Description
Description / Steps to reproduce the issue
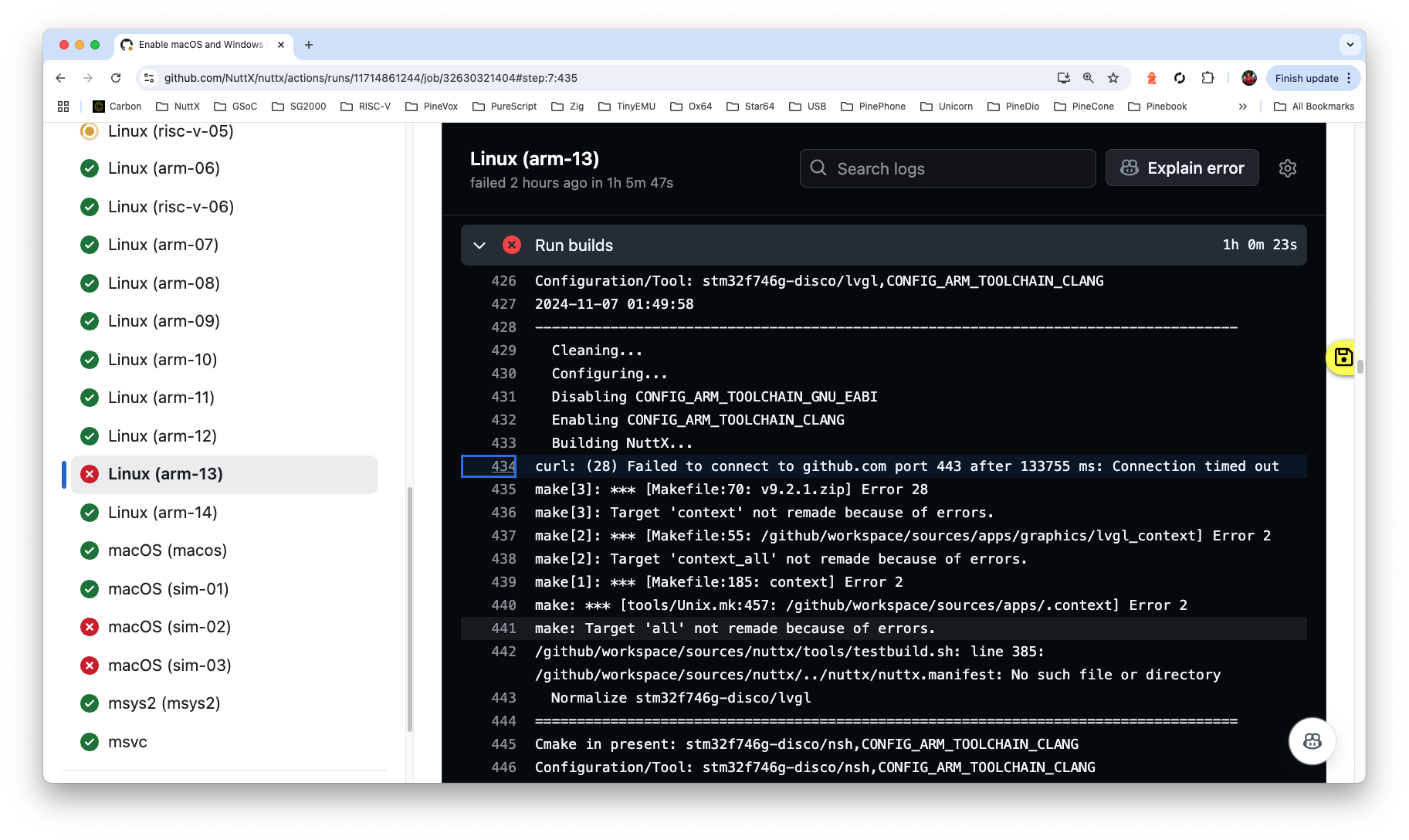
Something super strange about Network Timeouts (pic below) in our CI Docker Workflows at GitHub Actions. Here's an example...
-
First Run fails while downloading something from GitHub...
Configuration/Tool: imxrt1050-evk/libcxxtest,CONFIG_ARM_TOOLCHAIN_GNU_EABI curl: (28) Failed to connect to github.com port 443 after 134188 ms: Connection timed out make[1]: *** [libcxx.defs:28: libcxx-17.0.6.src.tar.xz] Error 28 -
Second Run fails again, while downloading NimBLE from GitHub...
Configuration/Tool: nucleo-wb55rg/nimble,CONFIG_ARM_TOOLCHAIN_GNU_EABI curl: (28) Failed to connect to github.com port [443](https://github.com/nuttxpr/nuttx/actions/runs/11535899222/job/32112716849#step:7:444) after 134619 ms: Connection timed out make[2]: *** [Makefile:55: /github/workspace/sources/apps/wireless/bluetooth/nimble_context] Error 2 -
Third Run succeeds. Why do we keep seeing these errors: GitHub Actions with Docker, can't connect to GitHub itself?
-
Is there a Concurrent Connection Limit for GitHub HTTPS Connections?
We see 4 Concurrent Connections to GitHub HTTPS...
The Fifth Connection failed: arm-02 at 00:42:52
-
Should we use a Caching Proxy Server for curl?
$ export https_proxy=https://1.2.3.4:1234 $ curl https://github.com/... -
Is something misconfigured in our Docker Image? But the exact same Docker Image runs fine on our own Build Farm. It doesn't show any errors.
-
Is GitHub Actions starting our Docker Container with the wrong MTU (Network Packet Size)? 🤔
-
Meanwhile I'm running a script to Restart Failed Jobs on our NuttX Mirror Repo: restart-failed-job.sh
These Timeout Errors will cost us precious GitHub Minutes. The remaining jobs get killed, and restarting these killed jobs from scratch will consume extra GitHub Minutes. (The restart below costs us 6 extra GitHub Runner Hours)
-
How do we Retry these Timeout Errors?
-
Can we have Restartable Builds?
Doesn't quite make sense to kill everything and rebuild from scratch (arm6, arm7, riscv7) just because one job failed (xtensa2)
-
Or xtensa2 should wait for others to finish, before it declares a timeout and croaks?
Configuration/Tool: esp32s2-kaluga-1/lvgl_st7789
curl: (28) Failed to connect to github.com port 443 after 133994 ms: Connection timed out
On which OS does this issue occur?
[OS: Linux]
What is the version of your OS?
Ubuntu LTS at GitHub Actions
NuttX Version
master
Issue Architecture
[Arch: all]
Issue Area
[Area: Build System]
Verification
- I have verified before submitting the report.