- 1.Softmax的定义和作用
- 2.交叉熵定义和作用
- 3.格拉姆矩阵的相关概念?
- 4.感知损失的相关概念?
- 5.KL散度相关概念
- 6.JS散度相关概念
- 7.什么是机器学习中的局部最优与全局最优?
- 8.介绍一下机器学习中的目标函数、代价函数和损失函数的概念
- 9.常用的距离度量方法
- 10.KL散度和交叉熵的区别是什么?
- 11.介绍一下总变分损失的概念与作用
- 12.机器学习中将余弦相似度作为损失函数有哪些优势?
- 13.介绍一下机器学习中的L2损失函数
- 14.介绍一下机器学习中的MSE损失函数
- 15.介绍一下机器学习中的Huber Loss损失函数
- 16.介绍一下机器学习中的Dice Loss损失函数
- 17.介绍一下机器学习中的三元组损失函数
在二分类问题中,我们可以使用sigmoid函数将输出映射到【0,1】区间中,从而得到单个类别的概率。当我们将问题推广到多分类问题时,可以使用Softmax函数,对输出的值映射为概率值。
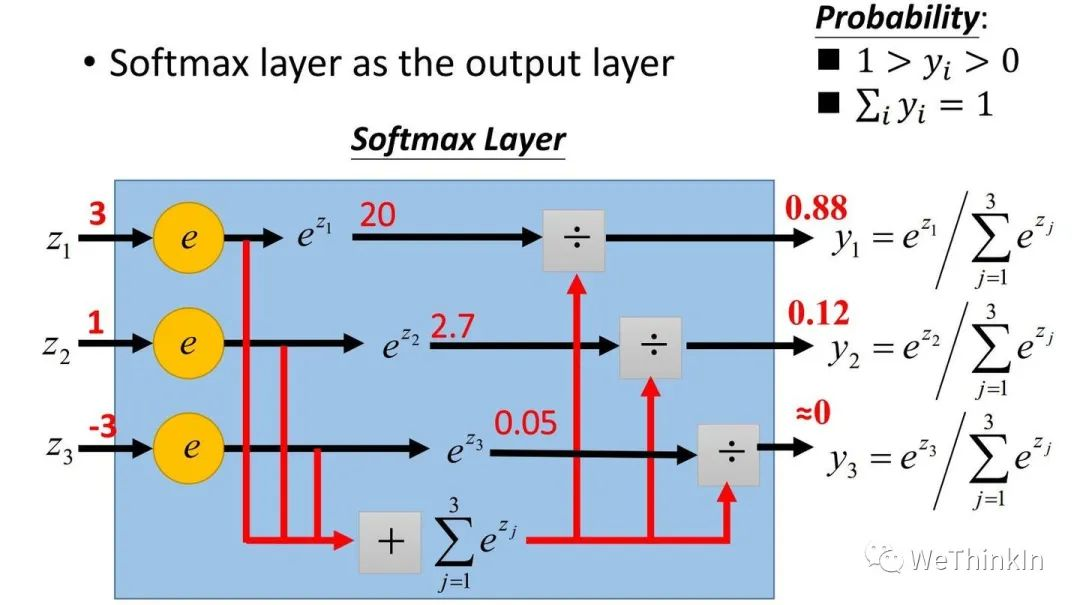
其定义为:
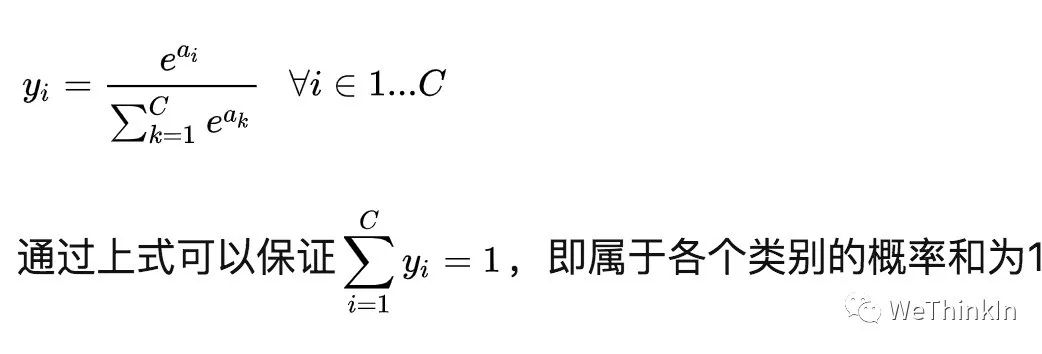
其中a代表了模型的输出。
交叉熵(cross entropy)常用于深度学习中的分类任务,其可以表示预测值与ground truth之间的差距。
交叉熵是信息论中的概念。其定义为:
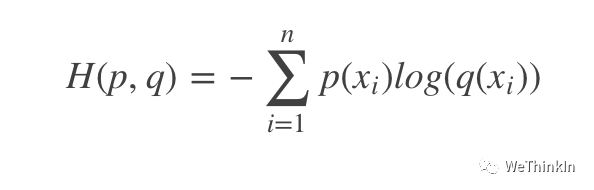
n维欧式空间中任意k个向量之间两两的内积所组成的矩阵,称为这k个向量的格拉姆矩阵(Gram matrix),这是一个对称矩阵。


其中对角线元素提供了k个不同特征图(a1,a2 ... ,ak)各自的信息,其余元素提供了不同特征图之间的相关信息。既能体现出有哪些特征,又能体现出不同特征间的紧密程度。图像风格迁移领域将其定义为风格特征。
格拉姆矩阵在风格迁移中有广泛的应用,深度学习中经典的风格迁移流程是:
-
准备基线图像和风格图像。
-
使用特征提取器分别提取基线图像和风格图像的feature map。
-
分别计算两个图像的feature map的格拉姆矩阵,以两个图像的格拉姆矩阵的差异最小化为优化目标,不断调整基线图像,使风格不断接近目标风格图像。
感知损失在图像生成领域中比较常用。其核心是将gt图片卷积得到的高层feature与生成图片卷积得到的高层feature进行回归,从而约束生成图像的高层特征(内容和全局结构)。
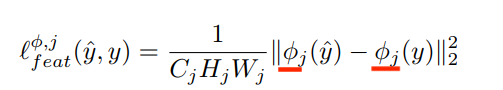
上面的公式中,划线部分代表了高层特征,一般使用VGG作为特征提取器。
KL散度(Kullback-Leibler divergence),可以以称作相对熵(relative entropy)或信息散度(information divergence)。KL散度的理论意义在于度量两个概率分布之间的差异程度,当KL散度越大的时候,说明两者的差异程度越大;而当KL散度小的时候,则说明两者的差异程度小。如果两者相同的话,则该KL散度应该为0。
接下来我们举一个具体的🌰:
我们设定两个概率分布分别为
从上面的公式可以看出,当且仅当
我们再来看看离散的情况下用
接下来我们对上面的式子进行展开:
最后得到的第一项称作
在信息论中,熵代表着信息量,
对深度学习中的生成模型来说,我们希望最小化真实数据分布与生成数据分布之间的KL散度,从而使得生成数据尽可能接近真实数据的分布。在实际场景中,我们是几乎不可能知道真实数据分布
JS散度全称Jensen-Shannon散度,简称JS散度。在概率统计中,JS散度也与KL散度一样具备了测量两个概率分布相似程度的能力,它的计算方法基于KL散度,继承了KL散度的非负性等,但有一点重要的不同,JS散度具备了对称性。
JS散度的公式如下所示,我们设定两个概率分布为
如果我们把KL散度公式写入展开的话,结果如下所示:
深度学习中使用KL散度和JS散度进行度量的时候存在一个问题:
如果两个分布
在机器学习中,特别是在训练各种类型的模型时,局部最优和全局最优的概念是理解模型优化过程的关键部分。这些概念与模型的目标函数或损失函数的优化密切相关。
首先,让我们了解机器学习模型中用于训练的基本元素之一:目标函数或损失函数。简单来说,这是一个数学函数,用于衡量模型预测的好坏。训练模型的过程实质上是一个优化问题,目的是找到最小化(或最大化,取决于问题)这个函数的参数设置。
全局最优是指目标函数的最优解,无论从函数的哪个点出发,这个解都是最佳的。在全局最优点,目标函数达到其可能的最小值(对于最小化问题)或最大值(对于最大化问题)。这意味着没有其他可行的参数值能使得损失函数的值比在全局最优点更小(或更大)。
与全局最优相对的是局部最优。在局部最优点,目标函数的值比其相邻点更优,但可能不如其他远离该点的值。简单来说,局部最优点在其周围的小区域内是最优的,但在整个参数空间中不一定是最优的。在高维空间中,局部最优可能非常频繁,特别是在复杂的模型如深度学习模型中。
柏拉图有一天向他的老师苏格拉底提出了一个问题:“什么是爱情?”苏格拉底让他走进一片麦田,从中挑选出最大的一颗麦穗带回来,但规定他在选择过程中不得回头,且只能摘取一次。结果柏拉图空手而归,他解释说,虽然途中见到了不少不错的麦穗,但总想是否还有更好的,结果一路走到了尽头,才发现早先见到的麦穗是更好的。于是他选择了放弃。苏格拉底对他说:“这就是爱情。”
这个故事启示我们,由于生命的有限性和不确定性,寻找全局最优解非常困难,甚至可以说根本不存在。我们应该设定一些限制条件,在这些条件下寻找最优解,即局部最优解。有所收获总比空手而归好,哪怕这种收获仅仅是一次有趣的经历。
柏拉图又一次询问苏格拉底:“什么是婚姻?”这一次,苏格拉底让他走进一片树林,挑选一棵最好的树作为圣诞树,同样规定不能回头,只能选择一次。这次,柏拉图带着疲惫的身躯挑选了一棵看起来直挺且翠绿但稍显稀疏的杉树,他解释说,吸取了之前的教训,当他看到一棵看似不错的树时,意识到时间和体力都快不够用了,便不再迟疑,不管它是否是最好的,就将它带了回来。苏格拉底对他说:“这就是婚姻。”
理解局部最优和全局最优在机器学习中的作用对于设计和调整模型至关重要。尽管寻找全局最优可能在某些情况下非常困难甚至不可行,通过适当的策略和技术,可以有效地缓解局部最优的限制,提高模型的整体性能。
在机器学习中,目标函数(Objective Function)、代价函数(Cost Function)和损失函数(Loss Function)是几个非常重要的概念。
- 损失函数(Loss Function):评估单个样本的误差,是模型预测与真实值之间差异的度量。
- 代价函数(Cost Function):评估整个模型在所有训练样本上的整体误差,是所有损失函数的平均值或总和。
- 目标函数(Objective Function):包括代价函数和其他优化目标(如正则化项),指导模型的整体优化过程。
损失函数用于衡量单个训练样本的预测值与真实值之间的误差。它度量了模型对单个样本的预测效果。
对于一个单一训练样本
其中:
-
$h_\theta(x_i)$ 是模型的预测值。 -
$y_i$ 是样本的真实值。 -
$L$ 是用于度量预测值和真实值差异的损失函数。
- 均方误差(Mean Squared Error, MSE):
- 对数损失(Log Loss):
- 绝对误差(Mean Absolute Error, MAE):
代价函数是一个整体的度量,用于评估整个模型的性能。它通常是所有训练样本的损失的平均值或总和。代价函数反映了模型在所有训练数据上的整体表现。
假设我们有一个包含
其中:
-
$\theta$ 表示模型的参数。 -
$L_i(\theta)$ 是第$i$ 个样本的损失函数。
代价函数用于评估整个模型在训练集上的整体误差,并作为优化算法的目标。模型训练的目标是通过调整参数
目标函数是一个更广义的概念,它不仅包括代价函数,还可以包括正则化项或其他需要优化的目标。目标函数的目的是指导模型的优化过程,确保模型不仅在训练集上表现良好,还具备良好的泛化能力。
目标函数可以表示为代价函数和正则化项的组合:
其中:
-
$J(\theta)$ 是代价函数。 -
$\lambda$ 是正则化系数,用于控制正则化项的影响。 -
$R(\theta)$ 是正则化项,用于防止过拟合。
目标函数用于指导模型的整体优化过程。通过最小化目标函数,可以确保模型在训练数据和新数据上都表现良好。
-
损失函数(Loss Function):
- 衡量单个样本的误差。
- 是代价函数的组成部分。
-
代价函数(Cost Function):
- 衡量所有训练样本的整体误差(通常是损失函数的平均值或总和)。
- 用于评估模型的整体性能。
-
目标函数(Objective Function):
- 包括代价函数和其他优化目标(如正则化项)。
- 指导模型的整体优化过程。
假设我们有一个线性回归模型,目标是预测房价。数据集包含三个样本,每个样本的损失函数为均方误差(MSE)。具体如下:
- 样本1:真实房价
$y_1 = 300,000$ ,预测房价$\hat{y}_1 = 310,000$ - 样本2:真实房价
$y_2 = 400,000$ ,预测房价$\hat{y}_2 = 390,000$ - 样本3:真实房价
$y_3 = 500,000$ ,预测房价$\hat{y}_3 = 510,000$
计算每个样本的损失函数:
计算代价函数(均方误差的平均值):
假设我们加上L2正则化项,正则化项
最终目标函数为:
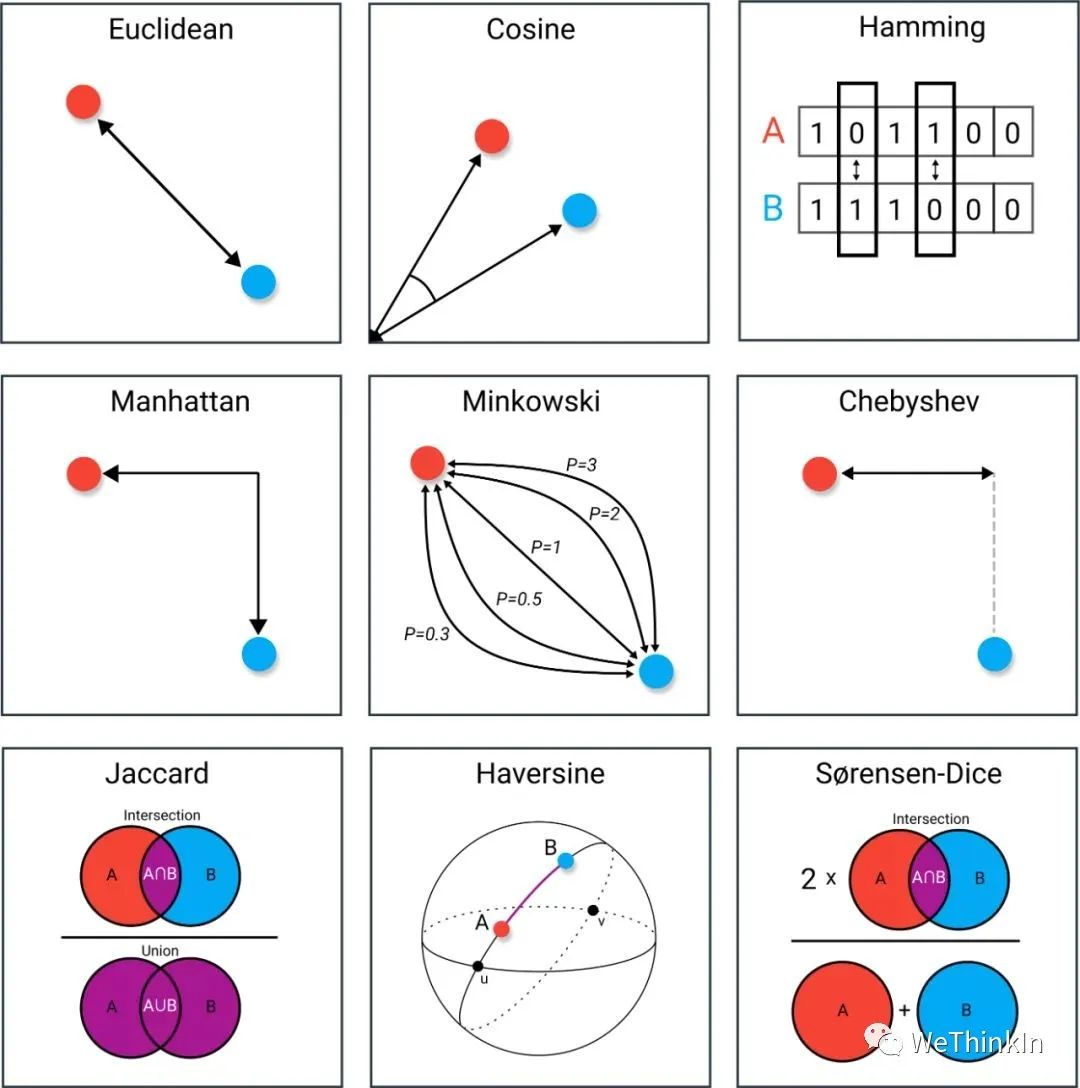
-
欧式距离
-
闵可夫斯基距离
-
马氏距离
-
互信息
-
余弦距离
-
皮尔逊相关系数
-
Jaccard相关系数
-
曼哈顿距离
KL散度(Kullback-Leibler Divergence)和交叉熵(Cross-Entropy)是机器学习中用于衡量概率分布之间差异的两个重要概念。
KL散度是一种用于衡量两个概率分布
对于连续分布则如下所示:
- 非对称:
$D_{KL}(P || Q) \neq D_{KL}(Q || P)$ - 非负性:
$D_{KL}(P || Q) \geq 0$ ,且当且仅当$P = Q$ 时等于0 - 度量了信息损失:
$D_{KL}(P || Q)$ 可以被理解为使用分布$Q$ 近似分布$P$ 时的信息损失
交叉熵用于衡量一个分布
对于连续分布则如下所示:
- 包含了熵(Entropy):
$H(P, Q) = H(P) + D_{KL}(P || Q)$ ,其中$H(P)$ 是分布$P$ 的熵 - 非负性:
$H(P, Q) \geq 0$ - 衡量不确定性: 交叉熵越小,表示分布
$Q$ 与目标分布$P$ 越接近
交叉熵可以表示为熵和KL散度的和:
其中:
-
$H(P)$ 是分布$P$ 的熵,表示$P$ 的固有不确定性 -
$D_{KL}(P || Q)$ 是KL散度,表示分布$Q$ 相对于$P$ 的信息损失
- KL散度: 常用于变分推断、信息论和测量两个概率分布之间的差异。
- 交叉熵: 常用于分类任务中的损失函数(例如逻辑回归、神经网络中的Softmax损失),用于评估模型预测与真实分布之间的差异。
假设我们有一个二分类问题,其中真实分布
- 真实分布
$P$ : [0.9, 0.1] - 预测分布
$Q$ : [0.6, 0.4]
我们计算交叉熵和KL散度:
通过计算,我们可以量化预测分布
在图像生成和图像处理领域,总变分损失(Total Variation Loss,简称TV损失)是一种常用的正则化方法,旨在减少生成图像中的噪声和不必要的细节,从而获得更加平滑和自然的结果。它在风格迁移、图像超分辨率、生成对抗网络(GAN)等应用中起到了重要作用。
理解总变分损失的概念和作用,可以帮助我们在实际应用中更好地构建和优化图像生成模型,提升生成图像的质量。
总变分最初是数学分析中的一个概念,用于衡量一个函数在其定义域内变化的总量。在图像处理中,总变分用于衡量图像像素值在空间上的变化程度。
简单来说,总变分就是图像中所有像素之间差异的总和。如果一幅图像的总变分值较大,意味着图像中有较多的细节和噪声;如果总变分值较小,说明图像更平滑,细节和噪声较少。
在深度学习中,总变分损失是通过计算相邻像素之间的差异来定义的,其目的是鼓励生成的图像在空间上更加平滑,减少过度的噪声和纹理。
总变分损失通常表示为:
-
$I_{i,j}$ 表示图像中第$i$ 行第$j$ 列像素的值。 -
$\beta$ 是一个超参数,通常取值为1。
在图像生成过程中,模型可能会生成一些不必要的噪声和伪影,使得图像看起来不自然。总变分损失通过惩罚相邻像素之间的过大差异,鼓励图像的平滑性,减少噪声。
虽然总变分损失鼓励平滑,但它不会过度模糊图像,因为它只惩罚相邻像素之间的过大差异,而不会影响整体的图像结构和重要的细节。
在生成图像时,我们希望图像既有足够的细节,又不会因为噪声过多而影响视觉效果。总变分损失帮助模型在细节和平滑性之间取得平衡。
总变分损失通过计算图像中每个像素与其右边和下边像素的差异,然后将这些差异的平方和累加起来。
-
水平差异:
$(I_{i,j} - I_{i+1,j})^2$ -
垂直差异:
$(I_{i,j} - I_{i,j+1})^2$
将所有像素的水平和垂直差异累加,得到总变分损失。这代表了图像中像素值变化的总量。
在训练模型时,将总变分损失作为损失函数的一部分,与其他损失(如内容损失、风格损失等)组合在一起。这样,模型在优化时会同时考虑生成图像的内容、风格和平滑性。
总变分损失通常会乘以一个权重系数,调节其在总损失中的影响力。通过调整这个权重,可以控制生成图像的平滑程度。
在风格迁移中,我们希望将一张内容图像的结构与另一张风格图像的纹理融合。总变分损失在这里用于:
- 减少噪声:防止生成的图像出现过多的随机纹理。
- 保持平滑性:使得生成的图像在视觉上更加连贯。
在提高图像分辨率的任务中,总变分损失帮助模型生成更平滑的高分辨率图像,避免由于放大而产生的噪声。
如果总变分损失的权重设置过高,可能会导致生成的图像过于平滑,丢失重要的细节。因此,需要在实验中找到合适的权重。
总变分损失通常与其他损失函数一起使用,需要根据具体任务调整各个损失的权重,以达到最佳效果。
在机器学习中,余弦相似度(Cosine Similarity)是一种用于衡量两个向量之间相似度的常用方法,尤其适用于高维空间的特征向量。将余弦相似度作为损失函数(通常转化为余弦相似度损失)具有多个优势,特别是在文本、图像特征和推荐系统等任务中。
余弦相似度的公式如下:
其中:
-
$\vec{A}$ 和$\vec{B}$ 是两个向量。 - 分子部分
$\vec{A} \cdot \vec{B}$ 是两个向量的内积。 - 分母部分
$||\vec{A}|| \cdot ||\vec{B}||$ 是两个向量的模长的乘积。
余弦相似度的取值范围为 ([-1, 1]):
- 1 表示两个向量方向完全一致(最相似)。
- 0 表示两个向量正交(无相关性)。
- -1 表示两个向量方向完全相反(最不相似)。
余弦相似度损失通常是将余弦相似度取负值,或使用 (1 - \text{Cosine Similarity}),使得两个向量越相似,损失越小。
- 余弦相似度仅衡量两个向量的方向相似性,而不考虑它们的模长。
- 在许多任务中,如文本表示或图像嵌入,两个向量可能在数值上有较大的差异(模长不同),但如果方向相同,则可以认为它们表示相似的概念。
- 这种性质在嵌入空间中尤其有用,因为我们通常关心特征的相对相似性,而不是绝对的数值大小。
- 余弦相似度在高维稀疏数据(如文本向量、用户行为数据)中表现良好,因为它只计算非零元素的方向相似度。
- 在推荐系统中,用户的特征向量可能是高维且稀疏的(如用户对物品的评分),余弦相似度可以有效处理这种稀疏数据,避免因为缺失值影响相似度计算。
- 余弦相似度实际上是将向量归一化到单位球面上,确保向量长度一致。
- 这种归一化操作可以减少模型对数值缩放变化的敏感性,使得模型更加鲁棒,特别是在特征值变化较大的情况下。
- 在很多任务中,我们希望将相似的对象拉近、不相似的对象拉远。使用余弦相似度作为损失函数,可以很好地表达这个需求。
- 在对比学习(contrastive learning)中,余弦相似度损失可以有效地将相似对象的嵌入向量方向拉得更近,将不相似对象的方向分开。
在自然语言处理(NLP)中,余弦相似度广泛用于衡量文本相似度,如句子嵌入的比较。在这种场景中:
- 文本经过编码器(如 BERT)得到句子嵌入向量,余弦相似度损失确保相似文本的向量方向一致。
- 余弦相似度损失可以忽略句子表示的绝对大小,只关心相对方向,有助于更好地度量语义相似性。
在图像处理任务(如人脸识别、图像检索)中,余弦相似度损失用于比较不同图像的嵌入表示:
- 将人脸图像编码成嵌入向量,余弦相似度损失可以确保相同人脸的向量方向一致,不同人脸的方向不一致。
- 使用余弦相似度损失可以增强模型对图像中相同特征的识别能力,提升匹配效果。
在推荐系统中,可以将用户与物品的特征向量转换为相同的嵌入空间:
- 使用余弦相似度损失来计算用户向量与物品向量之间的相似性,以衡量用户对物品的兴趣。
- 这种方法对高维稀疏特征尤其有效,且能适应不同用户和物品特征的变化。
总的来说,我们使用余弦相似度作为损失函数的优势总结如下:
- 忽略模长,专注方向:适合不关注特征绝对大小的任务,适用于嵌入表示。
- 高效处理高维稀疏数据:特别适用于文本、推荐系统等稀疏数据。
- 归一化操作:在训练过程中更稳定,对缩放不敏感。
- 自然匹配的距离度量:直接度量相似性,更符合直观的“相似度”需求。
因此,余弦相似度损失在文本相似度、图像特征匹配、推荐系统等领域得到了广泛应用,能够有效提升模型在这些任务中的表现。
在机器学习中,L2损失函数(也称为均方误差损失,Mean Squared Error, MSE)是一种用于评估模型预测值与真实值之间差异的常见损失函数。L2损失函数广泛应用于回归问题中,因为它具有较好的数值稳定性,且对于较大的误差给予更大的惩罚。
假设我们有一个模型,给定输入
其中:
-
$n$ 是样本数量。 -
$\hat{y}_i$ 是模型对第$i$ 个样本的预测值。 -
$y_i$ 是第$i$ 个样本的真实值。 -
$(\hat{y}_i - y_i)^2$ 是预测值与真实值之间误差的平方。
这个公式表示的是每个样本的预测误差平方的平均值,也被称为均方误差(Mean Squared Error, MSE)。
-
平方惩罚:L2损失函数通过平方差异来惩罚预测误差,这使得大的误差会产生更大的损失。这种性质对模型的优化具有重要作用,因为它会迫使模型更加重视大误差的样本。
-
平滑性:L2损失函数是连续且可导的(通常也是二阶可导的),这使得它在优化时很稳定。许多优化算法(如梯度下降)依赖于损失函数的平滑性,因此 L2 损失函数可以在许多任务中很好地工作。
-
对称性:L2损失函数的值只取决于误差的大小,不考虑方向。因此,无论预测值偏高还是偏低,损失的惩罚都是相同的。
在机器学习模型训练过程中,我们通常使用梯度下降方法来最小化损失函数。为此,需要计算损失函数相对于模型参数的梯度。对 L2 损失函数的每一个预测值
这表明:
- 误差越大,梯度越大,因此 L2 损失会对大误差的样本进行更强的惩罚。
- 误差的符号会影响梯度的方向,若预测值高于真实值,则梯度为正,模型会朝着降低预测值的方向调整参数;若预测值低于真实值,则梯度为负,模型会朝着增大预测值的方向调整参数。
L2损失函数适用于以下场景:
-
回归任务:L2损失广泛应用于回归问题中,因为它对大的误差有更强的惩罚作用,使得模型在训练时会更加关注偏差较大的样本。例如,预测房价、股票价格等问题中,常用L2损失来最小化预测误差。
-
深度学习中的回归网络:在神经网络中,尤其是用于回归问题的神经网络,L2损失是常用的损失函数之一。
-
特征学习和表示学习:L2损失可以用于衡量特征向量或表示向量之间的相似性。在表示学习任务中,我们希望特征之间的距离能够反映数据之间的语义相似性,L2损失可以很好地完成这个任务。
-
平滑性:L2损失函数是连续、平滑且可微的,这使得它在优化过程中非常稳定,适合使用梯度下降优化算法。
-
凸性:L2损失是一个凸函数(针对线性模型是严格凸函数),这意味着对大多数问题而言,它的最优解是唯一的,不会出现局部极小值问题。
-
对大误差的敏感性:由于平方惩罚机制,L2损失对大的误差更加敏感,有助于模型关注并减少大误差样本的影响。
-
对离群点的敏感性:由于 L2 损失会对误差进行平方,因此对离群点非常敏感。离群点会产生很大的误差,从而主导了损失的总值,导致模型被离群点牵引,可能导致欠拟合其他样本。对于受离群点影响较大的数据集,L1损失(绝对误差损失)可能是一个更好的选择。
-
可能导致欠拟合:如果数据中有较多离群点,L2损失的平方项会导致模型过度关注这些离群点,忽略其他正常样本的数据分布,最终影响模型的整体拟合效果。
在机器学习中,均方误差(MSE,Mean Squared Error)损失函数是回归任务中最常用的一种损失函数,用于衡量模型预测值和实际值之间的差距。MSE 损失函数通过计算预测值与真实值之差的平方来度量模型的误差,其值越小,说明模型的预测结果越接近真实值。
给定数据集
-
$y_i$ :第$i$ 个样本的实际值。 -
$\hat{y_i}$ :模型对第$i$ 个样本的预测值。 -
$n$ :样本的总数。
-
计算误差:对每一个样本计算误差,即实际值
$y_i$ 和预测值$\hat{y_i}$ 之差,得到误差项$y_i - \hat{y_i}$ 。 - 平方误差:对每个样本的误差取平方,这样可以消除误差的正负性,使得误差的方向不影响损失的计算。
- 求均值:将所有样本的平方误差求和,然后取平均,即得到均方误差。
MSE的取值为非负数,越接近 0 表示模型预测值和真实值越接近。
-
凸性:MSE 是一个凸函数,在优化过程中容易找到全局最小值。因此,梯度下降等优化算法可以较为高效地找到损失函数的极小值。
-
平滑性:MSE 函数是连续且可微的,在大多数优化算法中可以方便地计算梯度。
-
对异常值敏感:MSE 对异常值(outliers)非常敏感,因为误差取平方后会放大异常值的影响。这意味着即使只有一个预测值与真实值相差很大,MSE 的值也会明显增大。
MSE的导数是梯度下降算法计算权重更新量时需要的。对参数
在每次梯度下降的迭代中,模型的参数会根据这个梯度值调整,从而逐步减小 MSE 损失。
- 易于计算和优化:MSE 的计算非常简单,对每个样本的误差平方取均值,可以高效实现。
- 数学性质好:凸性和平滑性使得在参数优化时容易找到最优解,适合使用梯度下降法来优化模型。
- 对异常值敏感:如果数据集中存在异常值,MSE 会受到较大影响。异常值的平方误差可能非常大,导致模型过度拟合这些异常值。
- 解释性不如MAE:由于 MSE 是平方误差的均值,其单位与原始数据不一致(平方),因此在解释上不如 平均绝对误差(MAE) 直观。
Huber Loss 是一种用于回归问题的损失函数,它结合了均方误差(MSE)和绝对误差(MAE)的优点,主要用于对异常值(outliers)具有鲁棒性的场景。Huber Loss 在小误差时表现为 MSE,在大误差时表现为 MAE,结合了两者的优点。它特别适合含有异常值的回归问题,能够在对小误差敏感的同时,对异常值具备较强的鲁棒性。
Huber Loss的公式如下:
-
$a = y - \hat{y}$ :预测值与真实值的残差。 -
$\delta$ :控制损失函数转变点的超参数。
-
小误差情况
$(|a| \leq \delta$ ):- 损失函数为平方误差,即
$\frac{1}{2}(a)^2$ 。这一部分对误差较小的点较敏感,可以有效优化小范围内的误差。
- 损失函数为平方误差,即
-
大误差情况
$(|a| > \delta$ ):- 损失函数转为线性形式:
$\delta \cdot (|a| - \frac{\delta}{2})$ 。在这一部分,对误差的增长速度进行限制,从而减小异常值对模型的影响。
- 损失函数转为线性形式:
-
对小误差敏感:
- 在误差较小的情况下,Huber Loss与MSE相同,能够提供较好的梯度信息,使模型更快速地收敛。
-
对异常值具有鲁棒性:
- 在误差较大的情况下,Huber Loss切换到线性增长,类似于MAE,从而避免了异常值对总体损失的过大影响。
| 损失函数 | 对小误差的表现 | 对大误差的表现 | 梯度特性 | 优缺点 |
|---|---|---|---|---|
| MSE | 敏感 | 非常敏感 | 平滑(连续) | 优点:小误差优化效果好;缺点:对异常值过于敏感。 |
| MAE | 不敏感 | 稳定 | 梯度不连续 | 优点:鲁棒性强;缺点:梯度信息有限,优化过程不够高效。 |
| Huber | 敏感 | 稳定 | 平滑(连续) | 综合了MSE和MAE的优点:既对小误差敏感,又对大误差鲁棒。 |
-
回归问题:
- 预测房价、股市数据、机器设备寿命等回归任务中,尤其当数据可能存在异常值时。
-
异常值处理:
- 当数据中包含异常点(outliers),但不希望它们对模型的训练产生过大影响时。
-
鲁棒优化:
- 需要平衡模型对误差的敏感性和对异常点的鲁棒性时。
-
AIGC时代:
- 图像生成任务、视频生成任务等。
-
$\delta$ 是 Huber Loss 的一个关键超参数:- 较小的
$\delta$ :更接近 MSE,适合误差较小的数据集。 - 较大的
$\delta$ :更接近 MAE,适合误差较大的数据集(或者有更多异常值的场景)。
- 较小的
通常,可以通过交叉验证来选择最优的
Huber Loss 的梯度可以分段表示:
- 这种梯度形式使得 Huber Loss 在不同误差区间具有良好的可优化性。
Dice Loss源于Dice系数(Dice Coefficient),最初用于衡量两个集合的相似性,广泛应用于图像分割任务。其核心思想是通过计算预测结果与真实标签的重叠度来优化模型。
公式推导:
-
Dice系数:
$$\text{Dice} = \frac{2 \times |Y \cap \hat{Y}|}{|Y| + |\hat{Y}|} = \frac{2 \times \sum Y \cdot \hat{Y}}{\sum Y^2 + \sum \hat{Y}^2}$$ 其中,
$Y$ 为真实标签,$\hat{Y}$ 为预测值(通常经过Sigmoid或Softmax处理为概率值)。 -
Dice Loss:
$$\text{Dice Loss} = 1 - \text{Dice} = 1 - \frac{2 \times \sum Y \cdot \hat{Y} + \epsilon}{\sum Y^2 + \sum \hat{Y}^2 + \epsilon}$$ 加入平滑项
$\epsilon$ (如1e-5)避免分母为零。
核心特点:
- 关注重叠区域:直接优化预测与真实标签的交集,适合类别不平衡问题(如小目标分割)。
- 对假阴性敏感:漏检(False Negative)会显著增加损失,适合医学等对漏检容忍度低的场景。
场景:在肺部CT图像中分割肿瘤区域。
- 真实标签:医生标注的肿瘤区域(二值掩码,1表示肿瘤,0表示背景)。
- 模型预测:模型输出的概率图(经过Sigmoid激活)。
Dice Loss作用:
- 若模型预测的肿瘤区域与医生标注完全重合,Dice系数为1,损失为0。
- 若预测区域仅有50%重叠,Dice系数为
$2 \times 0.5 / (1 + 1) = 0.5$ ,损失为0.5。 - 模型通过最小化Dice Loss,逐步提升预测与真实标签的重叠度。
应用场景:生成带精确结构的图像(如人脸、服装设计)。
案例:生成二次元角色时,要求五官位置与参考图对齐。
- 方法:将生成图像的掩码(如眼睛、嘴巴区域)与参考掩码计算Dice Loss,约束生成结构与目标一致。
优势:避免生成结果的结构偏差(如眼睛错位),提升生成可控性。
应用场景:医学图像分割(如肿瘤、器官分割)。
案例:U-Net模型分割视网膜血管。
- 挑战:血管区域占比小(<5%),传统交叉熵损失易被背景主导。
- 方案:使用Dice Loss,直接优化血管区域的重叠度,提升小目标分割精度。
效果:在ISIC皮肤病分割等任务中,Dice Loss比交叉熵的IoU提升约10%。
应用场景:道路场景理解(如车辆、行人分割)。
案例:实时分割道路上的行人。
- 需求:高精度分割小目标(行人),避免漏检导致安全事故。
- 方案:在Mask R-CNN等模型中结合Dice Loss,优化行人的分割边界。
优势:减少漏检率,提升自动驾驶系统的安全性。
- 优势:Dice Loss在类别不平衡、小目标分割场景中表现优异,是图像分割任务的“黄金标准”之一。
- 扩展变体:
- Tversky Loss:调整假阴性/假阳性的权重,适用于对漏检更敏感的任务。
- Focal Dice Loss:结合Focal Loss,进一步解决难样本学习问题。
- 局限:对预测概率的绝对值不敏感,需结合交叉熵损失使用(如Dice + BCE联合损失)。
一句话总结:Dice Loss通过最大化预测与真实标签的重叠度,成为图像分割任务的利器,尤其擅长解决小目标、类别不平衡问题,在传统深度学习、AIGC、自动驾驶中均有落地应用。
三元组损失函数是一种用于特征嵌入学习的监督学习损失函数,最早在FaceNet论文中被提出用于人脸识别任务。它的核心目标是学习一个特征空间,使得同类样本更接近,异类样本更远离。
L = max(d(a, p) - d(a, n) + α, 0)
其中:
a(anchor):锚样本p(positive):与锚样本同类别的正样本n(negative):与锚样本不同类别的负样本d():样本间的距离度量(通常为欧氏距离)α:边界值(margin),控制正负样本对的最小间隔
- 最小化同类样本距离:d(a, p) → 0
- 最大化异类样本距离:d(a, n) → ∞
- 确保d(a, p) + α < d(a, n)
假设我们正在开发一个办公楼的人脸识别门禁系统:
- 锚样本(a):员工张三的证件照
- 正样本(p):张三在门口摄像头抓拍的实时照片
- 负样本(n):其他员工李四的照片
训练过程:
- 系统不断调整特征提取模型:
- 让张三的证件照和实时照在特征空间越来越近(减小d(a,p))
- 让张三的证件照和李四的照片在特征空间越来越远(增大d(a,n))
边界值α的作用: 设置α=0.5,要求:
d(张三_证件, 张三_实时) + 0.5 < d(张三_证件, 李四_照片)
这样即使光线变化导致张三的实时照特征稍有偏移,系统仍能准确识别。
应用场景:文本到图像生成的一致性控制
具体应用:
- 风格一致性生成:
- Anchor:文本提示"梵高风格"
- Positive:生成的符合梵高风格的图像
- Negative:其他艺术风格的图像
- 损失函数确保同一风格的生成图像在特征空间聚集
优势:解决AIGC中角色/风格"漂移"问题,确保多图生成中关键特征的一致性
应用场景:细粒度图像检索
具体应用:
- 电商商品检索:
- Anchor:用户查询的包包图片
- Positive:同一款式的不同颜色/角度图片
- Negative:相似但不同款式的包包图片
训练技巧:
- 半硬样本挖掘:选择满足d(a,p) < d(a,n) < d(a,p)+α的样本
- 四元组损失扩展:增加负样本对的距离约束
应用场景:道路场景理解与重识别
具体应用:
- 交通标志识别:
- Anchor:"限速60"标志
- Positive:不同光照/角度下的"限速60"
- Negative:"限速80"标志
实际应用效果:
- 提高恶劣天气下的标志识别鲁棒性
- 解决车辆遮挡后重识别问题
- 增强对相似车型(如白色SUV)的区分能力
优势:
- 比softmax更适合开集识别任务
- 学习到的特征具有更好的可迁移性
- 对类别不平衡问题不敏感
- 决策边界更灵活(对比中心损失)
局限性:
- 样本组合爆炸(O(N³)复杂度)
- 对样本采样策略敏感
- 收敛速度相对较慢
- 需要精心设计数据增强策略
三元组损失函数的核心价值:它教会了AI系统"物以类聚,人以群分"的认知能力,通过对比学习让机器理解"相似"与"不同"的本质差异。这种学习范式已成为表征学习的基石,从人脸识别到蛋白质结构预测,其思想正不断推动AI理解复杂世界。