信(用户)输入;验证它。
- 规则 4:不要在代码中使用断言。
- 规则 5:立即从代码库中删除未使用的(或死的)代码。
- 规则 6:彻底测试;目标是 100%的代码覆盖率。 花时间和精力学习使用强大的工具:安全内存检查器(Valgrind,杀菌器工具包)、静态和动态数据分析器、安全检查器(Checksec)、模糊器等(参见以下解释)。
- 规则 7:不要假设任何事情(假设,从u和Me得出ASS)。
这里有一些不遵守规则可能导致严重失败的例子:阿丽亚娜 5 号(Ariane 5)无人火箭在发射初期坠毁(1996 年 6 月 4 日);该漏洞最终被追溯到注册溢出问题,即单一类型转换错误(规则 5)。 骑士资本集团在 45 分钟内损失了 4.6 亿美元。 不要假设一页的大小。 使用getpagesize(2)系统调用或sysconf(3)来获取它。进一步沿着这些路线,请参阅题为低级软件设计的博客文章(在 GitHub 存储库的进一步阅读部分中有指向这些内容的链接)。
测试是一项关键活动;彻底和持续的测试(包括回归测试)会产生一个稳定的产品,工程团队和客户都对此充满信心。
这里有一个经常被忽视的事实:完整的代码复盖率测试是至关重要的! 为什么? 很简单--通常在从未经过实际测试的代码段中潜伏着隐藏的缺陷(错误处理就是典型的例子);但事实是,它们总有一天会受到攻击,这可能会导致可怕的失败。
话又说回来,不幸的是,测试只能揭示错误的存在,而不能揭示错误的存在;然而,良好和彻底的测试是绝对关键的。大多数执行的测试(编写的测试用例)往往是积极的测试用例;有趣的是,大多数软件(安全)和漏洞可能会在这种测试中逃脱。 负测试用例有助于捕获这些故障;称为模糊的一类软件测试在这方面非常有帮助。在不同的机器架构上测试代码也可以帮助暴露隐藏的缺陷。
使用 Linux 内核的cgroups组(控制组)技术来指定和约束资源分配和带宽。 现代 Linux 系统上的 cgroup 控制器包括以下内容:CPU(CPU 使用限制)、CPU 集(执行 CPU 亲和性的现代方式,将一组进程限制为一组 CPU)、blkio(I/O 限制)、设备(哪些进程可以使用哪些设备的限制)、Freezer(暂停/恢复任务执行)、内存(内存使用限制)、net_cls(网络数据包使用 classd 标记)、net_prio(限制每个接口的网络流量)、以及个命名空间。 perf_event(用于性能分析)。
不仅从需求角度,而且从安全角度来看,限制资源也很重要(想想恶意攻击者想出[D]DoS 攻击)。 顺便说一句,容器技术(本质上是一种轻量级虚拟化技术)是当今的热门话题,这在很大程度上是因为组合了两种已经充分发展的 Linux 内核技术:cgroup 和命名空间。
问:世界上最大的空间是多少? 答案:改进的空间!
一般说来,这应该总结了您在处理大型项目时应该持有的态度,并保持终身学习的主题,如 Linux。 我们再次敦促读者不仅要为了概念上的理解而阅读-这一点很重要!-而且还要亲手动手写代码。 犯错误,改正错误,并从中吸取教训。 为开源做贡献是一种很棒的方式。