동적 계획법 (Dynamic Programming)은 문제를 해결하기 위해 문제를 작은 하위 문제로 나누고, 그 결과를 저장해서 동일한 하위 문제를 반복해자 풀지 않도록 하는 알고리즘 기법이다.
DP를 사용하기 위해서는 다음 4가지 조건을 충족해야 한다.
- 참조 투명성
- Optimal Substructure (최적 부분 구조)
- Overrlapping Subproblems (겹치는 부분 문제)
- DAG (Directed Acyclic Graph) 구조
1번의 경우 입력을 제외한 외적 요소에 결과값이 영향을 미치지 않고, 동일한 입력에 대해 동일한 출력을 가져야함을 의미한다.
int add(int a, int b) {
return a + b
}위의 함수의 경우 매개변수에만 결과값이 영향을 받게 된다.
이때, 다음과 같이 외적 요소에 대해 결과값이 달라진다고 생각해보자.
int c = 0;
int add(int a, int b) {
return a + b;
}이러한 경우에는 참조 투명성이 지켜지지 않는다고 판단한다.
보통의 코딩테스트 문제의 경우에는 이러한 참조 투명성이 지켜진 상태로 문제가 주어지게 되므로, 특별하게 고려할 필요는 없다.
2번의 경우 문제를 해결할 때 하위 문제들을 해결한 결과를 이용해 전체 문제의 최적 해답을 구성할 수 있는 구조를 가지는 것을 의미한다. 가장 흔한 예로 피보나치 수열이 있다.
피보나치 수열을 구할 때,

5번째 요소의 값을 구하기 위해서 3번째 요소와 4번째 요소의 값을 더한 값을 취한다.
마찬가지로 4번째 요소의 값을 구하기 위해서 2번째 요소와 3번째 요소의 값을 활용한다.
이처럼 하위 문제의 결과값을 사용해서 상위 문제를 해결하는 것을 Obtimal Substructure라고 한다.
3번의 경우 동일한 하위 문제가 여러 번 반복해서 등장하는 경우, 이러한 문제의 해를 저장해 두고 재사용할 수 있는 구조를 가져야 한다.
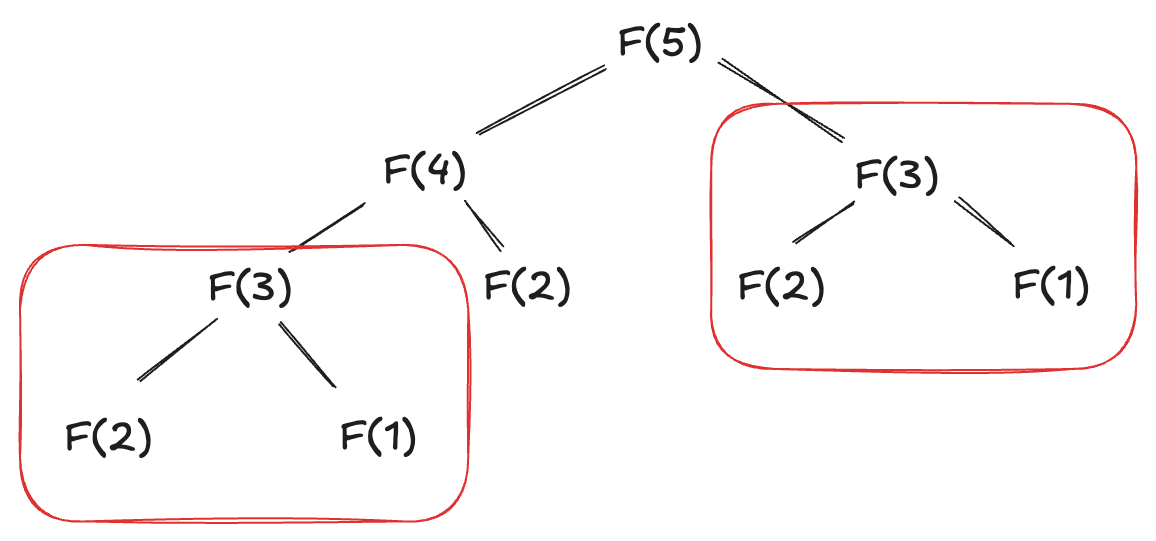
피보나치 수열에서
4번의 경우 방향성이 존재하고, 사이클이 없는 구조여야 한다는 것이다. 그러나 대부분의 그래프를 DP로 해결하는 문제의 경우 사이클이 없이 주어진다.
DP를 사용하기 위해서 위의 조건에 해당하는지 판단 후 DP를 적용하기는 어렵다.
그렇기 때문에 우선 완전 탐색을 통해 해당 문제를 해결할 수 있는지 판단해야 한다.
이때, 경우의 수가 제한조건 내에 해결 불가능하다면 메모이제이션을 통해 경우의 수에 해당하는 값들을 배열에 저장한다.
만약, 메모이제이션을 하기 위한 배열의 크기가 제한 조건 내에 불가능하다면, 그리디 혹은 또 다른 알고리즘을 사용해야 한다.
DP는 완전탐색 + 메모이제이션이다.
원래 DP로 문제를 해결하기 위해서는 점화식을 만들고, 점화식에 맞춰 코드를 구현해야 한다. 그러나 그렇게 하기에는 현실적으로 어렵다.
따라서 완전탐색 문제를 해결하듯 모든 경우의 수를 생각하고, 그 경우의 수를 메모이제이션 하는 것이다.
즉, 다음 순서로 DP를 구축하면 된다.
- 어떠한 인덱스에서 모든 경우의 수를 생각한다.
- 완전탐색을 하는 구조를 만든다.
- 메모이제이션을 건다.
2번 단계에서 사실상 완전탐색을 하는 구조가 점화식이 된다.
메모이제이션은 어떤 상태값을 자료구조에 저장하는 것이다. 이 상태값을 정의하고 잘 저장하는 것이 DP의 핵심 문제이다.
예를 들어 BFS 문제에서 최단거리를 담는 방문배열 visited[y][x]가 있을 때, y라는 상태값과 x라는 상태값을 기반으로 최단거리를 저장한다.
이와 비슷하게 문제에서 어떤 인덱스에서 어떤 순서의 상태값이 중요하다면 int dp[index][seqeunce]와 같은 2차원 배열을 정의해야 한다.
만약 두 상태뿐 아니라, 짝수인지 홀수인지까지 판별한다면 int dp[index][sequence][odd or even]과 같이 3차원 배열이 필요하다.
이처럼 문제를 보고 어떤 상태값을 기반으로 몇 개의 차원을 가진 배열을 통해 어떻게 메모이제이션을 할것인지 설정하는 것이 DP의 핵심 중 하나다.
- 사과가 1번 나무 또는 2번 나무에서 매초마다 1개씩 떨어진다.
- A는 처음 1번 나무 아래에 있다.
- 매초마다 원하는 나무 아래로 즉시 이동 가능하다. 단, 최대 M번만 이동 가능하다.
- 사과는 떨어지는 순간에만 받을 수 있다.
- S초 동안 어떤 나무에서 사과가 떨어지는지 주어진다.
- 최대 몇 개의 사과를 받을 수 있을까?
입력
7 2
2 1 1 2 2 1 1import java.util.*;
import java.io.*;
public class Solution {
public static int maxApplesFrom(int s, int pos, int m, int[][][] dp, int[] apples) {
if (m < 0) return Integer.MIN_VALUE;
if (s == apples.length) return 0;
// 이미 계산된 값이라면 값 반환
if (dp[s][pos][m] != -1) return dp[s][pos][m];
// 현재 위치에서 머무르는 경우
int stay = maxApplesFrom(s + 1, pos, m, dp, apples);
// 현재 위치에서 이동하는 경우
int move = maxApplesFrom(s + 1, 1 - pos, m - 1, dp, apples);
// 움직이기 전에 먹은 사과
int apple = (pos == apples[s] - 1) ? 1 : 0;
return dp[s][pos][m] = Math.max(stay, move) + apple;
}
public static int solution(int s, int m, int[] apples) {
int[][][] dp = new int[s + 1][2][m + 1];
for (int[][] level1 : dp) {
for (int[] level2 : level1) {
Arrays.fill(level2, -1);
}
}
return Math.max(
maxApplesFrom(0, 0, m, dp, apples),
maxApplesFrom(0, 1, m - 1, dp, apples)
);
}
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st = new StringTokenizer(br.readLine());
int s = Integer.parseInt(st.nextToken());
int m = Integer.parseInt(st.nextToken());
int[] apples = new int[s];
st = new StringTokenizer(br.readLine());
for (int i = 0; i < s; i++) {
apples[i] = Integer.parseInt(st.nextToken());
}
bw.write(solution(s, m, apples) + "\n");
bw.flush();
bw.close();
br.close();
}
}DP로 문제를 해결하기 위해서는 DP의 기본 구조를 잘 파악해야 한다. DP는 초기화, 기저사례, 메모이제이션, 로직으로 구성되어 있다.
int[][][] dp = new int[s + 1][2][m + 1];
for (int[][] level1 : dp) {
for (int[] level2 : level1) {
Arrays.fill(level2, -1);
}
}dp에서 메모이제이션에 사용될 자료구조는 어떤 값으로 초기화 해야할까? 초기화는 문제의 값이 될 수 없는 값으로 초기화 해야한다.
그리고 DP에서 최소를 구할 때는 초기 DP 자료구조를 최대로 초기화하고, 최대를 구할 때는 최소로 초기화해야 한다.
이를 통해 메모이제이션에 사용될 배열의 값이 아직 계산되지 않았음을 표현해야 한다.
기저 사례는 재귀 함수에서 재귀 호출이 종료되는 조건을 의미한다. 이전의 예시 문제에서는 두 가지 기저 사례가 존재한다.
if (m < 0) return Integer.MIN_VALUE;남은 이동 횟수가 음수가 되면 이동이 불가능한 경우로 간주하여 매우 작은 값인 Integer.MIN_VALUE를 반환한다. 이는 불가능한 경로임을 표시하고, 최댓값을 계산할 때 해당 경우의 수가 제외되도록 한다.
if (s == apples.length) return 0;현재 시간이 전체 시간과 같아졌다면 0을 반환하도록 한다.
dp 배열을 사용해서 이미 계산된 값을 저장한다. dp[s][pos][m]은 s 시간에 pos(1번 나무 또는 2번 나무)에 위치하며, 남은 이동 횟수가 m일 때의 최대 사과 개수를 저장한다.
if (dp[s][pos][m] != -1) return dp[s][pos][m];현재 상태에서 dp 배열에 저장된 값이 -1이 아니면 이미 계산된 값을 의미한다. 이때 그 값을 바로 반환한다.
값이 존재하는 경우, 그 값을 바로 반환하는 것이 메모이제이션이다.
이처럼 DP는 어떤 값을 반환해서 쌓아가야 하는 알고리즘이기 때문에 DP 함수의 반환 자료형은 void일 수 없다.
// 현재 위치에서 머무르는 경우
int stay = maxApplesFrom(s + 1, pos, m, dp, apples);
// 현재 위치에서 이동하는 경우
int move = maxApplesFrom(s + 1, 1 - pos, m - 1, dp, apples);
// 움직이기 전에 먹은 사과
int apple = (pos == apples[s] - 1) ? 1 : 0;
return dp[s][pos][m] = Math.max(stay, move) + apple;현재 상태에서 다음 시간의 상태값으로 이동하는 두 가지 선택지를 고려한다. 위의 예제에서는 2가지 경우의 수밖에 없다.
- 현재 나무 아래에 그대로 머무를 경우
- 다른 나무로 이동할 경우. 이 경우 이동 횟수가 하나 줄어들어야 한다.
이 두 가지 경우 중 더 큰 값을 선택하고, 현재 사과가 떨어지는 나무와 현재 나무가 같은 경우에는 1을 더해준다.
피보나치 수열을 통해 두 가지의 DP로 해결방법을 살펴보자.
public class Fibonacci {
static int[] dp;
public static int fibo(int n) {
if (n <= 1) return n;
if (dp[n] != -1) return dp[n];
return dp[n] = fibo(n - 1) + fibo(n - 2);
}
public static void main(String[] args) {
int n = 10;
dp = new int[n + 1];
Arrays.fill(dp, -1);
System.out.println(fibo(n));
}
}Top Down 방식의 경우 재귀적인 구조를 통해 문제를 해결하낟. 큰 N에서 1 또는 0 등 작은 숫자로 향하게 함수가 호출되며, DP에 필요한 배열만을 만들며 코드가 직관적이다. 그러나, 재귀 호출에 대한 오버헤드가 존재한다.
public class Fibonacci {
public static int fibo(int n) {
if (n <= 1) return n;
int[] dp = new int[n + 1];
dp[0] = 0;
dp[1] = 1;
for (int i = 2; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
}
public static void main(String[] args) {
int n = 10;
System.out.pritnln(fibo(n));
}
}Bottom Up의 경우 보통 0이나 1과 같은 작은 숫자에서 N까지 반복문을 통해 DP를 만든다. 재귀호출에 대한 오버헤드가 없다는 장점이 있지만, 문제에 필요한 배열뿐만 아니라, 모든 배열을 다 만들어야 한다는 단점이 존재한다. 보통 Top Down 방식보다 더 빠르다.
경우의 수를 풀 때 DP를 사용하는 경우가 있다. 이때는 다 더한다고 생각하면 된다.
- 정수 N을 1, 2, 3의 합으로 표현하는 방법의 수를 구하라.
- 합을 나타낼 때는 숫자를 1개 이상 사용해야 하며, 합을 이루는 숫자의 순서는 중요하지 않다.
- 첫 줄에는 테스트케이스의 수가 주어지고, 그 다음 줄부터 정수 N이 주어진다.
입력
2
8
10000출력
10
8338334import java.util.*;
import java.io.*;
public class Solution {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st = new StringTokenizer(br.readLine());
int t = Integer.parseInt(st.nextToken());
long[] dp = new long[10001];
dp[0] = 1;
for (int i = 1; i <= 3; i++) {
for (int j = 1; j <= 10000; j++) {
if (j - i >= 0) {
dp[j] += dp[j - i];
}
}
}
while (t-- > 0) {
int n = Integer.parseInt(br.readLine());
bw.write(dp[n] + "\n");
}
bw.flush();
bw.close();
br.close();
}
}보통 경우의 수 문제는 매우 큰 숫자가 나오기 때문에 int 자료형을 피하는 것이 좋다.
dp배열의 dp[i]는 정수 i를 1, 2, 3의 합으로 나타내는 방법의 수를 저장한다.
이때 첫 요소인 dp[0] = 1;로 지정한다. 이는 숫자 0을 만들기 위한 경우의 수는 아무 숫자도 선택하지 않는 경우 하나만 존재하기 때문이다.
for (int i = 1; i <= 3; i++) {
for (int j = 1; j <= 10000; j++) {
if (j - i >= 0) {
dp[j] += dp[j - i];
}
}
}i는 사용 가능한 숫자 (1, 2, 3)을 나타낸다. 이 반복문은 각 숫자를 사용할 때의 경우의 수를 DP 배열에 반영한다.
j는 목표 숫자이다. j를 1부터 10000까지 순회하며, j를 i를 사용하여 만들 수 있는 경우의 수를 갱신한다.
dp[j] += dp[j - i]는 j에서 i를 뺀 값 j - i에서 i를 추가하는 경우를 더해준다. 이를 통해 j를 만들 수 있는 모든 경우의 수를 누적해서 dp배열을 구성한다.
미리 10000까지의 값을 모두 계산하여, 각 테스트케이스마다 계속 계산할 필요를 없앤다.
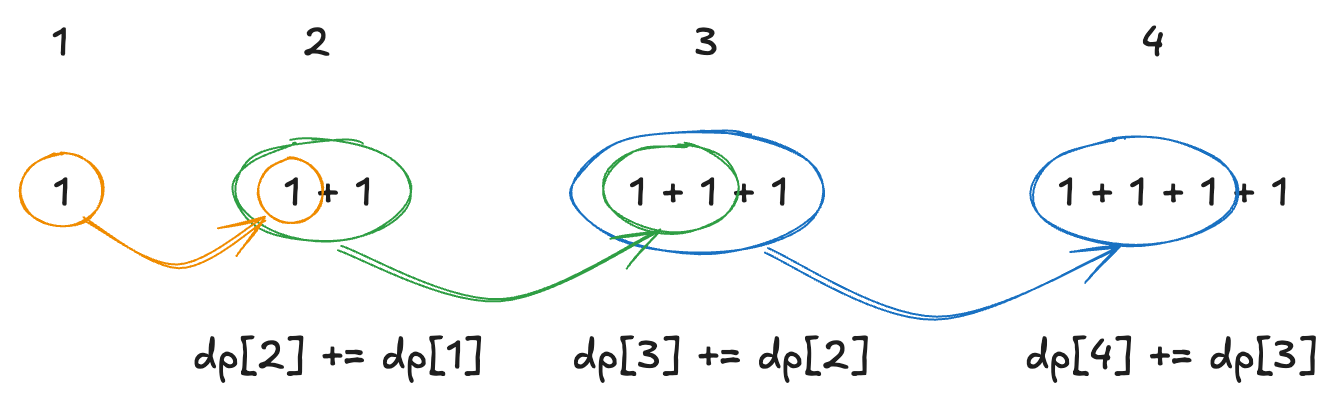
숫자 1을 통해 각 숫자를 구성하는 방법은 다음과 같다.
여기서 4라는 숫자를 구성하기 위해서는 3을 사용하고, 이때 dp 배열에 저장된 3을 만들기 위한 방법을 통해 경우의 수를 구할 수 있다.