|
| 1 | +--- |
| 2 | +id: from-scaling-pains-to-seamless-growth-why-vector-database-architecture-matters.md |
| 3 | +title: "From Scaling Pains to Seamless Growth: Why Vector Database Architecture Matters" |
| 4 | +author: James Luan |
| 5 | +date: 2025-03-18 |
| 6 | +desc: Many developers—from startups to enterprises—have recognized the significant overhead associated with manual database sharding. Milvus takes a fundamentally different approach, enabling seamless scaling from millions to billions of vectors without the complexity. |
| 7 | +cover: assets.zilliz.com/From_Scaling_Pains_to_Seamless_Growth_Why_Vector_Database_Architecture_Matters_7ce21ed9a2.png |
| 8 | +tag: Engineering |
| 9 | +recommend: true |
| 10 | +canonicalUrl: https://milvus.io/blog/from-scaling-pains-to-seamless-growth-why-vector-database-architecture-matters.md |
| 11 | +--- |
| 12 | + |
| 13 | +_"We initially built our vector search system on pgvector because all our relational data was already in PostgreSQL,"_ recalls Alex, CTO of an enterprise AI SaaS startup. _"But as soon as we hit product-market fit, our growth trajectory exposed a critical limitation: pgvector requires manual sharding to scale, which created enormous engineering complexity."_ |
| 14 | + |
| 15 | +Alex's team discovered this the hard way. _"Simple tasks—like rolling out schema updates across multiple shards—turned into tedious, error-prone processes that consumed days of engineering effort. When we reached 100 million vector embeddings, query latency spiked to over a second—far beyond what our customers would tolerate."_ |
| 16 | + |
| 17 | +That's when they decided to make a change. _"Moving to Milvus eliminated the need for manual sharding entirely. Looking back, juggling individual database servers felt like working with fragile artifacts. No company should have to endure that engineering burden when they should be focused on growth."_ |
| 18 | + |
| 19 | + |
| 20 | +## A Common Challenge for AI Companies |
| 21 | + |
| 22 | +Alex's experience isn't unique to pgvector users. Whether you're using pgvector, Qdrant, Weaviate, or any other vector database that relies on manual sharding, the scaling challenges remain the same. What starts as a manageable solution quickly turns into a technical bottleneck as data volumes grow. |
| 23 | + |
| 24 | +For AI startups today, **scalability isn't optional—it's mission-critical**. This is especially true for products powered by Large Language Models (LLMs) and vector databases, where the leap from early adoption to exponential growth can happen overnight. Achieving product-market fit often triggers a surge in user acquisition, overwhelming data inflows, and skyrocketing query demands. But if the database infrastructure can't keep up, slow queries and operational inefficiencies can stall momentum and hinder business success. |
| 25 | + |
| 26 | +Short-term technical decisions often lead to long-term bottlenecks, forcing engineering teams to constantly address urgent performance issues, database crashes, and system failures instead of focusing on innovation. The worst-case scenario? A costly, time-consuming database re-architecture—precisely when a company should be scaling. |
| 27 | + |
| 28 | + |
| 29 | +## The Scaling Dilemma: Up or Out? |
| 30 | + |
| 31 | +When facing growth challenges, companies typically consider two approaches to scalability: |
| 32 | + |
| 33 | +**Scale-Up**: The simplest approach involves enhancing a single machine's capabilities—adding more CPU, memory, or storage to handle larger data volumes. While straightforward, this strategy quickly runs into practical limitations. Particularly in Kubernetes environments, large pods aren't efficient solutions, and a single node's failure can trigger substantial downtime. |
| 34 | + |
| 35 | +**Scale-Out**: If Scale-Up isn't feasible, businesses naturally turn to distributing data across multiple servers through sharding. At first glance, this seems simple: split your database into smaller, independent databases, creating more capacity and multiple writable primary nodes. |
| 36 | + |
| 37 | +Unfortunately, while conceptually simple, sharding quickly becomes incredibly complex in practice. Once a single vector database is fragmented into multiple shards, every piece of application code interacting with data must be revised or rewritten. |
| 38 | + |
| 39 | + |
| 40 | +## Why Manual Sharding Becomes a Burden |
| 41 | + |
| 42 | +_"We originally estimated implementing manual sharding for our pgvector database would take two engineers about six months,"_ Alex remembers. _"What we didn't realize was that those engineers would_ **_always_** _be needed. Every schema change, data rebalancing operation, or scaling decision required their specialized expertise. We were essentially committing to a permanent 'sharding team' just to keep our database running."_ |
| 43 | + |
| 44 | +Real-world challenges with sharded vector databases include: |
| 45 | + |
| 46 | +1. **Data Distribution Imbalance (Hotspots)**: In multi-tenant use cases, data distribution can range from hundreds to billions of vectors per tenant. This imbalance creates hotspots where certain shards become overloaded while others sit idle. |
| 47 | + |
| 48 | +2. **The Resharding Headache**: Choosing the right number of shards is nearly impossible. Too few leads to frequent and costly resharding operations. Too many creates unnecessary metadata overhead, increasing complexity and reducing performance. |
| 49 | + |
| 50 | +3. **Schema Change Complexity**: Many vector databases implement sharding by managing multiple underlying databases. This makes synchronizing schema changes across shards cumbersome and error-prone, slowing development cycles. |
| 51 | + |
| 52 | +4. **Resource Waste**: In storage-compute coupled databases, you must meticulously allocate resources across every node while anticipating future growth. Typically, when resource utilization reaches 60-70%, you need to start planning for resharding. |
| 53 | + |
| 54 | +Simply put, **sharding is bad for your business**. Instead of locking your engineering team into constant shard management, consider investing in a vector database designed to scale automatically—without the operational burden. |
| 55 | + |
| 56 | + |
| 57 | +## How Milvus Solves the Scalability Problem |
| 58 | + |
| 59 | +Many developers—from startups to enterprises—have recognized the significant overhead associated with manual database sharding. Milvus takes a fundamentally different approach, enabling seamless scaling from millions to billions of vectors without the complexity. |
| 60 | + |
| 61 | + |
| 62 | +### Automated Scaling Without the Engineering Tax |
| 63 | + |
| 64 | +Milvus leverages Kubernetes and a disaggregated storage-compute architecture to support seamless expansion. This design enables: |
| 65 | + |
| 66 | +- Rapid scaling in response to changing demands |
| 67 | + |
| 68 | +- Automatic load balancing across all available nodes |
| 69 | + |
| 70 | +- Independent resource allocation, letting you adjust compute, memory, and storage separately |
| 71 | + |
| 72 | +- Consistent high performance, even during periods of rapid growth |
| 73 | + |
| 74 | + |
| 75 | +### How Milvus Scales: The Technical Foundation |
| 76 | + |
| 77 | +Milvus achieves its scaling capabilities through two key innovations: |
| 78 | + |
| 79 | +**Segment-Based Architecture**: At its core, Milvus organizes data into "segments"—the smallest units of data management: |
| 80 | + |
| 81 | +- Growing Segments reside on StreamNodes, optimizing data freshness for real-time queries |
| 82 | + |
| 83 | +- Sealed Segments are managed by QueryNodes, utilizing powerful indexes to accelerate search |
| 84 | + |
| 85 | +- These segments are evenly distributed across nodes to optimize parallel processing |
| 86 | + |
| 87 | +**Two-Layer Routing**: Unlike traditional databases where each shard lives on a single machine, Milvus distributes data in one shard dynamically across multiple nodes: |
| 88 | + |
| 89 | +- Each shard can store over 1 billion data points |
| 90 | + |
| 91 | +- Segments within each shard are automatically balanced across machines |
| 92 | + |
| 93 | +- Expanding collections is as simple as increasing the number of shards |
| 94 | + |
| 95 | +- The upcoming Milvus 3.0 will introduce dynamic shard splitting, eliminating even this minimal manual step |
| 96 | + |
| 97 | + |
| 98 | +### Query Processing at Scale |
| 99 | + |
| 100 | +When executing a query, Milvus follows an efficient process: |
| 101 | + |
| 102 | +1. The Proxy identifies relevant shards for the requested collection |
| 103 | + |
| 104 | +2. The Proxy gathers data from both StreamNodes and QueryNodes |
| 105 | + |
| 106 | +3. StreamNodes handle real-time data while QueryNodes process historical data concurrently |
| 107 | + |
| 108 | +4. Results are aggregated and returned to the user |
| 109 | + |
| 110 | + |
| 111 | +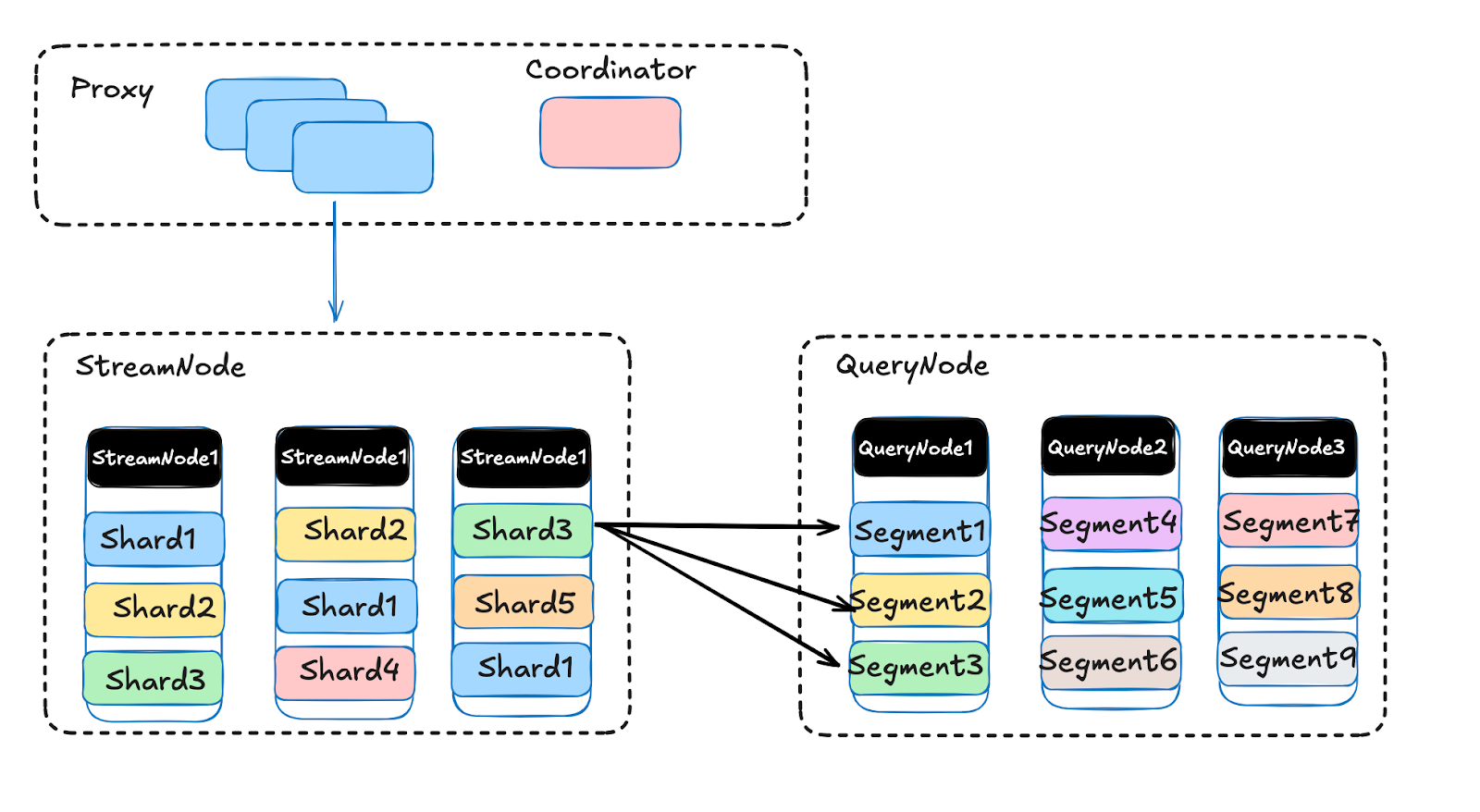 |
| 112 | + |
| 113 | +## A Different Engineering Experience |
| 114 | + |
| 115 | +_"When scalability is built into the database itself, all those headaches just... disappear,"_ says Alex, reflecting on his team's transition to Milvus. _"My engineers are back to building features customers love instead of babysitting database shards."_ |
| 116 | + |
| 117 | +If you're grappling with the engineering burden of manual sharding, performance bottlenecks at scale, or the daunting prospect of database migrations, it's time to rethink your approach. Visit[ ](https://milvus.io/docs/overview.md)our [docs page](https://milvus.io/docs/overview.md#What-Makes-Milvus-so-Scalable) to learn more about Milvus architecture, or experience effortless scalability firsthand with [Zilliz Cloud, a fully managed Milvus service](https://zilliz.com/cloud) at[zilliz.com](https://zilliz.com/). |
| 118 | + |
| 119 | +With the right vector database foundation, your innovation knows no limits. |
| 120 | + |
| 121 | + |
0 commit comments