对于客户端 /v1/messages 的请求路由到sub2api的OpenAI的账号时,模型转换正确,但是/v1/messages 响应字段中的输入token数不正确。 /v1/messages 的响应中 input_tokens应该是要先减去缓存读的token数也就是 54006 - 50688 图一是sub2api的请求信息,图2是响应。图3是请求正常 /v1/messages 兼容的账号时的客户端响应,图4是请求正常 /v1/messages 兼容的账号时sub2api的响应。    
对于客户端 /v1/messages 的请求路由到sub2api的OpenAI的账号时,模型转换正确,但是/v1/messages 响应字段中的输入token数不正确。
/v1/messages 的响应中
input_tokens应该是要先减去缓存读的token数也就是 54006 - 50688

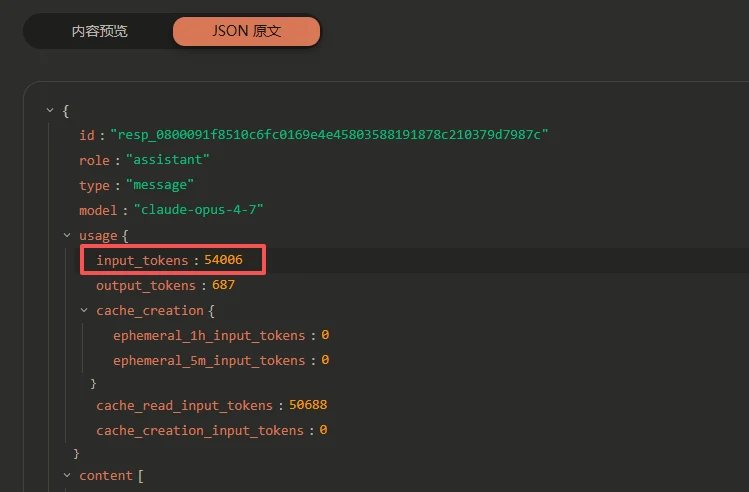
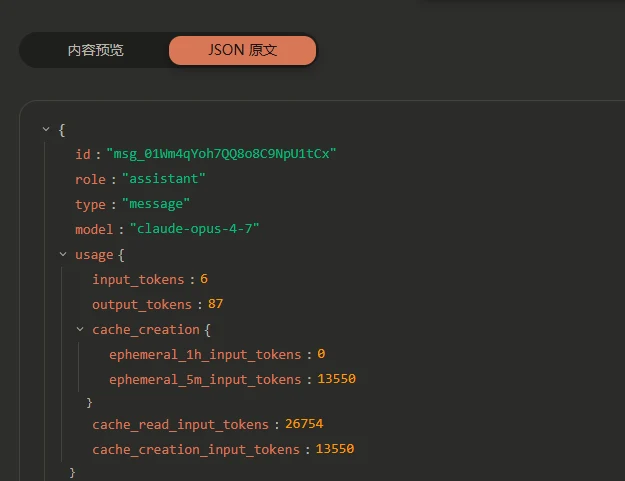

图一是sub2api的请求信息,图2是响应。图3是请求正常 /v1/messages 兼容的账号时的客户端响应,图4是请求正常 /v1/messages 兼容的账号时sub2api的响应。