[EPIC] Improve Cluster Observability #1426
Description
Two major directions (as of now):
Collect Executor Statistics
As starting point we could start by collecting and aggregating executor statistic, something similar to spark UI executor tab
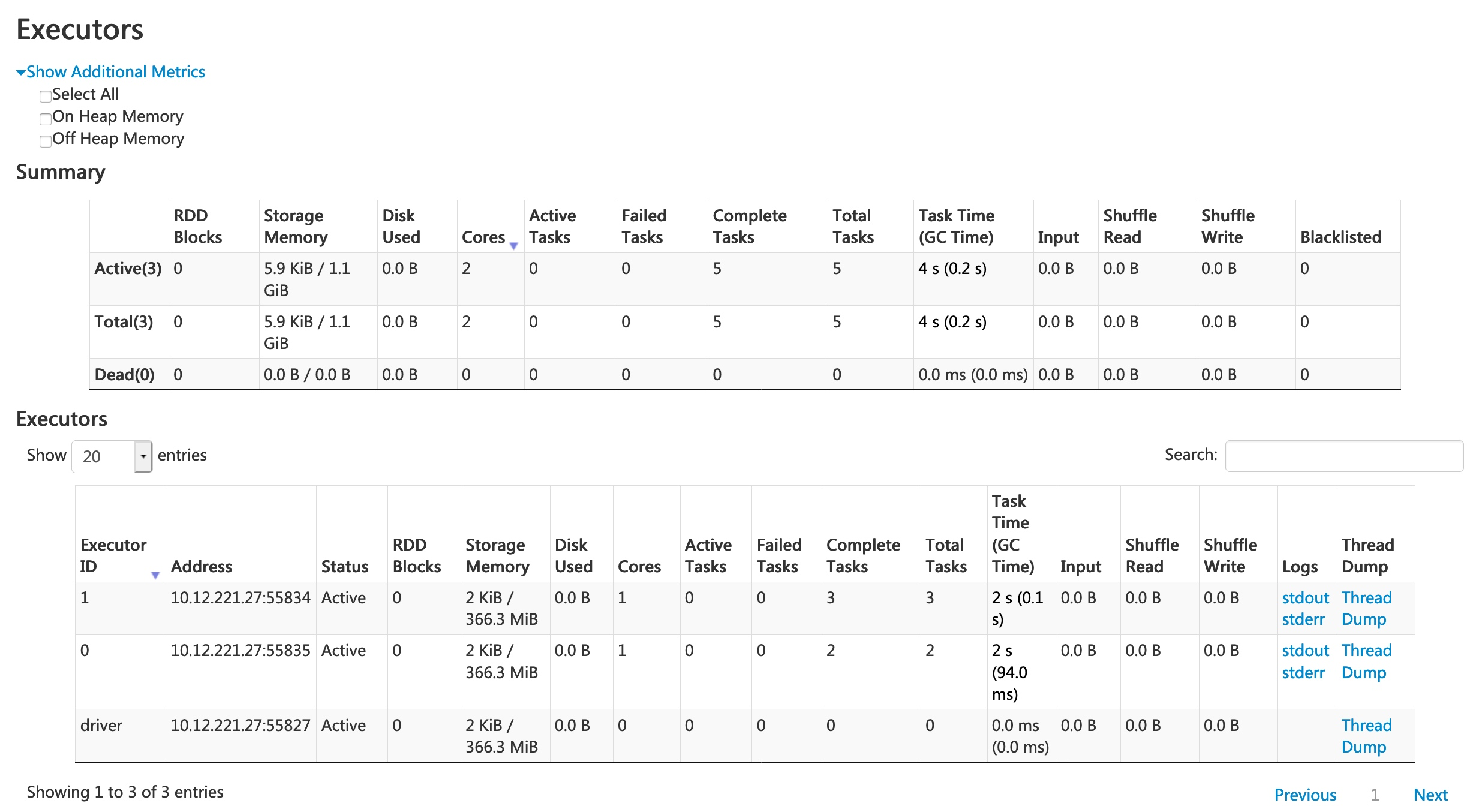
some statistics, such as memory utilisation, disk usage, would be collected on the executor, other like shuffle read and write may be collected on scheduler side.
We would need to expose additional rest interface to expose collected metrics
Per Stage Flame Graph
Similar to Nvidia RAPIDS Per Stage Flame Graph collect stats and produce flame graphs.
We would need to further investigate what should be done