|
| 1 | +--- |
| 2 | +id: how-opussearch-built-exact-matching-for-enterprise-rag-with-milvus-bm25.md |
| 3 | +title: How OpusSearch Built Exact Matching for Enterprise RAG with Milvus BM25 |
| 4 | +author: Chronos Kou |
| 5 | +date: 2025-10-17 |
| 6 | +cover: assets.zilliz.com/Chat_GPT_Image_2025_10_18_10_43_29_93fe542daf.png |
| 7 | +tag: Tutorials |
| 8 | +recommend: false |
| 9 | +publishToMedium: true |
| 10 | +tags: Milvus, vector database |
| 11 | +meta_keywords: Milvus, enterprise RAG, vector database, semantic search |
| 12 | +meta_title: How OpusSearch Built Exact Matching for Enterprise RAG with Milvus |
| 13 | +desc: Learn how OpusSearch uses Milvus BM25 to power exact matching in enterprise RAG systems—combining semantic search with precise keyword retrieval. |
| 14 | +origin: https://medium.com/opus-engineering/how-opussearch-built-exact-matching-for-enterprise-rag-with-milvus-bm25-aa1098a9888b |
| 15 | +--- |
| 16 | + |
| 17 | +This post was originally published on [Medium](https://medium.com/opus-engineering/how-opussearch-built-exact-matching-for-enterprise-rag-with-milvus-bm25-aa1098a9888b) and is reposted here with permission. |
| 18 | + |
| 19 | +## The Semantic Search Blind Spot |
| 20 | + |
| 21 | +Picture this: You’re a video editor on deadline. You need clips from “episode 281” of your podcast. You type it into our search. Our AI-powered semantic search, proud of its intelligence, returns clips from 280, 282, and even suggests episode 218 because the numbers are similar, right? |
| 22 | + |
| 23 | +**Wrong**. |
| 24 | + |
| 25 | +When we launched [OpusSearch](https://www.opus.pro/opussearch) for enterprises in January 2025, we thought semantic search would be enough. Natural language queries like “find funny moments about dating” worked beautifully. Our [Milvus](https://milvus.io/)-powered RAG system was crushing it. |
| 26 | + |
| 27 | +**But then reality hit us in the face with user feedback:** |
| 28 | + |
| 29 | +“I just want clips from episode 281. Why is this so hard?” |
| 30 | + |
| 31 | +“When I search ‘That’s what she said,’ I want EXACTLY that phrase, not ‘that’s what he meant.’” |
| 32 | + |
| 33 | +Turns out that video editors and clippers don’t always want AI to be clever. Sometimes they want software to be **straightforward and correct**. |
| 34 | + |
| 35 | +## Why do we care about Search? |
| 36 | + |
| 37 | +We built an [enterprise search function](https://www.opus.pro/opussearch) because we identified that **monetizing** large video catalogs is the key challenge organizations face. Our RAG-powered platform serves as a **growth agent** that enables enterprises to **search, repurpose, and monetize their entire video libraries**. Read about success case stories from **All The Smoke**, **KFC Radio** and **TFTC** [here](https://www.opus.pro/blog/growing-a-new-youtube-channel-in-90-days-without-creating-new-videos). |
| 38 | + |
| 39 | +## Why We Doubled Down on Milvus (Instead of Adding Another Database) |
| 40 | + |
| 41 | +The obvious solution was to add Elasticsearch or MongoDB for exact matching. However, as a startup, maintaining multiple search systems introduces significant operational overhead and complexity. |
| 42 | + |
| 43 | + |
| 44 | + |
| 45 | +Milvus had recently shipped their full-text search feature, and an evaluation with our own dataset **without any tuning** showed compelling advantages: |
| 46 | + |
| 47 | +- **Superior partial matching accuracy**. For example “drinking story” and “jumping high”, other vector DBs returns sometimes “dining story” and “getting high” which alters the meaning. |
| 48 | + |
| 49 | +- Milvus **returns longer, more comprehensive results** than other databases when queries are general, which is naturally more ideal for our use case. |
| 50 | + |
| 51 | +## Architecture from 5000 feet |
| 52 | +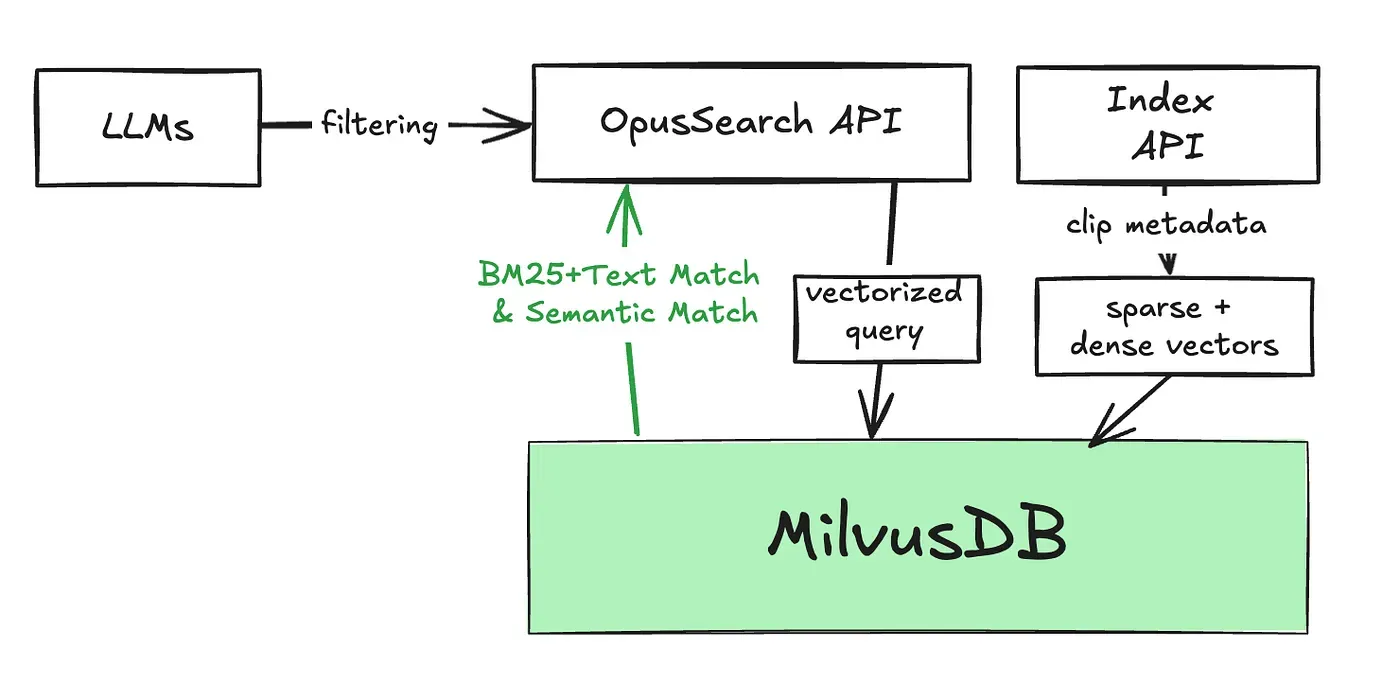 |
| 53 | +## BM25 + Filtering = Exact Match Magic |
| 54 | + |
| 55 | +Milvus’s full-text search isn’t really about exact matching, but it’s about relevance scoring using BM25 ([Best Matching 25](https://en.wikipedia.org/wiki/Okapi_BM25)), which calculates how relevant a document is to your query. It’s great for “find me something close,” but terrible for “find me exactly this.” |
| 56 | + |
| 57 | +We then **combined BM25’s power with Milvus’s TEXT\_MATCH filtering**. Here’s how it works: |
| 58 | + |
| 59 | +1. **Filter first**: TEXT\_MATCH finds documents containing your exact keywords |
| 60 | + |
| 61 | +2. **Rank second**: BM25 sorts those exact matches by relevance |
| 62 | + |
| 63 | +3. **Win**: You get exact matches, ranked intelligently |
| 64 | + |
| 65 | +Think of it as “give me everything with ‘episode 281’, then show me the best ones first.” |
| 66 | + |
| 67 | +## The Code That Made It Work |
| 68 | + |
| 69 | +### Schema Design |
| 70 | + |
| 71 | +**Important**: We disabled stop words entirely, as terms like “The Office” and “Office” represent distinct entities in our content domain. |
| 72 | +``` |
| 73 | +export function getExactMatchFields(): FieldType[] { |
| 74 | + return [ |
| 75 | + { |
| 76 | + name: "id", |
| 77 | + data_type: DataType.VarChar, |
| 78 | + is_primary_key: true, |
| 79 | + max_length: 100, |
| 80 | + }, |
| 81 | + { |
| 82 | + name: "text", |
| 83 | + data_type: DataType.VarChar, |
| 84 | + max_length: 1000, |
| 85 | + enable_analyzer: true, |
| 86 | + enable_match: true, // This is the magic flag |
| 87 | + analyzer_params: { |
| 88 | + tokenizer: 'standard', |
| 89 | + filter: [ |
| 90 | + 'lowercase', |
| 91 | + { |
| 92 | + type: 'stemmer', |
| 93 | + language: 'english', // "running" matches "run" |
| 94 | + }, |
| 95 | + { |
| 96 | + type: 'stop', |
| 97 | + stop_words: [], // Keep ALL words (even "the", "a") |
| 98 | + }, |
| 99 | + ], |
| 100 | + }, |
| 101 | + }, |
| 102 | + { |
| 103 | + name: "sparse_vector", |
| 104 | + data_type: DataType.SparseFloatVector, |
| 105 | + }, |
| 106 | + ] |
| 107 | +} |
| 108 | +``` |
| 109 | +### BM25 Function Setup |
| 110 | +``` |
| 111 | +export const FUNCTIONS: FunctionObject[] = [ |
| 112 | + { |
| 113 | + name: 'text_bm25_embedding', |
| 114 | + type: FunctionType.BM25, |
| 115 | + input_field_names: ['text'], |
| 116 | + output_field_names: ['sparse_vector'], |
| 117 | + params: {}, |
| 118 | + }, |
| 119 | +] |
| 120 | +``` |
| 121 | +### Index Config |
| 122 | + |
| 123 | +These bm25\_k1 and bm25\_b parameters were tuned against our production dataset for optimal performance. |
| 124 | + |
| 125 | +**bm25\_k1**: Higher values (up to \~2.0) give more weight to repeated term occurrences, while lower values reduce the impact of term frequency after the first few occurrences. |
| 126 | + |
| 127 | +**bm25\_b**: Values closer to 1.0 heavily penalize longer documents, while values closer to 0 ignore document length entirely. |
| 128 | +``` |
| 129 | +index_params: [ |
| 130 | + { |
| 131 | + field_name: 'sparse_vector', |
| 132 | + index_type: 'SPARSE_INVERTED_INDEX', |
| 133 | + metric_type: 'BM25', |
| 134 | + params: { |
| 135 | + inverted_index_algo: 'DAAT_MAXSCORE', |
| 136 | + bm25_k1: 1.2, // How much does term frequency matter? |
| 137 | + bm25_b: 0.75, // How much does document length matter? |
| 138 | + }, |
| 139 | + }, |
| 140 | +], |
| 141 | +``` |
| 142 | + |
| 143 | +### The Search Query That Started Working |
| 144 | +``` |
| 145 | +await this.milvusClient.search({ |
| 146 | + collection_name: 'my_collection', |
| 147 | + limit: 30, |
| 148 | + output_fields: ['id', 'text'], |
| 149 | + filter: `TEXT_MATCH(text, "episode 281")`, // Exact match filter |
| 150 | + anns_field: 'sparse_vector', |
| 151 | + data: 'episode 281', // BM25 ranking query |
| 152 | +}) |
| 153 | +``` |
| 154 | +For multi-term exact matches: |
| 155 | +``` |
| 156 | +filter: `TEXT_MATCH(text, "foo") and TEXT_MATCH(text, "bar")` |
| 157 | +``` |
| 158 | +## The Mistakes We Made (So You Don’t Have To) |
| 159 | + |
| 160 | +### Dynamic Fields: Critical for Production Flexibility |
| 161 | + |
| 162 | +Initially, we didn’t enable dynamic fields, which was problematic. Schema modifications required dropping and recreating collections in production environments. |
| 163 | + |
| 164 | +``` |
| 165 | +await this.milvusClient.createCollection({ |
| 166 | + collection_name: collectionName, |
| 167 | + fields: fields, |
| 168 | + enable_dynamic_field: true, // DO THIS |
| 169 | + // ... rest of config |
| 170 | +}) |
| 171 | +``` |
| 172 | +### Collection Design: Maintain Clear Separation of Concerns |
| 173 | + |
| 174 | +Our architecture uses dedicated collections per feature domain. This modular approach minimizes the impact of schema changes and improves maintainability. |
| 175 | + |
| 176 | +### Memory Usage: Optimize with MMAP |
| 177 | + |
| 178 | +Sparse indexes require significant memory allocation. For large text datasets, we recommend configuring MMAP to utilize disk storage. This approach requires adequate I/O capacity to maintain performance characteristics. |
| 179 | + |
| 180 | +``` |
| 181 | +// In your Milvus configuration |
| 182 | +use_mmap: true |
| 183 | +``` |
| 184 | +## Production Impact and Results |
| 185 | + |
| 186 | +Following the June 2025 deployment of exact match functionality, we observed measurable improvements in user satisfaction metrics and reduced support volume for search-related issues. Our dual-mode approach enables semantic search for exploratory queries while providing precise matching for specific content retrieval. |
| 187 | + |
| 188 | +The key architectural benefit: maintaining a single database system that supports both search paradigms, reducing operational complexity while expanding functionality. |
| 189 | + |
| 190 | +## What’s Next? |
| 191 | + |
| 192 | +We’re experimenting with **hybrid** **queries combining semantic and exact match in a single search**. Imagine: “Find funny clips from episode 281” where “funny” uses semantic search and “episode 281” uses exact match. |
| 193 | + |
| 194 | +The future of search isn’t picking between semantic AI and exact matching. It’s using **both** intelligently in the same system. |
0 commit comments