|
| 1 | +--- |
| 2 | +id: minhash-lsh-in-milvus-the-secret-weapon-for-fighting-duplicates-in-llm-training-data.md |
| 3 | +title: > |
| 4 | + MinHash LSH in Milvus: The Secret Weapon for Fighting Duplicates in LLM Training Data |
| 5 | +author: Li Liu, Yaya Cheng |
| 6 | +date: 2025-05-16 |
| 7 | +desc: MinHash LSH in Milvus 2.6 offers an efficient solution for deduplicating massive LLM training datasets, with 2x faster processing and 3- 5x cost savings compared to traditional methods. |
| 8 | +cover: assets.zilliz.com/Chat_GPT_Image_May_16_2025_09_46_39_PM_1f3290ce5e.png |
| 9 | +tag: Engineering |
| 10 | +recommend: true |
| 11 | +publishToMedium: true |
| 12 | +tags: Milvus, vector database, vector search, AI Agents, LLM |
| 13 | +meta_keywords: MinHash LSH, Locality Sensitive Hashing, Milvus, LLM training data |
| 14 | +meta_title: > |
| 15 | + MinHash LSH in Milvus: The Secret Weapon for Fighting Duplicates in LLM Training Data |
| 16 | +origin: https://milvus.io/blog/minhash-lsh-in-milvus-the-secret-weapon-for-fighting-duplicates-in-llm-training-data.md |
| 17 | +--- |
| 18 | + |
| 19 | +Large Language Models (LLMs) have transformed the AI landscape with their ability to write code, create content, and solve complex problems. However, these powerful models require enormous amounts of high-quality data to fuel their training. |
| 20 | + |
| 21 | +The challenge is that raw training data often contains significant redundancy. It's like teaching a child by repeating the same lessons over and over while skipping other important topics. A large AI company approached us with exactly this problem - they were building an ambitious new language model but struggled with deduplicating tens of billions of documents. Traditional matching methods couldn't scale to this volume, and specialized deduplication tools required massive computational resources, making them economically unviable. |
| 22 | + |
| 23 | +To solve this problem, our solution is: MinHash LSH (Locality Sensitive Hashing) indexing, which will be available in Milvus 2.6. In this article, we'll explore how MinHash LSH efficiently solves the data deduplication problem for LLM training. |
| 24 | + |
| 25 | + |
| 26 | + |
| 27 | + |
| 28 | +## Data Deduplication: Why It Matters for LLM Training |
| 29 | + |
| 30 | +High-quality, diverse data is essential for training powerful LLMs. When duplicate content appears in training data, it creates several significant problems: |
| 31 | + |
| 32 | +- **Wasted Resources:** Redundant data increases training time, costs, and energy consumption. |
| 33 | + |
| 34 | +- **Reduced Performance:** Models can overfit to repeated content, limiting their ability to generalize to new information. |
| 35 | + |
| 36 | +- **Memorization Effect:** Duplicated content increases the chance of models memorizing and reproducing specific text verbatim. It could also potentially lead to privacy leaks or copyright issues. |
| 37 | + |
| 38 | +- **Misleading Evaluations:** Duplicates between training and test sets can accidentally inflate performance metrics. |
| 39 | + |
| 40 | +There are three main approaches to finding and removing duplicates: |
| 41 | + |
| 42 | +- **Exact Matching:** Identifies identical duplicates through hashing. |
| 43 | + |
| 44 | +- **Approximate Matching:** Finds near-duplicates using algorithms like MinHash LSH and Jaccard similarity. |
| 45 | + |
| 46 | +- **Semantic Matching:** Identifies content with similar meaning using vector embeddings. |
| 47 | + |
| 48 | +With pre-training corpora reaching terabytes or even petabytes, traditional exact matching methods like pairwise comparisons are computationally infeasible. Semantic deduplication adds significant overhead by using embedding models to generate vectors. We need smarter approximate methods—like **MinHash LSH**—that balance recall and precision while keeping costs manageable, making large-scale deduplication practical. |
| 49 | + |
| 50 | + |
| 51 | +## MinHash LSH: Efficiently Detecting Near-Duplicates in Massive Datasets |
| 52 | + |
| 53 | +To find near-duplicates in an ocean of training data, we need an approximate matching algorithm that’s both efficient and accurate. MinHash LSH (Locality Sensitive Hashing) is a great tool for this goal. Let’s break down this seemingly complex term step by step. |
| 54 | + |
| 55 | + |
| 56 | +### Step 1: Representing Documents with MinHash |
| 57 | + |
| 58 | +First, we need a way to measure document similarity. The standard approach uses Jaccard similarity: |
| 59 | + |
| 60 | +$$J(A,B) = \frac{|A\cap B|}{|A \cup B|}$$ |
| 61 | + |
| 62 | +This formula measures the overlap between document A and document B - specifically, the ratio of shared elements to total unique elements. A higher value means the documents are more similar. |
| 63 | + |
| 64 | +However, computing this directly for billions of document pairs is resource-intensive and would take years. MinHash creates compact "fingerprints" (signatures) that preserve similarity relationships while making comparisons much faster. |
| 65 | + |
| 66 | +1. **Shingling:** Break each document into overlapping sequences of words or characters (k-shingles). For example, the sentence “I love vector search” with k=3 (by word) yields: {“I love vector”, “love vector search”} |
| 67 | + |
| 68 | +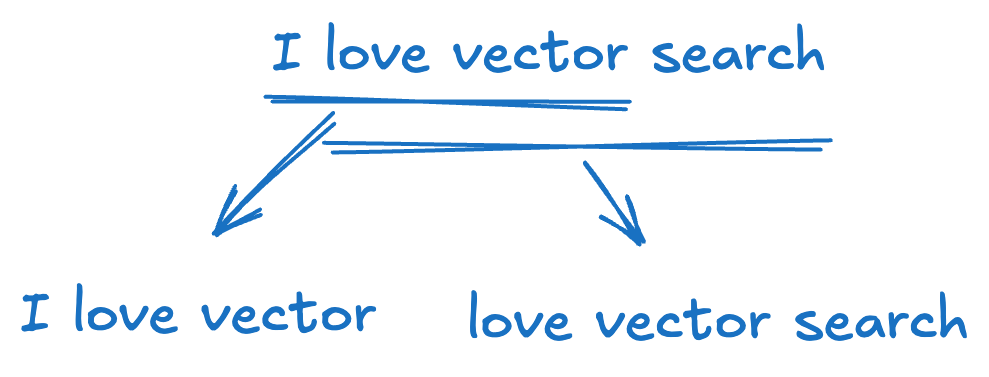 |
| 69 | + |
| 70 | +2. **MinHashing:** Apply multiple hash functions to each set of shingles and record the minimum hash value from each function. This results in a signature vector for each document. |
| 71 | + |
| 72 | + |
| 73 | + |
| 74 | +When calculating similarity, the probability that hash values align at the same positions in the MinHash signatures of two documents (which corresponds to the Jaccard distance of these signatures) provides a close approximation of the Jaccard similarity of their original shingle sets. This allows us to effectively estimate document similarity without needing to compare the larger original texts directly; instead, we can analyze their compact MinHash signatures. |
| 75 | + |
| 76 | +The MinHash principle involves using the word with the smallest hash value to represent the entire document, enhancing accuracy by incorporating additional hash functions. Minor word changes are likely to be overlooked as they typically do not affect the minimum hash value, while more substantial changes tend to alter the hash value and are more easily detected. This method can be seen as a min-pooling of hash values across various words. In addition to MinHash, alternatives like SimHash are available for generating document signatures, but those will not be discussed here. |
| 77 | + |
| 78 | + |
| 79 | +### Step 2: Identifying Similar Documents via LSH |
| 80 | + |
| 81 | +Even with compact MinHash signatures, comparing every pair across millions or billions of documents remains computationally expensive. That’s where **Locality Sensitive Hashing (LSH)** comes in. |
| 82 | + |
| 83 | +The key idea of LSH is to use hash functions that **intentionally cause collisions**—similar items are more likely to hash into the same bucket, while dissimilar ones are not. This is the opposite of traditional hashing, which aims to avoid collisions. |
| 84 | + |
| 85 | +For MinHash, a popular LSH strategy is the **banding technique**: |
| 86 | + |
| 87 | +1. **Banding**: Split each MinHash signature (a vector of length _N_) into _b_ bands, each with _r_ rows (_N = b × r_). |
| 88 | + |
| 89 | +2. **Hashing Bands:** Hash each band (a sub-vector of _r_ values) into a bucket using a standard hash function. |
| 90 | + |
| 91 | +3. **Candidate Pairs:** If two documents share a bucket in **any** band, they are flagged as potential matches. |
| 92 | + |
| 93 | +By adjusting the number of bands (b) and the number of rows per band (r), you can control the trade-off between recall, precision, and search efficiency. |
| 94 | + |
| 95 | +The key idea is: highly similar documents will have many matching hash values in their MinHash signatures. When these signatures are split into bands, even one band with all matching values is enough to place two documents in the same bucket. The more similar the documents are, the higher the probability that this happens in at least one band, allowing LSH to efficiently surface candidate pairs without exhaustively comparing all signatures. |
| 96 | + |
| 97 | +In short, **MinHash + LSH** enables scalable approximate deduplication: MinHash compresses documents into compact signatures, and LSH efficiently narrows the search space by grouping likely matches. It’s like spotting twins in a crowd: first, take a quick feature snapshot of everyone (MinHash), group lookalikes (LSH), then inspect the smaller groups closely for actual duplicates. |
| 98 | + |
| 99 | + |
| 100 | +## Integrating MinHash LSH in Milvus 2.6 |
| 101 | + |
| 102 | +The integration of MinHash LSH into Milvus 2.6 was driven by a real-world need. As mentioned earlier, a Milvus user—one of the leading LLM companies—approached us with a challenge: efficiently deduplicating massive volumes of text data for LLM pre-training. |
| 103 | + |
| 104 | +Traditional deduplication pipelines typically rely on external tools that are decoupled from storage and retrieval systems, requiring costly data transfers between components. This fragmented workflow increases operational overhead and prevents full utilization of distributed computing resources. |
| 105 | + |
| 106 | +Recognizing Milvus’s strengths in handling high-throughput vector data, a natural idea emerged: **_What if MinHash LSH were built into Milvus natively, making approximate deduplication a first-class database feature?_** |
| 107 | + |
| 108 | +This approach enables a complete workflow from deduplication to semantic retrieval within Milvus, simplifying MLOps while leveraging its scalability and unified API. Together with our partner, we optimized MinHash LSH for Milvus’s cloud-native architecture, resulting in a fast and scalable solution for large-scale deduplication. |
| 109 | + |
| 110 | + |
| 111 | +### Core capabilities in Milvus 2.6 include: |
| 112 | + |
| 113 | +- **Native MinHash LSH Indexing:** Implements the standard banding technique for LSH and supports optional Jaccard re-ranking to improve recall. Provides both in-memory and mmap-based implementations for flexibility across different workloads. |
| 114 | + |
| 115 | +- **Seamless API Integration:** Users can define MinHash vector fields, build `MINHASH_LSH` indexes, insert signature data, and perform approximate similarity searches using Milvus’s standard SDK and declarative APIs. |
| 116 | + |
| 117 | +- **Distributed and Scalable:** Built on Milvus’s cloud-native architecture, the feature supports horizontal scaling for large datasets and high-throughput processing. |
| 118 | + |
| 119 | +This integration delivered impressive results. By running MinHash LSH on fully-managed Milvus (Zilliz Cloud), we helped this user deduplicate **10 billion documents** efficiently. Compared to their previous MapReduce-based approach, the new solution **more than doubled processing speed** and achieved **3-5x cost savings**, thanks to Milvus’s optimized indexing and query execution. |
| 120 | + |
| 121 | + |
| 122 | +## Hands-On: Deduplicating LLM Datasets Using Milvus |
| 123 | + |
| 124 | +Let's roll up our sleeves and use MinHash LSH in Milvus 2.6 to perform approximate deduplication at scale. |
| 125 | + |
| 126 | + |
| 127 | +### Prerequisite: Generating MinHash Signatures |
| 128 | + |
| 129 | +Milvus handles the indexing and search of **pre-generated** MinHash signatures. You’ll need to generate these during preprocessing using tools like `datasketch` in Python or a custom implementation. The typical steps are: |
| 130 | + |
| 131 | +1. Read raw documents |
| 132 | + |
| 133 | +2. Shingle (tokenize or chunk) each document |
| 134 | + |
| 135 | +3. Apply multiple hash functions to generate a MinHash signature (e.g., an uint64 array of size 128 ) |
| 136 | + |
| 137 | +``` |
| 138 | +from datasketch import MinHash |
| 139 | +
|
| 140 | +text = "example text for minhash signature" |
| 141 | +tokens = text.lower().split() # Step 1 & 2: preprocess + tokenize/shingle |
| 142 | +mh = MinHash(num_perm=128) # Step 3: initialize MinHash |
| 143 | +for token in tokens: |
| 144 | + mh.update(token.encode('utf-8')) # Add shingles to MinHash |
| 145 | +signature = mh.hashvalues # This is your MinHash signature (128-dimensional) |
| 146 | +``` |
| 147 | + |
| 148 | + |
| 149 | + |
| 150 | +### Step 1: Create a Schema in Milvus |
| 151 | + |
| 152 | +We need to create a Milvus collection to store the MinHash signatures and their corresponding document IDs. |
| 153 | + |
| 154 | +``` |
| 155 | +import numpy as np |
| 156 | +from pymilvus import MilvusClient |
| 157 | +from pymilvus import DataType |
| 158 | +MILVUS_URI = "localhost:19530" |
| 159 | +COLLECTION_NAME = "llm_data_dedup_minhash" |
| 160 | +MINHASH_DIM = 128 |
| 161 | +MINHASH_BIT_WIDTH = 64 # Assuming 64-bit hash values |
| 162 | +
|
| 163 | +# Load data from NPY file |
| 164 | +base = np.load('minhash_vectors.npy') |
| 165 | +ids = [str(i) for i in range(base.shape[0])] # Generate string IDs |
| 166 | +
|
| 167 | +client = MilvusClient(uri=MILVUS_URI) |
| 168 | +# Check and drop existing collection if needed |
| 169 | +if collection_name in client.list_collections(): |
| 170 | + print(f"Collection {collection_name} exists, dropping it...") |
| 171 | + client.drop_collection(collection_name) |
| 172 | +# Create collection schema |
| 173 | +schema = MilvusClient.create_schema( |
| 174 | + auto_id=False, |
| 175 | + enable_dynamic_field=False, |
| 176 | +) |
| 177 | +
|
| 178 | +schema.add_field(field_name="input_id", datatype=DataType.INT64, is_primary=True) |
| 179 | +schema.add_field(field_name="minhash", datatype=DataType.BINARY_VECTOR, dim=MINHASH_DIM * MINHASH_BIT_WIDTH) |
| 180 | +schema.add_field(field_name="id", datatype=DataType.VARCHAR, max_length=200) |
| 181 | +``` |
| 182 | + |
| 183 | + |
| 184 | +### **Step 2: Create the MINHASH_LSH Index and Collection** |
| 185 | + |
| 186 | +This is the core step. We need to specify JACCARD as the metric type and configure LSH-related parameters. |
| 187 | + |
| 188 | +``` |
| 189 | +INDEX_FIELD_NAME = "minhash_signature" |
| 190 | +# Metric type, should be JACCARD for MinHash LSH |
| 191 | +METRIC_TYPE = "MHJACCARD" |
| 192 | +INDEX_TYPE = "MINHASH_LSH" |
| 193 | +MINHASH_DIM = 128 |
| 194 | +MINHASH_BIT_WIDTH = 64 # Assuming 64-bit hash values |
| 195 | +
|
| 196 | +index_params = MilvusClient.prepare_index_params() |
| 197 | +
|
| 198 | +index_params.add_index( |
| 199 | + field_name=INDEX_FIELD_NAME, |
| 200 | + index_type=INDEX_TYPE, |
| 201 | + metric_type=METRIC_TYPE, |
| 202 | + params={ |
| 203 | + # LSH-specific parameters might be configured here, e.g.: |
| 204 | + # "band": 32, # Hypothetical parameter: number of bands |
| 205 | + # "element_bit_width": 64 # Bit width of minhash values |
| 206 | + } |
| 207 | +) |
| 208 | +# Create collection |
| 209 | +client.create_collection( |
| 210 | + collection_name=collection_name, |
| 211 | + schema=schema, |
| 212 | + index_params=index_params |
| 213 | +) |
| 214 | +``` |
| 215 | + |
| 216 | + |
| 217 | +A Note on Parameter Tuning: The effectiveness of MinHash LSH heavily depends on parameter choices. For instance, the number of hash functions used during MinHash signature generation (i.e., `MINHASH_DIM`) affects the signature's precision and size. In the LSH phase, the number of bands (`num_bands`) and rows per band together determine the sensitivity range of the similarity threshold and the balance between recall and precision. Users need to experiment and fine-tune based on their dataset characteristics and deduplication requirements. This is often an iterative process. |
| 218 | + |
| 219 | + |
| 220 | +### **Step 3: Insert MinHash Signatures** |
| 221 | + |
| 222 | +Let's say you have a batch of documents and their corresponding MinHash signatures. |
| 223 | + |
| 224 | +``` |
| 225 | +# Insert data in batches |
| 226 | +batch_size = 2000 |
| 227 | +total_records = base.shape[0] |
| 228 | +num_batches = (total_records + batch_size - 1) // batch_size |
| 229 | +
|
| 230 | +for batch_idx in range(num_batches): |
| 231 | + start = batch_idx * batch_size |
| 232 | + end = min((batch_idx + 1) * batch_size, total_records) |
| 233 | + |
| 234 | + print(f"Inserting batch {batch_idx + 1}/{num_batches} (records {start}-{end})") |
| 235 | + |
| 236 | + # Prepare batch data |
| 237 | + batch_data = [{ |
| 238 | + "input_id": i, |
| 239 | + "minhash": base[i].tobytes(), |
| 240 | + "id": ids[i] |
| 241 | + } for i in range(start, end)] |
| 242 | + |
| 243 | + # Insert batch |
| 244 | + client.insert(collection_name, batch_data) |
| 245 | +
|
| 246 | +print("Data insertion complete") |
| 247 | +``` |
| 248 | + |
| 249 | + |
| 250 | +### Step 5: Search for Near-Duplicates |
| 251 | + |
| 252 | +Use a document’s MinHash signature to search for similar documents in the collection. |
| 253 | + |
| 254 | +``` |
| 255 | +# Perform search |
| 256 | +search_vectors = [vec.tobytes() for vec in base[:10]] |
| 257 | +results = client.search( |
| 258 | + collection_name, |
| 259 | + data=search_vectors, |
| 260 | + param={"metric_type": METRIC_TYPE, "params": search_params_lsh}, |
| 261 | + limit=1, |
| 262 | + output_fields=["id"]) |
| 263 | +
|
| 264 | +print("\nSearch results:") |
| 265 | +for i, result in enumerate(results): |
| 266 | + print(f"Query {i}:") |
| 267 | + for hit in result: |
| 268 | + print(f" - ID: {hit['entity']['id']}, Distance: {hit['distance']}") |
| 269 | +``` |
| 270 | + |
| 271 | + |
| 272 | + |
| 273 | +### Step 6: Post-Processing and Clustering |
| 274 | + |
| 275 | +The returned results are **candidate near-duplicates**. To form complete deduplication groups, you can apply clustering techniques like **Union-Find** on the candidate pairs. Each resulting group represents a set of duplicates; keep one representative document and archive or remove the rest. |
| 276 | + |
| 277 | + |
| 278 | +## **Conclusion** |
| 279 | + |
| 280 | +MinHash LSH in Milvus 2.6 is a leap forward in AI data processing. What started as a solution for LLM data deduplication now opens doors to broader use cases—web content cleanup, catalog management, plagiarism detection, and more. |
| 281 | + |
| 282 | +If you have a similar use case, please reach out to us on the Milvus Discord to sign up for an Office Hour meeting. |
0 commit comments