New initialization method to make k-means more accurate and fast.
-
Choose an initial center uniformly at random from dataset X.
-
choose the next center c = x' with probability, D(x) is the distance bewteen x and the closest center that we've already choosen.
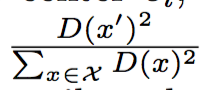
-
Repeat Step 1 until we choose a total of k centers.
-
Continue the standard k-means algorithm.
- The above initialization algorithm makes intuitive sense. By choosing the point that is far from its assigned center to be the next center, one can get k centers that are distant from each other. This way kmeans will converge faster and more likely to stop at a better minima.
- sklearn has a good implementation of this algorithm.
Arthur D, Vassilvitskii S. k-means++: The advantages of careful seeding[C]//Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms. Society for Industrial and Applied Mathematics, 2007: 1027-1035.