Releases: ProjectPhysX/FluidX3D
FluidX3D v3.5 (multi-GPU particles)
Thank you for using FluidX3D! Update v3.5 finally brings multi-GPU support for the PARTICLES extension. Now all extensions are supported with multi-GPU. Thanks to @jasonxauat for helping with the implementation approach!
Improvements
PARTICLESextension now also works with multi-GPU- faster force spreading if volume force is axis-aligned
- added more documentation for boundary conditions
- updated FAQs
- improved "hydraulic jump" sample setup
- updated GPU driver install instructions
Bug fixes
- disabled zero-copy on ARM iGPUs because
CL_MEM_USE_HOST_PTRis broken there
Have fun with the software!
-- Moritz

Contributors
Assets 8
FluidX3D v3.4 (bug fixes)
Thank you for using FluidX3D! Finally I also have an AMD GPU in my posession, so I can test FluidX3D locally on AMD/Intel/Nvidia GPUs within the same PC, to guarantee full compatibility. This allowed me to identify and fix 2 critical bugs that were coding mistakes on my side yet somehow only exposed with AMD's driver.
Improvements
- updated OpenCL driver install versions
- minor refactoring in
stream_collide()
Bug fixes
- fixed bug in insertion-sort in
voxelize_mesh()kernel causing crash on AMD GPUs - fixed bug in
voxelize_mesh_on_device()host code causing initialization corruption on AMD GPUs - fixed dual CU and IPC reporting on AMD RDNA 1-4 GPUs
Have fun with the software!
-- Moritz
PS: Here's a little demo of "SLI"-ing AMD+Intel+Nvidia GPUs with FluidX3D:

FluidX3D v3.3 (faster .vtk export)
Thank you for using FluidX3D! Update v3.3 brings improvements to .vtk export and bug fixes:
Improvements
.vtkexport now converts and writes data in chunks, to reduce memory footprint and time for large memory allocation.vtkfiles now contain original file name as metadata in titleINTERACTIVE_GRAPHICS_ASCIInow renders in 2x vertical resolution but less colors- updated OpenCL-Wrapper: more robust dp4a detection, fixed core count reporting for RDNA4 GPUs
Bug fixes
- fixed
update_moving_boundaries()kernel not being called with flags other thanTYPE_S - fixed corrupted first frame until resizing with
INTERACTIVE_GRAPHICS_ASCII - fixed
resolution()function for D2Q9 - fixed missing
<chrono>header on some compilers - fixed bug in
split_regex() - fixed compiler warning with
min_int
Have fun with the software!
-- Moritz
FluidX3D v3.2 (fast force/torque summation)
Thank you for using FluidX3D! Update v3.2 brings the much requested GPU-accelerated force/torque summation:
Improvements
- implemented GPU-accelerated force/torque summation (~20x faster than CPU-multithreaded implementation before)
- simplified calculating object force/torque in setups; before:
now:
lbm.voxelize_mesh_on_device(mesh, TYPE_S|TYPE_X); const float3 lbm_com = lbm.calculate_object_center_of_mass(TYPE_S|TYPE_X); // ... lbm.calculate_force_on_boundaries(); lbm.F.read_from_device(); // having to copy entire lbm.F from GPU VRAM to CPU RAM was slow!! const float3 lbm_force = lbm.calculate_force_on_object(TYPE_S|TYPE_X); // slow CPU-multithreaded summation const float3 lbm_torque = lbm.calculate_torque_on_object(lbm_com, TYPE_S|TYPE_X); // slow CPU-multithreaded summation
lbm.voxelize_mesh_on_device(mesh, TYPE_S|TYPE_X); const float3 lbm_com = lbm.object_center_of_mass(TYPE_S|TYPE_X); // ... const float3 lbm_force = lbm.object_force(TYPE_S|TYPE_X); // fast GPU-accelerated summation, copy only result to CPU const float3 lbm_torque = lbm.object_torque(lbm_com, TYPE_S|TYPE_X); // fast GPU-accelerated summation, copy only result to CPU
- improved coloring in
VIS_FIELD/ray_grid_traverse_sum() - updated OpenCL-Wrapper now compiles OpenCL C code with
-cl-std=CL3.0if available
Bug fixes
- fixed compiling on macOS with new OpenCL headers
Have fun with the software!
-- Moritz
Here a showcase of the improved coloring in VIS_FIELD/ray_grid_traverse_sum():


FluidX3D v3.1 (more bug fixes)
Thank you for using FluidX3D! Update v3.1 brings two critical bug fixes/workarounds and various small improvements under the hood:
Improvements
- faster
enqueueReadBuffer()on modern CPUs with 64-Byte-alignedhost_buffer - hardened ray intersection functions against planar ray edge case
- updated OpenCL headers
- better OpenCL device specs detection using vendor ID and Nvidia compute capability
- better VRAM capacity reporting correction for Intel dGPUs
- improved styling of performance mermaid gantt chart in Readme
- added multi-GPU performance mermaid gantt chart in Readme
- updated driver install guides
Bug fixes
- fixed voxelization being broken on some GPUs
- added workaround for compiler bug in Intel CPU Runtime for OpenCL that causes Q-criterion isosurface rendering corruption
- fixed TFlops estimate for Intel Battlemage GPUs
- fixed wrong device name reporting for AMD GPUs (unlike every sane GPU vendor they don't report device name as
CL_DEVICE_NAMEbut needCL_DEVICE_BOARD_NAME_AMDextension instead)
Have fun with the software!
-- Moritz
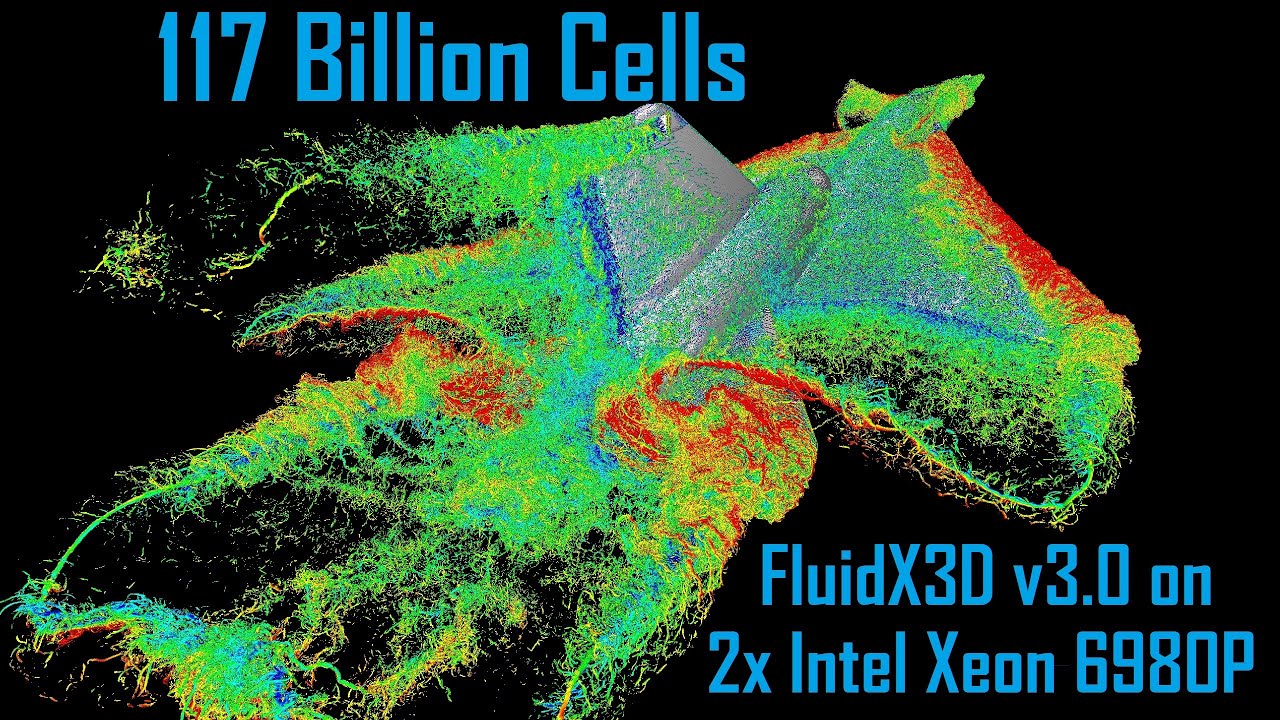
FluidX3D v3.0 (larger CPU/iGPU simulations)
A little gift to you all: FluidX3D v3.0 enables 31% larger grid resolution when running on CPUs or iGPUs!
Improvements
- reduced memory footprint on CPUs and iGPU from 72 to 55 Bytes/cell (fused OpenCL host+device buffers for
rho/u/flags), allowing 31% higher resolution in the same RAM capacity - faster hardware-supported and faster fallback emulation atomic floating-point addition for
PARTICLESextension - hardened
calculate_f_eq()against bad user input forD2Q9
Bug fixes
- fixed velocity voxelization for overlapping geometry with different velocity
- fixed Remaining Time printout during paused simulation
- fixed CPU/GPU memory printout for CPU/iGPU simulations
- fixed bug that
default_filename()would fail if there was a.in the file path
Have fun with the software!
-- Moritz
PS: Here's a little demo of what FluidX3D v3.0 is capable of:
FluidX3D v2.19 (camera splines)
Thank you for using FluidX3D! Update v2.19 adds Catmull-Rom splines for smooth camera movement, and bug fixes:
Improvements
- the camera can now fly along a smooth path through a list of provided keyframe camera placements, using Catmull-Rom splines
- more accurate remaining runtime estimation that includes time spent on rendering
- enabled FP16S memory compression by default
- printed camera placement using key G is now formatted for easier copy/paste
- added benchmark chart in Readme using mermaid gantt chart
- placed memory allocation info during simulation startup at better location
Bug fixes
- fixed threading conflict between
INTERACTIVE_GRAPHICSandlbm.graphics.write_frame(); - fixed maximum buffer allocation size limit for AMD GPUs and in Intel CPU Runtime for OpenCL
- fixed wrong
Re<Re_maxinfo printout for 2D simulations - minor fix in
bandwidth_bytes_per_cell_device()
Have fun with the software!
-- Moritz
FluidX3D v2.18 (more bug fixes)
Thank you for using FluidX3D! Update v2.18 brings support for high refresh rate monitors on Linux and bug fixes:
Improvements
- added support for high refresh rate monitors on Linux
- more compact OpenCL Runtime installation scripts in Documentation
- driver/runtime installation instructions will now be printed to console if no OpenCL devices are available
- added domain information to
LBM::write_status() - added
LBM::indexfunction foruint3input parameter
Bug fixes
- fixed that very large simulations sometimes wouldn't render properly by increasing maximum render distance from 10k to 2.1M
- fixed mouse input stuttering at high screen refresh rate on Linux
- fixed graphical artifacts in free surface raytracing on Intel CPU Runtime for OpenCL
- fixed runtime estimation printed in console for setups with multiple
lbm.run(...)calls - fixed density oscillations in sample setups (too large
lbm_u) - fixed minor graphical artifacts in
raytrace_phi() - fixed minor graphical artifacts in
ray_grid_traverse_sum() - fixed wrong printed time step count on raindrop sample setup
Have fun with the software!
-- Moritz
FluidX3D v2.17 (unlimited domain resolution)
Thank you for using FluidX3D! Update v2.17 removes the limit on 2³² cells per domain and adds new field visualization:
Improvements
- for GPUs/CPUs with >225 GB memory: domains are no longer limited to 4.29 billion (2³², 1624³) grid cells; if more are used, the OpenCL code will automatically compile with 64-bit indexing
- new, faster raytracing-based field visualization for single-GPU simulations (thanks @Snektron for the idea!)
- added GPU Driver and OpenCL Runtime installation instructions to documentation
- refactored
INTERACTIVE_GRAPHICS_ASCII
Bug fixes
- fixed memory leak in destructors of
floatN,floatNxN,doubleN,doubleNxN(all unused) - made camera movement/rotation/zoom behavior independent of framerate
- fixed that
smart_device_selection()would print a wrong warning if device reports 0 MHz clock speed
Have fun with the software!
-- Moritz
A glimpse of the new raytracing-based field visualization:

Contributors
Assets 8
FluidX3D v2.16 (bug fixes)
I'm doing my part! With the v2.16 update I've put down all remaining known bugs for good. 🖖😎❌🪳❌
WOULD YOU LIKE TO KNOW MORE?
Bug fixes in this release:
- fixed that voxelization failed in Intel OpenCL CPU Runtime due to array out-of-bounds access
- fixed that voxelization did not always produce binary identical results in multi-GPU compared to single-GPU
- fixed that velocity voxelization failed for free surface simulations
- fixed terrible performance on ARM GPUs by macro-replacing fused-multiply-add (
fma) witha*b+c - fixed that Y/Z keys were incorrect for
QWERTYkeyboard layout in Linux - fixed that free camera movement speed in help overlay was not updated in stationary image when scrolling
- fixed that cursor would sometimes flicker when scrolling on trackpads with Linux-X11 interactive graphics
- fixed flickering of interactive rendering with multi-GPU when camera is not moved
- fixed missing
XInitThreads()call that could crash Linux interactive graphics on some systems - fixed z-fighting between
graphics_rasterize_phi()andgraphics_flags_mc()kernels
Other improvements:
- simplified 10% faster marching-cubes implementation with 1D interpolation on edges instead of 3D interpolation, allowing to get rid of edge table
- added faster, simplified marching-cubes variant for solid surface rendering where edges are always halfway between grid cells
- refactoring in OpenCL rendering kernels
With GitHub I can track every bug from day it was discovered/fixed back to the day it was first introduced. This allows me to graph the number of open bugs over time, along with a curve weighted by their individual severity (minor 0.25, low 0.5, medium 1.0, high 2.0, showstopper 4.0):

Here is the distribution of days open, days till discovery and days till fix. I fixed 56% of bugs on the day of discovery. Notice the bimodal distribution of days open - a clear separation into "easy" and "nasty" bugs.

Lessons learned:
- Since release there was 63 bugs in FluidX3D in total, with at max 41 open bugs at one time. 🖖😱 Now there is 0, at least until I find more. 🖖😎 For reference: FluidX3D is 12.1k lines of code.
- Most bugs were a byproduct of big feature updates, like v2.0 (multi-GPU) and v2.1/v2.2 (voxelization). Of course at the time of introduction I didn't know that bugs slipped through, and I (or users) only discovered them later.
- Only 17% of bugs were found by users, all the others I found myself with rigorous testing. It takes continuous poking around in the code to find these often super rare bugs.
- 30% of bugs were actually bugs in the compiler, driver or operating system that needed a workaround on application side.
- The latest v2.16 release is the best FluidX3D has ever been. The worst, most bugged version by this metric is v2.2. 🖖🤠
Have fun with the software!
-- Moritz
PS: Here's an amusing FluidX3D video from @SLGY, he's doing his part too!
