|
| 1 | + |
| 2 | +## 参考资料 |
| 3 | + |
| 4 | +- Greg Durrett, 2021-2024, "CS388 Natural Language Processing course materials", retrieved from https://www.cs.utexas.edu/~gdurrett/courses/online-course/materials.html |
| 5 | + |
| 6 | +- Philipp Krähenbühl, 2020-2024, "AI394T Deep Learning course materials", retrieved from https://www.philkr.net/dl_class/material and https://ut.philkr.net/deeplearning/ |
| 7 | + |
| 8 | +- Philipp Krähenbühl, 2025, "AI395T Advances in Deep Learning course materials", retrieved from https://ut.philkr.net/advances_in_deeplearning/ |
| 9 | + |
| 10 | + |
| 11 | +- François Fleuret, The Little Book of Deep Learning, [-PDF-](https://fleuret.org/public/lbdl.pdf) |
| 12 | + - 梯度下降部分介绍的很好 |
| 13 | + |
| 14 | + |
| 15 | +## ANN |
| 16 | + |
| 17 | +- CS229 Lecture Notes, 2023, Stanford University, [7.2 Neural networks](https://cs229.stanford.edu/main_notes.pdf#page=81.24) |
| 18 | + - 写得非常清楚 |
| 19 | + |
| 20 | + |
| 21 | +## 简单 ANN |
| 22 | + |
| 23 | +### 激活函数 |
| 24 | + |
| 25 | +> Smets, B. M. N. (2024). Mathematics of Neural Networks (Lecture Notes Graduate Course) (Version 1). arXiv. [Link](https://doi.org/10.48550/arXiv.2403.04807) (rep), [PDF](https://arxiv.org/pdf/2403.04807.pdf), [Google](<https://scholar.google.com/scholar?q=Mathematics of Neural Networks (Lecture Notes Graduate Course) (Version 1)>). |
| 26 | +
|
| 27 | + |
| 28 | +We list some commonly used scalar activation functions which are also illustrated in Figure 1.2. |
| 29 | + |
| 30 | +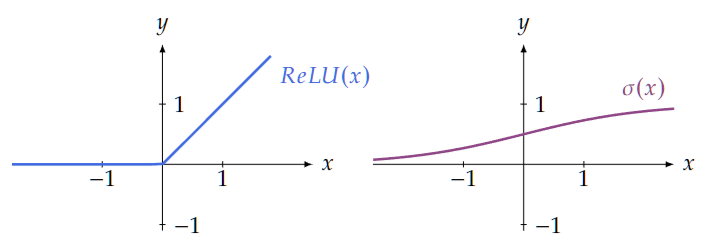 |
| 31 | + |
| 32 | +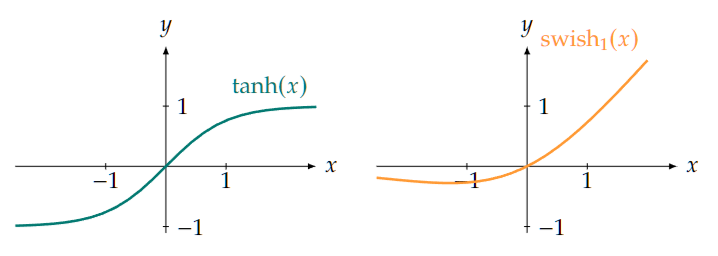 |
| 33 | + |
| 34 | +> Figure 1.2. |
| 35 | +
|
| 36 | +- Rectified Linear Unit (ReLU): arguably the most used activation function in modern neural networks, it is calculated as |
| 37 | + |
| 38 | +$$ |
| 39 | +\sigma(\lambda)=\operatorname{ReLU}(\lambda):=\max \{0, \lambda\} . |
| 40 | +$$ |
| 41 | + |
| 42 | +- Sigmoid (also known as logistic sigmoid or soft-step): |
| 43 | + |
| 44 | +$$ |
| 45 | +\sigma(\lambda):=\frac{1}{1+e^{-\lambda}} . |
| 46 | +$$ |
| 47 | + |
| 48 | + |
| 49 | +The sigmoid was commonly used as activation function in early neural networks, which is the reason that activations functions in general are still often labeled with a $\sigma$. |
| 50 | +- Hyperbolic tangent: very similar to the sigmoid, it is given by |
| 51 | + |
| 52 | +$$ |
| 53 | +\tanh (\lambda):=\frac{e^\lambda-e^{-\lambda}}{e^\lambda+e^{-\lambda}} . |
| 54 | +$$ |
| 55 | + |
| 56 | +- Swish: a more recent choice of activation function that can be thought of as a smooth variant of the ReLU. It is given by the multiplication of the input itself with the sigmoid function: |
| 57 | + |
| 58 | +$$ |
| 59 | +\operatorname{swish}_\beta(\lambda):=\lambda \sigma(\beta \lambda):=\frac{\lambda}{1+e^{-\beta \lambda}}, |
| 60 | +$$ |
| 61 | + |
| 62 | +where $\beta>0$. The $\beta$ parameter is usually chosen to be 1 but could be treated as a trainable parameter if desired. In case of $\beta=1$, this function is also called the sigmoid-weighted linear unit or SiLU. |
| 63 | + |
| 64 | +### 多变量激活函数 |
| 65 | + |
| 66 | +Activation functions need not be scalar, we list some common multivariate functions. |
| 67 | +- Softmax, also known as the normalized exponential function: softmax : $\mathbb{R}^n \rightarrow[0,1]^n$ is given by |
| 68 | + |
| 69 | +$$ |
| 70 | +\operatorname{softmax}\left(\left[\begin{array}{c} |
| 71 | +x_1 \\ |
| 72 | +x_2 \\ |
| 73 | +\vdots \\ |
| 74 | +x_n |
| 75 | +\end{array}\right]\right):=\frac{1}{\sum_{i=1}^n e^{x_i}}\left[\begin{array}{c} |
| 76 | +e^{x_1} \\ |
| 77 | +e^{x_2} \\ |
| 78 | +\vdots \\ |
| 79 | +e^{x_n} |
| 80 | +\end{array}\right] |
| 81 | +$$ |
| 82 | + |
| 83 | + |
| 84 | +Softmax has the useful property that its output is a discrete probability distribution, i.e. each value is a non-negative real in the range [ 0,1 ], and all the values in its output add up to exactly 1 . |
| 85 | +- Maxpool: here each output is the maximum of a certain subset of the inputs: the function $\operatorname{maxpool}: \mathbb{R}^n \rightarrow \mathbb{R}^m$ is given by |
| 86 | + |
| 87 | +$$ |
| 88 | +\text { maxpool }\left(\left[\begin{array}{c} |
| 89 | +x_1 \\ |
| 90 | +x_2 \\ |
| 91 | +\vdots \\ |
| 92 | +x_n |
| 93 | +\end{array}\right]\right):=\left[\begin{array}{cc} |
| 94 | +\max _{j \in I_1} & x_j \\ |
| 95 | +\max _{j \in I_2} & x_j \\ |
| 96 | +\vdots & \\ |
| 97 | +\max _{j \in I_m} & x_j |
| 98 | +\end{array}\right] . |
| 99 | +$$ |
| 100 | + |
| 101 | + |
| 102 | +Where for each $i \in\{1, \ldots, m\}$ we have a $I_i \subset\{1, \ldots, n\}$ that specifies over which inputs to take the maximum for each output. Maxpooling can easily be generalised by replacing the max operation with $\min$, the average, the mean, etc. |
| 103 | + |
| 104 | +- Normalization, sometimes it is desirable to re-center and re-scale a signal: |
| 105 | + |
| 106 | +$$ |
| 107 | +\text { normalize }\left(\left[\begin{array}{c} |
| 108 | +x_1 \\ |
| 109 | +x_2 \\ |
| 110 | +\vdots \\ |
| 111 | +x_n |
| 112 | +\end{array}\right]\right):=\left[\begin{array}{c} |
| 113 | +\frac{x_1-\mu}{\sigma} \\ |
| 114 | +\frac{x_2-\mu}{\sigma} \\ |
| 115 | +\vdots \\ |
| 116 | +\frac{x_n-\mu}{\sigma} |
| 117 | +\end{array}\right] \text {, } |
| 118 | +$$ |
| 119 | + |
| 120 | +where $\mu=\mathbb{E}[x]$ and $\sigma^2=\operatorname{Var}(x)$. There are many variants on normalization where the difference is how $\mu$ and $\sigma$ are computed: over time, over subsets of the incoming signals, etc. |
| 121 | + |
| 122 | +All the previous examples of activation functions are deterministic, but stochastic activation functions are also used. |
| 123 | + |
| 124 | +- Dropout is a stochastic function that is often used during the training process but is removed once the training is finished. It works by randomly setting individual values of a signal to zero with probability $p$ : |
| 125 | + |
| 126 | +$$ |
| 127 | +\left(\operatorname{dropout}_p(x)\right)_i:= \begin{cases}0 & \text { with probability } p \\ x_i & \text { with probability } 1-p\end{cases} |
| 128 | +$$ |
| 129 | + |
| 130 | +- Heatbath is a scalar function that outputs 1 or -1 with a probability that depends on the input: |
| 131 | + |
| 132 | +$$ |
| 133 | +\text { heatbath }(\lambda):=\left\{\begin{aligned} |
| 134 | +1 & \text { with probability } \frac{1}{1+e^{-\lambda}} \\ |
| 135 | +-1 & \text { otherwise. } |
| 136 | +\end{aligned}\right. |
| 137 | +$$ |
| 138 | + |
| 139 | + |
| 140 | +All the activation functions we seen are essentially fixed functions, swish and dropout have a parameter but it is usually fixed to some chosen value. That means that the trainable parameters of a neural network are usually the linear weights and biases. There is however no a-priori reason why that needs to be the case, in fact we will see a class of non-linear operators with trainable parameters at the end of Chapter 3. Regardless, having parameters in the non-linear part of a network is somewhat rare in practice at the time of this writing. |
| 141 | + |
| 142 | + |
| 143 | +## Gradient Desent |
| 144 | + |
| 145 | + |
| 146 | + |
| 147 | + |
| 148 | + |
| 149 | + |
| 150 | +> <https://www.cs.cmu.edu/~ggordon/MCMC/ggordon.MCMC-tutorial.pdf> |
| 151 | +
|
| 152 | +- https://www.cs.cornell.edu/courses/cs4780/2022sp/notes/LectureNotes11.html |
| 153 | + |
| 154 | + |
| 155 | + |
| 156 | +> https://bayen.berkeley.edu/sites/default/files/lecture101.pdf |
| 157 | +
|
| 158 | +#### 重点参考 |
| 159 | + |
| 160 | +- Ryan Tibshirani Scribes: Cong Lu/Yu Zhao, 2012, [Lecture 5: Gradient Desent Revisited](https://www.cs.cmu.edu/~ggordon/10725-F12/scribes/10725_Lecture5.pdf) |
| 161 | + |
| 162 | + |
| 163 | +- Ryan Tibshirani Scribes: Cong Lu/Yu Zhao, 2012, [Lecture 2: Optimization](https://www.cs.cmu.edu/~ggordon/10725-F12/scribes/10725_Lecture2.pdf) |
| 164 | +Gradient descent is the grandfather of first order methods. It simply starts at an initial point and then repeatedly takes a step opposite to the gradient direction of the function at the current point. The gradient descent algorithm to minimize a function $f(x)$ is as follows: |
| 165 | + |
| 166 | +$ |
| 167 | +\begin{aligned} |
| 168 | +& \text { for } k=0,1,2, \ldots \text { do } \\ |
| 169 | +& \qquad g_k \leftarrow \nabla f\left(x_k\right) \\ |
| 170 | +& \quad x_{k+1} \leftarrow x_k-t_k g_k \\ |
| 171 | +& \text { end for } |
| 172 | +\end{aligned} |
| 173 | +$ |
| 174 | + |
| 175 | + |
| 176 | +### 随机梯度下降 |
| 177 | + |
| 178 | +> <https://ubc-mds.github.io/DSCI_572_sup-learn-2/lectures/03_sgd-intro-to-nn.html> |
| 179 | +
|
| 180 | +- But if we have large $n$ and/or $\mathbf{w}$, gradient descent becomes very computationally expensive (when we get to deep learning, we'll have models where the number of weights to optimize is in the millions) |
| 181 | +- Say $\mathrm{n}=1,000,000$, we have 1000 parameters to optimize, and we do 1000 iterations $=O\left(10^{12}\right)$ computations |
| 182 | +- For each data point, we need to compute gradients with respect to each of model parameter. |
| 183 | +- For each iteration, it'll have to compute $10^6 \times 10^3=10^9$ gradients |
| 184 | +- We can reduce this workload by using just a fraction of our dataset to update our parameters each iteration (rather than using the whole data set) |
| 185 | +- This is called stochastic gradient descent [1] |
| 186 | + |
| 187 | + |
| 188 | +## Python codes |
| 189 | + |
| 190 | +- [financial-data-science-notebooks](https://github.com/lianxhcn/financial-data-science-notebooks/tree/main) / [6.3\_deep\_learning.ipynb](https://github.com/lianxhcn/financial-data-science-notebooks/blob/main/6.3_deep_learning.ipynb) |
0 commit comments