You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
||||
71
71
72
-
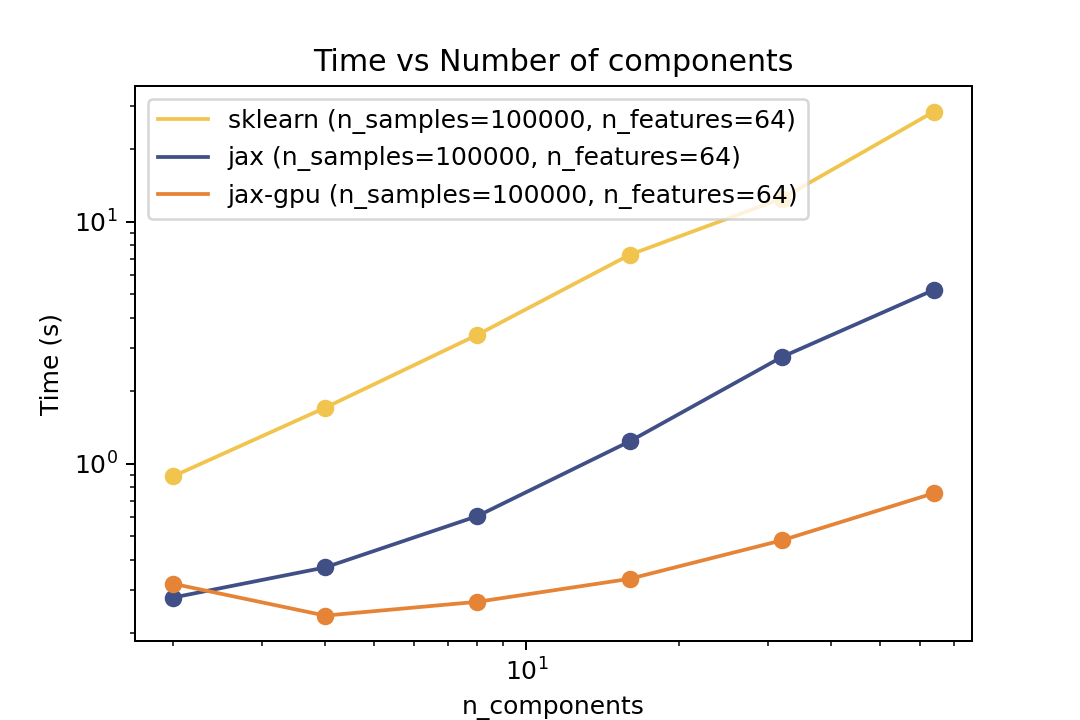
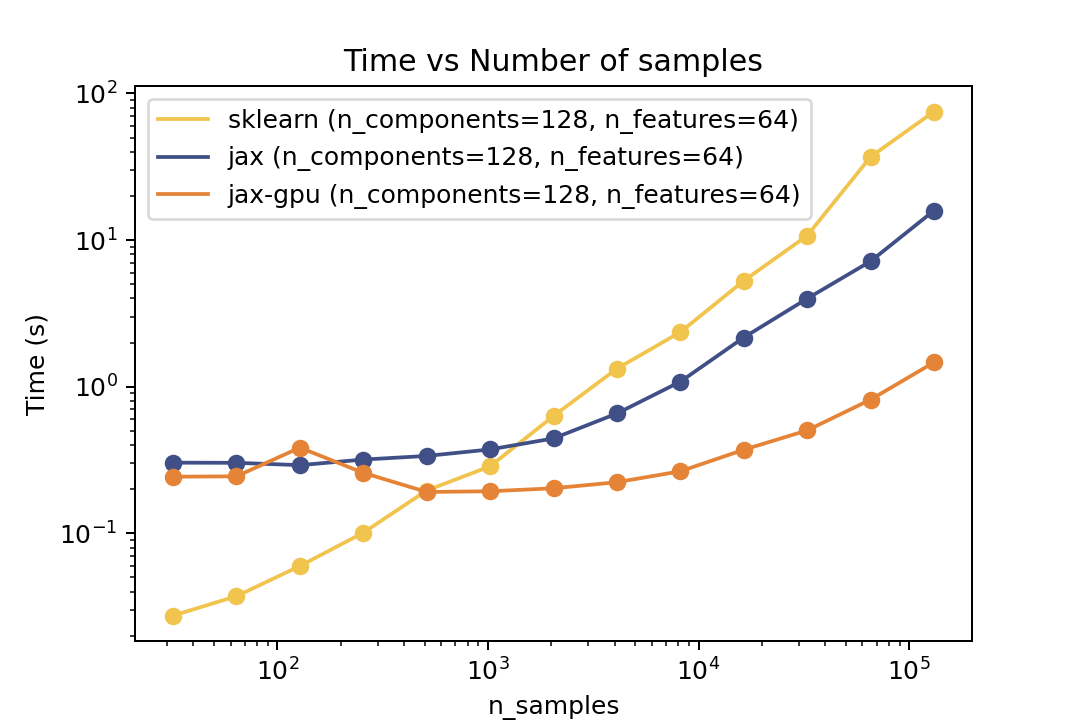
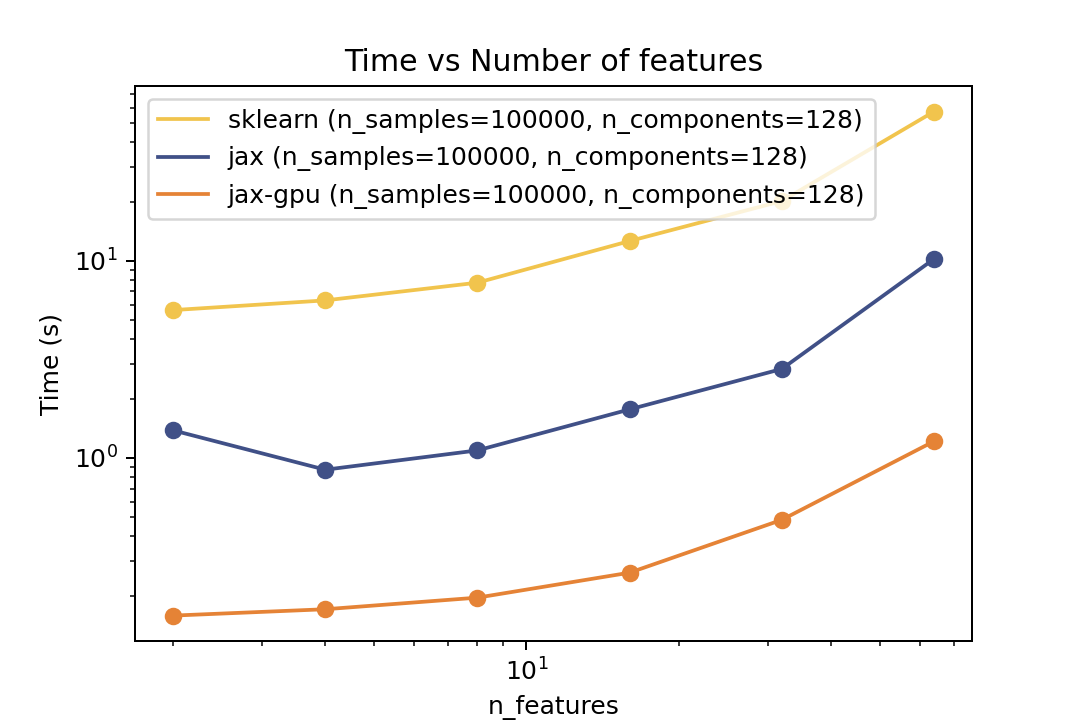
For prediction the speedup is around 2-3x for varying number of components and features. For the number of samples the cross-over point is around O(10^4) samples.
72
+
For prediction the speedup is around 5-6x for varying number of components and features and ~50x speedup on the GPU. For the number of samples the cross-over point is around O(10^3) samples.
73
73
74
74
### Training Time
75
75
76
76
| Time vs. Number of Components | Time vs. Number of Samples | Time vs. Number of Features |
||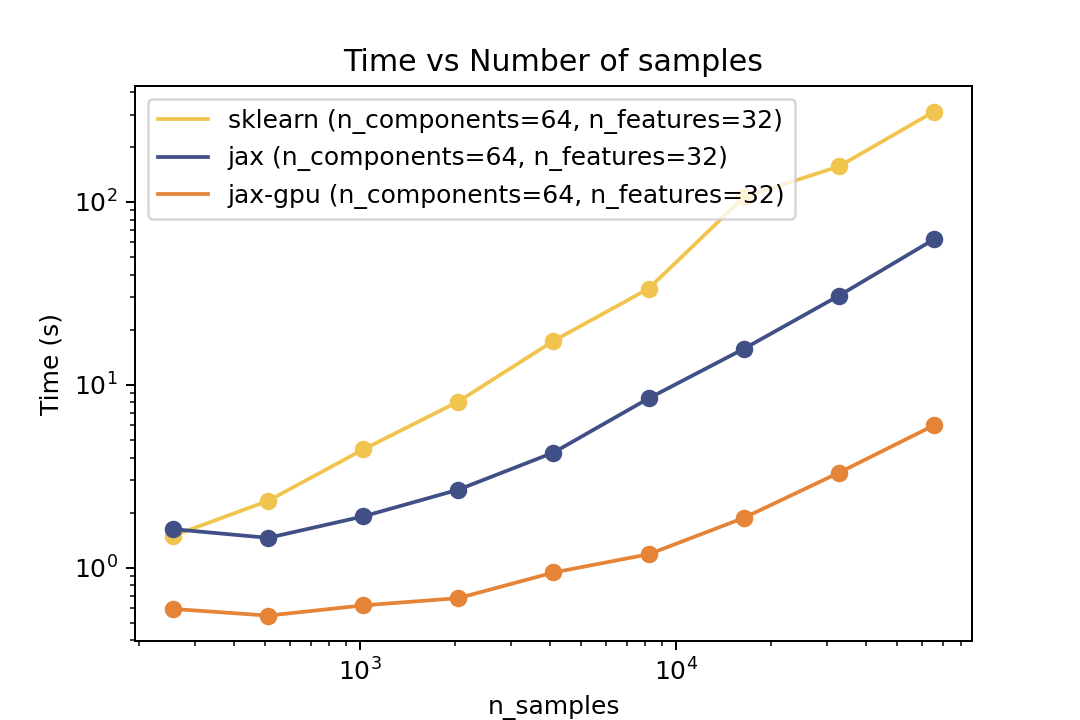|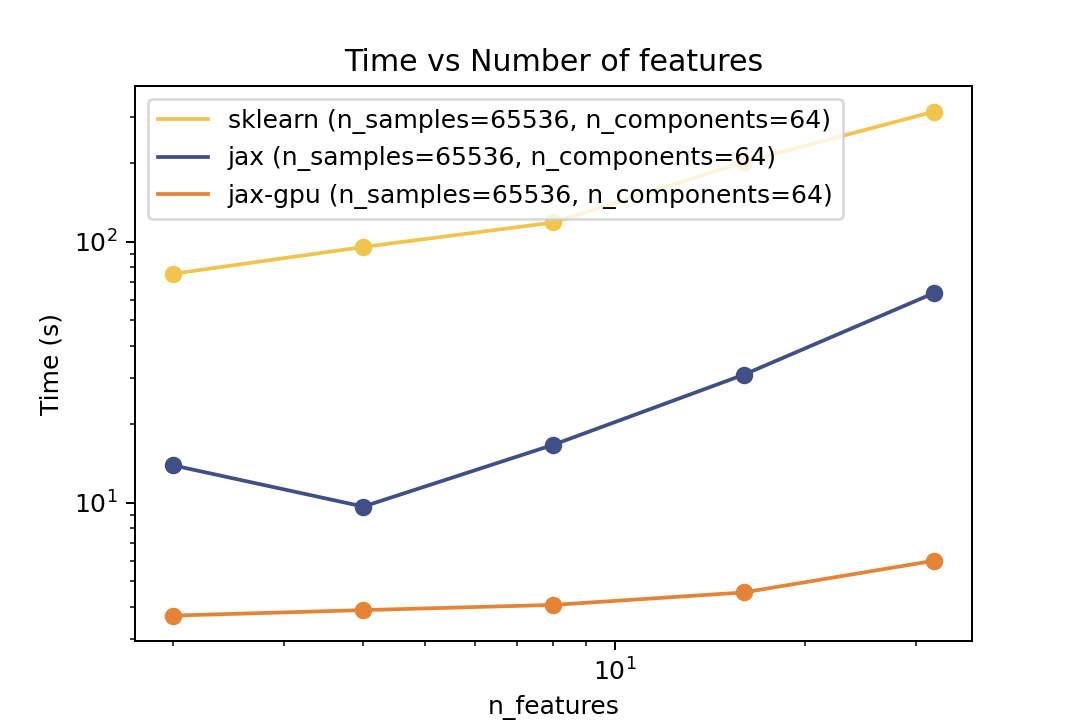|
79
79
80
-
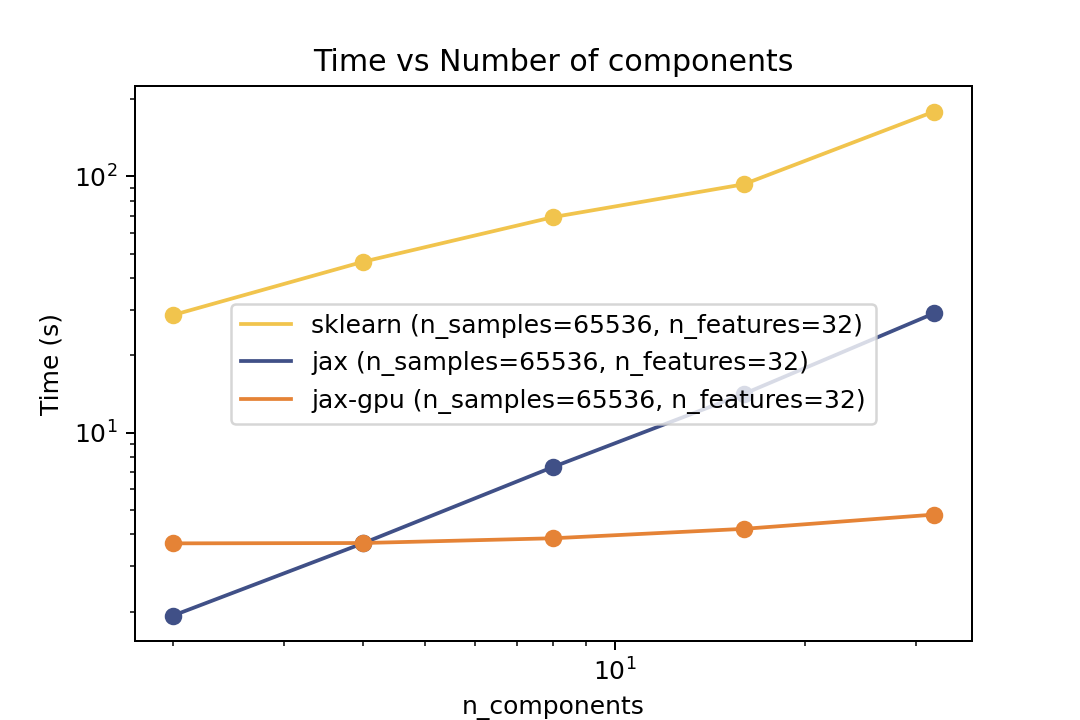
For training the speedup is around >10x on the same architecture and close to 100x speedup on the GPU. However there is no guarantee that it will converge to the same solution as Scikit-Learn. But there are some tests in the `tests` folder that compare the results of the two implementations which shows good agreement.
80
+
For training the speedup is around ~5-6x on the same architecture and ~50x speedup on the GPU. However there is no guarantee that it will converge to the same solution as Scikit-Learn. But there are some tests in the `tests` folder that compare the results of the two implementations which shows good agreement.
0 commit comments