Adds OpenACC for optional GPU utilization #116
Conversation
…ilation on gfortran
|
@RGates94 It's better to disable the OpenMP directives with an #ifdef statement instead of removing them completely. How about something like: Actually, we could also use |
|
Hi @RGates94 and @stephethier. Would you be ready to present any progress at the DCON users roundtable in 2 weeks? Or maybe the one after that? Just let me know whenever you feel you have something to show. In the meantime, I'll note this replaces #97 (which, in turn, was meant to be an extension of #82). @RGates94 can find nice summary flowcharts of the codes in those PR discussions. |
|
I'll also record @parkjk's recommendations for getting a fast kinetic run to use for debugging here so everyone can just refer to it whenever we have another PR or issue. In equil.in: equil_control, And make sure it actually stops and ends at those psi limits by turning dcon.in:dcon_control Then kinetic dcon ran either by GPEC-1.3 release version and a develop branch in my area within 18 seconds (with 9 OMP threads) : See /p/gpec/users/jpark/runs/gpec_DIIID_kinetic_example. The poloidal harmonic numbers can also be reduced in dcon.in: dcon_control and the loop over bounce harmonic numbers in pentrc.in: pent_input You may also want to try to increase tolerance of kinetic (or lambda) integration in pentrc.in: pent_control |
|
@logan-nc Thanks Nik. 18 seconds is good enough. It becomes difficult to measure speedups when the run is too short (< 1 sec). |
|
@stephethier I will definitely change the way I am disabling the OMP directives to what you are suggesting. @logan-nc I'm not sure whether I will have something to present for the next roundtable, however I am very confident that something will be ready for the one after that. Most of the work so far has been in preparing the codebase to use OpenACC directives, and while the code is now compiling with OpenACC enabled, tests so far don't seem to indicate any speedups compared to runs on the same compiler. (Although gfortran seems to run around 14% faster than intel overall) The largest current roadblock is compiler specific bugs in pgfortran, as the Nvidia profiler only works with executables produced with this compiler. |
|
@logan-nc (and @RGates94 ) Nik, the "tpsi" function in torque.F90 has a lot of allocation and deallocation: This is not good for GPU. We can either allocate everything in advance, or bring the nested loops inside of "tpsi". There are some performance implications for both but I'm trying to figure out which one would be the easiest to implement. |
|
thanks for the update @RGates94. Just keep recording progress here and we can decide when there is sufficient material to warrant a devoted agenda item. In the meantime, feel free to join the meetings and ask/state any minor questions/observations as you go. For the allocations in Note, |
|
In reply to an email from @stephethier:
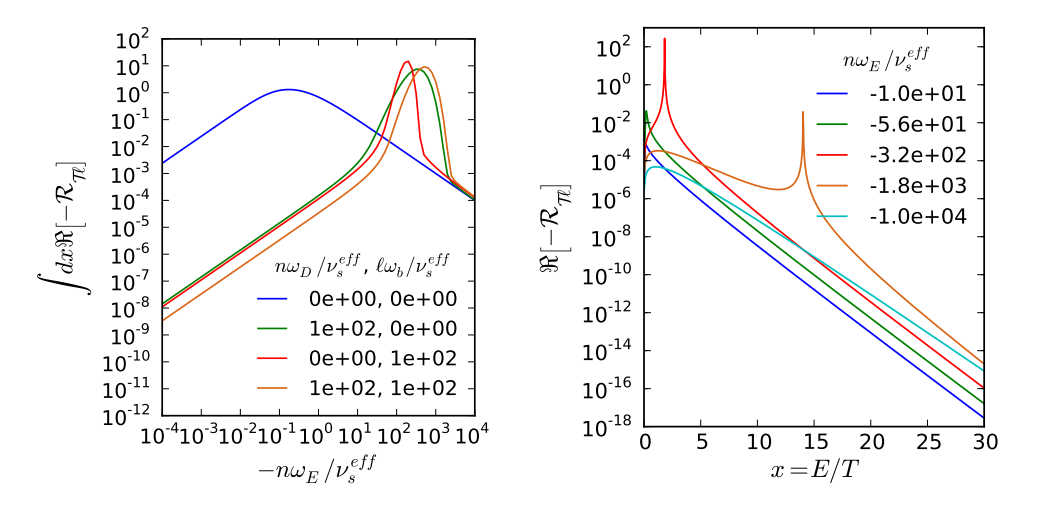
Indeed the These integrations can involve very sharp resonances. I tried analytically estimating where they would be and using a smart-packed grid early on, but it was not accurate / never as good as LSODE. Here are some examples of the energy integrand: Here are some of the pitch: I am 100% open to changing the integrator. I only used LSODE because it was what DCON used and a quick googling (back when I was very new to fortran) confirmed it was still one of the "best" (at least "tried and true") dynamic integrators around. That seemed good for doing lots of integrals that might or might not be very sharp. Do you have something better? [1] N. C. Logan, J.-K. Park, K. Kim, Z. Wang, and J. W. Berkery, “Neoclassical toroidal viscosity in perturbed equilibria with general tokamak geometry,” Phys. Plasmas, vol. 20, no. 12, p. 122507, Dec. 2013. |
|
@stephethier @RGates94 I had a thought. I never checked this explicitly, but I guess if we used |
|
Since today is my last day at the lab, I thought it would be beneficial to share an update on current progress and my thoughts on where to continue from here. After I got OpenACC working and checked performance, I found there were no significant speedups, so I went and looked into where most of the time was being spent in the program. I found that a vast majority of the time was spent on a call to lsode1 in pentrc/pitch.f90. Therefore on the suggestion of @stephethier I began replacing LSODE with CVODE. As this call to lsode1 took lintgrnd as a parameter, and lintgrnd called xintgrl_lsode which calls lsode2 which takes the xintgrnd subroutine as a parameter, I started by replacing xintgrnd with a wrapper over a C function. To do this I first added a module that called into C shared objects, I then added a subroutine newxintgrnd which wraps a C function with the same behavior. The next steps will be to go up this call stack, replacing each fortran subroutine with a C function with the same behavior. This will allow use of CVODE in place of lsode calls. I expect that this process will allow for significant speedups, and moreover by moving this portion of the code into C, it opens up the ability to access the larger C and CUDA ecosystem, along with the ecosystems of other languages that expose a C ABI. One other area I would have liked to tackle if I had more time is the warnings that occur in various modules, many of these are simply formatting issues or legacy, however some of these are serious and are very likely causing undefined behavior. For example this warning: vacuum_math.f:348:11:
346 | do 115 l=2,n
| 2
347 | ia=x(l-1)
348 | ib=x(l)
| 1
Warning: Array reference at (1) out of bounds (2 > 1) in loop beginning at (2)could cause correctness errors in other parts of the code, and this could be triggered by changes that are themselves correct. I appreciate the time that I have worked here and I wish the best of luck to everyone in continuing to improve this code. If you have any questions for me before I leave, please let me know, and I will do my best to answer them. |
|
👍 Thanks for the wrap-up @RGates94. I appreciate the work you put into this and wish you all the best in your new position! |
|
@stephethier, I noticed when merging the codes that STRIDE uses ZVODE. In DCON & PENTRC we are using LSODE to integrate complex functions by splitting the real and imaginary parts and doubling the number of equations. This is a non-intuitive "trick" of the LSODE routine that Alan Glasser used decades ago and got propagated from there. Do you think perhaps switching PENTRC to ZVODE would speed things up? |
|
@RGates94 do you have any numbers associated with
I expect it is +90%? I would then expect most of that time to be spent in lsode2 in energy.f90... is that correct? In my experience, LSODE spends a lot of unnecessary time at the start when the integral is low. I think it is figuring out what is safe based on relative tolerances. I wonder if there are balances of atol and rtol we can use to prevent this, or better ways of pre-normalizing the problem (absolute tolerance atol=0.001 impacts int(x) differently than int(x/10000)). |
|
Hi Nik @logan-nc |
|
Citations can always be found on the GPEC website. The abstract from [Glasser, Phys. Plasmas 2018] is,
Basically, it speeds things up by solving the same equation using a different numerical approach that lends itself well to parallelization (calculate a bunch of transition matrices in distinct regions). Another way to look at it is: It is just DCON with the lsode call replaced 😛. |
|
I should clarify: STRIDE does NOT contain the kinetic physics that is taking up all the time in the DCON runs we are trying to speed up. It only reproduces the ideal DCON ( We form the kinetic matrices before starting the ODE solve, so even if we used something like STRIDE it would not actually help speed up the kinetic time sink - just the ~6s integration after all the kinetic matrices are formed up. |
The exact amount of time spent on the lsode1 call depends on the exact parameters used for the run, in the DIIID_kinetic example it is approximately 90%, but I don't have a simple way to give exact numbers at the moment. Regarding how much is spent on the lsode2 call, I am not sure exactly, however I strongly suspect that it takes up nearly all of the time. |
This branch will add OpenACC directives, intended to increase performance of dcon and related workflows by utilizing the GPU clusters.
More details will be added as work progresses.