- 1.标准化/归一化(Normalization)
- 2.图像数据预处理方法总结
- 3.Mixup
- 4.CutMix和Cutout
- 5.Mosaic
- 6.Copy-Paste
- 7.AutoAugment
- 8.RandAugment
- 9.不同模态的数据如何进行Token化操作?
- 10.介绍一下深度学习中张量的概念
- 11.数据标准化和归一化的区别是什么,分别适用于什么场景?
- 12.如何处理数据集中的缺失值,分别列举数值型和分类型数据的处理方法
- 13.简述图像数据增强的常用方法。
- 14.对于时间序列数据,如何进行数据预处理以适应深度学习模型?
- 15.什么是独热编码(One-Hot-Encoding),它的优缺点是什么?
- 16.在处理文本数据时,词袋模型(Bag-of-Words)和词嵌入(Word Embedding)有什么区别?
- 17.如何处理数据集中的不平衡问题,列举至少三种方法。
- 18.数据预处理中的特征选择有什么作用,常用的特征选择方法有哪些?
- 19.对于高维数据,如何进行降维处理,简述主成分分析(PCA)的原理。
待补充。。。
待补充。。。
在深度学习中,数据预处理是非常重要的,它能够帮助模型更好地学习特征并提高模型的性能。是深度学习模型训练中很关键的一部分。以下是一些常见的深度学习数据预处理方法:
数据标准化是一个常用的数据预处理操作,目的是处理不同规模和量纲的数据,使其缩放到相同的数据区间和范围,以减少规模、特征、分布差异等对模型的影响。 将数据按特征进行缩放,使其均值为0,方差为1,有助于加速模型收敛并提高模型性能。

描述:将数据映射到指定的范围,如:把数据映射到0~1或-1~1的范围之内处理。)
计算公式为:

作用: 1、数据映射到指定的范围内进行处理,更加便捷快速。2、把有量纲表达式变成无量纲表达式,便于不同单位或量级的指标能够进行比较和加权。经过归一化后,将有量纲的数据集变成纯量,还可以达到简化计算的作用。
【注意】:不要“中心化”稀疏数据!
在稀疏特征上执行min-max缩放和标准化时一定要慎重,它们都会从原始特征值中减去一个量。对于min-max缩放,这个平移量是当前特征所有值中的最小值;对于标准化,这个量是均值。如果平移量不是0,那么这两种变换会将一个多数元素为0的稀疏特征向量变成密集特征向量。根据实现方式的不同,这种改变会给分类器带来巨大的计算负担。
数据标准化方法多种多样,主要分为直线型方法(如极值法、标准差法)、折线型方法(如三折线法)、曲线型方法(如半正态性分布)。不同的标准化方法,对系统的评价结果会产生不同的影响。每种方法对系统评价结果的影响各不相同。
在这些方法中,Z-Score 标准化是应用最广泛的一种。该方法将数据转换为均值为0、标准差为1的标准正态分布,使得数据分布更符合统计学上的正态分布特性。不同的标准化方法选择可以根据数据分布、预期效果以及具体问题的需要来进行,因为不同的方法可能会对评价结果产生不同的影响。
计算公式: 其中 x 是原始数据,μ 是均值,σ 是标准差。
其中 x 是原始数据,μ 是均值,σ 是标准差。
作用:
1、提升模型的收敛速度(加快梯度下降的求解速度)
2、提升模型的精度(消除量级和量纲的影响)
3、简化计算(与归一化的简化原理相同)
归一化/标准化实质是一种线性变换,线性变换有很多良好的性质,这些性质决定了对数据改变后不会造成“失效”,反而能提高数据的表现,这些性质是归一化/标准化的前提。比如有一个很重要的性质:线性变换不会改变原始数据的数值排序。
1、数据的分布本身就服从正态分布,使用Z-Score。 2、有离群值的情况:使用Z-Score。 这里不是说有离群值时使用Z-Score不受影响,而是,Min-Max对于离群值十分敏感,因为离群值的出现,会影响数据中max或min值,从而使Min-Max的效果很差。相比之下,虽然使用Z-Score计算方差和均值的时候仍然会受到离群值的影响,但是相比于Min-Max法,影响会小一点。
当数据中有离群点时,我们可以使用Z-Score进行标准化,但是标准化后的数据并不理想,因为异常点的特征往往在标准化后容易失去离群特征,此时就可以用RobustScaler 针对离群点做标准化处理。
Robust即鲁棒性,健壮性 训练模型时向算法内添加噪声(如对抗训练),以便测试算法的「鲁棒性」。可以将此处的鲁棒性理解述算法对数据变化的容忍度有多高。鲁棒性并不同于稳定性,稳定性通常意味着「特性随时间不变化的能力」,鲁棒性则常被用来描述可以面对复杂适应系统的能力,需要更全面的对系统进行考虑。 即使用中位数和四分位数范围进行缩放,能够更好地处理异常值的影响。
图像数据的预处理包括裁剪、缩放、旋转、翻转等操作,以及色彩空间转换(如灰度化、彩色通道变换等),有助于增强模型的鲁棒性和泛化能力。
在训练过程中,通过对原始数据进行随机变换、旋转、平移、缩放、翻转、随机色调(H)、饱和度(S)、明度(V)调整、等操作,生成新的训练样本,扩充数据集,有助于减少过拟合,提高模型泛化能力。 缺失值处理:
处理数据中的缺失值,常见方法包括删除缺失值、填充缺失值(均值、中位数、众数填充等)、插值填充等。
根据特征的相关性、重要性等进行特征选择,排除不重要或冗余的特征,提高模型效率并减少过拟合的风险。
独热编码可以将分类变量转换为二进制变量从而被深度学习模型进行有效处理,适用于某些机器学习模型和深度学习模型的输入。 于每一个特征,如果它有m个可能值,那么经过独热编码后,就变成了m个二元特征.并且,这些特征互斥,每次只有一个激活.因此,数据会变成稀疏的.
稀疏数据相比密集数据而言,对于计算机加载处理也更为有优势. 这样做的好处主要有:
解决了分类器不好处理属性数据的问题
在一定程度上也起到了扩充特征的作用
当数据集中的类别分布不平衡时,模型可能倾向于偏向数量较多的类别,导致对于少数类别的识别或预测性能较差。可以考虑用以下方法来降低数据类别不平衡产生的影响:
- 过采样: 通过复制少数类别样本或生成合成样本来增加少数类别的样本数量。常见的过采样方法包括随机过采样(从少数类别中随机选择样本,之后复制多次来达到与多数类别的样本量的平衡,其中复制的次数选择不当有可能引入过拟合问题)、SMOTE方法(在少数类别样本中进行插值来生成新的合成样本,但是该方法可能会引入一定程度的噪声)
- 欠采样: 通过减少多数类别样本的数量来平衡类别分布。但是删除样本会导致丢失一些信息。
- 集成方法:集成方法可以用来处理不平衡数据、提高模型的泛化能力以及增强预测的稳定性。Voting和Stacking是两种常见的集成方法。
- 类别权重:通过给予少数类别更高的权重,可以在模型训练中引入偏重,以平衡不同类别的重要性。这样可以使模型更加关注少数类别的样本,从而提高对少数类别的分类性能。
- 特征工程:根据领域知识或数据特点,设计并生成与少数类别相关的新特征。这些特征可以帮助模型更好地区分不同类别,提高少数类别的分类性能。
- 阈值调整:调整分类器的预测阈值,使得模型更倾向于少数类别。通常,降低阈值可以增加对少数类别的预测,但同时也可能增加误分类率。 需要注意的是:处理不平衡数据时,需要在训练集和测试集上保持类别分布的一致性,以确保模型在真实场景中的性能。
对于时间序列数据或文本数据,常见的预处理方法包括分词、词嵌入、标记化、截断、填充等操作。 这些预处理方法通常根据具体的数据类型和问题领域进行选择和组合,以提高模型的性能、鲁棒性和泛化能力。
这是一种使用广泛的数据降维算法,是一种无监督学习方法,主要是用来将特征的主要分成找出,并去掉基本无关的成分,从而达到降维的目的。
总结一下PCA的算法步骤: 设有n条m维数据。
将原始数据按列组成m行n列矩阵X
将X的每一行(代表一个属性字段)进行零均值化
求出协方差矩阵
求出协方差矩阵的特征值及对应的特征向量
将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P
Y=P×X即为降维到k维后的数据
就是把各个特征轴上的数据除以对应特征值,从而达到在每个特征轴上都归一化幅度的结果。也就是在PCA的基础上再除以每一个特征的标准差,以使其normalization,其标准差就是奇异值的平方根:Xwhite = Xrot / np.sqrt(S + 1e-5)
但是白化因为将数据都处理到同一个范围内了,所以如果原始数据有原本影响不大的噪声,它原本小幅的噪声也会放大到与全局相同的范围内了。 另外我们为了防止出现除以0的情况在分母处多加了0.00001,如果增大他会使噪声减小。 白化之后得到是一个多元高斯分布,如下图whitened所示:
注意事项:
以上只是总结数据预处理的方法而已,并不是说每次都会用这么多方法,相反,在图像数据处理或者CNN中,一般只需要进行去均值和归一化,不需要PCA和白化
常见陷阱:在进行数据的预处理时(比如计算数据均值),我们只能在训练数据上进行,然后应用到验证/测试数据上。如果我们对整个数据集-整个数据集的均值,然后再进行训练/验证/测试数据的分割的话,这样是不对的。正确做法是计算训练数据的均值,然后分别把它从训练/验证/测试数据中减去。
论文链接:https://arxiv.org/pdf/1710.09412.pdf
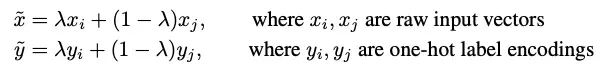

mixup的效果如上图所示。
实现方法:随机选择两个训练样本的向量,以及其对应的label,使用线性插值的方法生成一个新的向量和对应的label,作为增强的数据。
用在图像分类中就是将随机的两张样本按比例混合,分类的结果按比例分配。
论文链接:CutMix https://arxiv.org/pdf/1905.04899v2.pdf
Cutout https://arxiv.org/pdf/1708.04552.pdf
cutmix的公式如下:

第一条式子是图像结合,第二条式子是标签结合。

cutmix和cutout的效果如上图所示。
实现方法:
Cutout:随机的将样本中的部分区域cut掉,并且填充0像素值,分类的结果不变;
CutMix:直接在图像的像素级别对两个样本进行混合。对于一个图像随机选择一个要mask的区域,使用另一个图像对应的区域进行填充,得到一个新的输入图片。
论文链接:https://arxiv.org/pdf/2004.10934.pdf(YOLOv4提出的数据增强方法)

Mosaic实现效果如上图所示。
实现方法:Mosaic将4张不同的训练图像混合成一张大的合成图像。这4张图像通常被随机选取,每张图像的位置和尺寸也可能会随机变化。这种混合过程包括将4张图像拼接在一起,通常以某种方式重叠,从而创建一个大的合成图像。
论文链接:https://arxiv.org/pdf/2012.07177.pdf

copy-paste的效果如上图所示。
实现方法:随机选择两张图像并对它们进行尺度扭曲和水平翻转,然后从其中一张图像中选择一组随机对象并将它们粘贴到另一张图像上。
论文链接:https://arxiv.org/pdf/1805.09501.pdf
AutoAugment定义了一个包含16种图像处理操作以及相关超参数的数据增强搜索空间,将数据增强策略表示为多个子策略的序列,每个子策略包含两种随机选择的操作及其应用概率和幅度;然后使用强化学习在该搜索空间中搜索能最大化模型在验证集上准确率的最优策略序列,并将其应用于训练数据进行增强

autoaugment效果如上图所示。
论文链接:https://arxiv.org/pdf/1909.13719.pdf
RandAugment方法的主要步骤如下:
- 设定一个操作集,例如14种操作。
- RandAugment只需要两个参数:N和M。其中N表示每次增强时使用的操作次数,每次随机从操作集中选择操作,并将其应用到图像上。M表示所有操作的幅度都相同。
- 使用网格搜索或其他方法,在完整数据集和网络上实验,找到最适合的N和M值。这样一来,搜索空间大幅缩减,简化了超参数选择的过程。
通过调整N和M的值,可以控制训练时的正则化强度。较大的N和M值意味着更强的正则化效果。


randaugment效果如上图所示。
RandAugment通过随机应用一系列预定义的图像增强操作(如旋转、缩放、翻转、颜色变换等),来生成多样化的训练数据。该方法无需搜索最佳策略,简化了增强流程。
在AI行业中,不同模态的数据(如文本、图像、音频、视频、表格等)通常需要经过Token化操作,将数据转换为模型能够处理的标准化表示形式。这种操作的目标是将输入数据转化为一系列离散的表示(Token),便于输入到 Transformer 或其他AI网络结构中进行处理。
在AIGC、传统深度学习以及自动驾驶领域中,不同模态的数据具有各自的特性,Token 化需要针对性设计:
- 文本:BPE 和子词级 Token 化是主流。
- 图像:Patch Token 化和 VQ-VAE 被广泛应用。
- 音频:频谱图和帧级特征是常见方法。
- 视频:空间时间 Patch 和 CNN+RNN 是主流方案。
- 多模态融合:通过独立 Token 化和跨模态注意力机制实现。
下面Rocky详细讲解常见模态的数据及其 Token 化方法:
文本数据的 Token 化是最成熟的领域之一,方法包括:
- 方法:
- 将文本拆分为单词,通常通过空格分割。
- 每个单词分配一个唯一的索引。
- 优点:
- 简单易用,训练和推理速度较快。
- 缺点:
- 词表较大(尤其对多语言),无法处理未登录词(OOV)。
- 示例:
text = "Deep learning is amazing!" tokens = ["Deep", "learning", "is", "amazing", "!"]
- 方法:
- 使用 BPE(Byte Pair Encoding)、WordPiece、Unigram 等算法,将文本拆分为子词单元。
- 优点:
- 词表大小可控,能够高效处理未登录词。
- 应用:
- GPT 使用 BPE,BERT 使用 WordPiece。
- 示例:
text = "unbelievable" tokens = ["un", "##believ", "##able"]
- 方法:
- 将文本按字符拆分,每个字符作为一个 Token。
- 优点:
- 无需复杂的预处理,天然支持多语言。
- 缺点:
- 序列长度较长,效率较低。
- 示例:
text = "Hello" tokens = ["H", "e", "l", "l", "o"]
- 方法:
- 将文本按字节级拆分。
- 优点:
- 高效支持任意字符集。
- 应用:
- OpenAI 的 CLIP 和 GPT 使用字节级 BPE。
- 示例:
text = "你好" tokens = [206, 149, 206, 189]
对于图像数据,Token 化需要将二维的像素阵列转换为一维 Token 序列:
- 方法:
- 将图像分割为固定大小的 Patch,每个 Patch 被展平为向量。
- 对每个 Patch 使用线性变换将其映射到 Token 表示空间。
- 优点:
- 高效,将图像处理问题转化为序列问题。
- 应用:
- ViT(Vision Transformer)、CLIP。
- 示例:
- 输入图像大小 (224 \times 224 ),Patch 大小 (16 \times 16),输出序列长度 ( (224/16)^2 = 196 )。
patches = image_to_patches(image, patch_size=16) # 分割为 16x16 的 Patch tokens = linear_projection(patches) # 线性变换
- 方法:
- 使用 CNN 提取特征图,每个特征点作为一个 Token。
- 优点:
- 适合与 Transformer 结合的场景。
- 示例:
feature_map = cnn_model(image) # 输出特征图 (H, W, C) tokens = feature_map.reshape(-1, feature_map.shape[-1]) # 转换为序列
- 方法:
- 使用 VQ-VAE 将图像压缩到离散的 Token 表示。
- 优点:
- 适合生成任务,如 DALL-E。
- 示例:
quantized_tokens = vq_vae(image)
音频数据通常是连续的波形信号,需要离散化处理:
- 方法:
- 将音频信号转换为频谱图,类似于图像。
- 使用 Patch 或 CNN 方法进行 Token 化。
- 示例:
spectrogram = waveform_to_spectrogram(audio) # 转为频谱图 tokens = image_to_patches(spectrogram, patch_size=16)
- 方法:
- 使用 VQ-VAE 将音频频谱图压缩为离散的 Token。
- 应用:
- AudioLM、Jukebox。
- 示例:
quantized_tokens = vq_vae(audio)
- 方法:
- 将音频分割为固定长度的帧(如 20 ms)。
- 每帧使用特征提取器(如 MFCC、Mel 特征)。
- 示例:
frames = audio_to_frames(audio, frame_size=20) tokens = [mfcc(frame) for frame in frames]
视频数据的 Token 化通常需要同时考虑时间和空间维度:
- 方法:
- 对每一帧应用 Patch Token 化,将其展平为序列。
- 在时间维度上叠加帧序列。
- 应用:
- Video Transformer。
- 示例:
video_patches = [image_to_patches(frame, patch_size=16) for frame in video] tokens = concatenate(video_patches, axis=0)
- 方法:
- 使用 CNN 提取每帧的特征,RNN 聚合时间信息。
- 示例:
frame_features = [cnn_model(frame) for frame in video] tokens = rnn_model(frame_features)
表格数据的 Token 化主要考虑行、列和单元格:
- 方法:
- 将每个单元格作为一个 Token,可能需要处理数值和文本的混合数据。
- 示例:
tokens = [tokenize(cell) for row in table for cell in row]
- 方法:
- 将每列的值序列化,并作为一组 Token。
- 示例:
tokens = [tokenize(column) for column in table.T]
当需要同时处理多模态数据时(如 CLIP),需要对各模态的数据进行独立 Token 化后再融合:
- 文本:使用文本 Token 化(如 BPE)。
- 图像:使用 Patch Token 化。
- 最终通过共享的 Transformer 模型对 Token 进行处理。
- 使用跨模态的注意力机制(Cross-Attention)来融合不同模态的 Token。
- 示例:
text_tokens = text_tokenizer(text) image_tokens = image_tokenizer(image) fused_tokens = cross_attention([text_tokens, image_tokens])
在深度学习中,张量 (Tensor) 是一个核心概念,它本质上是一个多维数组,用于表示AI模型中的数据、权重和各种操作结果。张量在深度学习框架(如 TensorFlow 和 PyTorch)中是主要的数据结构,所有计算都围绕它展开。
从深度学习的角度,张量是一个带有维度信息的多维数组。它可以用于存储和处理标量、向量、矩阵以及更高维数据。
-
标量 (0 阶张量): 一个单一的数值。
例如:$3.14, -5, 42$
在深度学习中,用于表示模型中的单一值,例如损失函数的输出。 -
向量 (1 阶张量): 一维数组。
例如:$[1.0, 2.0, 3.0]$ 或$[x_1, x_2, x_3]$
用于表示一个数据样本的特征或模型参数。 -
矩阵 (2 阶张量): 二维数组。
例如:$$\begin{bmatrix} 1&2\ 3&4\ \end{bmatrix}$$
用于表示数据批次、图像通道或网络层的权重。
-
高阶张量 (3 阶及以上张量): 多维数组。
例如:一个三维张量可以是形状为$(2, 3, 4)$ 的数组。
在深度学习中常见于表示批量数据、图像或序列数据。
-
秩 (Rank):
- 张量的维度数。
- 0 阶:标量
- 1 阶:向量
- 2 阶:矩阵
-
$n$ 阶:高阶张量
- 张量的维度数。
-
形状 (Shape):
- 张量每一维的大小,表示为元组形式。例如:
- 向量的形状为
$(3,)$ - 矩阵的形状为
$(2, 3)$ - 三维张量的形状为
$(32, 28, 28)$ (例如批量大小为 32 的 28x28 灰度图像)。
- 向量的形状为
- 张量每一维的大小,表示为元组形式。例如:
-
数据类型 (Dtype):
- 张量中的元素通常具有特定的数据类型,例如:
- 浮点数:
float32,float64 - 整数:
int32,int64 - 布尔值:
bool
- 浮点数:
- 张量中的元素通常具有特定的数据类型,例如:
-
存储:
- 张量的数据可以存储在 CPU 或 GPU 上。
- 深度学习框架提供了灵活的张量存储和分配机制。
-
结构化数据: 使用二维张量表示特征矩阵,形状为
$(\text{批量大小}, \text{特征数})$ 。
例如:用二维张量表示 100 个样本,每个样本有 10 个特征:$(100, 10)$ 。 -
图像数据: 使用四维张量表示,形状为
$(\text{批量大小}, \text{高度}, \text{宽度}, \text{通道数})$ 。
例如,32 张$28 \times 28$ 的灰度图像:$(32, 28, 28, 1)$ 。 -
序列数据: 使用三维张量表示,形状为
$(\text{批量大小}, \text{序列长度}, \text{特征数})$ 。
例如,处理自然语言文本时,可以用形状为$(64, 100, 300)$ 的张量,表示 64 个样本,每个样本有 100 个单词,每个单词被编码为 300 维向量。
- 深度学习模型的权重和偏置通常用张量表示。例如:
- 全连接层权重:二维张量,形状为
$(\text{输入维度}, \text{输出维度})$ 。 - 卷积层的滤波器:四维张量,形状为
$(\text{滤波器数}, \text{高度}, \text{宽度}, \text{通道数})$ 。
- 全连接层权重:二维张量,形状为
- 神经网络中每一层的输出通常是张量。
- 损失函数、梯度、优化步骤也涉及大量张量操作。
深度学习框架提供了大量针对张量的操作,包括但不限于:
- 加法、减法、乘法、除法: 元素级操作。
- 点积 (Dot Product): 用于向量或矩阵间的操作。
- 矩阵乘法 (Matrix Multiplication): 用于网络层计算。
- 重塑 (Reshape): 改变张量的形状。
- 转置 (Transpose): 调换张量的维度顺序。
- 扩展 (Broadcasting): 自动调整维度以进行兼容计算。
- 求逆、特征值分解、奇异值分解 (SVD): 用于更复杂的模型和研究。
- 规范化 (Normalization): 对张量数据进行标准化处理。
- 卷积 (Convolution): 处理图像数据的核心操作。
- 池化 (Pooling): 用于下采样张量数据。
- 激活函数 (Activation Functions): 作用在张量上以引入非线性。
数据标准化是将数据按比例缩放,使之落入一个小的特定区间,通常是将数据转换为均值为 0,标准差为 1 的分布,归一化则是将数据缩放到 [0, 1] 区间。 标准化适用于数据分布近似正态分布,并且模型对数据尺度敏感的场景,比如线性回归、逻辑回归、支持向量机等。归一化适用于数据分布未知,或者需要将数据压缩到一个固定区间的场景,例如在神经网络中,输入层的数据进行归一化可以加快模型收敛速度。
- 删除法:如果缺失值占比非常小,可以直接删除包含缺失值的样本。
- 填充法:使用均值、中位数或众数进行填充。例如,对于正态分布的数据,使用均值填充;对于有偏态分布的数据,使用中位数填充。
- 模型预测法:利用其他特征建立模型来预测缺失值,比如线性回归、决策树等。
- 删除法:同样在缺失值占比小的情况下可以直接删除对应样本。
- 填充法:使用众数进行填充,即出现频率最高的类别。
- 增加类别:将缺失值作为一个新的类别进行处理。
- 几何变换:包括翻转(水平翻转、垂直翻转)、旋转(任意角度旋转)、缩放(放大或缩小)、平移(上下左右移动)等,这些操作可以增加图像的多样性。
- 颜色变换:调整亮度、对比度、饱和度、色调等,模拟不同光照条件下的图像。
- 裁剪:随机裁剪图像的一部分,保留图像的局部特征。
- 噪声添加:向图像中添加高斯噪声、椒盐噪声等,提高模型对噪声的鲁棒性。
- 缺失值处理:可以使用插值法(如线性插值、样条插值)填充缺失值,或者使用前一个或后一个时间步的值进行填充。
- 归一化或标准化:将时间序列数据缩放到合适的范围,例如使用 Min - Max 归一化将数据缩放到 [0, 1] 区间,或者使用 Z - Score 标准化将数据转换为均值为 0,标准差为 1 的分布。
- 序列划分:将时间序列数据划分为输入序列和目标序列,通常采用滑动窗口的方法。
- 特征提取:提取时间序列的统计特征(如均值、方差、最大值、最小值等),或者使用傅里叶变换、小波变换等方法提取频域特征。
独热编码是将分类型变量转换为二进制向量的一种编码方式。对于一个具有 (n) 个不同类别的特征,会创建 (n) 个二进制特征,每个类别对应一个二进制特征,只有该类别对应的二进制特征为 1,其余为 0。
- 可以处理分类型数据,使模型能够直接处理这些数据。
- 不会引入额外的顺序信息,避免了对分类型数据错误的量化。
- 会增加数据的维度,导致维度灾难,尤其是当类别数量较多时。
- 可能会导致数据稀疏,增加计算量和存储成本。
词袋模型是一种简单的文本表示方法,它将文本看作是一个无序的词汇集合,忽略了词汇的顺序和语法结构。每个文本被表示为一个向量,向量的每个维度对应一个词汇,向量的值表示该词汇在文本中出现的频率。
词嵌入是将词汇映射到一个低维的连续向量空间中,使得语义相似的词汇在向量空间中距离较近。常见的词嵌入方法有 Word2Vec、GloVe 等。
词袋模型的优点是简单易实现,但它忽略了词汇的语义信息,并且向量维度通常很高。词嵌入能够捕捉词汇的语义信息,降低了向量维度,提高了模型的性能,但训练词嵌入模型需要大量的文本数据。
- 过采样:增加少数类样本的数量,常见的方法有随机过采样(简单复制少数类样本)和 SMOTE(Synthetic Minority Over - sampling Technique),SMOTE 通过在少数类样本之间进行插值来生成新的样本。
- 欠采样:减少多数类样本的数量,如随机欠采样(随机删除多数类样本),但这种方法可能会丢失一些重要信息。
- 调整模型权重:在模型训练时,对少数类样本赋予更高的权重,使得模型更加关注少数类样本的分类错误。
- 集成方法:使用多个分类器进行集成,每个分类器在不同的子集上进行训练,最后综合各个分类器的结果。
特征选择的作用是从原始特征中选择出最具有代表性和区分性的特征,减少特征的数量,从而降低模型的复杂度,提高模型的训练速度和泛化能力,同时避免过拟合问题。
常用的特征选择方法有:
- 过滤法:基于特征的统计特性进行选择,如方差分析(选择方差较大的特征)、相关性分析(选择与目标变量相关性较高的特征)。
- 包装法:将特征选择看作一个搜索问题,使用某种机器学习模型作为评估函数,通过不断尝试不同的特征子集来找到最优的特征子集,如递归特征消除(RFE)。
- 嵌入法:在模型训练过程中自动进行特征选择,如 Lasso 回归,它可以通过引入 L1 正则化项,使得一些特征的系数为 0,从而实现特征选择。
对于高维数据,可以使用以下降维方法:
- 主成分分析(PCA):通过线性变换将原始数据投影到一个新的低维空间中,使得投影后的数据方差最大化。
- 线性判别分析(LDA):寻找一个投影方向,使得不同类别的数据在投影后尽可能分开,同一类别的数据在投影后尽可能聚集。
- t - SNE:一种非线性降维方法,它能够较好地保留数据的局部结构,常用于可视化高维数据。
主成分分析(PCA)的原理是:首先计算数据的协方差矩阵,然后对协方差矩阵进行特征值分解,得到特征值和特征向量。特征向量表示数据的主成分方向,特征值表示主成分的方差大小。选择前 (k) 个最大特征值对应的特征向量,将原始数据投影到这些特征向量构成的低维空间中,从而实现降维。