- 1.什么是机器学习?
- 2.机器学习有哪些学习方式?
- 3.什么是模型的偏差和方差?
- 4.训练集/验证集/测试集划分
- 5.什么是奥卡姆剃刀原理?
- 6.什么是没有免费的午餐定理?
- 7.判别式模型和生成式模型的本质区别?
- 8.如何理解:“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限”这个行业基本认知?
- 9.什么是AutoML?
- 10.什么是熵?
- 11.什么是交叉熵?
- 12.什么是KL散度?
- 13.耦合和解耦的思想如何在机器学习中实践?
- 14.什么是代价函数及其意义?
- 15.什么是二次代价函数?
- 16.什么是交叉墒代价函数?
- 17.什么是对数似然代价函数?
- 18.介绍一下机器学习中的特征编码与特征解码的概念
- 19.机器学习中的Embeddings特征的本质是什么?
- 20.AI行业主要有哪些核心的数据模态?
- 21.机器学习中数据增强的本质是什么?
- 22.机器学习中音频数据有哪些特点?
- 23.什么是机器学习中的全局最优和局部最优问题?
- 24.什么是机器学习中的对比学习?
- 25.机器学习中训练集、验证集、测试集之间有哪些区别?
- 26.介绍一下机器学习中热插拔式和冷启动的相关概念
- 27.介绍一下机器学习中TopK的概念
- 28.介绍一下模型预训练和模型微调之间的区别
- 29.什么是迁移学习?
- 30.介绍一下数据集在机器学习中的本质作用
机器学习(Machine Learning)是人工智能的一个子领域,早在1950年阿兰·图灵(Alan Turing)提出了图灵测试,探讨了机器是否能够表现出智能行为。在1952年Arthur Samuel 在IBM工作期间开发了一个具有学习能力的西洋跳棋程序,这个程序可以在不断对弈中提高自己的水平,Arthur Samuel也因此正式提出了“机器学习”的概念。
机器学习技术专注于让计算机系统能够自动从数据中进行学习和进步,而不需要显式地持续编程。机器学习的核心在于数据、算法和模型,这些算法和模型可以通过分析数据和识别数据中的模式进行决策。
机器学习技术目前已经在AIGC、传统深度学习、自动驾驶三个领域全面落地,发展出Stable Diffusion、ChatGPT、Sora、Transformers、YOLO、GAN、U-Net、ResNet、随机森林、支持向量机、决策树、逻辑回归、感知机等实用算法,开始帮助人类完成各种各样的脑力任务。
目前数据的情况,机器学习的学习方式可以分为 监督学习(supervised learning)、无监督学习(unsupervised learning),半监督学习(semi-supervised learning)、弱监督学习(weakly supervised learning)、强化学习(Reinforcement Learning)、自监督学习(Self-Supervised Learning)、联邦学习(Federated Learning) 等。
-
监督学习(Supervised Learning):
- 定义:监督学习是一种机器学习方法,其中模型在训练过程中使用带有标签的数据,即每个输入数据都有对应的输出标签。目标是学习从输入到输出的映射关系,能够对新输入进行准确预测。
- 目标:学习从输入到输出的映射关系,能够对新输入进行准确预测。
- 应用:分类(例如垃圾邮件检测)、回归(例如房价预测)。
- 经典算法:
- 分类算法:逻辑回归、支持向量机(SVM)、决策树、随机森林、k-近邻(k-NN)、神经网络等。
- 回归算法:线性回归、岭回归、Lasso回归、支持向量回归(SVR)等。
-
无监督学习(Unsupervised Learning):
- 定义:无监督学习是一种机器学习方法,其中模型在训练过程中使用未标记的数据,即只有输入数据而没有对应的输出标签。
- 目标:发现数据中的结构和模式,如聚类、降维等。
- 应用:客户细分、市场分析、降维和特征提取。
- 例子:
- 聚类算法:k-均值(k-Means)、层次聚类、高斯混合模型(GMM)、DBSCAN等。
- 降维算法:主成分分析(PCA)、t-SNE、线性判别分析(LDA)、独立成分分析(ICA)等。
-
半监督学习(Semi-Supervised Learning):
- 定义:半监督学习结合了少量标记数据和大量未标记数据进行训练。
- 目标:利用未标记数据提升模型的泛化能力和准确性。
- 应用:在标记数据获取成本高或困难时,如医学图像分析。
- 例子:半监督支持向量机、图神经网络等。
-
弱监督学习(Weak Supervision):
- 定义:弱监督学习的逻辑是机器学习模型在训练过程中使用的数据的标签存在不可靠的情况。这里的不可靠可以是标注不正确,多重标记,标记不充分,局部标记,包含噪声等情况。一个直观的例子是相对于分割的标签来说,分类的标签就是弱标签。
- 应用:数据标注困难或成本高的场景。
- 常见方法:噪声建模、数据编程。
-
强化学习(Reinforcement Learning):
- 定义:强化学习是一种机器学习方法,其中智能体通过与环境交互,以获得最大化累积奖励的策略。
- 目标:学习如何在环境中采取行动以最大化长期奖励。
- 应用:游戏AI、机器人控制、自动驾驶、推荐系统。
- 例子:Q学习、深度Q网络(DQN)、策略梯度方法、Actor-Critic方法等。
-
自监督学习(Self-Supervised Learning):
- 定义:自监督学习是一种机器学习方法,利用数据内部的结构信息自动生成标签,从而进行模型训练。
- 目标:通过生成自标签,利用大规模未标记数据进行训练。
- 应用:自然语言处理(如BERT、GPT)、计算机视觉(如SimCLR、BYOL)。
- 例子:对比学习、生成对抗网络(GAN)的某些变体。 机器学习的学习方式可以根据数据标签的存在与否、学习的目标和方法等标准进行分类。主要的学习方式包括以下几种:
-
联邦学习(Federated Learning):
- 定义:联邦学习是一种分布式机器学习方法,其中多个节点在不共享原始数据的情况下协同训练模型。目标是保护数据隐私,同时利用多个数据源进行学习。
- 应用:跨设备学习、数据隐私保护。
- 常见方法:联邦平均算法(Federated Averaging)、加密计算。
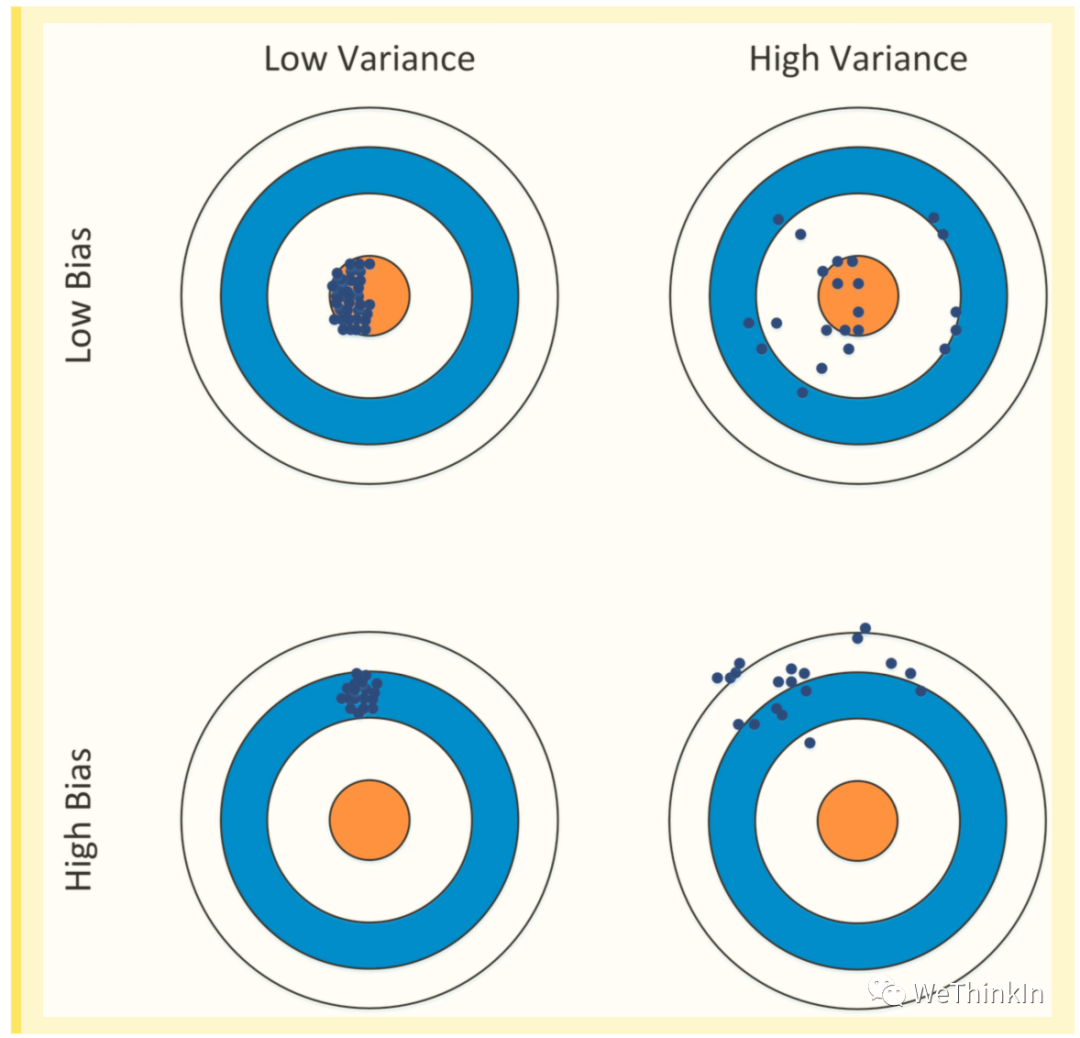
误差(Error)= 偏差(Bias) + 方差(Variance) + 噪声(Noise),一般地,我们把机器学习模型的预测输出与样本的真实label之间的差异称为误差,其反应的是整个模型的准确度。
噪声(Noise):描述了在当前任务上任何机器学习算法所能达到的期望泛化误差的下界,即刻画了当前任务本质的难度。
偏差(Bias):衡量了模型拟合训练数据的能力,偏差反应的是所有采样得到的大小相同的训练集训练出的所有模型的输出平均值和真实label之间的偏差,即模型本身的精确度。
偏差通常是由于我们对机器学习算法做了错误的假设所导致的,比如真实数据分布映射的是某个二次函数,但我们假设模型是一次函数。
偏差(Bias)越小,拟合能力却强(可能产生过拟合);反之,拟合能力越弱(可能产生欠拟合)。偏差越大,越偏离真实数据。
方差描述的是预测值的变化范围,离散程度,也就是离期望值的距离。方差越大,数据的分布越分散,模型的稳定程度越差。
方差也反应了模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性。由方差带来的误差通常体现在测试误差相对于训练误差的增量上。
方差通常是由于模型的复杂度相对于训练样本数过高导致的。方差越小,模型的泛化能力越高;反之,模型的泛化能力越低。
常见模型评价方法:
均方误差 (回归任务常用指标)
错误率(分类任务常用指标) $$ error = \frac{1}{m} * \sum_{i=1}^{m} II (f(x_i) \not= y_i) $$ $$ error = \int (f(x) \not= y)^2p(x)dx \ $$
精度(分类任务常用指标) $$ accuracy = \frac{1}{m} * \sum_{i=1}^{m} II (f(x_i) = y_i) $$ $$ accuracy = \int (f(x) = y)^2p(x)dx \ $$
查准率(precision, P),查全率(recall, R)和F1得分(分类任务常用指标)
P-R曲线 在评估分类模型性能时,常常绘制查准率-查全率曲线(P-R曲线),其中查准率作为纵轴,查全率作为横轴。这种曲线能够直观地展示模型在不同阈值下的精确度和召回率。当一个模型的P-R曲线完全被另一个模型的曲线所包围时,我们通常认为被包围的模型性能较差。相反,如果两个模型的P-R曲线存在交叉,我们则需要比较它们在查全率等于查准率时的平衡点/整体曲线面积。一般来说,平衡点更高/曲线面积更大的模型被认为性能更优,因为它在保持较高的精确度的同时,也保持了较高的召回率。
ROC曲线 根据模型的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出真正例率和假正例率,分别以它们为横、纵坐标作图,就得到了“ROC 曲线”。其评价桶P-R曲线
机器学习的直接目的是希望模型在真实场景的数据上有很好的预测效果,泛化误差越低越好。
如何去跟踪泛化误差呢?这时就需要验证集和测试集了。
我们可以使用训练集的数据来训练模型,然后用测试集上的误差推测最终模型在应对现实场景中的泛化误差。有了测试集,我们可以在本地验证模型的最终的近似效果。
与此同时,我们在模型训练过程中要实时监控模型的指标情况,从而进行模型参数优选操作。验证集就用于模型训练过程中的指标评估。
一般来说,如果当数据量不是很大的情况(万级别以下)可以将训练集、验证集和测试集划分为6:2:2;如果是万级别甚至十万级别的数据量,可以将训练集、验证集和测试集比例调整为98:1:1。
常见数据集划分方法:
留出法(hold-out) 直接将数据集划分为两个互斥的集合,其中一个集合作为训练集,另一个作为测试集。在训练集上训练出模型后,用测试集来评估其测试误差,作为对泛化误差的估计。
k折交叉验证(k-fold cross validation) 通过分层抽样的方法,将数据集划分为$k$个大小相似的互斥子集。选择$k-1$个子集合并作为训练集,用于模型的训练,而剩下的一个子集则作为测试集,用于评估模型的性能。这个过程重复$k$次,每次选择不同的子集作为测试集,从而获得$k$组不同的训练/测试集组合。这种方式可以对模型进行k次独立的训练和测试,最终得到一个更加稳健和可靠的性能评估结果
自助法(boostrapping) 通过采用有放回抽样的方法,我们每次从原始数据集$D$中随机选择一个样本,并将其复制到新的数据集$D'$中。这个过程重复进行$m$次,从而创建了一个包含$m$个样本的训练集$D'$。根据概率论的公式,这种有放回抽样的方式意味着每个样本在$m$次抽样中都不被选中的概率是$(1-1/m)^m$。当m趋向于无穷大时,这个概率的极限值为36.8%。因此,可以预期大约有36.8%的原始样本不会出现在新数据集$D'$中,这些未出现在D’中的样本可以用来作为测试集,以评估模型的性能。
(注:在数据集划分时要主要类别的平衡)
如果模型在训练集上拟合效果比较优秀,但是在测试集上拟合效果比较差,则表示方差较大,说明模型的稳定程度较差,出现这种现象可能是由于模型对训练集过拟合造成的。
接下来我们用下面的射击的例子进一步解释这二者的区别。假设一次射击就是机器学习模型对一个样本进行预测。射中靶心位置代表预测准确,偏离靶心越远代表预测误差越大,其中左上角是最好的结果。
在机器学习领域中,奥卡姆剃刀(Occam's Razor)原理是一个重要的理论指导原则,通常被表述为:“面对一个具体问题,选择最合适和最简单的能够满足需求的算法模型。”
这一原则来源于14世纪的逻辑学家威廉·奥卡姆,他主张:“如无必要,勿增实体。”
这在传统深度学习领域已经经过大量的验证,比如说图像分类领域的ResNet、图像分割领域的U-Net、目标检测领域的YOLO,这些都是能够跨过周期的AI算法模型,都具备简洁、稳定、高效等特点。
在机器学习模型的设计和训练过程中,奥卡姆剃刀原则可以解释为:当两个或多个不同复杂度的模型都能够合理地解释或预测数据时,应选择最简单的那个。这一原则的应用主要体现在以下几个方面:
-
模型的泛化能力:简单的模型通常比复杂的模型更容易泛化到未见过的新数据上。复杂的模型可能会在训练数据上表现得非常好,但可能会因为过拟合而在新数据上表现不佳。
-
避免过拟合:在选择模型时,遵循奥卡姆剃刀原则有助于减少过拟合的风险。简单模型在参数少和结构简单的情况下,对数据的噪声和偶然的特征不那么敏感。
-
计算效率:简单模型通常计算需求较低,更快速且易于部署。在资源受限的环境中,如移动设备或嵌入式系统中,简单模型尤其受到青睐。
-
可解释性:简单模型通常更容易被理解和解释。在需要对模型的性能进行解释的领域(如金融、医疗等领域)中,简单模型可能更受欢迎。
在实践中,实现奥卡姆剃刀原则可以通过以下策略:
- 深入理解应用长颈:只有深入理解实际场景,在能够知道其中的特点与痛点,才能高屋建瓴为算法解决方案与产品的构建提供指导思想。
- 选择合适的算法模型:根据实际场景,选择适当复杂度的模型。
- 使用优化技巧:在模型训练过程中使用正则化项、修改模型部分结构等方法,来优化模型性能。
- 交叉验证:使用交叉验证来评估不同模型的性能,帮助选择最合适的模型。
总之,奥卡姆剃刀原则是一种有助于指导机器学习领域的算法工程师工作的哲学思想,它鼓励我们针对实际场景寻找最简洁的算法模型。在模型选择和开发过程中恰当地应用这一原则,可以帮助开发出既有效又高效的机器学习算法解决方案。
在机器学习和优化领域,没有免费的午餐定理(No Free Lunch Theorem, NFL)是一个非常重要的概念,由David Wolpert和William Macready在1997年首次提出。
这个定理深刻地表述了机器学习领域一个看似简单却深刻的观点:所有的优化算法在所有可能的问题上的平均性能都是相同的。
没有免费的午餐定理主要针对机器学习算法和优化搜索算法,它表明没有任何一个算法能在所有可能的问题上都表现得比其他算法更好。
换句话说,一个算法如果在某类问题上表现出色,那么必然存在另一类问题,在那里它的表现就不那么理想。这意味着机器学习算法的效果很大程度上依赖于它所应用的细分领域与具体问题(具体问题具体分析)。
更深层次的挖掘,Rocky认为NFL定理告诉我们,在机器学习领域,所有的行为与优化,都是“有得必有失的”,这个哲学思想也可以让算法工程师们破圈,不仅仅用于AI行业。
NFL定理的一个重要启示是,选择适当的机器学习算法需要考虑到具体问题的特性。例如,在处理含有大量噪声的数据时,某些算法可能就不如其他算法那么有效。这强调了对问题本质的理解对于算法选择的重要性。
由于没有任何一个算法能保证在所有情况下都是最优的,因此在选择模型和算法时,进行广泛的实验和交叉验证变得尤为重要。通过比较不同算法在特定数据集上的表现,我们可以更好地选择适合当前问题的模型。
NFL定理鼓励算法设计者和研究人员开发和测试多种不同的方法。因为不存在单一的最佳算法,多样化的方法可以提供更广泛的工具集来处理各种各样的问题。
这一定理也告诫我们:评价一个算法模型的时候不能脱离具体应用场景。一个算法不能仅仅因为它在某个任务上表现出色就被认为是普遍优越的,同样,也不能因为在某个任务上的表现不佳就被完全摒弃。
例如,在机器学习中,决策树可能在某些类型的分类问题上表现得很好,而在其他问题上,则可能由于数据的特性(如特征间的非线性关系)导致表现不佳。相比之下,神经网络可能在处理复杂模式(如图像和语音数据)时表现更好,但在一些简单或小规模的数据集上则可能过拟合。
“没有免费的午餐”定理提醒我们,算法选择应基于具体问题的性质和数据特点进行。它强调了机器学习实践中对问题理解的重要性,并指导我们在实际应用中采取多种策略进行算法选择和优化。这一理论对于推动算法创新和适应性选择具有重要意义。
判别式模型和生成式模型在机器学习中的本质区别主要在于它们的模型目标和学习方法。
判别式模型(Discriminative Model):
- 目标:直接学习输入数据
$X$ 和标签$Y$ 之间的决策边界,即条件概率$P(Y|X)$ 。 - 任务:对未见数据$X$ ,根据
$P(Y|X)$ 可以求得标签$Y$ ,即可以直接判别出来未见数据的标签,主要用于分类和回归任务,关注如何区分不同类别。 - 例子:逻辑回归、支持向量机(SVM)、神经网络、随机森林等。
生成式模型(Generative Model):
- 目标:学习输入数据
$X$ 和标签$Y$ 的联合概率分布$P(X, Y)$ ,并通过它推导出条件概率$P(Y|X)$ 。 - 任务:不仅用于分类,还可以生成新的数据样本、建模数据的分布。
- 例子:扩散模型、高斯混合模型(GMM)、隐马尔可夫模型(HMM)、朴素贝叶斯、生成对抗网络(GAN)等。
判别式模型:
- 只关心数据之间的决策边界,直接学习如何将输入数据映射到标签。
- 通过优化损失函数(如交叉熵损失、均方误差等)来调整模型参数。
- 只需要考虑如何将特征
$X$ 映射到标签$Y$ ,不考虑数据本身的生成机制。
生成式模型:
- 关心数据的生成过程,学习数据和标签的联合分布
$P(X, Y)$ 。 - 通过学习数据分布,可以生成新的数据样本。
- 可以通过贝叶斯定理
$P(Y|X) = \frac{P(X, Y)}{P(X)}$ 来进行分类。
判别式模型:
- 主要用于分类和回归任务,如图像分类、文本分类、情感分析等。
- 优点:在分类任务上通常表现更好,因为直接优化分类决策边界。
生成式模型:
- 用于生成数据、填补缺失数据、异常检测、隐变量模型等。
- 优点:能够生成新数据样本,可以更好地理解数据的内部结构和分布。
判别式模型:
- 优点:通常在分类精度和性能上优于生成式模型,尤其在大数据集和高维特征空间下表现更好。
- 缺点:无法生成数据,无法建模数据的内部生成机制。
生成式模型:
- 优点:可以生成新的数据样本,能够更好地理解数据的生成过程;在小数据集或数据缺失的情况下表现较好。
- 缺点:在分类任务上可能不如判别式模型精确,计算复杂度通常较高。
具体例子:判断一个图像是是二次元图像还是写实图像。
-
判别式模型:学习建模决策边界
$P(Y|X)$ ,通过优化损失函数来找到最佳决策边界。然后通过提取这张图像的特征来预测出这张图像是二次元图像的概率和是写实图像的概率,最后取概率较大者。 -
生成式模型:学习建模二次元图像的联合概率分布
$P(X, Y_{1})$ ,再学习建模写实图像的联合概率分布$P(X, Y_{2})$ ,然后通过贝叶斯定理计算$P(Y|X)$ 。然后从这张图像中提取特征,放到二次元图像模型中看概率是多少,再放到写实图像模型中看概率是多少,哪个概率大就是哪个。同时因为学习到的二次元图像模型可以去生成二次元图像特征的概率分布,由学习到的写实图像模型可以去生成写实图像特征的概率分布,所以生成式模型可以生成新的数据。
生成式模型和判别式模型的目的都是在使后验概率最大化,判别式是直接对后验概率建模,但是生成模型通过贝叶斯定理这一“桥梁”使问题转化为求联合概率。
总而言之,判别式模型和生成式模型在模型目标、学习方式、应用场景和优缺点等方面都有显著区别。选择哪种模型取决于具体的AI应用需求。
这句话是AI领域的一个行业基本认知,强调了数据质量和特征选择在AI领域中的核心作用。下面Rocky将分步详细解释这个行业基本认知的含义及其重要性:
数据的质量和数量:
- 数据的质量:数据质量包括准确性、完整性、一致性和可靠性。高质量的数据能够更好地代表实际问题,提供更真实的学习材料。
- 数据的数量:数据量决定了AI模型能学到的“经验”与“知识”的多少。在很多情况下,数据量的增加可以显著提高AI模型的整体性能和泛化能力。
特征的选择和构造:
- 特征选择:从现有的数据特征中选择最有影响力的特征。选择正确的特征可以提高模型的学习效率和预测准确度。
- 特征工程:是指通过专业知识和技术手段创造出更有用的特征,以增强模型的学习能力和效果,比如说数据标注就是一个典型的特征工程。
模型和算法在机器学习中的作用是在给定的数据和特征基础上,通过学习来逼近理想的函数或决策过程。换言之,它们负责找到数据中的模式和关系,然后用这些学到的模式来做预测、分类和生成。虽然选择合适的模型和优化算法对提升性能至关重要,但它们的能力上限依旧受到数据质量和特征选择的限制。
这里的“上限”指的是在最优数据和特征组合的条件下,模型可能达到的最高性能。理论上,这是对给定问题能够实现的最佳解决方案的一种估计。任何机器学习模型,无论其复杂度如何,都只能逼近这个上限。
在实际的AI项目中,这意味着应该优先关注数据的采集、筛选、处理和特征的构造。一旦这些基础做好,再通过适当的模型和算法来尽可能逼近这个理论上限。忽视数据和特征的重要性而过分依赖模型和算法的调优,可能会导致资源的浪费和AI项目效果的不理想。
因此,Rocky认为这句话强调了在AI领域,我们应当将大量的精力和资源投入到数据和特征的质量提升上,这是成功落地AI项目的关键。而模型和算法的优化虽然也很重要,但更多的是在已有的“上限”内进行效率和性能的提升。
AutoML(Automated Machine Learning)是指通过自动化技术来简化和加速机器学习模型开发、优化和部署的过程。AutoML技术的目标是让我们能够轻松构建高性能的机器学习模型,而不需要具备深厚的AI专业知识。以下是Rocky对AutoML的详细讲解:
-
自动化数据预处理
- 数据清洗:处理缺失值、异常值和重复数据。
- 特征工程:自动化数据增强、特征选择、数据优化等。
- 数据分割:自动化数据集划分为训练集、验证集和测试集。
-
自动化模型选择
- 算法选择:根据数据集特点自动选择适合的AI模型,如CNN、Transformer、扩散模型、自回归模型等。
- 超参数调优:自动搜索最佳的超参数组合,如学习率、正则化参数、迭代次数等。
-
自动化模型训练和评估
- 模型训练:自动化训练模型并评估其性能。
- 模型评估:自动选择评估指标(如准确率、精确率、召回率、F1分数等)并优化模型。
-
自动化模型部署
- 模型导出:自动化将训练好的模型导出为可部署的格式。
- 模型部署:自动化将模型部署到生产环境中进行预测服务。
- 超参数优化(Hyperparameter Optimization, HPO)
- 神经架构搜索(Neural Architecture Search, NAS)
- 自动特征工程(Automated Feature Engineering)
- 模型集成(Model Ensemble)
优点:
- 简化机器学习流程:降低了模型开发的门槛,使非专家用户也能构建高性能模型。
- 提高生产效率:减少了模型开发时间和成本,快速迭代模型。
- 自动化优化:通过自动化超参数调优和架构搜索,提升模型性能。
缺点:
- 计算资源消耗:自动化搜索和调优过程可能需要大量计算资源。
- 解释性不足:自动生成的模型和特征可能难以解释,影响透明度。
- AIGC
- 传统深度学习
- 自动驾驶
AutoML通过自动化数据预处理、模型选择、超参数调优、模型训练和部署,极大地简化了机器学习模型的开发过程,提高了模型的性能和开发效率。虽然仍存在一些挑战和限制,但随着技术的不断进步,AutoML在各个领域的应用前景十分广阔,将推动AI领域的持续发展。
熵也称为香农熵、信息熵,它衡量了一个概率分布的随机性程度,或者说它包含的信息量的大小。而随机变量可以取多个值,因此需要计算它取所有值时所包含的信息量。随机变量取每个值都有一个概率,因此可以计算它取各个值时的数学期望,这个均值就是熵。
对于离散型随机变量,假设其取值有n种情况,则计算公式为:
- 对于离散型随机变量,当其服从均匀分布时,熵有极大值为lnn。取某个值的概率为1,其他概率为0时,熵有极小值
- 对于连续型随机变量,当其服从正态分布时,熵有极大值为$\ln\left(\sqrt{2\pi}\sigma\right)+\frac{1}{2}$
注意
- 正态分布的熵只与方差有关而与均值无关
- 以上极大值证明均可通过构造拉格朗日乘子函数求解
交叉熵定义于两个概率分布之上,反映了它们之间的差异程度。机器学习算法在很多时候的训练目标是使模型拟合出的概率分布尽量接近目标概率分布,因此可以用交叉熵来构造损失函数。
交叉熵的定义与熵类似,但定义在两个概率分布之上。交叉熵同样是数学期望,衡量了两个概率分布的差异。其值越大,两个概率分布的差异越大,越小,则两个概率分布的差异越小。
对与离散型随机变量,p(x)和 q(x)是两个概率分布的概率质量函数,交叉熵定义为
- 交叉熵不具有对称性,H(p,q)!=H(q,p)
- 当两个概率分布相等时,交叉熵有极小值(可通过构造拉格朗日乘子函数证明)
证明logistic回归和softmax回归的损失函数是交叉熵损失函数
STEP1:由极大似然估计写出似然函数
STEP2:对似然函数取对数即可得到交叉熵损失函数
KL散度的概念来源于概率论和信息论中,在机器学习、深度学习领域中,KL散度被广泛运用于EM算法和生成模型中,如变分自编码器(Variational AutoEncoder)、GAN、Diffusion-model等。KL散度是用来衡量两个概率分布之间的差异。其值越大,则两个分布之间的差距越大,当两个概率分布完全相等时,KL散度值为0
KL散度的定义在两个概率分布之上,用于度量两个分布之间的差异,通常用于构造目标函数以及对算法进行理论分析。
KL散度在信息论中的专业术语为相对熵。其可理解为编码系统对信息进行编码时所需要的平均附加信息量。其中信息量的单位随着计算公式中log运算的底数而变化。
- log底数为2:单位为比特(
bit) - log底数为
e:单位为奈特(nat)
对于同一个随机变量x有两个单独的概率分布p(x)和q(x),可以使用KL散度来衡量这两个分布的差异
对于两个离散型概率分布p和q,他们之间的KL散度定义为:
对于两个连续型概率分布p和q,他们之间的KL散度定义为:
KL 散度与交叉熵均反映了两个概率分布之间的差异程度,下面推导它们之间的关系。根据KL散度与交叉熵、熵的定义,有
$\begin{aligned} D_{K L}(p | q) & =H(p ,q)-H(p) \ & =-\sum_{x} p(x) \log q(x)+\sum_{x}p(x) \log p(x) \ & =-\sum_{x} p(x)(\log p(x)-\log q(x)) \ & =-\sum_{x} p(x) \log \frac{p(x)}{q(x)} \end{aligned}$
1、kL散度非负,对于任意两个概率分布p和q,有
当且仅当两个概率分布相等,KL散度有最小值0
2、KL散度不具有对称性,即一般情况下
3、两个d维正态分布KL散度计算公式
他们的KL散度为
4、d维正态分布与标准正态分布KL散度计算公式
在机器学习领域中,耦合(coupling)和解耦(decoupling)是两个关键概念,涉及到模型、数据、测试和系统整体设计的独立性与依赖性。理解这两个概念有助于我们构建更灵活、可维护性更高的机器学习系统。根据具体应用场景选择合适的设计方法,将极大地提升机器学习项目的成功率和可持续性。
首先我们对这两个概念进行详细的解释:
耦合指的是机器学习系统的不同部分之间存在较强的依赖关系。高耦合的机器学习系统各部分紧密联系,改变一个部分可能会影响到其他部分,导致系统整体的复杂性和维护成本增加。
解耦指的是机器学习系统的不同部分之间尽可能减少依赖关系,使得它们可以独立研发、测试和维护。解耦可以提高系统整体的灵活性、可扩展性和可维护性。
-
模型和数据存在耦合的情况:
- 例如,一个AI模型可能对特定的数据分布或特征非常依赖。这意味着如果数据分布发生变化,模型的性能可能会显著下降。
- 例子:在AIGC时代中,如果数据中大量混入低质量数据,模型推理效果可能很差,导致模型需要重新训练。
-
算法和硬件的耦合:
- 一些算法可能针对特定硬件(如GPU)的优化,这会导致算法无法在其他硬件(如CPU)上高效运行。
- 例子:深度神经网络训练时通常依赖GPU加速,如果没有GPU资源,训练速度会大大降低。
-
模型和超参数的耦合:
- 一些模型需要精细化调优超参数来取得较好的性能,如果参数调整的不正确,模型的性能可能会显著下降。
- 例子:AIGC、传统深度学习、自动驾驶领域的AI模型都有这个特性。
-
模块化设计:
- 模型、数据和算力等模块彼此独立,可以单独测试和优化。
- 例子:在AIGC、传统深度学习、自动驾驶领域中,将数据处理、模型训练、模型测试、模型部署分开,每个模块单独研发和测试。
-
通用接口:
- 使用通用接口使得不同模块可以方便地互相替换或升级,而不会影响整个AI系统。
- 例子:定义标准的数据输入输出格式,使得更换数据预处理模块不会影响模型训练过程。
-
优点:
- 优化性能:针对特定任务或数据进行优化可以提高模型的性能。
- 简化设计:在特定任务中,高耦合可以简化设计,因为所有部分紧密集成。
-
挑战:
- 维护困难:修改或扩展系统时,可能需要同时修改多个部分。
- 可移植性差:高耦合系统通常难以迁移到不同的环境或任务中。
-
优点:
- 灵活性高:各模块可以独立研发、测试和优化,提高AI系统的灵活性。
- 可扩展性好:新模块可以方便地集成到现有AI系统中,而不需要大规模改动。
-
挑战:
- 设计复杂:设计解耦的AI系统需要考虑更多的接口和模块化设计,增加了初始设计的复杂性。
- 性能优化:解耦的AI系统中的各模块可能需要单独优化,确保整体性能。
代价函数是一种用于衡量模型预测值与实际真实值之间差异的函数。其主要用途是通过不断调整模型参数来最小化这个差异,从而寻找模型参数的最优解。在这个过程中,代价函数作为一个优化目标,其值反映了模型在给定参数下的性能表现。
在代价函数的设计中,非负性是一个重要的特性。非负性的存在使得在优化过程中,如果算法能够持续地减小代价函数的值,根据单调有界准则,我们可以认为这个优化算法是收敛且有效的;同时,代价函数的非负性还保证了所有的代价值都是正值或者零,这对于模型的评估和调试来说更为方便。
- 二次代价函数:
其中,
- 分析
根据假设(1)样本预测值为
可以看出,
- 交叉熵代价函数:
其中,
- 分析
根据假设(1)样本预测值为
可以看出,
- 和交叉熵函数的差异
如果输出层神经元是sigmoid函数,可以使用交叉墒代价函数。而如果将softmax作为最后一层,此时常用的代价函数是对数似然代价函数。
- 对数似然代价函数
其中,
- 分析
根据假设(1)样本预测值为
可以看出,
在机器学习中,特征编码和特征解码是数据预处理的重要环节。特征编码(Feature Encoding)是将原始数据转换为AI模型能够处理的数值形式,而特征解码(Feature Decoding)是将AI模型输出的数值形式转换回原始数据形式或可解释的形式。
特征编码是指将原始数据转换成数值形式,以便模型可以处理。不同类型的数据需要不同的编码方法。
数值特征通常可以直接使用,但为了提高模型性能,常进行标准化或归一化。
-
标准化(Standardization):将数据转换为均值为0,标准差为1的分布。
$$z = \frac{x - \mu}{\sigma}$$ 其中,
$x$ 是原始数据,$\mu$ 是均值,$\sigma$ 是标准差。 -
归一化(Normalization):将数据缩放到特定范围(通常是0到1)。
$$x' = \frac{x - \min(x)}{\max(x) - \min(x)}$$
类别特征需要转换为数值形式,常用的方法有:
-
独热编码(One-Hot Encoding):将每个类别转换为一个独热向量。例如,类别
A、B、C可以转换为[1,0,0]、[0,1,0]、[0,0,1]。 -
标签编码(Label Encoding):将每个类别转换为一个唯一的整数。例如,类别
A、B、C可以转换为0、1、2。 -
目标编码(Target Encoding):将类别特征编码为目标变量的均值。常用于目标是数值回归问题时。
对于时间序列或文本数据,通常使用嵌入或特定的预处理方法,如:
-
词嵌入(Word Embedding):如Word2Vec、GloVe、BERT等,将单词映射到一个高维向量空间中。
-
序列填充(Padding):将不同长度的序列填充到相同长度,以便批处理。常用于RNN、LSTM等模型。
特征解码是将模型的输出转换回原始数据形式或可解释的形式。
如果在编码过程中对数据进行了标准化或归一化,需要在解码时反向转换:
-
反标准化:
$$x = z \cdot \sigma + \mu$$ -
反归一化:
$$x = x' \cdot (\max(x) - \min(x)) + \min(x)$$
对于类别特征的解码,常用的方法有:
-
独热编码解码:将独热向量转换回原始类别。例如,
[1,0,0]解码为类别A。 -
标签编码解码:将整数标签转换回原始类别。例如,
0解码为类别A。
对于序列数据,解码过程可能涉及将嵌入向量转换回单词或其他序列元素:
-
嵌入解码:将嵌入向量转换回对应的单词或类别。
-
序列生成:在自然语言处理任务中,生成文本序列(如机器翻译、文本生成等)。
import numpy as np
# 数据标准化
def standardize(data):
mean = np.mean(data)
std = np.std(data)
standardized_data = (data - mean) / std
return standardized_data, mean, std
# 数据反标准化
def destandardize(standardized_data, mean, std):
original_data = standardized_data * std + mean
return original_data
data = np.array([1, 2, 3, 4, 5])
standardized_data, mean, std = standardize(data)
print("Standardized Data:", standardized_data)
original_data = destandardize(standardized_data, mean, std)
print("Original Data:", original_data)from sklearn.preprocessing import LabelEncoder, OneHotEncoder
# 标签编码
label_encoder = LabelEncoder()
labels = ['cat', 'dog', 'fish']
encoded_labels = label_encoder.fit_transform(labels)
print("Label Encoded:", encoded_labels)
# 标签解码
decoded_labels = label_encoder.inverse_transform(encoded_labels)
print("Label Decoded:", decoded_labels)
# 独热编码
onehot_encoder = OneHotEncoder(sparse=False)
encoded_labels = encoded_labels.reshape(len(encoded_labels), 1)
onehot_labels = onehot_encoder.fit_transform(encoded_labels)
print("One-Hot Encoded:", onehot_labels)在机器学习中,Embedding特征的本质是将高维、稀疏或类别特征映射到一个低维的、密集的向量空间中,同时保留并捕捉特征之间的语义关系。它通过优化输入表示,使得机器学习模型能够更加有效地学习数据中的模式和关系。
Embedding 是一种特征向量化的过程。原始的输入数据(如单词、物品ID、用户ID等)通常是离散的、类别性的,并且维度可能非常高。例如,假设我们有一个包含数百万个单词的词汇表,每个单词可以看作是一个独立的类别。如果直接使用这些类别作为输入,模型将难以有效处理,因为这些类别通常用独热编码(one-hot encoding)表示,这会导致极高维度且非常稀疏的输入向量。
Embedding通过将这些高维的类别特征映射到低维的向量空间中,使得原本稀疏的、离散的表示变成了密集的、连续的向量。这些向量通常具有较低的维度,并且能够捕捉类别之间的语义相似性。
Embedding 的一个关键特性是它可以捕捉到类别之间的语义关系。在文本处理中,类似的单词会在Embedding空间中靠得更近,例如“猫”和“狗”可能会具有相似的向量表示,因为它们在语义上是相近的。这种语义关系可以通过模型在训练数据上学习到,并在Embedding空间中反映出来。
Embedding特征为模型提供了更加紧凑且有意义的输入表示,使得模型能够更好地学习和泛化。通过将高维的离散特征压缩到低维的连续空间,模型不仅减少了计算复杂度,还能够更好地捕捉特征之间的隐含关系。
Embedding 特征通常是通过模型训练得到的。在训练过程中,Embedding 矩阵的权重会不断更新,以便更好地满足特定任务的目标。这意味着 Embedding 不仅是一种数据预处理方式,更是一种可学习的表示方法,它随着模型的训练不断优化,进而提高模型在特定任务上的性能。
Embedding 特征在多个领域得到了广泛应用,包括自然语言处理(词嵌入)、推荐系统(用户和物品的嵌入)、计算机视觉(图像特征的嵌入)等。在这些应用中,Embedding 帮助模型更好地理解和处理复杂的输入数据,提升了模型的预测能力。
在AI领域中,数据模态(Data Modalities)指的是不同类型的数据形式。每种模态数据都有其特定的结构和特点,AI模型必须以不同的方式处理它们。以下是一些主要的数据模态的详细解释:
- 类型:图像、视频
- 人类信息接收比例:约占人类感知信息的80%左右。
- 描述:
- 图像和视频是人类最重要的感知形式,视觉模态的数据主要用于计算机视觉领域的任务,如图像分类、目标检测、语义分割、人脸识别、目标追踪、图像生成、视频生成、视频分析等。
- 视觉数据的主要特点是高维度、结构化等。
- 类型:声音、语音、音乐
- 人类信息接收比例:约占人类感知信息的10-15%左右。
- 描述:
- 听觉模态包括声音和语音数据,音频信号是随时间变化的一维数据,但其频域特征也非常重要。
- 在AI领域中,听觉模态主要应用于语音识别、语音合成、情感识别、音乐推荐、声纹识别等任务。
- 类型:文本、自然语言
- 人类信息接收比例:人类直接通过语言获取的信息占比约为7-10%,但如果考虑通过阅读、学习获取的信息,比例会更高。
- 描述:
- 语言模态包括所有形式的书面或口头语言,它是人类交流的核心工具。文本数据通常是离散的、高度结构化的序列数据、代表符号或词汇。
- 在AI领域中,语言模态被用于任务如机器翻译、情感分析、文本生成、问答系统等。
- 类型:压力、振动、温度、纹理
- 人类信息接收比例:约占人类感知信息的1-2%。
- 描述:
- 触觉模态涉及通过皮肤感知物理特性,如压力、温度、质地等。这种感知在机器人、假肢控制、虚拟现实中非常重要。
- 在AI领域中,触觉数据通常来源于传感器阵列,需要进行高分辨率的时空分析。应用包括机器人抓取、材料识别、触觉反馈系统等。触觉模态的处理通常与其他模态结合,如视觉和运动,来提供更丰富的感知和交互能力。
- 类型:位置、速度、加速度、角度、姿态
- 人类信息接收比例:占比很小,但在特定任务如运动控制中非常重要。
- 描述:
- 运动模态涉及对物体或人体的运动轨迹、速度、加速度等的感知。它在运动捕捉、机器人导航、虚拟现实等领域尤为重要。
- 这类数据通常由加速度计、陀螺仪、摄像机等传感器捕获,在应用中经常与其他数据模态结合进行多模态融合分析。
- 类型:结合上述多种模态的数据
- 描述:
- 多模态融合是指结合来自不同感知通道的数据,以获得更全面的信息表示。例如,在自动驾驶中,视觉(摄像头)、雷达、激光雷达和运动传感器的数据融合,可以提供更加可靠的环境感知能力。
- 处理多模态数据的挑战在于如何有效地整合不同模态的信息,因为它们的数据结构和特性通常不同。
在AI行业中,不管是AIGC、传统深度学习还是自动驾驶领域,数据增强都是一个非常重要的技术手段。
数据增强通过扩展训练数据集的数量,让训练数据分布逼近真实的细分领域数据分布。举个例子,比如说我们要检测识别花卉种类,那么我们的训练数据集要尽可能包含真实世界的所有花卉,还要考虑到他们的所处的环境干扰。在这里花卉就是一个细分领域,是我们需要使用数据增强技术进行逼近的分布。
更宽泛的来讲,未来的AGI时代,AGI模型需要知晓真实世界的所有数据分布,那么这时训练数据集就要逼近真实世界的所有分布。
实际效果上看,通过数据增强技术,从而丰富AI模型学习的特征空间,能够提高AI模型的泛化性和鲁棒性。
在机器学习中,音频数据具有一些独特的特点,了解这些特点有助于我们设计更有效的算法和模型:
音频信号是一种典型的时序数据,随着时间变化而变化。这意味着音频数据中的每个样本都是时间序列的一部分,音频数据的处理需要考虑时间的连续性。时间维度的存在使得音频数据不同于普通的静态数据,分析音频时,必须理解每个时间点的声音如何与上下文相关联。我们可以使用 RNN(循环神经网络)、LSTM 或者 Transformer 模型来处理音频时序性。
音频信号的频率特征反映了其波动的快慢。声音可以分解为不同的频率分量,每个频率对应不同的音调。频率特性是音频信号的关键特征之一,可以通过傅里叶变换或小波变换将音频数据从时域转换到频域,来捕捉其中的频率信息。
音频信号通常是非平稳的,即音频信号的统计特性(如均值和方差)会随时间变化。例如,语音信号中的不同语音片段对应不同的频率和能量分布。为了更好地处理这种非平稳性,音频信号通常被分割成多个短时间窗口,每个窗口假设为平稳信号。我们可以使用短时傅里叶变换 (STFT) 等特征提取方法可以帮助分析音频的非平稳性。
原始音频数据(如采样后的波形)往往具有非常高的维度。以 CD 质量音频为例,采样率为 44.1kHz,这意味着每秒音频需要处理 44,100 个采样点。对于长时间音频或高采样率音频,维度极高,处理起来非常耗时且复杂。我们可以使用降维方法,如 MFCC 或频谱图,可以从高维音频数据中提取重要特征,减少计算开销。
音频数据通常会受到噪声的影响,包括环境噪声、麦克风噪声和其他干扰信号。噪声会对音频的质量和特征提取过程产生负面影响。因此,处理音频数据时,通常需要进行降噪或噪声处理,我们可以使用降噪技术包括自回归模型、维纳滤波、神经网络降噪方法等。
音频信号往往与其他模态(如文本、视频等)相关联。例如,语音数据通常可以与文本数据配对,用于语音识别或自然语言处理任务。在多模态学习中,音频信号是一个重要的输入信号。
音频信号(尤其是音乐信号)往往表现出一定的周期性。例如,音调、节奏、乐器的声音等具有固定的频率和重复的结构。这种周期性特征是音频处理中的重要信息。通过频域分析可以提取音频信号的周期特征,如音高检测和节奏分析。
音频信号的能量分布能够反映声音的强弱,语音信号中的不同片段可能具有不同的能量。常见的音频特征如谱图能量可以帮助分析音频信号中的不同部分,能量的变化有时可以用于检测音频的起始或终止点。
音频信号除了频率和幅度之外,还包含相位信息。相位描述了信号在特定时间点的周期性波动的开始和结束位置。在某些应用中,如音乐生成或音频修复,相位信息是关键的,但在特征提取时,通常主要关注频率和幅度特征,相位信息可以忽略。
由于人耳对不同频率的声音有不同的敏感性,音频数据中的一些高频或低频成分可能并不重要。在音频处理中,通常会使用类似于梅尔刻度的频率变换来模拟人耳的听觉感知。
为了同时捕获音频的时间和频率特性,通常会采用时频分析工具,如短时傅里叶变换 (STFT)、梅尔谱图或连续小波变换 (CWT),这些工具能够同时展示音频信号在时间和频率上的变化。
在机器学习和优化问题中,全局最优(Global Optimum)和局部最优(Local Optimum)是两个非常重要的概念,尤其在涉及非线性优化、模型训练和参数优化时。理解它们的区别和影响对于选择合适的优化算法、调优模型具有重要意义。
全局最优指的是在整个可行解空间中,找到的最优解(通常指目标函数的最大值或最小值)是所有可能解中的最优解,即整个搜索空间中最好的解。
- 如果是最小化问题,全局最优是指在整个空间内,目标函数取得最小值的点。
- 如果是最大化问题,全局最优是指目标函数取得最大值的点。
数学表达:
或
其中,
局部最优指的是在某个局部区域内(局部邻域或子集)找到的最优解。即该解在它周围的解中是最优的,但不一定是整个解空间中的最优解。
- 在最小化问题中,局部最优点是指在某个小区域内,目标函数在这个点的值小于或等于周围所有点的值。
- 在最大化问题中,局部最优点是指在某个小区域内,目标函数在这个点的值大于或等于周围所有点的值。
数学表达:
或
其中, $N(x^)$ 是局部区域或邻域, $x^$ 是局部最优解。
-
定义范围不同:
- 全局最优解是在整个搜索空间中的最优解。
- 局部最优解是在局部区域内的最优解,但它不一定是全局最优解。
-
解的唯一性:
- 全局最优解通常是唯一的(但也有可能存在多个等值的全局最优解)。
- 局部最优解可能有多个,每个局部区域都有可能存在局部最优解。
-
求解难度:
- 找到全局最优解在复杂的非凸优化问题中通常非常困难,需要更多的计算资源和更复杂的算法。
- 局部最优解相对容易找到,许多简单的优化算法(如梯度下降法)在没有特殊设计的情况下,往往会停留在局部最优解上。
找到全局最优解在理论上是优化问题的最终目标。无论是最小化损失函数还是最大化奖励函数,找到全局最优解意味着我们已经找到了整个问题的最优解决方案,这是最优性能的保证。
例如:
- 在深度学习中,全局最优意味着找到能使模型损失函数(如交叉熵、均方误差)在整个参数空间中最小的参数组合。
- 在强化学习中,找到全局最优策略意味着找到了在所有可能状态下都能最大化累积回报的策略。
在实际应用中,找到局部最优解也是有意义的,特别是在非常复杂的高维问题中,全局最优解难以求解,局部最优解往往已经能提供相对不错的解决方案。此外,很多现实问题中,找到某个局部最优解也已经能满足需求。
例如:
- 在深度学习模型训练中,由于损失函数通常是非凸的(特别是在深度神经网络中),找到全局最优解非常困难,但找到一个合适的局部最优解往往已经能保证模型的较好性能。
- 在优化时间受限的情况下,快速找到一个局部最优解有时比花费大量时间去逼近全局最优更加实用。
对比学习(Contrastive Learning)是一种无监督学习方法,其核心目标是通过对比数据样本之间的相似性与差异性,学习出高质量的特征表示。在机器学习和深度学习中,对比学习被广泛用于生成语义丰富的表示,特别是在视觉、自然语言处理(NLP)和多模态任务中。
对比学习的关键在于:
- 将相似的数据样本拉近:对语义相似或共享上下文的样本,学到的表示应该在高维嵌入空间中接近。
- 将不相似的数据样本拉远:对于语义无关或无上下文关系的样本,其嵌入表示应该远离。
通过这一拉近和拉远的机制,模型可以在没有明确监督信号(如标签)的情况下,学习到语义上有意义的特征。
- 正样本对是语义相似的两个数据样本。
- 通常通过数据增强生成,例如对一张图像应用不同的增强方法(裁剪、翻转、变换等)。
- 负样本对是语义上不相关的两个数据样本。
- 通常在一个小批量数据中,将不同样本视为负样本。
- 对比学习通过设计损失函数,使正样本对在嵌入空间中更接近,负样本对更远离。
- 常用的对比损失包括:
-
基于欧几里得距离的对比损失:
$$
L = y \cdot D^2 + (1-y) \cdot \max(0, m-D)^2
$$
-
$D$ 是样本对的欧几里得距离。 -
$y$ 表示样本对的标签(1 为正样本对,0 为负样本对)。 -
$m$ 是一个距离的阈值。
-
-
InfoNCE 损失:
$$
L = -\log \frac{\exp(\text{sim}(z_i, z_j)/\tau)}{\sum_{k=1}^N \exp(\text{sim}(z_i, z_k)/\tau)}
$$
-
$z_i, z_j$ 是正样本对的嵌入表示。 -
$\text{sim}(\cdot)$ 表示相似度函数(如余弦相似度)。 -
$\tau$ 是温度参数,用于调节分布平滑性。 -
$N$ 表示小批量中的样本数。
-
-
基于欧几里得距离的对比损失:
$$
L = y \cdot D^2 + (1-y) \cdot \max(0, m-D)^2
$$
对比学习的正样本对通常通过数据增强生成,常用的方法包括:
- 图像任务:随机裁剪、旋转、翻转、颜色扰动。
- 文本任务:同义词替换、删除、句子重组。
- 时间序列任务:时间窗裁剪、噪声添加。
使用神经网络将数据样本映射到高维嵌入空间:
- 使用主干模型(如 ResNet、Transformer)提取特征。
- 加入投影头(Projection Head)将特征映射到嵌入空间,用于对比学习。
在每个小批量中,生成多个正样本对和负样本对:
- 正样本对:同一数据的增强视图。
- 负样本对:其他样本的视图。
-
无需标签:
- 通过无监督学习,大幅减少对人工标注的依赖。
-
语义相关性:
- 嵌入空间的表示保留了语义信息,可以用在分类、检索等任务中。
-
泛化能力强:
- 学到的特征可以迁移到不同的下游任务。
在机器学习中,数据集的划分是非常关键的一步,通常将数据划分为训练集、验证集和测试集。
- 训练集是模型学习的依据;
- 验证集是模型优化的工具;
- 测试集是评估模型性能的标准。
正确地划分和使用这些数据子集是确保模型性能和泛化能力的关键。
训练集是用于训练模型的数据子集。模型通过训练集中的样本学习输入特征和目标输出之间的关系,调整模型的参数(如权重和偏置)以最小化预测误差。
- 模型训练的主要依据:训练集是用来优化模型的,模型会直接接触这些数据并从中学习。
- 数据量通常是最多的,以保证模型有足够的样本来学习数据分布。
- 通常用在监督学习中,训练集包括输入特征
$(X)$ 和对应的目标标签$(y)$ 。
- 优化模型的性能,使其能够尽可能准确地预测训练数据中的目标值。
- 学习数据的模式和规律。
验证集是用于评估模型性能并调整超参数的数据子集。模型通过验证集来评估在未见数据上的表现,从而指导模型的超参数调节和选择最佳模型。
- 模型优化的工具:验证集用来调节超参数(如学习率、正则化强度、神经网络的层数等),而不直接影响模型的权重。
- 验证集中的样本不用于训练,因此它能更好地反映模型在未知数据上的表现。
- 数据量一般比训练集少,但必须足够大以保证评估的可靠性。
- 避免模型过拟合(overfitting)或欠拟合(underfitting)。
- 帮助选择最佳的模型结构或超参数。
如果超参数调节过多,验证集实际上可能成为一种“隐式训练数据”,从而降低模型对真正未知数据的泛化能力。
测试集是用于最终评估模型性能的数据子集。这些数据在模型训练和验证过程中是完全未见的,目的是对模型的真实泛化能力进行客观评估。
- 最终性能的衡量标准:模型在测试集上的表现代表了它对完全未知数据的预测能力。
- 测试集数据不能用于模型的训练或优化。
- 数据量一般比训练集和验证集更少,但应足够大以确保评估的可靠性。
- 提供对模型在生产环境中真实表现的估计。
- 检测模型是否有过拟合的迹象(即在训练集和验证集上表现良好,但在测试集上表现差)。
| 特性 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|
| 用途 | 训练模型、调整权重 | 调整超参数,选择最佳模型 | 最终评估模型性能 |
| 模型接触方式 | 模型直接接触,权重被更新 | 模型间接接触,用于优化超参数 | 模型完全不可见,仅用于测试 |
| 数据量 | 最大 | 中等 | 最小 |
| 影响阶段 | 训练阶段 | 优化阶段 | 评估阶段 |
| 能否调整参数 | 是 | 是(调整超参数) | 否(仅用于测试) |
根据数据集大小的不同,训练集、验证集和测试集的划分比例也会有所不同。以下是常见的划分比例:
- 常规情况:训练集 : 验证集 : 测试集 = 6:2:2 或 8:1:1。
- 小数据集:由于数据量少,可以采用交叉验证(Cross-Validation)代替单一验证集。
- 大数据集:可以划分出更多比例的数据作为测试集或验证集。
-
验证集的动态性:
- 在训练过程中,验证集可能会多次用来评估模型。
- 如果过度依赖验证集调整超参数,可能导致模型在验证集上表现较好但对真正未知数据(测试集)表现较差。
-
测试集的隔离性:
- 测试集必须完全独立,不能用于调参,否则会失去衡量模型真实性能的意义。
- 如果多个模型使用同一个测试集进行评估,可能会导致数据泄漏或过度拟合。
在机器学习中,热插拔(Hot Plugging) 和 冷启动(Cold Boot) 的概念与计算机硬件领域类似,但其应用更侧重于算法、模型组件和数据的动态管理与初始化。
热插拔指在机器学习系统运行过程中,动态替换或扩展模型组件、数据源或计算资源,而无需中断系统整体运行的能力。其核心目标是提升系统的灵活性和实时响应能力。
- 动态模型架构:支持模块化设计(如插件式网络层)。
- 在线学习:实时加载新数据或调整模型参数。
- 资源弹性分配:在分布式训练中动态增减计算节点。
| 领域 | 案例 |
|---|---|
| AIGC | 实时切换生成模型的风格模块(如从“油画风”切换到“水墨风”)。 |
| 传统深度学习 | 在训练过程中动态插入注意力机制层以提升模型性能。 |
| 自动驾驶 | 动态加载不同天气条件下的感知模型(如雨天切换专用目标检测模型)。 |
冷启动指从零开始初始化机器学习系统或模型,通常涉及完整的数据加载、参数初始化和环境配置流程。其特点是资源消耗大但状态可控。
- 数据加载:从存储介质读取训练/推理数据。
- 模型初始化:随机初始化参数或加载预训练权重。
- 环境配置:设置超参数、优化器及硬件资源(如GPU分配)。
| 领域 | 案例 |
|---|---|
| AIGC | 首次部署多模态生成模型(如DALL·E 3)时的完整初始化。 |
| 传统深度学习 | 从零训练ResNet模型,需加载ImageNet数据集并初始化所有网络层参数。 |
| 自动驾驶 | 车辆启动时加载高精地图、感知模型(如YOLOv8)和路径规划算法。 |
| 特性 | 热插拔 | 冷启动 |
|---|---|---|
| 系统状态 | 运行中动态调整 | 完全初始化 |
| 资源开销 | 低(局部更新) | 高(全局初始化) |
| 典型场景 | 实时适配需求变化 | 系统首次部署或彻底重置 |
| 技术挑战 | 模块兼容性、状态一致性 | 初始化速度、资源占用优化 |
-
热插拔案例:
- 动态风格迁移:在生成视频时,用户实时更换风格化模块(如将“赛博朋克”风格插件热加载到Stable Diffusion模型中)。
- 技术实现:使用模块化设计(如PyTorch的
torch.nn.Module动态替换),结合API网关路由请求到不同模型分支。
-
冷启动挑战:
- 大模型加载延迟:启动175B参数的GPT-4需加载数百GB权重,耗时可能超过10分钟。
- 优化方案:使用参数分片(如DeepSpeed的ZeRO-3)和NVMe SSD加速加载。
-
热插拔案例:
- 在线模型增强:在推荐系统训练中,动态插入用户行为分析模块(如Transformer层)。
- 技术实现:通过PyTorch的
register_module接口动态扩展网络结构。
-
冷启动优化:
- 分布式训练初始化:使用Horovod或PyTorch Lightning的
DDP策略,优化多节点参数同步。 - 加速方案:预加载数据至共享内存(如Apache Arrow格式),减少IO延迟。
- 分布式训练初始化:使用Horovod或PyTorch Lightning的
-
热插拔案例:
- 传感器容错切换:当激光雷达故障时,动态切换至纯视觉感知模型(如Tesla的Occupancy Network)。
- 技术实现:ROS 2的
Component接口支持动态加载节点,确保系统持续运行。
-
冷启动关键性:
- 实时性要求:车辆启动时需在500ms内完成感知模型(如BEVFormer)和规划算法加载。
- 硬件加速:使用NVIDIA Jetson AGX的快速启动模式,结合QNX实时操作系统。
TopK 是机器学习中用于筛选数据集中前K个最相关元素的关键操作,其核心逻辑包含两个维度:
- 排序方向:选择最大(TopK Max)或最小(TopK Min)的K个值。
- 筛选粒度:可作用于单个样本(如分类概率排序)或整个数据集(如全局特征选择)。
-
全排序法:对全部元素排序后取前K个,时间复杂度为
$O(N \log N)$ ,适用于小数据量。 -
部分排序法:使用快速选择(Quickselect)算法,平均时间复杂度
$O(N)$ ,例如C++中的std::nth_element。 -
堆优化法:构建最大堆(取TopK Min)或最小堆(取TopK Max),时间复杂度
$O(N \log K)$ ,适合流式数据。
假设有数据集
其中
场景:用户购买手机后,需推荐Top5相关配件。
步骤:
- 特征提取:计算手机与配件的关联度(如协同过滤得分、语义相似度)。
- TopK筛选:对全平台配件按关联度排序,取前5名。
- 多样性控制:加入类别去重(如不重复推荐“充电器”类商品)。
代码片段(Python示例):
import heapq
def recommend_topk(items, scores, k=5, category_limit=2):
# 使用堆获取原始TopK
topk = heapq.nlargest(k, zip(scores, items))
# 控制品类多样性
category_count = {}
final_results = []
for score, item in topk:
cat = item.category
if category_count.get(cat, 0) < category_limit:
final_results.append(item)
category_count[cat] = category_count.get(cat, 0) + 1
if len(final_results) == k:
break
return final_results- 应用场景:文本/图像生成的多候选择优。
- 技术细节:
- Beam Search:在生成每个token时保留概率TopK的候选序列,平衡生成质量与计算开销。
- 图像超分重建:对Latent Diffusion模型输出的多个候选图像,通过CLIP分数选取Top3进行融合。
- 案例:Stable Diffusion的
k-diffusion采样器,在每一步去噪时对潜在空间噪声预测结果做TopK筛选,提升生成稳定性。
- 应用场景:分类与目标检测。
- 技术细节:
- TopK准确率:ImageNet评估中不仅看最高概率类别,还计算预测概率前5名是否包含真实标签。
- 非极大值抑制(NMS):目标检测中,对同一物体的多个候选框按置信度排序后,保留Top1并抑制重叠框。
- 案例:YOLOv7的NMS模块采用加权融合策略,对TopK候选框进行坐标加权平均,提升定位精度。
- 应用场景:多目标跟踪与路径规划。
- 技术细节:
- 点云目标检测:对激光雷达点云进行体素化后,在每个体素区域内保留强度TopK的点以降低计算量。
- 轨迹预测:对自动驾驶车辆周围的行人/车辆,预测其未来Top3可能路径,用于风险评估。
- 案例:Waymo的PathNet模型通过TopK采样子未来轨迹,结合马尔可夫链蒙特卡洛(MCMC)优化最终路径选择。
| 维度 | 预训练(Pre-training) | 微调(Fine-tuning) |
|---|---|---|
| 目标 | 学习通用特征表示(如语言结构、视觉基础模式) | 适配特定任务(如情感分析、目标检测) |
| 数据 | 大规模无标注/弱标注数据(如Common Crawl、ImageNet) | 小规模高质量标注数据(如业务日志、专业数据集) |
| 训练方式 | 自监督/无监督学习(如MLM、对比学习) | 监督学习(任务特定损失函数,如交叉熵) |
| 计算资源 | 高(需GPU集群训练数周) | 低(单卡数小时至数天) |
| 参数更新 | 全部或大部分参数 | 通常仅更新部分层(如分类头)或轻量适配器(LoRA) |
| 输出 | 通用基础模型(如BERT、ResNet) | 领域专用模型(如医疗BERT、自动驾驶YOLO) |
场景:构建一个银行业务问答系统。
-
预训练阶段:
- 数据:在1TB的通用文本(维基百科、书籍等)上训练BERT模型。
- 任务:掩码语言建模(MLM),预测被遮蔽的单词(如“请到[遮蔽]办理业务” → “柜台”)。
- 结果:模型学会语法、常识和基础语义,但无法理解专业金融术语。
-
微调阶段:
- 数据:5万条银行客服对话(含“转账”“利率”等专业表述)。
- 任务:序列分类(判断用户意图)和实体识别(提取账号金额)。
- 方法:冻结BERT底层参数,仅训练分类头和实体识别层。
- 结果:模型准确率从预训练后的62%提升至89%,且支持专业术语理解。
-
预训练:
- 案例:Stable Diffusion在LAION-5B图像-文本对上训练,学习通用图文对齐能力。
- 数据:50亿互联网图片及其Alt-Text描述。
- 技术:扩散模型+CLIP联合训练,最小化图文潜在空间距离。
-
微调:
- 案例:DreamBooth个性化生成,使用用户提供的10张宠物照片微调模型。
- 方法:锁定基础UNet,仅优化交叉注意力层中的特定token嵌入。
- 效果:生成“用户的金毛犬在太空漫步”等定制化图像,保留原宠物特征。
-
预训练:
- 案例:ImageNet预训练的ResNet-50,学习通用视觉特征(边缘、纹理等)。
- 数据:140万张标注图像,1000个类别。
-
微调:
- 案例:医学影像诊断(肺炎X光检测)。
- 方法:替换ResNet最后一层为二分类头,在1万张X光片上微调。
- 效果:AUC从随机初始化的0.72提升至0.94,超越放射科医生平均水平。
-
预训练:
- 案例:Waymo在仿真环境中预训练3D目标检测模型。
- 数据:100万帧带标注的LiDAR点云(含雨天、夜间等复杂场景)。
-
微调:
- 案例:适配特定城市道路(如北京五环)。
- 方法:使用本地采集的5万帧数据微调检测头,冻结主干特征提取器。
- 效果:误检率降低40%,适应本地特有的三轮车和护栏样式。
面试回答点睛:
“本质区别是预训练是“通才培养”,微调是“专精训练”。预训练与微调的关系,如同教学生先掌握九年义务教育知识(预训练),再针对高考科目专项突破(微调)。在AIGC中,这表现为Stable Diffusion先学习‘如何画狗’,再微调学会‘如何画用户的金毛犬’。”
迁移学习是一种机器学习方法,其核心思想是将已在一个任务(源任务)上学习到的知识(如特征表示、模型参数等)迁移到另一个相关但不同的任务(目标任务)上,以提升目标任务的性能或减少训练成本。其理论基础基于以下假设:
- 共享特征假设:源任务和目标任务共享某些底层特征(如边缘检测、语义理解等)。
- 任务相关性:源任务的学习结果对目标任务有正向迁移效果。
迁移学习的核心流程:
- 选择预训练模型:在源任务(如ImageNet分类)上训练的基础模型(如ResNet)。
- 知识迁移:
- 特征提取:冻结预训练模型的部分层,将其作为固定特征提取器。
- 微调(Fine-tuning):解冻部分层,在目标任务数据上继续训练。
- 目标任务适配:替换或扩展模型输出层(如将1000类分类头改为10类)。
场景:构建一个花卉种类识别App,但仅有少量标注数据(每类花卉50张图片)。
传统方法问题:
- 若从零训练CNN模型,因数据量不足易过拟合(准确率约60%)。
迁移学习解决方案:
- 源任务预训练:使用在ImageNet(140万张图像,1000类)上预训练的ResNet-50模型,该模型已学习通用视觉特征(如纹理、形状)。
- 知识迁移:
- 特征提取:移除ResNet-50的原始分类头,冻结所有卷积层权重。
- 适配目标任务:添加新的全连接层(输出维度为花卉类别数),仅训练新添加的层。
- 效果:准确率提升至92%,且训练时间从10小时缩短至1小时。
根据源任务与目标任务的差异,迁移学习可分为以下类型:
| 类型 | 特点 | 案例 |
|---|---|---|
| 同领域迁移 | 源任务和目标任务数据分布相似(如不同花卉分类) | ImageNet预训练模型→花卉分类 |
| 跨领域迁移 | 源任务和目标任务数据分布不同但相关(如自然图像→医学影像) | ResNet预训练模型→肺炎X光检测 |
| 跨模态迁移 | 源任务和目标任务模态不同(如文本→图像) | CLIP(图文对齐预训练)→图像生成引导 |
| 多任务学习 | 同时优化多个相关任务,共享部分参数 | 自动驾驶中联合训练目标检测与语义分割 |
- 应用场景:文本到图像生成(如Stable Diffusion)。
- 迁移学习作用:
- 预训练:在LAION-5B(50亿图文对)上训练CLIP模型,学习图文对齐表示。
- 迁移到生成任务:将CLIP的文本编码器作为条件输入,引导扩散模型生成与文本匹配的图像。
- 效果:生成图像与文本描述的匹配度(CLIP Score)提升35%。
- 应用场景:医学影像诊断(如视网膜病变检测)。
- 迁移学习作用:
- 预训练:在ImageNet上训练ResNet-101,学习通用视觉特征。
- 迁移到医疗领域:冻结底层卷积层,微调顶层网络,使用10万张眼底图像训练。
- 效果:相比从零训练,AUC从0.75提升至0.96,数据需求减少90%。
- 应用场景:多传感器融合目标检测。
- 迁移学习作用:
- 预训练:在仿真环境中训练YOLOv7模型,学习通用物体检测能力。
- 迁移到真实场景:使用真实LiDAR和摄像头数据微调检测头,适应光照、天气变化。
- 效果:在nuScenes数据集上,mAP提升22%,误检率降低40%。
面试回答点睛:
“迁移学习如同‘借东风’——ImageNet预训练的ResNet好比学会了‘看世界的基本法则’,而微调阶段则是让它快速掌握‘识别特定花卉的秘诀’。在自动驾驶中,这表现为将游戏仿真中学到的驾驶策略迁移到真实道路,大幅降低实车训练风险。”
我们需要深入剖析**数据集(Dataset)**在机器学习(ML)中的本质含义。这不仅是面试中的核心概念,更是理解机器学习如何工作的基石。
数据集的本质:机器学习模型的“经验来源”与“世界映射”
简单来说,数据集在机器学习中的本质是:
用于训练、验证和测试机器学习模型的、经过(或未经过)预处理的样本集合,它承载了模型需要学习的“知识”、“规律”或“模式”的载体,是对现实世界某个特定方面或问题域的有限、有偏但结构化的映射。
让我们逐层拆解这个本质:
-
知识的载体(The Carrier of Knowledge):
- 核心: 机器学习模型本身是“无知”的(初始化参数通常是随机的)。它获得“智能”的唯一途径就是从数据中学习。
- 如何承载? 数据集中的每一个样本(例如:一张图片及其标签“猫”,一条用户行为记录,一段语音信号,一个传感器读数序列)都包含了关于任务目标的信息片段。标签(监督学习)或数据本身的结构(无监督/自监督学习)则提供了学习的方向或约束。
- 本质体现: 模型通过算法(如梯度下降)不断调整自身参数,使得其在数据集上的预测或表示能力达到最优(或次优)。这个过程就是模型“消化”数据、吸收其中蕴含的知识和规律的过程。数据集的质量、数量和代表性直接决定了模型能学到什么以及学得多好。
-
现实世界的有限映射(A Finite Mapping of Reality):
- 核心: 数据集永远无法包含现实世界的全部情况。它只是对某个特定问题域(Problem Domain) 在特定时间、特定条件下的一个采样(Sampling)。
- 有限性: 数据量是有限的,无法涵盖所有可能的输入组合或极端情况(长尾问题)。
- 有偏性: 数据的收集过程、来源、标注规则都可能引入偏差(Bias)。例如,人脸识别数据集如果主要包含特定肤色的人,模型对其他肤色的人识别效果可能就会差。
- 结构化表示: 数据需要以机器可处理的形式组织(如数值、向量、矩阵、张量、图结构)。常见的结构包括:
- 表格数据: 行代表样本,列代表特征。
- 图像数据: 像素矩阵(2D/3D)。
- 文本数据: 词序列、词嵌入矩阵。
- 时序数据: 按时间顺序排列的观测值序列。
- 图数据: 节点和边的集合。
- 本质体现: 模型学习到的是数据集所映射的那个“小世界”的规律,而非绝对真理。模型的泛化能力,就是其将在这个“小世界”学到的规律,应用到更广阔但相关的现实世界的能力。数据集就是这个“小世界”的蓝图。
-
模型行为的定义者(The Definer of Model Behavior):
- 核心: “垃圾进,垃圾出”(Garbage In, Garbage Out)。模型最终的表现(预测什么、如何预测、预测的倾向性)从根本上由它被训练的数据集决定。
- 学习目标: 在监督学习中,数据集通过标签明确定义了模型需要预测什么(分类、回归)。在无监督学习中,数据集的结构定义了模型需要发现什么模式(聚类、降维、关联)。
- 偏好与偏见: 如果数据集中某种模式或群体占主导,模型就会倾向于预测该模式或服务该群体,可能对其他模式或群体表现不佳甚至产生歧视性结果。数据集中的错误(噪声、错误标签)也会被模型学习。
- 本质体现: 选择或构建什么样的数据集,直接决定了训练出的模型具有什么样的能力和“性格”。解决模型偏见、公平性问题,源头在于数据集。
-
模型性能的评估基准(The Benchmark for Performance):
- 核心: 我们如何知道模型学得好不好?通过它在(未见过的)数据集上的表现来衡量!
- 划分: 数据集通常被划分为:
- 训练集(Training Set): 用于直接调整模型参数,是模型学习的“教材”。
- 验证集(Validation Set): 用于在训练过程中监控模型性能、选择超参数(如学习率、网络层数)、进行模型选择(选择哪个模型架构更好)以及决定何时停止训练(早停),是学习的“模拟考”。
- 测试集(Test Set): 用于在模型训练和调优完全结束后,独立、公正地评估模型的最终泛化性能,是学习的“最终大考”。测试集必须严格隔离,不能用于任何训练或调优决策。
- 本质体现: 数据集的不同部分扮演着不同的角色,共同构成了评估模型从学习能力到最终应用潜力的完整体系。模型的好坏,最终由其在测试集上的表现说了算,而测试集本身也是数据集的一部分。
-
构建数据集:
- 你(老师)想教一个AI小朋友(模型)认识苹果、香蕉和橙子。
- 你收集了很多水果的图片(样本)。每张图片标注了正确的水果名称(标签:苹果、香蕉、橙子)。这就是你的带标签数据集。
- 你收集了1000张图片(有限性):可能主要是常见的红苹果、黄香蕉、橙子(有偏性:缺少青苹果、绿香蕉、血橙等)。图片都被整理成统一的像素大小(结构化表示)。
-
数据集作为知识载体:
- AI小朋友一开始什么水果都不认识(随机初始化)。
- 你训练它:给它看一张苹果图片(样本),告诉它“这是苹果”(标签)。它内部调整参数,试图记住“苹果看起来是这样”。
- 它再看到一张香蕉图片,调整参数区分苹果和香蕉… 如此反复。它从这1000张标注图片中学习“苹果”、“香蕉”、“橙子”的视觉特征(知识载体)。
-
数据集作为世界映射:
- 这1000张图片代表了AI小朋友认识的“水果世界”。它学到的规律是基于这些图片的。
- 如果数据集里苹果都是红的,它可能认为绿色的苹果(青苹果)不是苹果(映射偏差导致泛化错误)。
-
数据集定义模型行为:
- 因为数据集只教了苹果、香蕉、橙子,所以AI小朋友只会认这三种水果(学习目标由数据集定义)。
- 如果数据集中香蕉图片特别多(占70%),它可能看到一个黄色弯弯的东西,即使不太像香蕉,也倾向于猜“香蕉”(数据偏差导致预测偏好)。
-
数据集作为评估基准:
- 训练: 你用其中800张图片(训练集)反复教AI小朋友。
- 验证: 训练过程中,你偶尔拿出100张图片(验证集)考它:“这是什么?” 根据它答对的多少(准确率),你调整教学方法(超参数),或者换一种教法(模型选择),或者决定是否继续教(早停)。
- 测试: 最后,你把完全没用来教也没用来考过的最后100张新图片(测试集)拿出来做最终考试。它在这100张上的准确率,才是它真实水平的反映。如果测试集里有很多青苹果、绿香蕉,而它之前没见过,考砸了,就说明它在“小世界”(训练/验证集)学得不错,但泛化到更广世界(测试集)失败了。
-
AIGC (生成式人工智能):
- 本质体现: 数据集是创作灵感库与风格教科书。
- 应用与数据特点:
- 训练数据: 海量(数十亿级别)图文对(如
[图片:星空下的梵高风格村庄, 文本:”A village under a starry night sky in the style of Van Gogh“)、无标签图像/视频/音频、特定风格作品集。 - 作用:
- 学习世界关联: 图文对数据集(如LAION)让模型学习视觉概念(“星空”、“村庄”、“梵高风格”)与语言描述之间的复杂映射关系。这是生成符合文本描述图像的基础。
- 学习数据分布: 海量无标签图像/视频让模型(如GAN、Diffusion Model)学习真实世界视觉元素(物体、纹理、光影)的分布规律。模型学习“一张逼真照片应该长什么样”。
- 学习特定风格: 专门收集的莫奈画作数据集,能让模型精调,学会生成“莫奈风格”的图像。
- 挑战: 数据规模巨大、质量参差不齐、版权/伦理问题突出、数据偏差(如过度代表某些文化/风格)会导致生成结果出现偏见或不准确。
- 训练数据: 海量(数十亿级别)图文对(如
-
传统深度学习 (如CV、NLP分类、检测等):
- 本质体现: 数据集是任务定义书与性能标尺。
- 应用与数据特点:
- 训练/验证/测试数据: 规模相对适中(数万到数百万),高质量、精准标注是关键。例如:
- ImageNet: 数百万图片 + 1000类精确标签 -> 训练图像分类模型。
- COCO: 数十万图片 + 目标框/分割掩码/类别标签 -> 训练目标检测、实例分割模型。
- GLUE/SQuAD: 大量文本句子/段落 + 情感标签/问题答案 -> 训练文本分类、问答模型。
- 作用:
- 明确定义任务: COCO数据集的存在,定义了“目标检测”任务的标准(检测80类常见物体,输出框和类别)。模型的学习目标由数据集结构清晰界定。
- 提供学习样本: 每个标注样本(如图片+框+类别)直接告诉模型“在什么位置有什么物体”。
- 标准化评估: 这些权威数据集提供了标准化的测试集,使得不同模型可以在完全相同的基准下进行比较(如ImageNet Top-5准确率,COCO mAP),推动领域进步。
- 挑战: 标注成本高昂、类别不平衡、标注错误(噪声)、覆盖度不足(新类别/场景难处理)。
- 训练/验证/测试数据: 规模相对适中(数万到数百万),高质量、精准标注是关键。例如:
-
自动驾驶:
- 本质体现: 数据集是虚拟驾校与安全考卷。
- 应用与数据特点:
- 训练/验证/测试数据: 极其多模态、大规模、长尾、高精度标注。
- 来源: 真实路测车辆(摄像头、激光雷达、毫米波雷达、GPS/IMU数据)+ 高精地图 + 极端场景采集 + 海量仿真合成数据。
- 标注: 3D目标框(车辆、行人、骑车人)、像素级语义分割(道路、车道线、可行驶区域)、轨迹预测、关键点(行人姿态)、事件标签(急刹、接管)等。标注精度要求极高(厘米级)。
- 规模: 动辄数百万公里驾驶数据,PB级存储。长尾数据(Corner Cases) 收集是重中之重(如罕见车型、特殊天气、突发事故)。
- 作用:
- 学习感知世界: 多传感器数据融合数据集训练感知模型识别和跟踪周围一切动态/静态物体,理解道路结构(感知)。
- 学习决策规则(间接): 通过记录人类驾驶员在复杂场景下的操作(方向盘、油门、刹车)与对应的环境数据(状态),训练预测或端到端模型(行为克隆、强化学习)。
- 覆盖极端情况: 专门收集的“Corner Cases”数据集(如突然横穿马路的行人、故障车辆)是训练模型应对高风险、低概率事件的关键,直接关系到安全性。仿真数据可无限生成此类场景。
- 严苛评估: 测试集包含大量精心设计的复杂场景和极端案例,是模型上路前的终极安全考核。评估指标极其严格(漏检率、误检率、定位精度)。
- 挑战: 数据采集成本极高、传感器同步/标定复杂、标注成本/难度巨大(3D点云标注)、数据安全/隐私、仿真数据与真实数据的差距(Sim2Real)、长尾问题极端突出。
- 训练/验证/测试数据: 极其多模态、大规模、长尾、高精度标注。
数据集在机器学习中的本质远超“一堆数据”。它是:
- 知识的唯一源泉: 模型从中汲取智能。
- 世界的有限镜像: 模型学习的是这个镜像中的规律,并期望能映射到真实世界(泛化)。
- 模型行为的模具: 模型做什么、怎么做、偏好什么,皆由数据塑造。
- 性能衡量的基石: 训练、验证、测试集共同定义了学习过程和最终成绩。
理解数据集的本质,意味着理解:
- 为什么数据质量(准确、一致、相关、无偏)比算法技巧更重要? 因为模型只能反映数据。
- 为什么数据量通常越大越好(尤其深度学习)? 因为更大的样本能更好地逼近真实世界的复杂分布。
- 为什么数据预处理和特征工程如此关键? 因为这是让数据更有效承载知识、更清晰映射世界的必要步骤。
- 为什么会有过拟合? 因为模型过度学习了训练数据(那个“小世界”)的噪声和特定模式,失去了对更广阔世界(测试集)的泛化能力。
- 为什么领域特定数据(如自动驾驶的Corner Cases, AIGC的特定风格)如此宝贵? 因为它们直接定义了模型在特定场景下的核心能力边界。
在AI算法岗面试中,清晰地阐述数据集的本质及其在不同领域的应用特点,不仅能展现扎实的基础,更能体现对机器学习全流程的深刻理解。