在这一章中,我们将集中讨论编写设备驱动程序的一个非常关键的方面:什么是硬件中断,更重要的是,作为驱动程序作者,您具体如何处理它们。事实上,很大一部分外设(您有兴趣为其编写设备驱动程序)通过断言硬件中断来指示它们需要通过操作系统或驱动程序立即采取行动。实际上,这是一个电信号,最终会向处理器的控制单元发出警报(通常,该警报必须将控制重定向到受影响外设的中断处理程序例程,因为它需要立即引起注意)。
为了处理这些类型的中断,你需要了解它们如何工作的一些基本原理;也就是说,操作系统如何处理它们,最重要的是,作为驱动程序作者,您应该如何与它们合作。作为一个基于虚拟机的丰富操作系统,Linux 在处理中断时需要并使用一些抽象,这又增加了一层复杂性。因此,您将从学习如何处理硬件中断的(非常)基本工作流程开始。然后,我们将看看像您这样的驱动程序作者主要感兴趣的主题:如何准确地分配一个 IRQ 并编写处理程序例程本身的代码——有一些非常具体的注意事项!然后,我们将介绍更新的线程中断模型背后的动机和用法,启用/禁用特定的 IRQ,通过 proc 查看有关 IRQ 线路的信息,以及什么是上半部分和下半部分以及如何使用它们。我们将通过回答几个关于中断处理的常见问题来结束这一章。
在本章中,我们将涵盖以下主题:
-
硬件中断以及内核如何处理它们
-
分配硬件 IRQ
-
实现中断处理程序例程
-
使用线程中断模型
-
启用和禁用 IRQ
-
查看所有分配的中断(IRQ)线路
-
理解和使用上半部分和下半部分
-
回答了一些剩余的常见问题
我们开始吧!
本章假设您已经通过了前言部分来充分利用本书,并且已经适当地准备了一个运行 Ubuntu 18.04 LTS(或更高的稳定版本)的来宾 VM,并且安装了所有需要的软件包。如果没有,我强烈建议你先做这个。为了最大限度地利用这本书,我强烈建议您首先设置工作空间环境,包括克隆这本书的 GitHub 代码存储库,并以动手的方式进行处理。知识库可以在这里找到:https://github . com/PacktPublishing/Linux-内核-编程-第 2 部分。
许多(如果不是大多数)外围控制器使用硬件中断来通知操作系统或设备驱动程序需要一些(通常是紧急的)操作。典型的例子包括网络适配器(网卡)、块设备(磁盘)、USB 设备、AV 设备、人机接口设备 ( HIDs )如键盘、鼠标、触摸屏和视频屏幕、时钟/定时器芯片、DMA 控制器等。硬件中断背后的主要思想是效率。而不是不断轮询芯片(在电池供电的设备上),这会导致电池快速耗尽!),中断是使低级软件仅在需要时运行的手段。
这里有一个快速的硬件级概述(不做过多赘述):现代系统主板将会有某种中断控制器芯片,它通常被称为 x86 上的**【IO】【A】PIC**,是 IO-【高级】可编程中断控制器的缩写(x86 IO-APIC 的内核文档可以在https://www . kernel . org/doc/html/latest/x86/i386/IO-apic . html # IO-apic或 A【上找到 PIC(为了简单起见,我们将只使用通用术语 PIC)有一行连接到中央处理器的中断引脚。能够断言中断的板载外设将有一条到 PIC 的 IRQ 线。
IRQ is the common abbreviated term for Interrupt ReQuest*;* it denotes the interrupt line (or lines) that's allocated to a peripheral device.
假设有问题的外围设备是网络适配器(网卡),并且收到了网络数据包。(高度简化的)流程如下:
- 外围设备(网卡)现在需要发出(断言)硬件中断;因此,它在 PIC 上断言其线路(根据需要为低或高逻辑;所有这些都是硬件内部的)。
- PIC 在看到一条外围线路被置位后,将置位的线路值保存在寄存器中。
- 然后,PIC 置位中央处理器的中断引脚。
- 处理器上的控制单元在每一条机器指令运行后检查每个中央处理器上是否存在硬件中断。因此,如果硬件中断发生,它肯定会立即知道。然后,中央处理器将发出硬件中断(当然,中断可以被屏蔽;我们将在后面的启用和禁用 IRQs 部分更详细地讨论这一点。
- 操作系统上的低级(BSP/platform)代码会被钩住并做出反应(这通常是汇编级的代码);例如,在 ARM-32 上,硬件中断的低级 C 入口点是
arch/arm/kernel/irq.c:asm_do_IRQ()。 - 从这里,操作系统执行代码路径,最终调用驱动程序的注册中断处理程序例程,该中断将由该例程提供服务。(同样,我们无意在本章中关注硬件层,甚至硬件中断的特定于 arch 的平台级细节。作为驱动程序作者,我想重点谈谈什么与您相关–如何处理它们!).
硬件中断实际上是 Linux 操作系统的重中之重:它抢占当前正在运行的任何东西——无论是用户还是内核空间代码路径——以便运行。话虽如此,稍后,我们将会看到,在现代 Linux 内核上,有可能采用一种改变事物的线程中断模型;请耐心一点,我们会到达那里的!
现在,让我们离题。我们提到了一个典型外围设备的例子,网络控制器(或网卡),基本上是说它通过硬件中断来服务包的发送和接收(发送/接收)。过去确实如此,但现代高速网卡(通常为 10 Gbps 或更高)并非总是如此。为什么呢?答案很有意思:中断会字面上中断处理器的极端速度会导致系统陷入一种被称为活锁的有问题的情况;无法应对极高中断需求的情况!与死锁一样(涵盖在第 6 章、内核同步–第 1 部分中),系统实际上倾向于冻结或挂起。那么,关于活锁,我们该怎么做呢?大多数高端现代网卡支持轮询操作模式;Linux 等现代操作系统有一个名为 NAPI 的网络接收路径基础设施(注意,这与婴儿无关——这是新 API 的缩写),允许驱动程序根据需求在中断和轮询模式之间切换,从而更有效地处理网络数据包(在接收路径上)。
既然我们已经介绍了硬件中断,那么让我们来了解一下作为驱动程序作者,您如何使用它们。本章剩余的大部分章节都将讨论这个问题。让我们从学习如何分配或注册一个 IRQ 线路开始。
通常,编写设备驱动程序的一个关键部分实际上是捕获和处理硬件中断的工作,您编写驱动程序的芯片会发出硬件中断。你是怎么做到的?问题是硬件中断从中断控制器芯片路由到中央处理器的方式差异很大;它非常特定于平台。好消息是,Linux 内核提供了一个抽象层来抽象掉所有硬件级别的差异;它被称为通用中断(或 IRQ)处理层。本质上,它在幕后执行所需的工作,并公开完全通用的 API 和数据结构。因此,至少在理论上,您的代码可以在任何平台上工作。这个通用 IRQ 层当然是我们,主要作为驱动作者,应该使用的;我们使用的所有 API 和助手例程都属于这一类。
回想一下,至少最初是核心内核处理中断(正如我们在上一节中所了解的)。然后它指的是链表的数组(这是 Linux 上非常常见的数据结构;这里,数组的索引是 IRQ 号)来计算要调用的驱动级函数。(没有过多赘述,列表上的节点是 IRQ 描述符结构;也就是include/linux/interrupt.h:struct irqaction。)但是,如何将驱动程序的中断处理函数放到这个列表中,以便当设备发生中断时内核可以调用它呢?啊,这就是关键:你向内核注册它。现代 Linux 至少提供了四种方法(API),您可以通过这些方法注册对中断线路的兴趣,如下所示:
request_irq()devm_request_irq()request_threaded_irq()devm_request_threaded_irq()(推荐!)
让我们一个接一个地解决它们(有一些额外的例程是它们的微小变化)。在此过程中,我们将查看一些驱动程序的一些代码,并学习如何处理线程中断。有很多要学习和做的事情;让我们继续吧!
就像我们看到的输入/输出内存和输入/输出端口一样,IRQ 线路被认为是内核负责的资源。request_irq()内核 API 可以被认为是驱动程序作者注册他们对 IRQ 的兴趣并将该资源分配给他们自己的传统方式,从而允许内核在中断异步到达时调用他们的处理程序。
It might strike you that this discussion seems very analogous to user space signal handling. There, we call the sigaction(2) system call to register interest in a signal. When the signal (asynchronously) arrives, the kernel invokes the registered signal handler (user mode) routine!
这里有一些关键的区别。首先,用户空间信号处理器不是中断;第二,用户空间信号处理器纯粹在非特权用户模式下运行;相反,驱动程序的内核空间中断处理程序以内核权限在中断的上下文中(异步)运行!
此外,有些信号实际上是处理器异常引发的软件副作用;广义来说,当出现非法情况时,处理器会引发故障、陷阱或中止,它必须“陷阱”(切换)到内核空间来处理。试图访问无效页面(或没有足够权限)的进程或线程会导致 MMU 引发故障或中止;这导致操作系统故障处理代码在进程上下文上(即在current上)发出SIGSEGV信号!然而,引发某种异常并不总是意味着有问题——系统调用只不过是操作系统的陷阱;也就是说,编程异常(通过 x86/ARM 上的syscall / SWI)。
内核源代码中的以下注释(在下面的代码片段中部分再现)告诉我们更多关于request[_threaded]_irq() API 的功能:
// kernel/irq/manage.c:request_threaded_irq()
[...]
* This call allocates interrupt resources and enables the
* interrupt line and IRQ handling. From the point this
* call is made your handler function may be invoked.实际上,request_irq()只是request_threaded_irq() API 的一个薄薄的包装;我们将在后面讨论这个 API。request_irq()原料药的签名如下:
#include <linux/interrupt.h>
int __must_check
request_irq(unsigned int irq, irq_handler_t (*handler_func)(int, void *), unsigned long flags, const char *name, void *dev);始终包括linux/interrupt.h头文件。让我们逐一检查request_irq()的每个参数:
-
int irq:这是您试图注册或陷阱/钩入的 IRQ 线路。这意味着当这个特定的中断触发时,您的中断处理函数(第二个参数,handler_func)被调用。关于irq的问题是:我怎么知道 IRQ 号是什么?我们在第 3 章处理硬件输入/输出内存中,在(真正关键的)获取设备资源部分解决了这个一般性问题。快速重申一下,一条 IRQ 线是一个资源,这意味着它是以通常的方式获得的——在现代嵌入式系统上,它是通过解析设备树 ( DT )获得的;旧的方法是硬编码特定于板的源文件中的值(放松,您将在 IRQ 分配-现代方式-托管中断工具部分看到一个通过 DT 查询 IRQ 行的例子)。在个人电脑类型的系统中,您可能不得不求助于询问设备所在的总线(对于冷设备)。在这里,PCI 总线(和朋友)很常见。内核甚至提供了 PCI 助手例程,您可以使用它来查询资源,从而找到分配的 IRQ 行。 -
irq_handler_t (*handler_func)(int, void *):这个参数是一个指向中断处理函数的指针(在 C 语言中,只要提供函数名就足够了)。当然,这是硬件中断触发时异步调用的代码。它的工作是服务中断(稍后将详细介绍)。内核如何知道它在哪里?回想一下struct irqaction,它是由request_irq()例程填充的结构。其中一个成员是handler,设置为第二个参数。 -
unsigned long flags:这是request_irq()的第三个参数,是标志位掩码。当设置为零时,它实现其默认行为(我们将在设置中断标志部分讨论一些关键的中断标志)。 -
const char *name:这是拥有中断的代码/驱动程序的名称。通常,这被设置为设备驱动程序的名称(这样,/proc/interrupts可以显示使用中断的驱动程序的名称;这是最右边的一栏;详情见查看所有分配的中断(IRQ) 行部分。) -
void *dev:这是request_irq()的第五个也是最后一个参数,允许你将任何你想要的数据项(通常称为 cookie)传递给中断处理程序例程,这是一种常见的软件技术。在第二个参数中,您可以看到中断处理程序例程属于void *类型。这是传递该参数的地方。 大多数现实世界的驱动程序都有某种上下文或私有数据结构,它们在其中存储所有必需的信息。此外,这种上下文结构通常嵌入到驱动程序的设备(通常由子系统或驱动程序框架专门化)结构中。事实上,内核通常会帮助您这样做;例如,网络驱动程序使用alloc_etherdev()将其数据嵌入struct net_device,平台驱动程序将其数据嵌入struct platform_device的platform_device.device.platform_data成员,I2C 客户端驱动程序使用i2c_set_clientdata()助手将其私有/上下文数据“设置”到i2c_client结构,等等。
Note that when you're using a shared interrupt (we'll explain this shortly), you must initialize this parameter to a non-NULL value (otherwise, how will free_irq() know which handler to free?). If you do not have a context structure or anything specific to pass along, passing the THIS_MODULE macro here will do the trick (assuming you're writing the driver using the loadable kernel module framework; it's the pointer to your kernel module's metadata structure; that is, struct module).
从request_irq()返回的值是一个整数,按照通常的0/-E内核惯例(参见配套指南 Linux 内核编程- 第 4 章、编写你的第一个内核模块–LKMs 第 1 部分、0/-E 返回惯例一节),成功时为0,失败时为负errno值。正如__must_check编译器属性明确规定的那样,您当然需要检查故障情况(这在任何情况下都是很好的编程实践)。
Linux Driver Verification (LDV) project: In the companion guide Linux Kernel Programming, Chapter 1 - Kernel Workspace Setup, in the section The LDV - Linux Driver Verification - project, we mentioned that this project has useful "rules" with respect to various programming aspects of Linux modules (drivers, mostly) as well as the core kernel.
With regard to our current topic, here's one of the rules, a negative one, implying that you cannot do this: "Making no delay when probing for IRQs" (http://linuxtesting.org/ldv/online?action=show_rule&rule_id=0037). This discussion really applies to x86[_64] systems. Here, in some circumstances, you might need to physically probe for the correct IRQ line number. For this purpose, the kernel provides an "autoprobe" facility via the probe_irq_{on|off}() APIs (probe_irq_on() returns a bitmask of potential IRQ lines that can be used). The thing is, a delay is required between the probe_irq_on() and probe_irq_off() APIs; not invoking this delay can cause issues. The LDV page mentioned previously covers this in some detail, so do take a look. The actual API used to perform the delay is typically udelay(). Worry not, we cover it (and several others) in detail in Chapter 5, Working with Kernel Timers, Threads, and Workqueues in the section Delaying for a given time in the kernel.
在驱动程序的代码中,你应该在哪里调用request_irq() API(或者它的等价物)?对于几乎所有坚持现代 Linux 设备模型 ( LDM )的现代驱动程序来说,probe()方法是正确的。
相反,当卸载驱动程序或拆卸设备时,remove()(或disconnect())方法是您应该调用逆向例程–free_irq()-将 IRQ 线路释放回内核的正确位置:
void *free_irq(unsigned int, void *);free_irq()的第一个参数是释放回内核的 IRQ 线。第二个参数也是传递给中断处理程序的相同值(通过最后一个参数传递给request_irq(),因此您通常必须用设备结构指针(嵌入您的驱动程序上下文或私有数据结构)或THIS_MODULE宏填充它。
返回值是成功时作为request_irq()例程的第四个参数传递的设备名称参数(是的,它是一个字符串),失败时作为NULL参数传递的。
作为驱动程序作者,您务必注意以下几点:
- 当共享 IRQ 线路时,在调用
free_irq()之前,禁用板上的中断 - 仅从流程上下文调用它
此外,free_irq()只有在该 IRQ 行的任何和所有执行中断完成时才会返回。
在我们看一些代码之前,我们需要简单介绍两个额外的领域:中断标志和电平/边沿触发中断的概念。
当使用{devm_}request{_threaded}_irq()API 分配中断(IRQ 线路)时(我们将很快介绍request_irq()的变体),您可以指定某些中断标志,这些标志将影响中断线路的配置和/或行为。负责这个的参数是unsigned long flags(正如我们在中提到的,用 request_irq() 部分分配您的中断处理程序)。重要的是要意识到这是一个位掩码;您可以按位“或”几个标志,以获得它们的组合效果。标志值大致分为几类:与 IRQ 线路共享、中断线程和暂停/恢复行为有关的标志。它们都在IRQF_foo格式的linux/interrupt.h标题中。以下是一些最常见的例子:
IRQF_SHARED:这样可以让你在几个设备之间共享 IRQ 线(PCI 总线上的设备需要)。IRQF_ONESHOT:hard rq 处理程序执行完毕后,IRQ 不启用。该标志通常由线程中断使用(包含在使用线程中断模型部分),以确保在线程处理器完成之前,IRQ 保持禁用状态。
The __IRQF_TIMER flag is a special case. It's used to mark the interrupt as a timer interrupt. As seen in the companion guide Linux Kernel Programming, Chapter 10, The CPU Scheduler - Part 1, and Chapter 11, The CPU Scheduler - Part 2, when we looked at CPU scheduling, that the timer interrupt fires at periodic intervals and is responsible for implementing the kernel's timer/timeout mechanisms, scheduler-related housekeeping, and so on.
定时器中断标志由这个宏指定:
#define IRQF_TIMER(__IRQF_TIMER | IRQF_NO_SUSPEND | IRQF_NO_THREAD)除了指定它被标记为定时器中断(__IRQF_TIMER)之外,IRQF_NO_SUSPEND标志还指定即使系统进入挂起状态,中断也保持启用状态。此外,IRQF_NO_THREAD标志指定此中断不能使用线程模型(我们将在使用线程中断模型一节中讨论这一点)。
我们还可以使用其他几个中断标志,包括IRQF_PROBE_SHARED、IRQF_PERCPU、IRQF_NOBALANCING、IRQF_IRQPOLL、IRQF_FORCE_RESUME、IRQF_EARLY_RESUME和IRQF_COND_SUSPEND。我们在这里不做明确的介绍(看一下linux/interrupt.h头文件中简要描述它们的注释头)。
现在,让我们简单了解一下什么是电平触发和边沿触发中断。
当外设断言中断时,中断控制器被触发以锁存该事件。它用来触发中央处理器硬件中断的电气特性分为两大类:
- 电平触发:电平变化(从非激活变为激活或置位)时触发中断;在它被取消断言之前,该行保持在断言状态。即使在您的处理程序返回之后也是如此;如果该行仍然被断言,您将再次得到中断。
- 边沿触发:当电平从非活动变为活动时,中断仅触发一次。
此外,中断可以在上升沿或下降沿(时钟)触发高电平或低电平。内核允许通过附加标志进行配置和指定,如IRQF_TRIGGER_NONE、IRQF_TRIGGER_RISING、IRQF_TRIGGER_FALLING、IRQF_TRIGGER_HIGH、IRQF_TRIGGER_LOW等。外围芯片的这些低级电气特性通常在 BSP 级代码中预先配置,或者在 DT 中指定。
电平触发中断迫使您理解中断源,以便您可以正确取消断言(或确认)它(在共享 IRQ 的情况下,在检查它是否适合您之后)。通常,这是您在维修时必须做的第一件事;否则,它会一直开火。例如,如果中断是在某个设备寄存器达到值0xff时触发的,那么驱动程序必须将寄存器设置为,比如说,0x0后才能解除置位!这很容易看出,但很难正确处理。
另一方面,边沿触发中断很容易处理,因为不需要了解中断源,但也很容易错过!一般来说,固件设计者使用边沿触发中断(尽管这不是规则)。同样,这些特性实际上处于硬件/固件的边界。您应该研究为您编写驱动程序的外设提供的数据表和任何相关文档(如原始设备制造商的应用笔记)。
You might by now realize that writing a device driver (well!) requires two distinct knowledge domains. First, you'll need to have a deep understanding of the hardware/firmware and how it works - it's theory of operation (TOO), its control/data planes, register banks, I/O memory, and so on. Second, you'll need to have a deep (enough) understanding of the OS (Linux) and its kernel/driver framework, how Linux works, memory management, scheduling, interrupt models, and so on. Also, you need to understand the modern LDM and kernel driver frameworks and how to go about debugging and profiling them. The better you get at these things, the better you'll be at writing the driver!
我们将学习如何在查看所有分配的(IRQ)线路部分找到使用的触发类型。查看进一步阅读部分,了解更多关于 IRQ 边沿/电平触发的链接。
现在,让我们继续看一些有趣的东西。为了帮助您吸收到目前为止所学的知识,我们将从一个 Linux 网络驱动程序中查看一些小的代码片段!
是时候看看代码了。让我们看一下英特尔 IXGB 网络适配器驱动程序(驱动 82597EX 系列中的几个英特尔网络适配器)的一小部分代码。在市场上的众多产品中,英特尔拥有一个名为 IXGB 网络适配器的产品线。控制器是英特尔 82597EX 这些通常是用于服务器的 10 千兆位以太网适配器(英特尔关于该控制器的产品简介可在https://www . Intel . com/img/PDF/prod brief/pro 10g be _ LR _ SA-ds . PDF)中找到:

Figure 4.1 – The Intel PRO/10GbE LR server adapter (IXGB, 82597EX) network adapter
首先,让我们看看它调用request_irq()来分配 IRQ 行:
// drivers/net/ethernet/intel/ixgb/ixgb_main.c
[...]int
ixgb_up(struct ixgb_adapter *adapter)
{
struct net_device *netdev = adapter->netdev;
int err, irq_flags = IRQF_SHARED;
[...]
err = request_irq(adapter->pdev->irq, ixgb_intr, irq_flags,
netdev->name, netdev);
[...]在前面的代码片段中,您可以看到驱动程序调用request_irq() API 在网络驱动程序的ixgb_up()方法中分配这个中断。当网络接口打开时(通过网络实用程序,如ip(8)或(较旧的)ifconfig(8),调用该方法。让我们依次看看传递到request_irq()这里的参数:
- 这里,从
pci_dev结构的irq成员中查询 IRQ 号——第一个参数(因为该设备位于 PCI 总线上)。pdev结构指针位于名为ixgb_adapter的驱动程序上下文(或私有)元数据结构中。它的成员叫做irq。 - 第二个参数是指向中断处理程序例程的指针(它通常被称为 hardirq 处理程序;我们将在后面更详细地讨论这一切);这里,是名为
ixgb_intr()的函数。 - 第三个参数是
flags位掩码。您可以看到,在这里,驱动程序指定该中断是共享的(通过IRQF_SHARED标志)。这条总线上的设备共享它们的中断线路是 PCI 规范的一部分。这意味着驱动程序将需要验证中断确实是为它准备的。它在中断处理程序中这样做(它通常是非常特定于硬件的代码,通常检查给定寄存器的某个期望值)。 - 第四个参数是处理这个中断的驱动程序的名称。它是通过专门的
net_device结构的name成员获得的(这个驱动程序在其探测方法ixgb_probe()中调用register_netdev(),已经将这个成员注册到内核的网络框架中)。 - 第五个参数是传递给中断处理程序例程的值。正如我们之前提到的,它(再次)是嵌入其中的专用
net_device结构(内部有驱动程序的上下文结构(struct ixgb_adapter)!).
反之,当网络接口关闭时,内核调用ixgb_down()方法。出现这种情况时,它会禁用 NAPI 并释放带有free_irq()的 IRQ 线路:
void
ixgb_down(struct ixgb_adapter *adapter, bool kill_watchdog)
{
struct net_device *netdev = adapter->netdev;
[...]
napi_disable(&adapter->napi);
/* waiting for NAPI to complete can re-enable interrupts */
ixgb_irq_disable(adapter);
free_irq(adapter-pdev->irq, netdev);
[...]既然你已经学会了如何通过request_irq()陷入硬件中断,我们需要了解一些关于编写中断处理程序例程本身代码的要点,这是处理中断的实际工作执行的地方。
通常情况下,中断是硬件外设通知系统(实际上是驱动程序)数据可用并且应该获取数据的方式。这就是典型的驱动程序所做的:它们从设备缓冲区(或端口,或其他任何地方)获取输入数据。不仅如此,还有可能存在想要这些数据的用户模式进程(或线程)。因此,他们很可能已经打开了设备文件并发出了read(2)(或等效的)系统调用。这使得他们目前正在阻止(睡眠)这一事件;也就是说,来自设备的数据。
On detecting that data currently isn't available, the driver's read method typically puts the process context to sleep using one of the wait_event*() APIs.
因此,一旦驱动程序的中断处理程序将数据提取到某个内核缓冲区,它通常会唤醒睡眠中的读取器。他们现在运行驱动程序的读取方法(在进程上下文中),提取数据,并根据需要将其传输到用户空间缓冲区。
本节分为两大部分。首先,我们将了解在中断处理程序中我们可以做什么和不可以做什么。然后,我们将介绍编写代码的机制。
中断处理程序例程是典型的 C 代码,有一些警告。关于硬件中断处理程序的设计和实现的几个要点如下:
- 处理程序在中断上下文中运行,所以不要阻塞:首先,这个代码总是在中断上下文中运行;也就是说,原子上下文。在可抢占的内核上,抢占是禁用的,所以关于它能做什么和不能做什么有一些限制。特别是,它不能做任何直接或间接调用调度程序(
schedule())的事情! 实际上,您无法执行以下操作:- 在内核和用户空间之间传输数据,因为这可能会导致页面错误,这在原子上下文中是不允许的。
- 在内存分配中使用
GFP_KERNEL标志。您必须使用GFP_ATOMIC标志,这样分配才不会阻塞-分配要么成功,要么立即失败。 - 调用任何阻塞的应用编程接口(也就是说,调用
schedule())。换句话说,它必须是纯粹的非阻塞代码路径。(我们在配套指南 Linux 内核编程- 第 8 章、模块作者的内核内存分配–第 1 部分中的从不在中断或原子上下文中休眠一节中详细介绍了原因)。
- 中断屏蔽:默认情况下,当您的中断处理程序正在运行时,您的处理程序正在执行的本地 CPU 内核上的所有中断都被屏蔽(禁用),并且您正在处理的特定中断在所有内核上被屏蔽**。因此,您的代码本质上是可重入安全的。** *** **保持快速!:你正在编写的代码会字面上打断其他流程——系统在你粗暴打断它之前正在运行的其他“业务”;因此,您必须尽可能快地做需要做的事情,然后返回,允许中断的代码路径继续。重要的系统软件指标包括最差情况中断长度和最差情况中断禁用时间(我们将在本章末尾的测量指标和延迟部分对此进行更多介绍)。
**这些要点非常重要,值得更多的细节,因此我们将在下面的小节中更全面地介绍它们。
这实际上归结为一个事实,当你处于中断或原子环境中时,不要做任何会称之为schedule() *的事情。*现在,让我们看看如果我们的中断处理程序的伪代码看起来像这样会发生什么:
my_interrupt()
{
struct mys *sp;
ack_intr();
x = read_regX();
sp = kzalloc(SIZE_HWBUF, GFP_KERNEL);
if (!sp)
return -ENOMEM;
sp = fetch_data_from_hw();
copy_to_user(ubuf, sp, count);
kfree(sp);
}你在这里发现了巨大的潜在(虽然可能还是微妙的)bug 吗?(在继续下一步之前,花点时间找出它们。)
首先,用GFP_KERNEL标志调用kzalloc()可能会导致其内核代码调用schedule()!如果是这样,这将导致“哎呀”,这是一个内核错误。在典型的生产环境中,这会导致内核死机(因为在生产中名为panic_on_oops的系统通常设置为1;做sysctl kernel.panic_on_oops会显示当前设置)。接下来,copy_to_user()调用可能导致页面错误,因此需要上下文切换,这当然会调用schedule();这在原子或中断上下文中是不可能的——同样是一个严重的错误!
因此,更一般地说,让您的中断处理程序调用一个函数a(),其中a()的调用链如下:
a() -- b() -- c() -- [...] -- g() -- schedule() -- [...]在这里,你可以看到调用a()最终导致schedule()被调用,正如我们刚才指出的,这将导致一个“哎呀”,这是一个内核错误。所以,这里的问题是,你这个驱动开发者,怎么知道当你调用a()时,会导致schedule()被调用?关于这一点,您需要了解和利用几点:
- (如配套指南 Linux 内核编程- 第 8 章、模块作者的内核内存分配–第 1 部分中所述)您可以提前发现您的内核代码是否会进入原子或中断上下文的一种方法是直接查看内核。当您配置内核时(同样,如配套指南 *Linux 内核编程中所见,*从 Linux 内核编程- 第 2 章、从源代码构建 5.x Linux 内核–第 1 部分中回忆
make menuconfig,您可以打开内核配置选项来帮助您准确发现这种情况。看看内核黑客/锁定调试菜单。在那里,您将在原子部分检查中找到一个名为 Sleep 的布尔可调参数。打开它!
The config option is named CONFIG_DEBUG_ATOMIC_SLEEP; you can always grep your kernel's config file for it. As seen in the companion guide Linux Kernel Programming - Chapter 5, Writing Your First Kernel Module - LKMs Part 2, in the Configuring a debug kernel section, we specified that this option should be turned ON!
- 接下来(这个有点迂腐,但是会对你有帮助!),养成查找相关函数的内核文档的习惯(更好的方法是,简单地查找它的代码)。这是一个阻塞调用的事实通常会在注释头中记录或指定。
- 内核有一个名为
might_sleep()的助手宏;对于这些情况,它是一个有用的调试工具!下面的截图(来自内核源码,include/linux/kernel.h)解释的很清楚:

Figure 4.2 – The comment for might_sleep() is helpful
同样,内核提供了帮助宏,如might_resched()、cant_sleep()、non_block_start()、non_block_end()等。
- 为了提醒您,我们在配套指南 Linux 内核编程、 第 8 章,模块作者的内核内存分配第 1 部分**处理 GFP 标志一节(以及其他部分)中提到了几乎相同的事情——关于不在原子上下文中阻塞。此外,我们还向您展示了有用的 LDV 项目(在配套指南 Linux 内核编程、第 1 章内核工作空间设置中的LDV-Linux 驱动程序验证项目一节中提到)如何捕获并修复内核和驱动程序模块代码中的几个此类违规。
在这一节的开始,我们提到,通常,休眠的用户空间读取器会在数据到达时阻塞。它的到达通常由硬件中断发出信号。然后,您的中断处理程序例程将数据提取到内核 VAS 缓冲区,并唤醒睡眠者。嘿,这不是不允许的吗?否–本质上wake_up*()API 是非阻塞的。你需要明白的是,它们只会将进程(或线程)的状态从睡眠状态(T1)切换到清醒状态,准备运行(T2)。这不会调用计划程序;内核将在下一个机会点这样做(我们在配套指南 Linux 内核编程、 第 10 章、CPU 调度程序–第 1 部分、以及 第 11 章、CPU 调度程序–第 2 部分)中讨论了 CPU 调度。
回想一下,中断控制器芯片(PIC/GIC)将有一个屏蔽寄存器。OS 可以对其进行编程根据需要屏蔽或阻塞硬件中断(当然,有些中断可能是不可屏蔽的;不可屏蔽中断 ( NMI )是我们在本章后面讨论的一个典型案例。
不过,重要的是要认识到,尽可能保持中断启用(不屏蔽)是衡量操作系统质量的一个重要标准!为什么?如果中断被阻止,外围设备将无法响应,系统性能将会滞后或受到影响(只需按下并释放一个键盘键就会导致两个硬件中断)。您必须尽可能长时间地启用中断。使用 spinlock 锁定将导致中断和抢占被禁用!保持关键部分的简短(我们将在本书的最后两章深入讨论锁定)。
接下来,谈到 Linux 操作系统上的默认行为,当硬件中断发生并且该中断没有被屏蔽时(总是默认的),假设它是 IRQn(其中 n 是 IRQ 号),内核确保当它的中断(hardirq)处理程序执行时,处理程序正在执行的本地 CPU 内核上的所有中断都被禁用,并且所有 CPU 上的 IRQn 都被禁用。因此,您的处理程序代码本质上是可重入安全的。这很好,因为它意味着您永远不必担心以下问题:
- 屏蔽会打断你自己
- 何时在 CPU 内核上自动运行,直到完成且没有中断
As we'll see later, a bottom-half can still be interrupted by a top-half, thus necessitating locking.
例如,当 IRQn 在 CPU 核心 1 上执行时,除了核心 1 之外,其他中断在所有 CPU 核心上保持启用(未屏蔽)。因此,在多核系统硬件上,中断可以在不同的 CPU 内核上并行运行。这很好,只要他们不互相踩对方的脚趾,就全球数据而言!如果他们这样做了,您将不得不使用锁定,这将在本书的最后两章中详细介绍。
再者,在 Linux 上,所有中断都是对等的,所以它们之间没有优先级;换句话说,它们都以相同的优先级运行。只要它没有被屏蔽,任何硬件中断都可以在任何时间点中断系统;中断甚至可以中断中断!然而,他们通常不做后者。这是因为,正如我们刚刚了解到的,当一个中断 IRQn 在一个 CPU 内核上运行时,该内核上的所有中断都被禁用(屏蔽),并且 IRQn 被全局禁用(跨所有内核),直到它完成;唯一的例外是 NMI。
中断是指:它中断机器的正常工作;这是一个必须容忍的烦恼。必须保存上下文,必须执行处理程序(连同下半部分,我们将在理解和使用上半部分和下半部分部分中讨论),然后必须将上下文恢复到中断的内容。所以,你得到了这样的想法:这是一个关键的代码路径,所以不要费力——要快速和无阻塞!
这也带来了一个问题,多快才算快?答案当然是依赖于平台的,但一个启发是这样的:尽可能快地进行中断处理,在几十微秒内。如果持续超过 100 微秒,那么就需要替代策略。我们将在本章后面介绍当这种情况发生时您可以做什么。
关于我们简单的my_interrupt()伪代码片段(显示在不要阻塞–发现可能阻塞的代码路径部分),首先,问问你自己,我真的必须在关键的非阻塞的需要快速执行的代码路径(如中断处理程序)中分配内存吗?你能设计模块/驱动程序来更早地分配内存(并且只使用指针)吗?
同样,现实情况是,有时需要做大量的工作来正确地服务中断(网络/块驱动程序就是很好的例子)。我们将介绍一些我们可以用来处理这个问题的典型策略。
现在,让我们快速学习它的机械部分。硬件中断处理程序例程(通常称为 hardirq 例程)的签名如下:
static irqreturn_t interrupt_handler(int irq, void *data);当您的驱动程序(通过request_irq()或朋友应用编程接口)感兴趣的硬件 IRQ 被触发时,内核的通用 IRQ 层会调用中断处理程序例程。它接收两个参数:
- 第一个参数是 IRQ 行(整数)。触发此事件会导致调用此处理程序。
- 第二个参数是通过最后一个参数传递给
request_irq()的值。正如我们前面提到的,通常是驱动程序的专用设备结构嵌入了驱动程序上下文或私有数据。正因为如此,它的数据类型是通用的void *,允许request_irq()传递任何类型,在处理程序例程中适当地进行类型转换并使用它。
处理程序是常规的 C 代码,但是有我们在前面部分提到的所有警告!注意遵循这些指导方针。虽然细节是特定于硬件的,但通常情况下,中断处理程序的首要责任是清除板上的中断,实际上是确认它并尽可能多地告诉 PIC。这通常通过将一些特定位写入电路板或控制器上的特定硬件寄存器来实现;请阅读您的特定芯片、芯片组或硬件设备的数据手册,找出答案。在这里,in_irq()宏将返回true,通知您您的代码当前处于 hardirq 上下文中。
处理程序完成的其余工作显然是非常特定于设备的。例如,输入驱动程序会想要扫描刚刚从某个寄存器或外围存储器位置按下或释放的键码(或触摸屏坐标或鼠标键/移动或其他任何东西),并可能将其保存在某个存储器缓冲区中。或者,它可能会立即将它向上传递到堆栈上方的通用输入层。我们不会试图在这里深究这些细节。同样,驱动程序框架是您需要了解的驱动程序类型;这超出了本书的范围。
从 hardirq 处理程序返回的值是多少?irqreturn_t返回值为enum,如下所示:
// include/linux/irqreturn.h
/**
* enum irqreturn
* @IRQ_NONE interrupt was not from this device or was not handled
* @IRQ_HANDLED interrupt was handled by this device
* @IRQ_WAKE_THREAD handler requests to wake the handler thread
*/
enum irqreturn {
IRQ_NONE = (0 0),
IRQ_HANDLED = (1 0),
IRQ_WAKE_THREAD = (1 1),
};
前面的注释标题清楚地指出了它的含义。本质上,通用的 IRQ 框架坚持如果你的驱动处理了中断,你就返回IRQ_HANDLED值。如果中断不是你的或者你不能处理它,你应该返回IRQ_NONE值。(这也有助于内核检测虚假中断。如果你不知道这是否是你的打扰,只需返回IRQ_HANDLED。)下面我们来看看IRQ_WAKE_THREAD是如何使用的。
现在,让我们再看一些代码!在下一节中,我们将检查两个驱动程序的硬件中断处理程序代码(我们在本章和上一章中已经看到了这些代码)。
在前一章第三章使用硬件 I/O 内存中,在 A PIO 示例–i8042部分,我们学习了 i8042 设备驱动程序如何使用一些非常简单的助手例程在 I 8042 芯片的 I/O 端口上执行 I/O(读/写)(这通常是 x86 系统上的键盘/鼠标控制器)。下面的代码片段显示了它的硬件中断处理程序例程的一些代码;您可以清楚地看到它同时读取状态和数据寄存器:
// drivers/input/serio/i8042.c
/*
* i8042_interrupt() is the most important function in this driver -
* it handles the interrupts from the i8042, and sends incoming bytes
* to the upper layers.
*/
static irqreturn_t i8042_interrupt(int irq, void *dev_id)
{
unsigned char str, data;
[...]
str = i8042_read_status();
[...]
data = i8042_read_data();
[...]
if (likely(serio && !filtered))
serio_interrupt(serio, data, dfl);
out:
return IRQ_RETVAL(ret);
}在这里,serio_interrupt()调用是这个驱动程序如何将它从硬件读取的数据传递到上面的“输入”层,后者将进一步处理它,并最终准备好供用户空间进程使用。(请看本章末尾的提问部分;您可以尝试的练习之一是编写一个简单的“键记录器”设备驱动程序。)
我们再来看一个例子。在这里,我们看一下英特尔 IXGB 以太网适配器设备驱动程序的硬件中断处理程序,我们之前提到过:
// drivers/net/ethernet/intel/ixgb/ixgb_main.c
static irqreturn_t
ixgb_intr(int irq, void *data)
{
struct net_device *netdev = data;
struct ixgb_adapter *adapter = netdev_priv(netdev);
struct ixgb_hw *hw = &adapter-hw;
u32 icr = IXGB_READ_REG(hw, ICR);
if (unlikely(!icr))
return IRQ_NONE; /* Not our interrupt */
[...]
if (napi_schedule_prep(&adapter-napi)) {
[...]
IXGB_WRITE_REG(&adapter-hw, IMC, ~0);
__napi_schedule(&adapter-napi);
}
return IRQ_HANDLED;
}在前面的代码片段中,请注意驱动程序如何从作为第二个参数接收的net_device结构(网络设备的专用结构)获得对其私有(或上下文)元数据结构(struct ixgb_adapter)的访问;这是非常典型的。(这里,用于从通用net_device结构中提取驾驶员私有结构的netdev_priv()助手有点类似于众所周知的container_of()助手宏。事实上,这个帮手也经常被用在类似的情况下。)
接下来,它通过IXGB_READ_REG()宏执行外围输入/输出内存读取(它使用 MMIO 方法——关于 MMIO 的详细信息,请参见上一章;IXGB_READ_REG()是一个宏,调用我们在上一章中介绍的readl()应用编程接口——执行 32 位 MMIO 读取的旧风格例程。不要错过这里的关键点:这是驱动程序如何确定中断是否是为它准备的,因为,回想一下,这是一个共享中断!如果这是为了它(可能的情况),它继续它的工作;由于这个适配器支持 NAPI,驱动程序现在安排轮询的 NAPI 读取,在网络数据包进入时吸收它们,并将其发送到网络协议栈进行进一步处理(嗯,其实没那么简单;实际的内存传输工作将通过 DMA 执行)。
现在,一个转移但很重要的转移:你需要学习如何以现代方式分配 IRQ 线路——通过devm_*API。这就是所谓的管理方法。
许多现代驱动程序出于各种目的使用内核的 devres 或托管 API 框架。现代 Linux 内核中的托管 API 为您提供了不必担心释放您分配的资源的优势(我们已经介绍了其中的一些,包括devm_k{m,z}alloc()和devm_ioremap{_resource}())。当然,您必须适当地使用它们,通常是在驱动程序的探测方法(或init代码)中。
建议在编写驱动程序时,使用这种更新的应用编程接口风格。在这里,我们将向您展示如何使用devm_request_irq()应用编程接口来分配(注册)您的硬件中断。其签名如下:
#include <linux/interrupt.h>
int __must_check
devm_request_irq(struct device *dev, unsigned int irq, irq_handler_t handler,
unsigned long irqflags, const char *devname, void *dev_id);第一个参数是指向设备的device结构的指针(正如我们在第 1 章、编写简单的杂项字符设备驱动程序中看到的,必须通过注册到适当的内核框架来获得)。其余五个参数与request_irq()相同;我们在这里不再重复。关键是,一旦注册,你就不用打电话给free_irq();内核将根据需要自动调用它(在驱动程序移除或设备分离时)。这极大地帮助我们开发人员避免了常见和臭名昭著的泄漏类型错误。
为了帮助阐明它的用途,让我们快速看一个例子。以下是来自 V4L 电视调谐器驱动程序的一段代码:
// drivers/gpu/drm/exynos/exynos_mixer.c
[...]
res = platform_get_resource(mixer_ctx->pdev, IORESOURCE_IRQ, 0);
if (res == NULL) {
dev_err(dev, "get interrupt resource failed.\n");
return -ENXIO;
}
ret = devm_request_irq(dev, res->start, mixer_irq_handler,
0, "drm_mixer", mixer_ctx);
if (ret) {
dev_err(dev, "request interrupt failed.\n");
return ret;
}
mixer_ctx-irq = res->start;
[...]正如我们在第 3 章、中看到的获取 MMIO 的物理地址使用硬件输入/输出内存,在获取设备资源部分,这里,相同的驱动程序使用platform_get_resource()应用编程接口提取 IRQ 号(用IORESOURCE_IRQ指定资源类型作为 IRQ 行)。一旦有了它,它就发布devm_request_irq()应用编程接口来分配或注册中断!因此,正如预期的那样,在该驱动程序中搜索free_irq()不会产生任何结果。
接下来,我们将学习什么是线程中断,如何使用线程中断,以及更重要的是,它的为什么。
正如在配套指南 Linux 内核编程- 第 11 章**CPU 调度器–第 2 部分中看到的,在将主线 Linux 转换为 RTOS 部分,我们介绍了 Linux (RTL)的实时补丁,它允许您将 Linux 作为 RTOS 进行补丁、配置、构建和运行!如果你对此不清楚,请回头参考。我们在这里不再重复同样的信息。
实时 Linux*(【RTL】)项目的工作已经稳定地移植到主线 Linux 内核中。RTL 做出的关键改变之一是将线程中断功能合并到主线内核中。这发生在内核版本 2 . 6 . 30(2009 年 6 月)中。这项技术做了一些乍一看似乎很奇怪的事情:它将硬件中断处理程序“转换”为内核线程。*
*您将在下一章中了解到,内核线程实际上非常类似于用户模式线程——它独立运行,在进程上下文中,并且有自己的任务结构(因此有自己的 PID、TGID 等),这意味着它可以被调度;也就是说,当处于可运行状态时,它会与其他竞争线程竞争在一个 CPU 内核上运行。关键区别在于,用户模式线程总是有两个地址空间——它所属的进程 VAS(用户空间)和内核 VAS,当它发出系统调用时,它会切换到内核 VAS。另一方面,内核线程纯粹在内核空间中运行,没有用户空间的视图;它只看到它总是在其中执行的内核 VAS (技术上,它的current-mm值总是NULL!).
那么,如何决定是否应该使用线程中断呢?在这变得完全清楚之前,我们需要覆盖更多的主题(对于那些不耐烦的人,这里有一个简短的答案:当(作为一个快速启发式)中断工作需要超过 100 微秒时,使用线程中断处理程序;向前跳到hardirks、小任务、线程处理程序–当部分使用什么,并查看那里的表格快速查看)。
现在,让我们通过检查可用的 API 来学习如何使用线程中断模型——包括常规的和托管的。然后,我们将学习如何使用托管版本以及如何在驱动程序中使用它。在这之后,我们将看看它的内部实现,并深入研究它的原因。
为了理解线程中断模型的内部工作方式,让我们来看看相关的 API。我们已经介绍了使用request_irq()应用编程接口。让我们看看它的实现:
// include/linux/interrupt.hstatic inline int __must_check
request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags, const char *name, void *dev)
{
return request_threaded_irq(irq, handler, NULL, flags, name, dev);
}这个应用编程接口只是request_threaded_irq()应用编程接口的一个薄薄的包装!其签名如下:
int __must_check
request_threaded_irq(unsigned int irq, irq_handler_t handler,
irq_handler_t thread_fn,
unsigned long flags, const char *name, void *dev);除第三个参数外,其他参数与request_irq()相同。以下是需要注意的几个要点:
irq_handler_t handler:第二个参数是指向通常的中断处理函数的指针。我们现在称它为主处理器。如果它为空并且thread_fn(第三个参数)为非空,则(内核的)默认主处理程序会自动安装(如果您对这个默认主处理程序感到疑惑,我们将在内部实现线程中断一节中更详细地介绍它)。irq_handler_t thread_fn:第三个参数是线程中断函数的指针;API 行为取决于您是否将此参数作为 null 传递:- 如果它是非空的,那么中断的实际服务由这个函数执行。它在专用内核线程的上下文(进程)中运行——这是一个线程中断!
- 如果为空,这是调用
request_irq()时的默认值,则只运行主处理程序,不创建内核线程。
如果指定了主处理程序(第二个参数),它将在所谓的 hardirq 或硬中断上下文中运行(如request_irq()的情况)。如果主处理程序为非空,那么您需要编写它的代码,并(至少)在其中执行以下操作:
- 验证中断是否适合您;如果不是,返回
IRQ_NONE。 - 如果适合您,您可以清除和/或禁用板/设备上的中断。
- 返回
IRQ_WAKE_THREAD;这将导致内核唤醒代表线程中断处理程序的内核线程。内核线程的名称将采用irq/irq#-name格式。这个内核线程现在将在内部调用thread_fn()函数,在那里您执行实际的中断处理工作。
另一方面,如果主处理程序为空,那么当中断触发时,只有您的线程处理程序——由第三个参数指定的函数——将由操作系统作为内核线程自动运行**。**
与request_irq()一样,request_threaded_irq()的返回值是一个整数,遵循通常的0/-E内核约定:成功时为0,失败时为负值errno。你应该检查一下。
同样,使用托管应用编程接口来分配线程中断将是现代驱动程序的推荐方法。内核为此提供了devm_request_threaded_irq()应用编程接口:
#include linux/interrupt.h
int __must_check
devm_request_threaded_irq(struct device *dev, unsigned int irq,
irq_handler_t handler, irq_handler_t thread_fn,
unsigned long irqflags, const char *devname,
void *dev_id);除了第一个参数(指向设备结构的指针)之外,所有参数都与request_threaded_irq()相同。这样做的主要优点是,您不需要担心释放 IRQ 线路。内核将在设备分离或驱动程序移除时自动释放它,就像我们在devm_request_irq()中学到的那样。与request_threaded_irq()一样,devm_request_threaded_irq()的返回值是一个整数,遵循通常的0/-E内核惯例:成功时为0,失败时为负 errno 值;你应该检查一下。
Don't forget! Using the managed devm_request_threaded_irq() API is the modern recommended approach for allocating a threaded interrupt. However, note that it won't always be the right approach; see the Constraints when using a threaded handler section for more information.
线程中断处理函数的签名与 hardirq 中断处理函数的签名相同:
static irqreturn_t threaded_handler(int irq, void *data);这些参数也有相同的含义。
线程中断通常使用IRQF_ONESHOT中断标志;include/linux/interrupt.h中的内核注释描述得最好:
* IRQF_ONESHOT - Interrupt is not reenabled after the hardirq handler finished.
* Used by threaded interrupts which need to keep the
* irq line disabled until the threaded handler has been run.事实上,内核坚持当你的驱动程序包含一个线程处理程序并且主处理程序是内核默认的时候,你使用IRQF_ONESHOT标志。当等级触发中断发生时,不使用IRQF_ONESHOT标志将是致命的。为了安全起见,内核会抛出一个错误——当这个标志不在irqflags位掩码参数中时——甚至对于边缘触发也是如此。如果你好奇的话,kernel/irq/manage.c:__setup_irq()的代码只检查这个(链接:https://酏. boot in . com/Linux/v 5.4/source/kernel/IRQ/manage . c # l 1486)。
A kernel parameter called threadirqs exists that you can pass to the kernel command line (via the bootloader). This force threads all the interrupt handlers except those marked explicitly as IRQF_NO_THREAD. To find out more about this kernel parameter, go to https://www.kernel.org/doc/html/latest/admin-guide/kernel-parameters.html.
在下面的小节中,我们将看一下 Linux 驱动程序的 STM32 微控制器之一。在这里,我们将重点关注中断分配是如何通过我们刚刚介绍的“托管”应用编程接口来完成的。
STM32 F7 是 STMicroelectronics 基于 ARM-Cortex M7F 内核制造的一系列微控制器的一部分:

Figure 4.3 – The STM32F103 microcontroller pinout with some I2C pins highlighted (see the lower left) Image Credit: The preceding image, which has been slightly added to by myself, has been taken from https://www.electronicshub.org/wp-content/uploads/2020/02/STM32F103C8T6-Blue-Pill-Pin-Layout.gif. Image by Rasmus Friis Kjekisen. This image falls under Creative Commons CC BY-SA 1.0 (https://creativecommons.org/licenses/by-sa/1.0/).
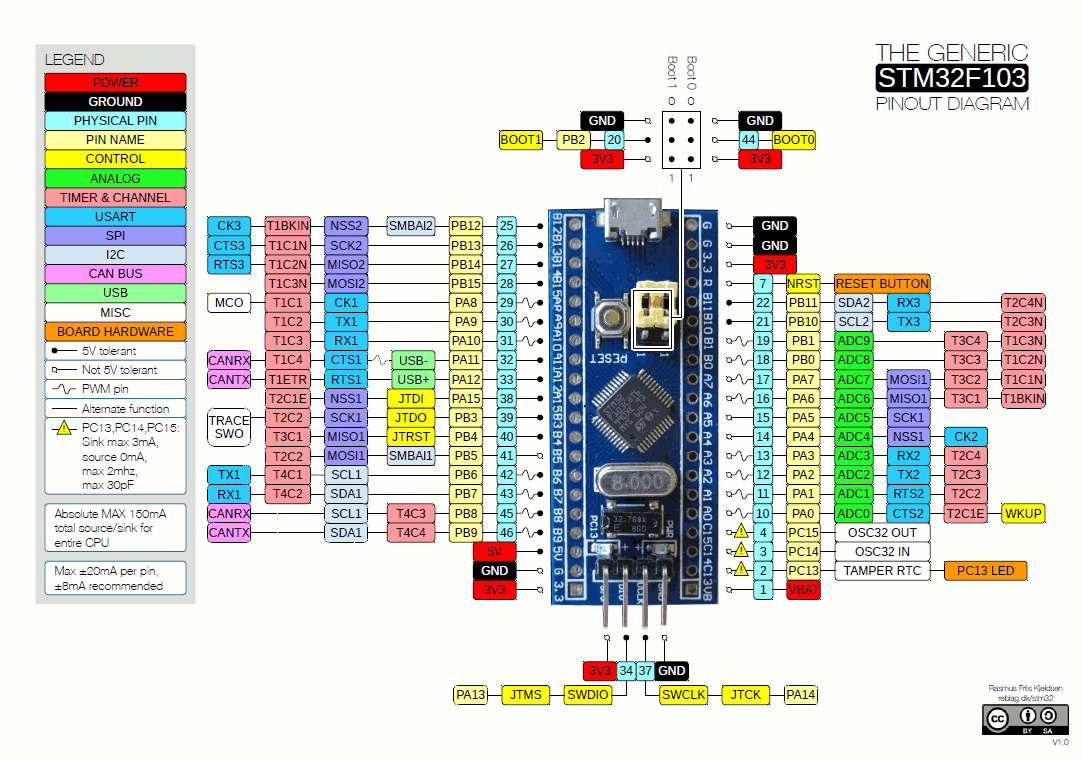{kind=link}
Linux 内核通过各种驱动程序和 DTS 文件支持 STM32 F7。在这里,我们将看一下这个微控制器的 I2C 总线驱动程序(drivers/i2c/busses/i2c-stm32f7.c)的一小部分代码。它分配两个硬件中断:
- 事件 IRQ 线路,通过
devm_request_threaded_irq()应用编程接口 - 错误 IRQ 线,通过
request_irq()应用编程接口
如所料,分配 IRQ 行的代码在其探测方法中:
// drivers/i2c/busses/i2c-stm32f7.c
static int stm32f7_i2c_probe(struct platform_device *pdev)
{
struct stm32f7_i2c_dev *i2c_dev;
const struct stm32f7_i2c_setup *setup;
struct resource *res;
int irq_error, irq_event, ret;
[...]
irq_event = platform_get_irq(pdev, 0);
[...]
irq_error = platform_get_irq(pdev, 1);
[...]
ret = devm_request_threaded_irq(&pdev->dev, irq_event,
stm32f7_i2c_isr_event,
stm32f7_i2c_isr_event_thread,
IRQF_ONESHOT,
pdev->name, i2c_dev);
[...]
ret = devm_request_irq(&pdev->dev, irq_error, stm32f7_i2c_isr_error, 0,
pdev->name, i2c_dev);让我们关注对devm_request_threaded_irq()的调用。第一个参数是指向设备结构的指针。由于这是一个平台驱动程序(通过module_platform_driver包装宏注册),它的探测方法接收struct platform_device *pdev参数;device结构就是从中提取出来的。第二个参数是要分配的 IRQ 行。同样,正如我们已经看到的,它是通过一个助手例程提取的。这里,这是platform_get_irq()原料药。
第三个参数指定主处理程序;那是哈迪克。由于它是非空的,当 IRQ 被触发时,这个例程将被调用。它对设备和 I2C 传输执行特定于硬件的验证,如果一切正常,它将返回IRQ_WAKE_THREAD值。这唤醒了线程中断例程,第四个参数,函数stm32f7_i2c_isr_event_thread()在进程上下文中作为内核线程运行!设置为IRQF_ONESHOT的irqflags参数是线程处理程序的典型参数;它指定在线程处理程序完成之前,IRQ 行保持禁用状态(不仅仅是 hardirq)。线程处理例程完成工作,并在完成后返回IRQ_HANDLED。
由于错误 IRQ 行是通过devm_request_irq() API 分配的,并且因为我们已经介绍了如何使用该 API(参考 IRQ 分配-现代方式-托管中断设施部分),我们在此不再重复任何相关信息。
现在,让我们看看内核如何在内部实现线程中断模型。
正如我们前面提到的,如果主处理程序为空,并且线程函数为非空,内核将使用默认的主处理程序。这个函数被称为irq_default_primary_handler(),它所做的只是返回IRQ_WAKE_THREAD值,从而唤醒(并使其可调度)内核线程。
此外,运行您的thread_fn例程的实际内核线程是在request_threaded_irq()应用编程接口的代码中创建的。调用图(从 5.4.0 版的 Linux 内核开始)如下:
kernel/irq/manage.c:request_threaded_irq() -- __setup_irq() --
setup_irq_thread() -- kernel/kthread.c:kthread_create()kthread_create() API 的调用如下。在这里,您可以清楚地看到新内核线程名称的格式将是怎样的irq/irq#-name格式:
t = kthread_create(irq_thread, new, "irq/%d-%s", irq, new->name);这里(我们不显示代码),新的内核线程被编程为设置为SCHED_FIFO调度策略和MAX_USER_RT_PRIO/2实时调度优先级,其通常具有值50(范围SCHED_FIFO从1到99,MAX_USER_RT_PRIO是100)。我们将在*中讨论为什么这很重要,为什么要使用线程中断?*节。如果您不确定线程调度策略及其优先级,请参考配套指南 Linux 内核编程- 第 10 章、CPU 调度器–第 1 部分、POSix 调度策略部分。
内核管理这个内核线程,代表整个线程中断处理程序。正如我们已经看到的,它通过[devm_]request_threaded_irq() API 在 IRQ 分配上创建它;然后,内核线程简单地休眠。每当被分配的 IRQ 被触发时,它被内核按需唤醒;当free_irq()被调用时,内核会将其销毁。目前不要担心细节;我们将在下一章讨论内核线程和其他有趣的主题。
到目前为止,虽然您已经学习了如何使用线程中断模型,但还没有清楚地解释为什么(以及何时)您应该使用线程中断模型。下一节将详细介绍这一点。
通常被问到的一个关键问题是,当常规 hardirq 类型的中断存在时,我为什么要使用线程中断?完整的答案有点敷衍;以下是主要原因:
- 真正做到实时。
- 它消除/减少了软件瓶颈。由于线程处理程序实际上是在进程上下文中运行它的代码,所以它不像 hardirq 处理程序那样是一个关键的代码路径;因此,中断处理可能需要更长的时间。
In a nutshell, as a quick rule of thumb, when the interrupt handling consistently takes over 100 microseconds, use the threaded interrupt model (see the table in Hardirqs, tasklets, threaded handlers – what to use when section).
在接下来的小节中,我们将详细介绍这些要点。
这是一个关键点,需要一些解释。
标准 Linux 操作系统上的优先级从最高到最低如下(我们将在每个项目符号后面加上它运行的上下文;它要么是进程,要么是中断。如果你在这一点上不清楚,理解这一点非常重要;有关更多信息,请参考配套指南 Linux 内核编程- 第 6 章、内核内部要素–进程和线程、理解进程和中断上下文部分:
-
硬件中断:这些先发制人。hardirq 处理程序在 CPU 上自动运行(直到完成,没有中断);
context:interrupt。 -
实时线程(即
SCHED_FIFO或SCHED_RR调度策略),包括内核和用户空间,实时优先级为正(rtprio);context:process:- 具有相同实时优先级(
current-rtprio)的内核线程比具有相同实时优先级的用户空间线程获得轻微的优先级提升。
- 具有相同实时优先级(
-
处理器异常:这包括系统调用(它们确实是同步异常;比如 x86 上的
syscall、ARM 上的SWI),页面故障、保护故障等等;context:process。 -
用户模式线程:默认使用
SCHED_OTHER调度策略,使用0的rtprio;context:process。
下图显示了 Linux 上的相对优先级(这个图有点简单;稍后通过图 4.10 和图 4.11 可以看到更精细的图表:

Figure 4.4 – Relative prioritization on the standard Linux OS
假设您正在开发一个实时多线程应用。在进程内存在的几十个线程中,有三个(为了简单起见,我们称之为线程 A、B 和 C)被认为是关键的“实时”线程。相应地,您让应用分别为线程 A、B 和 C 授予SCHED_FIFO和 30、45 和 60 的实时优先级的调度策略(如果您对这几点不清楚,请参考配套指南 Linux 内核编程- 第 10 章、CPU 调度器-第 1 部分和 第 11 章、CPU 调度器-第 2 部分,关于 CPU 调度)。由于这是一个实时应用,这些线程完成工作的最长时间被缩短了。换句话说,*期限是存在的;*对于我们的示例场景,假设线程 B 完成工作的最坏情况截止时间为 12 毫秒。
现在,就相对优先级而言,这将如何工作?为了简单起见,假设系统只有一个 CPU 内核。现在,另一个线程 X(使用调度策略SCHED_OTHER运行,实时优先级为0,这是默认的调度策略/优先级值)当前正在 CPU 上执行代码。但是,如果任何实时线程正在等待的“事件”发生,它将抢占当前正在执行的线程并运行。这是意料之中的事;回想一下,实时调度的基本规则非常简单:最高优先级的可运行线程必须是正在运行的线程。好吧。那很好。现在,我们需要考虑硬件中断。我们已经看到,硬件中断的优先级最高。这意味着它会抢占任何东西,包括你的(所谓的)实时线程(见上图)!
假设中断处理需要 200 微秒;在 Linux 这样的丰富操作系统上,这并不算太糟糕。然而,在这种情况下,五次硬件中断将消耗 1 毫秒;如果设备变得繁忙(例如,许多传入的数据包)并以连续流的形式发出例如 20 个硬件中断怎么办?这肯定会被优先考虑,并且会消耗(至少)4 毫秒!您的实时线程肯定会在中断处理运行时被抢占,并且无法获得所需的 CPU,直到为时已晚!(12 毫秒)的最后期限将早已过去,系统将会失败(如果你的应用是真正的实时应用,这可能是灾难性的)。
下图从概念上表示了这个场景(为了简洁明了,我们只展示了我们的一个用户空间SCHED_FIFO实时线程;即rtprio 45 处的螺纹 B:

Figure 4.5: The hardirq model – a user mode RT SCHED_FIFO thread interrupted by a hardware interrupt flood; deadline missed
实时线程 B 被描述为从时间t0开始运行(在 x 轴上;y 轴代表实时优先级;螺纹 B 的rtprio为 45°;它有 12 毫秒(一个艰难的期限)来完成它的工作。然而,假设 6 毫秒后(在时间t1处),硬件中断触发。
在图 4.5 中,我们没有显示执行的低级中断设置代码。现在硬件中断在时间t1触发,导致中断处理程序被调用;也就是 hardirq(在上图中显示为大的黑色垂直双箭头)。很明显,硬件中断抢占了线程 b,现在假设执行需要 200 微秒;这并不多,但是如果大量的中断(比如 20 个中断,从而消耗掉 4 ms)到来了呢!这在上图中有描述:中断以很快的速度继续,直到时间t2;只有在它们全部完成之后,上下文才会被恢复。因此,调度代码运行并且(假设)上下文切换回线程 B,给它处理器(在现代英特尔 CPU 上,我们假定保守的上下文切换时间为 50 微秒:https://blog . tsunanet . net/2010/11/制造上下文需要多长时间. html )。然而,不久之后,在t3时刻,硬件中断再次触发,再次抢占 B。这可以无限期地进行下去;RT 线程最终会运行(当中断风暴完成时),但可能会也可能不会达到它的截止日期!这是主要问题。
The problem that was described in the preceding paragraph doesn't go away by simply raising the real-time priority of your user mode threads; the hardirq hardware interrupts will still always preempt them, regardless of their priority.
通过将线程中断从 RTL 项目反向移植到主线 Linux,我们可以解决这个问题。怎么做?想想看:有了线程中断模型,现在大部分的中断处理工作都是由一个SCHED_FIFO内核线程执行的,该线程的实时优先级为50。因此,只需设计您的用户空间应用,使其在必要时具有实时优先级高于50 的SCHED_FIFO实时线程。这将确保它们优先于硬件中断处理程序运行!
The key idea here is that a user mode thread under the SCHED_FIFO policy and a real-time priority 50, can, in effect, preempt the (threaded) hardware interrupt! Quite a thing indeed.
因此,对于我们的示例场景,让我们现在假设我们正在使用线程中断。接下来,调整用户空间多线程应用的设计:为我们的三个实时线程分配SCHED_FIFO策略和 60、65 和 70 的实时优先级。下图概念性地描述了这个场景(为了清楚起见,我们只显示了我们的一个用户空间SCHED_FIFO线程,线程 B,这次是在65的rtprio):

Figure 4.6 – Threaded interrupt model – a user mode RT SCHED_FIFO rtprio 50 thread can preempt the threaded interrupt; deadline achieved
在上图中,RT 线程 B 现在处于SCHED_FIFO调度策略,其rtprio为65。它最多需要 12 毫秒来完成(达到截止日期)。再说一遍,执行 6 毫秒(t0到t1);在时间t1时,硬件中断触发。这里,低级设置代码和(内核默认或驱动程序的)hardirq 处理程序将立即执行,抢占处理器上的任何东西。但是,hardirq 或主处理程序执行时间很短(最多几微秒)。正如我们已经讨论过的,这是现在正在执行的主处理程序;它将在返回IRQ_WAKE_THREAD值之前完成所需的最少工作,这将使内核唤醒代表线程处理程序的内核线程。然而——这是关键——线程中断,也就是优先级为50的SCHED_FIFO,现在正与其他可运行的线程争夺 CPU 资源。由于线程 B 是一个SCHED_FIFO实时线程,rtprio 为65,会把线程处理程序打到 CPU,转而运行!
综上所述,在上图中,发生了以下情况:
- 时间
t0到t1:用户模式 RT 线程(SCHED_FIFO,rtprio 65)正在执行代码(6 毫秒) - 在
t1时刻,细灰色条代表 hardirq 低级设置/BSP 代码。 - 细的黑色双箭头垂直线代表主 hardirq 处理程序(上面两个都只需要几微秒就可以完成)。
- 蓝色条是排班代码。
- 紫色条(在
t3+ 50 us)代表在 rtprio50运行的线程中断处理程序。
所有这一切的结果是线程 B 在它的期限内很好地完成了它的工作(这里,作为一个例子,它在 10 毫秒多一点的时间内完成了它的期限)。
除非时间限制非常关键,否则使用线程中断模型来处理设备的中断对大多数设备和驱动程序都非常有效。在撰写本文时,倾向于保留在传统的上/下半部分方法中的设备(在理解和使用上半部分和下半部分部分中有详细介绍)通常是高性能网络、数据块和(某些)多媒体设备。
关于线程处理程序的最后一点:内核不会盲目地允许你对任何 IRQ 使用线程处理程序;它尊重一些约束。在注册您的线程处理程序时(通过[devm_]request_threaded_irq()API),它会执行几个有效性检查,其中一个我们已经提到过了:IRQF_ONESHOT对于线程处理程序必须存在。
也要看实际的 IRQ 线;例如,我曾经尝试过在 x86 上对 IRQ 1使用线程处理程序(通常是 i8042 键盘/鼠标控制器芯片的中断线路)。它失败了,内核显示以下内容:
genirq: Flags mismatch irq 1\. 00002080 (driver-name) vs. 00000080 (i8042)因此,从前面的输出中,我们可以看到 i8042 将只接受用于 IRQ 标志的0x80位掩码,而我传递了一个值0x2080;稍加检查就会发现0x2000旗确实是IRQF_ONESHOT旗;显然,这导致了不匹配,是不允许的。不仅如此,还要注意是谁标记了错误——是内核的通用 IRQ 层(genirq)在幕后检查东西。(请注意,这种错误检查不限于线程中断。)
此外,某些关键设备会发现使用线程处理程序实际上会减慢它们的速度;这对于现代网卡、块设备和一些多媒体设备来说非常典型。他们通常使用 hardirq 上半部分和 tasklet/softirq 下半部分机制(这将在理解和使用上半部分和下半部分一节中解释)。
在我们结束这一部分之前,还有一个有趣的点需要考虑:内核提供了一个 IRQ 分配 API,根据某些情况,它会将您的中断处理程序设置为传统的 hardirq 处理程序或线程处理程序。这个 API 叫做request_any_context_irq();请注意,它是作为仅 GPL 导出的。其签名如下:
int __must_check
request_any_context_irq(unsigned int irq, irq_handler_t handler,
unsigned long flags, const char *name, void *dev_id);参数与request_irq()相同。当被调用时,该例程将决定中断处理函数——参数handler——是在原子 hardirq 上下文中运行,还是在支持睡眠的进程上下文(内核线程的上下文)中运行,换句话说,作为线程处理程序运行。你怎么知道handler()会出现在哪个语境中?根据handler()将要运行的上下文,返回值让您知道:
- 如果它将在 hardirq 上下文中运行,它将返回一个值
IRQC_IS_HARDIRQ。 - 如果它将在进程/线程上下文中运行,它将返回一个值
IRQC_IS_NESTED。 - 失败时将返回否定的
errno(您应该检查这一点)。
然而,这到底意味着什么呢?本质上,有些控制器在慢速公共汽车上(I2C 就是一个很好的例子);它们衍生出使用所谓“嵌套”中断的处理程序,这实际上意味着处理程序本质上不是原子的。它可能会调用休眠的函数(同样,I2C 函数就是一个很好的例子),因此需要被抢占。使用request_any_context_irq() API 可以确保如果是这种情况,底层通用 IRQ 代码会检测到它,并给你一个合适的处理接口。GPIO 驱动的矩阵键盘驱动程序是另一个利用该应用编程接口(drivers/input/keyboard/matrix_keypad.c)的例子。
有了这些内容,您现在了解了什么是线程中断,以及它们为什么会非常有用。现在,让我们看一个更短的主题:作为驱动程序作者,您如何选择性地启用/禁用 IRQ 行。
通常,处理低级中断管理的是核心内核(和/或特定于 arch 的)代码。这包括在需要时屏蔽它们。然而,在启用/禁用硬件中断时,一些驱动程序以及操作系统需要细粒度的控制。当您的驱动程序或模块代码以内核权限运行时,内核提供了(导出的)帮助程序,允许您完全这样做:
| 简评 | API 或助手例程 |
| 禁用/启用本地处理器上的所有中断 | |
| 无条件禁用本地(当前)处理器内核上的所有中断。 | local_irq_disable() |
| 无条件启用本地(当前)处理器内核上的所有中断。 | local_irq_enable() |
| 保存的状态(中断屏蔽),然后禁用本地(当前)处理器内核上的所有中断。状态保存在通过的flags参数中。 | local_irq_save(unsigned long flags); |
| 恢复通过的状态(中断屏蔽),从而根据flags参数启用本地(当前)处理器内核上的中断。 | local_irq_restore(unsigned long flags); |
| 禁用/启用特定的 IRQ 线路 | |
| 禁用 IRQ 线路irq;在返回之前,将等待并同步任何未决中断(在该 IRQ 线路上)完成。 | void disable_irq(unsigned int irq); |
| 禁用 IRQ 线路irq;不会等待任何未决中断(在那个 IRQ 线上)完成(nosync)。 | void disable_irq_nosync(unsigned int irq); |
| 禁用 IRQ 线路irq并等待活动的 hardirq 处理程序完成后再返回。如果与该 IRQ 行相关的任何线程处理程序处于活动状态(需要 GPL),则返回false。 | bool disable_hardirq(unsigned int irq); |
| 启用 IRQ 线路irq;撤销对disable_irq()的一次调用的效果。 | void enable_irq(unsigned int irq); |
local_irq_disable() / local_irq_enable()助手被设计为禁用/启用本地或当前处理器内核上的所有中断(除了 NMI)。
The implementation on x86[_64] of local_irq_disable()/local_irq_enable() is done via the (in)famous cli/sti pair of machine instructions; in the bad old days, these used to disable/enable interrupts across the system, on all CPUs. Now, they work on a per-CPU basis.
disable_{hard}irq*() / enable_irq()助手被设计成选择性地禁用/启用特定的 IRQ 线路,并被称为一对。前面提到的一些例程可以从中断上下文中调用,尽管这应该小心进行!确保从流程上下文中调用它们更安全。之所以有“小心”的说法,是因为这些助手中有几个是通过内部调用非阻塞例程来工作的,比如cpu_relax(),它们通过在处理器上重复运行一些机器指令来等待。(cpu_relax()是这种“需要小心使用”情况的一个很好的例子,因为它通过在无限循环中调用nop机器指令来工作;当任何硬件中断触发时,循环退出,这正是我们所等待的!现在,在中断上下文中等待一段时间被认为是一件错误的事情;因此有了“小心”的说法。)用于disable_hardirq()的内核提交(链接:https://github . com/Torvalds/Linux/commit/02 CEA 3958664723 a5d 2236 f 0058 de 97 c 7e 4693)解释了它可以用于像 netpoll 这样的需要禁用原子上下文中断的情况。
禁用中断时,请注意确保您没有持有(锁定)处理程序可能使用的任何共享资源。这将导致(自我)死锁!(锁定及其许多场景将在本书的最后两章中详细解释。)
除了不可屏蔽中断 ( NMI ) ***之外,前面所有的应用编程接口和助手都处理所有的硬件中断。***NMI 是一个特定于 arch 的中断,用于实现硬件看门狗和调试功能(例如,所有内核的无条件内核堆栈转储;我们将很快展示一个例子)。此外,NMI 中断线路不能共享。
内核所谓的魔法系统工具就是利用 NMI 的一个简单例子。要查看为魔法 SysRq 分配的键盘热键,您必须通过键入[Alt][SysRq][letter]组合键来调用或触发它。
magic SysRq triggering: Instead of getting your fingers all twisted typing [Alt][SysRq][letter], there's an easier – and more importantly non-interactive – way to do so: just echo the relevant letter to a proc pseudofile (as root, of course): echo letter/proc/sysrq-trigger.
但是我们需要输入哪个字母呢?以下输出显示了一种快速找到答案的方法。这是对魔法系统的一种快速帮助(我是在我的树莓皮 3B+上做的):
rpi # dmesg -C
rpi # echo ? /proc/sysrq-trigger
rpi # dmesg
[ 294.928223] sysrq: HELP : loglevel(0-9) reboot(b) crash(c) terminate-all-tasks(e) memory-full-oom-kill(f) kill-all-tasks(i) thaw-filesystems(j) sak(k) show-backtrace-all-active-cpus(l) show-memory-usage(m) nice-all-RT-tasks(n) poweroff(o) show-registers(p) show-all-timers(q) unraw(r) sync(s) show-task-states(t) unmount(u) show-blocked-tasks(w) dump-ftrace-buffer(z)
rpi # 我们目前感兴趣的是粗体显示的字母l(小写字母 L)—show-backtrace-all-active-cpus(l)。一旦被触发,它就像承诺的那样——它显示了所有活动 CPU 上内核模式堆栈的堆栈回溯!(这可能是一个有用的调试辅助工具,因为您将看到每个 CPU 内核现在正在运行什么。)怎么做?它通过向他们发送一个 NMI 来做到这一点;也就是对所有的 CPU 核心!这是一种方法,我们可以确切地看到在命令被触发的那一刻,中央处理器在做什么!当系统出现问题时,这可能非常有用。
在这里,echo l /proc/sysrq-trigger(作为根)起作用了!以下部分屏幕截图显示了输出:

Figure 4.7 – The output when the NMI is sent to all CPUs, showing the kernel stack backtrace on each of them
在前面的截图中,可以看到bash PID 633 运行在 CPU 0上,内核线程swapper/1运行在 CPU 1上(可以看到每个的内核栈;以自下而上的方式阅读它)。
魔法 SysRq 设施的代码可以在drivers/tty/sysrq.c找到;浏览一下很有趣。以下是当魔法 SysRq l被触发时 x86 上发生的情况的大致调用图:
include/linux/nmi.h:trigger_all_cpu_backtrace() arch_trigger_cpumask_backtrace()
arch/x86/kernel/apic/hw_nmi.c:arch_trigger_cpumask_backtrace()
nmi_trigger_cpumask_backtrace()最后一个函数实际上在lib/nmi_backtrace.c:nmi_trigger_cpumask_backtrace()变成了通用(非特定于 arch)代码。这里的代码通过向每个 CPU 发送一个 NMI 来触发 CPU 回溯。这是通过nmi_cpu_backtrace()功能实现的。这个函数依次通过调用show_regs()或dump_stack()例程来显示我们在前面截图中看到的信息,这些例程最终会变成特定于 arch 的代码来转储 CPU 寄存器以及内核模式堆栈。该代码也足够智能,不会试图在那些处于低功耗(空闲)状态的 CPU 内核上显示回溯。
Again, things are not always simple in the real world; see this article by Steven Rostedt on the complex issues people have faced with the x86 NMI and how they've been addressed: The x86 NMI iret problem, March 2012: https://lwn.net/Articles/484932/.
到目前为止,我们还没有真正看到分配的 IRQ 行的内核视图;很自然,接口是通过procfs文件系统;让我们深入研究一下。
现在您已经了解了足够多的关于 IRQ 和中断处理的细节,我们可以(最后!)利用内核的proc 文件系统,这样我们就可以查看当前分配的 IRQ。我们可以通过阅读/proc/interrupts伪文件的内容来做到这一点。我们将显示几个截图:第一个(图 4.8 )显示了我的树莓 Pi ZeroW 上的 IRQ 状态—每个 I/O 设备每个 CPU 服务的中断数,而第二个(图 4.9 )在我们“常用”的 x86_64 Ubuntu 18.04 VM 上显示了这一点:

Figure 4.8 – IRQ status on a Raspberry Pi ZeroW
在前面的/proc/interrupts输出中,系统上的每一条 IRQ 线都会发出一条线(或记录)。让我们解释输出的每一列:
- 第一列是已经分配的 IRQ 号。
- 第二列(向前)显示了每个 CPU 内核(从系统启动到现在)已经服务的 hardirqs 的数量。该数字表示中断处理程序在该 CPU 内核上运行的次数(列数因系统上处理 IRQ 的活动内核数量而异)。在前面的截图中,树莓 Pi Zero 只有一个 CPU 内核,而我们的 x86_64 VM 有两个(虚拟化的)CPU 内核,中断分布在这两个内核上并进行处理(在负载平衡中断和 IRQ 相似性一节中有更多相关内容)。
- 第三列(或后面的列)显示中断控制器芯片。在 x86(图 4.9第四列)上,IO-APIC 这个名字意味着中断控制器是一个增强的,在多核系统上使用,将中断分配给不同的内核或 CPU 组(在高端系统上,可能会有多个 IO-apic 在运行)。
- 其后的列显示正在使用的中断触发类型;也就是电平或边沿触发(我们在理解电平和边沿触发中断一节中讨论了这一点)。这里,
Edge告诉我们 IRQ 是边缘触发的。它前面的数字(例如,前面截图中的35 Edge)非常依赖于系统。它通常表示中断源(内核映射到一个 IRQ 行;许多嵌入式设备驱动程序经常使用 GPIO 引脚作为中断源)。最好不要试图解释它(除非你真的知道如何解释),而只是依赖于 IRQ 号(第一列)。 - 右边的最后一列是 IRQ 线的当前所有者。通常,这是设备驱动程序或内核组件的名称(通过其中一个
*request_*irq()API 分配了这个 IRQ 行)。

Figure 4.9 – IRQ status on an x86_64 Ubuntu 18.04 VM (truncated screenshot)
从 2.6.24 内核来看,对于 x86 和 AMD64 系统(或 x86_64),这里甚至会显示非设备(I/O)中断(系统中断),比如 NMI、本地定时器中断 ( LOC )、PMI、IWI 等等。在图 4.9 中可以看到,最后一行显示IWI,是工间中断。
显示/proc/interrupts前面输出的内核 procfs 代码——也就是它的show 方法——可以在kernel/irq/proc.c:show_interrupts()找到(链接:https://酏剂. boot in . com/Linux/v 5.4/source/kernel/IRQ/proc . c # L438)。首先,它打印标题行,然后为每个 IRQ 行发出一行“记录”。统计数据主要来源于各 IRQ 行的元数据结构内–struct irq_desc;在每个 IRQ 中,它在每个处理器内核上循环(通过for_each_online_cpu()助手例程),打印为每个内核服务的 hardirqs 的数量。最后(最后一列),通过struct irqaction的name成员打印 IRQ 线的“所有者”。x86 的专用中断(如NMI、LOC、PMI和IWI IRQs)通过arch/x86/kernel/irq.c:arch_show_interrupts()的代码显示。
On the x86, IRQ 0 is always the timer interrupt. In the companion guide Linux Kernel Programming - Chapter 10, The CPU Scheduler - Part 1, we learned that, in theory, the timer interrupt fires HZ times per second. In practice, for efficiency, this has now been replaced with a per-CPU periodic high-resolution timer (HRT); it shows up as the IRQ named LOC (for LOCal) for timer interrupts in /proc/interrupts.
This actually explains why the number of hardware timer interrupts under the timer row is very low; check this out (on an x86_64 guest with four (virtual) CPUs):
$ egrep "timer|LOC" /proc/interrupts ; sleep 1 ; egrep "timer|LOC" /proc/interrupts
0: 33 0 0 0 IO-APIC 2-edge timer
LOC: 11038 11809 10058 8848 Local timer interrupts
0: 33 0 0 0 IO-APIC 2-edge timer
LOC: 11104 11844 10086 8889 Local timer interrupts
$ Notice how IRQ 0 doesn't increment but the LOC IRQ does indeed (per CPU core).
/proc/stat伪文件还提供了一些关于在每个 CPU 的基础上利用服务中断的信息,以及可以服务的中断数量(更多细节请参考proc(5)手册页)。
Softirqs, as explained in detail in the Understanding and using top and bottom halves section, can be viewed via /proc/softirqs; more on this later.
至此,您已经了解了如何查看分配的 IRQ 行。然而,中断处理的一个主要方面仍然存在:理解所谓的上半/下半二分法,它们存在的原因,以及如何使用它们。我们将在下一节讨论这个问题。
非常强调的事实是,您的中断处理程序必须快速完成其工作(如保持快速部分和其他地方所解释的)。话虽如此,一个实际问题确实出现了。让我们考虑一下这个场景:您已经分配了 IRQn,并编写了中断处理函数来处理到达的中断。大家可能还记得,我们这里所说的函数,通常称为 hardirq 或 **ISR(中断服务例程)**或主处理程序,是request_{threaded}_irq() API 的第二个参数,是devm_request_irq() API 的第三个参数,是devm_request_threaded_irq() API 的第四个参数。
正如我们之前提到的,有一个快速的启发:如果你的 hardirq 例程的处理持续超过 100 微秒,那么你将需要使用替代策略。假设您的处理程序在这段时间内完成得很好;在这种情况下,根本没有问题!但是如果它确实需要更多的时间呢?也许外围设备的低级规范要求您在中断到达时做许多事情(比如说有 10 个项目要完成)。您正确地编写了代码,但是它几乎总是超过时间限制(根据经验法则是 100 微秒)!你是做什么的?一方面,有这些内核乡亲在吼你快点完成;另一方面,外围设备的低级规范要求您遵循几个关键步骤来正确处理中断!(谈进退两难!)
正如我们之前所暗示的,在这种情况下,有两种广泛的策略可以遵循:
- 使用线程中断来处理大部分工作;考虑了现代的方法。
- 使用“下半部分”程序来处理大部分工作;传统的方法。
我们在使用线程中断模型一节中详细介绍了线程中断的概念理解、实际用法以及为什么。在上下半部模型中,这是一种方法:
- 所谓的上半部分是硬件中断触发时最初调用的功能。因此,这是您所熟悉的-它只不过是您通过其中一个
*request_*irq()API 注册的 hardirq 、ISR 或主处理程序例程(为清楚起见:通过这些 API 之一:request_irq()/devm_request_irq()/request_threaded_irq()/devm_request_threaded_irq())。) - 我们还注册了一个所谓的下半部分例程来执行大部分中断处理工作。
换句话说,中断处理被分成两半–顶部和底部。然而,这并不是一个真正令人愉快的描述方式(因为英文单词 half 让你直观地认为例程的大小大致相同);现实更像这样:
- 上半部分执行所需的最少工作(通常,确认中断,可能在上半部分期间在板上将其关闭,然后执行任何(最少)特定于硬件的工作,包括根据需要从/向设备接收/发送一些数据)。
- 下半部分例程执行大部分中断处理工作。
那么,下半部分是什么?这只是一个在内核中注册的 C 函数。您应该使用的实际注册 API 取决于您打算使用的下半部分的类型。有三种类型:
- 旧的下半部机制,现已弃用;缩写为 BH (你几乎可以忽略它)。
- 现代推荐的(如果你首先使用这种上下半技术)机制是:小任务。
- 底层内核机制:软件。
You will come to see that the tasklet is actually built upon a kernel softirq.
事情是这样的:上半部分——我们一直在使用的 hardirq 处理器——正如我们之前提到的那样,只做最少的工作;然后,它“调度”其下半部分并退出(返回)。这里的 schedule 这个词并不意味着它叫schedule(),因为那将是荒谬的(毕竟,我们处在一个中断的环境中!);这只是用来描述事实的词。内核会保证一旦上半部分完成,下半部分尽快运行;特别是,没有用户或内核线程会抢占它。
等一下:即使我们做了所有这些——将处理程序分成两半,让它们一起执行工作——那么我们是如何节省时间的呢?毕竟这是初衷。现在调用两个函数而不是一个函数的开销会不会更长?啊,这给我们带来了一个真正的关键点:上半部分(hardirq)总是在当前 CPU 及其处理的 irq 在所有 CPU 上禁用(屏蔽)所有中断的情况下运行,但下半部分处理程序在所有中断启用的情况下运行。
请注意,下半部分仍然在原子或中断上下文中运行!因此,适用于 hardirq(上半部)处理器的相同注意事项也适用于下半部处理器:
- 您不能(向或从用户内核空间)传输数据。
- 只能用
GFP_ATOMIC标志分配内存(如果真的必须)。 - 你不能直接或间接地称呼
schedule()。
这种下半部分处理是内核延迟功能能力的子集;内核有以下几种延迟功能机制:
- 工作队列(基于内核线程);
context:process - 下半部分/小任务(基于 softirqs
context:interrupt - Softirqs
context:interrupt - 内核定时器;
context:interrupt
We will cover kernel timers and workqueues in Chapter 5, Working with Kernel Timers, Threads, and Workqueues.
所有这些机制都允许内核(或驱动程序)指定在安全的情况下,某些工作必须在以后执行(被推迟)。
此时,您应该能够理解我们已经讨论过的线程中断机制有点类似于延迟功能机制。这被认为是现代的使用方法;同样,尽管它的性能对于大多数外设来说是可以接受的,但是一些设备类别——通常是网络/块/多媒体——可能仍然需要传统的上下半部机制来提供足够高的性能。此外,我们再次强调:上半部分和下半部分总是在原子(中断)上下文中运行,而线程处理程序实际上在进程上下文中运行;你可以认为这是一个优点或缺点。事实是,尽管线程处理程序在技术上是在流程上下文中,但最好在其中执行快速的非阻塞操作。
小任务和内核的 softirq 机制之间的一个关键区别是,小任务更容易处理,这使得它们成为典型驱动程序的一个很好的选择。当然,如果你可以用一个线程处理程序来代替,就这么做;稍后,我们将展示一张表格,帮助您决定使用什么以及何时使用。让小任务更容易使用的一个关键因素是(在 SMP 系统上)特定的小任务永远不会与自身并行运行;换句话说,一个给定的小任务一次只在一个 CPU 上运行(使其相对于自身是非并发的或序列化的)。
linux/interrupt.h中的标题注释也给出了小任务的一些重要属性:
[...] Properties:
* If tasklet_schedule() is called, then tasklet is guaranteed
to be executed on some cpu at least once after this.
* If the tasklet is already scheduled, but its execution is still not
started, it will be executed only once.
* If this tasklet is already running on another CPU (or schedule is
called from tasklet itself), it is rescheduled for later.
* Tasklet is strictly serialized wrt itself, but not
wrt another tasklets. If client needs some intertask synchronization,
he makes it with spinlocks. [...]我们将很快显示tasklet_schedule()功能。前面注释块中的最后一点将在本书的最后两章中讨论。
那么,我们如何使用小任务呢?首先,我们要用tasklet_init() API 来设置;然后,我们必须安排执行。让我们学习如何做到这一点。
tasklet_init()函数初始化一个小任务;其签名如下:
#include <linux/interrupt.h>
void tasklet_init(struct tasklet_struct *t, void (*func)(unsigned long), unsigned long data);让我们来看看它的参数:
struct tasklet_struct *t:这个结构是表示小任务的元数据。正如你已经知道的,指针本身没有记忆!记得给数据结构分配内存,然后在这里传递指针。void (*func)(unsigned long):这是小任务函数本身–hardirq 完成后运行的“下半部分”;该下半部分功能执行大部分中断处理过程。unsigned long data:你希望传递给小任务例程的任何数据项(一个 cookie)。
这个初始化工作应该在哪里进行?通常,这是在驾驶员的探头(或init)功能中完成的。那么,现在它已经初始化并准备好了,我们如何调用它呢?我们来看看。
小任务是下半部分。因此,在上半部分,也就是你的 hardirq 处理程序例程中,你在返回之前应该做的最后一件事就是“安排”你的小任务执行:
void tasklet_schedule(struct tasklet_struct *t);只需将指向你的(初始化的)小任务结构的指针传递给tasklet_schedule()API;内核将处理剩下的。内核是做什么的?它计划执行这个小任务;实际上,您的小任务的函数代码保证在控制返回到最初被中断的任务(无论是用户还是内核线程)之前运行。更多细节可以在了解内核如何运行软件部分找到。
关于小任务,有几件事你需要清楚:
- 小任务在中断(原子)上下文中执行其代码;这实际上是一个软上下文。所以,记住,所有适用于上半部分的限制也适用于这里!(查看中断上下文指南–做什么和不做什么部分了解限制的详细信息)
- 同步(在 SMP 盒上):
- 给定的小任务永远不会与其自身并行运行。
- 不同的小任务可以在不同的 CPU 内核上并行运行。
- 你的小任务本身可以被 hardirq 打断,包括你自己的 irq!这是因为,默认情况下,小任务在本地内核上所有中断都被启用的情况下运行,当然,hardirq 是系统的最高优先级
- 锁定含义确实很重要——我们将在本书的最后两章详细介绍这些领域(尤其是当我们介绍自旋锁时)。
一些(通用驱动程序)示例代码如下(为了清楚起见,我们避免显示任何错误路径):
#include <"convenient.h"> // has the PRINT_CTX() macro
static struct tasklet_struct *ts;
[...]
static int __init mydriver_init(void)
{
struct device *dev;
[...]
/* Register the device with the kernel 'misc' driver framework */
ret = misc_register(&keylog_miscdev);
dev = keylog_miscdev.this_device;
ts = devm_kzalloc(dev, sizeof(struct tasklet_struct), GFP_KERNEL);
tasklet_init(ts, mydrv_tasklet, 0);
ret = devm_request_irq(dev, MYDRV_IRQ, my_hardirq_handler,
IRQF_SHARED, OURMODNAME, THIS_MODULE);
[...]在前面的代码片段中,我们声明了一个全局指针ts,指向struct tasklet_struct;在驱动程序的init 代码中,我们将驱动程序注册为属于misc 内核框架。接下来,我们为小任务结构分配内存(通过有用的devm_kzalloc()应用编程接口)。接下来,我们通过tasklet_init()应用编程接口初始化小任务。请注意,我们指定了函数名(第二个参数),并简单地将0作为第三个参数传递,这是要传递的 cookie(许多真正的驱动程序在这里传递它们的上下文/私有数据结构指针)。然后,我们分配了一条内部评级线(通过devm_request_irq()应用编程接口)。
让我们继续看这个通用驱动程序的代码:
/ * Our 'bottom half' tasklet routine */
static void mydrv_tasklet(unsigned long data)
{
PRINT_CTX(); // from our convenient.h header
process_it(); // majority of the interrupt work done here
}
/* Our 'hardirq' interrupt handler routine - our 'top half' */
static irqreturn_t my_hardirq_handler(int irq, void *data)
{
/* minimal work: ack/disable hardirq, fetch and/or queue data, etc ... */
tasklet_schedule(ts);
return IRQ_HANDLED;
}在前面的代码中,让我们假设我们做了上半部分所需的任何最小的工作(函数my_hardirq_handler())。然后我们启动了我们的小任务,这样它就可以通过调用tasklet_schedule()应用编程接口来运行。你会发现小任务几乎会在 hardirq 之后立即运行(在前面的代码中,小任务函数被称为mydrv_tasklet())。在小任务中,您需要执行大部分的中断处理工作。其中,我们称我们的宏为PRINT_CTX();正如您将在完全理解上下文部分看到的,它打印了关于我们当前上下文的各种细节,这有助于调试/学习(您会发现它显示了我们当前正在中断上下文中运行)。
您可以通过tasklet_hi_schedule()应用编程接口使用替代例程来代替tasklet_schedule()应用编程接口。这在内部使得小任务成为最高优先级软任务(软任务优先级0)!(更多信息可以在了解内核软 irq 机制部分找到。)请注意,这几乎从未完成;小任务享有的默认(softirq)优先级通常已经足够了。将其设置为hi级别实际上只是针对极端情况;尽可能避免。
On version 5.4.0 Linux, there are 70-odd instances of the tasklet_hi_schedule() function being used by drivers. The drivers are typically high-performance network drivers – a few GPU, crypto, USB, and mmc drivers, as well as a few other drivers.
说到小任务,内核一直在进化。Kees Cook 和其他人最近(截至撰写本文时,2020 年 7 月)修补程序正在寻求更新小任务例程(回调)。更多信息请访问https://www . open wall . com/list/kernel-Harding/2020/07/16/1。
此时,您明白了下半部分,即小任务,是一种延迟的功能机制,在运行时不会屏蔽中断。它们旨在让您两全其美:如果情况需要,它们允许驱动程序进行相当长的中断处理和以延迟安全的方式进行,同时允许系统业务(通过硬件中断)继续。
您已经学习了如何使用小任务——这是延迟功能机制的一个很好的例子。但是它们是如何在内部实现的呢?内核通过名为 softirq (或软件中断)机制*的底层工具实现小任务。*虽然从表面上看,它们类似于我们之前看到的线程中断,但在许多重要方面确实非常不同。软 IRQ 的以下特征将帮助您理解它们:
- Softirqs 是一种纯内部内核延迟功能机制,因为它们是在内核编译时静态分配的(它们都被硬编码到内核中);您不能动态创建新的 softirq。
- 内核(从 5.4 版本开始)总共提供 10 个独立的软件:
- 每一个 softirq 都是为了满足特定的需求而设计的,通常与特定的硬件中断或内核活动有关。(这里的例外可能是为通用小任务保留的软 IRQ:
HI_SOFTIRQ和TASKLET_SOFTIRQ。) - 这 10 个软 IRQ 有一个优先顺序(并将按此顺序消费)。
- 事实上,小任务是特定 softirq (
TASKLET_SOFTIRQ)之上的一个精简抽象,它是 10 个可用软件之一。小任务是唯一一个可以随意注册、运行和注销的小任务,这使得它成为许多设备驱动程序的理想选择。
- 每一个 softirq 都是为了满足特定的需求而设计的,通常与特定的硬件中断或内核活动有关。(这里的例外可能是为通用小任务保留的软 IRQ:
- softirq 在中断-soft IRQ-上下文中运行。
in_softirq()宏在这里返回true,暗示你处于一个 softirq(或小任务)上下文中。 - 所有软件维护都被认为是系统的高优先级。在硬件中断(即
hardirq/ISR/primary处理程序)旁边,softirq 在系统中具有最高优先级。在首先被中断的过程上下文被恢复之前,挂起的软件请求被内核消耗。
*下图是我们先前在标准 Linux 上描述优先级的超集;这一个包括软 IRQ(其中是小任务):

Figure 4.10 – Relative priorities on standard Linux, showing softirqs as well
所以,是的,如你所见,软 IRQ 是 Linux 上一个非常高优先级的机制;有 10 个不同的优先事项。它们是什么,它们的目的是什么,将在下一小节中介绍。
给定 softirq 执行的工作被静态编译到内核映像中(这是固定的)。软 irq 和它所采取的动作(实际上,它通过action函数指针运行的代码)的这种耦合是通过以下代码完成的:
// kernel/softirq.c
void open_softirq(int nr, void (*action)(struct softirq_action *))
{
softirq_vec[nr].action = action;
}下图是 Linux 上可用软 irq 及其优先级的概念性表示(从内核版本 5.4 开始),其中0是最高的,9是最低的软 IRQ 优先级:

Figure 4.11 – The 10 softirqs on Linux in order of priority (0:highest, 9:lowest)
下表按照优先级顺序(T0)总结了单个内核的软 IRQ:HI_SOFTIRQ是优先级最高的一个,以及动作或向量、它的功能和提到它的用例的注释:
| 软 irq# | 软 irq | 评论(它用于/做什么) | “动作”或“矢量”功能 |
| 0 | HI_SOFTIRQ | 高任务:最高优先级软件;调用tasklet_hi_schedule()时使用。对于大多数用例,不建议这样做。请改用常规小任务(softirq # 6)。 | tasklet_hi_action() |
| 1 | TIMER_SOFTIRQ | 定时器:定时器中断的下半部分运行过期的定时器以及其他“内务”任务(包括调度器 CPU runqueue + vruntime更新、众所周知的jiffies_64变量的增量等)。 | run_timer_softirq() |
| 2 | NET_TX_SOFTIRQ | 网络:网络堆栈传输路径下半部分(qdisc)。 | net_tx_action() |
| 3 | NET_RX_SOFTIRQ | 网络:网络栈接收路径下半部分(NAPI 轮询)。 | net_rx_action() |
| 4 | BLOCK_SOFTIRQ | 阻塞:阻塞处理(完成输入输出操作;调用模块 MQ 的完整功能,blk_mq_ops)。 | blk_done_softirq() |
| 5 | IRQ_POLL_SOFTIRQ | irqpoll :实现内核的块层轮询 IRQ 模式(相当于网络层的 NAPI 处理)。 | irq_poll_softirq() |
| 6 | TASKLET_SOFTIRQ | 常规小任务:实现小任务下半部机制,唯一动态(灵活)的 softirq:可以根据需要由驱动注册、使用、注销。 | tasklet_action() |
| 7 | SCHED_SOFTIRQ | sched :用于 SMP 上 CFS 调度器的周期性负载均衡;如果需要,将任务迁移到其他运行队列。 | run_rebalance_domains() |
| 8 | HRTIMER_SOFTIRQ | HRT :用于高分辨率定时器 ( HRT )。它在 4.2 版本中被删除,并在 4.16 版本中以更好的形式重新进入内核。 | hrtimer_run_softirq() |
| 9 | RCU_SOFTIRQ | RCU :执行读拷贝更新 ( RCU )处理,这是内核内部使用的一种无锁技术。 | rcu_core_si() / rcu_process_callbacks() |
很有意思;网络和块堆栈是非常高优先级的代码路径(定时器中断也是如此),因此它们的代码必须尽快运行。因此,他们有显式的软件来服务这些关键的代码路径。
我们能看到到目前为止已经发射的软件吗?当然,非常像我们如何查看 hardirqs(通过其proc/interrupts伪文件)。我们有/proc/softirqs伪文件来跟踪软件。下面是我的原生(四核)x86_64 Ubuntu 系统的截图示例:

Figure 4.12 – Output of /proc/softirqs on a native x86_64 system with 4 CPU cores
就像/proc/interrupts一样,上一张截图中显示的数字描述了从系统启动开始,特定软错误在特定 CPU 内核上发生的次数。此外,功能强大的crash工具 FYI 有一个有用的命令irq,显示关于中断的信息;irq -b显示该内核上定义的软 IRQ。
以下是在 x86 上触发硬件中断时使用的(近似)调用图:
do_IRQ() -> handle_irq() -> entering_irq() -> hardirq top-half runs -> exiting_irq() -> irq_exit() -> invoke_softirq() -> do_softirq() -> ... bottom half runs: tasklet/softirq ... -> restore context前面的一些代码路径是依赖于 arch 的。请注意,“将上下文标记为中断”上下文实际上是一个工件。内核被标记为已经在entering_irq()函数中进入该上下文,并且一旦exiting_irq()返回(在 x86 上)就离开它。但是坚持住!exiting_irq()内联函数调用kernel/softirq.c:irq_exit()函数。正是在这个例程中,内核处理并消耗所有待定的软 IRQ。基本调用图(从do_softirq()开始)如下:
do_softirq() -- [assembly]do_softirq_own_stack -- __do_softirq()真正的工作发生在内部__do_softirq()例程中(https://酏. bootin . com/Linux/v 5.4/source/kernel/softirq . c # L249)。在这里,任何未决的软件都按优先级顺序消耗。请注意,softirq 处理是在上下文恢复到中断的任务之前完成的。
现在,让我们简单关注一下小任务执行的一些内部细节,接下来是如何使用 ksoftirqd 内核线程来卸载 softirq 工作。
一个关于小任务调用内部的词:我们知道小任务软件通过tasklet_schedule()运行。该 API 最终调用内核内部的__tasklet_schedule_common()函数(https://酏. boot in . com/Linux/v 5.4/source/kernel/softirq . c # L471),该函数内部调用raise_softirq_irqoff(softirq_nr)(https://酏. boot in . com/Linux/v 5.4/source/kernel/softirq . c # L423)。这提高了softirq_nr软 IRQ;对于常规的小任务,这个值是TASKLET_SOFTIRQ,而当通过tasklet_hi_schedule() API 调度小任务时,这个值是HI_SOFTIRQ,最高优先级的软任务!很少使用它,如果有的话。
我们现在知道“时间表”功能已经设置了 softirq 在这里,实际执行发生在该优先级的 softirqs(这里是0或6)实际运行的时候。运行 softirqs 的函数叫做do_softirq();对于常规小任务,它最终调用tasklet_action() softirq 向量(如上表所示);这就调用了tasklet_action_common()(https://酏剂. boot in . com/Linux/v 5.4/source/kernel/softirq . c # L501),它(在一些列表设置之后)启用硬件中断(通过local_irq_enable()),然后循环每个 CPU 的小任务列表,消耗(运行)其上的小任务功能。你有没有注意到这里提到的几乎所有功能都是独立的?-这是好事。
当有大量软件等待处理时,它们会给系统带来巨大的负载。这在网络(以及某种程度上的块)层中反复出现,导致轮询模式 IRQ 处理的发展;对于网络(接收)路径,它被称为 NAPI,对于数据块层,它只是简单的中断轮询处理。但是,如果即使使用轮询模式处理,软件泛滥仍然存在呢?内核还有一个锦囊妙计:如果 softirq 处理时间超过 2 毫秒,内核会将挂起的 softirq 工作卸载到名为ksoftirqd/n的每个 CPU 内核线程上(其中n代表 CPU 数量,从0开始)。这种方法的一个好处是,因为内核线程必须与其他线程竞争 CPU 资源,所以用户空间最终不会完全缺乏 CPU(这可能发生在纯 hard rq/soft IRQ 负载的情况下)。
这听起来是一个不错的解决方案,但现实世界却不一样。2019 年 2 月,一系列用于设置 softirq 矢量细粒度屏蔽的补丁看起来很有希望,但最终似乎失败了(请阅读进一步阅读部分中提供的非常有趣的细节)。以下来自 Linus Torvalds 的邮件很好地澄清了真正的问题(https://lore . kernel . org/lkml/CAHk-= wgOZuGZaVOOiC = drg6ykvkogk 8 rrxz _ CrPBMXHKjTg0dg @ mail . Gmail . com/# t):
... Note that this is all really fairly independent of the whole masking
logic. Yes, the masking logic comes into play too (allowing you to run
a subset of softirq's at a time), but on the whole the complaints I've
seen have not been "the networking softirq takes so long that it
delays USB tasklet handling", but they have been along the lines of
"the networking softirq gets invoked so often that it then floods the
system and triggers [k]softirqd, and _that_ then makes tasklet handling
latency go up insanely ..."声明的最后一部分一针见血。
So, this begs the question: can we measure hardirq/softirq instances and latencies? We cover this in the section Measuring metrics and latency.
正如我们在小任务方面所了解到的,必须从软件方面理解并发的一些要点:
- 正如小任务(在 SMP 上)所指出的,小任务永远不会与自身并行运行;这是一个更容易使用的特性。软 irq 不是这样:同一个软 IRQ 向量确实可以在另一个 CPU 上与自身并行运行!因此,softirq 矢量代码在使用锁定(和避免死锁)时必须特别小心。
- 一个软 irq 总是可以被一个 hardirq 中断,包括导致它被引发的 irq(这是因为,和小任务一样,软 IRQ 在本地内核上所有中断都被启用的情况下运行)。
- 一个 softirq 不能抢占另一个当前正在执行的 softirq,即使它们具有优先级;它们按优先级顺序被消耗。
- 现实是内核提供了像
spin_lock_bh()这样的 API,允许你在锁被持有时禁用 softirq 处理。当 hardirq 和 softirq 处理程序都在处理共享数据时,这是防止死锁所必需的。锁定的含义确实很重要。我们将在本书的最后两章详细介绍这一点。
如您所知,hardirq 代码旨在进行最简单的设置和中断处理,通过我们之前讨论的延迟功能机制,即小任务和/或 softirq,以安全的方式执行大部分中断处理。这种“下半部分”以及延迟功能处理是按优先级顺序执行的——首先是 softirq 内核定时器,然后是小任务(这两者都只是底层 softirq 机制的特例),然后是线程中断,最后是工作队列(后两者使用底层内核线程)。
所以,最大的问题是,当你写你的驱动程序时,你应该使用哪一个?你应该使用延迟机制吗?这真的取决于时间量 你的完整中断处理需要来完成。如果您的完整中断处理可以在几微秒内持续完成,那么只需使用上半部分 hardirq 不需要其他东西。
但如果事实并非如此呢?请看下表;第一列指定了完成中断处理所需的总时间,而其他列提供了一些关于其使用的建议以及优缺点:
| 时间:如果硬件中断处理始终需要 | 做什么 | 前进/后退 | | < = 10 微秒 | 仅使用 hardirq(上半部分);不需要其他东西。 | 最佳案例;不典型。 | | 在 10 到 100 微秒之间 | 要么只有 hardirq,要么同时有 hardirq 和一个小任务(softirq)。 | 运行压力测试/工作负载,看看是否真的需要一个小任务。对于线程处理程序或工作队列,不建议使用它。 | | 100 微秒,非关键设备 | 使用主处理器(hard rq);也就是说,要么使用自己的处理函数(如果需要硬件特定的工作),要么简单地使用内核默认值和一个线程处理程序。或者,如果可以接受,只需使用工作队列(将在下一章中介绍)。 | 这避免了 softirq 处理,这有助于减少系统延迟,但会导致处理速度稍慢。这是因为线程处理程序与其他线程争夺 CPU 时间。工作队列也基于内核线程,具有相似的特征。 | | 100 微秒,关键设备(通常是网络、数据块和一些多媒体设备) | 使用主处理器(hard rq/上半部分)和小任务(下半部分)。 | 当大量中断到达时,它会优先处理设备。这也是一个缺点,因为这会导致“活锁”问题和长时间的软延迟“泛滥”!测试并确定。 | | 100 微秒,极其关键的工作/设备 | 使用一个主处理器(hardirq/上半部分)和一个 hi-tasklet 或者(可能)你自己的(新的!)softirq。 | 这是一个相当极端、不太可能的情况;要添加自己的 softirq,您需要更改内部(GPL-ed)内核代码。这使得维护成本很高(除非你的核心内核改变+驱动是上游贡献的!). |
当然,第一列中以微秒为单位的时间是有争议的,取决于牌局,并且可以(也将)随着时间而改变。100 微秒作为基线的建议值只是一种试探。
正如我们已经提到的,softirq 处理本身应该在几百微秒内完成;大量未处理的软请求会再次导致活锁情况。内核以两种广泛的方式减轻(或消除)这种风险:
- 线程中断或工作队列(均基于内核线程)
- 调用
ksoftirqd/n内核线程接管软 irq 处理
前面的案例在进程上下文中运行,因此缓解了真正的(用户空间)线程通过调度器需要中央处理器的问题(因为内核线程本身必须竞争中央处理器资源)。
关于上表的最后一行,创建一个新 softirq 的唯一方法是真正深入内核代码并修改它。这里,我们指的是修改(GPL 许可的)内核代码库。就嵌入式项目而言,修改内核源代码并不少见。但是,添加 softirq 被认为(非常)不常见,而且根本不是一个好主意,因为如果没有更多的 soft IRQ 处理来应对,延迟可能已经很高了!这种情况已经很多年没有发生了。
在实时性和确定性方面,在配套指南 Linux 内核编程、 第 11 章、CPU 调度程序–第 2 部分中,在查看结果部分,我们提到在运行标准 Linux 的微处理器上,中断处理中的抖动(时间方差)约为+/- 10 微秒。有了 RTL 内核,它会好得多,但不是百分之百确定。那么,你能完全确定 Linux 上的中断处理吗?一个有趣的方法是使用 FIQs ,也就是某些处理器(尤其是 ARM)提供的所谓快速中断机制。它们在 Linux 内核的范围之外工作,这就是为什么编写一个 FIQ 中断处理程序可以消除任何内核引起的抖动。更多信息请看这篇文章:https://boot in . com/blog/fiq-handlers-in-arm-Linux-kernel/。
最后,值得一提的是(在撰写本文时),这里正在进行大量的重新思考:一些内核开发人员的观点是,不再需要整个上半部分下半部分机制。然而,事实是这种机制被深深地嵌入到内核结构中,使得移除它变得非常重要。
中断上下文指南–做什么和不做什么部分明确指出:当您处于任何类型的中断(或原子)上下文中时,不要调用任何可能阻塞的 API(最终调用schedule())*;*这真的归结为几个关键点(正如我们看到的)。一个是你不应该进行任何内核到用户空间(反之亦然)的数据传输;另外,如果必须分配内存,请使用GFP_ATOMIC标志。
这当然引出了一个问题:**我如何知道我的驱动程序(或模块)代码当前是在进程还是中断(原子)上下文中运行?**此外,如果它在中断上下文中运行,它是在上半部分还是下半部分?对这一切的简单回答是内核提供了几个宏,你可以用它们来解决这个问题。这些宏在linux/preempt.h标题中定义。我们将在这里显示相关的内核注释头,而不是不必要地重复信息;它清楚地命名和描述了这些宏:
// include/linux/preempt.h[...]/*
* Are we doing bottom half or hardware interrupt processing?
*
* in_irq() - We're in (hard) IRQ context
* in_softirq() - We have BH disabled, or are processing softirqs
* in_interrupt() - We're in NMI,IRQ,SoftIRQ context or have BH disabled
* in_serving_softirq() - We're in softirq context
* in_nmi() - We're in NMI context
* in_task() - We're in task context
[...]We covered a subset of this topic in the companion guide Linux Kernel Programming, Chapter 6, Kernel Internals Essentials – Processes and Threads, under the Determining the context section.
所以,很简单;在我们的convenient.h头(https://github . com/PacktPublishing/Linux-Kernel-Programming-Part-2/blob/main/便捷. h )中,我们定义了一个名为PRINT_CTX()的便捷宏,当被调用时,它会将当前上下文打印到内核日志中。这封邮件的格式非常刻意。以下是调用时发出的典型输出的示例:
001) rdwr_drv_secret :29141 | .N.0 /* read_miscdrv_rdwr() */一开始,你可能会觉得这种格式很奇怪。然而,我只是遵循内核的 Ftrace(延迟)输出格式来显示上下文(除了DURATION列;我们这里没有)。Ftrace 输出格式得到了开发人员和内核用户的良好支持和理解。以下输出向您展示了如何解释它:
The Ftrace 'latency-format'
_-----= irqs-off [d]
/ _----= need-resched [N]
| / _---= hardirq/softirq [H|h|s] [1]
|| / _--= preempt-depth [#]
||| /
CPU TASK PID |||| FUNCTION CALLS
| | | |||| | | | |
001) rdwr_drv_secret :29141 | .N.0 /* read_miscdrv_rdwr() */
[1] 'h' = hard irq is running ; 'H' = hard irq occurred inside a softirq这可能非常有用,因为它可以帮助您理解并调试困难的情况!您不仅可以看到正在运行什么(它的名称和 PID,以及在哪个 CPU 内核上),还可以看到四个有趣的列(以粗体(.N.0)突出显示)。前面这四列的 ASCII 艺术视图实际上与 Ftrace 本身生成的相同。让我们来解释一下这四列(在我们这里的例子中,是值.N.0):
-
第 1 栏:IRQ 状态。如果中断被启用(通常情况下),则显示
.,如果中断被禁用,则显示d。 -
第 2 列:位状态
TIF_NEED_RESCHED。如果1,内核将在下一个机会点调用schedule()(从系统调用返回或从中断返回,以先到者为准)。设置时显示N,清除时显示.。 -
第 3 列:如果我们处于中断上下文中,我们可以使用更多的宏来检查我们是处于 hardirq(上半部分)还是 softirq(下半部分)上下文中。它显示如下:
.:流程(任务)上下文- 中断/原子上下文:
h:哈迪克在跑H:hardiq 发生在软 irq 内部(也就是说,hardiq 发生在软 irq 执行时,中断了它)s: Softirq(或小任务)上下文
-
第 4 列:一个名为
preempt_depth的整数值(来自位掩码)。本质上,它在每次锁定时递增,在每次解锁时递减。所以,如果它是正的,它意味着代码在一个关键的或原子的部分。
以下是我们对convenient.h:PRINT_CTX()宏的(部分)代码实现(仔细研究代码,并使用代码中的宏来理解它):
// convenient.h
[...]
#define PRINT_CTX() do { \
int PRINTCTX_SHOWHDR = 0; \
char intr = '.'; \
if (!in_task()) { \
if (in_irq() && in_softirq()) \
intr = 'H'; /* hardirq occurred inside a softirq */ \
else if (in_irq()) \
intr = 'h'; /* hardirq is running */ \
else if (in_softirq()) \
intr = 's'; \
} \
else \
intr = '.'; \它基本上以if条件为中心,并通过in_task()宏检查代码是否在进程(或任务)上下文中,因此是否在中断(或原子)上下文中。
You might have come across the in_interrupt() macro being used in situations like this. If it returns true, your code is within an interrupt context, while if it returns false, it isn't. However, the recommendation for modern code is to not rely on this macro (and in_softirq()) due to the fact that bottom-half disabling can interfere with its correct working). Hence, we use in_task() instead.
让我们继续看PRINT_CTX()宏的代码:
[...]
if (PRINTCTX_SHOWHDR == 1) \
pr_debug("CPU) task_name:PID | irqs,need-resched,hard/softirq,preempt-depth /* func_name() */\n"); \
pr_debug( \
"%03d) %c%s%c:%d | " \
"%c%c%c%u " \
"/* %s() */\n" \
, smp_processor_id(), \
(!current-mm?'[':' '), current-comm, (!current-mm?']':' '), current-pid, \
(irqs_disabled()?'d':'.'), \
(need_resched()?'N':'.'), \
intr, \
(preempt_count() && 0xff), __func__); \
} while (0)如果PRINTCTX_SHOWHDR变量设置为1,则打印一个表头行;默认情况下是0。这是宏发出(调试级)printk(通过pr_debug())的地方,它以 Ftrace(延迟)格式显示上下文信息,如前面的代码片段所示。
例如,在我们的ch1/miscdrv_rdwr杂项驱动程序代码(实际上还有其他几个)中,我们使用了这个宏(PRINT_CTX())来显示上下文。以下是我们简单的rdwr_drv_secret应用从驱动程序读取“秘密信息”时的一些示例输出(为了清晰起见,我删除了dmesg时间戳):
CPU) task_name:PID | irqs,need-resched,hard/softirq,preempt-depth /* func_name() */
001) rdwr_drv_secret :29141 | .N.0 /* read_miscdrv_rdwr() */标题行显示了如何解释输出。(事实上,默认情况下,此标题行是关闭的。我暂时把PRINTCTX_SHOWHDR变量的值改成了1在这里显示。)
以下是运行(下半部分)小任务代码时(树外)驱动程序的另一个示例(我们在部分介绍了小任务理解和使用上下半部分部分):
000) gnome-terminal- :3075 | .Ns1 /* mydrv_tasklet() */让我们更详细地解释前面的输出;从左到右:
-
000):小任务在 CPU 核0上运行。 -
被此中断的任务是带有 PID
3075的gnome-terminal*-*过程。实际上,它可能被在这个小任务运行之前触发的 hardirq 中断了,并且只有在小任务完成后才会恢复执行——最好的情况。 -
我们可以从前面的四列输出(第
.Ns1部分)中推断出以下内容:.:所有中断(在本地核心上,核心#0)被使能。N:置位TIF_NEED_RESCHED位(表示下一个调度“机会点”命中时调度程序代码将运行;意识到它将很可能由gnome-terminal-线程运行(在进程上下文中)。s:小任务是一个中断——更准确的说是一个软 IRQ——上下文(准确的说是TASKLET_SOFTIRQ软 IRQ);原子环境;这是意料之中的——我们正在运行一个小任务!1:preempt_depth的值为1;这意味着当前持有(自旋)锁(同样,这意味着我们当前处于原子环境中)。
-
在小任务上下文中运行的驱动函数被称为
mydrv_tasklet()。
Often, when viewing a capture like this, in interrupt context, the interrupted task shows up as the swapper/n kernel thread (where n is the CPU core's number). This typically implies that the swapper/nkernel thread was interrupted by the hardirq, further implying that the interrupt triggered while that CPU was in an idle state (since the swapper/n threads only run then), which is a pretty common occurrence on a lightly loaded system.
既然您已经了解了色域中的许多领域,我们可以缩小范围,看看 Linux 内核是如何区分事情优先级的。以下(概念性)图表——早期类似图表的超集——巧妙地总结了这一点:

Figure 4.13 – Relative priorities across the full stack - user, kernel process context, and kernel interrupt contexts
这个图很不言自明,请仔细研究一下。
在这个冗长的部分中,您已经通过上半部分和下半部分机制了解了中断处理,首先了解了中断处理的原因,以及中断处理是如何组织的并被驱动程序使用的。你现在明白了,所有的下半部分机制都是通过 softirqs 在内部实现的;小任务是主要的下半部分机制,作为驱动程序作者,您可以轻松使用它。当然,这并不意味着你必须使用它们——如果你可以简单地只使用上半部分,或者更好的是,只使用一个线程处理程序,那就太好了。hardirks、小任务和线程处理程序–当部分详细介绍了这些注意事项时使用什么。
说完了,我们就快完了!但是,一些杂七杂八的区域还是需要穿越的。让我们通过熟悉的常见问题格式跳进去看看吧!
以下是一些关于硬件中断及其处理方式的常见问题。我们还没有触及这些领域:
- 在多核系统上,所有硬件中断都路由到一个 CPU 吗?如果没有,它们是如何进行负载平衡的?我能换这个吗?
- 内核是否维护独立的 IRQ 栈?
- 如何获取中断的度量?我可以测量中断延迟吗?
这里的想法是提供简短的答案;我们鼓励你深入挖掘,亲自尝试!冒着重复的风险,记住经验方法是最好的!
首先,在多核(SMP)系统中,硬件中断路由到 CPU 内核的方式往往是特定于主板和中断控制器的。说到这里,Linux 上的通用 IRQ 层提供了一个非常有用的抽象:它允许(并实现)中断负载平衡,这样就不会有(一组 CPU 中的)CPU 过载。甚至还有前端实用程序irqbalance(1)和irqbalance-ui(1),允许管理员(或根用户)执行 IRQ 平衡(irqbalance-ui是irqbalance的ncurses前端)。
你能改变发送到处理器内核的中断吗?是的,通过/proc/irq/IRQ/smp_affinity伪文件!它是一个位掩码,指定了这个 IRQ 允许路由到的 CPU。问题是默认设置总是默认允许所有 CPU 内核处理中断。例如,在具有八个内核的系统上,IRQ 线路的smp_affinity值将是0xff(二进制1111 1111)。为什么这是个问题? CPU 缓存。简而言之,如果多个内核处理同一个中断,缓存会被丢弃,因此可能会发生许多缓存无效(以保持内存与中央处理器缓存的一致性),从而导致各种性能问题;在拥有数十个内核和多个网卡的高端系统上尤其如此。
We cover more on CPU caching issues in Chapter 7, Kernel Synchronization - Part 2 in the section Cache effects and false sharing.
It's recommended that you keep a single important IRQ line (such as the Ethernet interrupt) affined to a particular CPU core (or at most, to a physical core that is hyperthreaded). Not only that, but keeping the related network application processes and threads affined to the same core will (probably) result in better performance (we covered process/thread CPU affinity in the companion guide Linux Kernel Programming - Chapter 11, The CPU Scheduler - Part 2 , in the Understanding, querying, and setting the CPU affinity mask section).
让我们再看几个要点:
/proc/interrupts的输出将反映 IRQ 亲和力(和 IRQ 平衡),并允许您查看有多少中断被路由到系统上的哪个中央处理器内核。(我们在查看所有分配的中断(IRQ)行一节中详细解释了它的输出。)irqbalance服务实际上会导致问题,因为它在启动时会将 IRQ 关联性设置恢复为默认值(https://UNIX . stackexchange . com/questions/68812/making-a-IRQ-SMP-affinity-change-permanent);如果您正在仔细调整设置(可能在启动时通过rc.local或等效的systemd脚本),您可能想要禁用它。)更新版本的irqbalance允许你禁用 IRQ 线路,不会(重新)设置。
在 第 6 章**内核内部和本质——进程和线程的配套指南中,在组织进程、线程及其堆栈——用户和* 内核空间部分,我们介绍了一些要点:每个单个用户空间线程都有两个堆栈:用户空间堆栈和内核空间堆栈。当线程在非特权用户空间运行时,它利用用户模式堆栈,而当它切换到特权内核空间时(通过系统调用或异常),它使用其内核模式堆栈工作(返回参考配套指南 Linux 内核编程中的图 6.3 )。接下来,内核模式堆栈非常有限,并且大小固定——只有 2 或 4 页长(取决于您的 arch 是 32 位还是 64 位)!*
因此,假设您的驱动程序代码(比如说ioctl()方法)在一个深度嵌套的代码路径中运行。这意味着该进程上下文的内核模式堆栈已经加载了大量元数据——它所调用的每个函数的堆栈框架。现在,一个硬件中断来了!归根结底,这也是必须运行的代码,因此需要堆栈。我们可以让它简单地使用已经在运行的现有内核模式堆栈,但是这大大增加了堆栈溢出的机会(假设我们嵌套很深并且堆栈很小)。内核中的堆栈溢出是灾难性的,因为系统将简单地挂起/死亡,而没有关于根本原因的真正线索(嗯,CONFIG_VMAP_STACK内核配置正是为了缓解这种情况而引入的,并且默认情况下在 x86_64 上设置)。
因此,长话短说,在几乎所有现代架构上,内核为每个 CPU 分配一个单独的内核空间堆栈用于硬件中断处理。这就是所谓的 IRQ 堆栈。当硬件中断到达时,堆栈位置(通过适当的中央处理器堆栈指针寄存器)被切换到正在处理中断的中央处理器的 IRQ 堆栈(并在 IRQ 退出时恢复)。一些 arch(PPC)有一个名为CONFIG_IRQSTACKS的内核配置来启用 IRQ 堆栈。IRQ 堆栈的大小是固定的,因为该值依赖于拱形。在 x86_64 上,它有 4 页长(16 KB,典型的 4K 页面大小)。
在某种程度上,我们已经在配套指南 Linux 内核编程- 第 11 章**中央处理器调度器–第 2 部分中延迟及其测量部分讨论了什么是延迟以及如何测量调度延迟。在这里,我们将了解系统延迟及其测量的更多方面。
大家已经知道,procfs 是丰富的信息来源;我们已经看到,每个 CPU 内核生成的 hardirqs 和 softirqs 的数量都可以通过/proc/interrupts和/proc/softirqs(伪)文件查看。类似信息可通过/proc/stat获得。
在配套指南 Linux 内核编程 - 第 1 章、内核工作空间设置中,在与【e】BPF的现代跟踪和性能分析部分,我们指出了(最近的 4.x) Linux 的现代跟踪、性能测量和分析方法是如何[ e]BPF 、增强的伯克利数据包过滤器(也叫 BPF)的。在 it 库存的过多工具中(https://github.com/iovisor/bcc#tools),有两个工具适合我们追踪、测量和分析中断(hardirqs 和 softirqs)的直接目的。(这些工具在 Ubuntu 上被命名为toolname-bpfcc,其中toolname是问题工具的名称,如hardirqs-bpfcc、softirqs-bpfcc)。这些工具动态跟踪中断(在编写时,它们还没有基于内核跟踪点)。您将需要 root 访问权限才能运行这些[e]BPF 工具。
Important: You can install the BCC tools for your regular host Linux distro by reading the installation instructions here: https://github.com/iovisor/bcc/blob/master/INSTALL.md. Why not do this on our guest Linux VM? You can do this when you're running a distro kernel (such as an Ubuntu- or Fedora-supplied kernel). The reason you can do this is because the installation of the BCC toolset includes (and depends on) the installation of the linux-headers-$(uname -r) package; this linux-headers package exists only for distro kernels (and not for our custom 5.4 kernel, which you might be running on the guest).
hardirqs[-bpfcc]工具显示维护硬件中断所花费的总时间。下面的截图显示我们正在运行hardirqs-bpfcc工具。在这里,您可以看到 3 秒钟内每 1 秒钟(第一个参数)维护 hardirqs 所花费的总时间(第二个参数):

Figure 4.14 – hardirqs-bpfcc showing the time that was spent servicing hardirqs every 1 second for 3 seconds
下面的截图显示了我们使用相同的工具生成硬 IRQ 时间分布的直方图(通过-d开关):

Figure 14.15 – hardirqs-bpfcc -d showing a histogram
请注意,大多数网络 hardirq(iwlwifi,其中 48 个)只需要 4 到 7 微秒就能完成,尽管少数(其中三个)需要 16 到 31 微秒。
你可以在上找到更多如何使用hardirqs[-bpfcc]工具的例子。查找它的手册页也是有益的。
类似于我们之前对 hardirqs 所做的,我们现在将使用softirqs[-bpfcc]工具。它显示为 softirqs(软件中断)服务所花费的总时间。同样,您将需要 root 访问权限来运行这些[e]BPF 工具。
首先,让我们的系统(运行 Ubuntu 的本机 x86_64)承受一些压力(这里,它执行网络下载、网络上传和磁盘活动)。下面的截图显示了我们正在运行softirqs-bpfcc工具,该工具提供了关于每 1 秒(第一个参数)维护 softirqs 所花费的总时间的信息(没有第二个参数):

Figure 4.16 – softirqs-bpfcc displaying the time that was spent servicing softirqs every 1 second (under some I/O stress)
请注意 tasklet softirq 是如何发挥作用的。
让我们看另一个使用相同工具生成软 IRQ 时间分布直方图的例子(通过-d开关,同样是在系统处于某种输入/输出-网络和磁盘-压力下)。下面的截图显示了我们运行sudo softirqs-bpfcc -d命令后得到的输出:

Figure 4.17 – softirqs-bpfcc -d showing a histogram (under some I/O stress)
同样,在这个小样本集中,大多数NET_RX_SOFTIRQ实例仅花费了 4 到 7 微秒,而大多数BLOCK_SOFTIRQ实例花费了 16 到 31 微秒来完成。
这些 BPF 工具也有手册页(同样,有例子)。我建议您在本机 Linux 系统上安装这些[e]BPF(参见配套指南 Linux 内核编程- 第 1 章、内核工作区设置、带有[e]BPF 的现代跟踪和性能分析部分)。看一看,自己试试工具。
Linux 内核本身内置了一个非常强大的跟踪引擎,名为 Ftrace *。*正如您可以通过用户空间中的(哦,太有用了)strace(1)(以及通过ltrace(1)的库 API)实用程序跟踪系统调用一样,您也可以通过 Ftrace 跟踪内核空间中运行的几乎每个函数。然而,Ftrace 不仅仅是一个功能跟踪器——它是一个框架,是内核底层跟踪基础设施的关键。
Steven Rostedt is the original author of Ftrace. His paper entitled Finding Origins of Latencies Using Ftrace is a very good read. You can find it here: https://static.lwn.nimg/conf/rtlws11/papers/proc/p02.pdf.
In this section, we don't intend to cover how to use Ftrace in an in-depth manner as it's really not part of the subject matter here. Learning to use Ftrace isn't difficult, and is a valuable weapon in your kernel debug armory! If you're unfamiliar with it, please go through the links we've provided on Ftrace in the Further reading section at the end of this chapter.
潜伏期是指某件事情应该发生的时间和实际发生的时间之间的延迟(理论和实践之间的半开玩笑的区别)。操作系统中的系统延迟可能是性能问题的根本原因。其中包括中断和调度延迟。但是这些延迟的真正原因是什么呢?借用史蒂夫·罗斯特特的论文(前面提到过),四个事件导致了这些延迟:
- 中断禁用:如果 IRQs 关闭,中断只有在开启后才能被服务(这里,我们将重点测量这一个。)
- 抢占被禁用:如果是这种情况,被唤醒的线程在抢占被启用之前无法运行。
- 调度延迟:一个线程被调度运行和它实际运行在一个内核上之间的延迟(我们在配套指南 Linux 内核编程- 第 11 章,CPU 调度器-第 2 部分中延迟及其测量一节中讨论了测量这个延迟。)
- 中断反转:当中断优先于优先级较高的任务运行时(类似于优先级反转,这可以硬实时发生;当然,如您所知,这正是线程处理程序是关键的原因)。
Ftrace 可以记录除最后一个以外的所有内容。在这里,我们将重点学习如何利用 Ftrace 来找到(或者实际上是采样)硬件中断被禁用的最坏情况时间。这被称为irqsoff延迟跟踪。走吧!
Ftrace 有许多可以使用的插件(或跟踪程序)。首先,您需要确保irqsoff延迟跟踪器(或 Ftrace 的插件)在内核中实际启用。您可以通过两种不同的方式进行检查:
- 检查内核配置文件(
grep中的CONFIG_IRQSOFF_TRACER)。 - 通过 Ftrace 基础设施检查可用的跟踪程序(或插件)。
我们将在这里选择后者:
$ sudo cat /sys/kernel/debug/tracing/available_tracers
hwlat blk mmiotrace function_graph wakeup_dl wakeup_rt wakeup function nop在前面的输出中,irqsoff跟踪器——我们需要的那个——丢失了!通常情况就是这样,这意味着您必须配置内核(打开它)并(重新)构建您的定制 5.4 内核。(这将在本章末尾的问题部分作为练习提供。)我们还建议您为 Ftrace 安装一个非常有用的名为trace-cmd(1)实用程序的前端(我们在配套指南 Linux 内核编程 - 第 1 章、内核工作区设置中提到了这个实用程序,并在第 11 章【CPU 调度程序-第 2 部分】中的部分使用 trace-cmd 可视化进行了使用)。
Lockdep can cause issues here: if enabled, it's really best to disable the kernel's lockdep feature when you're performing latency tracing (it could add too much overhead). We'll discuss lockdep in some detail in Chapter 7, Kernel Synchronization - Part 2.
一旦您启用了CONFIG_IRQSOFF_TRACER(并且安装了trace-cmd,请按照以下步骤让 Ftrace 的延迟跟踪器计算出最坏情况下的中断关闭延迟。不用说,这些步骤必须作为根来执行:
- 为自己获取一个根 Shell(您将需要根权限来做到这一点):
sudo /bin/bash- 重置 Ftrace 框架(这可以通过 Ftrace 的
trace-cmd(1)前端完成):
trace-cmd reset- 将目录更改为 ftrace 的目录:
cd /sys/kernel/debug/tracing它通常可以在这里找到。如果您将debugfs伪文件系统安装在不同的目录下,那么请将cd放在那里(并放在它下面的tracing目录下)。
- 使用
echo 0 tracing_on关闭所有追踪(确保在0和>符号之间留有空间)。 - 将
irqsoff跟踪器设置为当前跟踪器:
echo irqsoff current_tracer- 现在,打开跟踪:
echo 1 tracing_on
... it runs! ... - 以下输出显示了最坏情况
irqsoff latency(这通常以微秒为单位显示;不用担心,我们将很快展示一个示例运行):
cat tracing_max_latency
[...]- 获取并阅读完整的报告。所有 Ftrace 输出都保存在
trace伪文件中:
cp trace /tmp/mytrc.txt
cat /tmp/mytrc.txt- 重置 Ftrace 框架:
trace-cmd reset我们获得的输出如下所示:
# cat /tmp/mytrc.txt
# tracer: irqsoff
#
# irqsoff latency trace v1.1.5 on 5.4.0-llkd01
# --------------------------------------------------------------------
# latency: 234 us, #53/53, CPU#1 | (M:desktop VP:0, KP:0, SP:0 HP:0 #P:2)
# -----------------
# | task: sshd-25311 (uid:1000 nice:0 policy:0 rt_prio:0)
# -----------------
# = started at: schedule
# = ended at: finish_task_switch
[...]这里,最坏的情况irqsoff延迟是 234 微秒(在执行带有 PID 25311 的sshd任务时经历的),这意味着在这段时间内硬件中断是关闭的。为了方便起见,我提供了一个简单的包装器 Bash 脚本(ch4/irqsoff_latency_ftrc.sh)来完成同样的工作。
现在,我们将提到一些您可以用来测量系统延迟的其他有用工具。
以下是在捕获和分析系统延迟方面值得一提的几个工具(以及更多工具):
- 您可以学习如何设置和使用强大的 Linux 跟踪工具包–下一代 ( LTTng )工具集来记录运行中的系统跟踪。我强烈推荐使用高超的轨迹罗盘 GUI 来分析。事实上,在配套指南 Linux 内核编程- 第 1 章**内核工作区设置中,在 Linux Tracing Toolkit 下一代(LTTng) 部分,我们展示了 Trace Compass GUI 有趣的截图(图 1.9 )用于显示和分析 IRQ 第 1 行和第 130 行(i8042 和 Wi-Fi 的中断行
- 您也可以尝试使用
latencytop工具来确定哪个内核操作哪些用户空间线程被阻塞。为此,您必须在内核配置中打开CONFIG_LATENCYTOP。 - 除了延迟度量,您还可以使用
dstat(1)、mpstat(1)、watch(1)等获得中断的“顶级”视图(https://UNIX . stackexchange . com/questions/8699/是否有解释-proc-中断-数据-时间的实用程序)。
至此,我们已经完成了这一部分和这一章。
恭喜你!这一章很长,但很有价值。关于如何处理硬件中断,您将学到很多东西。在了解作为驱动程序作者,您必须如何处理中断之前,我们先简单了解一下操作系统如何处理中断。为此,您学习了如何通过几种方法分配 IRQ 线路(并释放它们)和实现硬件中断例程。在这里,讨论了几个限制和警告,基本上归结为这是一个原子活动的事实。然后介绍了“线程中断”模型的方式和原因;它通常被认为是现代处理中断的推荐方式。之后,我们了解并学习了如何与 hard rqs/soft irqs 和上/下半部分合作。最后,我们以典型的常见问题解答的形式,讲述了关于负载平衡中断、IRQ 堆栈以及如何使用一些有用的框架和工具来测量中断度量和延迟的信息。
当涉及到设计一个必须处理硬件中断的写得好的驱动程序时,所有这些都是必不可少的知识!
下一章涵盖了处理时间的领域:内核空间中的延迟和超时,创建和管理内核线程,以及使用内核工作队列。建议你勤勤恳恳的做好这一章的练习,浏览进一步阅读部分的众多资源,然后休息一下(嘿,只工作不玩耍,聪明的孩子也会变傻,对吧!?)在潜水回来之前!那里见!
- 在 x86 系统上(虚拟机也可以),显示当定时器中断(IRQ
0)的数量保持不变时,另一个周期性的系统中断实际上在不断增加(因此在每个 CPU 的基础上跟踪时间)。 *提示:*使用与中断相关联的proc伪文件。 - 键盘记录器 _ 简单;仅限本机 x86 仅用于道德黑客攻击;可能不适用于 VM]
(高级一点)使用“misc”内核框架编写一个简单的键盘记录器驱动程序。将其夹在 i8042 的 IRQ 1 中,以便将其“夹”在键盘中按下/释放并读取按键扫描代码。使用
kfifo数据结构将键盘扫描代码保存在内核空间内存中。让用户模式进程(或线程)定期将驱动程序kfifo中的数据项读入用户空间缓冲区,并将它们写入日志文件。编写一个应用(或使用另一个线程)来解释键盘按键。 提示:- 您能确保它只在 x86 上运行吗(应该如此)?有;在代码的最开始使用
#ifdef CONFIG_X86! - 您能否确保它仅在本机系统上运行,而不在虚拟机中运行?是的,您可以使用包装脚本中的
virt-what脚本来加载驱动程序;仅在不在虚拟机上时执行insmod(或modprobe)。 - 写一个驱动程序实际上是一件困难的事情(而且完全没有必要!)实现键记录器的方法(在这里,您只是作为一个学习练习来这样做,以便知道如何在设备驱动程序中处理硬件中断)。在更高层次的抽象上工作确实更简单更好——基本上,通过查询内核的
events层来获取击键。一个简单的方法是使用事件监控和捕获工具–evtest(1)很好!(以 root 身份运行它;https://www . kernel . org/doc/html/latest/input/input _ uapi . html。
- 您能确保它只在 x86 上运行吗(应该如此)?有;在代码的最开始使用
本作业的参考文献:
- 使用内核 kfifo:https://酏
- 美国键盘地图及解读:http://www.philipstorr.id.au/pcbook/book3/scancode.htm;http://www.osdever.net/bkerndev/Docs/keyboard.htm
- 内核提供了“延迟功能”机制,通常称为 _ _ _ _ _ ;它们被刻意设计成两全其美:(i) __________ 和(ii) _ _ _ _ _ _。
- 上半部分;尽快运行 hardirq 之后立即恢复中断的上下文。
- 下半部分;如果情况需要,允许驱动程序作者进行相当长的中断处理。在允许系统业务继续的同时,以一种延迟的、安全的方式做到这一点。
- 好一半;在中断上下文中做更多的工作,这样以后就不用为它付费了。
- 下半部分;在中断被禁用的情况下运行中断代码,并让它长时间运行。
- 使用代码浏览工具(
cscope(1)是一个不错的选择)来查找使用tasklet_hi_schedule()API 的驱动程序。 - 使用 Ftrace
irqsoff延迟跟踪器插件来查找中断被关闭的最长时间。 提示 : 这将涉及使用irqsoff插件(CONFIG_IRQSOFF_TRACER);如果默认情况下没有打开它,您将不得不配置内核,以便它包含它(以及其他所需的跟踪程序;你可以在make menuconfig : Kernel Hacking / Tracers下找到它们)。然后,您必须构建内核并关闭它。 提示 : 在测量系统延迟(中断关闭、中断和抢占关闭、调度延迟)等情况时,最好禁用lockdep。 参考: 使用 Ftrace 、Steven Rostedt、RedHat:https://static . lwn . nimg/conf/rtlw S11/papers/proc/p02 . pdf。
Solutions to some of the preceding questions could be found at https://github.com/PacktPublishing/Linux-Kernel-Programming-Part-2/tree/main/solutions_to_assgn.
-
内核文档: Linux 通用 IRQ 处理:https://www . kernel . org/doc/html/latest/core-API/generic IRQ . html # Linux-generic-IRQ-处理
-
中断时的 LWN 内核索引:https://lwn.net/Kernel/Index/#Interrupts
-
电平/边沿的中断触发:
- 边缘触发与水平触发中断,3 月 13 日:http://venkateshabrapu . blogspot . com/2013/03/边缘触发与水平触发. html
- 电平触发与边沿触发中断,2008 年 11 月:
-
如何以编程方式禁用不可屏蔽中断?:https://stackoverflow . com/questions/55394608/怎么办-I-disable-不可屏蔽-中断-编程方式
-
可线程化的 NAPI 投票、软 irqs 和适当的修复,乔恩·科尔贝特,2016 年 5 月,LWN:https://lwn.net/Articles/687617/
-
未来可能的方向:softirq 矢量细粒度屏蔽:
- 每矢量软件中断屏蔽,乔恩·科贝特,2019 年 2 月,LWN:https://lwn.net/Articles/779738/
- 软可中断软 irq(或按矢量屏蔽),Frederic Weisbecker,SuSe:https://linuxplumbersconf . org/event/4/contributions/420/attachments/375/609/LPC _ softirq . pdf
-
IRQ 平衡和相似性:
- IRQ 平衡,ntop 项目:https://www.ntop.org/pf_ring/irq-balancing/
- 设置中断关联系统,RHEL8:https://access . RedHat . com/documentation/en-us/red _ hat _ enterprise _ Linux/8/html/monitoring _ and _ management _ system _ status _ and _ performance/配置操作系统以优化 cpu 利用率 _ monitoring-and-management-system-status-performance #设置-中断关联-systems _ configuration-操作系统以优化 cpu 利用率
-
用循证医学方法进行绩效测量和分析的现代方法;
- Linux bcc/eBPF 追踪工具,Brendan Gregg:https://github.com/iovisor/bcc#tools
- 密件抄送教程:https://github . com/iovisor/bcc/blob/master/docs/Tutorial . MD # bcc-教程
-
客户名称:
- 内核文档:ftrace-Function Tracer:https://www.kernel.org/doc/Documentation/trace/ftrace.txt
- 以下是关于 LWN Ftrace 文章的链接集合(这里提到了其中一些):https://lwn.net/Kernel/Index/#Ftrace
- 使用 ftrace 调试内核-第 1 部分,Steven Rostedt,LWN,2009 年 12 月:https://lwn.net/Articles/365835/
- ftrace 函数跟踪器的秘密,史蒂文·罗斯特特,LWN,2010 年 1 月:https://lwn.net/Articles/370423/
- trace-cmd:ftrace的前端,史蒂文·罗斯特特,LWN,2010 年 10 月:https://lwn.net/Articles/410200/
- 使用 Ftrace 寻找延迟的来源,Steven Rostedt,2011 年 10 月:
-
LWN 内核指数在 延迟:https://lwn.net/Kernel/Index/#Latency****