| sourceTitle | An update on recent Claude Code quality reports |
|---|---|
| sourceUrl | https://www.anthropic.com/engineering/april-23-postmortem |
| sourceRequestedUrl | https://www.anthropic.com/engineering/april-23-postmortem |
| sourceAuthor | @AnthropicAI |
| sourcePublishedAt | 2026-04-23 |
| sourceCoverImage | https://cdn.sanity.io/images/4zrzovbb/website/3f522820d47355885631ebda60e5d1f3e5c0fbc2-2000x1050.heif |
| title | 关于近期 Claude Code 质量报告的更新 |
| summary | Anthropic 对近期 Claude Code 质量下降报告的工程复盘:三个独立变更影响了 Claude Code、Claude Agent SDK 和 Claude Cowork,但 API 未受影响。 |
| sourceSummary | Anthropic is an AI safety and research company that's working to build reliable, interpretable, and steerable AI systems. |
| sourceAdapter | generic |
| sourceCapturedAt | 2026-05-22T07:29:19.500Z |
| sourceConversionMethod | defuddle |
| sourceKind | generic/article |
| language | zh-CN |
| sourceLanguage | en |
过去一个月,我们一直在调查部分用户关于 Claude 回复质量变差的报告。我们将这些报告追溯到三个独立变更,它们影响了 Claude Code、Claude Agent SDK 和 Claude Cowork。API 未受影响。
截至 4 月 20 日(v2.1.116),这三个问题都已经解决。
在这篇文章中,我们会解释发现了什么、修复了什么,以及未来会有哪些不同做法,以大幅降低类似问题再次发生的可能性。
我们非常认真地对待关于质量退化的报告。我们从不会有意降低模型质量,并且能够立即确认 API 和推理层没有受到影响。
经过调查,我们识别出三个不同问题:
- 3 月 4 日,我们将 Claude Code 的默认推理强度(reasoning effort)从
high改为medium,目的是降低部分用户在high模式下遇到的极长延迟;那种延迟足以让 UI 看起来像是冻结了。这是一个错误取舍。4 月 7 日,在用户告诉我们他们更希望默认获得更高智能、并在简单任务上主动选择较低 effort 之后,我们撤回了这个变更。该问题影响了 Sonnet 4.6 和 Opus 4.6。 - 3 月 26 日,我们发布了一个变更:对空闲超过一小时的会话,清除 Claude 较早的 thinking,以降低用户恢复这些会话时的延迟。一个 bug 导致清理不只发生一次,而是在会话剩余时间里的每一轮都持续发生,这让 Claude 显得健忘且重复。我们在 4 月 10 日修复了它。该问题影响了 Sonnet 4.6 和 Opus 4.6。
- 4 月 16 日,我们增加了一条系统提示词指令,用来减少冗长输出。它与其他 prompt 变更叠加后,损害了编码质量,并在 4 月 20 日被撤回。该问题影响了 Sonnet 4.6、Opus 4.6 和 Opus 4.7。
由于每个变更都在不同时间影响了不同流量切片,聚合后的效果看起来像是广泛且不一致的质量下降。我们从 3 月初开始调查这些报告,但一开始很难把它们与用户反馈中的正常波动区分开;我们的内部使用情况和评测最初也没有复现后来识别出的问题。
这不是 Claude Code 用户应有的体验。截至 4 月 23 日,我们正在为所有订阅用户重置使用额度。
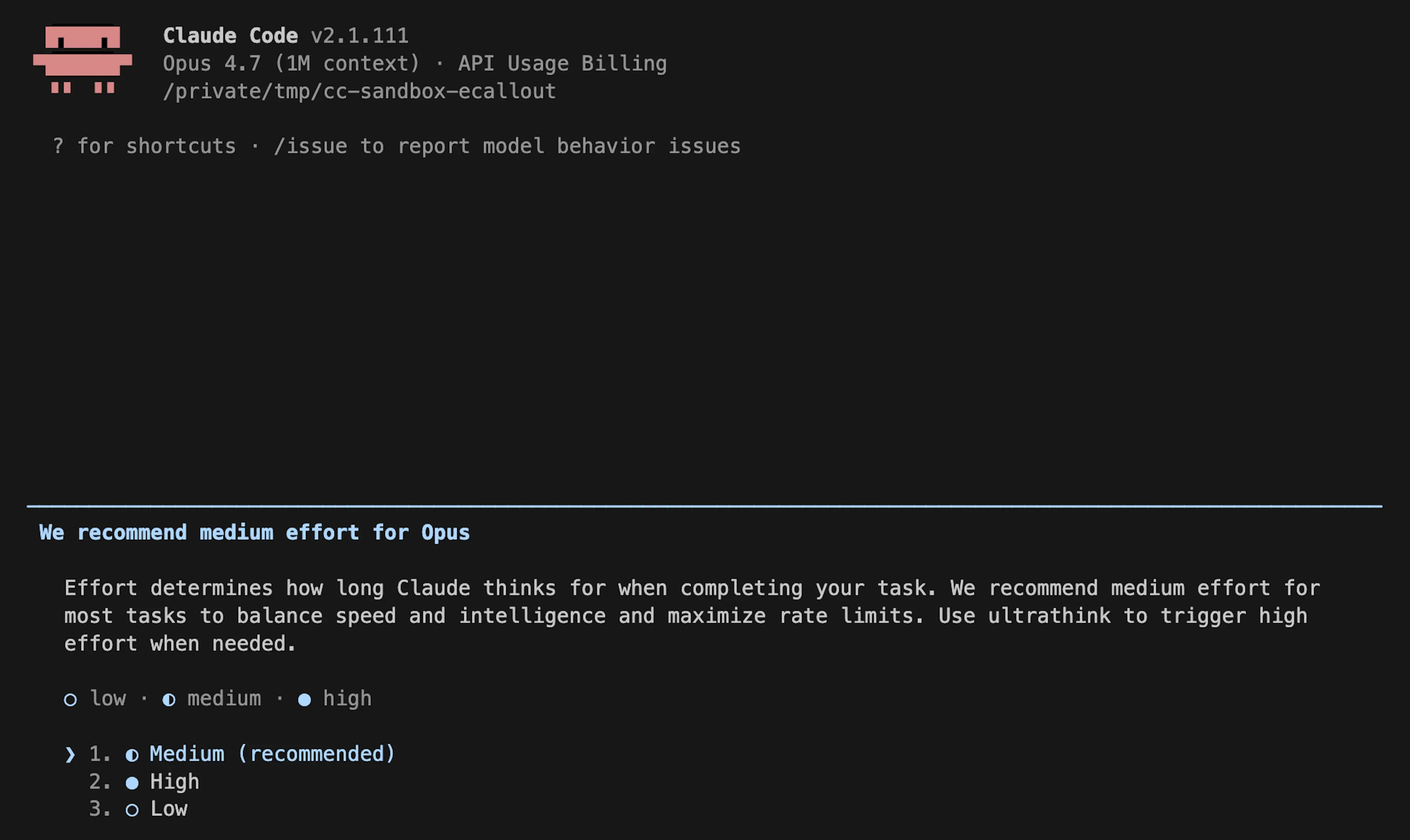
今年 2 月,我们在 Claude Code 中发布 Opus 4.6 时,将默认推理强度设为 high。
不久之后,我们收到用户反馈:Claude Opus 4.6 在 high effort 模式下偶尔会思考太久,导致 UI 看起来冻结,并给这些用户带来不成比例的延迟和 token 使用量。
一般来说,模型思考越久,输出越好。effort 档位是 Claude Code 让用户设置这种取舍的方式:更多思考,还是更低延迟和更少使用额度消耗。在为模型校准 effort 档位时,我们会考虑这种取舍,以便在测试时计算(test-time compute)曲线上选出能给用户提供最佳选项范围的点。在产品层,我们随后选择这条曲线上的哪个点作为默认值,并将该值作为 effort 参数发送给 Messages API;其他选项则通过 /effort 提供。
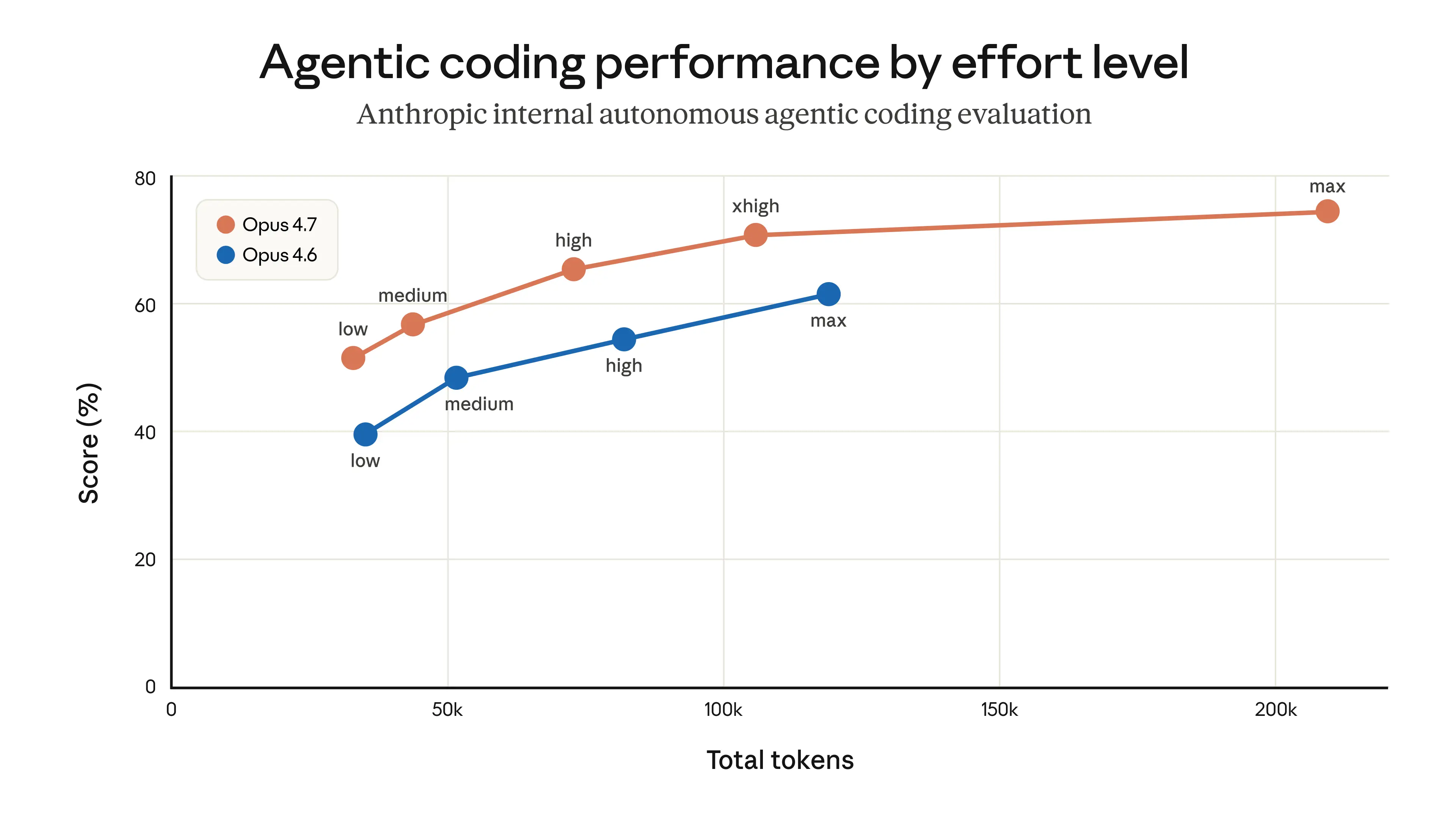
在我们的内部评测和测试中,对大多数任务来说,medium effort 的智能表现略低,但延迟显著更低。它也没有出现 thinking 偶发超长尾延迟的相同问题,并且有助于最大化用户的使用额度。因此,我们发布了一个变更,把 medium 设为默认 effort,并通过产品内对话框解释了理由。
发布后不久,用户开始反馈 Claude Code 感觉不如以前聪明。我们做了多轮设计迭代,让当前 effort 设置更加清晰,以提醒用户可以更改默认值(启动时提示、行内 effort 选择器,以及恢复 ultrathink),但大多数用户仍保留了 medium effort 默认值。
在听取更多客户反馈后,我们于 4 月 7 日撤回了这一决定。现在,所有用户在 Opus 4.7 上默认使用 xhigh effort,在其他所有模型上默认使用 high effort。
当 Claude 对任务进行推理时,这些推理通常会保存在对话历史中,这样在后续每一轮中,Claude 都能看到自己为什么做出了那些编辑和工具调用。
3 月 26 日,我们发布了一个原本旨在提升该功能效率的变更。我们使用提示词缓存,让连续 API 调用对用户来说更便宜、更快。Claude 在发起 API 请求时会把输入 token 写入缓存;经过一段不活跃时间后,prompt 会从缓存中驱逐,为其他 prompt 腾出空间。缓存利用率是我们谨慎管理的内容(更多信息可见我们的方法介绍)。
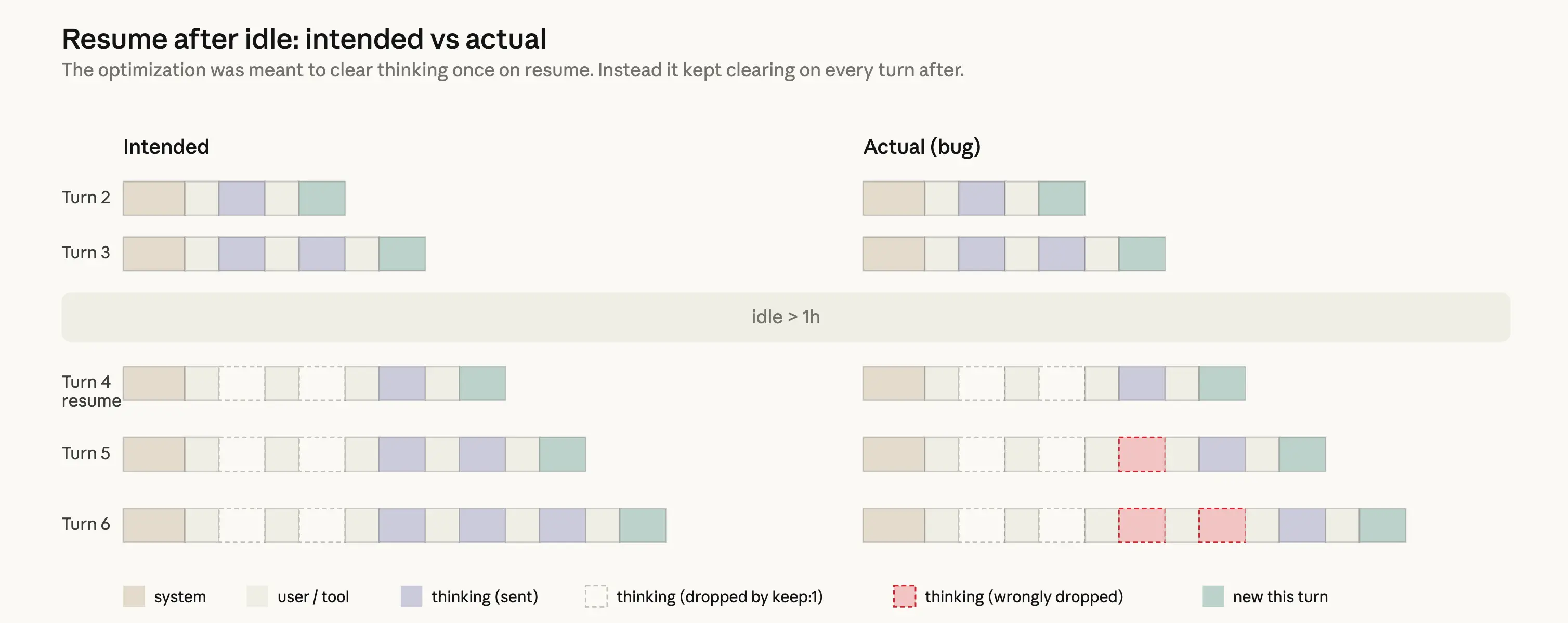
设计本应很简单:如果一个会话已经空闲超过一小时,我们可以清理旧 thinking 区块,降低用户恢复该会话的成本。由于该请求无论如何都会缓存未命中,我们可以从请求中剪掉不必要的消息,以减少发送给 API 的未缓存 token 数量。之后,我们会恢复发送完整 reasoning 历史。为此,我们使用了 clear_thinking_20251015 API header 和 keep:1。
实现中有一个 bug。它不是只清理一次 thinking 历史,而是在会话剩余时间里的每一轮都持续清理。一个会话只要跨过一次空闲阈值,该进程后续的每个请求都会告诉 API 只保留最近一个 reasoning 区块,并丢弃此前所有内容。这种影响会叠加:如果你在 Claude 正在使用工具时发送后续消息,就会在损坏的标志下开始新一轮,因此甚至当前轮次中的 reasoning 也会被丢弃。Claude 会继续执行,但越来越不记得自己为什么选择这么做。这表现为用户报告的健忘、重复和奇怪的工具选择。
由于这会持续从后续请求中丢弃 thinking 区块,这些请求也会导致缓存未命中。我们认为这就是另一些关于使用额度比预期消耗更快的报告的原因。
{kind=link}
两个无关实验让我们一开始很难复现该问题:一个与消息队列相关、只在内部启用的服务端实验;另一个则是 thinking 展示方式上的正交变更,它在大多数 CLI 会话中抑制了这个 bug,因此即使测试外部构建时我们也没发现它。
这个 bug 位于 Claude Code 的上下文管理、Anthropic API 和 extended thinking 的交叉处。引入它的变更通过了多次人工和自动代码审查,也通过了单元测试、端到端测试、自动验证和 dogfooding。再加上它只发生在一个角落场景(陈旧会话)中,而且难以复现,我们花了一周多时间才发现并确认根因。
作为调查的一部分,我们使用 Opus 4.7 对有问题的 pull request 回测了 Code Review。在提供必要代码仓库以获取完整上下文后,Opus 4.7 找到了这个 bug,而 Opus 4.6 没有。为了防止此类问题再次发生,我们正在落地对更多仓库作为 code review 上下文的支持。
我们在 4 月 10 日的 v2.1.101 中修复了这个 bug。
我们的最新模型 Claude Opus 4.7 相比前代有一个显著行为特点:正如我们在发布文章中所写,它往往相当冗长。这让它在难题上更聪明,但也会产生更多输出 token。
在发布 Opus 4.7 的几周前,我们开始为 Claude Code 做调优准备。每个模型的行为都略有不同,我们会在每次发布前花时间为它优化 Harness 和产品。
我们有多种降低冗长程度的工具:模型训练、prompting,以及在产品中改进 thinking UX。最终我们都用了,但其中加入系统提示词的一条指令,对 Claude Code 智能表现产生了过大的影响:
“Length limits: keep text between tool calls to ≤25 words. Keep final responses to ≤100 words unless the task requires more detail.”
经过多周内部测试,并且在我们运行的一组评测中没有发现回归后,我们对这个变更有信心,并在 4 月 16 日随 Opus 4.7 一起发布了它。
作为本次调查的一部分,我们使用更广泛的评测集运行了更多消融实验(移除系统提示词中的某些行,以理解每一行的影响)。其中一项评测显示,Opus 4.6 和 4.7 都下降了 3%。我们随即在 4 月 20 日发布中撤回了该 prompt。
为了避免这些问题,我们会采取几项不同做法:确保更大比例的内部员工使用 Claude Code 的精确公开构建(而不是我们用来测试新功能的版本);改进我们内部使用的 Code Review 工具,并把这个改进版本提供给客户。
我们也在为系统提示词变更增加更严格控制。对 Claude Code 的每一次系统提示词变更,我们都会运行覆盖更广的逐模型评测套件,继续通过消融实验理解每一行的影响,并且已经构建了新的工具,让 prompt 变更更容易审查和审计。我们还在 CLAUDE.md 中增加了指导,确保针对特定模型的变更只作用于它们所面向的具体模型。对于任何可能牺牲智能表现的变更,我们都会增加浸泡期、更广泛的评测套件和渐进发布,以便更早发现问题。
我们最近在 X 上创建了 @ClaudeDevs,以便有空间深入解释产品决策及其背后的理由。我们也会在 GitHub 的集中讨论串中分享相同更新。
最后,我们想感谢用户:正是那些使用 /feedback 命令向我们分享问题(或在网上发布具体、可复现示例)的人,最终让我们能够识别并修复这些问题。今天,我们正在为所有订阅用户重置使用额度。
我们非常感谢你们的反馈和耐心。