Qwen-Vl ~ Qwen2.5VL
1、Qwen-VL系列视觉编码器的核心演进路径及每代解决的问题?
2、Qwen2-VL中提出的M-RoPE如何统一处理文本、图像和视频的位置编码?
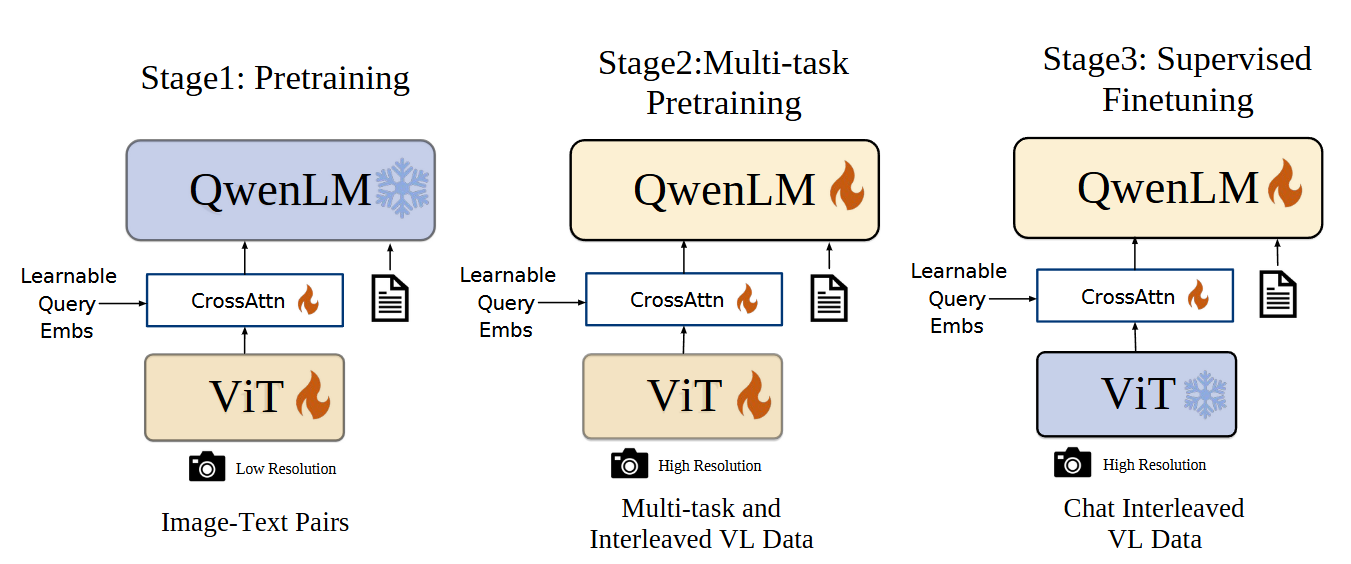
3、Qwen-VL系列模型的三阶段训练范式的具体运作机制与各阶段数据策略?
4、Qwen2.5-VL使用绝对位置坐标相比归一化坐标在目标检测中的优势?
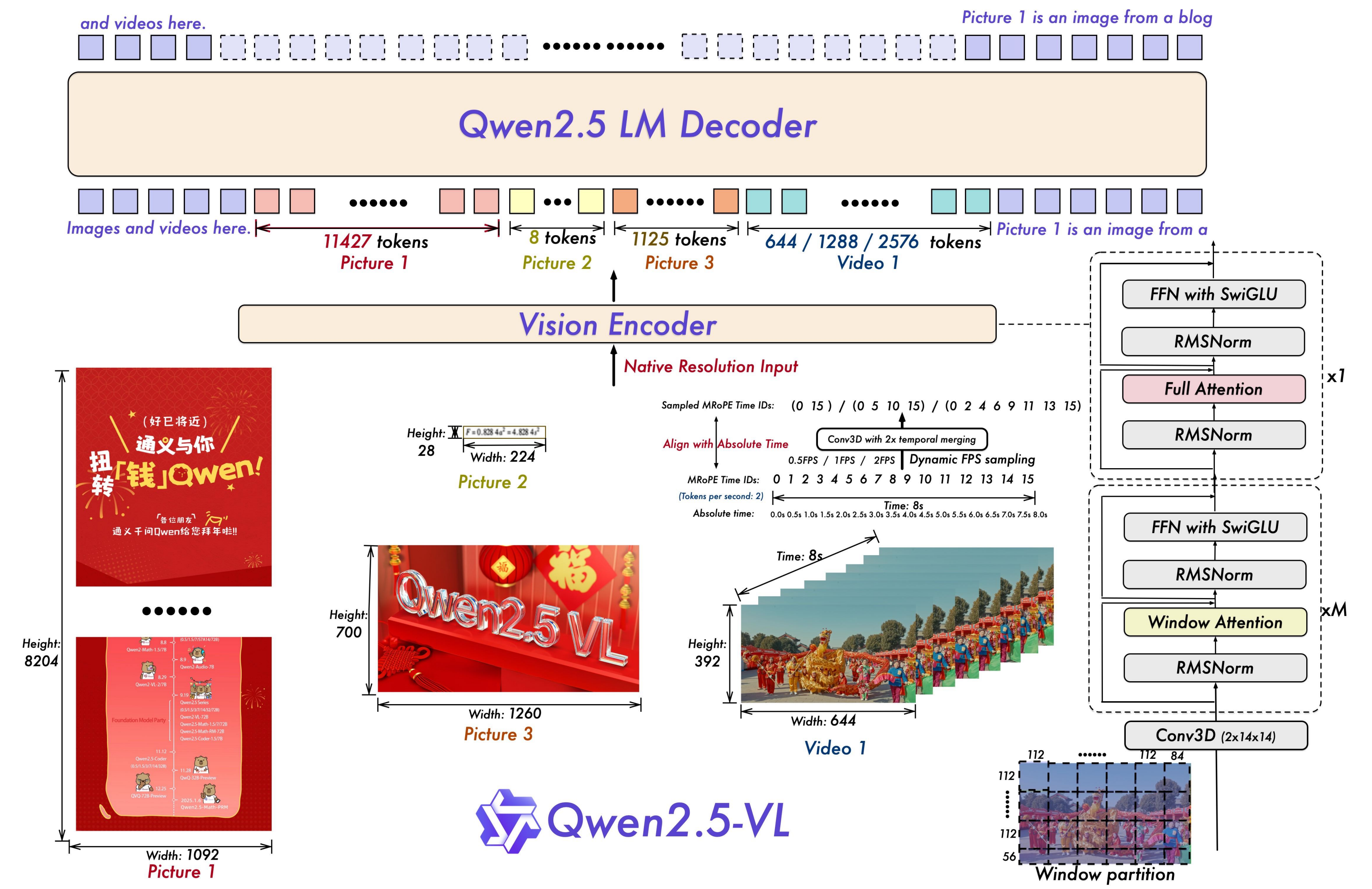
5、Qwen2.5-VL使用动态FPS采样与3D patch划分如何协同提升视频理解?
6、Qwen2.5-VL后训练阶段如何结合监督微调(SFT)和直接偏好优化(DPO)?
7、Qwen-VL系列模型中多模态统一序列化格式的具体实现方式?
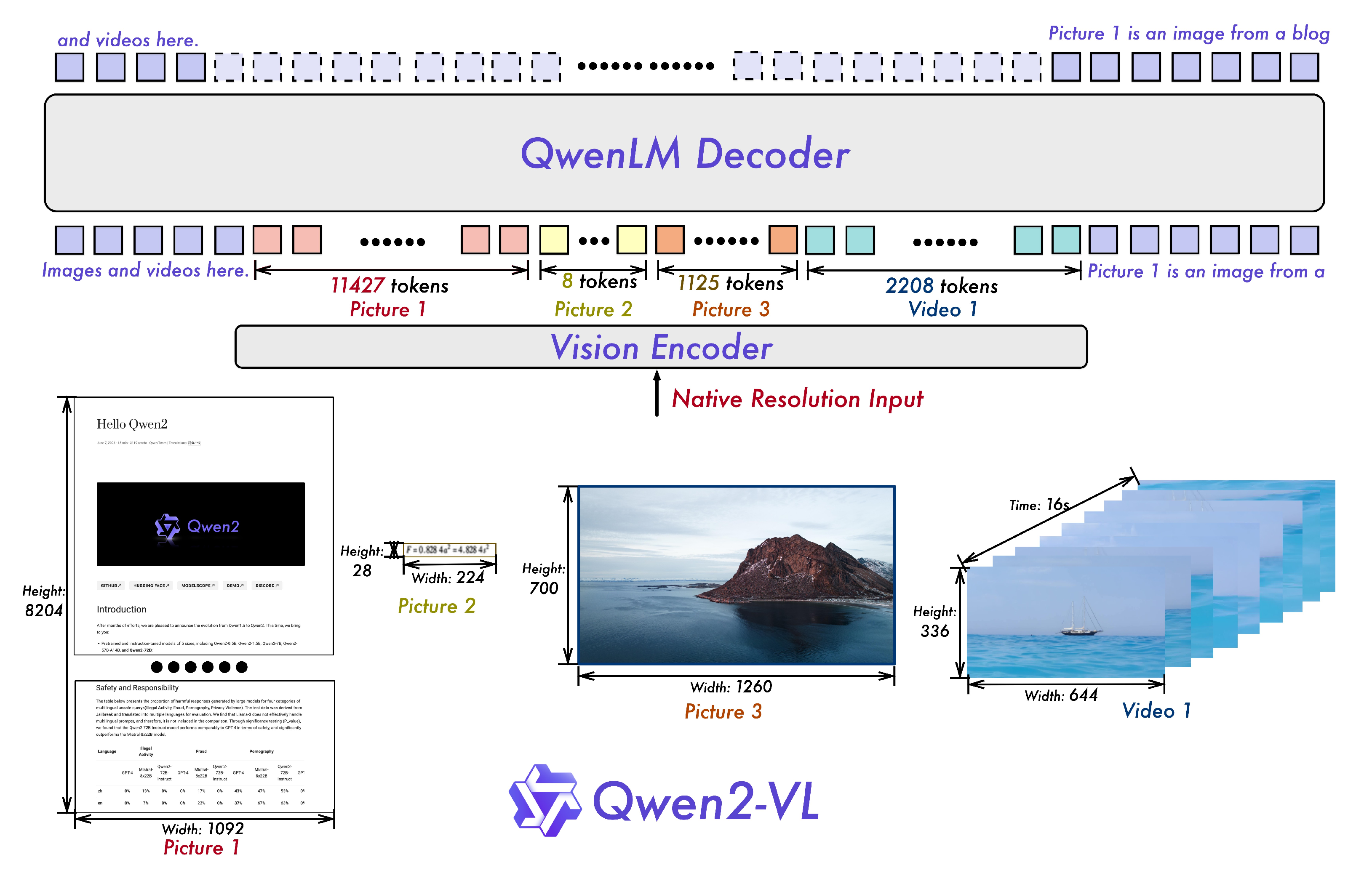
8、Qwen2-VL及之后模型使用的Naive Dynamic Resolution机制的原理与效果?
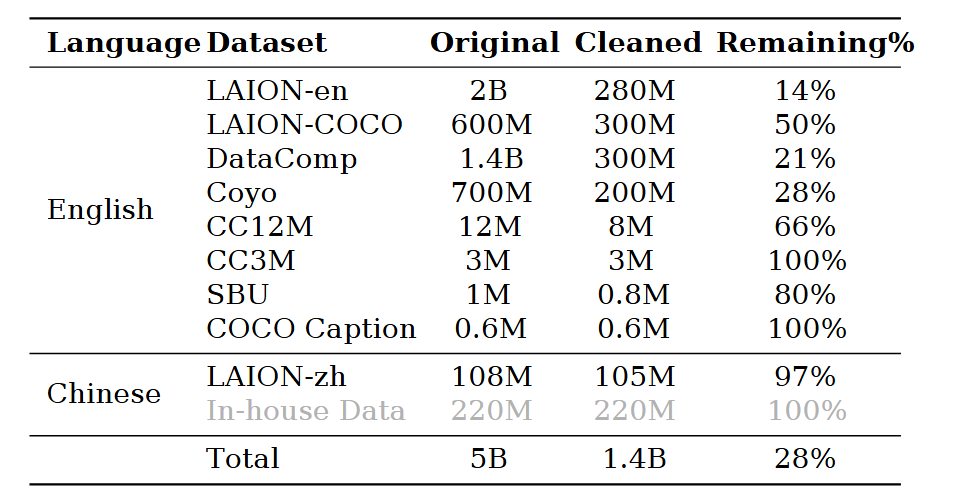
9、Qwen2.5-VL预训练数据构建的核心质量策略?
10、从Qwen-VL到Qwen2.5-VL的多语言支持演进?
Qwen3-VL
11、解释 Qwen3-VL 中 MRoPE-Interleave 的设计原理?
12、Qwen3-VL 引入的 DeepStack 技术如何实现 ViT 多层次特征融合?
13、Qwen3-VL 将 T-RoPE 升级为文本时间戳对齐机制,这一改进如何实现?
14、Qwen3-VL 如何处理不同分辨率的图像和视频输入?
15、Qwen3-VL 对视频使用 3D 卷积进行 Patch Embedding,这与传统 2D 方法有何不同?
16、Qwen3-VL 如何将图像/视频特征嵌入到文本序列中?
17、 Qwen3-VL 在视觉编码器和文本解码器中都使用了RoPE,但实现方式不同。请说明两者的差异?
18、Qwen3-VL 如何处理视频的帧采样?请说明 sample_frames 方法的实现逻辑和 VideoMetadata 的作用?
19、Qwen3-VL 如何在一个batch中处理不同分辨率的图像和不同长度的视频?
Qwen3.5-原生多模态
20、怎么理解 Qwen3.5 的技术定位?尤其是相对 Qwen3,它在架构和能力上有哪些本质升级?
21、Qwen3.5 的一个关键卖点是混合注意力:Gated DeltaNet + 全局注意力。请详细说说 Gated DeltaNet 属于哪类线性注意力,它是如何在保持表达能力的前提下降低复杂度的?3:1 的混合比例有什么技术考量?
22、关于稀疏 MoE,Qwen3.5 宣称总参数接近 397B,但推理时只有 17B 激活。你能系统性说明它的 MoE 设计思路、路由策略,以及如何保证负载均衡和稳定性吗?
23、“原生多模态 VLM”这个说法很抽象,具体在模型结构和训练方式上是怎样体现的?尤其在图片、文档、视频理解这些任务上,它相比传统“语言模型+视觉编码器拼接”的方案强在哪里?
24、托管版 Qwen3.5-Plus 号称支持 1M token 上下文。结合它的混合注意力和推理优化,你能讲讲实现这种超长上下文的关键技术点吗?
25、官方博客提到为 Qwen3.5 搭建了一套异步强化学习框架,用来支撑大规模智能体训练。你能具体说明异步 RL 相对传统同步 RL 的改进点,以及它如何在工具使用、多轮对话等场景中发挥作用吗?
26、Qwen3.5 推理端大规模采用 FP8,你如何看待它在性能和精度之间的平衡?哪些模块会刻意保留更高精度?
27、qwen3.5 在很多基准上表现接近甚至对标 GPT-5.x / Claude 4.5 这类闭源模型。你能大致归纳一下它在语言、多模态、代码这些方向的能力表现和特点吗?
28、从工程和应用角度,如果你要在项目里选型 Qwen3.5,你怎么权衡开源版 Qwen3.5-397B-A17B 跟托管版 Qwen3.5-Plus?各自更适合哪些场景?
29、如果设计一个基于 Qwen3.5 的企业级多模态 Copilot(比如能看 PDF、看报表、看界面截图,还能写代码、查文档),会怎么搭架构?怎么用好它的多模态和 Agent 能力?
Qwen-VL系列的视觉编码器演进,清晰地体现了团队在追求更高视觉理解精度和更低计算开销之间的权衡与创新。
第一代Qwen-VL 搭建了一个稳健的基线。它采用了基于OpenClip的ViT-bigG架构,但处理方式相对传统:将所有输入图像固定缩放到448x448分辨率。这样做虽然保证了处理速度,但高分辨率图像的细节信息损失是无法避免的。为了将漫长的图像特征序列适配到语言模型,它引入了一个非常关键的设计——位置感知视觉-语言适配器。这个适配器通过256个可学习的查询(Query),通过交叉注意力机制从图像特征中提炼出256个token的“视觉摘要”。同时,它在这个适配器中保留了2D绝对位置编码,确保了空间信息的不丢失。这个阶段的核心目标是验证架构可行性并建立基础的视觉-语言关联。
第二代Qwen2-VL 的核心突破是动态分辨率支持。模型不再对图像进行强制缩放,而是允许高分辨率图像生成更多的视觉token(最多16384个),从而保留更丰富的细节,这对于理解图表中的小字或图像中的微小物体至关重要。随之而来的问题是序列长度可能变得非常长。为此,它采用了一个轻量级的MLP压缩器,将相邻的2x2个视觉token合并为1个,高效地减少了序列长度。更重要的是,它在ViT中集成了2D-RoPE,这是一种将旋转位置编码扩展到二维空间的方法,让模型能更精确地理解像素之间的空间相对关系。这一代的核心任务是提升高分辨率图像的细节感知能力并优化计算效率。
第三代Qwen2.5-VL 的视觉编码器近乎是一次重构。它支持原生分辨率输入,并引入了窗口注意力(Window Attention) 机制,使得计算复杂度与序列长度呈线性关系而非二次增长,从而能高效处理手机全屏截图或高清海报等超高分辨率输入。对于视频模态,它创新性地使用了3D patch划分,将连续两帧的图像组合成一个处理单元,极大地提升了对视频时序信息的理解效率。这一代的使命是突破分辨率和序列长度的极限,为模型处理长视频、复杂文档等现实场景扫清架构障碍。
M-RoPE的核心思想是为多模态数据构建一个统一的、分解式的时空坐标系。
传统的RoPE是为文本这种一维序列设计的,它通过旋转矩阵为每个token赋予一个基于其顺序的位置信息。但图像是二维的,视频是三维(时间+空间)的,直接套用一维编码会丢失大量信息。
M-RoPE的解决方案是将位置嵌入分解为**时间(t)、高度(h)、宽度(w)**三个正交的分量。
- 对于纯文本输入,这三个分量被赋予完全相同的值(即token的序列位置),此时M-RoPE在数学上完全等价于一维RoPE,实现了完美的向后兼容。
- 对于图像输入,将“时间”分量置为一个常数(例如0),而“高度”和“宽度”分量则根据每个视觉token在图像中的具体坐标(x, y)进行赋值。这样,模型就能精确地知道一个token是来自图像的左上角还是右下角。
- 对于视频输入,“时间”分量会随着帧序号的增加而递增(t=0,1,2,...),而每一帧内的空间信息依旧由高度和宽度分量编码。这就自然地同时编码了时空信息。

这种分解式的设计,使得模型可以用同一套数学机制来理解单词在句子中的顺序、像素在图像中的位置、以及帧在视频中的顺序,是一种极其优雅和统一的解决方案。
Qwen-VL的三阶段训练是一个“先预训练,再解锁(多任务预训练),后精修(指令微调(SFT))”的经典范式,后续迭代也基于此进行优化。
第一阶段:预训练
- 目标:在海量图像-文本对上,让模型学习视觉表征与语言概念的最基本关联。此时,大型语言模型(LLM)的参数是被冻结的,只训练视觉编码器和视觉-语言适配器。这相当于先给模型“植入”视觉神经元。
- 数据:规模巨大,约50亿对,但经过严格清洗后保留14亿高质量对(英语77.3%,中文22.7%),清洗保留率28%。数据来源多样,如LAION、Coyo等。
第二阶段:多任务预训练
- 目标:引入高质量、细粒度的标注数据,解锁所有模型参数,激发模型的多任务能力(如VQA、定位、OCR等)。
- 数据:约77M样本,任务类型多达7种,包括说明、VQA、对齐、引用对齐、接地说明、OCR、纯文本自回归。数据来源包括GRIT、RefCOCO等权威数据集和内部数据。
- 在此阶段,图像分辨率会提升至448x448,并移除窗口注意力以捕捉更多细节。

第三阶段:指令微调(SFT)
- 目标:让模型学会遵循人类指令进行对话和任务执行。此时,视觉编码器被冻结,只微调LLM和适配器,生成最终的Chat版本。
- 数据:使用约350K指令数据,包含模型自生成的描述、人工标注的定位数据、以及多轮对话数据,旨在让模型变得“有用”和“易用”。

Qwen2.5-VL在此基础上进一步细化,将预训练拆分为视觉预训练、多模态预训练、长上下文预训练三个阶段,并引入了拒绝采样等高级技术来极致化数据质量,但其核心思想仍源于此范式。
核心目的是让模型建立起对真实物理世界的尺度感知能力。
传统的归一化坐标(将边界框坐标除以图像宽高,缩放到0-1之间)是一种与设备无关的表示方法,但它丢失了图像的绝对尺寸信息。对于模型而言,一个在1920x1080图像中归一化坐标为(0.5, 0.5)的点,和一个在224x224图像中同样为(0.5, 0.5)的点,在抽象意义上没有区别。但现实中,前者可能代表一个巨大的广告牌上的一个像素,而后者可能代表手机屏幕上的一个图标,它们的实际物理尺寸天差地别。
Qwen2.5-VL改用绝对坐标,即直接使用图像的真实宽高(如[x, y, width, height] = [960, 540, 100, 50])来表示边界框。这样做的好处是:
- 消除分辨率缩放偏差:模型无需再去猜测输入图像是否被缩放或如何缩放,定位精度更高。
- 增强现实世界理解:模型能逐渐学习到“100像素宽”的物体在屏幕上大概有多大,从而更好地理解UI界面、文档布局等场景。
- 简化预处理流程:无需为了训练和推理的一致性而进行复杂的图像预处理,流程更直接。
这个改动是模型迈向更通用、更实用的智能体(Agent)应用的关键一步,因为它需要精确理解屏幕上每个UI元素的真实大小和位置才能执行点击等操作。
处理长视频的核心挑战在于如何在有限的序列长度内,尽可能保留完整的时序信息和每帧的空间细节。Qwen2.5-VL通过这两项技术形成了一个高效的组合拳。
动态采样FPS是一种时间维度的自适应策略。对于一段长时间的视频(例如1小时),如果每秒都采样,会产生3600帧,序列长度会爆炸。动态采样允许模型根据视频的总长度来智能调整采样率。例如,对长视频采用较低的FPS(如0.5fps),只抽取关键帧;对短视频采用较高的FPS(如2fps),保留更丰富的动作变化。这样可以确保无论视频多长,抽取的总帧数都在一个可控的范围内,优先保证时序信息的完整性。
3D patch划分则是一种空间-时间维度的联合压缩技术。传统的做法是将每一帧独立编码成视觉token,然后拼接起来,这样序列长度与帧数成线性增长。Qwen2.5-VL的创新在于,它将连续的两帧图像在patch层面进行组合,形成一个3D的patch立方体,然后一次性输入给ViT编码器。
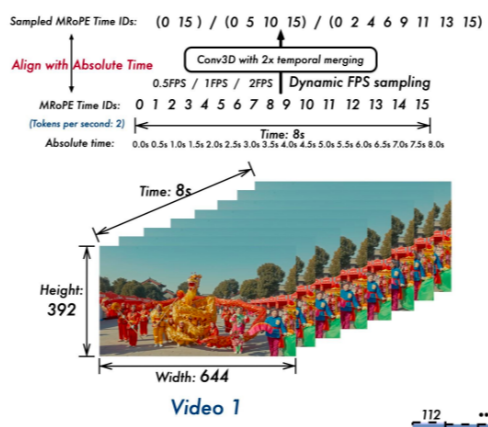
这样做有两个巨大优势:
- 序列长度减半:两帧被压缩成一组特征,极大减少了输入后续语言模型的视觉token数量。
- 原生时序建模:ViT在编码的最底层就能同时看到相邻两帧的信息,从而更早、更有效地捕捉到帧与帧之间的微小变化(即运动信息)。
协同效应:动态采样FPS负责控制输入ViT的帧数量(T维度),而3D patch划分负责压缩每两帧产生的token数量(H*W维度)。两者共同作用,使得模型能够以前所未有的效率处理长达数十分钟甚至小时级的视频,并同时理解其中的空间细节和复杂的时间动态。
Qwen2.5-VL的后训练采用了一种非常精细的双阶段优化范式,旨在先提升能力,再对齐偏好。整个后训练阶段,视觉编码器的参数都是被冻结的。
首先在监督微调(SFT)阶段,核心任务是使用约200万条高质量的指令数据来充分激发模型在预训练中获得的各种能力。这批数据是精心配比的,包含50%的纯文本数据和50%的多模态(图文和视频文本)数据。为了保证数据质量,引入了一个基于Qwen2-VL的分类模型(Qwen2-VL-Instag)对海量候选数据进行智能分类和过滤。
最关键的一步是采用了拒绝采样(Rejection Sampling) 技术。具体来说,使用一个中间版本的Qwen2.5-VL模型,对一批带有标准答案的数据集(有Ground Truth)进行推理,生成模型的响应。然后,将模型的输出与标准答案进行严格比对,只保留那些模型输出与正确答案匹配的样本,而自动丢弃那些生成错误、冗长、存在代码切换或重复模式的低质量样本。
这个过程就像一个极其严格的“考官”,只有交出满分答卷的样本才能进入最终的高质量SFT数据集。通过这种方式,确保了用于微调的数据都是最高效、最准确的“教学材料”,从而让模型的性能提升事半功倍。
在随后的直接偏好优化(DPO)阶段,目标从“提升能力”转向“修正行为”,即让模型的输出更符合人类的偏好和价值观。使用人工标注的偏好数据(例如,选择哪个回答更好),对模型进行训练。值得注意的是,此阶段主要使用图文和纯文本数据,暂不涉及更复杂的视频模态。通过DPO,模型学会了输出更受欢迎、更有帮助且更安全的回答,完成了从“能力强大”到“行为友善”的转变。
该问题触及多模态模型的核心设计哲学,模型需要处理图像、视频和文档等多种模态的输入,解决方案是采用一种基于特殊标记的序列化格式,将所有模态都转化为语言模型所熟悉的“token序列”,从而实现无缝的统一处理。
整个模型的处理流程可以概括为:视觉编码器(ViT)将像素转换为视觉token,连接器(Adapter/MLP)进行压缩和投影,最终所有模态的token被拼接成一个统一的序列输入给LLM。
具体来说:
- 对于图像:图像经过视觉编码器处理后产生的视觉特征序列,会被包裹在一对特殊的标记之中。这相当于告诉语言模型:“接下来的这一串token,是从一张图片里来的”。
- 对于视频:视频被视作一系列图像帧的集合。每一帧都会像上述图像一样被处理。同时,会在帧的特征序列前插入时间戳标记(如
<video t=1.5s>),来明确指示该帧的时间位置。 - 对于复杂文档:为了统一处理文档中的表格、图表、公式等元素,将其全部转换为HTML格式的文本。HTML本身是一种文本标记语言,因此可以直接被语言模型理解和处理。图像等非文本元素则依旧用``标签嵌入到HTML文本序列中。
这种设计的好处是极致的简洁和灵活。语言模型不需要为不同模态准备不同的处理模块,它只需要学会理解这些特殊的“模态标记”和“时间戳标记”,就能以一种近乎相同的方式处理各种输入,大大降低了架构的复杂性。
朴素动态分辨率机制——“Naive Dynamic Resolution”是一种直观但非常有效的设计,其核心思想是让视觉token的数量与输入图像的分辨率动态适配,从而在计算资源允许的范围内最大限度地保留原始信息。
工作流程:
- 动态分词:模型不再将所有图像强制缩放到一个固定的尺寸(如224x224或448x448),而是根据图像的原生分辨率,通过视觉编码器(ViT)将其转换为相应数量的视觉token。一张1024x1024的图片自然会比一张224x224的图片产生多得多的视觉token。
- 智能压缩:为了避免产生的token序列过长,随后使用一个轻量的MLP压缩器,将空间上相邻的2x2个视觉token合并为1个token。这相当于将图像的“分辨率”在特征空间里降低了2倍,从而将序列长度减少到原来的1/4。
这个过程之所以能提升细节理解,关键在于第一步。对于高分辨率图像,即使经过后续的2x2合并压缩,其最终保留的视觉token数量仍然远高于低分辨率图像直接处理的结果。例如,一张4K图像最初可能生成上万token,压缩后仍能保留数千token;而一张低分辨率图像最初只能产生数百token。更多的token意味着更多的信息承载量,使得模型能够分辨出图像中更细微的元素,如文档里的小号字体、网页上的图标细节或街景中的远处路牌。
这种机制让模型在面对不同质量的输入时具备了“弹性”,既能细致入微地分析高清图片,也不会对低分辨率图片进行不必要的过度计算。
Qwen2.5-VL的性能飞跃,很大程度上源于在数据质量上进行的“精耕细作”。不再仅仅追求数据规模,而是通过一系列系统性的策略来构建一个“精英”数据集。
核心策略主要包括以下几个方面:
- 交错图文数据的精细化清洗:从海量原始数据中,通过基于CLIP模型的数据评分和一系列去重、去污的清洗流程,筛选出真正高质量、图文高度相关的样本。这确保了基础视觉-语言关联学习的可靠性。
- grounding数据的绝对坐标化:正如之前提到的,在检测和定位数据中摒弃了归一化坐标,采用基于图像真实尺寸的绝对坐标。这一改动虽然微小,但让模型学习到的空间关系是基于真实世界的尺度,极大提升了其在现实应用中的泛化能力。
- 文档数据的结构化合成:合成了大量包含表格、图表、公式、乐谱等复杂元素的文档数据,并统一用HTML格式来标注。这种结构化的表示方式让模型能无缝地理解和推理文档中的多模态元素之间的关系。
- 视频数据的时序精细化标注:对于视频数据,不仅动态采样帧,还构建了详细的长视频标题描述,并以“时分秒帧”(hmsf)的格式精确标注时间戳,让模型能够建立精确的时序理解。
- 智能体数据的多维构建:为了训练模型成为屏幕智能体,收集了移动端、Web和桌面的截图,并利用合成引擎生成了对UI元素的精准接地(grounding)注释。这使得模型能理解“可点击的按钮”在屏幕上的具体位置。
所有这些策略的共同点在于:不仅提供数据,更提供数据的精确上下文和结构化信息。是在为模型构建一个标注清晰、结构严谨的“教科书”,而不仅仅是提供一堆“阅读材料”。
多语言能力的扩展是一个系统工程,从数据和模型两个层面稳步推进。
- 多语言OCR数据的系统整合:广泛收集和整合了来自不同来源的OCR数据,包括合成数据、开源数据(如SROIE)和内部收集的数据,并重点覆盖了日语、韩语、阿拉伯语等更多语言。这教会了模型如何“阅读”全世界的文字。
- 多语言指令微调数据的构建:在SFT阶段,注入了包含多种语言的问答对和指令数据。这使得模型不仅能“看”懂多语言文字,还能用相应的语言进行思考和回答,实现了端到端的多模态多语言对话。
- 绝对坐标的间接增益:之前提到的绝对坐标标注策略,同样惠及多语言场景。例如,一个中文网页和一个阿拉伯文网页(从右向左书写)的UI元素位置分布可能不同,绝对坐标能帮助模型更好地理解这种与文化或语言书写方向相关的布局差异,从而做出更准确的定位。
MRoPE-Interleave 是 Qwen3-VL 在位置编码方面的核心创新之一。传统的 MRoPE(Multimodal Rotary Position Embedding)将特征维度按照时间(T)、高度(H)、宽度(W)的顺序分块划分,这导致时间信息全部集中在高频维度上,对长视频理解能力有限。
核心改进思路:
Qwen3-VL 采用 t,h,w 交错分布的形式,实现对时间、高度和宽度的全频率覆盖。这种设计使得位置编码更加鲁棒,在保证图片理解能力的同时,显著提升了对长视频的理解能力。
代码实现分析:
在 Qwen3VLTextRotaryEmbedding 类中,核心实现体现在 apply_interleaved_mrope 方法:
def apply_interleaved_mrope(self, freqs, mrope_section):
"""Apply interleaved MRoPE to 3D rotary embeddings.
Reorganizes frequency layout from chunked [TTT...HHH...WWW] to
interleaved [THTHWHTHW...TT], preserving frequency continuity.
args:
x: (3, bs, seq_len, head_dim // 2)
mrope_section: (3,)
returns:
x_t: (bs, seq_len, head_dim // 2)
"""
freqs_t = freqs[0] # 从时间维度开始
for dim, offset in enumerate((1, 2), start=1): # 遍历 H, W 维度
length = mrope_section[dim] * 3
idx = slice(offset, length, 3) # 步长为3,实现交错
freqs_t[..., idx] = freqs[dim, ..., idx]
return freqs_t关键技术点:
- 三维位置编码生成: 首先为 T、H、W 三个维度分别生成位置编码频率
- 交错重组: 通过
slice(offset, length, 3)实现步长为3的交错采样,将原本分块的 [TTT...HHH...WWW] 重组为 [THTHWHTHW...] - 频率覆盖: 这种交错方式确保每个维度的信息都分布在低频到高频的完整频谱上
在 forward 方法中的应用:
@torch.no_grad()
def forward(self, x, position_ids):
# position_ids 扩展为 3 维: (3, bs, seq_len)
if position_ids.ndim == 2:
position_ids = position_ids[None, ...].expand(3, position_ids.shape[0], -1)
inv_freq_expanded = self.inv_freq[None, None, :, None].float().expand(3, position_ids.shape[1], -1, 1)
position_ids_expanded = position_ids[:, :, None, :].float()
# 计算频率
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(2, 3)
# 应用交错 MRoPE
freqs = self.apply_interleaved_mrope(freqs, self.mrope_section)
emb = torch.cat((freqs, freqs), dim=-1)
cos = emb.cos() * self.attention_scaling
sin = emb.sin() * self.attention_scaling
return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)达到的功能: 这种设计使得模型在处理长视频时,时间信息不会被局限在高频维度,而是与空间信息(高度、宽度)在整个频率范围内均匀分布,提升了模型对视频时序关系的建模能力。
DeepStack 是 Qwen3-VL 的第二大创新,它打破了传统多模态大模型单层输入视觉 tokens 的缺点,改为在 LLM 的多层中注入来自 ViT 不同层的视觉特征,实现更精细化的视觉理解。
核心设计思想:
- 多层提取: 从 ViT 的不同深度层提取视觉特征
- 多层注入: 将这些特征分别注入到 LLM 的对应层
- 层级对齐: 保留从底层(low-level)到高层(high-level)的丰富视觉信息
视觉编码器端的实现:
在 Qwen3VLVisionModel 中,通过 deepstack_visual_indexes 配置指定提取特征的层:
def __init__(self, config, *inputs, **kwargs) -> None:
super().__init__(config, *inputs, **kwargs)
# ... 其他初始化代码
# 配置需要提取特征的层索引,默认为 [8, 16, 24]
self.deepstack_visual_indexes = config.deepstack_visual_indexes
# 为每个提取层创建独立的特征融合器
self.deepstack_merger_list = nn.ModuleList([
Qwen3VLVisionPatchMerger(
config=config,
use_postshuffle_norm=True, # 使用后归一化
)
for _ in range(len(config.deepstack_visual_indexes))
])在前向传播中提取多层特征:
def forward(self, hidden_states: torch.Tensor, grid_thw: torch.Tensor, **kwargs) -> torch.Tensor:
# ... 位置编码等预处理
deepstack_feature_lists = []
for layer_num, blk in enumerate(self.blocks):
hidden_states = blk(
hidden_states,
cu_seqlens=cu_seqlens,
position_embeddings=position_embeddings,
**kwargs,
)
# 在指定层提取特征
if layer_num in self.deepstack_visual_indexes:
idx = self.deepstack_visual_indexes.index(layer_num)
deepstack_feature = self.deepstack_merger_list[idx](hidden_states)
deepstack_feature_lists.append(deepstack_feature)
# 最后一层的常规输出
hidden_states = self.merger(hidden_states)
return hidden_states, deepstack_feature_lists语言模型端的特征注入:
在 Qwen3VLTextModel 中,通过 _deepstack_process 方法将视觉特征注入到对应层:
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
# ... 其他参数
visual_pos_masks: Optional[torch.Tensor] = None,
deepstack_visual_embeds: Optional[list[torch.Tensor]] = None,
**kwargs,
) -> Union[tuple, BaseModelOutputWithPast]:
# ... 输入处理
# 遍历解码器层
for layer_idx, decoder_layer in enumerate(self.layers):
layer_outputs = decoder_layer(
hidden_states,
attention_mask=attention_mask,
position_ids=text_position_ids,
past_key_values=past_key_values,
cache_position=cache_position,
position_embeddings=position_embeddings,
**kwargs,
)
hidden_states = layer_outputs
# 在前几层注入视觉特征
if deepstack_visual_embeds is not None and layer_idx in range(len(deepstack_visual_embeds)):
hidden_states = self._deepstack_process(
hidden_states,
visual_pos_masks,
deepstack_visual_embeds[layer_idx],
)
return BaseModelOutputWithPast(...)特征注入的具体实现:
def _deepstack_process(
self, hidden_states: torch.Tensor,
visual_pos_masks: torch.Tensor,
visual_embeds: torch.Tensor
):
visual_pos_masks = visual_pos_masks.to(hidden_states.device)
visual_embeds = visual_embeds.to(hidden_states.device, hidden_states.dtype)
# 克隆避免原地修改
hidden_states = hidden_states.clone()
# 在视觉 token 位置进行特征相加
local_this = hidden_states[visual_pos_masks, :] + visual_embeds
hidden_states[visual_pos_masks, :] = local_this
return hidden_states技术优势:
- 层级信息保留: 底层特征保留边缘、纹理等细节,高层特征包含语义信息
- 渐进式融合: 不同深度的 LLM 层接收对应层级的视觉信息,实现更自然的多模态对齐
- 细节增强: 显著提升了视觉细节捕捉能力和图文对齐精度
文本时间戳对齐机制采用"时间戳-视频帧"交错的输入形式,实现帧级别的时间信息与视觉内容的细粒度对齐。
核心设计理念:
传统的 T-RoPE 使用绝对时间位置编码,而 Qwen3-VL 改用显式时间戳,将每一帧的时间信息以文本形式嵌入到输入序列中,格式如 <2.5 seconds><|vision_start|><frame><|vision_end|>。
时间戳计算实现:
在 Qwen3VLProcessor 中,通过 _calculate_timestamps 方法计算每帧的时间戳:
def _calculate_timestamps(self, indices: Union[list[int], np.ndarray], video_fps: float, merge_size: int = 2):
if not isinstance(indices, list):
indices = indices.tolist()
# 确保帧数是 merge_size 的倍数,不足则填充
if len(indices) % merge_size != 0:
indices.extend(indices[-1] for _ in range(merge_size - len(indices) % merge_size))
# 根据帧索引和 FPS 计算时间戳
timestamps = [idx / video_fps for idx in indices]
# 时间patch内取平均:因为帧会被 merge_size 合并
# 所以取时间patch首尾帧的平均时间作为该patch的时间戳
timestamps = [
(timestamps[i] + timestamps[i + merge_size - 1]) / 2
for i in range(0, len(timestamps), merge_size)
]
return timestamps视频占位符构建:
在 __call__ 方法中构建包含时间戳的视频占位符:
if video_grid_thw is not None:
merge_length = self.video_processor.merge_size**2
index = 0
for i in range(len(text)):
while self.video_token in text[i]:
metadata = video_metadata[index]
# 推断或使用提供的 FPS
if metadata.fps is None:
logger.warning_once("Defaulting to fps=24...")
metadata.fps = 24
# 计算当前视频的时间戳
curr_timestamp = self._calculate_timestamps(
metadata.frames_indices,
metadata.fps,
self.video_processor.merge_size,
)
# 构建视频占位符:时间戳 + 视觉帧交错
video_placeholder = ""
frame_seqlen = video_grid_thw[index][1:].prod() // merge_length
for frame_idx in range(video_grid_thw[index][0]):
curr_time = curr_timestamp[frame_idx]
# 添加时间戳文本
video_placeholder += f"<{curr_time:.1f} seconds>"
# 添加视觉帧 tokens
video_placeholder += (
self.vision_start_token +
"<|placeholder|>" * frame_seqlen +
self.vision_end_token
)
# 替换原始视频 token
text[i] = text[i].replace(
f"{self.vision_start_token}{self.video_token}{self.vision_end_token}",
video_placeholder,
1
)
index += 1
# 将占位符替换为实际的视频 token
text[i] = text[i].replace("<|placeholder|>", self.video_token)位置索引的特殊处理:
在 Qwen3VLModel.get_rope_index 中,视频的 grid_thw 需要特殊处理:
def get_rope_index(
self,
input_ids: Optional[torch.LongTensor] = None,
image_grid_thw: Optional[torch.LongTensor] = None,
video_grid_thw: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
) -> tuple[torch.Tensor, torch.Tensor]:
"""Different from the original implementation, Qwen3VL use timestamps
rather than absolute time position ids."""
# 由于使用时间戳分隔视频帧,需要将 video_grid_thw 拆分
# 例如: <t1> <frame1> <t2> <frame2> ...
if video_grid_thw is not None:
video_grid_thw = torch.repeat_interleave(
video_grid_thw,
video_grid_thw[:, 0], # 按时间维度重复
dim=0
)
video_grid_thw[:, 0] = 1 # 每个时间戳对应1帧技术优势:
- 细粒度时间对齐: 每一帧都有明确的时间标记,模型能精确理解"在第5秒发生了什么"
- 原生时间感知: 模型可以直接输出秒数或HMS格式,无需后处理
- 时序推理增强: 显著提升事件定位、动作边界检测、跨模态时间问答等任务的性能
- 可解释性强: 时间信息以文本形式显式存在,便于调试和理解
实际输入示例:
<2.5 seconds><|vision_start|><image_tokens><|vision_end|>
<5.0 seconds><|vision_start|><image_tokens><|vision_end|>
What happened between 2 and 5 seconds?
这种设计使得模型能够精确定位视频中的事件,并进行复杂的时序推理。
智能缩放算法 - smart_resize:
在 video_processing_qwen3_vl.py 中实现了智能缩放函数:
def smart_resize(
num_frames: int,
height: int,
width: int,
temporal_factor: int = 2,
factor: int = 32,
min_pixels: int = 128 * 128,
max_pixels: int = 16 * 16 * 2 * 2 * 2 * 6144,
):
# 参数验证
if num_frames < temporal_factor:
raise ValueError(f"t:{num_frames} must be larger than temporal_factor:{temporal_factor}")
if height < factor or width < factor:
raise ValueError(f"height:{height} or width:{width} must be larger than factor:{factor}")
elif max(height, width) / min(height, width) > 200:
raise ValueError(f"absolute aspect ratio must be smaller than 200")
# 对齐到 factor 的倍数(patch_size * merge_size)
h_bar = round(height / factor) * factor
w_bar = round(width / factor) * factor
t_bar = round(num_frames / temporal_factor) * temporal_factor
# 像素数超出上限,按比例缩小
if t_bar * h_bar * w_bar > max_pixels:
beta = math.sqrt((num_frames * height * width) / max_pixels)
h_bar = max(factor, math.floor(height / beta / factor) * factor)
w_bar = max(factor, math.floor(width / beta / factor) * factor)
# 像素数低于下限,按比例放大
elif t_bar * h_bar * w_bar < min_pixels:
beta = math.sqrt(min_pixels / (num_frames * height * width))
h_bar = math.ceil(height * beta / factor) * factor
w_bar = math.ceil(width * beta / factor) * factor
return h_bar, w_bar关键设计点:
- 对齐约束: 确保尺寸是
patch_size * merge_size的倍数,便于后续的 patch 划分 - 像素范围控制: 通过
min_pixels和max_pixels控制计算量 - 宽高比保护: 限制宽高比不超过200,避免极端变形
位置编码的双线性插值:
由于输入尺寸可变,位置编码需要动态插值。在 Qwen3VLVisionModel.fast_pos_embed_interpolate 中实现:
def fast_pos_embed_interpolate(self, grid_thw):
grid_ts, grid_hs, grid_ws = grid_thw[:, 0], grid_thw[:, 1], grid_thw[:, 2]
device = grid_thw.device
idx_list = [[] for _ in range(4)] # 四个角的索引
weight_list = [[] for _ in range(4)] # 对应的权重
for t, h, w in zip(grid_ts, grid_hs, grid_ws):
# 计算插值位置
h_idxs = torch.linspace(0, self.num_grid_per_side - 1, h)
w_idxs = torch.linspace(0, self.num_grid_per_side - 1, w)
# 获取上下界索引
h_idxs_floor = h_idxs.int()
w_idxs_floor = w_idxs.int()
h_idxs_ceil = (h_idxs.int() + 1).clip(max=self.num_grid_per_side - 1)
w_idxs_ceil = (w_idxs.int() + 1).clip(max=self.num_grid_per_side - 1)
# 计算插值权重
dh = h_idxs - h_idxs_floor
dw = w_idxs - w_idxs_floor
# 计算四个角的索引
base_h = h_idxs_floor * self.num_grid_per_side
base_h_ceil = h_idxs_ceil * self.num_grid_per_side
indices = [
(base_h[None].T + w_idxs_floor[None]).flatten(), # 左上
(base_h[None].T + w_idxs_ceil[None]).flatten(), # 右上
(base_h_ceil[None].T + w_idxs_floor[None]).flatten(), # 左下
(base_h_ceil[None].T + w_idxs_ceil[None]).flatten(), # 右下
]
# 双线性插值权重
weights = [
((1 - dh)[None].T * (1 - dw)[None]).flatten(), # 左上权重
((1 - dh)[None].T * dw[None]).flatten(), # 右上权重
(dh[None].T * (1 - dw)[None]).flatten(), # 左下权重
(dh[None].T * dw[None]).flatten(), # 右下权重
]
for i in range(4):
idx_list[i].extend(indices[i].tolist())
weight_list[i].extend(weights[i].tolist())
# 执行加权求和
idx_tensor = torch.tensor(idx_list, dtype=torch.long, device=device)
weight_tensor = torch.tensor(weight_list, dtype=self.pos_embed.weight.dtype, device=device)
pos_embeds = self.pos_embed(idx_tensor).to(device) * weight_tensor[:, :, None]
patch_pos_embeds = pos_embeds[0] + pos_embeds[1] + pos_embeds[2] + pos_embeds[3]
# 重排以适应 merge 操作
patch_pos_embeds = patch_pos_embeds.split([h * w for h, w in zip(grid_hs, grid_ws)])
patch_pos_embeds_permute = []
merge_size = self.config.spatial_merge_size
for pos_embed, t, h, w in zip(patch_pos_embeds, grid_ts, grid_hs, grid_ws):
pos_embed = pos_embed.repeat(t, 1) # 时间维度重复
pos_embed = (
pos_embed.view(t, h // merge_size, merge_size, w // merge_size, merge_size, -1)
.permute(0, 1, 3, 2, 4, 5)
.flatten(0, 4)
)
patch_pos_embeds_permute.append(pos_embed)
patch_pos_embeds = torch.cat(patch_pos_embeds_permute)
return patch_pos_embeds技术优势:
- 任意分辨率支持: 无需预定义固定尺寸,适应各种输入
- 计算效率平衡: 通过像素范围控制避免过大或过小的输入
- 平滑插值: 双线性插值保证位置编码的连续性
- 批处理友好: 支持同一批次中不同尺寸的输入
Qwen3-VL 针对视频输入采用了 3D 卷积的 Patch Embedding 方案,这是一个重要的架构设计,能够在早期阶段就融合时空信息。
3D Patch Embedding 实现:
在 Qwen3VLVisionPatchEmbed 类中:
class Qwen3VLVisionPatchEmbed(nn.Module):
def __init__(self, config) -> None:
super().__init__()
self.patch_size = config.patch_size # 空间patch大小,如16
self.temporal_patch_size = config.temporal_patch_size # 时间patch大小,如2
self.in_channels = config.in_channels # 输入通道数,通常为3(RGB)
self.embed_dim = config.hidden_size # 嵌入维度,如1152
# 3D卷积核: [temporal_patch_size, patch_size, patch_size]
kernel_size = [self.temporal_patch_size, self.patch_size, self.patch_size]
# 使用3D卷积进行patch embedding
self.proj = nn.Conv3d(
self.in_channels,
self.embed_dim,
kernel_size=kernel_size,
stride=kernel_size, # stride等于kernel_size,实现非重叠划分
bias=True
)
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
target_dtype = self.proj.weight.dtype
# 重塑输入: (batch, channels, T, H, W)
hidden_states = hidden_states.view(
-1,
self.in_channels,
self.temporal_patch_size,
self.patch_size,
self.patch_size
)
# 3D卷积投影并展平
hidden_states = self.proj(hidden_states.to(dtype=target_dtype)).view(-1, self.embed_dim)
return hidden_states与2D方法的对比:
| 维度 | 2D Patch Embedding | 3D Patch Embedding (Qwen3-VL) |
|---|---|---|
| 处理方式 | 逐帧独立处理 | 时空联合处理 |
| 卷积核 | [patch_size, patch_size] | [temporal_patch_size, patch_size, patch_size] |
| 时间建模 | 后续层才建模 | 从embedding层就开始 |
| 参数量 | 较少 | 略多(增加时间维度) |
| 感受野 | 单帧空间区域 | 跨帧时空区域 |
在视频处理流程中的应用:
在 Qwen3VLVideoProcessor._preprocess 中,视频数据经过以下处理:
def _preprocess(
self,
videos: list[torch.Tensor],
do_resize: bool = True,
size: Optional[SizeDict] = None,
patch_size: Optional[int] = None,
temporal_patch_size: Optional[int] = None,
merge_size: Optional[int] = None,
**kwargs,
):
# 按形状分组处理
grouped_videos, grouped_videos_index = group_videos_by_shape(videos)
for shape, stacked_videos in grouped_videos.items():
B, T, C, H, W = stacked_videos.shape
# 动态调整尺寸
if do_resize:
resized_height, resized_width = smart_resize(
num_frames=T,
height=H,
width=W,
temporal_factor=temporal_patch_size, # 确保帧数对齐
factor=patch_size * merge_size,
min_pixels=size.shortest_edge,
max_pixels=size.longest_edge,
)
# ... resize操作
# 归一化处理
stacked_videos = self.rescale_and_normalize(
stacked_videos, do_rescale, rescale_factor, do_normalize, image_mean, image_std
)
patches = stacked_videos
# 确保帧数是temporal_patch_size的倍数
if patches.shape[1] % temporal_patch_size != 0:
repeats = patches[:, -1:].repeat(1, temporal_patch_size - 1, 1, 1, 1)
patches = torch.cat([patches, repeats], dim=1)
batch_size, grid_t, channel = patches.shape[:3]
grid_t = grid_t // temporal_patch_size # 时间维度下采样
grid_h, grid_w = resized_height // patch_size, resized_width // patch_size
# 重排为适合3D卷积的格式
patches = patches.view(
batch_size,
grid_t,
temporal_patch_size,
channel,
grid_h // merge_size,
merge_size,
patch_size,
grid_w // merge_size,
merge_size,
patch_size,
)
# 维度重排: (B, grid_t, grid_h, grid_w, merge_h, merge_w, C, T_patch, H_patch, W_patch)
patches = patches.permute(0, 1, 4, 7, 5, 8, 3, 2, 6, 9)
# 展平为序列
flatten_patches = patches.reshape(
batch_size,
grid_t * grid_h * grid_w,
channel * temporal_patch_size * patch_size * patch_size,
)技术优势:
- 早期时空融合: 在embedding阶段就捕捉时空相关性,而非依赖后续层
- 运动感知: 3D卷积天然能捕捉局部运动模式
- 参数效率: 相比分别处理时间和空间,3D卷积更紧凑
- 对齐友好:
temporal_patch_size=2与视频帧率很好配合,减少冗余
实际效果: 这种设计使得模型从底层就能理解"物体在移动"而非"两帧中物体位置不同",提升了视频理解的连贯性。
Qwen3-VL 采用了精巧的占位符替换机制,将变长的视觉特征无缝嵌入到文本序列中,实现真正的多模态融合。
整体流程概述:
- Processor阶段: 根据视觉输入的实际大小,将占位符token(如
<|image_pad|>)重复相应次数 - Model阶段: 将占位符对应的embedding替换为实际的视觉特征
Processor端的占位符扩展:
在 Qwen3VLProcessor.__call__ 中:
def __call__(
self,
images: ImageInput = None,
text: Union[TextInput, PreTokenizedInput, list[TextInput], list[PreTokenizedInput]] = None,
videos: VideoInput = None,
**kwargs,
) -> BatchFeature:
# 处理图像
if images is not None:
image_inputs = self.image_processor(images=images, **output_kwargs["images_kwargs"])
image_grid_thw = image_inputs["image_grid_thw"] # 每个图像的(T,H,W)网格大小
else:
image_inputs = {}
image_grid_thw = None
# 处理视频
if videos is not None:
videos_inputs = self.video_processor(videos=videos, **output_kwargs["videos_kwargs"])
video_grid_thw = videos_inputs["video_grid_thw"]
video_metadata = videos_inputs.get("video_metadata")
else:
videos_inputs = {}
video_grid_thw = None
if not isinstance(text, list):
text = [text]
text = text.copy() # 避免修改原始输入
# 图像占位符扩展
if image_grid_thw is not None:
merge_length = self.image_processor.merge_size**2
index = 0
for i in range(len(text)):
while self.image_token in text[i]:
# 计算该图像需要的token数量
num_image_tokens = image_grid_thw[index].prod() // merge_length
# 用临时占位符替换,数量与实际特征数匹配
text[i] = text[i].replace(
self.image_token,
"<|placeholder|>" * num_image_tokens,
1 # 每次只替换一个
)
index += 1
# 将临时占位符替换为真实的image_token
text[i] = text[i].replace("<|placeholder|>", self.image_token)关键计算 - token数量:
# 对于图像: grid_thw = [1, H_grid, W_grid]
# H_grid = resized_height // (patch_size * merge_size)
# W_grid = resized_width // (patch_size * merge_size)
num_image_tokens = grid_thw[0] * grid_thw[1] * grid_thw[2] // merge_length
= 1 * H_grid * W_grid // (merge_size^2)
= H_grid * W_grid // 4 # 当merge_size=2时Model端的特征替换:
在 Qwen3VLModel.forward 中:
def forward(
self,
input_ids: torch.LongTensor = None,
pixel_values: Optional[torch.Tensor] = None,
pixel_values_videos: Optional[torch.FloatTensor] = None,
image_grid_thw: Optional[torch.LongTensor] = None,
video_grid_thw: Optional[torch.LongTensor] = None,
**kwargs,
) -> Union[tuple, Qwen3VLModelOutputWithPast]:
# 获取文本embeddings
if inputs_embeds is None:
inputs_embeds = self.get_input_embeddings()(input_ids)
image_mask = None
video_mask = None
# 处理图像特征
if pixel_values is not None:
# 通过视觉编码器获取图像特征
image_embeds, deepstack_image_embeds = self.get_image_features(pixel_values, image_grid_thw)
image_embeds = torch.cat(image_embeds, dim=0).to(inputs_embeds.device, inputs_embeds.dtype)
# 获取占位符mask
image_mask, _ = self.get_placeholder_mask(
input_ids,
inputs_embeds=inputs_embeds,
image_features=image_embeds
)
# 用真实视觉特征替换占位符embedding
inputs_embeds = inputs_embeds.masked_scatter(image_mask, image_embeds)占位符mask的生成:
def get_placeholder_mask(
self,
input_ids: torch.LongTensor,
inputs_embeds: torch.FloatTensor,
image_features: Optional[torch.FloatTensor] = None,
video_features: Optional[torch.FloatTensor] = None,
):
# 定位image_token的位置
if input_ids is None:
# 从embeddings中识别
special_image_mask = inputs_embeds == self.get_input_embeddings()(
torch.tensor(self.config.image_token_id, dtype=torch.long, device=inputs_embeds.device)
)
special_image_mask = special_image_mask.all(-1) # 所有维度都匹配
else:
# 从input_ids中识别
special_image_mask = input_ids == self.config.image_token_id
# 验证数量匹配
n_image_tokens = special_image_mask.sum()
special_image_mask = special_image_mask.unsqueeze(-1).expand_as(inputs_embeds).to(inputs_embeds.device)
if image_features is not None and inputs_embeds[special_image_mask].numel() != image_features.numel():
raise ValueError(
f"Image features and image tokens do not match: "
f"tokens: {n_image_tokens}, features {image_features.shape[0]}"
)
return special_image_mask, special_video_mask图像和视频特征的联合处理:
# 当同时有图像和视频时,需要合并deepstack特征
if image_mask is not None and video_mask is not None:
image_mask = image_mask[..., 0]
video_mask = video_mask[..., 0]
visual_pos_masks = image_mask | video_mask # 合并mask
deepstack_visual_embeds = []
image_mask_joint = image_mask[visual_pos_masks]
video_mask_joint = video_mask[visual_pos_masks]
# 为每一层的deepstack特征创建联合embedding
for img_embed, vid_embed in zip(deepstack_image_embeds, deepstack_video_embeds):
embed_joint = img_embed.new_zeros(visual_pos_masks.sum(), img_embed.shape[-1])
embed_joint[image_mask_joint, :] = img_embed
embed_joint[video_mask_joint, :] = vid_embed
deepstack_visual_embeds.append(embed_joint)视觉RoPE - 2D空间位置编码:
在 Qwen3VLVisionRotaryEmbedding 中:
class Qwen3VLVisionRotaryEmbedding(nn.Module):
inv_freq: torch.Tensor
def __init__(self, dim: int, theta: float = 10000.0) -> None:
super().__init__()
# 标准RoPE频率计算
inv_freq = 1.0 / (theta ** (torch.arange(0, dim, 2, dtype=torch.float) / dim))
self.register_buffer("inv_freq", inv_freq, persistent=False)
def forward(self, seqlen: int) -> torch.Tensor:
seq = torch.arange(seqlen, device=self.inv_freq.device, dtype=self.inv_freq.dtype)
freqs = torch.outer(seq, self.inv_freq) # 外积生成频率表
return freqs视觉位置的2D展开:
在 Qwen3VLVisionModel.rot_pos_emb 中,将2D空间位置展开:
def rot_pos_emb(self, grid_thw: torch.Tensor) -> torch.Tensor:
merge_size = self.spatial_merge_size
max_hw = int(grid_thw[:, 1:].max().item())
freq_table = self.rotary_pos_emb(max_hw) # 生成频率表
total_tokens = int(torch.prod(grid_thw, dim=1).sum().item())
pos_ids = torch.empty((total_tokens, 2), dtype=torch.long, device=device) # 2D位置
offset = 0
for num_frames, height, width in grid_thw:
merged_h, merged_w = height // merge_size, width // merge_size
# 生成2D网格位置
block_rows = torch.arange(merged_h, device=device)
block_cols = torch.arange(merged_w, device=device)
intra_row = torch.arange(merge_size, device=device)
intra_col = torch.arange(merge_size, device=device)
# 计算每个patch内每个位置的全局坐标
row_idx = block_rows[:, None, None, None] * merge_size + intra_row[None, None, :, None]
col_idx = block_cols[None, :, None, None] * merge_size + intra_col[None, None, None, :]
row_idx = row_idx.expand(merged_h, merged_w, merge_size, merge_size).reshape(-1)
col_idx = col_idx.expand(merged_h, merged_w, merge_size, merge_size).reshape(-1)
coords = torch.stack((row_idx, col_idx), dim=-1) # (H*W, 2)
if num_frames > 1:
coords = coords.repeat(num_frames, 1) # 视频帧重复
num_tokens = coords.shape[0]
pos_ids[offset : offset + num_tokens] = coords
offset += num_tokens
# 查表获取位置编码
embeddings = freq_table[pos_ids] # (total_tokens, 2, dim//2)
embeddings = embeddings.flatten(1) # (total_tokens, dim)
return embeddings应用到注意力:
def apply_rotary_pos_emb_vision(
q: torch.Tensor, k: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor
) -> tuple[torch.Tensor, torch.Tensor]:
orig_q_dtype = q.dtype
orig_k_dtype = k.dtype
q, k = q.float(), k.float()
cos, sin = cos.unsqueeze(-2).float(), sin.unsqueeze(-2).float()
# 标准RoPE旋转
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed.to(orig_q_dtype), k_embed.to(orig_k_dtype)文本RoPE - 3D多模态位置编码:
在 Qwen3VLTextRotaryEmbedding 中,继承自 LlamaRotaryEmbedding 并扩展为3D:
class Qwen3VLTextRotaryEmbedding(LlamaRotaryEmbedding):
def __init__(self, config: Qwen3VLTextConfig, device=None):
super().__init__(config, device=device)
# mrope_section定义T,H,W各占用的维度数
self.mrope_section = config.rope_parameters.get("mrope_section", [24, 20, 20])
@torch.no_grad()
def forward(self, x, position_ids):
# position_ids扩展为3维: (3, bs, seq_len)
if position_ids.ndim == 2:
position_ids = position_ids[None, ...].expand(3, position_ids.shape[0], -1)
# 为T,H,W分别计算频率
inv_freq_expanded = self.inv_freq[None, None, :, None].float().expand(3, position_ids.shape[1], -1, 1)
position_ids_expanded = position_ids[:, :, None, :].float() # (3, bs, 1, seq_len)
with torch.autocast(device_type=device_type, enabled=False):
# 分别计算三个维度的频率
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(2, 3)
# 应用交错MRoPE
freqs = self.apply_interleaved_mrope(freqs, self.mrope_section)
emb = torch.cat((freqs, freqs), dim=-1)
cos = emb.cos() * self.attention_scaling
sin = emb.sin() * self.attention_scaling
return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)对比总结:
| 维度 | 视觉RoPE | 文本RoPE |
|---|---|---|
| 位置维度 | 2D (H, W) | 3D (T, H, W) |
| 频率生成 | 单一频率表 | 三个独立频率表 |
| 交错策略 | 无需交错 | MRoPE-Interleave |
| 应用范围 | 仅视觉tokens | 文本+视觉tokens |
| 时间建模 | 通过3D卷积 | 通过位置编码 |
| 配置参数 | theta=10000 | theta=5000000 (更大) |
设计考量:
- 视觉特性: 图像/视频的空间结构是主要关注点,2D RoPE足够表达空间关系
- 文本多模态: 文本序列中混合了纯文本和视觉tokens,需要统一的3D位置编码框架
- 长序列支持: 文本RoPE使用更大的theta值,支持更长的上下文
- 计算效率: 视觉RoPE更简单,减少视觉编码器的计算负担
实际效果: 这种差异化设计使得每个模态都能用最适合的方式编码位置信息,既保证了性能又优化了效率。
Qwen3-VL 实现了灵活的视频帧采样策略,能够根据视频特性和计算资源动态调整采样方式,同时通过 VideoMetadata 精确管理视频的时间信息。
帧采样核心方法:
在 Qwen3VLVideoProcessor.sample_frames 中:
def sample_frames(
self,
metadata: VideoMetadata,
num_frames: Optional[int] = None,
fps: Optional[Union[int, float]] = None,
**kwargs,
):
"""
默认采样函数,在0到总帧数之间均匀采样指定数量的帧。
如果传入fps,则按每秒fps帧的速率均匀采样。
num_frames和fps参数互斥。
"""
if fps is not None and num_frames is not None:
raise ValueError("`num_frames` and `fps` are mutually exclusive arguments!")
total_num_frames = metadata.total_num_frames
fps = fps if fps is not None else self.fps # 默认fps=2
# 根据fps计算需要采样的帧数
if num_frames is None and fps is not None:
if metadata.fps is None:
metadata.fps = 24 # 默认假设24fps
logger.warning_once(
"Asked to sample `fps` frames per second but no video metadata was provided. "
"Defaulting to `fps=24`. Please provide `video_metadata` for more accurate results."
)
# 计算公式: 采样帧数 = 总帧数 / 原始fps * 目标fps
num_frames = int(total_num_frames / metadata.fps * fps)
# 限制在[min_frames, max_frames]范围内
num_frames = min(max(num_frames, self.min_frames), self.max_frames, total_num_frames)
if num_frames is None:
num_frames = min(max(total_num_frames, self.min_frames), self.max_frames)
# 均匀采样
indices = np.linspace(0, total_num_frames - 1, num_frames).round().astype(int)
return indices采样策略分析:
- 均匀采样: 使用
np.linspace确保采样帧在时间上均匀分布 - FPS自适应: 根据原始视频fps和目标fps动态调整采样数量
- 边界保护: 通过
min_frames和max_frames控制计算量
VideoMetadata 数据结构:
@dataclass
class VideoMetadata:
"""视频元数据,包含时间信息"""
total_num_frames: int # 视频总帧数
fps: Optional[float] = None # 视频帧率
duration: Optional[float] = None # 视频时长(秒)
frames_indices: Optional[np.ndarray] = None # 实际采样的帧索引元数据在时间戳计算中的应用:
在 Qwen3VLProcessor._calculate_timestamps 中使用元数据:
def _calculate_timestamps(self, indices: Union[list[int], np.ndarray], video_fps: float, merge_size: int = 2):
if not isinstance(indices, list):
indices = indices.tolist()
# 确保帧数对齐
if len(indices) % merge_size != 0:
indices.extend(indices[-1] for _ in range(merge_size - len(indices) % merge_size))
# 根据帧索引和fps计算时间戳
timestamps = [idx / video_fps for idx in indices]
# 时间patch内取平均
timestamps = [
(timestamps[i] + timestamps[i + merge_size - 1]) / 2
for i in range(0, len(timestamps), merge_size)
]
return timestamps在Processor中的完整流程:
def __call__(self, images=None, text=None, videos=None, **kwargs):
# ... 图像处理
if videos is not None:
# 视频处理,返回元数据
videos_inputs = self.video_processor(videos=videos, **output_kwargs["videos_kwargs"])
video_grid_thw = videos_inputs["video_grid_thw"]
video_metadata = videos_inputs.get("video_metadata") # 获取元数据
# 使用元数据构建时间戳
if video_grid_thw is not None:
for i in range(len(text)):
while self.video_token in text[i]:
metadata = video_metadata[index] # 获取当前视频的元数据
# 检查fps是否可用
if metadata.fps is None:
logger.warning_once("Defaulting to fps=24...")
metadata.fps = 24
# 计算时间戳
curr_timestamp = self._calculate_timestamps(
metadata.frames_indices, # 使用实际采样的帧索引
metadata.fps,
self.video_processor.merge_size,
)
# 构建带时间戳的占位符
video_placeholder = ""
for frame_idx in range(video_grid_thw[index][0]):
curr_time = curr_timestamp[frame_idx]
video_placeholder += f"<{curr_time:.1f} seconds>"
video_placeholder += (
self.vision_start_token +
"<|placeholder|>" * frame_seqlen +
self.vision_end_token
)
text[i] = text[i].replace(self.video_token, video_placeholder, 1)
index += 1采样示例:
假设一个30秒、30fps的视频(总共900帧):
# 场景1: 按fps采样
metadata = VideoMetadata(total_num_frames=900, fps=30.0)
indices = sample_frames(metadata, fps=2) # 目标2fps
# 结果: 采样60帧,indices = [0, 15, 30, ..., 885]
# 场景2: 按帧数采样
indices = sample_frames(metadata, num_frames=32)
# 结果: 均匀采样32帧,indices = [0, 28, 56, ..., 872]
# 场景3: 自动限制
metadata = VideoMetadata(total_num_frames=10000, fps=30.0) # 超长视频
indices = sample_frames(metadata, fps=2)
# 结果: 限制在max_frames=768,不会超出技术优势:
- 灵活性: 支持按帧数或fps两种采样方式
- 精确性: 通过元数据精确计算每帧的时间戳
- 鲁棒性: 对缺失fps的情况有默认处理
- 可控性: 通过min/max_frames控制计算资源
形状分组机制 - group_videos_by_shape:
在 video_utils.py 中实现了按形状分组的工具函数:
def group_videos_by_shape(videos: list[torch.Tensor]) -> tuple[dict, list]:
"""
将视频按形状分组,相同形状的视频可以stack在一起批处理
Returns:
grouped_videos: {shape: stacked_tensor} 字典
grouped_videos_index: 记录原始顺序的索引列表
"""
shape_to_videos = {}
grouped_videos_index = []
for idx, video in enumerate(videos):
shape = tuple(video.shape)
if shape not in shape_to_videos:
shape_to_videos[shape] = []
shape_to_videos[shape].append(video)
grouped_videos_index.append((shape, len(shape_to_videos[shape]) - 1))
# Stack相同形状的视频
grouped_videos = {
shape: torch.stack(vids, dim=0)
for shape, vids in shape_to_videos.items()
}
return grouped_videos, grouped_videos_index
def reorder_videos(grouped_videos: dict, grouped_videos_index: list) -> list[torch.Tensor]:
"""根据索引恢复原始顺序"""
videos = []
for shape, idx in grouped_videos_index:
videos.append(grouped_videos[shape][idx])
return videos在视频预处理中的应用:
在 Qwen3VLVideoProcessor._preprocess 中:
def _preprocess(
self,
videos: list[torch.Tensor],
do_resize: bool = True,
**kwargs,
):
# 第一次分组: 按原始形状
grouped_videos, grouped_videos_index = group_videos_by_shape(videos)
resized_videos_grouped = {}
# 对每组相同形状的视频批量处理
for shape, stacked_videos in grouped_videos.items():
B, T, C, H, W = stacked_videos.shape
if do_resize:
# 计算该组的目标尺寸
resized_height, resized_width = smart_resize(
num_frames=T,
height=H,
width=W,
temporal_factor=temporal_patch_size,
factor=patch_size * merge_size,
min_pixels=size.shortest_edge,
max_pixels=size.longest_edge,
)
# 批量resize
stacked_videos = stacked_videos.view(B * T, C, H, W)
stacked_videos = self.resize(
stacked_videos,
size=SizeDict(height=resized_height, width=resized_width),
interpolation=interpolation,
)
stacked_videos = stacked_videos.view(B, T, C, resized_height, resized_width)
resized_videos_grouped[shape] = stacked_videos
# 恢复原始顺序
resized_videos = reorder_videos(resized_videos_grouped, grouped_videos_index)
# 第二次分组: 按resize后的形状(可能不同组变成相同了)
grouped_videos, grouped_videos_index = group_videos_by_shape(resized_videos)
processed_videos_grouped = {}
processed_grids = {}
for shape, stacked_videos in grouped_videos.items():
# 批量处理相同形状的视频
# ... 归一化、patch化等操作
batch_size, grid_t, channel = patches.shape[:3]
grid_h, grid_w = resized_height // patch_size, resized_width // patch_size
# 记录每个视频的grid信息
processed_grids[shape] = [[grid_t, grid_h, grid_w]] * batch_size
processed_videos_grouped[shape] = flatten_patches
# 再次恢复原始顺序
processed_videos = reorder_videos(processed_videos_grouped, grouped_videos_index)
processed_grids = reorder_videos(processed_grids, grouped_videos_index)
# 最终拼接
pixel_values_videos = torch.cat(processed_videos, dim=0)
video_grid_thw = torch.tensor(processed_grids)
return BatchFeature(data={
"pixel_values_videos": pixel_values_videos,
"video_grid_thw": video_grid_thw,
})生成时的beam search扩展:
在 Qwen3VLForConditionalGeneration._expand_inputs_for_generation 中:
def _expand_inputs_for_generation(
self,
expand_size: int = 1, # beam size
is_encoder_decoder: bool = False,
input_ids: Optional[torch.LongTensor] = None,
**model_kwargs,
) -> tuple[torch.LongTensor, dict[str, Any]]:
"""
重写以支持没有batch维度的视觉张量扩展
pixel_values.shape[0] 是所有样本的图像序列长度之和
image_grid_thw.shape[0] 是所有样本的图像数量之和
"""
if expand_size == 1:
return input_ids, model_kwargs
visual_keys = ["pixel_values", "image_grid_thw", "pixel_values_videos", "video_grid_thw"]
def _expand_dict_for_generation_visual(dict_to_expand):
image_grid_thw = model_kwargs.get("image_grid_thw", None)
video_grid_thw = model_kwargs.get("video_grid_thw", None)
# 获取每个样本的图像/视频数量
image_nums, video_nums = self._get_image_nums_and_video_nums(
input_ids, inputs_embeds=model_kwargs.get("inputs_embeds", None)
)
def _repeat_interleave_samples(x, lengths, repeat_times):
"""按样本重复,而非简单的整体重复"""
samples = torch.split(x, lengths)
repeat_args = [repeat_times] + [1] * (x.dim() - 1)
result = torch.cat([sample.repeat(*repeat_args) for sample in samples], dim=0)
return result
for key in dict_to_expand:
if key == "pixel_values":
# 计算每个样本的图像序列长度
samples = torch.split(image_grid_thw, list(image_nums))
lengths = [torch.prod(sample, dim=1).sum() for sample in samples]
dict_to_expand[key] = _repeat_interleave_samples(
dict_to_expand[key], lengths=lengths, repeat_times=expand_size
)
elif key == "image_grid_thw":
# 按样本的图像数量分割并重复
lengths = list(image_nums)
dict_to_expand[key] = _repeat_interleave_samples(
dict_to_expand[key], lengths=lengths, repeat_times=expand_size
)
elif key == "pixel_values_videos":
samples = torch.split(video_grid_thw, list(video_nums))
lengths = [torch.prod(sample, dim=1).sum() for sample in samples]
dict_to_expand[key] = _repeat_interleave_samples(
dict_to_expand[key], lengths=lengths, repeat_times=expand_size
)
elif key == "video_grid_thw":
lengths = list(video_nums)
dict_to_expand[key] = _repeat_interleave_samples(
dict_to_expand[key], lengths=lengths, repeat_times=expand_size
)
return dict_to_expand
# 先扩展视觉输入
model_kwargs = _expand_dict_for_generation_visual(model_kwargs)
# 再扩展文本输入
if input_ids is not None:
input_ids = input_ids.repeat_interleave(expand_size, dim=0)
# 扩展其他非视觉输入
def _expand_dict_for_generation(dict_to_expand):
for key in dict_to_expand:
if (key != "cache_position" and
dict_to_expand[key] is not None and
isinstance(dict_to_expand[key], torch.Tensor) and
key not in visual_keys):
dict_to_expand[key] = dict_to_expand[key].repeat_interleave(expand_size, dim=0)
return dict_to_expand
model_kwargs = _expand_dict_for_generation(model_kwargs)
return input_ids, model_kwargs技术优势:
- 计算效率: 相同形状的输入可以批量处理,充分利用GPU并行能力
- 内存优化: 避免padding到最大尺寸造成的内存浪费
- 灵活性: 支持任意组合的异构输入
- 生成兼容: beam search等生成策略能正确处理复杂的视觉输入结构
Qwen3.5 的核心定位可以概括为:面向原生多模态智能体的高效混合架构大模型。相对 Qwen3,它不只是“更大”,而是在三个关键层面做了体系级升级:
-
架构层面:从纯 Transformer 到混合注意力 + 稀疏 MoE 的 VLM
- 引入 Gated DeltaNet 线性注意力 与少量 全局自注意力 的混合堆叠:
- 大约 70–75% 的层是线性注意力(Gated DeltaNet)
- 25–30% 的层仍保留标准全局自注意力
- 主干语言模型本身是 稀疏 MoE(Mixture-of-Experts),总参数约 397B,但推理时仅激活约 17B 参数。
- 引入 Gated DeltaNet 线性注意力 与少量 全局自注意力 的混合堆叠:
-
多模态层面:原生 VLM 而非“拼接式多模态”
- 使用 ViT 视觉编码器,将图像/视频帧编码为视觉 token,与文本 token 一起喂入同一个 Transformer 栈(early fusion)。
- 这与早期“视觉模型 + 文本模型 + 中间对齐模块”的做法不同,跨模态交互发生在模型的很早阶段,对图文、视频+字幕这类复杂多模态任务更友好。
-
智能体与训练基础设施层面:Agent-first 设计
- 训练侧引入 异步强化学习(asynchronous RL)框架,允许大规模 Agent 脚本并行采样、异步回传奖励。
- 推理侧围绕 长上下文(最高 1M tokens)、工具调用、多模态对话 做深度优化,托管版 Qwen3.5-Plus 内置搜索、代码执行、文件处理等工具,并支持 Auto/Thinking/Fast 等推理模式。
综合来看,Qwen3.5 把 高容量(397B 总参)、高效率(17B 激活 + 线性注意力)、多模态(原生 VLM)和智能体训练基础设施 打包在一起,面向的是“真实世界复杂任务”和“企业级多模态 Copilot/Agent”。
21、Qwen3.5 的一个关键卖点是混合注意力:Gated DeltaNet + 全局注意力。请详细说说 Gated DeltaNet 属于哪类线性注意力,它是如何在保持表达能力的前提下降低复杂度的?3:1 的混合比例有什么技术考量?
Gated DeltaNet 可以理解为一种具备门控与增量状态更新的线性注意力 / SSM 变体,用于替代大部分标准自注意力层,核心目标是把计算和内存复杂度从 O(n²) 降到近似 O(n)。
-
基本思想:用“递归状态 + 门控”近似注意力
- 传统 Attention 要显式构造 n×n 的注意力矩阵,复杂度 O(n²)。
- Gated DeltaNet 将序列视为一个递归动态系统,每个 token 的表征依赖于前一时刻的“隐藏状态” hₜ₋₁ 和当前输入 xₜ:
- hₜ = Gate(hₜ₋₁, xₜ) + Delta(xₜ)
(这里 Gate 是门控函数,Delta 是增量更新)
- hₜ = Gate(hₜ₋₁, xₜ) + Delta(xₜ)
- 注意力“聚合历史信息”的效果被 状态 hₜ 的更新方程 近似实现,不再显式计算所有 token 两两之间的注意力得分。
-
门控机制的作用
- 引入类似 GRU/LSTM 的 update/reset gate,控制旧状态保留多少、新信息写入多少:
- zₜ = σ(Wᶻ xₜ + Uᶻ hₜ₋₁)
- hₜ = (1 − zₜ) ⊙ hₜ₋₁ + zₜ ⊙ ˜hₜ
- 这样可以:
- 减缓长序列中信息衰减问题;
- 提升对“关键 token”长程依赖的建模能力,缓解纯线性注意力经常出现的“长程依赖缺失”问题。
- 引入类似 GRU/LSTM 的 update/reset gate,控制旧状态保留多少、新信息写入多少:
-
为什么采用 3:1 的混合布局?
- 约 3 层 Gated DeltaNet + 1 层全局自注意力交替堆叠:
- 线性层:负责大部分 token 间的局部/中程依赖建模,成本线性、适合长上下文。
- 全局层:周期性地“重建”完整的全局相关性图,使模型不会完全丢失传统 Attention 在复杂推理、全局对齐方面的优势。
- 实测上:
- 在线性层比例 >75% 时,长上下文吞吐提升显著(官方给出的对比是 32K 上下文可以比上一代大模型快 8.6 倍,256K 上可以快到 19 倍量级);
- 而适当插入全局注意力层,能把线性注意力在“非局部对齐”和“长距推理”上的损失控制在可接受范围内(在常见语言、推理 benchmark 上接近甚至对标闭源旗舰模型)。
- 约 3 层 Gated DeltaNet + 1 层全局自注意力交替堆叠:
-
工程收益
- 线性注意力层的 KV Cache 不再随序列长度线性增长,推理显存压力显著下降;加上 FP8 量化,长上下文/多并发场景下吞吐和成本优势非常明显。
Qwen3.5 的语言主干是典型的 稀疏 Mixture-of-Experts(MoE)Transformer,关键点在于“容量极大,但单 token 激活专家极少”。
-
专家组织方式
- 模型内部包含大量 FFN 专家子网络(experts),总参数量堆到 ~397B 量级。
- 但对于任意一个 token,它只会被路由到 少数几个专家(如 Top-2),因此前向计算涉及的参数远小于总参量。
-
路由策略(Routing)
- 每个 MoE 层有一个门控网络(router / gate),对输入 token 表征 x 计算路由得分:
- logits = W_gate · x
然后取 Top-k(例如 k=2)专家:- 选出得分最高的两个专家 e₁, e₂
- 对对应输出做加权相加:
- y = α₁ · expert₁(x) + α₂ · expert₂(x)
其中 αᵢ = softmax(topk_logits)。
- y = α₁ · expert₁(x) + α₂ · expert₂(x)
- logits = W_gate · x
- 多数实现会在路由 logits 中加入轻微噪声(noisy top-k),提升探索性和训练鲁棒性。
- 每个 MoE 层有一个门控网络(router / gate),对输入 token 表征 x 计算路由得分:
-
负载均衡与稳定性
- 为防止部分专家“被喂饱”、部分“吃不饱”,MoE 训练一般会加一个 负载均衡正则项:
- 约束每个专家被选中的概率、实际负载与均匀分布不要差太多,从而保证算力利用率和泛化。
- Qwen3.5 在此基础上,还要适配多模态和长上下文:
- 不同模态(文本 vs 视觉)可能更偏好不同专家,路由层需要在训练中学到这种“模态特化”;
- 超长序列下的梯度回传要考虑专家之间的梯度方差,防止个别专家梯度爆炸。
- 为防止部分专家“被喂饱”、部分“吃不饱”,MoE 训练一般会加一个 负载均衡正则项:
-
为什么是 17B 激活?
-
简化理解:假设单个专家容量 ~数十亿参数,单个 token 仅路由到 2 个专家 + 主干非 MoE 层(embedding、attention、LN)。
-
所以实际执行过程中,每个 token 的前向路径只触及约 17B 参数,计算量接近一个 10B–20B 级稠密模型,而容量却是 397B 级。
-
这样做的好处是:训练时模型表达空间巨大,对多任务、多语言、多模态适应性强;推理时成本接近中型模型,具备很好的性价比。
Qwen3.5 的原生多模态主要体现在统一编码、统一 Transformer 栈、统一训练目标这三点:
-
统一编码
- 图像/视频通过 ViT 或 3D ViT 编码为 patch/帧 token 序列;
- 文本使用统一 tokenizer(扩展到 ~250k 词表,对多语言和多模态标记都更友好);
- 最终所有 token——无论是文字还是视觉——都被映射到同一向量空间,同一维度的 embedding。
-
统一 Transformer 栈(early fusion)
- 视觉 token 和文本 token 在输入层之后直接混合,共同经过 Gated DeltaNet + global attention + MoE 的共享层。
- 这意味着:
- 模型可以在极早期就学习“文字-图像-布局”的交互关系;
- 对文档、UI 截图、图表等信息密集型图像的理解更自然,不需要额外 layout-aware 模块。
-
统一训练目标
- 预训练阶段对多模态数据做统一的生成/掩码预测任务,例如:
- 读图写字幕、图文对 QA;
- 文档 OCR + 结构化理解;
- 视频帧 + 字幕的联合建模(理解时序 + 语义)。
- 以统一的 next-token prediction / seq2seq 风格训练,使得模型的语言头自然具备“看图说话 / 看视频说话”的能力。
- 预训练阶段对多模态数据做统一的生成/掩码预测任务,例如:
-
效果上的优势
- 在真实图片、文档、UI、表格等 benchmark(如 RealWorldQA、MMLongBench-Doc 等)上,相比上一代 Qwen3-VL 有明显提升;
- 在视频理解上:
- 通过时间位置编码 + 时序注意力,可以回答诸如“视频第 N 秒发生了什么”、“这个动作发生了几次”之类的问题;
- 对长视频进行结构化摘要,而不是只看几个关键帧。
简单说,Qwen3.5 不再是“一个 LLM 外接一个视觉插件”,而是从底层就是一个对多模态统一建模的大模型,这对构建“看屏幕操作界面”“看 PDF 答题”“看监控视频做分析”的智能体非常关键。
1M 级上下文主要依赖三个技术支柱:
-
线性注意力奠定计算复杂度基础
- 大量使用 Gated DeltaNet 将注意力复杂度从 O(n²) 降为近似 O(n),让 10⁵–10⁶ 级别序列在算力上变得可行;
- 少量全局自注意力层做全局对齐,但整体仍保持接近线性复杂度。
-
KV Cache 与状态管理优化
- FP8 全链路推理:对 KV Cache 使用 FP8 量化,使同样长度的上下文缓存显存占用减少约 50%,这是从“物理容量”上解决问题;
- 分块/分段机制:
- 将超长上下文切分成多个 segment,每个 segment 内局部注意力、跨 segment 使用压缩状态或稀疏连接;
- 对很久远但不再关键的上下文,可以只保留压缩后的“记忆 token”,减少 cache 压力。
- 部分实现会使用状态复用/池化,比如每若干 token 对隐藏状态做聚合,作为更粗粒度的记忆。
-
推理系统级优化
- 推测解码(speculative decoding):利用小模型或 draft 解码器先生成一批 token,再用大模型做验证,减少大模型实际前向次数;
- 动态 batch & 流式调度:在服务端合理合并多个请求,提升 GPU 利用率;
- 针对超长上下文场景做特化 kernel 和调度,把注意力、MoE 路由等算子做成高效的 CUDA/Fused Kernel。
整体效果是:上下文长度从 32K 提升到数十万乃至 1M 的同时,吞吐和延迟没有指数级恶化,而是控制在工程可接受范围内(官方对比数据显示,长上下文下对前代模型有数倍 ~ 数十倍吞吐提升)。
传统的同步 RL(如经典 PPO pipeline)通常是“采样端 – 训练端 强耦合”:
采样(rollout)完成一批 episode → 汇总 → 统一更新 → 再开始下一轮,整个过程容易被最慢的任务拖慢,扩展到大规模 Agent 场景会非常低效。
Qwen3.5 的 异步 RL 框架在三个维度上做了拆分和解耦:
-
采样与训练彻底异步
- 大量智能体进程(可能是数万甚至百万级)在不同环境中并行运行(网页、GUI、API 工具等),实时生成 (state, action, reward) 序列;
- 这些数据被写入分布式缓冲区/消息队列,训练服务端按需拉取,而不是等待“所有人一起结束”;
- 这样快任务不会被慢任务阻塞,新数据可以源源不断补充,训练端处于持续高负载状态,GPU 利用率更高。
-
多模态、多任务统一框架
- 文本生成、多轮对话、工具调用、视觉交互(比如 UI 截图分析)都以统一的“序列决策”形式表征;
- 奖励可以来自:
- 规则(例如工具调用是否成功);
- 判别模型(例如一个评估模型给出的质量打分);
- 人类反馈(如评级)。
- 这些多源奖励通过异步框架统一汇入训练过程。
-
稳定性和工程可运维性
- 可在训练端做 优先级重放(优先使用有信息量的样本)、多任务混合;
- 遇到单个环境故障、网络抖动不会影响整体训练,只会少一部分采样源;
- 易于做 A/B 测试:不同策略的 Agent 可以并行跑,异步汇总结果进行对比更新。
在工具使用、多轮对话场景中,这意味着模型可以通过持续在线交互,不断从“真实任务执行结果”中学习,而不是只依赖静态监督数据;也为“会自己用搜索、会调用代码执行器”的 System 2 型智能体打下基础。
FP8 的核心价值在于:几乎不牺牲任务精度的前提下,把显存占用和算力开销大幅压缩。Qwen3.5 在这方面遵循“关键路径高精度、宽路径低精度”的策略:
-
FP8 使用的主要区域
- 大部分矩阵乘(GEMM)——包括注意力中的 QK、V 投影和 FFN 层——都采用 FP8 Tensor Core 做加速;
- KV Cache 也用 FP8 存储,大大减小缓存尺寸,这对于长上下文尤为关键。
-
保持高精度的关键模块
- 对数值敏感的层,如:
- 最顶部几层的 attention / FFN;
- Norm 层、Router(MoE 路由 logits);
- 通常会保留在 BF16 或 FP16,以避免累积误差对最终输出质量造成冲击。
- 对数值敏感的层,如:
-
精度保障手段
- Block-wise / per-channel scaling:
每一小块(如若干通道)都单独维护 scale,减少量化误差; - 在线监控溢出/下溢,配合 fallback 机制:如果检测到不稳定,会在运行时切回更高精度路径;
- 训练阶段会针对 FP8 路径做对齐校准,确保量化后模型和 BF16 版本在关键 benchmark 上的差距可控(通常在 1 分以内的 MMLU 波动)。
- Block-wise / per-channel scaling:
总体来说,FP8 不是简单“硬砍精度”,而是在 算子级别精细分配精度预算,在保持旗舰模型能力的同时,让大模型推理成本下降到可商用的水平。
基于公开信息和社区评测,大致可以这样概括 Qwen3.5 的能力画像:
-
语言与知识理解
- 在 MMLU、C-Eval、MMLU-Pro/Redux 等综合知识测试上,分数处于当前开源阵营第一梯队,对标新一代闭源旗舰;
- 多语言能力显著增强:
- 支持语言/方言从 100+ 扩展到 ~200 级别;
- 扩大 vocab 至约 250k,使小语种和特殊符号的编码更高效。
-
推理与 STEM 能力
- 在数学、逻辑推理、科学问答类 benchmark 上表现稳健,尤其是结合“thinking 模式/深度推理”配置时;
- 开源社区实测表明,在复杂链式推理、多步骤工具使用上,配合异步 RL 强化后的版本具有明显优势。
-
代码能力
- 虽然 Qwen 系列有专门的 Coder 分支,但 Qwen3.5 主线本身也具备较强代码生成和理解能力:
- 支持多语言代码生成、重构、调试建议、测试样例生成等;
- 托管版内置 Code Interpreter,可在代码执行反馈的闭环中自动迭代解决问题。
- 虽然 Qwen 系列有专门的 Coder 分支,但 Qwen3.5 主线本身也具备较强代码生成和理解能力:
-
多模态能力
- 图像:物体识别、场景描述、OCR、表格理解、UI/原型图到代码转化等任务表现优秀;
- 文档:对 PDF、扫描件、表格等文档结构化解析有较强能力,是企业知识库问答的重要基础;
- 视频:能够进行动作识别、情节总结、镜头切分和时间线对齐等操作,在真实视频 QA 任务上比上一代 VLM 有明显提升。
整体上,Qwen3.5 的定位不是“某一项能力极致”,而是 “在语言、多模态、代码和智能体能力上形成综合均衡的旗舰开源方案”,并凭借架构和推理优化在性价比上对闭源模型形成冲击。
可以从 算力、数据安全、迭代速度和控制权 四个维度来判断:
-
托管版 Qwen3.5-Plus
- 特点:
- 默认提供 1M tokens 上下文、FP8 优化、内置工具(搜索、代码执行、文件处理等);
- Qwen 团队持续在线对齐与安全更新,支持多种对话模式(Auto / Thinking / Fast)。
- 适用场景:
- 中小团队或不愿/不便自建大规模 GPU 集群;
- 对 工程集成和上线速度 要求高,希望直接通过云 API 接入;
- 对数据合规有云侧解决方案(如在对应区域的云部署),能接受部分数据在云上流转。
- 特点:
-
开源版 Qwen3.5-397B-A17B
- 特点:
- 权重完全开源,可自定义微调、部署策略、量化方案;
- 适合与自身基础设施深度耦合,例如专有云、本地 GPU 集群、混合部署。
- 适用场景:
- 大厂、科研机构,有雄厚算力并希望对模型 有完全控制权(包括参数访问、微调、内网部署);
- 对数据隐私有极高要求,需要 数据不出本地/不出国境;
- 希望在 Qwen3.5 架构基础上做二次研究或创新(例如进一步改造 MoE/注意力)。
- 特点:
-
一个常见实践组合
- 生产环境中:
- 高敏数据/边缘场景:本地部署一个中型版本(如 27B/35B 系列)做第一层处理;
- 公网/低敏任务:调用托管版 Qwen3.5-Plus 获得更高质量和工具能力。
- 研发环境中:
- 使用开源权重做内部微调和离线评估;
- 使用托管版做快速 POC 和业务验证。
- 生产环境中:
从“模型层 – Agent 层 – 工具层 – 数据/知识层 – 监控与反馈层”五层来设计:
-
模型层
- 主力模型:托管版 Qwen3.5-Plus(享受 1M 上下文、多模态和工具生态);
- 备选/本地模型:开源 Qwen3.5-397B-A17B 或中型变体(用于内部高敏场景)。
-
Agent 层
- 使用 Qwen 官方的 Agent 框架或类似 LangChain 的 orchestration:
- Planner: 负责把用户需求分解为一系列子任务(阅读文档→抽取要点→比对多个来源→生成报告);
- Controller: 根据当前上下文决定调用哪些工具/检索/代码执行;
- Memory: 采用向量数据库存储长期记忆(历史对话、文档索引、任务执行结果)。
- 使用 Qwen 官方的 Agent 框架或类似 LangChain 的 orchestration:
-
工具层(Tooling)
- 搜索工具:内置 Web 搜索,用于实时知识获取;
- 代码执行工具:连接沙箱执行环境(Python/R/SQL),支持数据分析、脚本运行;
- 文件解析工具:将企业 PDF、Word、Excel、PPT 等转为结构化文本/表格,作为多模态输入;
- UI 操作工具:结合 Qwen3.5 的视觉能力,对 UI 截图进行语义理解并驱动自动化操作(相当于 GUI Agent)。
-
数据/知识层
- 建立企业内部知识索引:
- 文档向量化(包括文本和截图/扫描件),使用 Qwen3.5 的多模态编码能力;
- 插件形式的“知识库检索”工具,Agent 在回答问题前先检索相关文档再总结(RAG)。
- 对财报、报表等结构化数据,构造专门的数据 API 工具,Agent 可通过调用这些工具做精准分析。
- 建立企业内部知识索引:
-
监控与反馈层
- 日志与度量:
- 监控调用频次、延迟、失败率、token 消耗;
- 监控错误类型(事实性错误、安全越权、工具调用失败等)。
- 反馈闭环:
- 收集用户评分 + 漏标问题作为 RL 训练数据;
- 利用 Qwen3.5 的异步 RL 框架持续进行对齐和策略优化。
- 日志与度量:
通过这样分层设计,可以充分用好 Qwen3.5 的:
- 原生多模态能力(看图/看 PDF/看界面);
- 长上下文(跨文档、跨会话关联分析);
- Agent + 工具使用能力(检索、代码执行、自动化操作);
最终形成一个“既能读懂复杂企业信息,又能主动操作工具和系统”的企业级 Copilot,而不仅仅是一个聊天问答机器人。