|
2 | 2 | "cells": [ |
3 | 3 | { |
4 | 4 | "cell_type": "markdown", |
5 | | - "metadata": { |
6 | | - "jp-MarkdownHeadingCollapsed": true |
7 | | - }, |
| 5 | + "metadata": {}, |
8 | 6 | "source": [ |
9 | 7 | "# Building a Retrieval-Augmented Generation (RAG) System Workshop\n", |
10 | 8 | "\n", |
|
52 | 50 | "cell_type": "markdown", |
53 | 51 | "metadata": {}, |
54 | 52 | "source": [ |
55 | | - "# What is RAG (Retrieval-augmented generation)\n", |
| 53 | + "## What is RAG (Retrieval-augmented generation)\n", |
56 | 54 | "\n", |
57 | 55 | "**Retrieval-augmented generation (RAG)** is a technique for augmenting LLM knowledge with additional, often private or real-time, data. LLMs can reason about wide-ranging topics, but their knowledge is limited to the public data up to a specific point in time that they were trained on. If you want to build AI applications that can reason about private data or data introduced after a model’s cutoff date, you need to augment the knowledge of the model with the specific information it needs. The process of bringing the appropriate information and inserting it into the model prompt is known as Retrieval Augmented Generation (RAG)." |
58 | 56 | ] |
|
61 | 59 | "cell_type": "markdown", |
62 | 60 | "metadata": {}, |
63 | 61 | "source": [ |
64 | | - "## Step 1: Install Llamacpp python for SYCL\n", |
65 | | - "The llama.cpp SYCL backend is designed to support Intel GPU firstly. Based on the cross-platform feature of SYCL.\n", |
| 62 | + "## Setup llama.cpp python for Intel CPUs and GPUs\n", |
| 63 | + "The llama.cpp SYCL backend is designed to support Intel GPU. Based on the cross-platform feature of SYCL.\n", |
| 64 | + "\n", |
| 65 | + "We will setup Python environment and corresponding custom kernel for Jupyter Notebook, and we will install/build llama.cpp that will be used for the RAG Application.\n", |
| 66 | + "\n", |
| 67 | + "### Step 1: Create and activate Python environment:\n", |
| 68 | + "\n", |
| 69 | + "Open Terminal, make sure mini-forge is install and create new virtual environment\n", |
| 70 | + "\n", |
| 71 | + "```\n", |
| 72 | + " conda create -n llm-sycl python=3.11\n", |
| 73 | + "\n", |
| 74 | + " conda activate llm-sycl\n", |
66 | 75 | "\n", |
67 | | - "### After installation of conda-forge, open the Miniforge Prompt, and create a new python environment:\n", |
68 | | - " ```\n", |
69 | | - " conda create -n llm-sycl python=3.11\n", |
| 76 | + "```\n", |
| 77 | + "_Note: In case you want to remove the virtual environment, run the following command:_\n", |
| 78 | + "```\n", |
| 79 | + " [conda remove -n llm-sycl --all]\n", |
| 80 | + "```\n", |
70 | 81 | "\n", |
71 | | - " ```\n", |
| 82 | + "### Step 2: Setup a custom kernel for Jupyter notebook:\n", |
| 83 | + "\n", |
| 84 | + "Run the following commands in the terminal to setup custom kernel for the Jupyter Notebook.\n", |
72 | 85 | "\n", |
73 | | - "### Activate the new environment\n", |
74 | 86 | "```\n", |
75 | | - "conda activate llm-sycl\n", |
| 87 | + " conda install -c conda-forge ipykernel\n", |
76 | 88 | "\n", |
| 89 | + " python -m ipykernel install --user --name=llm-sycl\n", |
| 90 | + "```\n", |
| 91 | + "_Note: In case you want to remove the custom kernel from Jupyter, run the following command:_\n", |
| 92 | + "```\n", |
| 93 | + " [python -m jupyter kernelspec uninstall llm-sycl]\n", |
77 | 94 | "```\n", |
78 | 95 | "\n", |
79 | 96 | "<img src=\"Assets/llm4.png\">\n", |
80 | 97 | "\n", |
81 | | - "## For Windows\n", |
82 | | - "### With the llm-sycl environment active, enable oneAPI environment. \n", |
83 | | - "Type oneapi in the windows search and then open the Intel oneAPI command prompt for Intel 64 for Visual Studio 2022 App.\n", |
| 98 | + "### Step 3: Install and Build llama.cpp\n", |
| 99 | + "\n", |
| 100 | + "### For Linux\n", |
84 | 101 | "\n", |
| 102 | + "#### 1. Enable oneAPI environment\n", |
85 | 103 | "\n", |
86 | | - "#### Run the below command in the VS command prompt and you should see the below sycl devices displayed in the console\n", |
87 | | - "There should be one or more level-zero GPU devices displayed as ext_oneapi_level_zero:gpu.\n", |
| 104 | + "Make sure oneAPI Base Toolkit is installed to use the SYCL compiler for building llama.cpp\n", |
88 | 105 | "\n", |
| 106 | + "Run the following commands in terminal to initialize oneAPI environment and check available devices:\n", |
| 107 | + "\n", |
| 108 | + "```\n", |
| 109 | + " source /opt/intel/oneapi/setvars.sh\n", |
| 110 | + " sycl-ls\n", |
89 | 111 | "```\n", |
90 | | - "sycl-ls\n", |
| 112 | + "\n", |
| 113 | + "#### 2. Install and build llama.cpp Python\n", |
| 114 | + "\n", |
| 115 | + "Run the following commands in terminal to install and build llama.cpp\n", |
| 116 | + "\n", |
| 117 | + "```\n", |
| 118 | + " CMAKE_ARGS=\"-DGGML_SYCL=on -DCMAKE_C_COMPILER=icx -DCMAKE_CXX_COMPILER=icpx\" pip install llama-cpp-python==0.3.1\n", |
| 119 | + "```\n", |
| 120 | + "\n", |
| 121 | + "### For Windows\n", |
| 122 | + "\n", |
| 123 | + "#### 1. Enable oneAPI environment\n", |
| 124 | + "\n", |
| 125 | + "Make sure oneAPI Base Toolkit is installed to use the SYCL compiler for building llama.cpp\n", |
| 126 | + "\n", |
| 127 | + "Type oneapi in the windows search and then open the Intel oneAPI command prompt for Intel 64 for Visual Studio 2022 App.\n", |
| 128 | + "\n", |
| 129 | + "Run the following commands to initialize oneAPI environment and check available devices:\n", |
91 | 130 | "\n", |
92 | 131 | "```\n", |
93 | | - "### Install build tools\n", |
| 132 | + " @call \"C:\\Program Files (x86)\\Intel\\oneAPI\\setvars.bat\" intel64 --force\n", |
| 133 | + " sycl-ls\n", |
| 134 | + "```\n", |
| 135 | + "\n", |
| 136 | + "#### 2. Install build tools\n", |
94 | 137 | "\n", |
95 | 138 | "* Download & install [cmake for Windows](https://cmake.org/download/):\n", |
96 | 139 | "* The new Visual Studio will install Ninja as default. (If not, please install it manually: https://ninja-build.org/)\n", |
97 | 140 | "\n", |
98 | | - "### Install llama.cpp Python\n", |
| 141 | + "#### 3. Install and build llama.cpp Python\n", |
99 | 142 | "\n", |
100 | | - " \n", |
101 | 143 | "* On the oneAPI command line window, step into the llama.cpp main directory and run the following:\n", |
102 | 144 | " \n", |
103 | | - " ```\n", |
104 | | - " @call \"C:\\Program Files (x86)\\Intel\\oneAPI\\setvars.bat\" intel64 --force\n", |
105 | | - "\n", |
106 | | - " Open a new terminal and perform the following steps:\n", |
107 | | - "\n", |
108 | | - "\n", |
109 | | - "# Set the environment variables\n", |
| 145 | + "```\n", |
110 | 146 | " set CMAKE_GENERATOR=Ninja\n", |
111 | 147 | " set CMAKE_C_COMPILER=cl\n", |
112 | 148 | " set CMAKE_CXX_COMPILER=icx\n", |
|
115 | 151 | " set CMAKE_ARGS=\"-DGGML_SYCL=ON -DGGML_SYCL_F16=ON -DCMAKE_CXX_COMPILER=icx -DCMAKE_C_COMPILER=cl\"\n", |
116 | 152 | " \n", |
117 | 153 | " pip install llama-cpp-python==0.3.1 -U --force --no-cache-dir --verbose\n", |
118 | | - "\n", |
119 | | - "## For Linux\n", |
120 | | - " export GGML_SYCL=on\n", |
121 | | - "\n", |
122 | | - " source /opt/intel/oneapi/setvars.sh \n", |
123 | | - " CMAKE_ARGS=\"-DGGML_SYCL=on -DCMAKE_C_COMPILER=icx -DCMAKE_CXX_COMPILER=icpx\" pip install llama-cpp-python==0.3.1\n", |
124 | | - "\n", |
125 | | - "### Setup a custom kernel for Jupyter notebook:\n", |
126 | | - " conda install -c conda-forge ipykernel\n", |
127 | | - "\n", |
128 | | - " python -m ipykernel install --user --name=llm-sycl" |
129 | | - ] |
130 | | - }, |
131 | | - { |
132 | | - "cell_type": "code", |
133 | | - "execution_count": null, |
134 | | - "metadata": {}, |
135 | | - "outputs": [], |
136 | | - "source": [ |
137 | | - "!pip install -r rag/requirements.txt" |
| 154 | + "```\n" |
138 | 155 | ] |
139 | 156 | }, |
140 | 157 | { |
141 | 158 | "attachments": {}, |
142 | 159 | "cell_type": "markdown", |
143 | 160 | "metadata": {}, |
144 | 161 | "source": [ |
145 | | - "## Run QA over Document\n", |
146 | | - "\n", |
147 | | - "Now, when model created, we can setup Chatbot\n", |
| 162 | + "## RAG Application Details\n", |
148 | 163 | "\n", |
149 | 164 | "A typical RAG application has two main components:\n", |
150 | 165 | "\n", |
151 | | - "- **Indexing**: a pipeline for ingesting data from a source and indexing it. This usually happen offline.\n", |
| 166 | + "- **Indexing**: a pipeline for ingesting data from a source and indexing it. This usually happens offline.\n", |
152 | 167 | "\n", |
153 | 168 | "- **Retrieval and generation**: the actual RAG chain, which takes the user query at run time and retrieves the relevant data from the index, then passes that to the model.\n", |
154 | 169 | "\n", |
|
170 | 185 | "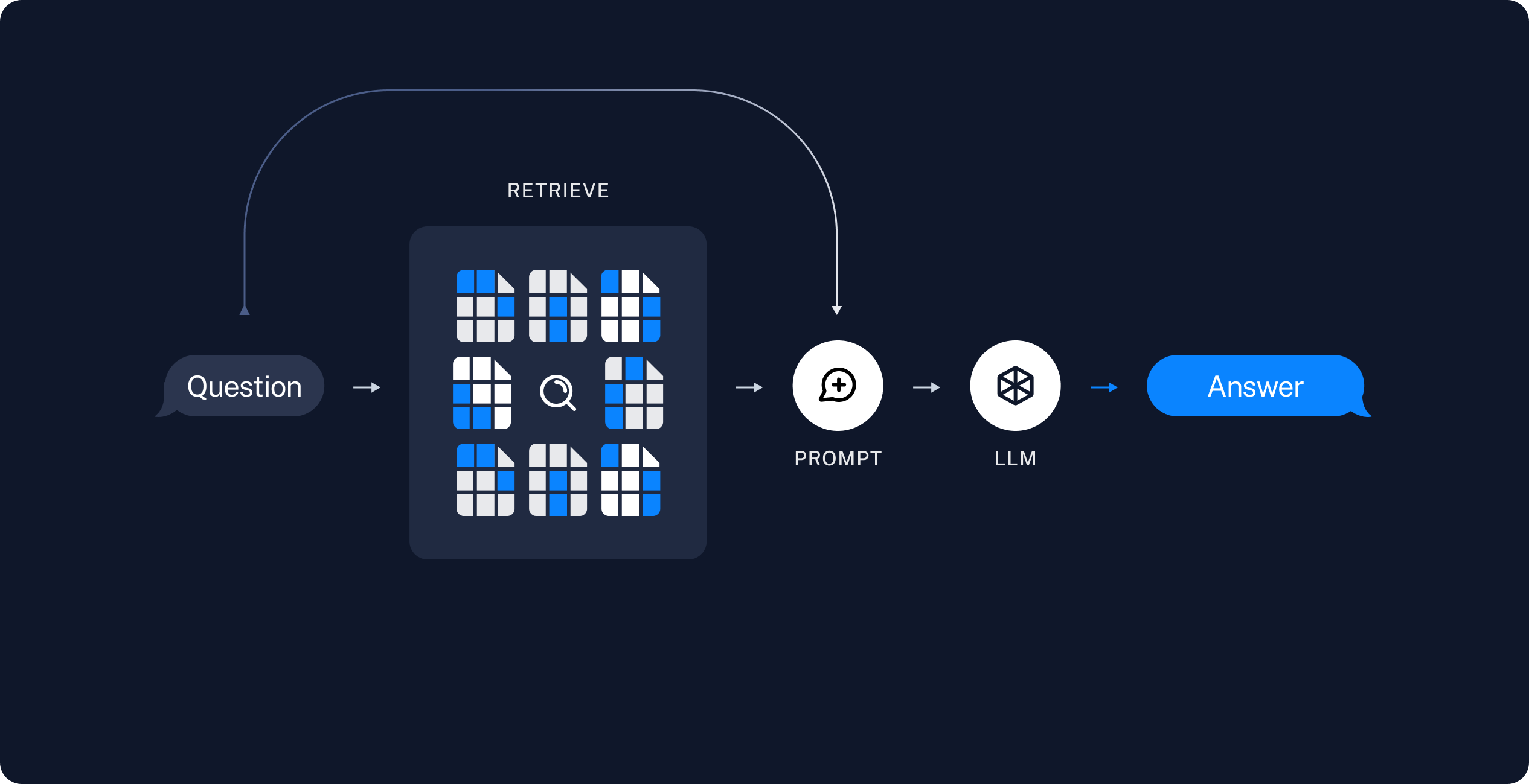\n" |
171 | 186 | ] |
172 | 187 | }, |
| 188 | + { |
| 189 | + "cell_type": "markdown", |
| 190 | + "metadata": {}, |
| 191 | + "source": [ |
| 192 | + "## Install Python Modules\n", |
| 193 | + "In Jupyter Lab, select `llm-sycl` as the kernel.\n", |
| 194 | + "\n", |
| 195 | + "You can now proceed installing modules and running python code in Jupyter Notebook" |
| 196 | + ] |
| 197 | + }, |
| 198 | + { |
| 199 | + "cell_type": "code", |
| 200 | + "execution_count": null, |
| 201 | + "metadata": { |
| 202 | + "scrolled": true |
| 203 | + }, |
| 204 | + "outputs": [], |
| 205 | + "source": [ |
| 206 | + "import sys\n", |
| 207 | + "!{sys.executable} -m pip install -r rag/requirements.txt" |
| 208 | + ] |
| 209 | + }, |
173 | 210 | { |
174 | 211 | "cell_type": "markdown", |
175 | 212 | "metadata": {}, |
|
609 | 646 | " \"\"\"\n", |
610 | 647 | " model_name_or_path = \"TheBloke/Llama-2-7B-Chat-GGUF\"\n", |
611 | 648 | " model_basename = \"llama-2-7b-chat.Q4_K_M.gguf\"\n", |
| 649 | + " print(\"Downloading Model...\\n \" + model_name_or_path + \"/\" + model_basename)\n", |
612 | 650 | " MODEL_PATH = hf_hub_download(repo_id=model_name_or_path, filename=model_basename)\n", |
| 651 | + " print(\"Download Complete.\")\n", |
613 | 652 | " \n", |
614 | 653 | " # Initialize components that don't need to be recreated\n", |
615 | 654 | " embedding_fn = initialize_embedding_fn()\n", |
|
718 | 757 | ], |
719 | 758 | "metadata": { |
720 | 759 | "kernelspec": { |
721 | | - "display_name": "llm-test2", |
| 760 | + "display_name": "Python 3 (ipykernel)", |
722 | 761 | "language": "python", |
723 | | - "name": "llm-test2" |
| 762 | + "name": "python3" |
724 | 763 | }, |
725 | 764 | "language_info": { |
726 | 765 | "codemirror_mode": { |
|
732 | 771 | "name": "python", |
733 | 772 | "nbconvert_exporter": "python", |
734 | 773 | "pygments_lexer": "ipython3", |
735 | | - "version": "3.11.10" |
| 774 | + "version": "3.11.5" |
736 | 775 | } |
737 | 776 | }, |
738 | 777 | "nbformat": 4, |
|
0 commit comments