Project Phase I
Welcome to the CoDist wiki!
Spring 2022 Project 1 Roadmap.
Our task was to develop a distributed system consisting of at least 3 microservices and 1 database technology. We were decided on the the type of architecture and the services we will be using for the project. We have mentioned below the Iterations of the architecture that was revised over the two weeks. After the announcement of the rules specific to the 4 member team, where they where needed to have 4 microservices and 2 database technologies, we had to carefully think of what service will be used for what and rethink the tech stack we will be using.
ITERATION 1
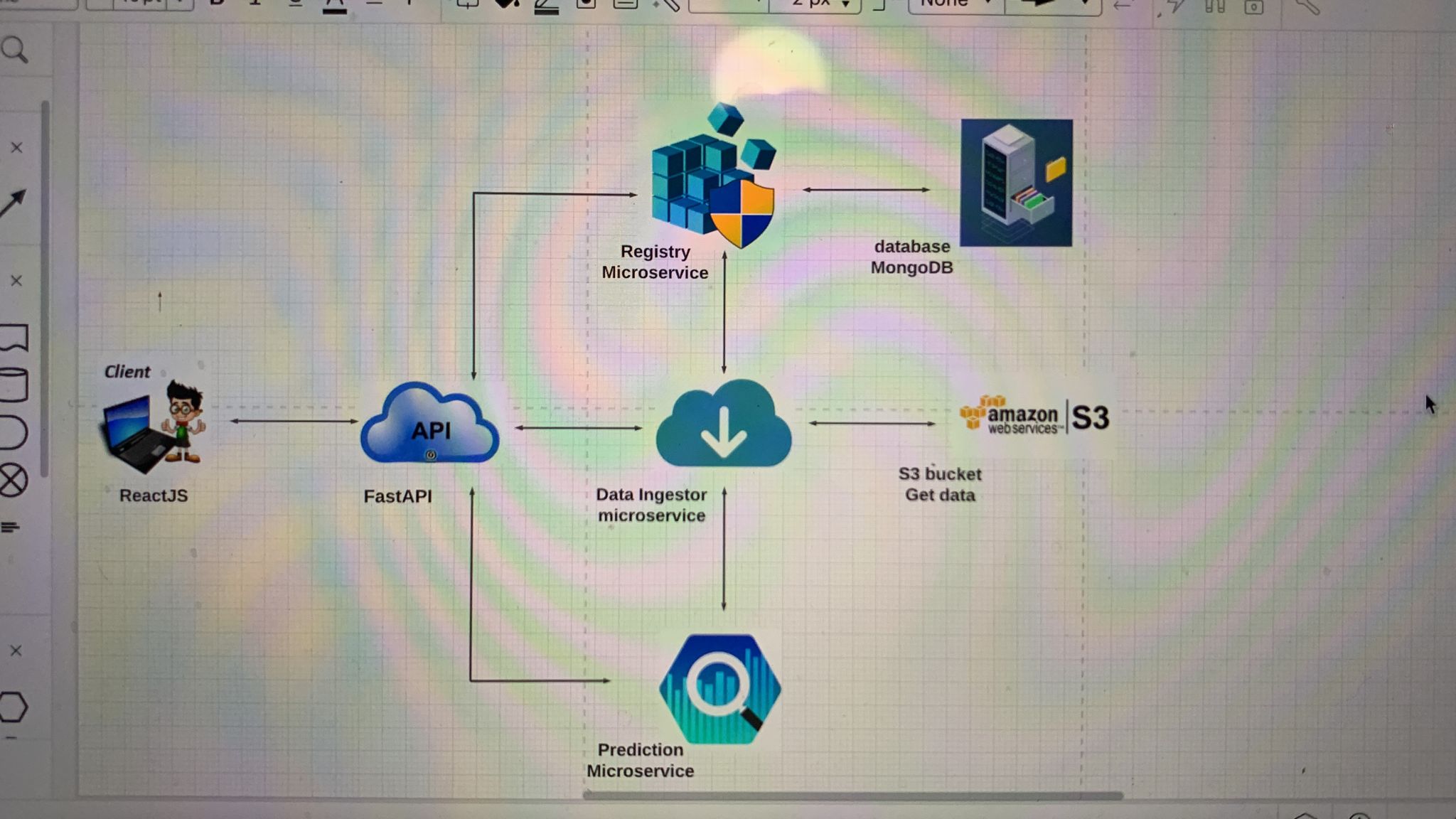
In the initial days of the first week we decided to go with this architecture, where the microservices
- API Gateway in Python using FastAPI.
- Registry Microservice NodeJS.
- Data Ingestor Microservice Java, Springboot.
- Plotting Microservice Python.
- MongoDB.
As we were developing and focusing on the architecture, and after discussion with other peers and TA, we realized that Python for API Gateway is not the most appropriate choice as it is not as fast as Java, and not hard coded which can be a requirement if we had to properly scale the system. This and other factors contributed to us switching to Java Spring Boot for API Gateway.
There were other changes as well. It is shown below.
ITERATION 2
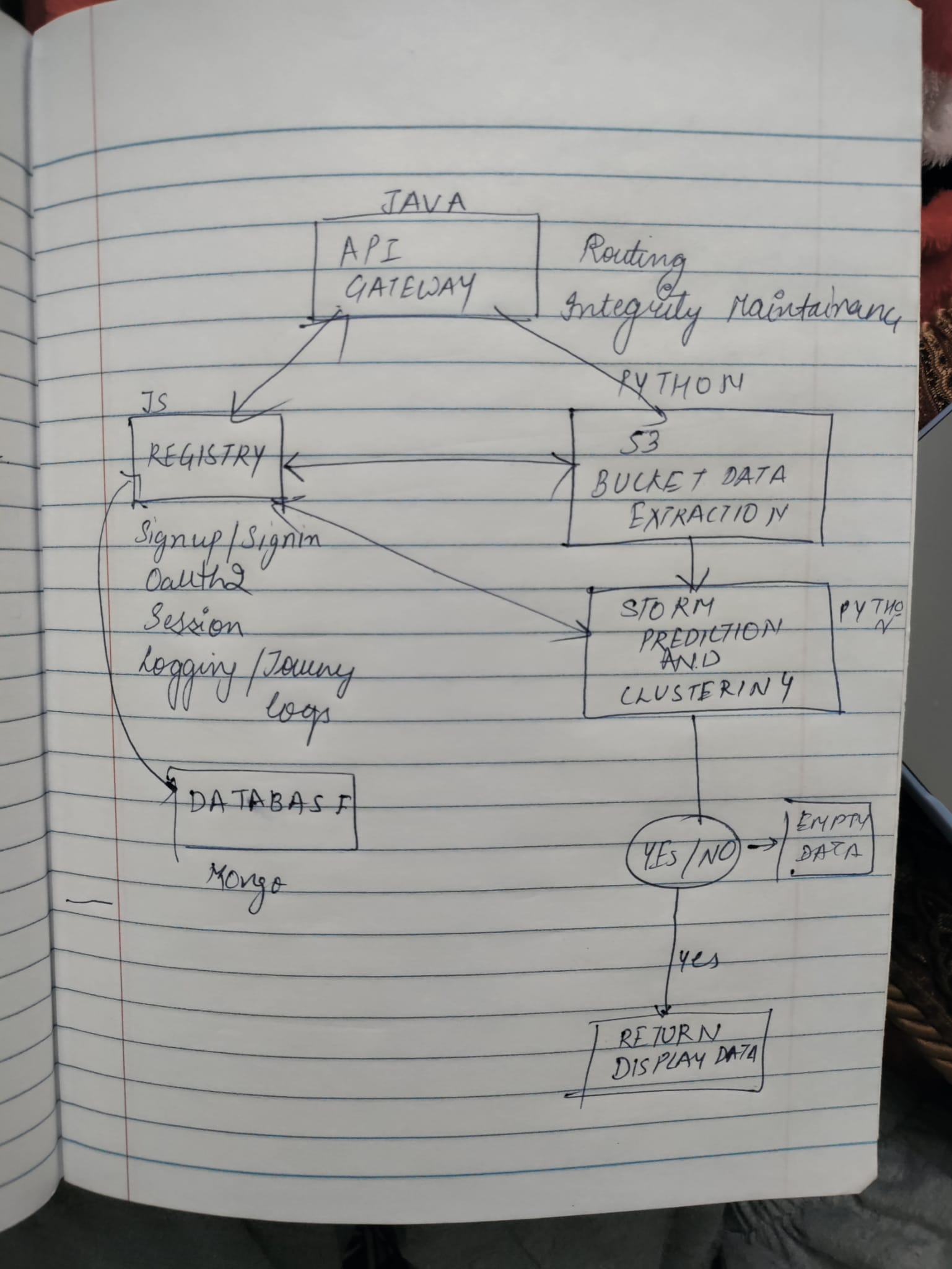
We switched to Java, but now we realized that there is too much communication between microservices and not through a single point. The reason that this might not be a good idea was if we where to scale the system, it would need to group the microservices together to form a group and then the group would need to be replicated horizontally. So we decided that there will be only one single point of Contact between other Microservices and that role was assigned to API Gateway. It would do the heavy loading of routing, checking from registry if the user is authorized to make a specific request or not.
After the requirement change of at least 4 Microservices and 2 database technologies, we decided to ditch the Data Ingestor that was written in Java and include its working to Plotting service, and move the Logging activities from Registry to another Microservice that would be built in GO and connect to PostgreSQL for storing the database. Its ease of use and familiarity to attributed to its selection.
Now there would be an argument as to that a Non Relational Database would be better to store the User history and logs, that was the reason we went with MongoDB in the first place, but now we had to use another Database and most of our features such as Oauth, JWT were already written, so we decided to switch just the User-History to PostgreSQL.
This is the final architecture we went with.
ITERATION 3
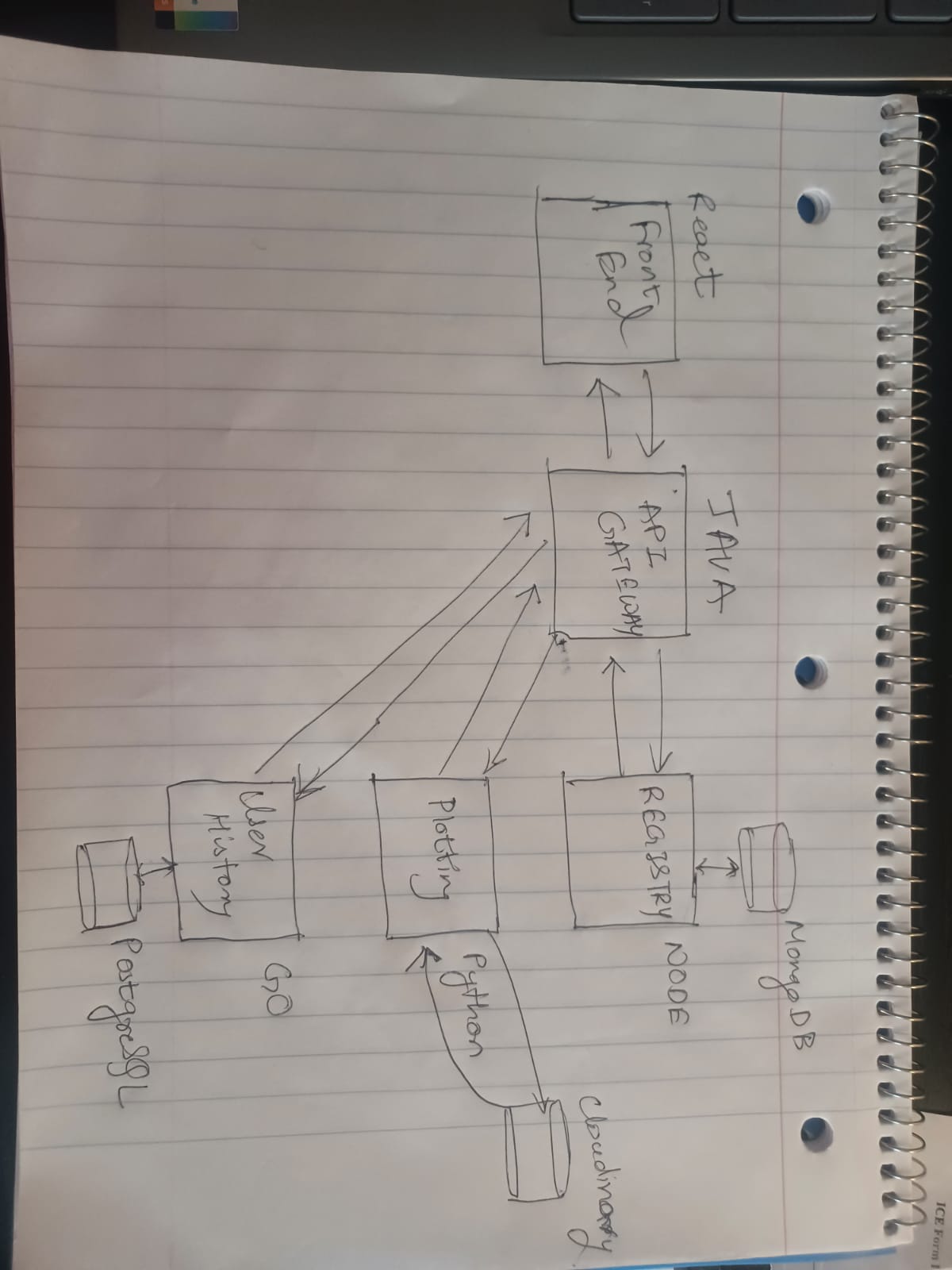
The Installation procedure and the API details is written in the README of dev-plotting branch.
This will include the code references and the libraries we used in this service and the reason behind their choosing.
- To access and download the AWS S3 data based on the required parameter we used Nexradraws library.
- Unidata Python Galary This was used because of the specific reason as to how should we go about actually getting the data we want from the file, different types of elevation and products. The given demo code was perfect for our task and we were able to plot the data.
- FLASK This was actually our second choice. The FAST API was first choice because of ease of implementation but we discovered a error in requests library used by uvicorn distribution for running the Fast API module. We tried searching and found it is an error in requests library, looking for how would we solve it was taking immense time that we did not have. So we decided to switch to Flask.
We decided to store the visualized images online to cloud service instead of storing it in our SQL database because of the fact that images take a lot of space which would add to the read performance and cost. Making it hard to backup the database if required. So know we would be storing the images elsewhere and store the reference to it in the database. We thought of using AWS S3 Bucket to dump the images because of the file structure it provides and highly scalable functionality. The problem was cost because at this scale there was no need of paid services, so we decided to go with other free online storage options.
- Cloudinary This provides a fantastic python supported API for uploading images.
If there was enough time I would hash the input data and the respective url for the plot generated in a persistent database, similar to the concept of Hash Map, where the key would be the input data and value would be the url. If the exact same input was previously encountered it would pick the respected value, which would greatly reduce the extra computational task and load.