- 1.卷积在CNN中的核心作用是什么
- 2.卷积操作的数学定义是什么
- 3.CNN中的卷积与传统信号处理中的卷积有何区别
- 4.卷积操作如何实现局部连接特性
- 5.权值共享在卷积操作中是如何体现的
- 6.局部连接和权值共享对CNN的性能有什么影响
- 7.卷积操作的输入和输出维度分别由哪些因素决定
- 8.写出卷积操作输出特征图尺寸的计算公式
- 9.什么是步幅(Stride),步幅增大对输出特征图有什么影响
- 10.什么是填充(Padding),填充的主要目的是什么
- 11.常见的Padding模式有哪些,它们的区别是什么
- 12.当输入尺寸为H×W×C,卷积核为K×K×C,步幅为S,Padding为P时,输出特征图尺寸是多少
- 13.卷积操作中为什么通常使用奇数尺寸的卷积核
- 14.3×3卷积核相比1×1、5×5卷积核有什么优势
- 15.卷积操作是如何提取图像特征的
- 16.卷积层的感受野是什么意思
- 21.如何计算卷积层中某个神经元的感受野大小
- 22.感受野的大小对CNN特征提取有什么影响
- 23.什么是互相关(Cross-Correlation),它与卷积的关系是什么
- 24.CNN训练中实际使用的是卷积还是互相关,为什么
- 25.多通道输入时,卷积操作是如何进行的
- 26.多通道输出的卷积层,其卷积核是如何设置的
- 27.卷积操作的计算复杂度与哪些因素有关
- 28.如何降低卷积操作的计算复杂度
- 29.卷积层的偏置项(Bias)是如何作用的
- 30.卷积操作对图像的平移不变性有什么贡献
- 31.什么是卷积的稀疏交互特性
- 32.稀疏交互对CNN的泛化能力有什么影响
- 33.卷积操作在反向传播时,梯度是如何计算的
- 34.卷积核的梯度计算与全连接层权重梯度计算有何不同
- 35.当输入存在噪声时,卷积操作能起到什么作用
- 36.卷积层可以学习到哪些类型的特征
- 37.浅层卷积层和深层卷积层学习到的特征有什么区别
- 38.为什么卷积层适合处理网格结构的数据(如图像)
- 39.卷积操作是否会改变输入数据的通道数
- 40.如果输入通道数为3,输出通道数为64,需要多少个卷积核
- 41.每个输出通道对应的卷积核与输入通道的关系是什么
- 42.什么是卷积的滑动窗口,它的大小由什么决定
- 43.滑动窗口的步幅为2时,窗口如何在输入上移动
- 44.当输入尺寸不能被步幅整除时,卷积操作会如何处理
- 45.卷积操作的线性特性体现在哪里
- 46.结合激活函数后,卷积层是否还具有线性特性
- 47.如何理解卷积操作的参数共享降低了模型过拟合风险
- 48.卷积层的输出特征图数量与模型的表达能力有什么关系
- 49.过多的输出特征图会带来什么问题
- 50.卷积操作在处理高分辨率图像时会面临什么挑战
- 1.卷积核的基本组成部分有哪些
- 2.卷积核的深度(Depth)与输入输出通道数的关系是什么
- 3.卷积核的大小选择需要考虑哪些因素
- 4.为什么CNN中很少使用大于7×7的卷积核
- 5.1×1卷积核的主要作用是什么
- 6.使用1×1卷积核如何实现通道数的调整
- 7.卷积核的数量是如何确定的
- 8.卷积核数量对模型性能和计算量的影响是什么
- 9.卷积层的参数数量如何计算
- 10.当输入通道数为C_in,输出通道数为C_out,卷积核大小为K×K时,参数数量是多少
- 11.偏置项是否计入卷积层的参数数量,如何计算
- 12.不同 Padding 模式对卷积层参数数量有影响吗
- 13.步幅大小对卷积层参数数量有影响吗
- 14.卷积核的初始化方法有哪些
- 15.为什么卷积核初始化不能全部设为0或相同的值
- 16.He初始化和Xavier初始化在卷积核初始化中有什么区别
- 17.预训练的卷积核有什么优势
- 18.卷积核学习过程中,其数值变化反映了什么
- 19.什么是卷积核的稀疏性
- 20.卷积核稀疏性对模型有什么意义
- 21.如何设计卷积核实现边缘检测
- 22.常见的边缘检测卷积核有哪些(如Sobel、Prewitt)
- 23.人工设计的卷积核与CNN学习到的卷积核有何区别
- 24.多尺度卷积核的设计思路是什么
- 25.使用多尺度卷积核有什么优势
- 26.什么是分组卷积(Group Convolution),其卷积核如何设计
- 27.分组卷积中,卷积核的数量与分组数的关系是什么
- 28.深度卷积(Depthwise Convolution)的卷积核设计特点是什么
- 29.深度卷积的参数数量与普通卷积有何差异
- 30.卷积核的正则化方法有哪些
- 31.L1正则化对卷积核有什么影响
- 32.L2正则化如何防止卷积核过拟合
- 33.什么是卷积核的剪枝(Pruning)
- 34.卷积核剪枝的依据是什么
- 35.卷积核量化(Quantization)是什么意思
- 36.卷积核量化对模型性能和部署有什么影响
- 37.如何设计卷积核以减少计算量
- 38.小卷积核堆叠与大卷积核在参数和性能上有什么区别
- 39.两个3×3卷积核堆叠的感受野与一个5×5卷积核的感受野相同吗
- 40.为什么两个3×3卷积核堆叠比一个5×5卷积核更优
- 41.卷积核的对称性对特征提取有什么影响
- 42.是否可以使用非正方形的卷积核(如3×5),适用场景是什么
- 43.卷积核的数值范围通常在什么区间,为什么
- 44.卷积核学习过程中出现梯度消失会导致什么问题
- 45.如何解决卷积核训练中的梯度爆炸问题
- 46.迁移学习中,预训练卷积核是否需要微调
- 47.不同任务(分类、检测、分割)中,卷积核的设计有什么差异
- 48.轻量级网络(如MobileNet)在卷积核设计上有什么特点
- 49.大模型(如ViT-CNN混合模型)中卷积核的作用发生了什么变化
- 50.未来卷积核设计的发展趋势是什么
- 1.普通卷积(Standard Convolution)的定义和计算过程是什么
- 2.普通卷积的优缺点分别是什么
- 3.什么是深度可分离卷积(Depthwise Separable Convolution)
- 4.深度可分离卷积分为哪两个步骤
- 5.深度卷积(Depthwise Convolution)的操作过程是怎样的
- 6.逐点卷积(Pointwise Convolution)的操作过程是怎样的
- 7.深度可分离卷积与普通卷积的参数数量比是多少
- 8.深度可分离卷积如何减少计算量
- 9.深度可分离卷积的优点和缺点分别是什么
- 10.深度可分离卷积在哪些网络中得到了应用
- 11.什么是分组卷积(Group Convolution)
- 12.分组卷积的输入通道和输出通道是如何分组的
- 13.分组卷积的参数数量如何计算
- 14.分组卷积与普通卷积的计算复杂度对比如何
- 15.分组卷积的“分组”会带来什么问题,如何解决
- 16.分组卷积在ResNeXt网络中的作用是什么
- 17.什么是转置卷积(Transposed Convolution)
- 18.转置卷积与普通卷积的关系是什么
- 19.转置卷积如何实现特征图的上采样
- 20.转置卷积的输出尺寸如何计算
- 21.转置卷积存在什么问题,如何改进
- 22.转置卷积在语义分割网络中的作用是什么
- 23.什么是空洞卷积(Dilated Convolution)
- 24.空洞卷积的 dilation rate 是什么意思
- 25.空洞卷积如何扩大感受野而不增加参数
- 26.空洞卷积的输出尺寸计算公式是什么
- 27.空洞卷积的“网格效应”是什么,如何避免
- 28.空洞卷积在哪些场景中适用
- 29.什么是1×1卷积,它的主要用途有哪些
- 30.1×1卷积为什么能减少计算量
- 31.什么是空间可分离卷积(Spatially Separable Convolution)
- 32.空间可分离卷积如何将2D卷积拆分为两个1D卷积
- 33.空间可分离卷积的参数减少比例是多少
- 34.空间可分离卷积的局限性是什么
- 35.什么是变形卷积(Deformable Convolution)
- 36.变形卷积与普通卷积的区别是什么
- 37.变形卷积的偏移量(Offset)是如何学习的
- 38.变形卷积在目标检测中的优势是什么
- 39.什么是分组深度可分离卷积(Grouped Depthwise Separable Convolution)
- 40.不同类型的卷积在参数效率上的排序是怎样的
- 41.在移动端部署中,优先选择哪种类型的卷积,为什么
- 42.如何根据任务需求选择合适的卷积类型
- 43.普通卷积、深度可分离卷积、分组卷积的特征提取能力对比如何
- 44.转置卷积与插值上采样(如双线性插值)有什么区别
- 45.空洞卷积与多尺度池化在扩大感受野上的差异是什么
- 46.变形卷积是否会增加模型的计算复杂度
- 47.不同卷积类型的组合使用有什么效果(如深度可分离+空洞卷积)
- 48.轻量级网络中常用的卷积组合策略有哪些
- 49.未来卷积类型的创新方向可能是什么
- 50.在大模型时代,卷积层是否会被完全取代,为什么
- 1.卷积有什么特点
- 2.不同层次的卷积都提取什么类型的特征
- 3.卷积核大小如何选取
- 4.卷积感受野的相关概念
- 5.网络每一层是否只能用一种尺寸的卷积核
- 6.1*1卷积的作用
- 7.转置卷积的作用
- 8.空洞卷积的作用
- 9.什么是转置卷积的棋盘效应
- 10.什么是有效感受野
- 11.分组卷积的相关知识
- 12.什么是可变形卷积?
- 13.什么是3D卷积?
- 14.分析一下卷积层的时间复杂度和空间复杂度
- 15.AIGC时代一共有多少种主流卷积类型?
- 16.卷积神经网络的本质是什么?
- 1.池化操作的核心目的是什么
- 2.池化操作如何实现特征降维
- 3.池化层在深度学习模型中主要解决什么问题
- 4.池化操作为什么能提高模型的平移不变性
- 5.池化原理中窗口滑动的基本规则是什么
- 6.池化操作对特征图的空间分辨率有什么影响
- 7.池化层是否会改变特征图的通道数
- 8.池化操作在反向传播过程中是如何计算梯度的
- 9.池化操作为什么能减少模型的计算量和参数量
- 10.池化层与卷积层的配合逻辑是什么
- 11.池化操作对输入特征图的局部信息有什么处理方式
- 12.什么是池化窗口,它的大小通常如何选择
- 13.池化操作的步长设置与窗口大小有什么关系
- 14.池化层能否缓解过拟合,为什么
- 15.池化操作对噪声的鲁棒性体现在哪里
- 16.池化原理中“局部不变性”具体指什么
- 17.池化操作是否需要训练参数
- 18.池化层在整个神经网络架构中的位置通常在哪里
- 19.池化操作如何保留输入特征图的关键信息
- 20.不同池化方式在原理上的共性是什么
- 21.池化操作对特征图的幅值有什么影响
- 22.为什么池化操作通常在卷积层之后使用
- 23.池化原理中是否存在重叠区域,重叠的意义是什么
- 24.池化操作如何帮助模型学习更抽象的特征
- 25.池化层的计算复杂度与哪些因素相关
- 26.池化操作对输入数据的维度有什么要求
- 27.池化原理与下采样有什么区别和联系
- 28.池化操作在图像分类任务中的具体作用是什么
- 29.池化层能否处理非图像类型的数据,为什么
- 30.池化操作的输出特征图大小如何计算
- 31.池化原理中为什么不需要像卷积层那样使用滤波器
- 32.池化操作对模型的收敛速度有什么影响
- 33.池化层在目标检测任务中起到什么作用
- 34.池化操作如何应对输入特征图的微小形变
- 35.池化原理中的“聚合操作”具体指什么
- 36.池化层是否会丢失一些细节信息,如何权衡
- 37.池化操作在不同通道上是独立进行的吗
- 38.池化原理与特征选择有什么关系
- 39.池化操作对模型的泛化能力有什么提升
- 40.池化层的输出与输入之间的映射关系是什么
- 41.池化操作为什么能减少过拟合的风险
- 42.池化原理中窗口的移动方向是怎样的
- 43.池化层在深度学习模型中的必要性体现在哪里
- 44.池化操作对输入特征图的对比度有什么影响
- 45.池化原理与人类视觉系统的哪些特性相似
- 46.池化操作在视频处理任务中如何应用
- 47.池化层的设计是否会影响模型的准确率
- 48.池化操作如何处理输入特征图的边界问题
- 49.池化原理中不同聚合函数的选择依据是什么
- 50.池化操作在语音识别任务中起到什么作用
- 1.最大池化的定义和计算方式是什么
- 2.平均池化与最大池化在计算上的主要区别是什么
- 3.最大池化为什么能更好地保留边缘和纹理特征
- 4.平均池化的优势体现在哪些方面
- 5.什么是全局最大池化,它与普通最大池化的区别是什么
- 6.全局平均池化的作用是什么,在模型中通常如何使用
- 7.中值池化的计算方式是什么,它的适用场景有哪些
- 8.随机池化的原理是什么,它相比最大池化有什么特点
- 9.最大池化在反向传播时梯度是如何分配的
- 10.平均池化的反向传播梯度计算规则是什么
- 11.在图像分类任务中,全局平均池化为什么常用来替代全连接层
- 12.最大池化容易丢失哪些类型的信息
- 13.平均池化在什么情况下会导致特征模糊
- 14.什么是重叠池化,它的主要目的是什么
- 15.重叠最大池化与非重叠最大池化的性能对比如何
- 16.L2池化的定义是什么,它的应用场景有哪些
- 17.混合池化的概念是什么,它结合了哪些池化类型的优点
- 18.最大池化的窗口大小对其性能有什么影响
- 19.平均池化在处理高对比度图像时表现如何
- 20.全局最大池化的输出维度是怎样的
- 21.中值池化为什么对椒盐噪声有较好的鲁棒性
- 22.随机池化如何提高模型的泛化能力
- 23.不同池化类型在计算复杂度上的差异是什么
- 24.在目标检测任务中,更适合使用哪种池化类型,为什么
- 25.最大池化是否会加剧模型的稀疏性
- 26.平均池化对模型的收敛速度有什么影响
- 27.什么是自适应池化,它的优势是什么
- 28.自适应最大池化与普通最大池化的区别是什么
- 29.池化类型的选择与数据集的特点有什么关系
- 30.最大池化在深层网络中可能会遇到什么问题
- 31.平均池化在小目标检测任务中的表现如何
- 32.全局平均池化是否会丢失过多的空间信息
- 33.中值池化的计算速度与最大池化相比如何
- 34.随机池化的随机性对模型训练的稳定性有什么影响
- 35.在语义分割任务中,常用的池化类型是什么
- 36.最大池化和平均池化在特征提取的侧重点上有什么不同
- 37.什么是金字塔池化,它的主要作用是什么
- 38.池化类型的选择对模型的过拟合风险有什么影响
- 39.平均池化在处理多通道特征图时是如何操作的
- 40.最大池化的步长设置对特征图的影响是什么
- 41.对比池化的定义是什么,它通常用于什么场景
- 42.不同池化类型在保留特征图全局信息方面的能力排序如何
- 43.最大池化为什么在CNN模型中应用最为广泛
- 44.平均池化在模型微调时的表现如何
- 45.什么是可分离池化,它的设计思路是什么
- 46.池化类型的替换对模型性能的影响通常需要通过什么方式验证
- 47.最大池化在处理旋转图像时的鲁棒性如何
- 48.平均池化与L2池化的区别是什么
- 49.在生成对抗网络中,常用的池化类型是什么
- 50.不同池化类型的组合使用有什么技巧
- 1. 全连接层的定义是什么?
- 2. 全连接层中神经元的连接方式有何特点?
- 3. 全连接层的输入和输出通常是什么形态的数据?
- 4. 全连接层中每个神经元的计算过程包括哪两步?
- 5. 全连接层在深度学习网络中通常位于什么位置?
- 6. 全连接层的核心作用是什么?
- 7. 全连接层如何实现特征的整合?
- 8. 全连接层与局部连接层的本质区别是什么?
- 9. 全连接层的神经元数量是如何确定的?
- 10. 全连接层是否可以接收多维特征图作为输入?如果可以需要做什么处理?
- 11. 全连接层的输出维度由什么决定?
- 12. 单个全连接层能否实现非线性变换?为什么?
- 13. 全连接层在分类任务中的作用是什么?
- 14. 全连接层在回归任务中的作用与分类任务有何不同?
- 15. 全连接层的结构示意图通常包含哪些元素?
- 16. 为什么全连接层又被称为稠密连接层(Dense Layer)?
- 21. 全连接层中不同神经元之间是否存在连接?
- 22. 全连接层的输入特征维度变化会影响层内结构吗?
- 23. 全连接层能否作为深度学习网络的输入层?
- 24. 全连接层与输出层的关系是什么?输出层一定是全连接层吗?
- 25. 全连接层中每个输入特征对所有输出神经元的影响是怎样的?
- 26. 全连接层的结构如何体现“全连接”这一特性?
- 27. 多层全连接层叠加的作用是什么?
- 28. 全连接层在特征提取和特征映射中扮演什么角色?
- 29. 全连接层处理图像数据时,为什么需要先将特征图展平?
- 30. 展平操作对全连接层的输入有什么影响?
- 31. 全连接层的神经元激活函数通常选择什么?为什么?
- 32. 全连接层的 bias 项有什么作用?可以省略吗?
- 33. 全连接层的结构是否会影响网络的训练难度?
- 34. 全连接层与嵌入层(Embedding Layer)的区别是什么?
- 35. 全连接层能否学习到全局特征?为什么?
- 36. 全连接层在循环神经网络(RNN)中是否有应用?如何应用?
- 37. 全连接层在Transformer模型中的作用是什么?
- 38. 全连接层的输入是否必须是一维向量?
- 39. 全连接层中权重矩阵的维度与输入输出维度的关系是什么?
- 40. 全连接层的结构对网络的泛化能力有何影响?
- 41. 全连接层如何将前层提取的局部特征转化为全局特征?
- 42. 全连接层的神经元数量过多或过少会有什么问题?
- 43. 全连接层是否支持并行计算?为什么?
- 44. 全连接层与卷积层的结构差异如何导致功能差异?
- 45. 全连接层在生成对抗网络(GAN)中的作用是什么?
- 46. 全连接层的输入特征数发生变化时,需要修改层的哪些参数?
- 47. 全连接层的“全连接”特性在实际硬件实现中有什么挑战?
- 48. 全连接层能否用于特征降维?如何实现?
- 49. 全连接层与自编码器(Autoencoder)中的编码层、解码层有什么关系?
- 50. 全连接层的结构设计需要遵循哪些基本原则?
- 1. 全连接层的参数主要包括哪两部分?
- 2. 若全连接层输入维度为n,输出维度为m,权重矩阵的维度是多少?
- 3. 全连接层的偏置项(bias)数量与什么有关?
- 4. 计算全连接层总参数数量的公式是什么?
- 5. 若输入特征数为100,输出神经元数为50,该全连接层的权重参数有多少个?
- 6. 接上题,该全连接层的偏置参数有多少个?总参数呢?
- 7. 当全连接层输入为多维特征图(如H×W×C)时,计算参数前需要做什么处理?处理后的输入维度如何计算?
- 8. 若输入为3×3×64的特征图,展平后的输入维度是多少?
- 9. 接上题,若输出神经元数为128,该全连接层总参数是多少?
- 10. 全连接层的参数数量与batch size有关吗?为什么?
- 11. 多层全连接层的总参数如何计算?
- 12. 若网络有两层全连接层,第一层输入100、输出50,第二层输入50、输出10,总参数是多少?
- 13. 全连接层的权重矩阵初始化方式对参数计算有影响吗?
- 14. 为什么全连接层的参数数量通常比卷积层多?
- 15. 全连接层中每个输出神经元对应的权重向量维度是多少?
- 16. 全连接层的参数存储开销与什么因素成正比?
- 17. 若全连接层输入维度为2048,输出维度为1000,总参数数量是多少?
- 18. 全连接层的偏置项是否需要单独计算数量?它的维度是什么?
- 19. 当全连接层的输入是批量数据(如batch×n)时,权重矩阵的维度是否会变化?
- 20. 全连接层的参数计算中,如何处理输入特征的通道数?
- 21. 若输入为1×1×1024的特征图,输出神经元数为512,该全连接层参数数量是多少?
- 22. 全连接层的参数数量是否会影响网络的训练速度?为什么?
- 23. 全连接层中权重矩阵的转置在计算时起什么作用?
- 24. 如何通过参数共享减少全连接层的参数数量?
- 25. 全连接层的参数数量与输入特征的空间维度(如图像的高和宽)有什么关系?
- 26. 若输入图像大小为28×28×1,展平后输入全连接层,输出神经元数为64,该层总参数是多少?
- 27. 全连接层的参数更新方式是否与参数数量有关?
- 28. 全连接层的权重矩阵中每个元素代表什么含义?
- 29. 全连接层的偏置项对每个输出神经元的影响是怎样的?
- 30. 计算全连接层参数时,是否需要考虑激活函数?为什么?
- 31. 若全连接层输入维度为512,输出维度为256,权重参数和偏置参数的存储大小(假设每个参数为4字节浮点数)分别是多少?
- 32. 全连接层的参数数量与网络的复杂度有什么关系?
- 33. 当全连接层作为输出层时,参数计算方式是否有变化?
- 34. 若输出层为全连接层,分类任务中输出维度与什么有关?此时参数如何计算?
- 35. 回归任务中全连接输出层的参数计算与分类任务有何不同?
- 36. 全连接层的参数数量是否会影响网络的过拟合风险?
- 37. 若全连接层输入为batch×3×224×224,展平后的输入维度是多少?
- 91. 接上题,若输出神经元数为100,该全连接层总参数是多少?
- 39. 全连接层的参数计算中,“输入维度”具体指的是什么?
- 40. 全连接层的参数数量与层的深度有什么关系?
- 41. 为什么全连接层在处理高分辨率图像时参数数量会急剧增加?
- 42. 若全连接层输入维度为1024,输出维度为1024,总参数数量是多少?
- 43. 全连接层的参数初始化值的范围是否会影响参数的后续计算?
- 44. 全连接层的参数数量与输入数据的类型(图像、文本、语音)有关吗?
- 45. 如何估算一个包含多个全连接层的网络的总参数数量?
- 46. 全连接层的参数数量过多会带来什么硬件挑战?
- 47. 若全连接层输入为二维张量(batch×seq_len×hidden_dim),展平后输入维度如何计算?
- 48. 接上题,若输出神经元数为50,该层总参数是多少?
- 49. 全连接层的参数计算中,是否需要区分训练阶段和推理阶段?
- 50. 总结全连接层参数计算的关键步骤是什么?
- 1. 全连接层的主要优点是什么?
- 2. 全连接层在特征整合方面有什么优势?
- 3. 全连接层的实现难度如何?为什么?
- 4. 全连接层对非线性关系的拟合能力如何?
- 5. 全连接层在分类任务中的优势体现在哪里?
- 6. 全连接层的结构灵活性体现在什么方面?
- 7. 为什么全连接层适合作为网络的输出层?
- 8. 全连接层在小数据集上的表现如何?
- 9. 全连接层的计算逻辑是否容易理解和调试?
- 10. 全连接层与其他层(如卷积层)结合时,能发挥什么优势?
- 11. 全连接层的主要缺点是什么?
- 12. 全连接层参数数量过多会导致什么问题?
- 13. 全连接层为什么容易发生过拟合?
- 14. 全连接层在处理高维输入时存在什么局限性?
- 15. 全连接层的计算效率如何?为什么?
- 16. 全连接层对输入数据的空间结构信息利用程度如何?
- 17. 全连接层在处理大尺寸图像时会面临什么问题?
- 18. 全连接层的存储开销主要来自哪里?
- 19. 为什么全连接层在深度学习网络中的占比逐渐降低?
- 20. 全连接层对噪声的鲁棒性如何?
- 21. 如何缓解全连接层参数过多的问题?
- 22. Dropout技术如何改善全连接层的过拟合问题?
- 23. 正则化(L1、L2)对全连接层的作用是什么?
- 24. 能否用其他层替代全连接层的功能?举例说明。
- 25. 全连接层与全局平均池化层(GAP)相比,各有什么优缺点?
- 26. 全连接层在移动端部署时面临什么挑战?
- 27. 如何在保持全连接层性能的同时减少其计算量?
- 28. 全连接层的“全连接”特性在哪些场景下会成为劣势?
- 29. 全连接层与稀疏连接层相比,计算复杂度有何差异?
- 30. 全连接层在处理序列数据时的局限性是什么?
- 31. 全连接层的优点是否适用于所有深度学习任务?
- 32. 全连接层在生成任务(如图片生成)中的缺点是什么?
- 33. 为什么全连接层不适合作为特征提取层的主要组成部分?
- 34. 全连接层的参数更新速度与参数数量有什么关系?
- 35. 全连接层在多任务学习中的优缺点是什么?
- 36. 如何评估全连接层在网络中的必要性?
- 37. 全连接层与注意力机制结合能否改善其缺点?如何改善?
- 38. 全连接层的存储开销对模型部署有什么影响?
- 39. 全连接层在处理高通道数特征图时的问题是什么?
- 40. 全连接层的过拟合问题除了Dropout和正则化,还有哪些解决方法?
- 41. 全连接层的计算并行性优势是否能抵消其参数过多的劣势?
- 42. 全连接层在小模型(如边缘设备模型)中的应用受限原因是什么?
- 43. 全连接层与卷积层的鲁棒性对比如何?
- 44. 全连接层的优点在Transformer模型中是如何体现的?
- 45. 全连接层的缺点在RNN模型中是否同样存在?
- 46. 如何根据任务需求决定是否使用全连接层?
- 47. 全连接层的参数压缩技术有哪些?原理是什么?
- 48. 全连接层在迁移学习中的优缺点是什么?
- 49. 全连接层未来的发展方向是什么?如何进一步优化其缺点?
- 1.全连接层的作用是什么?
- 2.介绍一下MLP网络
- 3.简述全连接层的定义与结构
- 4.全连接层的工作原理是什么,涉及哪些数学运算?
- 5.在图像识别任务中,全连接层通常在卷积神经网络(CNN)的什么位置,起到什么作用?
- 6.全连接层的参数数量如何计算?以输入层有512个神经元,隐藏层(全连接层)有256个神经元为例说明。
- 7.如何缓解全连接层带来的过拟合问题?
- 8.全连接层与卷积层在连接方式上有何区别?这种区别对它们的功能和应用场景有什么影响?
- 9.在一个多层全连接神经网络中,随着层数增加,会出现哪些问题?如何解决这些问题?
- 10.全连接层的输出维度是由什么决定的?若要将全连接层的输出维度从100调整为50,需要改变哪些参数?
- 11.在训练全连接层时,如何选择合适的学习率?过大或过小的学习率会有什么影响?
- 12.全连接层在自然语言处理任务(如文本分类)中是如何应用的?与在图像识别任务中的应用有何不同?
- 13.请解释全连接层中的偏置(bias)的作用是什么?去掉偏置会对模型产生什么影响?
- 14.全连接层在生成对抗网络(GAN)中扮演什么角色?在生成器和判别器中,全连接层的设计有何不同?
- 15.如何评估全连接层在一个深度学习模型中的重要性?有没有一些指标或方法可以用来量化这种重要性?
- 16.全连接层有哪些主流变体?
- 1.注意力机制的基本思想是什么
- 2.Transformer中的注意力机制属于哪种类型
- 3.多头注意力中Q、K、V分别代表什么含义
- 4.注意力分数的计算公式是什么
- 5.为什么要对注意力分数进行缩放(除以√d_k)
- 6.softmax函数在注意力机制中的作用是什么
- 7.多头注意力的“多头”具体指什么
- 8.多头注意力的计算步骤是怎样的
- 9.多头注意力中每个头的维度是如何确定的
- 10.多头注意力为什么要将多个头的结果拼接后再线性变换
- 11.多头注意力相比单头注意力有什么优势
- 12.假设模型维度d_model=512,头数h=8,每个头的维度d_k是多少
- 13.注意力权重矩阵的维度是怎样的
- 14.自注意力机制中Q、K、V的来源有什么特点
- 15.交叉注意力机制与自注意力机制的区别是什么
- 16.多头注意力层的参数量主要由哪些部分构成
- 17.Transformer编码器中的多头注意力是自注意力还是交叉注意力
- 18.Transformer解码器中的第一个多头注意力层为什么需要掩码
- 19.什么是掩码多头注意力(Masked Multi-Head Attention)
- 20.掩码的作用是如何实现的
- 21.多头注意力层的输入输出维度是否一致
- 22.如何理解多头注意力能够捕捉不同子空间的语义信息
- 23.在多头注意力计算中,Q、K、V的线性变换是否共享参数
- 24.不同头之间的参数是否共享
- 25.多头注意力的计算复杂度是多少(以序列长度n、模型维度d_model为例)
- 26.注意力机制能够解决RNN的什么问题
- 27.多头注意力层在处理长序列时会面临什么挑战
- 28.有哪些方法可以优化多头注意力在长序列上的性能
- 29.什么是稀疏注意力
- 30.局部注意力与全局注意力的区别是什么
- 31.多头注意力中每个头的重要性是否相同
- 32.如何可视化注意力权重
- 33.注意力权重的大小能直接代表特征的重要性吗
- 34.在机器翻译任务中,多头注意力是如何捕捉源语言和目标语言之间的对应关系的
- 35.多头注意力层是否可以并行计算
- 36.并行计算对多头注意力的训练效率有什么影响
- 37.什么是自注意力的“位置混淆”问题
- 38.位置编码是如何解决自注意力的位置混淆问题的
- 39.多头注意力层与位置编码的位置关系是怎样的
- 40.如果去掉多头注意力中的某个头,模型性能会如何变化
- 41.多头注意力的头数过多会带来什么问题
- 42.如何确定多头注意力的头数和每个头的维度
- 43.多头注意力中是否存在冗余的头
- 44.什么是跨层注意力
- 45.对比多头注意力和自注意力的异同点
- 46.多头注意力在自然语言处理之外的领域有哪些应用
- 47.在图像分类任务中,多头注意力是如何应用的
- 48.多头注意力层的Dropout通常应用在哪些环节
- 49.为什么要在多头注意力中使用Dropout
- 50.多头注意力的梯度传播有什么特点
- 1.Transformer中的前馈神经网络层由哪几部分组成
- 2.前馈神经网络层的激活函数通常是什么
- 3.为什么选择ReLU作为前馈层的激活函数(或其他激活函数的原因)
- 4.前馈神经网络层的输入输出维度是否一致
- 5.前馈层中中间层的维度通常是多少
- 6.假设模型维度d_model=512,前馈层中间层维度通常设为多少
- 7.前馈神经网络层的计算步骤是怎样的
- 8.前馈层的参数量主要由什么决定
- 9.前馈神经网络层与普通的全连接神经网络有什么区别
- 10.前馈层在Transformer中起到什么作用
- 11.前馈层的计算复杂度是多少(以序列长度n、模型维度d_model、中间层维度d_ff为例)
- 12.前馈层是否可以并行处理序列中的每个位置
- 13.并行处理对前馈层的训练速度有什么影响
- 14.前馈层中是否使用了偏置项
- 15.偏置项对前馈层的性能有什么影响
- 16.前馈层中通常会使用Dropout吗,应用在哪个环节
- 17.前馈层的Dropout率一般设为多少
- 18.什么是GELU激活函数,它与ReLU相比有什么优势
- 19.Transformer的前馈层使用GELU激活函数会带来什么好处
- 20.前馈层的权重初始化有什么要求
- 21.为什么前馈层需要进行权重初始化
- 22.前馈层的梯度消失问题如何缓解
- 23.前馈层与多头注意力层的执行顺序是怎样的(编码器和解码器中)
- 24.编码器中前馈层的输入是什么
- 25.解码器中前馈层的输入是什么
- 26.前馈层是否对序列的长度敏感
- 27.前馈层处理长序列时会有什么问题吗
- 28.不同Transformer层之间的前馈层参数是否共享
- 29.如果共享前馈层参数,会对模型产生什么影响
- 30.前馈层的输出会经过什么处理后传递到下一层
- 31.前馈层在特征提取中扮演什么角色
- 32.对比前馈层和卷积层的异同点
- 33.前馈层是否能够捕捉局部特征
- 34.在Transformer-XL中,前馈层有什么改进
- 35.在BERT中,前馈层的结构与原始Transformer有区别吗
- 36.前馈层的中间层维度过大或过小会有什么问题
- 37.如何确定前馈层的中间层维度
- 38.前馈层是否可以使用多层结构(超过两层)
- 39.多层前馈层会带来什么优势和挑战
- 40.前馈层的激活函数替换为tanh会有什么效果
- 41.前馈层中使用Batch Normalization吗
- 42.为什么Transformer中前馈层更倾向于使用Layer Normalization而不是BatchNormalization
- 43.前馈层的输出维度与模型维度不一致会导致什么问题
- 44.前馈层在训练过程中容易过拟合吗,如何防止
- 45.前馈层的计算量占Transformer整体计算量的比例是多少
- 46.如何优化前馈层的计算效率
- 47.前馈层的权重衰减(Weight Decay)有什么作用
- 48.在推理阶段,前馈层的计算过程与训练阶段有什么不同
- 49.前馈层是否可以与注意力层融合设计
- 50.前馈神经网络层对Transformer模型的泛化能力有什么影响
- 1.什么是层归一化(Layer Normalization, LN)
- 2.层归一化的计算公式是什么
- 3.层归一化中的均值和方差是如何计算的
- 4.层归一化有哪些参数,它们的作用是什么
- 5.层归一化与批量归一化(Batch Normalization, BN)的区别是什么
- 6.为什么Transformer中选择使用层归一化而不是批量归一化
- 7.层归一化在Transformer中的位置是怎样的
- 8.原始Transformer中是“预归一化”还是“后归一化”
- 9.什么是预归一化(Pre-Normalization)
- 10.预归一化相比后归一化有什么优势
- 11.残差连接(Residual Connection)的基本思想是什么
- 12.残差连接的计算公式是什么
- 13.残差连接在Transformer中起到什么作用
- 14.残差连接如何缓解梯度消失问题
- 15.Transformer中残差连接的连接对象是什么
- 16.编码器中残差连接的结构是怎样的
- 17.解码器中残差连接的结构与编码器有什么不同
- 18.如果去掉Transformer中的残差连接,模型会出现什么问题
- 19.层归一化与残差连接的组合方式有哪几种
- 20.常见的“LN+残差”还是“残差+LN”哪种更优
- 21.层归一化的epsilon参数有什么作用
- 22.epsilon参数通常设为多少
- 23.残差连接是否要求输入和输出的维度一致
- 24.如果输入输出维度不一致,如何处理残差连接
- 25.Transformer中是否存在输入输出维度不一致的残差连接场景
- 26.层归一化是否会影响模型的表达能力
- 27.层归一化在训练和推理阶段的计算有什么不同
- 28.残差连接的梯度传播有什么特点
- 29.层归一化对梯度传播有什么影响
- 30.什么是LayerScale,它与层归一化有什么关系
- 31.在Transformer中,层归一化是应用在多头注意力层之前还是之后
- 32.层归一化是否应用在前馈神经网络层前后
- 33.残差连接是否可以应用在Transformer的其他部分
- 34.多层Transformer中,层归一化的参数是否共享
- 35.共享层归一化参数会带来什么问题
- 36.层归一化是否对输入数据的分布敏感
- 37.残差连接如何提升模型的训练稳定性
- 38.什么是残差块(Residual Block),Transformer中的残差块与ResNet中的有什么区别
- 39.层归一化是否可以加速模型的收敛
- 40.如果层归一化的参数初始化不当,会对模型产生什么影响
- 41.残差连接中的“捷径”(Shortcut)是否可以带有参数
- 42.带有参数的残差捷径有什么作用
- 43.层归一化在小批量数据上的表现如何
- 44.批量归一化在小批量数据上的局限性是什么
- 45.如何改进层归一化以适应特定任务需求
- 46.残差连接是否会引入冗余计算
- 47.如何减少残差连接带来的计算开销
- 48.层归一化与残差连接的组合对模型的泛化能力有什么影响
- 49.在Transformer解码器中,掩码多头注意力层的残差连接是怎样的
- 50.如果去掉层归一化,只保留残差连接,模型性能会如何变化
卷积主要有三大特点:
-
局部连接。比起全连接,局部连接会大大减少网络的参数。在二维图像中,局部像素的关联性很强,设计局部连接保证了卷积网络对图像局部特征的强响应能力。
-
权值共享。参数共享也能减少整体参数量,增强了网络训练的效率。一个卷积核的参数权重被整张图片共享,不会因为图像内位置的不同而改变卷积核内的参数权重。
-
下采样。下采样能逐渐降低图像分辨率,实现了数据的降维,并使浅层的局部特征组合成为深层的特征。下采样还能使计算资源耗费变少,加速模型训练,也能有效控制过拟合。
-
浅层卷积
$\rightarrow$ 提取边缘特征 -
中层卷积
$\rightarrow$ 提取局部特征 -
深层卷积
$\rightarrow$ 提取全局特征
最常用的是

不过大卷积核(
目标检测和目标跟踪很多模型都会用到RPN层,anchor是RPN层的基础,而感受野(receptive field,RF)是anchor的基础。
感受野的作用:
-
一般来说感受野越大越好,比如分类任务中最后卷积层的感受野要大于输入图像。
-
感受野足够大时,被忽略的信息就较少。
-
目标检测任务中设置anchor要对齐感受野,anchor太大或者偏离感受野会对性能产生一定的影响。
感受野计算:
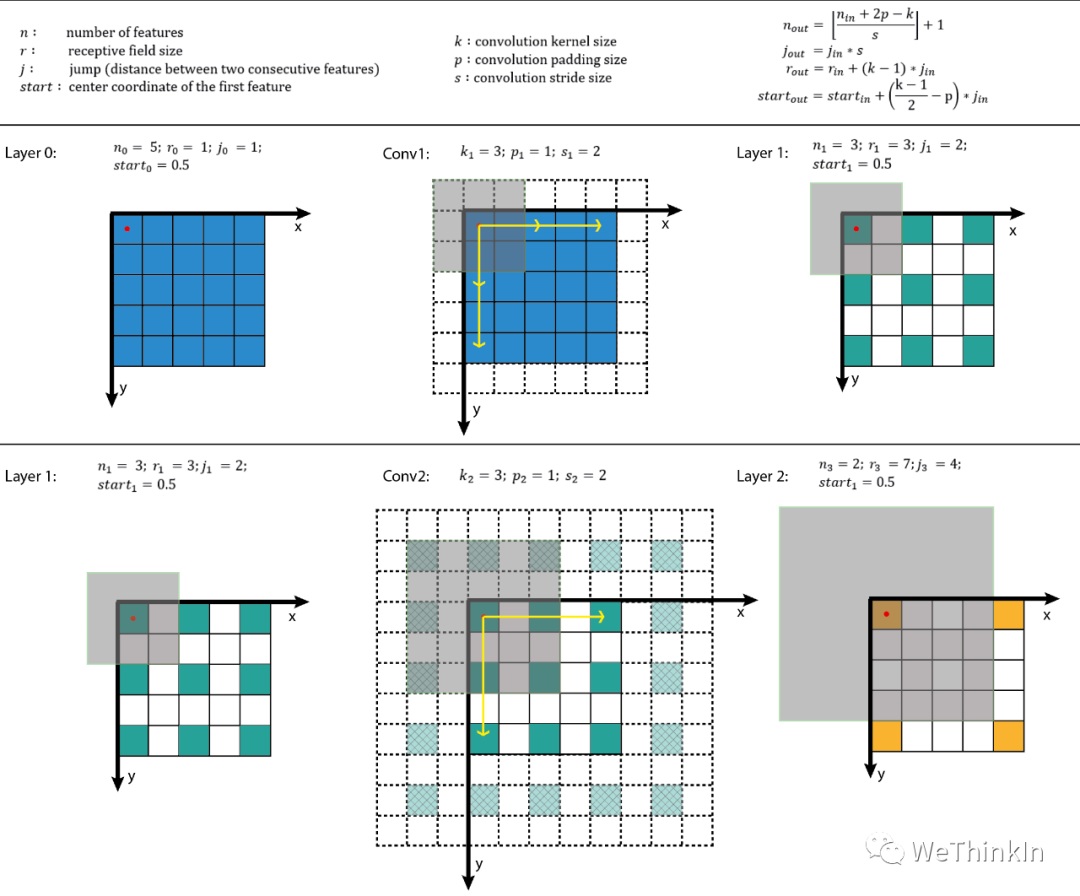
增大感受野的方法:
-
使用空洞卷积
-
使用池化层
-
增大卷积核
常规的神经网络一般每层仅用一个尺寸的卷积核,但同一层的特征图可以分别使用多个不同尺寸的卷积核,以获得不同尺度的特征,再把这些特征结合起来,得到的特征往往比使用单一尺寸卷积核的要好,如GoogLeNet 、Inception系列的网络,均是每层使用了多个不同的卷积核结构。如下图所示,输入的特征图在同一层分别经过
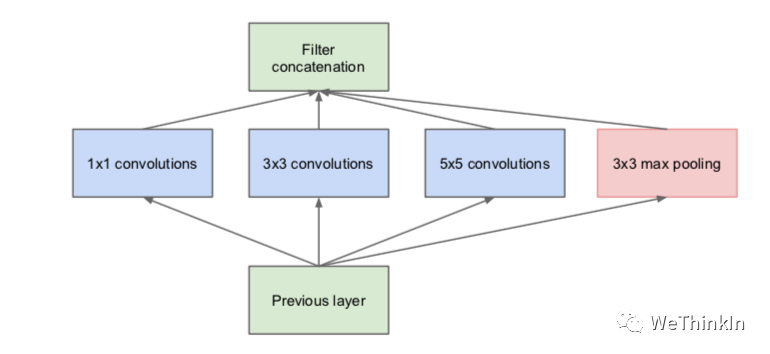
-
实现特征信息的交互与整合。
-
对特征图通道数进行升维和降维,降维时可以减少参数量。
-
$1*1$ 卷积+ 激活函数$\rightarrow$ 增加非线性,提升网络表达能力。


转置卷积通过训练过程学习到最优的上采样方式,来代替传统的插值上采样方法,以提升图像分割,图像融合,GAN等特定任务的性能。
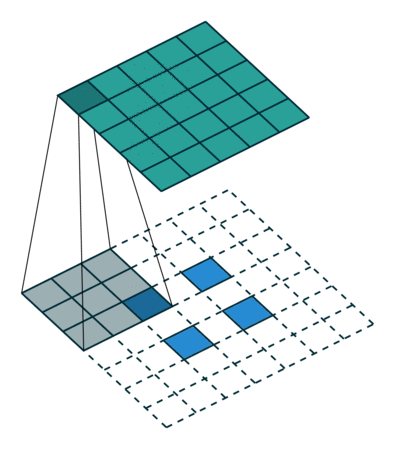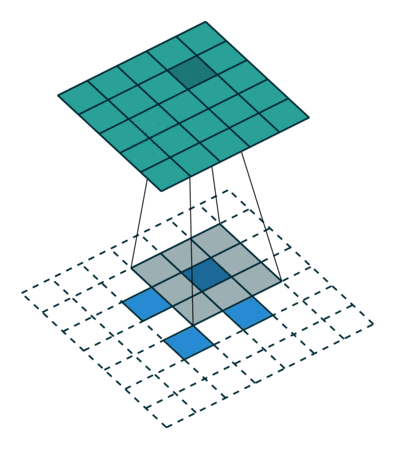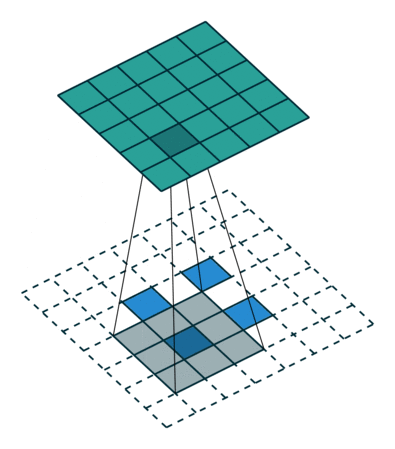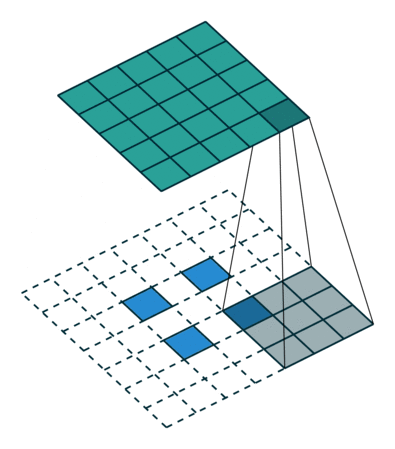
转置卷积并不是卷积的反向操作,从信息论的角度看,卷积运算是不可逆的。转置卷积可以将输出的特征图尺寸恢复卷积前的特征图尺寸,但不恢复原始数值。
转置卷积的计算公式:
我们设卷积核尺寸为
(1)当
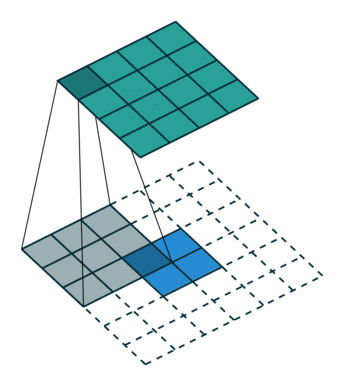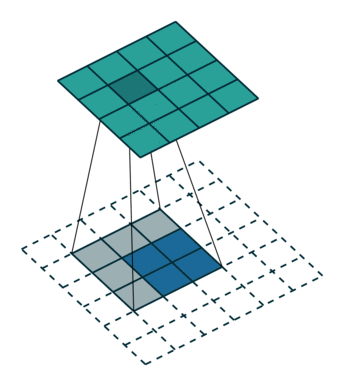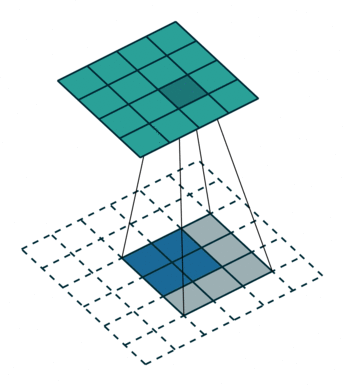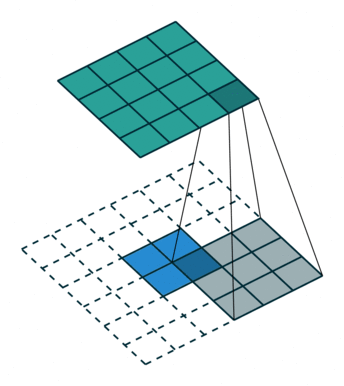
输入特征图在进行转置卷积操作时相当于进行了
输出特征图的尺寸 =
(2)当
输入特征图在进行转置卷积操作时相当于进行了
输出特征图的尺寸 =
空洞卷积的作用是在不进行池化操作损失信息的情况下,增大感受野,让每个卷积输出都包含较大范围的信息。
空洞卷积有一个参数可以设置dilation rate,其在卷积核中填充dilation rate个0,因此,当设置不同dilation rate时,感受野就会不一样,也获取了多尺度信息。
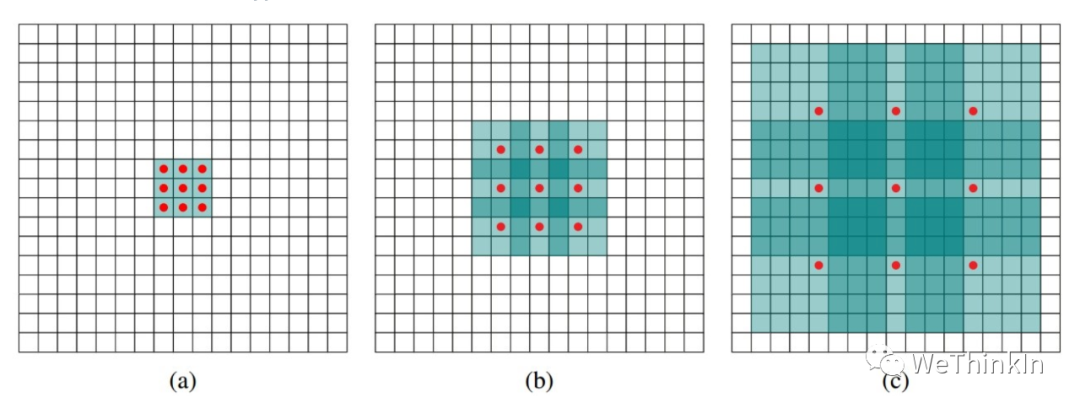
(a) 图对应

造成棋盘效应的原因是转置卷积的不均匀重叠(uneven overlap)。这种重叠会造成图像中某个部位的颜色比其他部位更深。
在下图展示了棋盘效应的形成过程,深色部分代表了不均匀重叠:
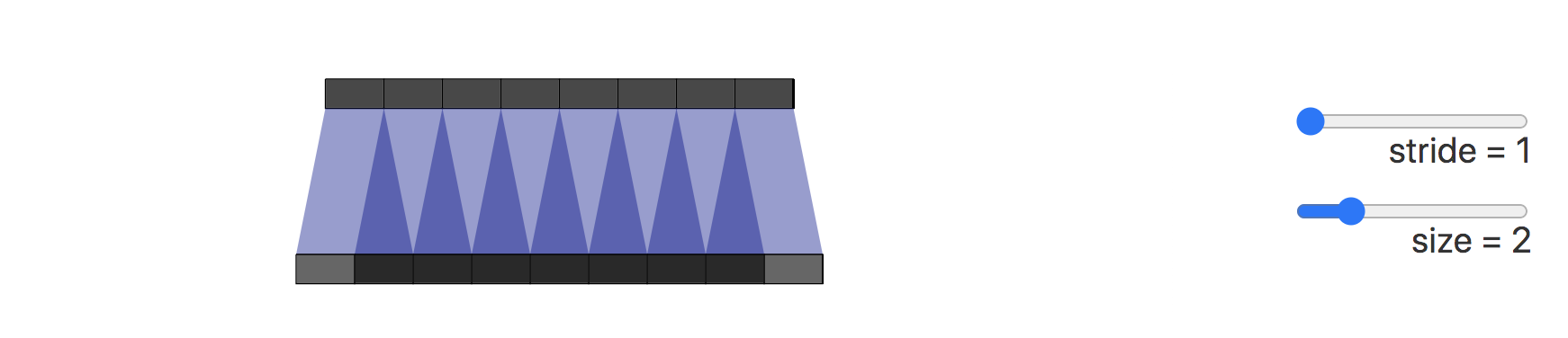
接下来我们将卷积步长改为2,可以看到输出图像上的所有像素从输入图像中接收到同样多的信息,它们都从输入图像中接收到一个像素的信息,这样就不存在转置卷带来的重叠区域。
我们也可以直接进行插值Resize操作,然后再进行卷积操作来消除棋盘效应。这种方式在超分辨率重建场景中比较常见。例如使用双线性插值和近邻插值等方法来进行上采样。
感受野的相关知识在上面的第四节中中介绍过。
我们接着再看看有效感受野(effective receptive field, ERF)的相关知识。
一般而言,feature map上有效感受野要小于实际感受野。其有效性,以中心点为基准,类似高斯分布向边缘递减。
总的来说,感受野主要描述feature map中的最大信息量,有效感受野则主要描述信息的有效性。
分组卷积(Group Convolution)最早出现在AlexNet网络中,分组卷积被用来切分网络,使其能在多个GPU上并行运行。

普通卷积进行运算的时候,如果输入feature map尺寸是
分组卷积的主要对输入的feature map进行分组,然后每组分别进行卷积。如果输入feature map尺寸是
分组卷积的作用:
-
分组卷积可以减少参数量。
-
分组卷积可以看成是稀疏操作,有时可以在较少参数量的情况下获得更好的效果(相当于正则化操作)。
-
当分组数量等于输入feature map通道数量,输出feature map数量也等于输入feature map数量时,分组卷积就成了Depthwise卷积,可以使参数量进一步缩减。
可变形卷积(Deformable Convolution)是一种改进传统卷积神经网络(CNN)能力的新型卷积方法,旨在解决CNN在建模几何变换方面的固有限制。传统的卷积操作在固定的几何结构上进行采样,这使得它们在面对不同对象的尺度、姿态、视角和部分变形时表现不佳。
可变形卷积通过在标准卷积的采样网格位置上添加2D偏移量,使得卷积核能够在自由形式的采样位置上进行操作。这些偏移量通过前面的特征图生成,并通过额外的卷积层进行学习,从而使得变形是基于输入特征局部和自适应的。
如下图所示:
- 输入特征图(Input Feature Map):传统卷积在输入特征图上以固定网格采样。
- 卷积核(Conv):在标准卷积中,卷积核在特征图上滑动,生成输出特征图。
- 偏移场(Offset Field):在可变形卷积中,偏移量由前一层特征图生成,并与卷积核一起应用于输入特征图。
- 输出特征图(Output Feature Map):最终生成的输出特征图具有更强的适应性,能够更好地捕捉图像中的几何变换。


标准卷积(a)和可变形卷积(b)中固定感受野和自适应感受野的示意图如上图所示。
3D卷积(3D Convolution)是一种用于处理三维数据的卷积运算。与我们常见的2D卷积不同,3D卷积不仅在图像的宽和高两个空间维度上滑动,还在第三个维度上滑动,通常是时间或深度维度。因此,3D卷积通常用于处理如视频、医学影像(如MRI或CT扫描)或任何具有时间、深度信息的三维数据。
要理解3D卷积的原理,我们可以从2D卷积入手。假设我们有一个2D卷积核(kernel),它在图像上滑动,生成一个特征图(Feature Map)。这个过程可以类比为在图片上用滤镜移动,提取特定的特征,例如边缘、纹理等。
现在,想象一下,我们不仅在图像的宽度和高度方向滑动卷积核,还在第三个维度上滑动,这个维度可以是时间(如视频中的帧)、深度(如CT扫描中的层)、或者颜色通道的组合。
-
输入数据:
- 3D卷积的输入通常是一个三维特征,例如一个视频可以表示为
(帧数, 高度, 宽度),或一个立体图像(如3D医疗图像)表示为(深度, 高度, 宽度)。
- 3D卷积的输入通常是一个三维特征,例如一个视频可以表示为
-
卷积核(Filter/Kernels):
- 3D卷积核是一个三维的小块。例如,一个
$3\times3\times3$ 的卷积核在三个维度上分别有3个单元。 - 卷积核在输入数据的三个维度上滑动,在每一个位置进行点积运算(每个元素相乘再整体相加),生成一个输出值。
- 3D卷积核是一个三维的小块。例如,一个
-
输出特征图:
- 输出特征也是一个三维特征图,它记录了卷积核在输入数据上每个位置滑动时的运算结果。输出的深度由输入数据的深度和卷积核的深度决定。
想象一下,我们在制作巧克力,模具就是我们的卷积核。我们有一个厚厚的巧克力板(3D输入数据),你要在这块板上用模具压出不同形状的巧克力(输出特征图)。
-
2D卷积:就像在一块平面的巧克力上用模具压出形状,我们只能在平面上移动模具(左右、上下),每次我们都会得到一个平面巧克力的形状。
-
3D卷积:现在我们不仅可以在平面上移动模具,还可以把模具往巧克力的厚度方向压进去。这样,我们每次压出的是一个立体的巧克力块。这块立体巧克力反映了我们在厚度方向(如时间、深度)上也进行了一次处理。
-
AI视频领域:
- 在AI视频领域中,3D卷积的作用非常明显,Sora、CogVideoX等主流AI视频大模型中都用到了3D卷积。视频数据通常是多个连续的帧序列,通过在时间维度上进行卷积,AI视频模型可以捕捉到动作的动态特征。
-
医学影像:
- 在医学影像中,如MRI或CT扫描,3D卷积可以在扫描的多个切片上滑动,以捕捉人体内部结构的三维特征,这对于诊断和分析非常重要。
-
人体姿态估计:
- 3D卷积可以用于从多帧图像中提取人体的姿态,帮助模型理解姿态变化和动作。
3D卷积的输入通常是一个四维张量,形状为 (D, H, W, C),其中:
D是深度(例如视频中的帧数或医学图像中的切片数)。H是高度。W是宽度。C是通道数(例如,RGB图像的通道数为3)。
假设我们有一个输入张量 X,其形状为 (D_in, H_in, W_in, C_in),其中 C_in 是输入的通道数。我们还有一个卷积核 W,其形状为 (D_k, H_k, W_k, C_in, C_out),其中 C_out 是输出的通道数。
-
滑动卷积核:
- 卷积核
W在输入张量X上按步长(stride)滑动。在每个位置,卷积核的每个元素与对应位置的输入数据相乘,并将这些乘积相加得到一个输出值。
- 卷积核
-
点积运算:
-
在每个滑动位置,对输入张量与卷积核进行点积运算。具体地,对于某个位置
(i, j, k)的输出值,计算公式为:$$Y(i, j, k, m) = \sum_{d=0}^{D_k-1} \sum_{h=0}^{H_k-1} \sum_{w=0}^{W_k-1} \sum_{c=0}^{C_in-1} X(i+d, j+h, k+w, c) \cdot W(d, h, w, c, m)$$ 其中:
-
Y(i, j, k, m)是输出张量在位置(i, j, k)和通道m上的值。 -
X(i+d, j+h, k+w, c)是输入张量X在位置(i+d, j+h, k+w)和通道c上的值。 -
W(d, h, w, c, m)是卷积核W在位置(d, h, w)和输入通道c、输出通道m上的权重。
-
-
-
应用偏置:
-
对于每个输出通道,可以添加一个偏置
b[m],使得最终的输出为:$$Y(i, j, k, m) = Y(i, j, k, m) + b[m]$$
-
-
输出张量:
- 经过上述操作后,得到的输出张量
Y的形状为(D_out, H_out, W_out, C_out),其中D_out、H_out和W_out分别是深度、高度和宽度方向上的输出尺寸。
- 经过上述操作后,得到的输出张量
假设我们有一个输入张量 X,其形状为 (4, 4, 4, 1),即深度、高度、宽度均为4,且有一个输入通道。我们有一个卷积核 W,其形状为 (2, 2, 2, 1, 1),即大小为2x2x2的立方体卷积核,有1个输入通道和1个输出通道。步长为1,无填充(padding)。
-
卷积核在输入张量上滑动:
- 卷积核首先覆盖输入张量的前2x2x2部分,与这部分的输入数据进行点积运算,得到一个输出值。
- 然后,卷积核滑动到下一个位置,重复上述过程,直到覆盖所有可能的位置。
-
计算每个位置的输出:
-
例如,对于第一个位置(顶点)上的输出值,计算公式为:
$$Y(0, 0, 0, 0) = X(0, 0, 0, 0) \cdot W(0, 0, 0, 0, 0) + X(0, 0, 1, 0) \cdot W(0, 0, 1, 0, 0) + \ldots + X(1, 1, 1, 0) \cdot W(1, 1, 1, 0, 0)$$
-
-
得到最终输出:
- 经过所有位置的计算后,得到的输出张量
Y的形状为(3, 3, 3, 1)。
- 经过所有位置的计算后,得到的输出张量
优点:
- 能够捕捉到输入数据的三维特征,尤其适合处理视频数据和3D图像数据。
- 能够捕捉时间维度(或深度维度)的变化,适用于动态特征提取。
缺点:
- 计算复杂度更高,训练时间更长。
- 需要更多的内存和计算资源。
1. 时间复杂度(计算量)
时间复杂度衡量卷积层的计算资源消耗,通常用**浮点运算次数(FLOPs)**表示。
公式:
其中:
-
$K$ :卷积核尺寸(假设为正方形核) -
$C_{\text{in}}$ :输入通道数 -
$C_{\text{out}}$ :输出通道数 -
$H_{\text{out}}, W_{\text{out}}$ :输出特征图的高度和宽度
注:乘法和加法各计1次运算,因此系数为2。
2. 空间复杂度(参数量与内存占用)
空间复杂度包含两部分:
-
参数量:模型存储的权重参数数量
$$\text{Params} = K^2 \times C_{\text{in}} \times C_{\text{out}}$$ -
激活内存:前向传播中特征图的存储需求
$$\text{Memory} = C_{\text{out}} \times H_{\text{out}} \times W_{\text{out}} \times \text{bytes-per-element}$$ (通常每个元素为4字节的float32类型)
案例:手机端图像分类模型
假设输入为RGB图像(3×224×224),使用一个卷积层:
- 卷积核:3×3,输出通道64,步长1,padding=1
- 输出尺寸:64×224×224
复杂度计算:
-
时间复杂度:
$$2 \times 3^2 \times 3 \times 64 \times 224 \times 224 = 1.73 \times 10^9 , \text{FLOPs}$$ -
参数量:
$$3^2 \times 3 \times 64 = 1,728 , \text{参数}$$ -
激活内存:
$$64 \times 224 \times 224 \times 4 , \text{Bytes} = 12.58 , \text{MB}$$
优化对比:
若改用深度可分离卷积(Depthwise Separable Convolution):
- 参数量降至
$3^2 \times 3 + 3 \times 64 = 27 + 192 = 219$ - FLOPs降至
$3^2 \times 3 \times 224^2 + 3 \times 64 \times 224^2 = 0.13 \times 10^9 , \text{FLOPs}$ 计算量减少约13倍,适用于移动端部署。
我们都知道,卷积是AI领域的核心模块之一,通过不同结构的卷积核提取输入数据的多层次特征。以下是Rocky总结的常见卷积类型及其在AIGC、传统深度学习、自动驾驶中的应用:
-
原理:使用固定大小的滑动窗口(如3×3、5×5)逐区域计算加权和,提取局部特征。
-
公式:
$$y(i,j) = \sum_{m}\sum_{n} x(i+m, j+n) \cdot k(m,n)$$ -
案例:图像分类任务中,CNN通过多层标准卷积提取边缘→纹理→物体部件等特征。
-
应用:
- AIGC:Stable Diffusion的基础卷积层生成图像细节。
- 传统深度学习:ResNet、VGG等模型的核心操作。
- 自动驾驶:摄像头图像中的车辆/行人检测。
- 原理:拆分标准卷积为深度卷积(逐通道) + 1×1卷积(通道融合),减少计算量。
-
计算量对比:
标准卷积:$D_K \times D_K \times M \times N$ 深度可分离:$D_K \times D_K \times M + M \times N$ ($D_K$ 为卷积核尺寸,$M$ 输入通道,$N$ 输出通道) - 案例:MobileNet通过此卷积在手机端实时运行图像分类。
-
应用:
- AIGC:轻量化文本生成模型部署到移动端。
- 传统深度学习:移动端/嵌入式设备模型优化。
- 自动驾驶:车载芯片实时处理多摄像头输入。
- 原理:在卷积核元素间插入空洞(间隔),扩大感受野且不增加参数量。
# PyTorch示例(空洞率=2) nn.Conv2d(in_channels, out_channels, kernel_size=3, dilation=2)
- 案例:DeepLab系列使用空洞卷积保持高分辨率特征图,提升语义分割精度。
- 应用:
- AIGC:高清图像生成时捕捉长程依赖(如头发纹理)。
- 传统深度学习:视频动作识别中建模时序跨度。
- 自动驾驶:LiDAR点云中的大范围障碍物检测。
- 原理:通过填充和步长实现上采样,重建高分辨率特征图。
- 操作示例:输入2×2 → 转置卷积(kernel=3, stride=2)→ 输出5×5。
- 案例:GAN生成器将低维噪声转换为高清图像。
- 应用:
- AIGC:图像超分辨率重建、风格迁移。
- 传统深度学习:U-Net解码器恢复医学影像细节。
- 自动驾驶:BEV(鸟瞰图)特征解码生成道路拓扑。
- 原理:将输入通道分组,每组独立卷积后拼接结果,减少计算量。
# ResNeXt的分组卷积(组数=32) nn.Conv2d(64, 128, kernel_size=3, groups=32)
- 案例:ResNeXt通过分组卷积提升模型容量而不显著增加计算量。
- 应用:
- AIGC:多任务生成模型(如同时生成图像和描述)。
- 传统深度学习:大规模分类模型加速训练。
- 自动驾驶:多传感器(摄像头+雷达)特征分组处理。
- 原理:通过偏移量学习动态调整卷积核采样位置,适应不规则形状。
# 可变形卷积层 from torchvision.ops import DeformConv2d DeformConv2d(in_channels, out_channels, kernel_size=3)
- 案例:DCN(可变形卷积网络)提升COCO数据集目标检测AP 3%~5%。
- 应用:
- AIGC:生成非刚性物体(如衣服褶皱、流体)。
- 传统深度学习:复杂场景下的实例分割。
- 自动驾驶:处理遮挡或形变的行人/车辆检测。
- 原理:在三维空间(长、宽、时间/深度)滑动,提取时空特征。
# 视频处理中的3D卷积 nn.Conv3d(in_channels, out_channels, kernel_size=(3,3,3))
- 案例:C3D网络分析视频中的动作时序特征。
- 应用:
- AIGC:视频生成(如动态纹理合成)。
- 传统深度学习:CT/MRI医学影像分析。
- 自动驾驶:多帧LiDAR序列处理预测运动轨迹。
- 原理:仅融合通道信息,不改变空间尺寸,用于升维/降维。
# Inception模块中的1×1卷积 nn.Conv2d(256, 128, kernel_size=1)
- 案例:SqueezeNet通过1×1卷积压缩参数,模型体积减少50倍。
- 应用:
- AIGC:StyleGAN中的风格向量通道调制。
- 传统深度学习:ResNet瓶颈层减少计算量。
- 自动驾驶:多模态特征通道融合(图像+点云)。
- 原理:根据输入动态生成卷积核权重,增强模型适应性。
# 动态卷积示例 weights = generate_weights(x) # 输入相关 output = dynamic_conv(x, weights)
- 案例:CondConv在ImageNet分类任务中提升精度1.2%。
- 应用:
- AIGC:个性化图像生成(根据用户输入调整风格)。
- 传统深度学习:小样本学习动态适配新类别。
- 自动驾驶:动态调整卷积核以适应不同天气条件。
| 卷积类型 | 核心作用 | AIGC应用 | 传统深度学习应用 | 自动驾驶应用 |
|---|---|---|---|---|
| 标准卷积 | 基础特征提取 | 图像生成 | ResNet分类 | 目标检测 |
| 深度可分离卷积 | 轻量化计算 | 移动端生成模型 | MobileNet | 实时多摄像头处理 |
| 空洞卷积 | 扩大感受野 | 高清细节生成 | DeepLab分割 | 大范围障碍物检测 |
| 转置卷积 | 上采样重建 | GAN生成器 | U-Net解码器 | BEV地图生成 |
| 分组卷积 | 多分支特征学习 | 多任务生成模型 | ResNeXt | 多传感器融合 |
| 可变形卷积 | 适应不规则形状 | 非刚性物体生成 | DCN检测 | 遮挡目标检测 |
| 3D卷积 | 时空建模 | 视频生成 | C3D动作识别 | LiDAR序列分析 |
| 1×1卷积 | 通道维度调整 | 风格调制 | 通道压缩 | 多模态特征融合 |
| 动态卷积 | 输入自适应计算 | 个性化生成 | CondConv | 环境自适应模型 |
Rocky总结的核心答案:卷积神经网络的本质是——利用具有“局部连接”、“权值共享”和“空间/时序层次化特征提取”能力的卷积操作,高效地从网格化数据(如图像、视频、音频频谱图)中自动学习具有平移不变性的层次化特征表示。
-
核心操作:卷积 (Convolution)
- 数学上: 本质是滤波器(Kernel/Filter) 在输入数据(如图像)上滑动,进行局部区域的点积运算。滤波器是一组可学习的权重参数。
- 直观上: 想象用一个带小窗口(滤波器)的放大镜在图片上移动。在每个位置,窗口只看到图片的一小块(局部区域),计算这个小块与窗口内部图案(滤波器权重)的匹配程度。匹配程度高,输出值就大。
- 作用: 检测输入数据中的局部模式,如边缘、角点、纹理、基本形状等。
-
关键特性:
- 局部连接 (Local Connectivity):
- 是什么: 输出特征图上的一个像素点(神经元),只与输入数据中对应位置附近的一个小区域(感受野)内的输入值相连,而不是与整个输入相连(像全连接层那样)。
- 为什么是本质: 这完美契合了图像等数据的特性——像素点的重要性主要取决于其邻近像素,远处的像素影响很小。极大减少了参数量和计算量,让处理高分辨率图像成为可能。
- 权值共享 (Parameter Sharing):
- 是什么: 同一个滤波器在整个输入数据上滑动并重复使用相同的权重参数。无论滤波器滑到图像的哪个位置,它都在检测相同的模式(比如垂直边缘)。
- 为什么是本质:
- 进一步显著减少参数量: 一个滤波器只有
Kernel_Width * Kernel_Height * Input_Channels个参数,无论输入图像有多大。 - 赋予平移不变性 (Translation Invariance): 这是CNN最强大的特性之一!无论目标物体(如猫)出现在图像的左上角还是右下角,只要用于检测“猫耳朵”或“猫胡须”的滤波器学到了这个模式,它就能在图像的任何位置将其检测出来。模型学会了关注“有什么特征”,而不是“特征具体在哪个绝对坐标位置”。
- 进一步显著减少参数量: 一个滤波器只有
- 层次化特征提取 (Hierarchical Feature Learning):
- 是什么: CNN通常由多个卷积层堆叠而成。浅层卷积层学习低级、简单的特征(边缘、角点、颜色斑点)。这些低级特征被输入到下一层。深层卷积层组合低级特征,学习中级特征(纹理、基本部件如眼睛、轮子)。更深层则组合中级特征,学习高级、抽象、语义化的特征(整个物体如人脸、汽车、特定场景)。
- 为什么是本质: 这种由简单到复杂、由局部到全局的层次化结构,模拟了人类视觉系统处理信息的方式(V1 -> V2 -> V4 -> IT区),使得CNN能够理解图像中复杂的结构和语义信息。
- 对网格化数据的天然适配:
- 是什么: CNN特别擅长处理具有规则网格结构的数据,如图像(2D像素网格)、视频(2D空间+1D时间网格)、语音(1D时间序列或2D频谱图)。
- 为什么是本质: 卷积操作的滑动特性天然利用了数据点在空间或时间上的邻近性和结构关系。
- 局部连接 (Local Connectivity):
想象我们要设计一个程序,通过指纹图像识别不同的人。指纹的核心是脊线(Ridge)和谷线(Valley)构成的独特纹理模式。
-
低级特征检测(浅层卷积):
- 使用第一个卷积层,滤波器就像一个小型“边缘探测器”。它在指纹图像上滑动。
- 当它滑过脊线和谷线交界的地方(即脊线边缘)时,由于像素值变化剧烈(暗变亮或亮变暗),滤波器的点积运算会输出一个高响应值(表明检测到了边缘)。
- 这个滤波器在整个图像上共享权重,所以无论脊线边缘出现在指纹的哪个位置(中心还是边缘),它都能被检测到(平移不变性)。
- 这一层输出一个“边缘激活图”,亮的地方表示检测到了脊线边缘。
-
中级特征检测(中层卷积):
- 第二层卷积接收第一层的“边缘激活图”作为输入。
- 它的滤波器更大一些,可以覆盖第一层输出的一个小区域(即原始图像中更大的区域)。
- 这一层的滤波器学习识别由多个边缘片段构成的基本纹理单元,比如一小段弯曲的脊线、一个短的分叉点、或者一个小环。
- 同样,这些检测脊线分叉、小环的滤波器在整个图像上权值共享,无论这些特征出现在哪里都能被检测到。
-
高级特征与识别(深层卷积 + 全连接):
- 更深层的卷积层组合中层检测到的纹理单元(分叉、环、端点),学习识别更复杂的指纹特征,如一个完整的“斗型纹”、“箕型纹”的核心区域,或者一个显著的“三角区”。
- 最后,这些高级的、抽象的特征图会被展平,送入全连接层。
- 全连接层学习这些高级特征的特定组合模式,每种模式对应一个特定的人(或指纹ID)。它判断检测到的斗型核心、三角区位置、脊线流向等特征组合是否与数据库中张三的指纹模式高度匹配。
在这个过程中,CNN的本质体现得淋漓尽致:
- 卷积操作: 逐层滑动滤波器,检测局部模式。
- 局部连接 & 权值共享: 每个特征检测器只关注一小块区域,且同一模式检测器(如边缘、分叉点检测器)在整个指纹上复用,大大降低了计算量和参数量。
- 平移不变性: 无论指纹图像在输入时是居中还是稍微偏移,只要脊线模式相同,CNN都能正确识别张三,因为检测关键特征的滤波器在图像任何位置都有效。
- 层次化特征: 从边缘(低级) -> 分叉/环(中级) -> 斗型/三角区(高级) -> 个体指纹模式(语义级),逐步抽象。
-
AIGC (生成式人工智能):
- 应用场景: 图像生成(Stable Diffusion, DALL-E)、视频生成(Sora)、音乐生成(频谱图)、图像超分辨率、图像修复、风格迁移。
- CNN本质的应用:
- 核心骨干: 大多数生成模型(如GAN的判别器/生成器、Diffusion Model的U-Net)深度依赖CNN(或其变体如ConvNeXt)作为特征提取器。
- 空间特征理解: 在图像/视频生成中,CNN编码器负责理解输入文本描述或噪声图像的空间结构和语义内容(低级纹理到高级物体)。解码器(通常是转置卷积)则利用学到的层次化特征在空间上“绘制”出符合语义和结构的像素,从粗糙轮廓到精细细节。
- 平移不变性 & 局部性: 确保生成的物体可以合理地出现在画面的不同位置,并且局部细节(如毛发、砖缝)是连贯的。
- 案例: Stable Diffusion 的 U-Net 使用CNN层处理图像潜空间表示,在去噪过程中逐步恢复图像的层次化结构(从模糊的全局结构到清晰的局部细节),同时条件机制(如文本嵌入)通过交叉注意力引导CNN特征生成符合描述的特定内容。
-
传统深度学习 (计算机视觉为主):
- 应用场景: 图像分类(ResNet, ViT虽流行但CNN仍是基础)、目标检测(YOLO, Faster R-CNN)、语义分割(U-Net, DeepLab)、人脸识别、图像描述生成(CNN + RNN/LSTM)。
- CNN本质的应用:
- 基石模型: CNN是计算机视觉领域近十年爆发的核心驱动力。ImageNet竞赛的优胜者(AlexNet, VGG, GoogLeNet, ResNet)都是CNN架构的演进。
- 高效特征提取: 利用局部连接、权值共享和层次化结构,CNN能从海量图像数据中高效地自动学习强大的视觉特征表示,替代了手工设计特征(如SIFT, HOG)。
- 平移不变性: 这是CV任务的关键需求。CNN天然保证检测到的物体(如猫、车)在图像中发生平移时,仍能被正确识别。
- 层次化理解: 从像素级边缘到物体级语义,CNN的特征图天然适合不同粒度的任务:分类(高级特征)、检测(中级特征定位+高级特征分类)、分割(需要保留空间信息的各级特征)。
- 案例: YOLO目标检测器。其骨干网络(如DarkNet)是CNN,负责从输入图像提取层次化特征图。不同尺度的特征图用于检测不同大小的物体(浅层特征图分辨率高,利于检测小物体;深层特征图语义强,利于检测大物体)。检测头利用这些特征图上的卷积操作,直接在网格单元上预测边界框和类别。
-
自动驾驶:
- 应用场景: 环境感知(摄像头/激光雷达目标检测、分割、车道线检测)、可行驶区域分割、传感器融合(图像+雷达/激光雷达)、端到端驾驶(输入图像直接输出控制指令)。
- CNN本质的应用:
- 感知的核心: 基于摄像头的感知系统几乎完全建立在CNN(及其3D/时序扩展)之上。处理激光雷达点云(投影为2D俯视图或多视图)也常用CNN。
- 处理高维空间数据: 摄像头图像是2D网格,激光雷达投影图也是2D网格。CNN的局部连接和权值共享特性使其成为处理这些高分辨率、高维度传感器数据的首选架构,能在有限的车载计算资源下高效运行。
- 平移不变性 & 空间理解: 对自动驾驶至关重要!无论车辆、行人、交通标志出现在视野中的哪个位置(左/右/远/近),CNN都能可靠地检测和识别它们。CNN强大的空间特征提取能力对于理解道路结构(车道线、路沿)、可行驶区域至关重要。
- 层次化特征用于不同任务: 低级特征(边缘)用于车道线检测;中级特征(车轮、车窗)用于车辆检测;高级特征(整个车辆、行人轮廓)用于目标分类和跟踪。多任务学习常共享CNN骨干提取的丰富特征。
- 时序/3D扩展: 处理视频流(时序信息)使用3D卷积或CNN+RNN,在空间卷积基础上增加时间维度,检测运动物体。处理原始点云使用3D稀疏卷积或投影后2D卷积。
- 案例: Tesla的HydraNet。它使用一个大型共享的CNN骨干网络(如ResNet变体)同时处理多个摄像头输入。骨干网络提取丰富的空间特征。然后,多个不同的任务特定“头”(也是CNN结构)连接到骨干的不同层次特征上,并行执行各种感知任务(车辆检测、行人检测、车道线分割、交通灯识别、深度估计等)。CNN的效率和层次化特征提取能力是实现这种高效多任务感知系统的关键。
卷积神经网络的本质优势在于其利用卷积操作,通过局部连接、权值共享实现了参数效率和计算效率,并赋予了模型关键的平移不变性。其层次化堆叠的结构使其能够从数据中自动学习从低级到高级的抽象特征表示,特别适合于处理具有空间或时序局部相关性和网格结构的数据(图像、视频、语音、点云等)。
在AIGC领域,CNN是理解和生成空间内容(图像、视频)的骨干,实现从文本到像素的精确空间映射和细节合成。在传统深度学习(CV) 领域,CNN是基石,彻底革新了特征提取方式,推动了图像理解任务的飞跃。在自动驾驶领域,CNN是环境感知系统的核心引擎,高效处理高维传感器数据,实现对周围世界可靠的空间理解,是行车安全的关键保障。理解CNN的本质,是驾驭现代AI,尤其在视觉相关领域,不可或缺的基础。
池化层的作用是 <font color=DeepSkyBlue>对感受野内的特征进行选择,提取区域内最具代表性的特征,能够有效地减少输出特征数量,进而减少模型参数量 </font>。按操作类型通常分为最大池化(Max Pooling)、平均池化(Average Pooling)和求和池化(Sum Pooling),它们分别提取感受野内最大、平均与总和的特征值作为输出,最常用的是最大池化和平均池化。
全局池化主要包括全局平均池化和全局最大池化。

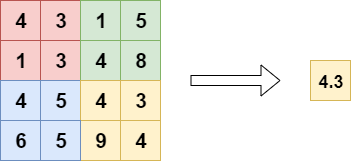
接下来,Rocky以全局平均池化为例,讲述其如何在深度学习网络中发挥作用。
刚才已经讲过,全局平均池化就是对最后一层卷积的特征图,每个通道求整个特征图的均值。如下图所示:
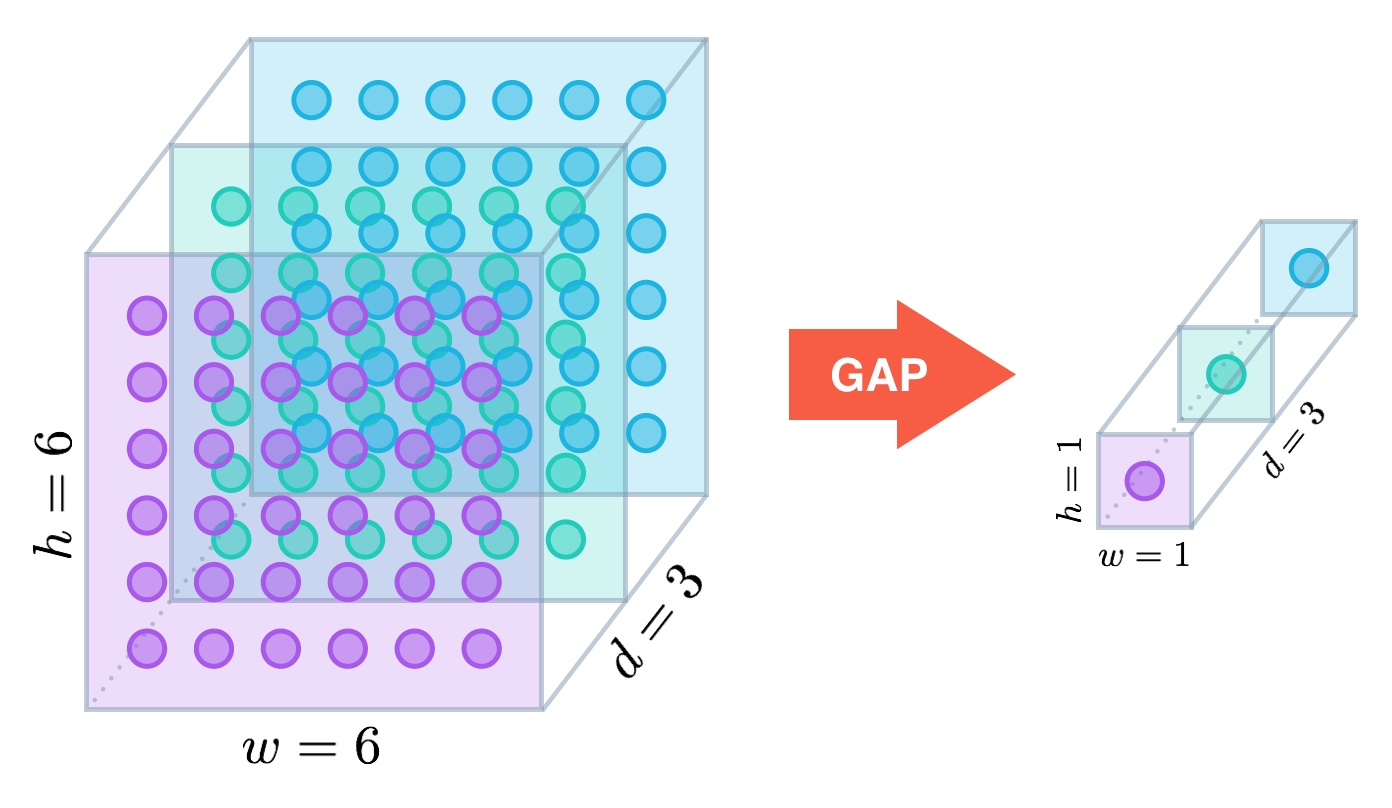
一般网络的最后会再接几个全连接层,但全局池化后的feature map相当于一像素,所以最后的全连接其实就成了一个加权相加的操作。这种结构比起直接的全连接更加直观,参数量大大幅下降,并且泛化性能更好:

全局池化的作用:
1.降低信息冗余 :
- 池化层有助于提取输入特征图中的主要信息,同时抑制次要信息。这种操作使得模型更专注于重要特征,减少冗余或不相关的特征,有利于模型的训练和泛化能力。
2.特征降维与下采样 :
- 池化操作导致输出特征图的尺寸减小,实现了特征降维和下采样的效果。这有助于减少计算量,并提高后续层对图像特征的感知范围,使得一个池化后的像素对应前面图片中的一个区域。
3.特征压缩与网络简化 :
- 池化层能够对特征图进行压缩,减少计算资源的消耗,简化网络结构,降低模型复杂度,有助于防止过拟合,提高模型的泛化能力。
4.提升模型的不变性 :
- 池化操作有助于提升模型对尺度、旋转和平移的不变性。经过池化后的特征图,在输入特征图的大小或旋转角度发生变化时,输出特征图的大小和旋转角度保持不变。这种不变性有助于提高模型的泛化能力和鲁棒性。
5.实现非线性。

在CNN中,池化层用于减小特征图的空间尺寸,以降低计算量并减少过拟合的可能性。最常见的池化操作有两种:
- 计算图像区域的平均值作为该区域池化后的值。
- 能够抑制由于邻域内大小受限造成估计值方差增大的现象。
- 其特点是对于背景的保留效果更好。
- 选取图像区域的最大值作为该区域池化后的值。
- 能够抑制网络参数误差造成估计均值偏移的现象。
- 其特点是更好地提取纹理信息。
- 根据概率对局部的值进行采样,采样结果便是池化结果。
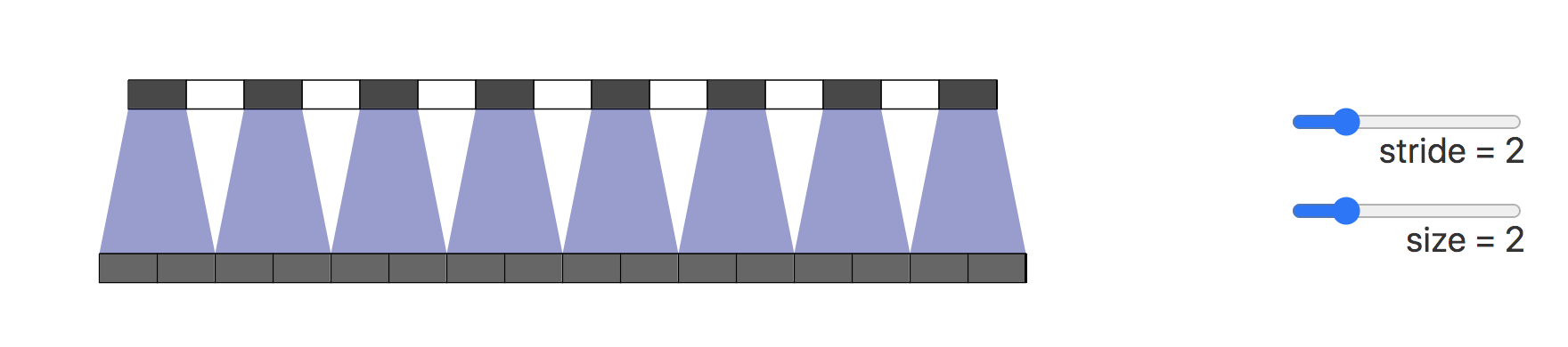
在某些情况下,相邻的池化窗口之间可以有重叠区域。这种情况下一般会设置池化窗口的大小(size)大于步幅(stride)。
重叠池化的特点是相比于常规池化操作,它可以更充分地捕获图像特征,但也可能导致计算量增加。
这些池化方法是CNN中常用的技术手段,用于在保留重要信息的同时减少数据尺寸和参数量,从而改善模型的性能和泛化能力。
论文名称:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 下载地址:https://arxiv.org/abs/1406.4729
空间金字塔池化(Spatial Pyramid Pooling,SPP)层的引入解决了在传统卷积神经网络(CNN)中需要固定输入图像尺寸的限制。传统的全连接层对于输入要求固定大小的特征向量,这意味着所有输入图像需要统一尺寸,通常需要进行裁剪或拉伸,导致图像失真。SPP层允许网络接受不同尺寸的输入图像,通过金字塔形状的池化区域对不同大小的特征图进行整合和提取特征。其作用在于将不同大小的特征图转换成固定大小的特征向量,使得在连接全连接层之前,所有输入都具有相同的大小,无需提前处理图像。这种灵活性提高了网络的适用性和泛化能力,使得模型能够更灵活地处理各种尺寸的输入。
SPP(空间金字塔池化)的显著特点有:
固定大小的输出:无论输入尺寸如何,SPP能够产生固定大小的输出,克服了全连接层要求固定长度输入的限制。
多个窗口的池化:SPP采用多个窗口的池化,使其能够在不同尺度下提取特征。
尺度不变性和特征一致性:可以处理不同纵横比和尺寸的输入图像,增强了模型的尺度不变性,降低了过拟合的风险。
其他特点包括:
多样性训练图像对网络收敛更容易:SPP允许训练使用不同尺寸的图像,相较于单一尺寸的训练图像,这种多样性训练更有利于网络的收敛。
独立于特定网络设计和结构:SPP可用作卷积神经网络的最后一层,不会影响网络结构,仅替换了原本的池化层。
适用于图像分类和目标检测:SPP不仅适用于图像分类,还可用于目标检测等任务,扩展了其应用领域。
SPP的这些特点使得它成为一个强大的工具,在处理不同尺寸、不同纵横比的图像时,保持固定长度特征向量的输出,提高了模型的灵活性和泛化能力。
CLIP(Contrastive Language-Image Pretraining)是强大的AI多模态模型,由 OpenAI 提出,用于将自然语言与图像相联系。CLIP 的核心是一个双塔结构,分别包含一个文本编码器和一个图像编码器,通过对比学习(contrastive learning)训练,使图像和文本在共享的嵌入空间中具有相似的表示。
其中,Pooled Embedding 是 CLIP 提供的一种高效的语义特征表示方法,主要用于提取文本或图像的全局特征,广泛用于AI多模态任务和下游应用。
在 CLIP 中:
- 图像编码器(如 ViT 或 ResNet)将图像输入转化为一组 token 的嵌入表示。
- 文本编码器(如 Transformer)将文本输入转化为一组 token 的嵌入表示。
这些编码器通常生成序列化的输出,表示输入的各个部分。但在很多任务中,我们需要一个全局的语义特征,这就是 Pooled Embedding 的作用。
-
CLS Token([CLS] 标记):
- 在 Transformer 架构中(例如 BERT 或 CLIP 的文本编码器),通常会在输入前加入一个特殊的
[CLS]标记。 - 编码完成后,CLS 的嵌入被视为全局语义表征。
- CLIP 文本编码器会直接使用该 CLS Token 的嵌入作为文本的 Pooled Embedding。
- 在 Transformer 架构中(例如 BERT 或 CLIP 的文本编码器),通常会在输入前加入一个特殊的
-
Global Average Pooling(全局平均池化):
- 对于图像编码器(如 ViT 或 ResNet),CLIP 通常使用全局平均池化操作,将图像的每个 token 的嵌入取平均值,生成单一向量表示,作为图像的 Pooled Embedding。
Pooled Embedding 提供了输入(文本或图像)的全局语义信息,适合于需要整体语义理解的任务。
- 文本: 表示整段文字的语义。
- 图像: 表示整张图片的视觉语义。
CLIP 的训练目标是将相关的图像-文本对拉近,而将不相关的对拉远。
- 文本和图像分别通过其编码器生成 Pooled Embedding。
- 通过对比学习(Contrastive Loss),CLIP 在高维空间中优化,使图像和对应文本的 Pooled Embedding 尽可能接近。
Pooled Embedding 是许多下游任务的基础特征,常用于:
- 分类任务: 提取图像或文本的嵌入后,输入分类器。
- 检索任务: 用于图像到文本、文本到图像的检索匹配。
- 多模态任务: 如视觉问答(VQA)和视觉-文本生成,使用 Pooled Embedding 作为全局上下文。
Pooled Embedding 通过一个固定大小的向量(如 512 维)表示输入,能够大幅简化计算,适合后续的处理和存储。
假设图像编码器使用的是 ViT(Vision Transformer):
- 输入图像被分成固定大小的 patch。
- 每个 patch 转换为 token,输入到 Transformer。
- 输出的 token 是一个序列,其中包括了
[CLS]token。 - CLIP 使用 全局平均池化(Global Average Pooling) 对所有 token 取平均值,得到图像的 Pooled Embedding。
假设文本编码器使用的是 Transformer:
- 输入文本被分解为 token(如单词或子词)。
- 特殊的
[CLS]token 被添加到输入序列的开头。 - Transformer 输出序列的表示,其中
[CLS]token 的嵌入被用作文本的 Pooled Embedding。
通过 Pooled Embedding,可以实现图像与文本的相互检索:
- 将图像的 Pooled Embedding 与文本的 Pooled Embedding 在共享空间中匹配。
- 相似度较高的嵌入被认为是相关的。
- 提取图像的 Pooled Embedding,作为输入特征传递给分类器。
- 可用于物体分类、情感分析等任务。
- 在生成任务中(如文本生成、图像生成),Pooled Embedding 可以作为条件输入,指导生成过程。
- 使用文本 Pooled Embedding,快速进行语义相关内容的检索。
- 如基于文本描述搜索图像。
- 简洁高效:Pooled Embedding 是固定大小的向量,便于存储和后续计算。
- 语义丰富:对输入的全局语义有良好概括。
- 适用广泛:适合检索、分类等多种任务。
- 上下文丢失:对于复杂输入,可能丢失部分局部细节。
- 固定长度限制:特征向量维度固定,可能不足以表达某些复杂场景的全部信息。
AI模型的池化层(Pooling Layer)不包含可学习的参数。
池化层的主要功能是对输入特征图进行下采样,减小特征图的尺寸,降低计算复杂度,同时保留重要的特征信息。常见的池化操作包括:
- 最大池化(Max Pooling):取池化窗口中的最大值。
- 平均池化(Average Pooling):计算池化窗口中的平均值。
-
池化层没有权重或偏置参数:
- 与卷积层或全连接层不同,池化层的操作只是固定规则的计算(如取最大值或平均值),不需要学习任何权重或偏置。
- 例如:
- 最大池化:在窗口内取最大值,不涉及任何可学习的参数。
- 平均池化:在窗口内取平均值,同样不需要参数。
-
仅依赖于池化窗口大小和步幅:
- 池化层的行为由超参数决定,如:
-
池化窗口大小(如
$2 \times 2$ ) - 步幅(Stride):窗口移动的步长
-
池化窗口大小(如
- 这些超参数是固定的,不需要通过训练学习。
- 池化层的行为由超参数决定,如:
| 层类型 | 是否包含参数 | 说明 |
|---|---|---|
| 卷积层(Conv) | ✅ 是 | 权重(Kernel)和偏置(Bias) |
| 全连接层(FC) | ✅ 是 | 权重矩阵和偏置向量 |
| 最大池化层(Max Pooling) | ❌ 否 | 固定规则:取最大值 |
| 平均池化层(Avg Pooling) | ❌ 否 | 固定规则:取平均值 |
| Dropout 层 | ❌ 否 | 用于随机丢弃神经元,无参数 |
| 批归一化(BatchNorm) | ✅ 是 | 包含可学习的缩放和平移参数 |
答案:全局平均池化的优势主要体现在: 减少参数数量:相比全连接层,GAP 将整个特征图直接平均为一个值,避免了大量参数的连接,大大减少了模型的参数量,降低了计算成本。 防止过拟合:参数数量的减少降低了模型复杂度,从而有效防止过拟合现象的发生。 增强可解释性:GAP 将每个类别对应的特征图进行全局平均,输出直接对应每个类别,使网络结构更具可解释性 。
答案:池化层的步长决定了池化窗口在输入特征图上移动的距离。当步长增大时,池化窗口在特征图上的覆盖范围更稀疏,输出特征图的尺寸会更小,下采样的程度更大,信息压缩更为明显;当步长减小时,池化窗口的覆盖范围更密集,输出特征图的尺寸相对较大,保留的信息更多。但如果步长过小,可能无法有效降低计算量和防止过拟合。
答案:池化层的平移不变性是指输入数据在空间位置上发生小幅度平移时,池化后的输出结果基本保持不变。例如,在图像识别中,对于一个包含猫的图像,即使猫在图像中的位置稍微向左或向右移动,经过最大池化后,猫的关键特征(如眼睛、耳朵等)仍然会被保留,且池化后的特征图在数值和结构上不会有显著变化。这使得模型在识别图像时,不会因为物体位置的微小变化而产生误判,增强了模型的鲁棒性。
答案:如果池化窗口大小大于步长,会导致池化窗口在输入特征图上有重叠部分。这意味着部分区域会被多次计算和池化,输出特征图会保留更多的信息,相对地,下采样的程度会减弱。这种设置在一些需要保留更多细节信息的任务中可能会被采用,但同时也会增加一定的计算量。
答案:选择合适的池化类型和参数需要考虑以下因素: 任务类型:对于图像分类等注重显著特征提取的任务,最大池化通常是较好的选择;对于需要考虑全局信息的任务,如场景分类,平均池化或全局平均池化可能更合适。 数据特点:如果数据噪声较多,平均池化可能有助于平滑噪声;对于包含大量细节信息的数据,较小的池化窗口和步长可以保留更多细节。 模型复杂度:如果希望降低模型复杂度,防止过拟合,可以适当增大池化窗口和步长,或者使用全局平均池化替代部分全连接层。此外,也可以通过实验对比不同池化设置下模型的性能指标(如准确率、损失值等),来确定最优的池化类型和参数 。
- 全连接层(fully connected layers,FC)在整个卷积神经网络中起到分类器模块的作用。在深度学习中,卷积层、池化层和激活函数层等操作将原始数据映射到隐层高维特征空间,全连接层则将这些学到的隐层高维特征映射到样本标签(label)空间中。在实际使用中,全连接层可由卷积操作实现:对前层是全连接的全连接层可以转化为卷积核为
$1\times1$ 的卷积;而前层是卷积层的全连接层可以转化为卷积核为$h\times w$ 的全局卷积,$h$ 和$w$ 分别为前层卷积结果的高和宽。
以VGG-16为例,对于224x224x3的输入,经过最后一层卷积的输出为7x7x512,如果后层是一个含4096个神经元的FC层,那么可用卷积核为7x7x512x4096的全局卷积来实现这一全连接运算过程,其中该卷积核参数如下:
“filter size = 7, padding = 0, stride = 1, D_in = 512, D_out = 4096”
经过此卷积操作后可得输出为1x1x4096的特征矩阵。如需再次叠加一个2048的FC层,则可设定参数如下的卷积层操作:
“filter size = 1, padding = 0, stride = 1, D_in = 4096, D_out = 2048”
-
由于全连接层参数存在冗余(仅全连接层参数就可占整个传统深度学习网络参数的80%左右)的情况,一些经典的传统深度学习模型(ResNet和GoogLeNet等)均用全局平均池化(global average pooling,GAP)层来取代FC层去融合模型学到的深度特征,后续再接softmax等损失函数作为传统深度学习模型的目标函数来指导训练过程。同时研究发现,用GAP层替代FC层的模型通常有较好的预测性能。
-
学术界研究发现FC层可在模型表示能力的迁移过程中充当“防火墙”的作用。具体来讲,假设在ImageNet上预训练得到的模型为
$\mathcal{M}$ ,则ImageNet可视为源域(迁移学习中的source domain)。微调(fine tuning)是深度学习领域最常用的迁移学习技术。针对模型的微调过程,如果目标域(target domain)中的图像与源域中图像差异巨大(假设相比ImageNet,目标域图像不是物体为中心的图像,而是智慧城市场景数据),不含FC层的网络微调后的结果要差于含FC层的网络。因此FC层可视作模型表达能力的“防火墙”,特别是在源域与目标域差异较大的情况下,FC层可保持较大的模型capacity从而保证模型表达能力的迁移,这是FC层冗余参数带来的优势。 -
在Transformers中,FC层重新繁荣,成为了Transformers架构模型的标配,成为AI领域中不可获取的关键部分。正是因为FC层能够保持大模型的capacity能力,如果没有全连接层,Self-Attention层输出的只有一些线性表达特征,表达能力有限,而全连接层可以自己学习复杂的特征表达。
多层感知器(Multilayer Perceptron, MLP)可以说是最基本的神经网络,由Frank Rosenblatt于1957提出,一直广泛应用于各种机器学习和深度学习任务中。
在传统深度学习时代,由于卷积神经网络的出现,一定程度上MLP网络的使用频率有所减少,但是在Transformer发布后,MLP结构重新站上AI行业的舞台。在现在的AIGC时代中,MLP结构已经成为AIGC模型的重要组成部分。
下面是Rocky对MLP网络的详细讲解:
MLP由一个输入层、一个或多个隐藏层和一个输出层组成。每一层都包含多个神经元(或节点),这些神经元之间是全连接的,即每个神经元的输出连接到下一层的每个神经元。
输入层的神经元数等于输入数据的特征数。如果输入是一个包含28x28像素的图像,则输入层的神经元数为784。
隐藏层由一个或多个层组成,每层包含若干个神经元。隐藏层的数量和每层的神经元数是超参数,我们可以根据不同的场景进行对应的设置。隐藏层通过激活函数(如ReLU、Sigmoid、Tanh等)引入非线性,使得MLP能够学习复杂的分布和特征。
输出层的神经元数取决于具体的AI任务。例如,对于二分类任务,输出层通常包含一个神经元;对于多分类任务,输出层的神经元数等于类别数。

MLP的工作原理基于前向传播和反向传播两个过程。
在前向传播过程中,输入数据通过网络层层传递,经过每一层的加权和激活函数计算,最终得到输出结果。具体步骤如下:
- 加权求和:每个神经元接收前一层的输出,通过权重进行加权求和,并加上一个偏置项。
其中,
- 激活函数:对加权求和的结果应用激活函数,引入非线性。
其中,
- 输出:将激活函数的输出传递给下一层,直到最后一层得到最终输出。
在反向传播过程中,网络通过计算损失函数的梯度来更新权重和偏置项,以最小化预测误差。具体步骤如下:
- 损失函数:计算网络的输出与实际标签之间的损失。常见的损失函数包括均方误差(MSE)和交叉熵损失。
其中,
- 梯度计算:通过链式法则计算每个权重和偏置项的梯度。
- 权重更新:使用梯度下降算法更新权重和偏置项。
其中,
全连接层(Fully Connected Layer,FC)是神经网络的核心组件之一,其每个输入节点与输出节点均相连,擅长捕捉全局特征。然而,传统全连接层存在参数过多、计算量大、易过拟合等问题,因此衍生出多种变体以适配不同任务需求。以下是主要变体及其应用场景:
- 原理:通过剪枝或稀疏约束(如L1正则化)减少有效连接数,仅保留关键权重。
- 案例:
- 图像分类:在ResNet中,对最后一层全连接进行剪枝,参数减少30%,精度损失<1%。
- 应用领域:
- 传统深度学习:压缩模型大小,提升部署效率(如移动端图像分类)。
- 自动驾驶:轻量化多任务感知模型(如车道线检测+目标检测)。
- 原理:根据输入动态调整权重,例如通过门控机制或条件计算。
- 案例:
- 多语言翻译:动态调整不同语言对的翻译权重,提升小语种性能(如Meta的M2M-100模型)。
- 应用领域:
- AIGC:生成多样化风格内容(如根据文本提示动态调整生成网络参数)。
- 自动驾驶:动态融合多传感器数据(如雨天增强激光雷达权重)。
- 原理:将输入/输出节点分组,组内全连接,组间隔离,减少参数量(类似分组卷积)。
- 案例:
- 推荐系统:用户兴趣分组(如性别、年龄),每组独立建模(如阿里的Deep Interest Network)。
- 应用领域:
- 传统深度学习:处理高维稀疏数据(如广告点击率预测)。
- AIGC:多模态生成(如文本、图像分组处理后再融合)。
-
原理:将权重矩阵分解为两个低秩矩阵(如
$W=U \cdot V$ ),减少参数量。 -
案例:
- 语音识别:在RNN-T模型中,低秩分解全连接层参数减少50%,推理速度提升20%。
-
应用领域:
- AIGC:轻量化生成模型(如手机端Stable Diffusion)。
- 自动驾驶:实时语义分割模型压缩。
- 原理:引入注意力机制,动态加权输入特征。
- 案例:
- 机器翻译:在Transformer解码器中,全连接层结合自注意力,提升长距离依赖建模(如Google的T5模型)。
- 应用领域:
- AIGC:生成连贯长文本(如小说续写)。
- 自动驾驶:时序行为预测(如行人轨迹预测)。
- 原理:权重或激活值二值化(+1/-1),减少计算资源。
- 案例:
- 边缘设备图像分类:二值化ResNet-18在CIFAR-10上精度保持85%,功耗降低70%。
- 应用领域:
- 自动驾驶:低功耗车载芯片实时推理。
- 传统深度学习:物联网设备端模型部署。
-
原理:引入残差连接(
$y = F(x) + x$ ),缓解梯度消失。 -
案例:
- 图像超分辨率:残差全连接层堆叠,提升高频细节恢复能力(如ESRGAN)。
-
应用领域:
- AIGC:高分辨率图像生成(如4K人脸合成)。
- 自动驾驶:高精度地图重建。
- 原理:通过门控机制(如Sigmoid)控制信息流动。
- 案例:
- 语音合成:门控全连接层调节音素与韵律特征(如WaveNet)。
- 应用领域:
- AIGC:多风格语音生成(如情感化TTS)。
- 自动驾驶:多模态信号融合(如语音指令+视觉导航)。
全连接层的变体通过参数优化、动态计算、结构创新等方式,解决了传统FC层的局限性,广泛应用于以下场景:
- AIGC:动态生成、轻量化部署;
- 传统深度学习:模型压缩、多任务学习;
- 自动驾驶:实时推理、多模态融合。