+(make sure you choose *username*/pytorch instead of pytorch/pytorch)
+
+ +1. Create a new branch called `pull-request` from `main` branch. +2. In the `torch/nn/functional.py` file, navigate to the `l1_loss` function (line 3308) and add code to check if the reduction mode is `sum` and raise an exception: +3. Commit the changes to the `pull-request` branch. Make sure you add a meaningful commit message. +4. Push the `pull-request` branch to the remote repository. +5. Create a pull request to merge the `pull-request` branch into the `main` branch. +6. Approve the pull request. +7. Merge the `pull-request` branch into the `main` branch. + + + +## Useful commands + +- `git checkout -b
-All [assignments](https://github.com/mlip-cmu/s2023/tree/main/assignments) available on GitHub now
+Most [assignments](https://github.com/mlip-cmu/s2024/tree/main/assignments) available on GitHub now
Series of 4 small to medium-sized **individual assignments**:
* Engage with practical challenges
@@ -541,38 +535,54 @@ Design your own research project and write a report
Very open ended: Align with own research interests and existing projects
-See the [project description](https://github.com/mlip-cmu/s2023/blob/main/assignments/research_project.md) and talk to us
+See the [project requirements](https://github.com/mlip-cmu/s2024/blob/main/assignments/research_project.md) and talk to us
First hard milestone: initial description due Feb 27
+
+.element: class="plain" style="width:100%"
+-->
----
-## Recitations
+## Labs
Introducing various tools, e.g., fastAPI (serving), Kafka (stream processing), Jenkins (continuous integration), MLflow (experiment tracking), Docker & Kubernetis (containers), Prometheus & Grafana (monitoring), CHAP (explainability)...
Hands on exercises, bring a laptop
-Often introducing tools relevant for assignments
+Often introducing tools useful for assignments
+
+about 1h of work, graded pass/fail, low stakes, show work to TA
-First recitation on **this Friday**: Calling, securing, and creating APIs
+First lab on **this Friday**: Calling, securing, and creating APIs
+
+----
+## Lab grading and collaboration
+
+We recommend to start at lab before the recitation, but can be completed during
+
+Graded pass/fail by TA on the spot, can retry
+
+*Relaxed collaboration policy:* Can work with others before and during recitation, but have to present/explain solution to TA individually
+
+(Think of recitations as mandatory office hours)
----
## Grading
-* 40% individual assignment
+* 35% individual assignment
* 30% group project with final presentation
* 10% midterm
* 10% participation
* 10% reading quizzes
+* 5% labs
* No final exam (final presentations will take place in that timeslot)
Expected grade cutoffs in syllabus (>82% B, >94 A-, >96% A, >99% A+)
@@ -600,14 +610,14 @@ Opportunities to resubmit work until last day of class
\ No newline at end of file
+
diff --git a/lectures/07_modeltesting/capabilities1.png b/lectures/07_modeltesting/capabilities1.png
deleted file mode 100644
index 0fd08926..00000000
Binary files a/lectures/07_modeltesting/capabilities1.png and /dev/null differ
diff --git a/lectures/07_modeltesting/capabilities2.png b/lectures/07_modeltesting/capabilities2.png
deleted file mode 100644
index 5d8ae5e4..00000000
Binary files a/lectures/07_modeltesting/capabilities2.png and /dev/null differ
diff --git a/lectures/07_modeltesting/checklist.jpg b/lectures/07_modeltesting/checklist.jpg
deleted file mode 100644
index 64d7b725..00000000
Binary files a/lectures/07_modeltesting/checklist.jpg and /dev/null differ
diff --git a/lectures/07_modeltesting/ci.png b/lectures/07_modeltesting/ci.png
deleted file mode 100644
index e686e50f..00000000
Binary files a/lectures/07_modeltesting/ci.png and /dev/null differ
diff --git a/lectures/07_modeltesting/coverage.png b/lectures/07_modeltesting/coverage.png
deleted file mode 100644
index 35f64927..00000000
Binary files a/lectures/07_modeltesting/coverage.png and /dev/null differ
diff --git a/lectures/07_modeltesting/easeml.png b/lectures/07_modeltesting/easeml.png
deleted file mode 100644
index 19bc1a62..00000000
Binary files a/lectures/07_modeltesting/easeml.png and /dev/null differ
diff --git a/lectures/07_modeltesting/googlehome.jpg b/lectures/07_modeltesting/googlehome.jpg
deleted file mode 100644
index 9c7660d2..00000000
Binary files a/lectures/07_modeltesting/googlehome.jpg and /dev/null differ
diff --git a/lectures/07_modeltesting/imgcaptioning.png b/lectures/07_modeltesting/imgcaptioning.png
deleted file mode 100644
index 9de8d250..00000000
Binary files a/lectures/07_modeltesting/imgcaptioning.png and /dev/null differ
diff --git a/lectures/07_modeltesting/inputpartitioning.png b/lectures/07_modeltesting/inputpartitioning.png
deleted file mode 100644
index e10dfcb8..00000000
Binary files a/lectures/07_modeltesting/inputpartitioning.png and /dev/null differ
diff --git a/lectures/07_modeltesting/inputpartitioning2.png b/lectures/07_modeltesting/inputpartitioning2.png
deleted file mode 100644
index b2a8f1ea..00000000
Binary files a/lectures/07_modeltesting/inputpartitioning2.png and /dev/null differ
diff --git a/lectures/07_modeltesting/mlflow-web-ui.png b/lectures/07_modeltesting/mlflow-web-ui.png
deleted file mode 100644
index 82e3e39a..00000000
Binary files a/lectures/07_modeltesting/mlflow-web-ui.png and /dev/null differ
diff --git a/lectures/07_modeltesting/mlvalidation.png b/lectures/07_modeltesting/mlvalidation.png
deleted file mode 100644
index e536d91f..00000000
Binary files a/lectures/07_modeltesting/mlvalidation.png and /dev/null differ
diff --git a/lectures/07_modeltesting/modelquality2.md b/lectures/07_modeltesting/modelquality2.md
deleted file mode 100644
index 0e59d2d0..00000000
--- a/lectures/07_modeltesting/modelquality2.md
+++ /dev/null
@@ -1,1339 +0,0 @@
----
-author: Christian Kaestner and Eunsuk Kang
-title: "MLiP: Model Testing beyond Accuracy"
-semester: Spring 2023
-footer: "Machine Learning in Production/AI Engineering • Christian Kaestner & Eunsuk Kang, Carnegie Mellon University • Spring 2023"
-license: Creative Commons Attribution 4.0
----
-
-
-
-## Machine Learning in Production
-
-
-# Model Testing beyond Accuracy
-
-
-7 individual tokens per student:
+8 individual tokens per student:
- Submit individual assignment 1 day late for 1 token (after running out of tokens 15% penalty per late day)
- Redo individual assignment for 3 token
- Resubmit or submit reading quiz late for 1 token
+- Redo or complete a lab late for 1 token (show in office hours)
- Remaining tokens count toward participation
-- 1 bonus token for attending >66% of recitations
-7 team tokens per team:
+8 team tokens per team:
- Submit milestone 1 day late for 1 token (no late submissions accepted when out of tokens)
- Redo milestone for 3 token
@@ -617,9 +627,9 @@ Opportunities to resubmit work until last day of class
## How to use tokens
* No need to tell us if you plan to submit very late. We will assign 0 and you can resubmit
-* Instructions and form for resubmission on Canvas
+* Instructions and Google form for resubmission on Canvas
* We will automatically use remaining tokens toward participation and quizzes at the end
-* Remaining individual tokens reflected on Canvas, for remaining team tokens ask your TA.
+* Remaining individual tokens reflected on Canvas, for remaining team tokens ask your team mentor.
@@ -629,9 +639,9 @@ Opportunities to resubmit work until last day of class
Instructor-assigned teams
-Teams stay together for project throughout semester, starting Feb 6
+Teams stay together for project throughout semester, starting Feb 5
-Fill out Catme Team survey before Feb 6 (3pt)
+Fill out Catme Team survey before Feb 5 (3pt)
Some advice in lectures; we'll help with debugging team issues
@@ -651,6 +661,8 @@ In a nutshell: do not copy from other students, do not lie, do not share or publ
In group work, be honest about contributions of team members, do not cover for others
+Collaboration okay on labs, but not quizzes, individual assignments, or exams
+
If you feel overwhelmed or stressed, please come and talk to us (see syllabus for other support opportunities)
----
@@ -659,7 +671,7 @@ If you feel overwhelmed or stressed, please come and talk to us (see syllabus fo
-GPT3, ChatGPT, ...? Reading quizzes, homework submissions, ...?
+GPT4, ChatGPT, CoPilot...? Reading quizzes, homework submissions, ...?
----
@@ -669,9 +681,9 @@ This is a course on responsible building of ML products. This includes questions
Feel free to use them and explore whether they are useful. Welcome to share insights/feedback.
-Warning: They are *[bullshit generators](https://aisnakeoil.substack.com/p/chatgpt-is-a-bullshit-generator-but)*! Requires understanding to check answers. We test them ourselves and they often generate bad/wrong answers for reading quizzes.
+Warning: Be aware of hallucinations. Requires understanding to check answers. We test them ourselves and they often generate bad/wrong answers for reading quizzes.
-**You are still responsible for the correctness of what you submit!**
+**You are responsible for the correctness of what you submit!**
diff --git a/lectures/10_qainproduction/bookingcom2.png b/lectures/02_systems/bookingcom2.png
similarity index 100%
rename from lectures/10_qainproduction/bookingcom2.png
rename to lectures/02_systems/bookingcom2.png
diff --git a/lectures/02_systems/systems.md b/lectures/02_systems/systems.md
index 7b4fe8b9..3d359f28 100644
--- a/lectures/02_systems/systems.md
+++ b/lectures/02_systems/systems.md
@@ -1,8 +1,8 @@
---
author: Christian Kaestner
title: "MLiP: From Models to Systems"
-semester: Spring 2023
-footer: "Machine Learning in Production/AI Engineering • Christian Kaestner & Eunsuk Kang, Carnegie Mellon University • Spring 2023"
+semester: Spring 2024
+footer: "Machine Learning in Production/AI Engineering • Claire Le Goues & Christian Kaestner, Carnegie Mellon University • Spring 2024"
license: Creative Commons Attribution 4.0 International (CC BY 4.0)
---
@@ -19,6 +19,16 @@ license: Creative Commons Attribution 4.0 International (CC BY 4.0)
---
+# Administrativa
+
+* Still waiting for registrar to add another section
+* Follow up on syllabus discussion:
+ * When not feeling well -- please stay home and get well, and email us for accommodation
+ * When using generative AI to generate responses (or email/slack messages) -- please ask it to be brief and to the point!
+
+
+----
+
# Learning goals
* Understand how ML components are a (small or large) part of a larger system
@@ -378,6 +388,13 @@ Passi, S., & Sengers, P. (2020). [Making data science systems work](https://jour
+----
+## Model vs System Goal?
+
+
+
+
+
----
## More Accurate Predictions may not be THAT Important
@@ -427,7 +444,7 @@ Wagstaff, Kiri. "Machine learning that matters." In Proceedings of the 29 th Int
* **MLOps** ~ technical infrastructure automating ML pipelines
* sometimes **ML Systems Engineering** -- but often this refers to building distributed and scalable ML and data storage platforms
* "AIOps" ~ using AI to make automated decisions in operations; "DataOps" ~ use of agile methods and automation in business data analytics
-* My preference: **Production Systems with Machine-Learning Components**
+* My preference: **Software Products with Machine-Learning Components**
@@ -466,7 +483,7 @@ Start understanding the **requirements** of the system and its components
* **Organizational objectives:** Innate/overall goals of the organization
-* **System goals:** Goals of the software system/feature to be built
+* **System goals:** Goals of the software system/product/feature to be built
* **User outcomes:** How well the system is serving its users, from the user's perspective
* **Model properties:** Quality of the model used in a system, from the model's perspective
*
@@ -622,8 +639,26 @@ As a group post answer to `#lecture` tagging all group members using template:
> User goals: ...
> Model goals: ...
+---- +## Academic Integrity Issue + +* Please do not cover for people not participating in discussion +* Easy to detect discrepancy between # answers and # people in classroom +* Please let's not have to have unpleasant meetings. +---- +## Breakout: Automating Admission Decisions + +What are different types of goals behind automating admissions decisions to a Master's program? + +As a group post answer to `#lecture` tagging all group members using template: +> Organizational goals: ...
+> Leading indicators: ...
+> System goals: ...
+> User goals: ...
+> Model goals: ...
+ diff --git a/lectures/03_requirements/requirements.md b/lectures/03_requirements/requirements.md index 0fbfc960..d8e4d3b0 100644 --- a/lectures/03_requirements/requirements.md +++ b/lectures/03_requirements/requirements.md @@ -1,8 +1,8 @@ --- -author: Christian Kaestner & Eunsuk Kang +author: Claire Le Goues & Christian Kaestner title: "MLiP: Gathering Requirements" -semester: Spring 2023 -footer: "Machine Learning in Production/AI Engineering • Eunsuk Kang & Christian Kaestner, Carnegie Mellon University • Spring 2023" +semester: Spring 2024 +footer: "Machine Learning in Production/AI Engineering • Claire Le Goues & Christian Kaestner, Carnegie Mellon University • Spring 2024" license: Creative Commons Attribution 4.0 International (CC BY 4.0) --- @@ -34,10 +34,10 @@ failures ---- ## Readings -Required reading: 🗎 Jackson, Michael. "[The world and the machine](https://web.archive.org/web/20170519054102id_/http://mcs.open.ac.uk:80/mj665/icse17kn.pdf)." In Proceedings of the International Conference on Software Engineering. IEEE, 1995. +Required reading: Jackson, Michael. "[The world and the machine](https://web.archive.org/web/20170519054102id_/http://mcs.open.ac.uk:80/mj665/icse17kn.pdf)." In Proceedings of the International Conference on Software Engineering. IEEE, 1995. -Going deeper: 🕮 Van Lamsweerde, Axel. [Requirements engineering: From system goals to UML models to software](https://bookshop.org/books/requirements-engineering-from-system-goals-to-uml-models-to-software-specifications/9780470012703). John Wiley & Sons, 2009. +Going deeper: Van Lamsweerde, Axel. [Requirements engineering: From system goals to UML models to software](https://bookshop.org/books/requirements-engineering-from-system-goals-to-uml-models-to-software-specifications/9780470012703). John Wiley & Sons, 2009. --- # Failures in ML-Based Systems @@ -571,7 +571,7 @@ Slate, 01/2022 -See 🗎 Jackson, Michael. "[The world and the machine](https://web.archive.org/web/20170519054102id_/http://mcs.open.ac.uk:80/mj665/icse17kn.pdf)." In Proceedings of the International Conference on Software Engineering. IEEE, 1995. +See Jackson, Michael. "[The world and the machine](https://web.archive.org/web/20170519054102id_/http://mcs.open.ac.uk:80/mj665/icse17kn.pdf)." In Proceedings of the International Conference on Software Engineering. IEEE, 1995. ---- ## Understanding requirements is hard @@ -589,7 +589,7 @@ See 🗎 Jackson, Michael. "[The world and the machine](https://web.archive.org/ -See also 🗎 Jackson, Michael. "[The world and the machine](https://web.archive.org/web/20170519054102id_/http://mcs.open.ac.uk:80/mj665/icse17kn.pdf)." In Proceedings of the International Conference on Software Engineering. IEEE, 1995. +See also Jackson, Michael. "[The world and the machine](https://web.archive.org/web/20170519054102id_/http://mcs.open.ac.uk:80/mj665/icse17kn.pdf)." In Proceedings of the International Conference on Software Engineering. IEEE, 1995. ---- ## Start with Stakeholders... @@ -779,12 +779,12 @@ Identify stakeholders, interview them, resolve conflicts
-----
-## Correlation vs Causation
-
-
-
-
-
-
-
-
-https://www.tylervigen.com/spurious-correlations
-
----
@@ -647,67 +633,6 @@ https://www.tylervigen.com/spurious-correlations
-----
-## Risks of Metrics as Incentives
-
-Metrics-driven incentives can:
- * Extinguish intrinsic motivation
- * Diminish performance
- * Encourage cheating, shortcuts, and unethical behavior
- * Become addictive
- * Foster short-term thinking
-
-Often, different stakeholders have different incentives
-
-**Make sure data scientists and software engineers share goals and success measures**
-
-----
-## Example: University Rankings
-
-
-
-
-
-
-
-* Originally: Opinion-based polls, but complaints by schools on subjectivity
-* Data-driven model: Rank colleges in terms of "educational excellence"
-* Input: SAT scores, student-teacher ratios, acceptance rates,
-retention rates, campus facilities, alumni donations, etc.,
-
-
-----
-## Example: University Rankings
-
-
-
-
-
-
-
-* Can the ranking-based metric be misused or cause unintended side effects?
-
-
-
-
-
-
-For more, see Weapons of Math Destruction by Cathy O'Neil
-
-
-Notes:
-
-* Example 1
- * Schools optimize metrics for higher ranking (add new classrooms, nicer
- facilities)
- * Tuition increases, but is not part of the model!
- * Higher ranked schools become more expensive
- * Advantage to students from wealthy families
-* Example 2
- * A university founded in early 2010's
- * Math department ranked by US News as top 10 worldwide
- * Top international faculty paid \$\$ as a visitor; asked to add affiliation
- * Increase in publication citations => skyrocket ranking!
@@ -1178,7 +1103,8 @@ Note: The curve is the real trend, red points are training data, green points ar
Example: Kaggle competition on detecting distracted drivers
- 
+
+
Relation of datapoints may not be in the data (e.g., driver)
diff --git a/lectures/06_teamwork/teams.md b/lectures/06_teamwork/teams.md
index afc45bb7..46bfbee3 100644
--- a/lectures/06_teamwork/teams.md
+++ b/lectures/06_teamwork/teams.md
@@ -1,8 +1,8 @@
---
-author: Christian Kaestner and Eunsuk Kang
+author: Christian Kaestner and Claire Le Goues
title: "MLiP: Working with Interdisciplinary (Student) Teams"
-semester: Spring 2023
-footer: "Machine Learning in Production/AI Engineering • Christian Kaestner & Eunsuk Kang, Carnegie Mellon University • Spring 2023"
+semester: Spring 2024
+footer: "Machine Learning in Production/AI Engineering • Christian Kaestner & Claire Le Goues, Carnegie Mellon University • Spring 2024"
license: Creative Commons Attribution 4.0 International (CC BY 4.0)
---
@@ -31,7 +31,7 @@ license: Creative Commons Attribution 4.0 International (CC BY 4.0)
* Say hi, introduce yourself: Name? SE or ML background? Favorite movie? Fun fact?
* Find time for first team meeting in next few days
* Agree on primary communication until team meeting
-* Pick a movie-related team name, post team name and tag all group members on slack in `#social`
+* Pick a movie-related team name (use a language model if needed), post team name and tag all group members on slack in `#social`
---
## Teamwork is crosscutting...
@@ -390,7 +390,7 @@ Based on research and years of own experience
----
-## Breakout: Navigating Team Issues
+## Breakout: Premortem
Pick one or two of the scenarios (or another one team member faced in the past) and openly discuss proactive/reactive solutions
@@ -580,4 +580,4 @@ Adjusting grades based on survey and communication with course staff
* Classic work on team dysfunctions: Lencioni, Patrick. “The five dysfunctions of a team: A Leadership Fable.” Jossey-Bass (2002).
* Oakley, Barbara, Richard M. Felder, Rebecca Brent, and Imad Elhajj. "[Turning student groups into effective teams](https://norcalbiostat.github.io/MATH456/notes/Effective-Teams.pdf)." Journal of student centered learning 2, no. 1 (2004): 9-34.
-> Model goals: ...
+---- +## Academic Integrity Issue + +* Please do not cover for people not participating in discussion +* Easy to detect discrepancy between # answers and # people in classroom +* Please let's not have to have unpleasant meetings. +---- +## Breakout: Automating Admission Decisions + +What are different types of goals behind automating admissions decisions to a Master's program? + +As a group post answer to `#lecture` tagging all group members using template: +> Organizational goals: ...
+> Leading indicators: ...
+> System goals: ...
+> User goals: ...
+> Model goals: ...
+ diff --git a/lectures/03_requirements/requirements.md b/lectures/03_requirements/requirements.md index 0fbfc960..d8e4d3b0 100644 --- a/lectures/03_requirements/requirements.md +++ b/lectures/03_requirements/requirements.md @@ -1,8 +1,8 @@ --- -author: Christian Kaestner & Eunsuk Kang +author: Claire Le Goues & Christian Kaestner title: "MLiP: Gathering Requirements" -semester: Spring 2023 -footer: "Machine Learning in Production/AI Engineering • Eunsuk Kang & Christian Kaestner, Carnegie Mellon University • Spring 2023" +semester: Spring 2024 +footer: "Machine Learning in Production/AI Engineering • Claire Le Goues & Christian Kaestner, Carnegie Mellon University • Spring 2024" license: Creative Commons Attribution 4.0 International (CC BY 4.0) --- @@ -34,10 +34,10 @@ failures ---- ## Readings -Required reading: 🗎 Jackson, Michael. "[The world and the machine](https://web.archive.org/web/20170519054102id_/http://mcs.open.ac.uk:80/mj665/icse17kn.pdf)." In Proceedings of the International Conference on Software Engineering. IEEE, 1995. +Required reading: Jackson, Michael. "[The world and the machine](https://web.archive.org/web/20170519054102id_/http://mcs.open.ac.uk:80/mj665/icse17kn.pdf)." In Proceedings of the International Conference on Software Engineering. IEEE, 1995. -Going deeper: 🕮 Van Lamsweerde, Axel. [Requirements engineering: From system goals to UML models to software](https://bookshop.org/books/requirements-engineering-from-system-goals-to-uml-models-to-software-specifications/9780470012703). John Wiley & Sons, 2009. +Going deeper: Van Lamsweerde, Axel. [Requirements engineering: From system goals to UML models to software](https://bookshop.org/books/requirements-engineering-from-system-goals-to-uml-models-to-software-specifications/9780470012703). John Wiley & Sons, 2009. --- # Failures in ML-Based Systems @@ -571,7 +571,7 @@ Slate, 01/2022 -See 🗎 Jackson, Michael. "[The world and the machine](https://web.archive.org/web/20170519054102id_/http://mcs.open.ac.uk:80/mj665/icse17kn.pdf)." In Proceedings of the International Conference on Software Engineering. IEEE, 1995. +See Jackson, Michael. "[The world and the machine](https://web.archive.org/web/20170519054102id_/http://mcs.open.ac.uk:80/mj665/icse17kn.pdf)." In Proceedings of the International Conference on Software Engineering. IEEE, 1995. ---- ## Understanding requirements is hard @@ -589,7 +589,7 @@ See 🗎 Jackson, Michael. "[The world and the machine](https://web.archive.org/ -See also 🗎 Jackson, Michael. "[The world and the machine](https://web.archive.org/web/20170519054102id_/http://mcs.open.ac.uk:80/mj665/icse17kn.pdf)." In Proceedings of the International Conference on Software Engineering. IEEE, 1995. +See also Jackson, Michael. "[The world and the machine](https://web.archive.org/web/20170519054102id_/http://mcs.open.ac.uk:80/mj665/icse17kn.pdf)." In Proceedings of the International Conference on Software Engineering. IEEE, 1995. ---- ## Start with Stakeholders... @@ -779,12 +779,12 @@ Identify stakeholders, interview them, resolve conflicts
-* 🕮 Van Lamsweerde, Axel. Requirements engineering: From system goals to UML models to software. John Wiley & Sons, 2009.
-* 🗎 Vogelsang, Andreas, and Markus Borg. "Requirements Engineering for Machine Learning: Perspectives from Data Scientists." In Proc. of the 6th International Workshop on Artificial Intelligence for Requirements Engineering (AIRE), 2019.
-* 🗎 Rahimi, Mona, Jin LC Guo, Sahar Kokaly, and Marsha Chechik. "Toward Requirements Specification for Machine-Learned Components." In 2019 IEEE 27th International Requirements Engineering Conference Workshops (REW), pp. 241-244. IEEE, 2019.
-* 🗎 Kulynych, Bogdan, Rebekah Overdorf, Carmela Troncoso, and Seda Gürses. "POTs: protective optimization technologies." In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, pp. 177-188. 2020.
-* 🗎 Wiens, Jenna, Suchi Saria, Mark Sendak, Marzyeh Ghassemi, Vincent X. Liu, Finale Doshi-Velez, Kenneth Jung et al. "Do no harm: a roadmap for responsible machine learning for health care." Nature medicine 25, no. 9 (2019): 1337-1340.
-* 🗎 Bietti, Elettra. "From ethics washing to ethics bashing: a view on tech ethics from within moral philosophy." In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, pp. 210-219. 2020.
-* 🗎 Guizani, Mariam, Lara Letaw, Margaret Burnett, and Anita Sarma. "Gender inclusivity as a quality requirement: Practices and pitfalls." IEEE Software 37, no. 6 (2020).
+* Van Lamsweerde, Axel. Requirements engineering: From system goals to UML models to software. John Wiley & Sons, 2009.
+* Vogelsang, Andreas, and Markus Borg. "Requirements Engineering for Machine Learning: Perspectives from Data Scientists." In Proc. of the 6th International Workshop on Artificial Intelligence for Requirements Engineering (AIRE), 2019.
+* Rahimi, Mona, Jin LC Guo, Sahar Kokaly, and Marsha Chechik. "Toward Requirements Specification for Machine-Learned Components." In 2019 IEEE 27th International Requirements Engineering Conference Workshops (REW), pp. 241-244. IEEE, 2019.
+* Kulynych, Bogdan, Rebekah Overdorf, Carmela Troncoso, and Seda Gürses. "POTs: protective optimization technologies." In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, pp. 177-188. 2020.
+* Wiens, Jenna, Suchi Saria, Mark Sendak, Marzyeh Ghassemi, Vincent X. Liu, Finale Doshi-Velez, Kenneth Jung et al. "Do no harm: a roadmap for responsible machine learning for health care." Nature medicine 25, no. 9 (2019): 1337-1340.
+* Bietti, Elettra. "From ethics washing to ethics bashing: a view on tech ethics from within moral philosophy." In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, pp. 210-219. 2020.
+* Guizani, Mariam, Lara Letaw, Margaret Burnett, and Anita Sarma. "Gender inclusivity as a quality requirement: Practices and pitfalls." IEEE Software 37, no. 6 (2020).
diff --git a/lectures/04_mistakes/mistakes.md b/lectures/04_mistakes/mistakes.md
index 42ebf6b4..3c6be2e5 100644
--- a/lectures/04_mistakes/mistakes.md
+++ b/lectures/04_mistakes/mistakes.md
@@ -1,8 +1,8 @@
---
-author: Eunsuk Kang and Christian Kaestner
+author: Claire Le Goues & Christian Kaestner
title: "MLiP: Planning for Mistakes"
-semester: Spring 2023
-footer: "Machine Learning in Production/AI Engineering • Eunsuk Kang & Christian Kaestner, Carnegie Mellon University • Spring 2023"
+semester: Spring 2024
+footer: "Machine Learning in Production/AI Engineering • Claire Le Goues & Christian Kaestner, Carnegie Mellon University • Spring 2024"
license: Creative Commons Attribution 4.0 International (CC BY 4.0)
---
@@ -12,6 +12,139 @@ license: Creative Commons Attribution 4.0 International (CC BY 4.0)
# Planning for Mistakes
+---
+# From last time...
+----
+## Requirements elicitation techniques (1)
+
+* Background study: understand organization, read documents, try to use old system
+* Interview different stakeholders
+ * Ask open ended questions about problems, needs, possible solutions, preferences, concerns...
+ * Support with visuals, prototypes, ask about tradeoffs
+ * Use checklists to consider qualities (usability, privacy, latency, ...)
+
+
+**What would you ask in lane keeping software? In fall detection software? In college admissions software?**
+
+----
+## ML Prototyping: Wizard of Oz
+
+
+
+Note: In a wizard of oz experiment a human fills in for the ML model that is to be developed. For example a human might write the replies in the chatbot.
+
+----
+## Requirements elicitation techniques (2)
+
+* Surveys, groups sessions, workshops: Engage with multiple stakeholders, explore conflicts
+* Ethnographic studies: embed with users, passively observe or actively become part
+* Requirements taxonomies and checklists: Reusing domain knowledge
+* Personas: Shift perspective to explore needs of stakeholders not interviewed
+
+----
+## Negotiating Requirements
+
+Many requirements are conflicting/contradictory
+
+Different stakeholders want different things, have different priorities, preferences, and concerns
+
+Formal requirements and design methods such as [card sorting](https://en.wikipedia.org/wiki/Card_sorting), [affinity diagramming](https://en.wikipedia.org/wiki/Affinity_diagram), [importance-difficulty matrices](https://spin.atomicobject.com/2018/03/06/design-thinking-difficulty-importance-matrix/)
+
+Generally: sort through requirements, identify alternatives and conflicts, resolve with priorities and decisions -> single option, compromise, or configuration
+
+
+
+----
+## Stakeholder Conflict Examples
+
+*User wishes vs developer preferences:* free updates vs low complexity
+
+*Customer wishes vs affected third parties:* privacy preferences vs disclosure
+
+*Product owner priorities vs regulators:* maximizing revenue vs privacy protections
+
+**Conflicts in lane keeping software? In fall detection software? In college admissions software?**
+
+
+**Who makes the decisions?**
+
+----
+## Requirements documentation
+
+
+
+
+
+----
+## Requirements documentation
+
+Write down requirements
+* what the software *shall* do, what it *shall* not do, what qualities it *shall* have,
+* document decisions and rationale for conflict resolution
+
+Requirements as input to design and quality assurance
+
+Formal requirements documents often seen as bureaucratic, lightweight options in notes, wikis, issues common
+
+Systems with higher risk -> consider more formal documentation
+
+----
+## Requirements evaluation (validation!)
+
+
+
+
+
+----
+## Requirements evaluation
+
+Manual inspection (like code review)
+
+Show requirements to stakeholders, ask for misunderstandings, gaps
+
+Show prototype to stakeholders
+
+Checklists to cover important qualities
+
+
+Critically inspect assumptions for completeness and realism
+
+Look for unrealistic ML-related assumptions (no false positives, unbiased representative data)
+
+
+----
+## How much requirements eng. and when?
+
+
+
+----
+## How much requirements eng. and when?
+
+Requirements important in risky systems
+
+Requirements as basis of a contract (outsourcing, assigning blame)
+
+Rarely ever fully completely upfront and stable, anticipate change
+* Stakeholders see problems in prototypes, change their minds
+* Especially ML requires lots of exploration to establish feasibility
+
+Low-risk problems often use lightweight, agile approaches
+
+(We'll return to this later)
+
+----
+# Summary
+
+Requirements state the needs of the stakeholders and are expressed
+ over the phenomena in the world
+
+Software/ML models have limited influence over the world
+
+Environmental assumptions play just as an important role in
+establishing requirements
+
+Identify stakeholders, interview them, resolve conflicts
+
---
## Exploring Requirements...
@@ -32,7 +165,7 @@ license: Creative Commons Attribution 4.0 International (CC BY 4.0)
-Required reading: 🕮 Hulten, Geoff. "Building Intelligent Systems: A
+Required reading: Hulten, Geoff. "Building Intelligent Systems: A
Guide to Machine Learning Engineering." (2018), Chapters 6–7 (Why
creating IE is hard, balancing IE) and 24 (Dealing with mistakes)
@@ -58,12 +191,6 @@ creating IE is hard, balancing IE) and 24 (Dealing with mistakes)
-----
-## Common excuse: Just software mistake
-
-
-
-
----
## Common excuse: The problem is just data
@@ -286,8 +413,7 @@ Notes: Cancer prediction, sentencing + recidivism, Tesla autopilot, military "ki

-* Fall detection smartwatch
-* Safe browsing
+* Fall detection smartwatch?
----
## Human in the Loop - Examples?
@@ -692,14 +818,15 @@ A number of methods:
-* Fault tree: A top-down diagram that displays the relationships
-between a system failure (i.e., requirement violation) and its potential causes.
- * Identify sequences of events that result in a failure
- * Prioritize the contributors leading to the failure
- * Inform decisions about how to (re-)design the system
+* Fault tree: A diagram that displays relationships
+between a system failure (i.e., requirement violation) and potential causes.
+ * Identify event sequences that can result in failure
+ * Prioritize contributors leading to a failure
+ * Inform design decisions
* Investigate an accident & identify the root cause
* Often used for safety & reliability, but can also be used for
other types of requirements (e.g., poor performance, security attacks...)
+* (Observation: they're weirdly named!)
@@ -728,7 +855,7 @@ other types of requirements (e.g., poor performance, security attacks...)
Event: An occurrence of a fault or an undesirable action
* (Intermediate) Event: Explained in terms of other events
- * Basic Event: No further development or breakdown; leaf
+ * Basic Event: No further development or breakdown; leaf (choice!)
Gate: Logical relationship between an event & its immediate subevents
* AND: All of the sub-events must take place
@@ -846,12 +973,25 @@ Solution combines a vision-based system identifying people in the door with pres
* Remove basic events with mitigations
* Increase the size of cut sets with mitigations
-
+* Recall: Guardrails

----
+## Guardrails - Examples
+
+Recall: Thermal fuse in smart toaster
+
+
+
+
++ maximum toasting time + extra heat sensor
+
+----
+
+
+

@@ -875,15 +1015,17 @@ Possible mitigations?
----
## FTA: Caveats
+
In general, building a **complete** tree is impossible
* There are probably some faulty events that you missed
* "Unknown unknowns"
+ * Events can always be decomposed; detail level is a choice.
Domain knowledge is crucial for improving coverage
* Talk to domain experts; augment your tree as you learn more
FTA is still very valuable for risk reduction!
- * Forces you to think about & explicitly document possible failure scenarios
+ * Forces you to think about, document possible failure scenarios
* A good starting basis for designing mitigations
diff --git a/lectures/04_mistakes/validation.svg b/lectures/04_mistakes/validation.svg
new file mode 100644
index 00000000..ec0ec642
--- /dev/null
+++ b/lectures/04_mistakes/validation.svg
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git a/lectures/15_process/waterfall.svg b/lectures/04_mistakes/waterfall.svg
similarity index 100%
rename from lectures/15_process/waterfall.svg
rename to lectures/04_mistakes/waterfall.svg
diff --git a/lectures/25_summary/wizard.gif b/lectures/04_mistakes/wizard.gif
similarity index 100%
rename from lectures/25_summary/wizard.gif
rename to lectures/04_mistakes/wizard.gif
diff --git a/lectures/05_modelaccuracy/modelquality1.md b/lectures/05_modelaccuracy/modelquality1.md
index 10c9c6f1..ed8aca78 100644
--- a/lectures/05_modelaccuracy/modelquality1.md
+++ b/lectures/05_modelaccuracy/modelquality1.md
@@ -1,8 +1,8 @@
---
-author: Christian Kaestner and Eunsuk Kang
+author: Christian Kaestner and Claire Le Goues
title: "MLiP: Model Correctness and Accuracy"
-semester: Spring 2023
-footer: "Machine Learning in Production/AI Engineering • Christian Kaestner & Eunsuk Kang, Carnegie Mellon University • Spring 2023"
+semester: Spring 2024
+footer: "Machine Learning in Production/AI Engineering • Christian Kaestner & Claire Le Goues, Carnegie Mellon University • Spring 2024"
license: Creative Commons Attribution 4.0 International (CC BY 4.0)
---
@@ -153,8 +153,6 @@ More on system vs model goals and other model qualities later
**Model:** $\overline{X} \rightarrow Y$
-**Training/validation/test data:** sets of $(\overline{X}, Y)$ pairs indicating desired outcomes for select inputs
-
**Performance:** In machine learning, "performance" typically refers to accuracy:
"this model performs better" = it produces more accurate results
@@ -617,18 +615,6 @@ As a group, post your answer to `#lecture` tagging all group members.
(Slicing, Capabilities, Invariants, Simulation, ...)
- - - - ---- -## More model-level QA... - - - - - ----- - -# Learning Goals - -* Curate validation datasets for assessing model quality, covering subpopulations and capabilities as needed -* Explain the oracle problem and how it challenges testing of software and models -* Use invariants to check partial model properties with automated testing -* Select and deploy automated infrastructure to evaluate and monitor model quality - ---- -# Model Quality - - -**First Part:** Measuring Prediction Accuracy -* the data scientist's perspective - -**Second Part:** What is Correctness Anyway? -* the role and lack of specifications, validation vs verification - -**Third Part:** Learning from Software Testing 🠔 -* unit testing, test case curation, invariants, simulation (next lecture) - -**Later:** Testing in Production -* monitoring, A/B testing, canary releases (in 2 weeks) - - - ----- - - - - -[XKCD 1838](https://xkcd.com/1838/), cc-by-nc 2.5 Randall Munroe - - - - - - - - - - - ---- -# Curating Validation Data & Input Slicing - - - - ----- -## Breakout Discussion - -
-
-Write a few tests for the following program:
-
-```scala
-def nextDate(year: Int, month: Int, day: Int) = ...
-```
-
-A test may look like:
-```java
-assert nextDate(2021, 2, 8) == (2021, 2, 9);
-```
-
-**As a group, discuss how you select tests. Discuss how many tests you need to feel confident.**
-
-Post answer to `#lecture` tagging group members in Slack using template:
-> Selection strategy: ...
-> Test quantity: ...
- -
-
-----
-## Defining Software Testing
-
-* Program *p* with specification *s*
-* Test consists of
- - Controlled environment
- - Test call, test inputs
- - Expected behavior/output (oracle)
-
-```java
-assertEquals(4, add(2, 2));
-assertEquals(??, factorPrime(15485863));
-```
-
-Testing is complete but unsound:
-Cannot guarantee the absence of bugs
-
-
-----
-## How to Create Test Cases?
-
-```scala
-def nextDate(year: Int, month: Int, day: Int) = ...
-```
-
-
-
-
-Note: Can focus on specification (and concepts in the domain, such as
-leap days and month lengths) or can focus on implementation
-
-Will not randomly sample from distribution of all days
-
-----
-## Software Test Case Design
-
--> Test quantity: ...
- -
-
-**Opportunistic/exploratory testing:** Add some unit tests, without much planning
-
-**Specification-based testing** ("black box"): Derive test cases from specifications
- - Boundary value analysis
- - Equivalence classes
- - Combinatorial testing
- - Random testing
-
-**Structural testing** ("white box"): Derive test cases to cover implementation paths
- - Line coverage, branch coverage
- - Control-flow, data-flow testing, MCDC, ...
-
-Test execution usually automated, but can be manual too; automated generation from specifications or code possible
-
-
-
-----
-## Example: Boundary Value Testing
-
-Analyze the specification, not the implementation!
-
-**Key Insight:** Errors often occur at the boundaries of a variable value
-
-For each variable select (1) minimum, (2) min+1, (3) medium, (4) max-1, and (5) maximum; possibly also invalid values min-1, max+1
-
-Example: `nextDate(2015, 6, 13) = (2015, 6, 14)`
- - **Boundaries?**
-
-----
-## Example: Equivalence classes
-
-**Idea:** Typically many values behave similarly, but some groups of values are different
-
-Equivalence classes derived from specifications (e.g., cases, input ranges, error conditions, fault models)
-
-Example `nextDate(2015, 6, 13)`
- - leap years, month with 28/30/31 days, days 1-28, 29, 30, 31
-
-Pick 1 value from each group, combine groups from all variables
-
-----
-## Exercise
-
-```scala
-/** Compute the price of a bus ride:
- * - Children under 2 ride for free, children under 18 and
- * senior citizen over 65 pay half, all others pay the
- * full fare of $3.
- * - On weekdays, between 7am and 9am and between 4pm and
- * 7pm a peak surcharge of $1.5 is added.
- * - Short trips under 5min during off-peak time are free.*/
-def busTicketPrice(age: Int,
- datetime: LocalDateTime,
- rideTime: Int)
-```
-
-*suggest test cases based on boundary value analysis and equivalence class testing*
-
-
-----
-## Selecting Validation Data for Model Quality?
-
-
-
-
-
-----
-## Validation Data Representative?
-
-* Validation data should reflect usage data
-* Be aware of data drift (face recognition during pandemic, new patterns in credit card fraud detection)
-* "*Out of distribution*" predictions often low quality (it may even be worth to detect out of distribution data in production, more later)
-
-*(note, similar to requirements validation: did we hear all/representative stakeholders)*
-
-
-
-
-----
-## Not All Inputs are Equal
-
-
-
-
-"Call mom"
-"What's the weather tomorrow?"
-"Add asafetida to my shopping list"
-
-----
-## Not All Inputs are Equal
-
-> There Is a Racial Divide in Speech-Recognition Systems, Researchers Say:
-> Technology from Amazon, Apple, Google, IBM and Microsoft misidentified 35 percent of words from people who were black. White people fared much better. -- [NYTimes March 2020](https://www.nytimes.com/2020/03/23/technology/speech-recognition-bias-apple-amazon-google.html)
-
-----
-
-
-----
-## Not All Inputs are Equal
-
-> some random mistakes vs rare but biased mistakes?
-
-* A system to detect when somebody is at the door that never works for people under 5ft (1.52m)
-* A spam filter that deletes alerts from banks
-
-
-**Consider separate evaluations for important subpopulations; monitor mistakes in production**
-
-
-
-----
-## Identify Important Inputs
-
-Curate Validation Data for Specific Problems and Subpopulations:
-* *Regression testing:* Validation dataset for important inputs ("call mom") -- expect very high accuracy -- closest equivalent to **unit tests**
-* *Uniformness/fairness testing:* Separate validation dataset for different subpopulations (e.g., accents) -- expect comparable accuracy
-* *Setting goals:* Validation datasets for challenging cases or stretch goals -- accept lower accuracy
-
-Derive from requirements, experts, user feedback, expected problems etc. Think *specification-based testing*.
-
-
-----
-## Important Input Groups for Cancer Prognosis?
-
-
-
-
-----
-## Input Partitioning
-
-* Guide testing by identifying groups and analyzing accuracy of subgroups
- * Often for fairness: gender, country, age groups, ...
- * Possibly based on business requirements or cost of mistakes
-* Slice test data by population criteria, also evaluate interactions
-* Identifies problems and plan mitigations, e.g., enhance with more data for subgroup or reduce confidence
-
-
-
-
-Good reading: Barash, Guy, Eitan Farchi, Ilan Jayaraman, Orna Raz, Rachel Tzoref-Brill, and Marcel Zalmanovici. "Bridging the gap between ML solutions and their business requirements using feature interactions." In Proc. Symposium on the Foundations of Software Engineering, pp. 1048-1058. 2019.
-
-----
-## Input Partitioning Example
-
-
-
-
-
-
-Input divided by movie age. Notice low accuracy, but also low support (i.e., little validation data), for old movies.
-
-
-
-Input divided by genre, rating, and length. Accuracy differs, but also amount of test data used ("support") differs, highlighting low confidence areas.
-
-
-
-
-
-
-
-Source: Barash, Guy, et al. "Bridging the gap between ML solutions and their business requirements using feature interactions." In Proc. FSE, 2019.
-
-----
-## Input Partitioning Discussion
-
-**How to slice evaluation data for cancer prognosis?**
-
-
-
-
-----
-## Example: Model Impr. at Apple (Overton)
-
-
-
-
-
-
-
-Ré, Christopher, Feng Niu, Pallavi Gudipati, and Charles Srisuwananukorn. "[Overton: A Data System for Monitoring and Improving Machine-Learned Products](https://arxiv.org/abs/1909.05372)." arXiv preprint arXiv:1909.05372 (2019).
-
-
-----
-## Example: Model Improvement at Apple (Overton)
-
-* Focus engineers on creating training and validation data, not on model search (AutoML)
-* Flexible infrastructure to slice telemetry data to identify underperforming subpopulations -> focus on creating better training data (better, more labels, in semi-supervised learning setting)
-
-
-
-
-Ré, Christopher, Feng Niu, Pallavi Gudipati, and Charles Srisuwananukorn. "[Overton: A Data System for Monitoring and Improving Machine-Learned Products](https://arxiv.org/abs/1909.05372)." arXiv preprint arXiv:1909.05372 (2019).
-
-
-
-
-
-
-
----
-# Testing Model Capabilities
-
-
-
-
-
-
-
-
-Further reading: Christian Kaestner. [Rediscovering Unit Testing: Testing Capabilities of ML Models](https://towardsdatascience.com/rediscovering-unit-testing-testing-capabilities-of-ml-models-b008c778ca81). Toward Data Science, 2021.
-
-
-
-----
-## Testing Capabilities
-
-
-
-Are there "concepts" or "capabilities" the model should learn?
-
-Example capabilities of sentiment analysis:
-* Handle *negation*
-* Robustness to *typos*
-* Ignore synonyms and abbreviations
-* Person and location names are irrelevant
-* Ignore gender
-* ...
-
-For each capability create specific test set (multiple examples)
-
-
-
-
-
-Ribeiro, Marco Tulio, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. "[Beyond Accuracy: Behavioral Testing of NLP Models with CheckList](https://homes.cs.washington.edu/~wtshuang/static/papers/2020-acl-checklist.pdf)." In Proceedings ACL, p. 4902–4912. (2020).
-
-
-----
-## Testing Capabilities
-
-
-
-
-
-
-From: Ribeiro, Marco Tulio, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. "[Beyond Accuracy: Behavioral Testing of NLP Models with CheckList](https://homes.cs.washington.edu/~wtshuang/static/papers/2020-acl-checklist.pdf)." In Proceedings ACL, p. 4902–4912. (2020).
-
-
-----
-## Testing Capabilities
-
-
-
-
-
-
-From: Ribeiro, Marco Tulio, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. "[Beyond Accuracy: Behavioral Testing of NLP Models with CheckList](https://homes.cs.washington.edu/~wtshuang/static/papers/2020-acl-checklist.pdf)." In Proceedings ACL, p. 4902–4912. (2020).
-
-----
-## Examples of Capabilities
-
-**What could be capabilities of the cancer classifier?**
-
-
-
-----
-## Capabilities vs Specifications vs Slicing
-
-
-
-----
-## Capabilities vs Specifications vs Slicing
-
-Capabilities are partial specifications of expected behavior (not expected to always hold)
-
-Some capabilities correspond to slices of existing test data, for others we may need to create new data
-
-----
-## Recall: Is it fair to expect generalization beyond training distribution?
-
-
-
-
-
-*Shall a cancer detector generalize to other hospitals? Shall image captioning generalize to describing pictures of star formations?*
-
-Note: We wouldn't test a first year elementary school student on high-school math. This would be "out of the training distribution"
-
-----
-## Recall: Shortcut Learning
-
-
-
-
-
-Figure from: Geirhos, Robert, et al. "[Shortcut learning in deep neural networks](https://arxiv.org/abs/2004.07780)." Nature Machine Intelligence 2, no. 11 (2020): 665-673.
-
-----
-## More Shortcut Learning :)
-
-
-
-
-Figure from Beery, Sara, Grant Van Horn, and Pietro Perona. “Recognition in terra incognita.” In Proceedings of the European Conference on Computer Vision (ECCV), pp. 456–473. 2018.
-
-----
-## Generalization beyond Training Distribution?
-
-
-
-* Typically training and validation data from same distribution (i.i.d. assumption!)
-* Many models can achieve similar accuracy
-* Models that learn "right" abstractions possibly indistinguishable from models that use shortcuts
- - see tank detection example
- - Can we guide the model towards "right" abstractions?
-* Some models generalize better to other distributions not used in training
- - e.g., cancer images from other hospitals, from other populations
- - Drift and attacks, ...
-
-
-
-
-
-See discussion in D'Amour, Alexander, et al. "[Underspecification presents challenges for credibility in modern machine learning](https://arxiv.org/abs/2011.03395)." arXiv preprint arXiv:2011.03395 (2020).
-
-----
-## Hypothesis: Testing Capabilities may help with Generalization
-
-* Capabilities are "partial specifications", given beyond training data
-* Encode domain knowledge of the problem
- * Capabilities are inherently domain specific
- * Curate capability-specific test data for a problem
-* Testing for capabilities helps to distinguish models that use intended abstractions
-* May help find models that generalize better
-
-
-
-
-
-See discussion in D'Amour, Alexander, Katherine Heller, Dan Moldovan, Ben Adlam, Babak Alipanahi, Alex Beutel, Christina Chen et al. "[Underspecification presents challenges for credibility in modern machine learning](https://arxiv.org/abs/2011.03395)." arXiv preprint arXiv:2011.03395 (2020).
-
-----
-
-## Strategies for identifying capabilities
-
-* Analyze common mistakes (e.g., classify past mistakes in cancer prognosis)
-* Use existing knowledge about the problem (e.g., linguistics theories)
-* Observe humans (e.g., how do radiologists look for cancer)
-* Derive from requirements (e.g., fairness)
-* Causal discovery from observational data?
-
-
-
-Further reading: Christian Kaestner. [Rediscovering Unit Testing: Testing Capabilities of ML Models](https://towardsdatascience.com/rediscovering-unit-testing-testing-capabilities-of-ml-models-b008c778ca81). Toward Data Science, 2021.
-
-
-
-----
-## Examples of Capabilities
-
-**What could be capabilities of image captioning system?**
-
-
-
-
-
-----
-## Generating Test Data for Capabilities
-
-**Idea 1: Domain-specific generators**
-
-Testing *negation* in sentiment analysis with template: -`I {NEGATION} {POS_VERB} the {THING}.` - -Testing texture vs shape priority with artificial generated images: - - - - -Figure from Geirhos, Robert, Patricia Rubisch, Claudio Michaelis, Matthias Bethge, Felix A. Wichmann, and Wieland Brendel. “ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness.” In Proc. International Conference on Learning Representations (ICLR), (2019). - ----- -## Generating Test Data for Capabilities - -**Idea 2: Mutating existing inputs** - -Testing *synonyms* in sentiment analysis by replacing words with synonyms, keeping label - -Testing *robust against noise and distraction* add `and false is not true` or random URLs to text - - - - - - -Figure from: Ribeiro, Marco Tulio, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. "[Beyond Accuracy: Behavioral Testing of NLP Models with CheckList](https://homes.cs.washington.edu/~wtshuang/static/papers/2020-acl-checklist.pdf)." In Proceedings ACL, p. 4902–4912. (2020). - - ----- -## Generating Test Data for Capabilities - -**Idea 3: Crowd-sourcing test creation** - -Testing *sarcasm* in sentiment analysis: Ask humans to minimally change text to flip sentiment with sarcasm - -Testing *background* in object detection: Ask humans to take pictures of specific objects with unusual backgrounds - - - - - -Figure from: Kaushik, Divyansh, Eduard Hovy, and Zachary C. Lipton. “Learning the difference that makes a difference with counterfactually-augmented data.” In Proc. International Conference on Learning Representations (ICLR), (2020). - ----- -## Generating Test Data for Capabilities - -**Idea 4: Slicing test data** - -Testing *negation* in sentiment analysis by finding sentences containing 'not' - - - - - - - -Ré, Christopher, Feng Niu, Pallavi Gudipati, and Charles Srisuwananukorn. "[Overton: A Data System for Monitoring and Improving Machine-Learned Products](https://arxiv.org/abs/1909.05372)." arXiv preprint arXiv:1909.05372 (2019). - - - ----- -## Examples of Capabilities - -**How to generate test data for capabilities of the cancer classifier?** - - - - ----- -## Testing vs Training Capabilities - -* Dual insight for testing and training -* Strategies for curating test data can also help select training data -* Generate capability-specific training data to guide training (data augmentation) - - - -Further reading on using domain knowledge during training: Von Rueden, Laura, Sebastian Mayer, Jochen Garcke, Christian Bauckhage, and Jannis Schuecker. "Informed machine learning–towards a taxonomy of explicit integration of knowledge into machine learning." Learning 18 (2019): 19-20. - - - ----- -## Preliminary Summary: Specification-Based Testing Techniques as Inspiration - -* Boundary value analysis -* Partition testing & equivalence classes -* Combinatorial testing -* Decision tables - -Use to identify datasets for **subpopulations** and **capabilities**, not individual tests. - ----- -## On Terminology - -* Test data curation is emerging as a very recent concept for testing ML components -* No consistent terminology - - "Testing capabilities" in checklist paper - - "Stress testing" in some others (but stress testing has a very different meaning in software testing: robustness to overload) -* Software engineering concepts translate, but names not adopted in ML community - - specification-based testing, black-box testing - - equivalence class testing, boundary-value analysis - - - - - - - - - - - - - - - - - ---- -# Automated (Random) Testing and Invariants - -(if it wasn't for that darn oracle problem) - - - - - ----- -## Random Test Input Generation is Easy - - -```java -@Test -void testNextDate() { - nextDate(488867101, 1448338253, -997372169) - nextDate(2105943235, 1952752454, 302127018) - nextDate(1710531330, -127789508, 1325394033) - nextDate(-1512900479, -439066240, 889256112) - nextDate(1853057333, 1794684858, 1709074700) - nextDate(-1421091610, 151976321, 1490975862) - nextDate(-2002947810, 680830113, -1482415172) - nextDate(-1907427993, 1003016151, -2120265967) -} -``` - -**But is it useful?** - ----- -## Cancer in Random Image? - - - ----- -## Randomly Generating "Realistic" Inputs is Possible - - -```java -@Test -void testNextDate() { - nextDate(2010, 8, 20) - nextDate(2024, 7, 15) - nextDate(2011, 10, 27) - nextDate(2024, 5, 4) - nextDate(2013, 8, 27) - nextDate(2010, 2, 30) -} -``` - -**But how do we know whether the computation is correct?** - - - ----- -## Automated Model Validation Data Generation? - -```java -@Test -void testCancerPrediction() { - cancerModel.predict(generateRandomImage()) - cancerModel.predict(generateRandomImage()) - cancerModel.predict(generateRandomImage()) -} -``` - -* **Realistic inputs?** -* **But how do we get labels?** - - ----- -## The Oracle Problem - -*How do we know the expected output of a test?* - -```java -assertEquals(??, factorPrime(15485863)); -``` - - - - ----- -## Test Case Generation & The Oracle Problem - -
-
-* Manually construct input-output pairs (does not scale, cannot automate)
-* Comparison against gold standard (e.g., alternative implementation, executable specification)
-* Checking of global properties only -- crashes, buffer overflows, code injections
-* Manually written assertions -- partial specifications checked at runtime
-
-
-
-
-
-
-----
-## Manually constructing outputs
-
-
-```java
-@Test
-void testNextDate() {
- assert nextDate(2010, 8, 20) == (2010, 8, 21);
- assert nextDate(2024, 7, 15) == (2024, 7, 16);
- assert nextDate(2010, 2, 30) throws InvalidInputException;
-}
-```
-
-```java
-@Test
-void testCancerPrediction() {
- assert cancerModel.predict(loadImage("random1.jpg")) == true;
- assert cancerModel.predict(loadImage("random2.jpg")) == true;
- assert cancerModel.predict(loadImage("random3.jpg")) == false;
-}
-```
-
-*(tedious, labor intensive; possibly crowd sourced)*
-
-----
-## Compare against reference implementation
-
-**assuming we have a correct implementation**
-
-```java
-@Test
-void testNextDate() {
- assert nextDate(2010, 8, 20) == referenceLib.nextDate(2010, 8, 20);
- assert nextDate(2024, 7, 15) == referenceLib.nextDate(2024, 7, 15);
- assert nextDate(2010, 2, 30) == referenceLib.nextDate(2010, 2, 30)
-}
-```
-
-```java
-@Test
-void testCancerPrediction() {
- assert cancerModel.predict(loadImage("random1.jpg")) == ???;
-}
-```
-
-*(usually no reference implementation for ML problems)*
-
-
-----
-## Checking global specifications
-
-**Ensure, no computation crashes**
-
-```java
-@Test
-void testNextDate() {
- nextDate(2010, 8, 20)
- nextDate(2024, 7, 15)
- nextDate(2010, 2, 30)
-}
-```
-
-
-```java
-@Test
-void testCancerPrediction() {
- cancerModel.predict(generateRandomImage())
- cancerModel.predict(generateRandomImage())
- cancerModel.predict(generateRandomImage())
-}
-```
-
-*(we usually do fear crashing bugs in ML models)*
-
-----
-## Invariants as partial specification
-
-
-```java
-class Stack {
- int size = 0;
- int MAX_SIZE = 100;
- String[] data = new String[MAX_SIZE];
- // class invariant checked before and after every method
- private void check() {
- assert(size>=0 && size<=MAX_SIZE);
- }
- public void push(String v) {
- check();
- if (size
-
-```java
-@Test
-void testCancerPrediction() {
- cancerModel.predict(generateRandomImage())
-}
-```
-
-
-
-* Manually construct input-output pairs (does not scale, cannot automate)
- - **too expensive at scale**
-* Comparison against gold standard (e.g., alternative implementation, executable specification)
- - **no specification, usually no other "correct" model**
- - comparing different techniques useful? (see ensemble learning)
- - semi-supervised learning as approximation?
-* Checking of global properties only -- crashes, buffer overflows, code injections - **??**
-* Manually written assertions -- partial specifications checked at runtime - **??**
-
-
-
-
-
-----
-## Invariants in Machine Learned Models (Metamorphic Testing)
-
-Exploit relationships between inputs
-
-* If two inputs differ only in **X** -> output should be the same
-* If inputs differ in **Y** output should be flipped
-* If inputs differ only in feature **F**, prediction for input with higher F should be higher
-* ...
-
-----
-## Invariants in Machine Learned Models?
-
-
-
-----
-## Some Capabilities are Invariants
-
-**Some capability tests can be expressed as invariants and automatically encoded as transformations to existing test data**
-
-
-* Negation should flip sentiment analysis result
-* Typos should not affect sentiment analysis result
-* Changes to locations or names should not affect sentiment analysis results
-
-
-
-
-
-
-From: Ribeiro, Marco Tulio, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. "[Beyond Accuracy: Behavioral Testing of NLP Models with CheckList](https://homes.cs.washington.edu/~wtshuang/static/papers/2020-acl-checklist.pdf)." In Proceedings ACL, p. 4902–4912. (2020).
-
-
-
-----
-## Examples of Invariants
-
-
-
-
-* Credit rating should not depend on gender:
- - $\forall x. f(x[\text{gender} \leftarrow \text{male}]) = f(x[\text{gender} \leftarrow \text{female}])$
-* Synonyms should not change the sentiment of text:
- - $\forall x. f(x) = f(\texttt{replace}(x, \text{"is not", "isn't"}))$
-* Negation should swap meaning:
- - $\forall x \in \text{"X is Y"}. f(x) = 1-f(\texttt{replace}(x, \text{" is ", " is not "}))$
-* Robustness around training data:
- - $\forall x \in \text{training data}. \forall y \in \text{mutate}(x, \delta). f(x) = f(y)$
-* Low credit scores should never get a loan (sufficient conditions for classification, "anchors"):
- - $\forall x. x.\text{score} < 649 \Rightarrow \neg f(x)$
-
-Identifying invariants requires domain knowledge of the problem!
-
-
-
-----
-## Metamorphic Testing
-
-Formal description of relationships among inputs and outputs (*Metamorphic Relations*)
-
-In general, for a model $f$ and inputs $x$ define two functions to transform inputs and outputs $g\_I$ and $g\_O$ such that:
-
-$\forall x. f(g\_I(x)) = g\_O(f(x))$
-
-
-
-e.g. $g\_I(x)= \texttt{replace}(x, \text{" is ", " is not "})$ and $g\_O(x)=\neg x$
-
-
-
-----
-## On Testing with Invariants/Assertions
-
-* Defining good metamorphic relations requires knowledge of the problem domain
-* Good metamorphic relations focus on parts of the system
-* Invariants usually cover only one aspect of correctness -- maybe capabilities
-* Invariants and near-invariants can be mined automatically from sample data (see *specification mining* and *anchors*)
-
-
-
-Further reading:
-* Segura, Sergio, Gordon Fraser, Ana B. Sanchez, and Antonio Ruiz-Cortés. "[A survey on metamorphic testing](https://core.ac.uk/download/pdf/74235918.pdf)." IEEE Transactions on software engineering 42, no. 9 (2016): 805-824.
-* Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. "[Anchors: High-precision model-agnostic explanations](https://sameersingh.org/files/papers/anchors-aaai18.pdf)." In Thirty-Second AAAI Conference on Artificial Intelligence. 2018.
-
-
-----
-## Invariant Checking aligns with Requirements Validation
-
-
-
-
-
-
-----
-## Approaches for Checking in Variants
-
-* Generating test data (random, distributions) usually easy
-* Transformations of existing test data
-* Adversarial learning: For many techniques gradient-based techniques to search for invariant violations -- that's roughly analogous to symbolic execution in SE
-* Early work on formally verifying invariants for certain models (e.g., small deep neural networks)
-
-
-
-
-Further readings:
-Singh, Gagandeep, Timon Gehr, Markus Püschel, and Martin Vechev. "[An abstract domain for certifying neural networks](https://dl.acm.org/doi/pdf/10.1145/3290354)." Proceedings of the ACM on Programming Languages 3, no. POPL (2019): 1-30.
-
-
-----
-## Using Invariant Violations
-
-* Are invariants strict?
- * Single violation in random inputs usually not meaningful
- * In capability testing, average accuracy in realistic data needed
- * Maybe strict requirements for fairness or robustness?
-* Do invariant violations matter if the input data is not representative?
-
-
-
-
----
-# Simulation-Based Testing
-
-
-
-
-
-----
-## One More Thing: Simulation-Based Testing
-
-In some cases it is easy to go from outputs to inputs:
-
-```java
-assertEquals(??, factorPrime(15485862));
-```
-
-```java
-randomNumbers = [2, 3, 7, 7, 52673]
-assertEquals(randomNumbers,
- factorPrime(multiply(randomNumbers)));
-```
-
-**Similar idea in machine-learning problems?**
-
-
-
-----
-## One More Thing: Simulation-Based Testing
-
-
-
-
-
-* Derive input-output pairs from simulation, esp. in vision systems
-* Example: Vision for self-driving cars:
- * Render scene -> add noise -> recognize -> compare recognized result with simulator state
-* Quality depends on quality of simulator:
- * examples: render picture/video, synthesize speech, ...
- * Less suitable where input-output relationship unknown, e.g., cancer prognosis, housing price prediction
-
-
-
-
-
-
-
-
-
-
-Further readings: Zhang, Mengshi, Yuqun Zhang, Lingming Zhang, Cong Liu, and Sarfraz Khurshid. "DeepRoad: GAN-based metamorphic testing and input validation framework for autonomous driving systems." In Proc. ASE. 2018.
-
-
-----
-## Preliminary Summary: Invariants and Generation
-
-* Generating sample inputs is easy, but knowing corresponding outputs is not (oracle problem)
-* Crashing bugs are not a concern
-* Invariants + generated data can check capabilities or properties (metamorphic testing)
- - Inputs can be generated realistically or to find violations (adversarial learning)
-* If inputs can be computed from outputs, tests can be automated (simulation-based testing)
-
-----
-## On Terminology
-
-**Metamorphic testing** is an academic software engineering term that's not common in ML literature, it generalizes many concepts regularly reinvented
-
-Much of the security, safety and robustness literature in ML focuses on invariants
-
-
-
-
-
-
-
-
-
-
----
-# Other Testing Concepts
-
-
-----
-
-## Test Coverage
-
-
-
-
-----
-## Example: Structural testing
-
-```java
-int divide(int A, int B) {
- if (A==0)
- return 0;
- if (B==0)
- return -1;
- return A / B;
-}
-```
-
-*minimum set of test cases to cover all lines? all decisions? all path?*
-
-
-
-
-
-----
-## Defining Structural Testing ("white box")
-
-* Test case creation is driven by the implementation, not the specification
-* Typically aiming to increase coverage of lines, decisions, etc
-* Automated test generation often driven by maximizing coverage (for finding crashing bugs)
-
-
-----
-## Whitebox Analysis in ML
-
-* Several coverage metrics have been proposed
- - All path of a decision tree?
- - All neurons activated at least once in a DNN? (several papers "neuron coverage")
- - Linear regression models??
-* Often create artificial inputs, not realistic for distribution
-* Unclear whether those are useful
-* Adversarial learning techniques usually more efficient at finding invariant violations
-
-----
-## Regression Testing
-
-* Whenever bug detected and fixed, add a test case
-* Make sure the bug is not reintroduced later
-* Execute test suite after changes to detect regressions
- - Ideally automatically with continuous integration tools
-*
-* Maps well to curating test sets for important populations in ML
-
-----
-## Mutation Analysis
-
-* Start with program and passing test suite
-* Automatically insert small modifications ("mutants") in the source code
- - `a+b` -> `a-b`
- - `a
-
-* Testing script
- * Existing model: Automatically evaluate model on labeled training set; multiple separate evaluation sets possible, e.g., for slicing, regressions
- * Training model: Automatically train and evaluate model, possibly using cross-validation; many ML libraries provide built-in support
- * Report accuracy, recall, etc. in console output or log files
- * May deploy learning and evaluation tasks to cloud services
- * Optionally: Fail test below bound (e.g., accuracy <.9; accuracy < last accuracy)
-* Version control test data, model and test scripts, ideally also learning data and learning code (feature extraction, modeling, ...)
-* Continuous integration tool can trigger test script and parse output, plot for comparisons (e.g., similar to performance tests)
-* Optionally: Continuous deployment to production server
-
-
-
-----
-## Dashboards for Model Evaluation Results
-
-[](https://eng.uber.com/michelangelo/)
-
-
-
-Jeremy Hermann and Mike Del Balso. [Meet Michelangelo: Uber’s Machine Learning Platform](https://eng.uber.com/michelangelo/). Blog, 2017
-
-----
-
-## Specialized CI Systems
-
-
-
-
-
-Renggli et. al, [Continuous Integration of Machine Learning Models with ease.ml/ci: Towards a Rigorous Yet Practical Treatment](http://www.sysml.cc/doc/2019/162.pdf), SysML 2019
-
-----
-## Dashboards for Comparing Models
-
-
-
-
-
-Matei Zaharia. [Introducing MLflow: an Open Source Machine Learning Platform](https://databricks.com/blog/2018/06/05/introducing-mlflow-an-open-source-machine-learning-platform.html), 2018
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
----
-# Summary
-
-
-
-Curating test data
- - Analyzing specifications, capabilities
- - Not all inputs are equal: Identify important inputs (inspiration from specification-based testing)
- - Slice data for evaluation
- - Identifying capabilities and generating relevant tests
-
-Automated random testing
- - Feasible with invariants (e.g. metamorphic relations)
- - Sometimes possible with simulation
-
-Automate the test execution with continuous integration
-
-
-
----
-# Further readings
-
-
-
-
-* Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. "[Semantically equivalent adversarial rules for debugging NLP models](https://www.aclweb.org/anthology/P18-1079.pdf)." In Proc. ACL, pp. 856-865. 2018.
-* Barash, Guy, Eitan Farchi, Ilan Jayaraman, Orna Raz, Rachel Tzoref-Brill, and Marcel Zalmanovici. "[Bridging the gap between ML solutions and their business requirements using feature interactions](https://dl.acm.org/doi/abs/10.1145/3338906.3340442)." In Proc. FSE, pp. 1048-1058. 2019.
-* Ashmore, Rob, Radu Calinescu, and Colin Paterson. "[Assuring the machine learning lifecycle: Desiderata, methods, and challenges](https://arxiv.org/abs/1905.04223)." arXiv preprint arXiv:1905.04223. 2019.
-* Christian Kaestner. [Rediscovering Unit Testing: Testing Capabilities of ML Models](https://towardsdatascience.com/rediscovering-unit-testing-testing-capabilities-of-ml-models-b008c778ca81). Toward Data Science, 2021.
-* D'Amour, Alexander, Katherine Heller, Dan Moldovan, Ben Adlam, Babak Alipanahi, Alex Beutel, Christina Chen et al. "[Underspecification presents challenges for credibility in modern machine learning](https://arxiv.org/abs/2011.03395)." *arXiv preprint arXiv:2011.03395* (2020).
-* Segura, Sergio, Gordon Fraser, Ana B. Sanchez, and Antonio Ruiz-Cortés. "[A survey on metamorphic testing](https://core.ac.uk/download/pdf/74235918.pdf)." IEEE Transactions on software engineering 42, no. 9 (2016): 805-824.
-
-
-
diff --git a/lectures/07_modeltesting/oracle.svg b/lectures/07_modeltesting/oracle.svg
deleted file mode 100644
index 5d0d3832..00000000
--- a/lectures/07_modeltesting/oracle.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/07_modeltesting/overton.png b/lectures/07_modeltesting/overton.png
deleted file mode 100644
index a3ccce38..00000000
Binary files a/lectures/07_modeltesting/overton.png and /dev/null differ
diff --git a/lectures/07_modeltesting/radiology-distribution.png b/lectures/07_modeltesting/radiology-distribution.png
deleted file mode 100644
index ad7f5375..00000000
Binary files a/lectures/07_modeltesting/radiology-distribution.png and /dev/null differ
diff --git a/lectures/07_modeltesting/radiology.jpg b/lectures/07_modeltesting/radiology.jpg
deleted file mode 100644
index 5bc31795..00000000
Binary files a/lectures/07_modeltesting/radiology.jpg and /dev/null differ
diff --git a/lectures/07_modeltesting/random.jpg b/lectures/07_modeltesting/random.jpg
deleted file mode 100644
index 5ec8eded..00000000
Binary files a/lectures/07_modeltesting/random.jpg and /dev/null differ
diff --git a/lectures/07_modeltesting/sarcasm.png b/lectures/07_modeltesting/sarcasm.png
deleted file mode 100644
index eb58e9c8..00000000
Binary files a/lectures/07_modeltesting/sarcasm.png and /dev/null differ
diff --git a/lectures/07_modeltesting/shortcutlearning-cows.png b/lectures/07_modeltesting/shortcutlearning-cows.png
deleted file mode 100644
index 4ce89b21..00000000
Binary files a/lectures/07_modeltesting/shortcutlearning-cows.png and /dev/null differ
diff --git a/lectures/07_modeltesting/shortcutlearning.png b/lectures/07_modeltesting/shortcutlearning.png
deleted file mode 100644
index c522e6b4..00000000
Binary files a/lectures/07_modeltesting/shortcutlearning.png and /dev/null differ
diff --git a/lectures/07_modeltesting/simulationbased-testing.svg b/lectures/07_modeltesting/simulationbased-testing.svg
deleted file mode 100644
index 5db26eb8..00000000
--- a/lectures/07_modeltesting/simulationbased-testing.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/07_modeltesting/simulationdriving.jpg b/lectures/07_modeltesting/simulationdriving.jpg
deleted file mode 100644
index 6716946f..00000000
Binary files a/lectures/07_modeltesting/simulationdriving.jpg and /dev/null differ
diff --git a/lectures/07_modeltesting/slices.jpg b/lectures/07_modeltesting/slices.jpg
deleted file mode 100644
index e4ac6a08..00000000
Binary files a/lectures/07_modeltesting/slices.jpg and /dev/null differ
diff --git a/lectures/07_modeltesting/texturevsshape.png b/lectures/07_modeltesting/texturevsshape.png
deleted file mode 100644
index d0da33f7..00000000
Binary files a/lectures/07_modeltesting/texturevsshape.png and /dev/null differ
diff --git a/lectures/07_modeltesting/uber-dashboard.png b/lectures/07_modeltesting/uber-dashboard.png
deleted file mode 100644
index 381ea6c5..00000000
Binary files a/lectures/07_modeltesting/uber-dashboard.png and /dev/null differ
diff --git a/lectures/07_modeltesting/white-noise.jpg b/lectures/07_modeltesting/white-noise.jpg
deleted file mode 100644
index 97d15bd7..00000000
Binary files a/lectures/07_modeltesting/white-noise.jpg and /dev/null differ
diff --git a/lectures/07_modeltesting/xkcd1838.png b/lectures/07_modeltesting/xkcd1838.png
deleted file mode 100644
index 38c4c1e5..00000000
Binary files a/lectures/07_modeltesting/xkcd1838.png and /dev/null differ
diff --git a/lectures/08_architecture/adversarial.png b/lectures/08_architecture/adversarial.png
deleted file mode 100644
index 497992d8..00000000
Binary files a/lectures/08_architecture/adversarial.png and /dev/null differ
diff --git a/lectures/08_architecture/architectures.png b/lectures/08_architecture/architectures.png
deleted file mode 100644
index 85d8b873..00000000
Binary files a/lectures/08_architecture/architectures.png and /dev/null differ
diff --git a/lectures/08_architecture/credit-card.jpg b/lectures/08_architecture/credit-card.jpg
deleted file mode 100644
index d843a542..00000000
Binary files a/lectures/08_architecture/credit-card.jpg and /dev/null differ
diff --git a/lectures/08_architecture/decisiontreeexample-full.png b/lectures/08_architecture/decisiontreeexample-full.png
deleted file mode 100644
index 7cc0bc0e..00000000
Binary files a/lectures/08_architecture/decisiontreeexample-full.png and /dev/null differ
diff --git a/lectures/08_architecture/decisiontreeexample.png b/lectures/08_architecture/decisiontreeexample.png
deleted file mode 100644
index 58c7973e..00000000
Binary files a/lectures/08_architecture/decisiontreeexample.png and /dev/null differ
diff --git a/lectures/08_architecture/design-space.svg b/lectures/08_architecture/design-space.svg
deleted file mode 100644
index f945ca6e..00000000
--- a/lectures/08_architecture/design-space.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/08_architecture/design.png b/lectures/08_architecture/design.png
deleted file mode 100644
index 7b73afb6..00000000
Binary files a/lectures/08_architecture/design.png and /dev/null differ
diff --git a/lectures/08_architecture/fashion_mnist.png b/lectures/08_architecture/fashion_mnist.png
deleted file mode 100644
index 213b1e1f..00000000
Binary files a/lectures/08_architecture/fashion_mnist.png and /dev/null differ
diff --git a/lectures/08_architecture/gizzard.png b/lectures/08_architecture/gizzard.png
deleted file mode 100644
index af77c1cb..00000000
Binary files a/lectures/08_architecture/gizzard.png and /dev/null differ
diff --git a/lectures/08_architecture/information-hiding.png b/lectures/08_architecture/information-hiding.png
deleted file mode 100644
index afbf8eac..00000000
Binary files a/lectures/08_architecture/information-hiding.png and /dev/null differ
diff --git a/lectures/08_architecture/lane-detect.jpg b/lectures/08_architecture/lane-detect.jpg
deleted file mode 100644
index 32df2433..00000000
Binary files a/lectures/08_architecture/lane-detect.jpg and /dev/null differ
diff --git a/lectures/08_architecture/lane.jpg b/lectures/08_architecture/lane.jpg
deleted file mode 100644
index b4b189fa..00000000
Binary files a/lectures/08_architecture/lane.jpg and /dev/null differ
diff --git a/lectures/08_architecture/linear-regression.png b/lectures/08_architecture/linear-regression.png
deleted file mode 100644
index 5f9defe8..00000000
Binary files a/lectures/08_architecture/linear-regression.png and /dev/null differ
diff --git a/lectures/08_architecture/ml-methods-poll.jpg b/lectures/08_architecture/ml-methods-poll.jpg
deleted file mode 100644
index 94414ff8..00000000
Binary files a/lectures/08_architecture/ml-methods-poll.jpg and /dev/null differ
diff --git a/lectures/08_architecture/mlperceptron.svg b/lectures/08_architecture/mlperceptron.svg
deleted file mode 100644
index 69feea0c..00000000
--- a/lectures/08_architecture/mlperceptron.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/08_architecture/netflix-leaderboard.png b/lectures/08_architecture/netflix-leaderboard.png
deleted file mode 100644
index fd264669..00000000
Binary files a/lectures/08_architecture/netflix-leaderboard.png and /dev/null differ
diff --git a/lectures/08_architecture/neur_logic.svg b/lectures/08_architecture/neur_logic.svg
deleted file mode 100644
index dbc62145..00000000
--- a/lectures/08_architecture/neur_logic.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/08_architecture/neural-network.png b/lectures/08_architecture/neural-network.png
deleted file mode 100644
index 00cc3d8b..00000000
Binary files a/lectures/08_architecture/neural-network.png and /dev/null differ
diff --git a/lectures/08_architecture/nfps.png b/lectures/08_architecture/nfps.png
deleted file mode 100644
index 88dfb163..00000000
Binary files a/lectures/08_architecture/nfps.png and /dev/null differ
diff --git a/lectures/08_architecture/not-dl.jpg b/lectures/08_architecture/not-dl.jpg
deleted file mode 100644
index 52d0e97f..00000000
Binary files a/lectures/08_architecture/not-dl.jpg and /dev/null differ
diff --git a/lectures/08_architecture/pareto-front.svg b/lectures/08_architecture/pareto-front.svg
deleted file mode 100644
index 74179042..00000000
--- a/lectures/08_architecture/pareto-front.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/08_architecture/parts.png b/lectures/08_architecture/parts.png
deleted file mode 100644
index dae64d96..00000000
Binary files a/lectures/08_architecture/parts.png and /dev/null differ
diff --git a/lectures/08_architecture/perceptron.svg b/lectures/08_architecture/perceptron.svg
deleted file mode 100644
index a31ed101..00000000
--- a/lectures/08_architecture/perceptron.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/08_architecture/radiology-scan.jpg b/lectures/08_architecture/radiology-scan.jpg
deleted file mode 100644
index 9ea3a9c4..00000000
Binary files a/lectures/08_architecture/radiology-scan.jpg and /dev/null differ
diff --git a/lectures/08_architecture/random-forest.png b/lectures/08_architecture/random-forest.png
deleted file mode 100644
index f4e43a6d..00000000
Binary files a/lectures/08_architecture/random-forest.png and /dev/null differ
diff --git a/lectures/08_architecture/req-arch-impl.svg b/lectures/08_architecture/req-arch-impl.svg
deleted file mode 100644
index 34bea3ff..00000000
--- a/lectures/08_architecture/req-arch-impl.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/08_architecture/smartkeyboard.jpg b/lectures/08_architecture/smartkeyboard.jpg
deleted file mode 100644
index bc8d59f8..00000000
Binary files a/lectures/08_architecture/smartkeyboard.jpg and /dev/null differ
diff --git a/lectures/08_architecture/spotify.png b/lectures/08_architecture/spotify.png
deleted file mode 100644
index b58b9ddf..00000000
Binary files a/lectures/08_architecture/spotify.png and /dev/null differ
diff --git a/lectures/08_architecture/system.svg b/lectures/08_architecture/system.svg
deleted file mode 100644
index 9d3cfe66..00000000
--- a/lectures/08_architecture/system.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/08_architecture/temi.png b/lectures/08_architecture/temi.png
deleted file mode 100644
index 29ce2dd5..00000000
Binary files a/lectures/08_architecture/temi.png and /dev/null differ
diff --git a/lectures/08_architecture/tradeoffs.md b/lectures/08_architecture/tradeoffs.md
deleted file mode 100644
index 7305586b..00000000
--- a/lectures/08_architecture/tradeoffs.md
+++ /dev/null
@@ -1,1093 +0,0 @@
----
-author: Christian Kaestner and Eunsuk Kang
-title: "MLiP: Toward Architecture and Design"
-semester: Spring 2023
-footer: "17-645 Machine Learning in Production • Christian Kaestner,
-Eunsuk Kang, Carnegie Mellon University • Spring 2023"
-license: Creative Commons Attribution 4.0 International (CC BY 4.0)
----
-
-
-
-## Machine Learning in Production
-
-# Toward Architecture and Design
-
-
-
----
-## After requirements...
-
-
-
-
-
-----
-## Learning Goals
-
-* Describe the role of architecture and design between requirements and implementation
-* Identify the different ML components and organize and prioritize their quality concerns for a given project
-* Explain they key ideas behind decision trees and random forests and analyze consequences for various qualities
-* Demonstrate an understanding of the key ideas of deep learning and how it drives qualities
-* Plan and execute an evaluation of the qualities of alternative AI components for a given purpose
-
-----
-## Readings
-
-Required reading: Hulten, Geoff. "Building Intelligent Systems: A
-Guide to Machine Learning Engineering." (2018), Chapters 17 and 18
-
-Recommended reading: Siebert, Julien, Lisa Joeckel, Jens Heidrich, Koji Nakamichi, Kyoko Ohashi, Isao Namba, Rieko Yamamoto, and Mikio Aoyama. “Towards Guidelines for Assessing Qualities of Machine Learning Systems.” In International Conference on the Quality of Information and Communications Technology, pp. 17–31. Springer, Cham, 2020.
-
-
-
-
-
-
-
-
-
-
-
-
-
-
----
-# Recall: ML is a Component in a System in an Environment
-
-
-
-----
-
-
-
-
-
-
-* **ML components** for transcription model, pipeline to train the model, monitoring infrastructure...
-* **Non-ML components** for data storage, user interface, payment processing, ...
-* User requirements and assumptions
-*
-* System quality vs model quality
-* System requirements vs model requirements
-
-
-
-
-----
-## Recall: Systems Thinking
-
-
-
-
-> A system is a set of inter-related components that work together in a particular environment to perform whatever functions are required to achieve the system's objective -- Donella Meadows
-
-
-
----
-# Thinking like a Software Architect
-
-
-
-
-----
-## So far: Requirements
-
-* Identify goals for the system, define success metrics
-* Understand requirements, specifications, and assumptions
-* Consider risks, plan for mitigations to mistakes
-* Approaching component requirements: Understand quality requirements and constraints for models and learning algorithms
-
-
-----
-## From Requirements to Implementations...
-
-We know what to build, but how? How to we meet the quality goals?
-
-
-
-
-**Software architecture:** Key design decisions, made early in the
- development, focusing on key product qualities
-
-Architectural decisions are hard to change later
-
-
-----
-## Software Architecture
-
-> The software architecture of a program or computing system is the **structure or structures** of the system, which comprise **software elements**, the ***externally visible properties*** of those elements, and the relationships among them.
-> -- [Kazman et al. 2012](https://www.oreilly.com/library/view/software-architecture-in/9780132942799/?ar)
-
-
-----
-## Architecture Decisions: Examples
-
-* What are the major components in the system? What does each
-component do?
-* Where do the components live? Monolithic vs microservices?
-* How do components communicate to each other? Synchronous vs
-asynchronous calls?
-* What API does each component publish? Who can access this API?
-* Where does the ML inference happen? Client-side or server-side?
-* Where is the telemetry data collected from the users stored?
-* How large should the user database be? Centralized vs decentralized?
-* ...and many others
-
-----
-## Software Architecture
-
-> Architecture represents the set of **significant** **design** decisions that shape the form and the function of a system, where **significant** is measured by cost of change.
-> -- [Grady Booch, 2006]
-
-----
-## How much Architecture/Design?
-
-
-
-
-
-Software Engineering Theme: *Think before you code*
-
-Like requirements: Slower initially, but upfront investment can prevent problems later and save overall costs
-
--> Focus on most important qualities early, but leave flexibility
-
-----
-## Quality Requirements Drive Architecture Design
-
-Driven by requirements, identify most important qualities
-
-Examples:
-* Development cost, operational cost, time to release
-* Scalability, availability, response time, throughput
-* Security, safety, usability, fairness
-* Ease of modifications and updates
-* ML: Accuracy, ability to collect data, training latency
-
-----
-## Architecture Design Involve Quality Trade-offs
-
-
-
-
-**Q. What are quality trade-offs between the two?**
-
-
-[Image source](https://medium.com/javanlabs/micro-services-versus-monolithic-architecture-what-are-they-e17ddc8d3910)
-
-----
-
-## Why Architecture? ([Kazman et al. 2012](https://www.oreilly.com/library/view/software-architecture-in/9780132942799/?ar))
-
-
-
-Represents earliest design decisions.
-
-Aids in **communication** with stakeholders: Shows them “how” at a level they can understand, raising questions about whether it meets their needs
-
-Defines **constraints** on implementation: Design decisions form “load-bearing walls” of application
-
-Dictates **organizational structure**: Teams work on different components
-
-Inhibits or enables **quality attributes**: Similar to design patterns
-
-Supports **predicting** cost, quality, and schedule: Typically by predicting information for each component
-
-Aids in software **evolution**: Reason about cost, design, and effect of changes
-
-
-
-----
-
-## Case Study: Twitter
-
-
-
-Note: Source and additional reading: Raffi. [New Tweets per second record, and how!](https://blog.twitter.com/engineering/en_us/a/2013/new-tweets-per-second-record-and-how.html) Twitter Blog, 2013
-
-----
-
-## Twitter - Caching Architecture
-
-
-
-
-Notes:
-
-* Running one of the world’s largest Ruby on Rails installations
-* 200 engineers
-* Monolithic: managing raw database, memcache, rendering the site, and * presenting the public APIs in one codebase
-* Increasingly difficult to understand system; organizationally challenging to manage and parallelize engineering teams
-* Reached the limit of throughput on our storage systems (MySQL); read and write hot spots throughout our databases
-* Throwing machines at the problem; low throughput per machine (CPU + RAM limit, network not saturated)
-* Optimization corner: trading off code readability vs performance
-
-----
-
-## Twitter's Redesign Goals
-
-
-
-* **Performance**
- * Improve median latency; lower outliers
- * Reduce number of machines 10x
-+ **Reliability**
- * Isolate failures
-+ **Maintainability**
- * *"We wanted cleaner boundaries with “related” logic being in one place"*:
-encapsulation and modularity at the systems level (vs class/package level)
-* **Modifiability**
- * Quicker release of new features: *"run small and empowered engineering teams that could make local decisions and ship user-facing changes, independent of other teams"*
-
-
-
-
-
-Raffi. [New Tweets per second record, and how!](https://blog.twitter.com/engineering/en_us/a/2013/new-tweets-per-second-record-and-how.html) Twitter Blog, 2013
-
-----
-## Twitter: Redesign Decisions
-
-
-
-* Ruby on Rails -> JVM/Scala
-* Monolith -> Microservices
-* RPC framework with monitoring, connection pooling, failover strategies, loadbalancing, ... built in
-* New storage solution, temporal clustering, "roughly sortable ids"
-* Data driven decision making
-
-
-
-
-
-
-
-----
-
-## Twitter Case Study: Key Insights
-
-Architectural decisions affect entire systems, not only individual modules
-
-Abstract, different abstractions for different scenarios
-
-Reason about quality attributes early
-
-Make architectural decisions explicit
-
-Question: **Did the original architect make poor decisions?**
-
-
-
-
-
-
-
-
-
----
-# Decomposition, Interfaces, and Responsibility Assignm.
-
-
-
-
-----
-## System Decomposition
-
-
-
-
-Identify components and their responsibilities
-
-Establishes interfaces and team boundaries
-
-----
-## Information Hiding
-
-
-
-
-Hide design decisions that are likely to change from clients
-
-**Q. Examples? What are the benefits of information hiding?**
-
-----
-## Information Hiding
-
-Decomposition enables scaling teams
-* Each team works on a component
-* Coordinate on *interfaces*, but implementations remain hidden
-
-**Interface descriptions are crucial**
-* Who is responsible for what
-* Component requirements (specifications), behavioral and quality
-* Especially consider nonlocal qualities: e.g., safety, privacy
-
-Challenges: Interfaces rarely fully specified, source of conflicts,
-changing requirements
-
-----
-## Each system is different...
-
-
-
-
-
-----
-## Each system is different...
-
-
-
-
-----
-## Each system is different...
-
-
-
-----
-## Each system is different...
-
-
-
-
-
-----
-## System Decomposition
-
-
-
-Each system is different, identify important components
-
-
-Examples:
-* Personalized music recommendations: microserivce deployment in cloud, logging of user activity, nightly batch processing for inference, regular model updates, regular experimentation, easy fallback
-* Transcription service: irregular user interactions, large model, expensive inference, inference latency not critical, rare model updates
-* Autonomous vehicle: on-board hardware sets limits, real-time needs, safety critical, updates necessary, limited experimentation in practice, not always online
-* Smart keyboard: privacy focused, small model, federated learning on user device, limited telemetry
-
-
-
-
-----
-## Common Components in ML-based Systems
-
-* **Model inference service**: Uses model to make predictions for input data
-* **ML pipeline**: Infrastructure to train/update the model
-* **Monitoring**: Observe model and system
-* **Data sources**: Manual/crowdsourcing/logs/telemetry/...
-* **Data management**: Storage and processing of data, often at scale
-* **Feature store**: Reusable feature engineering code, cached feature computations
-
-----
-## Common System-Wide Design Challenges
-
-Separating concerns, understanding interdependencies
-* e.g., anticipating/breaking feedback loops, conflicting needs of components
-
-Facilitating experimentation, updates with confidence
-
-Separating training and inference; closing the loop
-* e.g., collecting telemetry to learn from user interactions
-
-Learn, serve, and observe at scale or with resource limits
-* e.g., cloud deployment, embedded devices
-
-
-
-
-
-
----
-# Scoping Relevant Qualities of ML Components
-
-From System Quality Requirements to Component Quality Specifications
-
-
-----
-## AI = DL?
-
-
-
-----
-## ML Algorithms Today
-
-
-
-----
-## Design Decision: ML Model Selection
-
-How do I decide which ML algorithm to use for my project?
-
-Criteria: Quality Attributes & Constraints
-
-----
-## Recall: Quality Attributes
-
-
-
-Measurable or testable properties of a system that are used to indicate how well it satisfies its goals
-
-Examples
- * Performance
- * Features
- * Reliability
- * Conformance
- * Durability
- * Serviceability
- * Aesthetics
- * Perceived quality
- * and many others
-
-
-
-
-
-Reference:
-Garvin, David A., [What Does Product Quality Really Mean](http://oqrm.org/English/What_does_product_quality_really_means.pdf). Sloan management review 25 (1984).
-
-----
-## Accuracy is not Everything
-
-Beyond prediction accuracy, what qualities may be relevant for an ML component?
-
-
-
-Note: Collect qualities on whiteboard
-
-
-
-----
-## Qualities of Interest?
-
-Scenario: ML component for transcribing audio files
-
-
-
-
-Note: Which of the previously discussed qualities are relevant?
-Which additional qualities may be relevant here?
-
-Cost per transaction; how much does it cost to transcribe? How much do
-we make?
-
-----
-## Qualities of Interest?
-
-Scenario: Component for detecting lane markings in a vehicle
-
-
-
-Note: Which of the previously discussed qualities are relevant?
-Which additional qualities may be relevant here?
-
-Realtime use
-
-----
-## Qualities of Interest?
-
-Scenario: Component for detecting credit card frauds, as a service for banks
-
-
-
-
-
-Note: Very high volume of transactions, low cost per transaction, frequent updates
-
-Incrementality
-
-
-
-----
-## Common of ML Qualities to Consider
-
-* Accuracy
-* Correctness guarantees? Probabilistic guarantees (--> symbolic AI)
-* How many features?
-* How much data needed? Data quality important?
-* Incremental training possible?
-* Training time, memory need, model size -- depending on training data volume and feature size
-* Inference time, energy efficiency, resources needed, scalability
-* Interpretability, explainability
-* Robustness, reproducibility, stability
-* Security, privacy, fairness
-
-----
-
-
-
-
-From: Habibullah, Khan Mohammad, Gregory Gay, and Jennifer Horkoff. "[Non-Functional Requirements for Machine Learning: An Exploration of System Scope and Interest](https://arxiv.org/abs/2203.11063)." arXiv preprint arXiv:2203.11063 (2022).
-
-----
-## Preview: Interpretability/Explainability
-
-
-
-*"Why did the model predict X?"*
-
-**Explaining predictions + Validating Models + Debugging**
-
-```
-IF age between 18–20 and sex is male THEN predict arrest
-ELSE IF age between 21–23 and 2–3 prior offenses THEN predict arrest
-ELSE IF more than three priors THEN predict arrest
-ELSE predict no arrest
-```
-
-* Some models inherently simpler to understand
-* Some tools may provide post-hoc explanations
-* Explanations may be more or less truthful
-* How to measure interpretability?
-
-
-
-----
-## Preview: Robustness
-
-
-
-* Small input modifications may change output
-* Small training data modifications may change predictions
-* How to measure robustness?
-
-
-
-Image source: [OpenAI blog](https://openai.com/blog/adversarial-example-research/)
-
-
-----
-## Preview: Fairness
-
-
-*Does the model perform differently for different populations?*
-
-```
-IF age between 18–20 and sex is male THEN predict arrest
-ELSE IF age between 21–23 and 2–3 prior offenses THEN predict arrest
-ELSE IF more than three priors THEN predict arrest
-ELSE predict no arrest
-```
-
-* Many different notions of fairness
-* Often caused by bias in training data
-* Enforce invariants in model or apply corrections outside model
-* Important consideration during requirements solicitation!
-
-
-----
-## Recall: Measuring Qualities
-
-
-
-* Define a metric: Define units of interest
- - e.g., requests per second, max memory per inference, average training time in seconds for 1 million datasets
-* Collect data
-* Operationalize metric: Define measurement protocol
- - e.g., conduct experiment: train model with fixed dataset, report median training time across 5 runs, file size, average accuracy with leave-one-out cross-validation after hyperparameter tuning
- - e.g., ask 10 humans to independently label evaluation data, report
- reduction in error from the ML model over human predictions
-* Describe all relevant factors: Inputs/experimental units used, configuration decisions and tuning, hardware used, protocol for manual steps
-
-**On terminology:** *metric/measure* refer a method or standard format for measuring something; *operationalization* is identifying and implementing a method to measure some factor
-
-
-
-
-----
-## On terminology
-
-Data scientists seem to speak of *model properties* when referring to accuracy, inference time, fairness, etc
- * ... but they also use this term for whether a *learning technique* can learn non-linear relationships or whether the learning algorithm is monotonic
-
-Software engineering wording would usually be *quality attribute*, *quality requirement*, *quality specification*
- or *non-functional requirement*
-
-
-
-
----
-# Common ML Algorithms and their Qualities
-
-----
-## Linear Regression: Qualities
-
-
-
-* Tasks: Regression
-* Qualities: __Advantages__: ?? __Drawbacks__: ??
-
-Notes:
-* Easy to interpret, low training cost, small model size
-* Can't capture non-linear relationships well
-
-----
-## Decision Trees
-
-
-
-
-
-
-----
-## Building Decision Trees
-
-
-
-
-
-
-
-* Identify all possible decisions
-* Select the decision that best splits the dataset into distinct
- outcomes (typically via entropy or similar measure)
-* Repeatedly further split subsets, until stopping criteria reached
-
-
-
-----
-## Decision Trees: Qualities
-
-
-
-
-* Tasks: Classification & regression
-* Qualities: __Advantages__: ?? __Drawbacks__: ??
-
-Notes:
-* Easy to interpret (up to a size); can capture non-linearity; can do well with
- little data
-* High risk of overfitting; possibly very large tree size
-* Obvious ones: fairly small model size, low inference cost,
-no obvious incremental training; easy to interpret locally and
-even globally if shallow; easy to understand decision boundaries
-
-
-
-
-
-
-
-
-----
-## Random Forests
-
-
-
-
-* Train multiple trees on subsets of data or subsets of decisions.
-* Return average prediction of multiple trees.
-* Qualities: __Advantages__: ?? __Drawbacks__: ??
-
-Note: Increased training time and model size,
-less prone to overfitting, more difficult to interpret
-
-
-
-----
-
-# Neural Networks
-
-
-
-
-[XKCD 2173](https://xkcd.com/2173/), cc-by-nc 2.5 Randall Munroe
-
-Note: Artificial neural networks are inspired by how biological neural networks work ("groups of chemically connected or functionally associated neurons" with synapses forming connections)
-
-From "Texture of the Nervous System of Man and the Vertebrates" by Santiago Ramón y Cajal, via https://en.wikipedia.org/wiki/Neural_circuit#/media/File:Cajal_actx_inter.jpg
-
-----
-## Artificial Neural Networks
-
-Simulating biological neural networks of neurons (nodes) and synapses (connections), popularized in 60s and 70s
-
-Basic building blocks: Artificial neurons, with $n$ inputs and one output; output is activated if at least $m$ inputs are active
-
-
-
-
-(assuming at least two activated inputs needed to activate output)
-
-----
-## Threshold Logic Unit / Perceptron
-
-computing weighted sum of inputs + step function
-
-$z = w_1 x_1 + w_2 x_2 + ... + w_n x_n = \mathbf{x}^T \mathbf{w}$
-
-e.g., step: `$\phi$(z) = if (z<0) 0 else 1`
-
-
-
-
-----
-
-
-
-
-
-
-
-
-$o_1 = \phi(b_{1} + w_{1,1} x_1 + w_{1,2} x_2)$
-$o_2 = \phi(b_{2} + w_{2,1} x_1 + w_{2,2} x_2)$
-$o_3 = \phi(b_{3} + w_{3,1} x_1 + w_{3,2} x_2)$
-
-
-
-****
-$f_{\mathbf{W},\mathbf{b}}(\mathbf{X})=\phi(\mathbf{W} \cdot \mathbf{X}+\mathbf{b})$
-
-($\mathbf{W}$ and $\mathbf{b}$ are parameters of the model)
-
-----
-## Multiple Layers
-
-
-
-
-Note: Layers are fully connected here, but layers may have different numbers of neurons
-
-----
-$f_{\mathbf{W}_h,\mathbf{b}_h,\mathbf{W}_o,\mathbf{b}_o}(\mathbf{X})=\phi( \mathbf{W}_o \cdot \phi(\mathbf{W}_h \cdot \mathbf{X}+\mathbf{b}_h)+\mathbf{b}_o)$
-
-
-
-
-(matrix multiplications interleaved with step function)
-
-----
-## Learning Model Parameters (Backpropagation)
-
-
-
-Intuition:
-- Initialize all weights with random values
-- Compute prediction, remembering all intermediate activations
-- If predicted output has an error (measured with a loss function),
- + Compute how much each connection contributed to the error on output layer
- + Repeat computation on each lower layer
- + Tweak weights a little toward the correct output (gradient descent)
-- Continue training until weights stabilize
-
-Works efficiently only for certain $\phi$, typically logistic function: $\phi(z)=1/(1+exp(-z))$ or ReLU: $\phi(z)=max(0,z)$.
-
-
-
-----
-## Deep Learning
-
-More layers
-
-Layers with different numbers of neurons
-
-Different kinds of connections, e.g.,
- - Fully connected (feed forward)
- - Not fully connected (eg. convolutional networks)
- - Keeping state (eg. recurrent neural networks)
- - Skipping layers
-
-
-See Chapter 10 in Géron, Aurélien. ”[Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow](https://cmu.primo.exlibrisgroup.com/permalink/01CMU_INST/6lpsnm/alma991019662775504436)”, 2nd Edition (2019) or any other book on deep learning
-
-
-Note: Essentially the same with more layers and different kinds of architectures.
-
-
-----
-## Deep Learning
-
-
-
-* Tasks: Classification & regression
-* Qualities: __Advantages__: ?? __Drawbacks__: ??
-
-Notes:
-* High accuracy; can capture a wide range of problems (linear & non-linear)
-* Difficult to interpret; high training costs (time & amount of
-data required, hyperparameter tuning)
-
-
-----
-## Example Scenario
-
-*MNIST Fashion dataset of 70k 28x28 grayscale pixel images, 10 output classes*
-
-
-
-
-----
-## Example Scenario
-
-* MNIST Fashion dataset of 70k 28x28 grayscale pixel images, 10 output classes
-* 28x28 = 784 inputs in input layers (each 0..255)
-* Example model with 3 layers, 300, 100, and 10 neurons
-
-```python
-model = keras.models.Sequential([
- keras.layers.Flatten(input_shape=[28, 28]),
- keras.layers.Dense(300, activation="relu"),
- keras.layers.Dense(100, activation="relu"),
- keras.layers.Dense(10, activation="softmax")
-])
-```
-
-**How many parameters does this model have?**
-
-----
-## Example Scenario
-
-```python
-model = keras.models.Sequential([
- keras.layers.Flatten(input_shape=[28, 28]),
- # 784*300+300 = 235500 parameter
- keras.layers.Dense(300, activation="relu"),
- # 300*100+100 = 30100 parameters
- keras.layers.Dense(100, activation="relu"),
- # 100*10+10 = 1010 parameters
- keras.layers.Dense(10, activation="softmax")
-])
-```
-
-Total of 266,610 parameters in this small example! (Assuming float types, that's 1 MB)
-
-----
-## Network Size
-
-
-
-* 50 Layer ResNet network -- classifying 224x224 images into 1000 categories
- * 26 million weights, computes 16 million activations during inference, 168 MB to store weights as floats
-* Google in 2012(!): 1TB-1PB of training data, 1 billion to 1 trillion parameters
-* OpenAI’s GPT-2 (2019) -- text generation
- - 48 layers, 1.5 billion weights (~12 GB to store weights)
- - released model reduced to 117 million weights
- - trained on 7-8 GPUs for 1 month with 40GB of internet text from 8 million web pages
-* OpenAI’s GPT-3 (2020): 96 layers, 175 billion weights, 700 GB in memory, $4.6M in approximate compute cost for training
-
-
-Notes: https://lambdalabs.com/blog/demystifying-gpt-3/
-
-----
-## Cost & Energy Consumption
-
-
-
-
-
-| Consumption | CO2 (lbs) |
-| - | - |
-| Air travel, 1 passenger, NY↔SF | 1984 |
-| Human life, avg, 1 year | 11,023 |
-| American life, avg, 1 year | 36,156 |
-| Car, avg incl. fuel, 1 lifetime | 126,000 |
-
-
-
-| Training one model (GPU) | CO2 (lbs) |
-| - | - |
-| NLP pipeline (parsing, SRL) | 39 |
-| w/ tuning & experimentation | 78,468 |
-| Transformer (big) | 192 |
-| w/ neural architecture search | 626,155 |
-
-
-
-
-
-
-Strubell, Emma, Ananya Ganesh, and Andrew McCallum. "[Energy and Policy Considerations for Deep Learning in NLP](https://arxiv.org/pdf/1906.02243.pdf)." In Proc. ACL, pp. 3645-3650. 2019.
-
-
-----
-## Cost & Energy Consumption
-
-
-| Model | Hardware | Hours | CO2 | Cloud cost in USD |
-| - | - | - | - | - |
-| Transformer | P100x8 | 84 | 192 | 289–981 |
-| ELMo | P100x3 | 336 | 262 | 433–1472 |
-| BERT | V100x64 | 79 | 1438 | 3751–13K |
-| NAS | P100x8 | 274,120 | 626,155 | 943K–3.2M |
-| GPT-2 | TPUv3x32 | 168 | — | 13K–43K |
-| GPT-3 | | | — | 4.6M |
-
-
-
-Strubell, Emma, Ananya Ganesh, and Andrew McCallum. "[Energy and Policy Considerations for Deep Learning in NLP](https://arxiv.org/pdf/1906.02243.pdf)." In Proc. ACL, pp. 3645-3650. 2019.
-
-
-
-
-
-
-
-
-
-
----
-# Constraints and Tradeoffs
-
-
-
-
-
-----
-## Design Decision: ML Model Selection
-
-How do I decide which ML algorithm to use for my project?
-
-Criteria: Quality Attributes & Constraints
-
-----
-## Constraints
-
-Constraints define the space of attributes for valid design solutions
-
-
-
-
-Note: Design space exploration: The space of all possible designs (dotted rectangle) is reduced by several constraints on qualities of the system, leaving only a subset of designs for further consideration (highlighted center area).
-
-
-----
-## Types of Constraints
-
-**Problem constraints**: Minimum required QAs for an acceptable product
-
-**Project constraint**s: Deadline, project budget, available personnel/skills
-
-**Design constraints**
-* Type of ML task required (regression/classification)
-* Available data
-* Limits on computing resources, max. inference cost/time
-
-----
-## Constraints: Cancer Prognosis?
-
-
-
-
-----
-## Constraints: Music Recommendations?
-
-
-
-
-----
-## Trade-offs between ML algorithms
-
-If there are multiple ML algorithms that satisfy the given constraints, which
-one do we select?
-
-Different ML qualities may conflict with each other; this requires
-making a __trade-off__ between these qualities
-
-Among the qualities of interest, which one(s) do we care the most
-about?
-* And which ML algorithm is most suitable for achieving those qualities?
-* (Similar to requirements conflicts)
-
-----
-## Multi-Objective Optimization
-
-
-
-* Determine optimal solutions given multiple, possibly
- **conflicting** objectives
-* **Dominated** solution: A solution that is inferior to
- others in every way
-* **Pareto frontier**: A set of non-dominated solutions
-* Consider trade-offs among Pareto optimal solutions
-
-
-
-
-
-
-
-
-Note: Tradeoffs among multiple design solutions along two dimensions (cost and error). Gray solutions are all dominated by others that are better both in terms of cost and error (e.g., solution D has worse error and worse cost than solution A). The remaining black solutions are each better than another solution on one dimension but worse on another — they are all pareto optimal and which solution to pick depends on the relative importance of the dimensions.
-
-
-----
-## Trade-offs: Cost vs Accuracy
-
-
-
-
-
-
-
-
-_"We evaluated some of the new methods offline but the additional
-accuracy gains that we measured did not seem to justify the
-engineering effort needed to bring them into a production
-environment.”_
-
-
-
-
-
-Amatriain & Basilico. [Netflix Recommendations: Beyond the 5 stars](https://netflixtechblog.com/netflix-recommendations-beyond-the-5-stars-part-1-55838468f429),
-Netflix Technology Blog (2012)
-
-----
-## Trade-offs: Accuracy vs Interpretability
-
-
-
-
-**Q. Examples where one is more important than the other?**
-
-
-
-Bloom & Brink. [Overcoming the Barriers to Production-Ready Machine Learning
-Workflows](https://conferences.oreilly.com/strata/strata2014/public/schedule/detail/32314), Presentation at O'Reilly Strata Conference (2014).
-
-----
-## Breakout: Qualities & ML Algorithms
-
-Consider two scenarios:
-1. Credit card fraud detection
-2. Pedestrian detection in sidewalk robot
-
-As a group, post to `#lecture` tagging all group members:
-> * Qualities of interests: ??
-> * Constraints: ??
-> * ML algorithm(s) to use: ??
-
-
-
-
-
----
-# Summary
-
-Software architecture focuses on early key design decisions, focused on key qualities
-
-Between requirements and implementation
-
-Decomposing the system into components, many ML components
-
-Many qualities of interest, define metrics and operationalize
-
-Constraints and tradeoff analysis for selecting ML techniques in production ML settings
-
-
-
-
-----
-## Further Readings
-
-
-
-* Bass, Len, Paul Clements, and Rick Kazman. Software architecture in practice. Addison-Wesley Professional, 3rd edition, 2012.
-* Yokoyama, Haruki. “Machine learning system architectural pattern for improving operational stability.” In 2019 IEEE International Conference on Software Architecture Companion (ICSA-C), pp. 267–274. IEEE, 2019.
-* Serban, Alex, and Joost Visser. “An Empirical Study of Software Architecture for Machine Learning.” In Proceedings of the International Conference on Software Analysis, Evolution and Reengineering (SANER), 2022.
-* Lakshmanan, Valliappa, Sara Robinson, and Michael Munn. Machine learning design patterns. O’Reilly Media, 2020.
-* Lewis, Grace A., Ipek Ozkaya, and Xiwei Xu. “Software Architecture Challenges for ML Systems.” In 2021 IEEE International Conference on Software Maintenance and Evolution (ICSME), pp. 634–638. IEEE, 2021.
-* Vogelsang, Andreas, and Markus Borg. “Requirements Engineering for Machine Learning: Perspectives from Data Scientists.” In Proc. of the 6th International Workshop on Artificial Intelligence for Requirements Engineering (AIRE), 2019.
-* Habibullah, Khan Mohammad, Gregory Gay, and Jennifer Horkoff. "[Non-Functional Requirements for Machine Learning: An Exploration of System Scope and Interest](https://arxiv.org/abs/2203.11063)." arXiv preprint arXiv:2203.11063 (2022).
-
-
diff --git a/lectures/08_architecture/tradeoffs.png b/lectures/08_architecture/tradeoffs.png
deleted file mode 100644
index 5e2609c4..00000000
Binary files a/lectures/08_architecture/tradeoffs.png and /dev/null differ
diff --git a/lectures/08_architecture/transcriptionarchitecture2.svg b/lectures/08_architecture/transcriptionarchitecture2.svg
deleted file mode 100644
index 212a40f7..00000000
--- a/lectures/08_architecture/transcriptionarchitecture2.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/08_architecture/twitter-caching.png b/lectures/08_architecture/twitter-caching.png
deleted file mode 100644
index 9f08e32c..00000000
Binary files a/lectures/08_architecture/twitter-caching.png and /dev/null differ
diff --git a/lectures/08_architecture/twitter.png b/lectures/08_architecture/twitter.png
deleted file mode 100644
index d5bc26d4..00000000
Binary files a/lectures/08_architecture/twitter.png and /dev/null differ
diff --git a/lectures/08_architecture/xkcd2173.png b/lectures/08_architecture/xkcd2173.png
deleted file mode 100644
index 99fa0fc3..00000000
Binary files a/lectures/08_architecture/xkcd2173.png and /dev/null differ
diff --git a/lectures/09_deploying_a_model/2phase-prediction.svg b/lectures/09_deploying_a_model/2phase-prediction.svg
deleted file mode 100644
index f9b92a94..00000000
--- a/lectures/09_deploying_a_model/2phase-prediction.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/09_deploying_a_model/3tier-with-ml.svg b/lectures/09_deploying_a_model/3tier-with-ml.svg
deleted file mode 100644
index ccc2e2c2..00000000
--- a/lectures/09_deploying_a_model/3tier-with-ml.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/09_deploying_a_model/apollo.png b/lectures/09_deploying_a_model/apollo.png
deleted file mode 100644
index 03609231..00000000
Binary files a/lectures/09_deploying_a_model/apollo.png and /dev/null differ
diff --git a/lectures/09_deploying_a_model/ar-architecture.svg b/lectures/09_deploying_a_model/ar-architecture.svg
deleted file mode 100644
index 57759c9b..00000000
--- a/lectures/09_deploying_a_model/ar-architecture.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/09_deploying_a_model/arch-diagram-example.svg b/lectures/09_deploying_a_model/arch-diagram-example.svg
deleted file mode 100644
index ff959025..00000000
--- a/lectures/09_deploying_a_model/arch-diagram-example.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/09_deploying_a_model/deployment.md b/lectures/09_deploying_a_model/deployment.md
deleted file mode 100644
index cf4adccd..00000000
--- a/lectures/09_deploying_a_model/deployment.md
+++ /dev/null
@@ -1,899 +0,0 @@
----
-author: Christian Kaestner and Eunsuk Kang
-title: "MLiP: Deploying a Model"
-semester: Spring 2023
-footer: "Machine Learning in Production/AI Engineering • Christian Kaestner & Eunsuk Kang, Carnegie Mellon University • Spring 2023"
-license: Creative Commons Attribution 4.0 International (CC BY 4.0)
----
-
-
-
-## Machine Learning in Production
-
-# Deploying a Model
-
-
-
----
-## Deeper into architecture and design...
-
-
-
-
-
-
-----
-
-## Learning Goals
-
-
-
-* Understand important quality considerations when deploying ML components
-* Follow a design process to explicitly reason about alternative designs and their quality tradeoffs
-* Gather data to make informed decisions about what ML technique to use and where and how to deploy it
-* Understand the power of design patterns for codifying design knowledge
-*
-* Create architectural models to reason about relevant characteristics
-* Critique the decision of where an AI model lives (e.g., cloud vs edge vs hybrid), considering the relevant tradeoffs
-* Deploy models locally and to the cloud
-* Document model inference services
-
-
-
-----
-## Readings
-
-Required reading:
-* 🕮 Hulten, Geoff. "[Building Intelligent Systems: A Guide to Machine Learning Engineering.](https://www.buildingintelligentsystems.com/)" Apress, 2018, Chapter 13 (Where Intelligence Lives).
-* 📰 Daniel Smith. "[Exploring Development Patterns in Data Science](https://www.theorylane.com/2017/10/20/some-development-patterns-in-data-science/)." TheoryLane Blog Post. 2017.
-
-Recommended reading:
-* 🕮 Rick Kazman, Paul Clements, and Len Bass. [Software architecture in practice.](https://www.oreilly.com/library/view/software-architecture-in/9780132942799/?ar) Addison-Wesley Professional, 2012, Chapter 1
-
-
-
-
----
-# Deploying a Model is Easy
-
-----
-## Deploying a Model is Easy
-
-Model inference component as function/library
-
-```python
-from sklearn.linear_model import LogisticRegression
-model = … # learn model or load serialized model ...
-def infer(feature1, feature2):
- return model.predict(np.array([[feature1, feature2]])
-```
-
-----
-## Deploying a Model is Easy
-
-Model inference component as a service
-
-
-```python
-from flask import Flask, escape, request
-app = Flask(__name__)
-app.config['UPLOAD_FOLDER'] = '/tmp/uploads'
-detector_model = … # load model…
-
-# inference API that returns JSON with classes
-# found in an image
-@app.route('/get_objects', methods=['POST'])
-def pred():
- uploaded_img = request.files["images"]
- coverted_img = … # feature encoding of uploaded img
- result = detector_model(converted_img)
- return jsonify({"response":
- result['detection_class_entities']})
-
-```
-
-----
-## Deploying a Model is Easy
-
-Packaging a model inference service in a container
-
-
-```docker
-FROM python:3.8-buster
-RUN pip install uwsgi==2.0.20
-RUN pip install tensorflow==2.7.0
-RUN pip install flask==2.0.2
-RUN pip install gunicorn==20.1.0
-COPY models/model.pf /model/
-COPY ./serve.py /app/main.py
-WORKDIR ./app
-EXPOSE 4040
-CMD ["gunicorn", "-b 0.0.0.0:4040", "main:app"]
-```
-
-----
-## Deploying a Model is Easy
-
-Model inference component as a service in the cloud
-
-* Package in container or other infrastructure
-* Deploy in cloud infrastructure
-* Auto-scaling with demand ("*Stateless Serving Functions Pattern*")
-* MLOps infrastructure to automate all of this (more on this later)
- * [BentoML](https://github.com/bentoml/BentoML) (low code service creation, deployment, model registry),
- * [Cortex](https://github.com/bentoml/BentoML) (automated deployment and scaling of models on AWS),
- * [TFX model serving](https://www.tensorflow.org/tfx/guide/serving) (tensorflow GRPC services)
- * [Seldon Core](https://www.seldon.io/tech/products/core/) (no-code model service and many many additional services for monitoring and operations on Kubernetes)
-
-
-
-
-----
-## But is it really easy?
-
-Offline use?
-
-Deployment at scale?
-
-Hardware needs and operating cost?
-
-Frequent updates?
-
-Integration of the model into a system?
-
-Meeting system requirements?
-
-**Every system is different!**
-
-----
-## Every System is Different
-
-Personalized music recommendations for Spotify
-
-Transcription service startup
-
-Self-driving car
-
-Smart keyboard for mobile device
-
-----
-## Inference is a Component within a System
-
-
-
-
-
-
-
-
----
-# Recall: Thinking like a Software Architect
-
-
-
-
-
-----
-## Recall: Systems Thinking
-
-
-
-
-> A system is a set of inter-related components that work together in a particular environment to perform whatever functions are required to achieve the system's objective -- Donella Meadows
-
-
-
----
-
-# Architectural Modeling and Reasoning
-----
-
-Notes: Map of Pittsburgh. Abstraction for navigation with cars.
-----
-
-Notes: Cycling map of Pittsburgh. Abstraction for navigation with bikes and walking.
-----
-
-Notes: Fire zones of Pittsburgh. Various use cases, e.g., for city planners.
-----
-## Analysis-Specific Abstractions
-
-All maps were abstractions of the same real-world construct
-
-All maps were created with different goals in mind
- - Different relevant abstractions
- - Different reasoning opportunities
-
-Architectural models are specific system abstractions, for reasoning about specific qualities
-
-No uniform notation
-
-----
-
-## What can we reason about?
-
-
-
-
-----
-
-## What can we reason about?
-
-
-
-
-
-Ghemawat, Sanjay, Howard Gobioff, and Shun-Tak Leung. "[The Google file system.](https://ai.google/research/pubs/pub51.pdf)" ACM SIGOPS operating systems review. Vol. 37. No. 5. ACM, 2003.
-
-Notes: Scalability through redundancy and replication; reliability wrt to single points of failure; performance on edges; cost
-
-----
-## What can we reason about?
-
-
-
-
-
-Peng, Zi, Jinqiu Yang, Tse-Hsun Chen, and Lei Ma. "A first look at the integration of machine learning models in complex autonomous driving systems: a case study on Apollo." In Proc. FSE, 2020.
-
-----
-
-## Suggestions for Graphical Notations
-
-Use notation suitable for analysis
-
-Document meaning of boxes and edges in legend
-
-Graphical or textual both okay; whiteboard sketches often sufficient
-
-Formal notations available
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
----
-
-# Case Study: Augmented Reality Translation
-
-
-
-
-
-
-Notes: Image: https://pixabay.com/photos/nightlife-republic-of-korea-jongno-2162772/
-
-----
-## Case Study: Augmented Reality Translation
-
-
-
-----
-## Case Study: Augmented Reality Translation
-
-
-
-Notes: Consider you want to implement an instant translation service similar toGoogle translate, but run it on embedded hardware in glasses as an augmented reality service.
-----
-## System Qualities of Interest?
-
-
-
-
----
-# Design Decision: Selecting ML Algorithms
-
-What ML algorithms to use and why? Tradeoffs?
-
-
-
-
-
-Notes: Relate back to previous lecture about AI technique tradeoffs, including for example
-Accuracy
-Capabilities (e.g. classification, recommendation, clustering…)
-Amount of training data needed
-Inference latency
-Learning latency; incremental learning?
-Model size
-Explainable? Robust?
-
----
-# Design Decision: Where Should the Model Live?
-
-(Deployment Architecture)
-
-----
-## Where Should the Models Live?
-
-
-
-
-Cloud? Phone? Glasses?
-
-What qualities are relevant for the decision?
-
-Notes: Trigger initial discussion
-
-
-----
-## Considerations
-
-* How much data is needed as input for the model?
-* How much output data is produced by the model?
-* How fast/energy consuming is model execution?
-* What latency is needed for the application?
-* How big is the model? How often does it need to be updated?
-* Cost of operating the model? (distribution + execution)
-* Opportunities for telemetry?
-* What happens if users are offline?
-
-----
-## Breakout: Latency and Bandwidth Analysis
-
-
-1. Estimate latency and bandwidth requirements between components
-2. Discuss tradeoffs among different deployment models
-
-
-
-
-
-
-As a group, post in `#lecture` tagging group members:
-* Recommended deployment for OCR (with justification):
-* Recommended deployment for Translation (with justification):
-
-
-
-Notes: Identify at least OCR and Translation service as two AI components in a larger system. Discuss which system components are worth modeling (e.g., rendering, database, support forum). Discuss how to get good estimates for latency and bandwidth.
-
-Some data:
-200ms latency is noticable as speech pause;
-20ms is perceivable as video delay, 10ms as haptic delay;
-5ms referenced as cybersickness threshold for virtual reality
-20ms latency might be acceptable
-
-bluetooth latency around 40ms to 200ms
-
-bluetooth bandwidth up to 3mbit, wifi 54mbit, video stream depending on quality 4 to 10mbit for low to medium quality
-
-google glasses had 5 megapixel camera, 640x360 pixel screen, 1 or 2gb ram, 16gb storage
-
-
-----
-
-
-
-
-
-----
-## From the Reading: When would one use the following designs?
-
-* Static intelligence in the product
-* Client-side intelligence (user-facing devices)
-* Server-centric intelligence
-* Back-end cached intelligence
-* Hybrid models
-*
-* Consider: Offline use, inference latency, model updates, application updates, operating cost, scalability, protecting intellectual property
-
-
-Notes:
-From the reading:
-* Static intelligence in the product
- - difficult to update
- - good execution latency
- - cheap operation
- - offline operation
- - no telemetry to evaluate and improve
-* Client-side intelligence
- - updates costly/slow, out of sync problems
- - complexity in clients
- - offline operation, low execution latency
-* Server-centric intelligence
- - latency in model execution (remote calls)
- - easy to update and experiment
- - operation cost
- - no offline operation
-* Back-end cached intelligence
- - precomputed common results
- - fast execution, partial offline
- - saves bandwidth, complicated updates
-* Hybrid models
-
-
-----
-## Where Should Feature Encoding Happen?
-
-
-
-
-*Should feature encoding happen server-side or client-side? Tradeoffs?*
-
-Note: When thinking of model inference as a component within a system, feature encoding can happen with the model-inference component or can be the responsibility of the client. That is, the client either provides the raw inputs (e.g., image files; dotted box in the figure above) to the inference service or the client is responsible for computing features and provides the feature vector to the inference service (dashed box). Feature encoding and model inference could even be two separate services that are called by the client in sequence. Which alternative is preferable is a design decision that may depend on a number of factors, for example, whether and how the feature vectors are stored in the system, how expensive computing the feature encoding is, how often feature encoding changes, how many models use the same feature encoding, and so forth. For instance, in our stock photo example, having feature encoding being part of the inference service is convenient for clients and makes it easy to update the model without changing clients, but we would have to send the entire image over the network instead of just the much smaller feature vector for the reduced 300 x 300 pixels.
-
-
-----
-## Reusing Feature Engineering Code
-
-
-
-
-
-
-Avoid *training–serving skew*
-
-----
-## The Feature Store Pattern
-
-* Central place to store, version, and describe feature engineering code
-* Can be reused across projects
-* Possible caching of expensive features
-
-
-Many open source and commercial offerings, e.g., Feast, Tecton, AWS SageMaker Feature Store
-
-----
-## Tecton Feature Store
-
-
-
-----
-## More Considerations for Deployment Decisions
-
-Coupling of ML pipeline parts
-
-Coupling with other parts of the system
-
-Ability for different developers and analysts to collaborate
-
-Support online experiments
-
-Ability to monitor
-
-
-----
-## Real-Time Serving; Many Models
-
-
-
-
-
-Peng, Zi, Jinqiu Yang, Tse-Hsun Chen, and Lei Ma. "A first look at the integration of machine learning models in complex autonomous driving systems: a case study on Apollo." In Proc. FSE. 2020.
-
-
-----
-## Infrastructure Planning (Facebook Examp.)
-
-
-
-
-
-
-Hazelwood, Kim, Sarah Bird, David Brooks, Soumith Chintala, Utku Diril, Dmytro Dzhulgakov, Mohamed Fawzy et al. "Applied machine learning at facebook: A datacenter infrastructure perspective." In Int'l Symp. High Performance Computer Architecture. IEEE, 2018.
-
-----
-## Capacity Planning (Facebook Example)
-
-
-
-| Services | Relative Capacity | Compute | Memory |
-|--|--|--|--|
-| News Feed | 100x | Dual-Socket CPU | High |
-| Facer (face recognition) | 10x | Single-Socket CPU | Low |
-| Lumos (image understanding) | 10x | Single-Socket CPU | Low |
-| Search | 10x | Dual-Socket CPU | High |
-| Lang. Translation | 1x | Dual-Socket CPU | High |
-| Sigma (anomaly and spam detection) | 1x | Dual-Socket CPU | High |
-
-* Trillions of inferences per day, in real time
-* Preference for cheap single-CPU machines whether possible
-* Different latency requirements, some "nice to have" predictions
-* Some models run on mobile device to improve latency and reduce communication cost
-
-
-
-
-
-Hazelwood, et al. "Applied machine learning at facebook: A datacenter infrastructure perspective." In Int'l Symp. High Performance Computer Architecture. IEEE, 2018.
-
-
-----
-## Operational Robustness
-
-Redundancy for availability?
-
-Load balancer for scalability?
-
-Can mistakes be isolated?
- - Local error handling?
- - Telemetry to isolate errors to component?
-
-Logging and log analysis for what qualities?
-
-
-
----
-# Preview: Telemetry Design
-
-----
-## Telemetry Design
-
-How to evaluate system performance and mistakes in production?
-
-
-
-
-Notes: Discuss strategies to determine accuracy in production. What kind of telemetry needs to be collected?
-
-----
-## The Right and Right Amount of Telemetry
-
-
-
-Purpose:
- - Monitor operation
- - Monitor mistakes (e.g., accuracy)
- - Improve models over time (e.g., detect new features)
-
-Challenges:
- - too much data, no/not enough data
- - hard to measure, poor proxy measures
- - rare events
- - cost
- - privacy
-
-**Interacts with deployment decisions**
-
-
-
-----
-## Telemetry Tradeoffs
-
-What data to collect? How much? When?
-
-Estimate data volume and possible bottlenecks in system.
-
-
-
-
-Notes: Discuss alternatives and their tradeoffs. Draw models as suitable.
-
-Some data for context:
-Full-screen png screenshot on Pixel 2 phone (1080x1920) is about 2mb (2 megapixel); Google glasses had a 5 megapixel camera and a 640x360 pixel screen, 16gb of storage, 2gb of RAM. Cellar cost are about $10/GB.
-
-
-
-
-
----
-# Integrating Models into a System
-
-----
-## Recall: Inference is a Component within a System
-
-
-
-
-----
-## Separating Models and Business Logic
-
-
-
-
-
-Based on: Yokoyama, Haruki. "Machine learning system architectural pattern for improving operational stability." In Int'l Conf. Software Architecture Companion, pp. 267-274. IEEE, 2019.
-
-----
-## Separating Models and Business Logic
-
-Clearly divide responsibilities
-
-Allows largely independent and parallel work, assuming stable interfaces
-
-Plan location of non-ML safeguards and other processing logic
-
-
-
-----
-## Composing Models: Ensemble and metamodels
-
-
-
-
-----
-## Composing Models: Decomposing the problem, sequential
-
-
-
-
-----
-## Composing Models: Cascade/two-phase prediction
-
-
-
-
-
-
-
-
-
-
-
-
----
-# Documenting Model Inference Interfaces
-
-
-
-----
-## Why Documentation
-
-Model inference between teams:
- * Data scientists developing the model
- * Other data scientists using the model, evolving the model
- * Software engineers integrating the model as a component
- * Operators managing model deployment
-
-Will this model work for my problem?
-
-What problems to anticipate?
-
-----
-## Classic API Documentation
-
-
-```java
-/**
- * compute deductions based on provided adjusted
- * gross income and expenses in customer data.
- *
- * see tax code 26 U.S. Code A.1.B, PART VI
- */
-float computeDeductions(float agi, Expenses expenses);
-```
-
-
-
-----
-## What to document for models?
-
-
-
-----
-## Documenting Input/Output Types for Inference Components
-
-```js
-{
- "mid": string,
- "languageCode": string,
- "name": string,
- "score": number,
- "boundingPoly": {
- object (BoundingPoly)
- }
-}
-```
-From Google’s public [object detection API](https://cloud.google.com/vision/docs/object-localizer).
-
-----
-## Documentation beyond I/O Types
-
-Intended use cases, model capabilities and limitations
-
-Supported target distribution (vs preconditions)
-
-Accuracy (various measures), incl. slices, fairness
-
-Latency, throughput, availability (service level agreements)
-
-Model qualities such as explainability, robustness, calibration
-
-Ethical considerations (fairness, safety, security, privacy)
-
-
-**Example for OCR model? How would you describe these?**
-
-----
-## Model Cards
-
-* Proposal and template for documentation from Google
- * Intended use, out-of-scope use
- * Training and evaluation data
- * Considered demographic factors
- * Accuracy evaluations
- * Ethical considerations
-* 1-2 page summary
-* Focused on fairness
-* Widely discussed, but not frequently adopted
-
-
-Mitchell, Margaret, et al. "[Model cards for model reporting](https://arxiv.org/abs/1810.03993)." In *Proceedings of the Conference on Fairness, Accountability, and Transparency*, 2019.
-
-----
-
-
-
-
-Example from Model Cards paper
-
-----
-
-
-
-
-From: https://modelcards.withgoogle.com/object-detection
-
-----
-## FactSheets
-
-
-
-Proposal and template for documentation from IBM; intended to communicate intended qualities and assurances
-
-Longer list of criteria, including
- * Service intention, intended use
- * Technical description
- * Target distribution
- * Own and third-party evaluation results
- * Safety and fairness considerations, explainability
- * Preparation for drift and evolution
- * Security, lineage and versioning
-
-
-
-
-Arnold, Matthew, et al. "[FactSheets: Increasing trust in AI services through supplier's declarations of conformity](https://arxiv.org/pdf/1808.07261.pdf)." *IBM Journal of Research and Development* 63, no. 4/5 (2019): 6-1.
-
-----
-## Recall: Correctness vs Fit
-
-Without a clear specification a model is difficult to document
-
-Need documentation to allow evaluation for *fit*
-
-Description of *target distribution* is a key challenge
-
-
-
-
-
-
-
-
-
-
-
-
----
-# Design Patterns for AI Enabled Systems
-
-(no standardization, *yet*)
-
-----
-## Design Patterns are Codified Design Knowl.
-
-Vocabulary of design problems and solutions
-
-
-
-
-
-Example: *Observer pattern* object-oriented design pattern describes a solution how objects can be notified when another object changes without strongly coupling these objects to each other
-
-----
-## Common System Structures
-
-Client-server architecture
-
-Multi-tier architecture
-
-Service-oriented architecture and microservices
-
-Event-based architecture
-
-Data-flow architecture
-
-----
-## Multi-Tier Architecture
-
-
-
-
-
-Based on: Yokoyama, Haruki. "Machine learning system architectural pattern for improving operational stability." In Int'l Conf. Software Architecture Companion, pp. 267-274. IEEE, 2019.
-
-
-----
-## Microservices
-
-
-
-
-
-(more later)
-
-
-
-----
-## Patterns for ML-Enabled Systems
-
-* Stateless/serverless Serving Function Pattern
-* Feature-Store Pattern
-* Batched/precomuted serving pattern
-* Two-phase prediction pattern
-* Batch Serving Pattern
-* Decouple-training-from-serving pattern
-
-
-----
-## Anti-Patterns
-
-* Big Ass Script Architecture
-* Dead Experimental Code Paths
-* Glue code
-* Multiple Language Smell
-* Pipeline Jungles
-* Plain-Old Datatype Smell
-* Undeclared Consumers
-
-
-
-
-
-See also: 🗎 Washizaki, Hironori, Hiromu Uchida, Foutse Khomh, and Yann-Gaël Guéhéneuc. "[Machine Learning Architecture and Design Patterns](http://www.washi.cs.waseda.ac.jp/wp-content/uploads/2019/12/IEEE_Software_19__ML_Patterns.pdf)." Draft, 2019; 🗎 Sculley, et al. "[Hidden technical debt in machine learning systems](http://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf)." In NeurIPS, 2015.
-
-
-
-
-
-
-
-
-
-
-
-
-
-
----
-
-# Summary
-
-
-
-Model deployment seems easy, but involves many design decisions
- * What models to use?
- * Where to deploy?
- * How to design feature encoding and feature engineering?
- * How to compose with other components?
- * How to document?
- * How to collect telemetry?
-
-Problem-specific modeling and analysis: Gather estimates, consider design alternatives, make tradeoffs explicit
-
-Codifying design knowledge as patterns
-
-
-
-----
-## Further Readings
-
-
-* 🕮 Lakshmanan, Valliappa, Sara Robinson, and Michael Munn. Machine learning design patterns. O’Reilly Media, 2020.
-* 🗎 Mitchell, Margaret, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. “Model cards for model reporting.” In Proceedings of the conference on fairness, accountability, and transparency, pp. 220–229. 2019.
-* 🗎 Arnold, Matthew, Rachel KE Bellamy, Michael Hind, Stephanie Houde, Sameep Mehta, Aleksandra Mojsilović, Ravi Nair, Karthikeyan Natesan Ramamurthy, Darrell Reimer, Alexandra Olteanu, David Piorkowski, Jason Tsay, and Kush R. Varshney. “FactSheets: Increasing trust in AI services through supplier’s declarations of conformity.” IBM Journal of Research and Development 63, no. 4/5 (2019): 6–1.
-* 🗎 Yokoyama, Haruki. “Machine learning system architectural pattern for improving operational stability.” In 2019 IEEE International Conference on Software Architecture Companion (ICSA-C), pp. 267–274. IEEE, 2019.
-
-
\ No newline at end of file
diff --git a/lectures/09_deploying_a_model/ensemble.svg b/lectures/09_deploying_a_model/ensemble.svg
deleted file mode 100644
index 7be898f2..00000000
--- a/lectures/09_deploying_a_model/ensemble.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/09_deploying_a_model/facebook-flow.png b/lectures/09_deploying_a_model/facebook-flow.png
deleted file mode 100644
index 49989236..00000000
Binary files a/lectures/09_deploying_a_model/facebook-flow.png and /dev/null differ
diff --git a/lectures/09_deploying_a_model/featureencoding.svg b/lectures/09_deploying_a_model/featureencoding.svg
deleted file mode 100644
index 46fe79ba..00000000
--- a/lectures/09_deploying_a_model/featureencoding.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/09_deploying_a_model/gfs.png b/lectures/09_deploying_a_model/gfs.png
deleted file mode 100644
index b60e059d..00000000
Binary files a/lectures/09_deploying_a_model/gfs.png and /dev/null differ
diff --git a/lectures/09_deploying_a_model/googleglasses.jpg b/lectures/09_deploying_a_model/googleglasses.jpg
deleted file mode 100644
index 73e19a59..00000000
Binary files a/lectures/09_deploying_a_model/googleglasses.jpg and /dev/null differ
diff --git a/lectures/09_deploying_a_model/googletranslate.png b/lectures/09_deploying_a_model/googletranslate.png
deleted file mode 100644
index 0d653aa6..00000000
Binary files a/lectures/09_deploying_a_model/googletranslate.png and /dev/null differ
diff --git a/lectures/09_deploying_a_model/lan-boundary.png b/lectures/09_deploying_a_model/lan-boundary.png
deleted file mode 100644
index 6f3abcd8..00000000
Binary files a/lectures/09_deploying_a_model/lan-boundary.png and /dev/null differ
diff --git a/lectures/09_deploying_a_model/microservice.svg b/lectures/09_deploying_a_model/microservice.svg
deleted file mode 100644
index 09cdf95d..00000000
--- a/lectures/09_deploying_a_model/microservice.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/09_deploying_a_model/modelcard.png b/lectures/09_deploying_a_model/modelcard.png
deleted file mode 100644
index f390c256..00000000
Binary files a/lectures/09_deploying_a_model/modelcard.png and /dev/null differ
diff --git a/lectures/09_deploying_a_model/modelcard2.png b/lectures/09_deploying_a_model/modelcard2.png
deleted file mode 100644
index d9ff48c5..00000000
Binary files a/lectures/09_deploying_a_model/modelcard2.png and /dev/null differ
diff --git a/lectures/09_deploying_a_model/observer.png b/lectures/09_deploying_a_model/observer.png
deleted file mode 100644
index 44b26048..00000000
Binary files a/lectures/09_deploying_a_model/observer.png and /dev/null differ
diff --git a/lectures/09_deploying_a_model/pgh-cycling.jpg b/lectures/09_deploying_a_model/pgh-cycling.jpg
deleted file mode 100644
index 7f44fe0a..00000000
Binary files a/lectures/09_deploying_a_model/pgh-cycling.jpg and /dev/null differ
diff --git a/lectures/09_deploying_a_model/pgh-firezones.png b/lectures/09_deploying_a_model/pgh-firezones.png
deleted file mode 100644
index 7ff1cd2a..00000000
Binary files a/lectures/09_deploying_a_model/pgh-firezones.png and /dev/null differ
diff --git a/lectures/09_deploying_a_model/pgh.jpg b/lectures/09_deploying_a_model/pgh.jpg
deleted file mode 100644
index 4286fb9e..00000000
Binary files a/lectures/09_deploying_a_model/pgh.jpg and /dev/null differ
diff --git a/lectures/09_deploying_a_model/req-arch-impl.svg b/lectures/09_deploying_a_model/req-arch-impl.svg
deleted file mode 100644
index 34bea3ff..00000000
--- a/lectures/09_deploying_a_model/req-arch-impl.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/09_deploying_a_model/seoul.jpg b/lectures/09_deploying_a_model/seoul.jpg
deleted file mode 100644
index 7ef85dd7..00000000
Binary files a/lectures/09_deploying_a_model/seoul.jpg and /dev/null differ
diff --git a/lectures/09_deploying_a_model/sequential-model-composition.svg b/lectures/09_deploying_a_model/sequential-model-composition.svg
deleted file mode 100644
index 3fce8495..00000000
--- a/lectures/09_deploying_a_model/sequential-model-composition.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/09_deploying_a_model/shared-feature-encoding.svg b/lectures/09_deploying_a_model/shared-feature-encoding.svg
deleted file mode 100644
index ea221aeb..00000000
--- a/lectures/09_deploying_a_model/shared-feature-encoding.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/09_deploying_a_model/system.svg b/lectures/09_deploying_a_model/system.svg
deleted file mode 100644
index 9d3cfe66..00000000
--- a/lectures/09_deploying_a_model/system.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/09_deploying_a_model/transcriptionarchitecture2.svg b/lectures/09_deploying_a_model/transcriptionarchitecture2.svg
deleted file mode 100644
index 212a40f7..00000000
--- a/lectures/09_deploying_a_model/transcriptionarchitecture2.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/10_qainproduction/ab-button.png b/lectures/10_qainproduction/ab-button.png
deleted file mode 100644
index 94ec0068..00000000
Binary files a/lectures/10_qainproduction/ab-button.png and /dev/null differ
diff --git a/lectures/10_qainproduction/ab-groove.jpg b/lectures/10_qainproduction/ab-groove.jpg
deleted file mode 100644
index f5da8094..00000000
Binary files a/lectures/10_qainproduction/ab-groove.jpg and /dev/null differ
diff --git a/lectures/10_qainproduction/alexa.png b/lectures/10_qainproduction/alexa.png
deleted file mode 100644
index 9adf5327..00000000
Binary files a/lectures/10_qainproduction/alexa.png and /dev/null differ
diff --git a/lectures/10_qainproduction/amazon.png b/lectures/10_qainproduction/amazon.png
deleted file mode 100644
index 16de6074..00000000
Binary files a/lectures/10_qainproduction/amazon.png and /dev/null differ
diff --git a/lectures/10_qainproduction/bookingcom.png b/lectures/10_qainproduction/bookingcom.png
deleted file mode 100644
index 9a77b15a..00000000
Binary files a/lectures/10_qainproduction/bookingcom.png and /dev/null differ
diff --git a/lectures/10_qainproduction/canary.jpg b/lectures/10_qainproduction/canary.jpg
deleted file mode 100644
index 79b6948a..00000000
Binary files a/lectures/10_qainproduction/canary.jpg and /dev/null differ
diff --git a/lectures/10_qainproduction/confint.png b/lectures/10_qainproduction/confint.png
deleted file mode 100644
index adc08b63..00000000
Binary files a/lectures/10_qainproduction/confint.png and /dev/null differ
diff --git a/lectures/10_qainproduction/datarobot.png b/lectures/10_qainproduction/datarobot.png
deleted file mode 100644
index a9a634b4..00000000
Binary files a/lectures/10_qainproduction/datarobot.png and /dev/null differ
diff --git a/lectures/10_qainproduction/drift.jpg b/lectures/10_qainproduction/drift.jpg
deleted file mode 100644
index ff35da56..00000000
Binary files a/lectures/10_qainproduction/drift.jpg and /dev/null differ
diff --git a/lectures/10_qainproduction/flightforcast.jpg b/lectures/10_qainproduction/flightforcast.jpg
deleted file mode 100644
index 74101165..00000000
Binary files a/lectures/10_qainproduction/flightforcast.jpg and /dev/null differ
diff --git a/lectures/10_qainproduction/flywheel.png b/lectures/10_qainproduction/flywheel.png
deleted file mode 100644
index 1bfeed11..00000000
Binary files a/lectures/10_qainproduction/flywheel.png and /dev/null differ
diff --git a/lectures/10_qainproduction/grafana.png b/lectures/10_qainproduction/grafana.png
deleted file mode 100644
index 8bc0a0f7..00000000
Binary files a/lectures/10_qainproduction/grafana.png and /dev/null differ
diff --git a/lectures/10_qainproduction/grafanadashboard.png b/lectures/10_qainproduction/grafanadashboard.png
deleted file mode 100644
index 3ab72059..00000000
Binary files a/lectures/10_qainproduction/grafanadashboard.png and /dev/null differ
diff --git a/lectures/10_qainproduction/kohavi-bing-search.jpg b/lectures/10_qainproduction/kohavi-bing-search.jpg
deleted file mode 100644
index 4400b526..00000000
Binary files a/lectures/10_qainproduction/kohavi-bing-search.jpg and /dev/null differ
diff --git a/lectures/10_qainproduction/mturk.jpg b/lectures/10_qainproduction/mturk.jpg
deleted file mode 100644
index 46519d7b..00000000
Binary files a/lectures/10_qainproduction/mturk.jpg and /dev/null differ
diff --git a/lectures/10_qainproduction/perfcomp.png b/lectures/10_qainproduction/perfcomp.png
deleted file mode 100644
index 92faaf31..00000000
Binary files a/lectures/10_qainproduction/perfcomp.png and /dev/null differ
diff --git a/lectures/10_qainproduction/prometheusarchitecture.png b/lectures/10_qainproduction/prometheusarchitecture.png
deleted file mode 100644
index 1610bc02..00000000
Binary files a/lectures/10_qainproduction/prometheusarchitecture.png and /dev/null differ
diff --git a/lectures/10_qainproduction/qainproduction.md b/lectures/10_qainproduction/qainproduction.md
deleted file mode 100644
index 4aaac7e9..00000000
--- a/lectures/10_qainproduction/qainproduction.md
+++ /dev/null
@@ -1,886 +0,0 @@
----
-author: Christian Kaestner and Eunsuk Kang
-title: "MLiP: Testing in Production"
-semester: Spring 2023
-footer: "Machine Learning in Production/AI Engineering • Christian Kaestner & Eunsuk Kang, Carnegie Mellon University • Spring 2023"
-license: Creative Commons Attribution 4.0 International (CC BY 4.0)
----
-
-
-
-## Machine Learning in Production
-
-# Testing in Production
-
-
----
-
-
-
-
----
-## Back to QA...
-
-
-
-
-
-----
-## Learning Goals
-
-* Design telemetry for evaluation in practice
-* Understand the rationale for beta tests and chaos experiments
-* Plan and execute experiments (chaos, A/B, shadow releases, ...) in production
-* Conduct and evaluate multiple concurrent A/B tests in a system
-* Perform canary releases
-* Examine experimental results with statistical rigor
-* Support data scientists with monitoring platforms providing insights from production data
-
-----
-## Readings
-
-
-Required Reading:
-* 🕮 Hulten, Geoff. "[Building Intelligent Systems: A Guide to Machine Learning Engineering.](https://www.buildingintelligentsystems.com/)" Apress, 2018, Chapters 14 and 15 (Intelligence Management and Intelligent Telemetry).
-
-Suggested Readings:
-* Alec Warner and Štěpán Davidovič. "[Canary Releases](https://landing.google.com/sre/workbook/chapters/canarying-releases/)." in [The Site Reliability Workbook](https://landing.google.com/sre/books/), O'Reilly 2018
-* Kohavi, Ron, Diane Tang, and Ya Xu. "[Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing](https://bookshop.org/books/trustworthy-online-controlled-experiments-a-practical-guide-to-a-b-testing/9781108724265)." Cambridge University Press, 2020.
-
-
-
----
-# From Unit Tests to Testing in Production
-
-*(in traditional software systems)*
-
-----
-## Unit Test, Integration Tests, System Tests
-
-
-
-Note: Testing before release. Manual or automated.
-
-----
-## Beta Testing
-
-
-
-
-Note: Early release to select users, asking them to send feedback or report issues. No telemetry in early days.
-
-----
-## Crash Telemetry
-
-
-
-Note: With internet availability, send crash reports home to identify problems "in production". Most ML-based systems are online in some form and allow telemetry.
-
-----
-## A/B Testing
-
-
-
-Notes: Usage observable online, telemetry allows testing in production. Picture source: https://www.designforfounders.com/ab-testing-examples/
-
-----
-## Chaos Experiments
-
-
-[](https://en.wikipedia.org/wiki/Chaos_engineering)
-
-
-Note: Deliberate introduction of faults in production to test robustness.
-
-
-
-
-
-
-
----
-# Model Assessment in Production
-
-Ultimate held-out evaluation data: Unseen real user data
-
-----
-## Limitations of Offline Model Evaluation
-
-Training and test data drawn from the same population
-* **i.i.d.: independent and identically distributed**
-* leakage and overfitting problems quite common
-
-Is the population representative of production data?
-
-If not or only partially or not anymore: Does the model generalize beyond training data?
-
-
-----
-## Identify Feedback Mechanism in Production
-
-Live observation in the running system
-
-Potentially on subpopulation (A/B testing)
-
-Need telemetry to evaluate quality -- challenges:
-- Gather feedback without being intrusive (i.e., labeling outcomes), without harming user experience
-- Manage amount of data
-- Isolating feedback for specific ML component + version
-
-----
-## Discuss how to collect feedback
-
-* Was the house price predicted correctly?
-* Did the profanity filter remove the right blog comments?
-* Was there cancer in the image?
-* Was a Spotify playlist good?
-* Was the ranking of search results good?
-* Was the weather prediction good?
-* Was the translation correct?
-* Did the self-driving car break at the right moment? Did it detect the pedestriants?
-
-
-
-Notes: More:
-* SmartHome: Does it automatically turn of the lights/lock the doors/close the window at the right time?
-* Profanity filter: Does it block the right blog comments?
-* News website: Does it pick the headline alternative that attracts a user’s attention most?
-* Autonomous vehicles: Does it detect pedestrians in the street?
-
-
-
-----
-
-
-
-
-
-
-
-Notes:
-Expect only sparse feedback and expect negative feedback over-proportionally
-
-----
-
-
-Notes: Can just wait 7 days to see actual outcome for all predictions
-----
-
-
-Notes: Clever UI design allows users to edit transcripts. UI already highlights low-confidence words, can
-
-----
-## Manually Label Production Samples
-
-Similar to labeling learning and testing data, have human annotators
-
-
-
-----
-## Summary: Telemetry Strategies
-
-* Wait and see
-* Ask users
-* Manual/crowd-source labeling, shadow execution
-* Allow users to complain
-* Observe user reaction
-
-
-
-----
-## Breakout: Design Telemetry in Production
-
-Discuss how to collect telemetry (Wait and see, ask users, manual/crowd-source labeling, shadow execution, allow users to complain, observe user reaction)
-
-Scenarios:
-* Front-left: Amazon: Shopping app feature that detects the shoe brand from photos
-* Front-right: Google: Tagging uploaded photos with friends' names
-* Back-left: Spotify: Recommended personalized playlists
-* Back-right: Wordpress: Profanity filter to moderate blog posts
-
-(no need to post in slack yet)
-
-
-
-----
-## Measuring Model Quality with Telemetry
-
-
-
-* Usual 3 steps: (1) Metric, (2) data collection (telemetry), (3) operationalization
-* Telemetry can provide insights for correctness
- - sometimes very accurate labels for real unseen data
- - sometimes only mistakes
- - sometimes delayed
- - often just samples
- - often just weak proxies for correctness
-* Often sufficient to *approximate* precision/recall or other model-quality measures
-* Mismatch to (static) evaluation set may indicate stale or unrepresentative data
-* Trend analysis can provide insights even for inaccurate proxy measures
-
-
-----
-## Breakout: Design Telemetry in Production
-
-
-
-Discuss how to collect telemetry, the metric to monitor, and how to operationalize
-
-Scenarios:
-* Front-left: Amazon: Shopping app detects the shoe brand from photos
-* Front-right: Google: Tagging uploaded photos with friends' names
-* Back-left: Spotify: Recommended personalized playlists
-* Back-right: Wordpress: Profanity filter to moderate blog posts
-
-As a group post to `#lecture` and tag team members:
-> * Quality metric:
-> * Data to collect:
-> * Operationalization:
-
-
-
-----
-## Monitoring Model Quality in Production
-
-* Monitor model quality together with other quality attributes (e.g., uptime, response time, load)
-* Set up automatic alerts when model quality drops
-* Watch for jumps after releases
- - roll back after negative jump
-* Watch for slow degradation
- - Stale models, data drift, feedback loops, adversaries
-* Debug common or important problems
- - Monitor characteristics of requests
- - Mistakes uniform across populations?
- - Challenging problems -> refine training, add regression tests
-
-----
-
-
-----
-## Prometheus and Grafana
-
-[](https://prometheus.io/docs/introduction/overview/)
-
-
-----
-
-
-
-----
-## Many commercial solutions
-
-[](https://www.datarobot.com/platform/mlops/)
-
-
-
-e.g. https://www.datarobot.com/platform/mlops/
-
-Many pointers: Ori Cohen "[Monitor! Stop Being A Blind Data-Scientist.](https://towardsdatascience.com/monitor-stop-being-a-blind-data-scientist-ac915286075f)" Blog 2019
-
-
-----
-## Detecting Drift
-
-
-
-
-Image source: Joel Thomas and Clemens Mewald. [Productionizing Machine Learning: From Deployment to Drift Detection](https://databricks.com/blog/2019/09/18/productionizing-machine-learning-from-deployment-to-drift-detection.html). Databricks Blog, 2019
-
-----
-## Engineering Challenges for Telemetry
-
-
-----
-## Engineering Challenges for Telemetry
-* Data volume and operating cost
- - e.g., record "all AR live translations"?
- - reduce data through sampling
- - reduce data through summarization (e.g., extracted features rather than raw data; extraction client vs server side)
-* Adaptive targeting
-* Biased sampling
-* Rare events
-* Privacy
-* Offline deployments?
-
-----
-## Breakout: Engineering Challenges in Telemetry
-
-Discuss: Cost, privacy, rare events, bias
-
-Scenarios:
-* Front-left: Amazon: Shopping app feature that detects the shoe brand from photos
-* Front-right: Google: Tagging uploaded photos with friends' names
-* Back-left: Spotify: Recommended personalized playlists
-* Back-right: Wordpress: Profanity filter to moderate blog posts
-
-
-(can update slack, but not needed)
-
-
----
-# Telemetry for Training: The ML Flywheel
-
-----
-
-
-
-
-
-
- graphic by [CBInsights](https://www.cbinsights.com/research/team-blog/data-network-effects/)
-
-
----
-# Revisiting Model Quality vs System Goals
-
-----
-## Model Quality vs System Goals
-
-Telemetry can approximate model accuracy
-
-Telemetry can directly measure system qualities, leading indicators, user outcomes
-- define measures for "key performance indicators"
-- clicks, buys, signups, engagement time, ratings
-- operationalize with telemetry
-
-----
-## Model Quality vs System Quality
-
-
-
-
-
-Bernardi, Lucas, et al. "150 successful machine learning models: 6 lessons learned at Booking.com." In Proc. Int'l Conf. Knowledge Discovery & Data Mining, 2019.
-
-----
-## Possible causes of model vs system conflict?
-
-
-
-
-
-
-
-
-Bernardi, Lucas, et al. "150 successful machine learning models: 6 lessons learned at Booking.com." In Proc. Int'l Conf. Knowledge Discovery & Data Mining, 2019.
-
-
-Note: hypothesized
-* model value saturated, little more value to be expected
-* segment saturation: only very few users benefit from further improvement
-* overoptimization on proxy metrics not real target metrics
-* uncanny valley effect from "creepy AIs"
-
-----
-## Breakout: Design Telemetry in Production
-
-Discuss: What key performance indicator of the *system* to collect?
-
-Scenarios:
-* Front-left: Amazon: Shopping app feature that detects the shoe brand from photos
-* Front-right: Google: Tagging uploaded photos with friends' names
-* Back-left: Spotify: Recommended personalized playlists
-* Back-right: Wordpress: Profanity filter to moderate blog posts
-
-
-(can update slack, but not needed)
-
-
----
-# Experimenting in Production
-
-* A/B experiments
-* Shadow releases / traffic teeing
-* Blue/green deployment
-* Canary releases
-* Chaos experiments
-
-
-----
-
-
-
----
-# A/B Experiments
-----
-## What if...?
-
-
-
-* ... we hand plenty of subjects for experiments
-* ... we could randomly assign to treatment and control group without them knowing
-* ... we could analyze small individual changes and keep everything else constant
-
-
-▶ Ideal conditions for controlled experiments
-
-
-
-
-
-
-
-----
-## A/B Testing for Usability
-
-* In running system, random users are shown modified version
-* Outcomes (e.g., sales, time on site) compared among groups
-
-
-
-
-
-Notes: Picture source: https://www.designforfounders.com/ab-testing-examples/
-
-
-----
-
-
-
-
-
-
-
-## Bing Experiment
-
-* Experiment: Ad Display at Bing
-* Suggestion prioritzed low
-* Not implemented for 6 month
-* Ran A/B test in production
-* Within 2h *revenue-too-high* alarm triggered suggesting serious bug (e.g., double billing)
-* Revenue increase by 12% - $100M anually in US
-* Did not hurt user-experience metrics
-
-
-
-
-
-From: Kohavi, Ron, Diane Tang, and Ya Xu. "[Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing](https://bookshop.org/books/trustworthy-online-controlled-experiments-a-practical-guide-to-a-b-testing/9781108724265)." 2020.
-
-
-
-
-
-
-----
-## A/B Experiment for ML Components?
-
-* New product recommendation algorithm for web store?
-* New language model in audio transcription service?
-* New (offline) model to detect falls on smart watch
-
-
-
-----
-## Experiment Size
-
-With enough subjects (users), we can run many many experiments
-
-Even very small experiments become feasible
-
-Toward causal inference
-
-
-
-
-
-----
-
-## Implementing A/B Testing
-
-Implement alternative versions of the system
-* using feature flags (decisions in implementation)
-* separate deployments (decision in router/load balancer)
-
-Map users to treatment group
-* Randomly from distribution
-* Static user - group mapping
-* Online service (e.g., [launchdarkly](https://launchdarkly.com/), [split](https://www.split.io/))
-
-Monitor outcomes *per group*
-* Telemetry, sales, time on site, server load, crash rate
-
-----
-## Feature Flags (Boolean flags)
-
-
-
-```java
-if (features.enabled(userId, "one_click_checkout")) {
- // new one click checkout function
-} else {
- // old checkout functionality
-}
-```
-
-* Good practices: tracked explicitly, documented, keep them localized and independent
-* External mapping of flags to customers, who should see what configuration
- * e.g., 1% of users sees `one_click_checkout`, but always the same users; or 50% of beta-users and 90% of developers and 0.1% of all users
-
-```scala
-def isEnabled(user): Boolean = (hash(user.id) % 100) < 10
-```
-
-
-
-----
-
-
-
-
-
-
-
-
----
-# Confidence in A/B Experiments
-
-(statistical tests)
-
-----
-
-## Comparing Averages
-
-
-**Group A**
-
-*classic personalized content recommendation model*
-
-2158 Users
-
-average 3:13 min time on site
-
-
-
-**Group B**
-
-*updated personalized content recommendation model*
-
-10 Users
-
-average 3:24 min time on site
-
-
-----
-## Comparing Distributions
-
-
-
-
-----
-## Different effect size, same deviations
-
-
-
-
-
-
-
-----
-## Same effect size, different deviations
-
-
-
-
-
-
-
-Less noise --> Easier to recognize
-
-
-
-----
-
-## Dependent vs. independent measurements
-
-Pairwise (dependent) measurements
-* Before/after comparison
-* With same benchmark + environment
-* e.g., new operating system/disc drive faster
-
-Independent measurements
-* Repeated measurements
-* Input data regenerated for each measurement
-
-----
-## Significance level
-* Statistical change of an error
-* Define before executing the experiment
- * use commonly accepted values
- * based on cost of a wrong decision
-* Common:
- * 0.05 significant
- * 0.01 very significant
-* Statistically significant result ⇏ proof
-* Statistically significant result ⇏ important result
-* Covers only alpha error (more later)
-
-----
-
-## Intuition: Error Model
-* 1 random error, influence +/- 1
-* Real mean: 10
-* Measurements: 9 (50%) und 11 (50%)
-*
-* 2 random errors, each +/- 1
-* Measurements: 8 (25%), 10 (50%) und 12 (25%)
-*
-* 3 random errors, each +/- 1
-* Measurements : 7 (12.5%), 9 (37.5), 11 (37.5), 12 (12.5)
-----
-
-----
-## Normal Distribution
-
-
-
-
-
-(CC 4.0 [D Wells](https://commons.wikimedia.org/wiki/File:Standard_Normal_Distribution.png))
-----
-## Confidence Intervals
-
-----
-## Comparison with Confidence Intervals
-_
-
-
-
-
-Source: Andy Georges, et al. 2007. [Statistically rigorous java performance evaluation](https://dri.es/files/oopsla07-georges.pdf). In Proc. Conference on Object-Oriented Programming Systems and Applications.
-----
-# t-test
-
-```r
-> t.test(x, y, conf.level=0.9)
-
- Welch Two Sample t-test
-
-t = 1.9988, df = 95.801, p-value = 0.04846
-alternative hypothesis: true difference in means is
-not equal to 0
-90 percent confidence interval:
- 0.3464147 3.7520619
-sample estimates:
-mean of x mean of y
- 51.42307 49.37383
-
-> # paired t-test:
-> t.test(x-y, conf.level=0.9)
-```
-----
-
-
-
-
-Source: https://conversionsciences.com/ab-testing-statistics/
-----
-
-
-
-
-Source: https://cognetik.com/why-you-should-build-an-ab-test-dashboard/
-----
-## How many samples needed?
-
-**Too few?**
-
-
-
-**Too many?**
-
-
-
-
-
-
-
----
-# A/B testing automation
-
-* Experiment configuration through DSLs/scripts
-* Queue experiments
-* Stop experiments when confident in results
-* Stop experiments resulting in bad outcomes (crashes, very low sales)
-* Automated reporting, dashboards
-
-
-
-Further readings:
-* Tang, Diane, et al. [Overlapping experiment infrastructure: More, better, faster experimentation](https://ai.google/research/pubs/pub36500.pdf). Proc. KDD, 2010. (Google)
-* Bakshy, Eytan et al. [Designing and deploying online field experiments](https://arxiv.org/pdf/1409.3174). Proc. WWW, 2014. (Facebook)
-----
-## DSL for scripting A/B tests at Facebook
-```java
-button_color = uniformChoice(
- choices=['#3c539a', '#5f9647', '#b33316'],
- unit=cookieid);
-
-button_text = weightedChoice(
- choices=['Sign up', 'Join now'],
- weights=[0.8, 0.2],
- unit=cookieid);
-
-if (country == 'US') {
- has_translate = bernoulliTrial(p=0.2, unit=userid);
-} else {
- has_translate = bernoulliTrial(p=0.05, unit=userid);
-}
-```
-
-
-Further readings: Bakshy, Eytan et al. [Designing and deploying online field experiments](https://arxiv.org/pdf/1409.3174). Proc. WWW, 2014. (Facebook)
-
-----
-## Concurrent A/B testing
-
-Multiple experiments at the same time
- * Independent experiments on different populations -- interactions not explored
- * Multi-factorial designs, well understood but typically too complex, e.g., not all combinations valid or interesting
- * Grouping in sets of experiments (layers)
-
-
-
-Further readings:
-* Tang, Diane, et al. [Overlapping experiment infrastructure: More, better, faster experimentation](https://ai.google/research/pubs/pub36500.pdf). Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2010.
-* Bakshy, Eytan, Dean Eckles, and Michael S. Bernstein. [Designing and deploying online field experiments](https://arxiv.org/pdf/1409.3174). Proceedings of the 23rd International Conference on World Wide Web. ACM, 2014.
-
-
-
----
-# Other Experiments in Production
-
-Shadow releases / traffic teeing
-
-Blue/green deployment
-
-Canary releases
-
-Chaos experiments
-
-
-----
-## Shadow releases / traffic teeing
-
-Run both models in parallel
-
-Use predictions of old model in production
-
-Compare differences between model predictions
-
-If possible, compare against ground truth labels/telemetry
-
-**Examples?**
-
-----
-## Blue/green deployment
-
-Provision service both with old and new model (e.g., services)
-
-Support immediate switch with load-balancer
-
-Allows to undo release rapidly
-
-**Advantages/disadvantages?**
-
-----
-## Canary Releases
-
-
-
-Release new version to small percentage of population (like A/B testing)
-
-Automatically roll back if quality measures degrade
-
-Automatically and incrementally increase deployment to 100% otherwise
-
-
-
-
-
-
-
-
-----
-## Chaos Experiments
-
-[](https://en.wikipedia.org/wiki/Chaos_engineering)
-
-
-----
-## Chaos Experiments for ML Components?
-
-
-
-Note: Artifically reduce model quality, add delays, insert bias, etc to test monitoring and alerting infrastructure
-
-
-----
-## Advice for Experimenting in Production
-
-Minimize *blast radius* (canary, A/B, chaos expr)
-
-Automate experiments and deployments
-
-Allow for quick rollback of poor models (continuous delivery, containers, loadbalancers, versioning)
-
-Make decisions with confidence, compare distributions
-
-Monitor, monitor, monitor
-
-
-
-
----
-# Bonus: Monitoring without Ground Truth
-
-----
-## Invariants/Assertions to Assure with Telemetry
-
-
-
-* Consistency between multiple sources
- * e.g., multiple models agree, multiple sensors agree
- * e.g., text and image agree
-* Physical domain knowledge
- * e.g., cars in video shall not flicker,
- * e.g., earthquakes should appear in sensors grouped by geography
-* Domain knowledge about unlikely events
- - e.g., unlikely to have 3 cars in same location
-* Stability
- * e.g., object detection should not change with video noise
-* Input conforms to schema (e.g. boolean features)
-* And all invariants from model quality lecture, including capabilities
-
-
-
-
-
-Kang, Daniel, et al. "Model Assertions for Monitoring and Improving ML Model." Proc. MLSys 2020.
-
----
-# Summary
-
-Production data is ultimate unseen validation data
-
-Both for model quality and system quality
-
-Telemetry is key and challenging (design problem and opportunity)
-
-Monitoring and dashboards
-
-Many forms of experimentation and release (A/B testing, shadow releases, canary releases, chaos experiments, ...) to minimize "blast radius";
-gain confidence in results with statistical tests
-
-----
-
-## Further Readings
-
-
-
-* On canary releases: Alec Warner and Štěpán Davidovič. “[Canary Releases](https://landing.google.com/sre/workbook/chapters/canarying-releases/).” in[ The Site Reliability Workbook](https://landing.google.com/sre/books/), O’Reilly 2018
-* Everything on A/B testing: Kohavi, Ron. [*Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing*](https://bookshop.org/books/trustworthy-online-controlled-experiments-a-practical-guide-to-a-b-testing/9781108724265). Cambridge University Press, 2020.
-* A/B testing critiques: Josh Constine. [The Morality Of A/B Testing](https://techcrunch.com/2014/06/29/ethics-in-a-data-driven-world/). Blog 2014; the [Center of Humane Technology](https://www.humanetech.com/); and the Netflix documentary [The Social Dilemma](https://en.wikipedia.org/wiki/The_Social_Dilemma)
-* Ori Cohen “[Monitor! Stop Being A Blind Data-Scientist.](https://towardsdatascience.com/monitor-stop-being-a-blind-data-scientist-ac915286075f)” Blog 2019
-* Jens Meinicke, Chu-Pan Wong, Bogdan Vasilescu, and Christian Kästner.[ Exploring Differences and Commonalities between Feature Flags and Configuration Options](https://www.cs.cmu.edu/~ckaestne/pdf/icseseip20.pdf). In Proceedings of the Proc. International Conference on Software Engineering ICSE-SEIP, pages 233–242, May 2020.
-
\ No newline at end of file
diff --git a/lectures/10_qainproduction/simianarmy.jpg b/lectures/10_qainproduction/simianarmy.jpg
deleted file mode 100644
index 8a1f2bbe..00000000
Binary files a/lectures/10_qainproduction/simianarmy.jpg and /dev/null differ
diff --git a/lectures/10_qainproduction/skype1.jpg b/lectures/10_qainproduction/skype1.jpg
deleted file mode 100644
index a5dd482d..00000000
Binary files a/lectures/10_qainproduction/skype1.jpg and /dev/null differ
diff --git a/lectures/10_qainproduction/skype2.jpg b/lectures/10_qainproduction/skype2.jpg
deleted file mode 100644
index 76110b4b..00000000
Binary files a/lectures/10_qainproduction/skype2.jpg and /dev/null differ
diff --git a/lectures/10_qainproduction/splitio.png b/lectures/10_qainproduction/splitio.png
deleted file mode 100644
index be09513a..00000000
Binary files a/lectures/10_qainproduction/splitio.png and /dev/null differ
diff --git a/lectures/10_qainproduction/temi.png b/lectures/10_qainproduction/temi.png
deleted file mode 100644
index 29ce2dd5..00000000
Binary files a/lectures/10_qainproduction/temi.png and /dev/null differ
diff --git a/lectures/10_qainproduction/testexample.png b/lectures/10_qainproduction/testexample.png
deleted file mode 100644
index 031680a1..00000000
Binary files a/lectures/10_qainproduction/testexample.png and /dev/null differ
diff --git a/lectures/10_qainproduction/testexample2.png b/lectures/10_qainproduction/testexample2.png
deleted file mode 100644
index d9e3c26e..00000000
Binary files a/lectures/10_qainproduction/testexample2.png and /dev/null differ
diff --git a/lectures/10_qainproduction/testinglevels.png b/lectures/10_qainproduction/testinglevels.png
deleted file mode 100644
index dee6a0ea..00000000
Binary files a/lectures/10_qainproduction/testinglevels.png and /dev/null differ
diff --git a/lectures/10_qainproduction/twodist.png b/lectures/10_qainproduction/twodist.png
deleted file mode 100644
index 824de1b6..00000000
Binary files a/lectures/10_qainproduction/twodist.png and /dev/null differ
diff --git a/lectures/10_qainproduction/twodisteffect.png b/lectures/10_qainproduction/twodisteffect.png
deleted file mode 100644
index af55637d..00000000
Binary files a/lectures/10_qainproduction/twodisteffect.png and /dev/null differ
diff --git a/lectures/10_qainproduction/twodistnoise.png b/lectures/10_qainproduction/twodistnoise.png
deleted file mode 100644
index f67ba07b..00000000
Binary files a/lectures/10_qainproduction/twodistnoise.png and /dev/null differ
diff --git a/lectures/10_qainproduction/wincrashreport_windows_xp.png b/lectures/10_qainproduction/wincrashreport_windows_xp.png
deleted file mode 100644
index e6e28968..00000000
Binary files a/lectures/10_qainproduction/wincrashreport_windows_xp.png and /dev/null differ
diff --git a/lectures/10_qainproduction/windowsbeta.jpg b/lectures/10_qainproduction/windowsbeta.jpg
deleted file mode 100644
index 32ca1457..00000000
Binary files a/lectures/10_qainproduction/windowsbeta.jpg and /dev/null differ
diff --git a/lectures/11_dataquality/Accuracy_and_Precision.svg b/lectures/11_dataquality/Accuracy_and_Precision.svg
deleted file mode 100644
index a1f66057..00000000
--- a/lectures/11_dataquality/Accuracy_and_Precision.svg
+++ /dev/null
@@ -1,2957 +0,0 @@
-
-
-
-
diff --git a/lectures/11_dataquality/amazon-hiring.png b/lectures/11_dataquality/amazon-hiring.png
deleted file mode 100644
index 94822f89..00000000
Binary files a/lectures/11_dataquality/amazon-hiring.png and /dev/null differ
diff --git a/lectures/11_dataquality/data-explosion.png b/lectures/11_dataquality/data-explosion.png
deleted file mode 100644
index f03b202f..00000000
Binary files a/lectures/11_dataquality/data-explosion.png and /dev/null differ
diff --git a/lectures/11_dataquality/datacascades.png b/lectures/11_dataquality/datacascades.png
deleted file mode 100644
index d3b31f9e..00000000
Binary files a/lectures/11_dataquality/datacascades.png and /dev/null differ
diff --git a/lectures/11_dataquality/dataquality.md b/lectures/11_dataquality/dataquality.md
deleted file mode 100644
index 396565e0..00000000
--- a/lectures/11_dataquality/dataquality.md
+++ /dev/null
@@ -1,1115 +0,0 @@
----
-author: Eunsuk Kang and Christian Kaestner
-title: "MLiP: Data Quality"
-semester: Spring 2023
-footer: "Machine Learning in Production/AI Engineering • Eunsuk Kang & Christian Kaestner, Carnegie Mellon University • Spring 2023"
-license: Creative Commons Attribution 4.0 International (CC BY 4.0)
----
-
-
-
-## Machine Learning in Production
-
-
-# Data Quality
-
-
-
-
----
-# Midterm
-
-One week from today, here
-
-Questions based on shared scenario, apply concepts
-
-Past midterms [online](https://github.com/mlip-cmu/s2023/tree/main/exams), similar style
-
-All lectures and readings in scope, focus on concepts with opportunity to practice (e.g., recitations, homeworks, in-class exercises)
-
-Closed book, but 6 sheets of notes (sorry, no ChatGPT)
-
-
----
-## More Quality Assurance...
-
-
-
-
-
-
-----
-## Readings
-
-Required reading:
-* Sambasivan, N., Kapania, S., Highfill, H., Akrong, D., Paritosh, P., & Aroyo, L. M. (2021, May). “[Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI](https://dl.acm.org/doi/abs/10.1145/3411764.3445518). In Proc. Conference on Human Factors in Computing Systems (pp. 1-15).
-
-
-
-Recommended reading:
-* Schelter, S., et al. [Automating large-scale data quality verification](http://www.vldb.org/pvldb/vol11/p1781-schelter.pdf). Proceedings of the VLDB Endowment, 11(12), pp.1781-1794.
-
-
-
-----
-
-## Learning Goals
-
-* Distinguish precision and accuracy; understanding the better models vs more data tradeoffs
-* Use schema languages to enforce data schemas
-* Design and implement automated quality assurance steps that check data schema conformance and distributions
-* Devise infrastructure for detecting data drift and schema violations
-* Consider data quality as part of a system; design an organization that values data quality
-
-
----
-# Poor Data Quality has Consequences
-
-(often delayed, hard-to-fix consequences)
-
-----
-
-
-
-
-
-Image source: https://medium.com/@melodyucros/ladyboss-heres-why-you-should-study-big-data-721b04b8a0ca
-
-----
-
-
-
-
-----
-## GIGO: Garbage in, garbage out
-
-
-
-
-
-Image source: https://monkeylearn.com/blog/data-cleaning-python
-
-----
-## Example: Systematic bias in labeling
-
-Poor data quality leads to poor models
-
-Often not detectable in offline evaluation - **Q. why not**?
-
-Causes problems in production - now difficult to correct
-
-
-
-----
-## Delayed Fixes increase Repair Cost
-
-
-
-
-----
-## Data Cascades
-
-
-
-Detection almost always delayed! Expensive rework.
-Difficult to detect in offline evaluation.
-
-
-Sambasivan, N., et al. (2021, May). “[Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI](https://dl.acm.org/doi/abs/10.1145/3411764.3445518). In Proc. CHI (pp. 1-15).
-
-
-
----
-
-# Data-Quality Challenges
-
-----
-
-> Data cleaning and repairing account for about 60% of the work of data scientists.
-
-
-**Own experience?**
-
-
-
-Quote: Gil Press. “[Cleaning Big Data: Most Time-Consuming, Least Enjoyable Data Science Task, Survey Says](https://www.forbes.com/sites/gilpress/2016/03/23/data-preparation-most-time-consuming-least-enjoyable-data-science-task-survey-says/).” Forbes Magazine, 2016.
-
-
-----
-## Case Study: Inventory Management
-
-
-
-
-Goal: Train an ML model to predict future sales; make decisions about what to (re)stock/when/how many...
-
-----
-## Data Comes from Many Sources
-
-Manually entered
-
-Generated through actions in IT systems
-
-Logging information, traces of user interactions
-
-Sensor data
-
-Crowdsourced
-
-
-----
-## Many Data Sources
-
-
-
-*sources of different reliability and quality*
-
-
-----
-## Inventory Database
-
-
-
-Product Database:
-
-| ID | Name | Weight | Description | Size | Vendor |
-| - | - | - | - | - | - |
-| ... | ... | ... | ... | ... | ... |
-
-Stock:
-
-| ProductID | Location | Quantity |
-| - | - | - |
-| ... | ... | ... |
-
-Sales history:
-
-| UserID | ProductId | DateTime | Quantity | Price |
-| - | - | - | - |- |
-| ... | ... | ... |... |... |
-
-
-
-----
-## *Raw Data* is an Oxymoron
-
-
-
-
-
-
-
-Recommended Reading: Gitelman, Lisa, Virginia Jackson, Daniel Rosenberg, Travis D. Williams, Kevin R. Brine, Mary Poovey, Matthew Stanley et al. "[Data bite man: The work of sustaining a long-term study](https://ieeexplore.ieee.org/abstract/document/6462156)." In "Raw Data" Is an Oxymoron, (2013), MIT Press: 147-166.
-
-----
-## What makes good quality data?
-
-**Accuracy:** The data was recorded correctly.
-
-**Completeness:** All relevant data was recorded.
-
-**Uniqueness:** The entries are recorded once.
-
-**Consistency:** The data agrees with itself.
-
-**Timeliness:** The data is kept up to date.
-
-----
-## Data is noisy
-
-Unreliable sensors or data entry
-
-Wrong results and computations, crashes
-
-Duplicate data, near-duplicate data
-
-Out of order data
-
-Data format invalid
-
-**Examples in inventory system?**
-
-----
-## Data changes
-
-System objective changes over time
-
-Software components are upgraded or replaced
-
-Prediction models change
-
-Quality of supplied data changes
-
-User behavior changes
-
-Assumptions about the environment no longer hold
-
-**Examples in inventory system?**
-
-----
-## Users may deliberately change data
-
-Users react to model output; causes data shift (more later)
-
-Users try to game/deceive the model
-
-**Examples in inventory system?**
-
-----
-## Accuracy vs Precision
-
-
-
-Accuracy: Reported values (on average) represent real value
-
-Precision: Repeated measurements yield the same result
-
-Accurate, but imprecise: **Q. How to deal with this issue?**
-
-Inaccurate, but precise: ?
-
-
-
-
-
-
-
-
-
-
-(CC-BY-4.0 by [Arbeck](https://commons.wikimedia.org/wiki/File:Accuracy_and_Precision.svg))
-
-
-----
-
-## Accuracy and Precision Problems in Warehouse Data?
-
-
-
-
-
-----
-## Data Quality and Machine Learning
-
-More data -> better models (up to a point, diminishing effects)
-
-Noisy data (imprecise) -> less confident models, more data needed
- * some ML techniques are more or less robust to noise (more on robustness in a later lecture)
-
-Inaccurate data -> misleading models, biased models
-
--> Need the "right" data
-
--> Invest in data quality, not just quantity
-
-
-
-
-
-
-
----
-
-# Data Schema
-
-Ensuring basic consistency about shape and types
-
-
-----
-## Dirty Data: Example
-
-
-
-
-*Problems with this data?*
-
-
-
-----
-## Data Quality Problems
-
-
-
-
-* Schema-level: Generic, domain-independent issues in data
-* Instance-level: Application- and domain-specific
-
-
-
-Source: Rahm, Erhard, and Hong Hai Do. [Data cleaning: Problems and current approaches](http://dc-pubs.dbs.uni-leipzig.de/files/Rahm2000DataCleaningProblemsand.pdf). IEEE Data Eng. Bull. 23.4 (2000): 3-13.
-
-
-----
-## Data Schema
-
-Define the expected format of data
- * expected fields and their types
- * expected ranges for values
- * constraints among values (within and across sources)
-
-Data can be automatically checked against schema
-
-Protects against change; explicit interface between components
-
-
-----
-## Schema Problems: Uniqueness, data format, integrity, ...
-
-* Illegal attribute values: `bdate=30.13.70`
-* Violated attribute dependencies: `age=22, bdate=12.02.70`
-* Uniqueness violation: `(name=”John Smith”, SSN=”123456”), (name=”Peter Miller”, SSN=”123456”)`
-* Referential integrity violation: `emp=(name=”John Smith”, deptno=127)` if department 127 not defined
-
-
-
-Further readings: Rahm, Erhard, and Hong Hai Do. [Data cleaning: Problems and current approaches](http://dc-pubs.dbs.uni-leipzig.de/files/Rahm2000DataCleaningProblemsand.pdf). IEEE Data Eng. Bull. 23.4 (2000): 3-13.
-
-
-
-
-
-----
-## Schema in Relational Databases
-
-```sql
-CREATE TABLE employees (
- emp_no INT NOT NULL,
- birth_date DATE NOT NULL,
- name VARCHAR(30) NOT NULL,
- PRIMARY KEY (emp_no));
-CREATE TABLE departments (
- dept_no CHAR(4) NOT NULL,
- dept_name VARCHAR(40) NOT NULL,
- PRIMARY KEY (dept_no), UNIQUE KEY (dept_name));
-CREATE TABLE dept_manager (
- dept_no CHAR(4) NOT NULL,
- emp_no INT NOT NULL,
- FOREIGN KEY (emp_no) REFERENCES employees (emp_no),
- FOREIGN KEY (dept_no) REFERENCES departments (dept_no),
- PRIMARY KEY (emp_no,dept_no));
-```
-
-
-----
-## Which Problems are Schema Problems?
-
-
-
-
-
-----
-## What Happens When New Data Violates Schema?
-
-
-
-
-----
-## Modern Databases: Schema-Less
-
-
-
-
-
-Image source: https://www.kdnuggets.com/2021/05/nosql-know-it-all-compendium.html
-
-----
-## Schema-Less Data Exchange
-
-* CSV files
-* Key-value stores (JSon, XML, Nosql databases)
-* Message brokers
-* REST API calls
-* R/Pandas Dataframes
-
-```
-2022-10-06T01:31:18,230550,GET /rate/narc+2002=4
-2022-10-06T01:31:19,332644,GET /rate/i+am+love+2009=4
-```
-
-```json
-{"user_id":5,"age":26,"occupation":"scientist","gender":"M"}
-```
-
-----
-## Schema-Less Data Exchange
-
-**Q. Benefits? Drawbacks?**
-
-----
-## Schema Library: Apache Avro
-
-```json
-{ "type": "record",
- "namespace": "com.example",
- "name": "Customer",
- "fields": [{
- "name": "first_name",
- "type": "string",
- "doc": "First Name of Customer"
- },
- {
- "name": "age",
- "type": "int",
- "doc": "Age at the time of registration"
- }
- ]
-}
-```
-
-----
-## Schema Library: Apache Avro
-
-
-
-
-
-Schema specification in JSON format
-
-Serialization and deserialization with automated checking
-
-Native support in Kafka
-
-
-
-Benefits
- * Serialization in space efficient format
- * APIs for most languages (ORM-like)
- * Versioning constraints on schemas
-
-Drawbacks
- * Reading/writing overhead
- * Binary data format, extra tools needed for reading
- * Requires external schema and maintenance
- * Learning overhead
-
-
-
-
-
-Notes: Further readings eg https://medium.com/@stephane.maarek/introduction-to-schemas-in-apache-kafka-with-the-confluent-schema-registry-3bf55e401321, https://www.confluent.io/blog/avro-kafka-data/, https://avro.apache.org/docs/current/
-
-----
-## Many Schema Libraries/Formats
-
-Examples
-* Avro
-* XML Schema
-* Protobuf
-* Thrift
-* Parquet
-* ORC
-
-----
-## Discussion: Data Schema Constraints for Inventory System?
-
-
-
-Product Database:
-
-| ID | Name | Weight | Description | Size | Vendor |
-| - | - | - | - | - | - |
-| ... | ... | ... | ... | ... | ... |
-
-Stock:
-
-| ProductID | Location | Quantity |
-| - | - | - |
-| ... | ... | ... |
-
-Sales history:
-
-| UserID | ProductId | DateTime | Quantity | Price |
-| - | - | - | - |- |
-| ... | ... | ... |... |... |
-
-
-
-----
-## Summary: Schema
-
-Basic structure and type definition of data
-
-Well supported in databases and many tools
-
-*Very low bar of data quality*
-
-
-
-
-
-
-
-
-
----
-# Instance-Level Problems
-
-Application- and domain-specific data issues
-
-----
-## Dirty Data: Example
-
-
-
-
-*Problems with the data beyond schema problems?*
-
-
-----
-## Instance-Level Problems
-
-
-* Missing values: `phone=9999-999999`
-* Misspellings: `city=Pittsburg`
-* Misfielded values: `city=USA`
-* Duplicate records: `name=John Smith, name=J. Smith`
-* Wrong reference: `emp=(name=”John Smith”, deptno=127)` if department 127 defined but wrong
-
-**Q. How can we detect and fix these problems?**
-
-
-
-
-Further readings: Rahm, Erhard, and Hong Hai Do. [Data cleaning: Problems and current approaches](http://dc-pubs.dbs.uni-leipzig.de/files/Rahm2000DataCleaningProblemsand.pdf). IEEE Data Eng. Bull. 23.4 (2000): 3-13.
-
-
-----
-## Discussion: Instance-Level Problems?
-
-
-
-
-
-----
-## Data Cleaning Overview
-
-Data analysis / Error detection
- * Usually focused on specific kind of problems, e.g., duplication, typos, missing values, distribution shift
- * Detection in input data vs detection in later stages (more context)
-
-Error repair
- * Repair data vs repair rules, one at a time or holistic
- * Data transformation or mapping
- * Automated vs human guided
-
-----
-## Error Detection Examples
-
-Illegal values: min, max, variance, deviations, cardinality
-
-Misspelling: sorting + manual inspection, dictionary lookup
-
-Missing values: null values, default values
-
-Duplication: sorting, edit distance, normalization
-
-----
-## Error Detection: Example
-
-
-
-
-*Can we (automatically) detect instance-level problems? Which problems are domain-specific?*
-
-
-----
-## Example Tool: Great Expectations
-
-```python
-expect_column_values_to_be_between(
- column="passenger_count",
- min_value=1,
- max_value=6
-)
-```
-
-Supports schema validation and custom instance-level checks.
-
-
-https://greatexpectations.io/
-
-
-----
-## Example Tool: Great Expectations
-
-
-
-
-
-
-https://greatexpectations.io/
-
-
-----
-## Data Quality Rules
-
-Invariants on data that must hold
-
-Typically about relationships of multiple attributes or data sources, eg.
- - ZIP code and city name should correspond
- - User ID should refer to existing user
- - SSN should be unique
- - For two people in the same state, the person with the lower income should not have the higher tax rate
-
-Classic integrity constraints in databases or conditional constraints
-
-*Rules can be used to reject data or repair it*
-
-----
-## ML for Detecting Inconsistencies
-
-
-
-
-
-Image source: Theo Rekatsinas, Ihab Ilyas, and Chris Ré, “[HoloClean - Weakly Supervised Data Repairing](https://dawn.cs.stanford.edu/2017/05/12/holoclean/).” Blog, 2017.
-
-----
-## Example: HoloClean
-
-
-
-
-
-
-* User provides rules as integrity constraints (e.g., "two entries with the same
-name can't have different city")
-* Detect violations of the rules in the data; also detect statistical outliers
-* Automatically generate repair candidates (with probabilities)
-
-
-
-Image source: Theo Rekatsinas, Ihab Ilyas, and Chris Ré, “[HoloClean - Weakly Supervised Data Repairing](https://dawn.cs.stanford.edu/2017/05/12/holoclean/).” Blog, 2017.
-
-----
-## Discovery of Data Quality Rules
-
-
-
-
-
-Rules directly taken from external databases
- * e.g. zip code directory
-
-Given clean data,
- * several algorithms that find functional relationships ($X\Rightarrow Y$) among columns
- * algorithms that find conditional relationships (if $Z$ then $X\Rightarrow Y$)
- * algorithms that find denial constraints ($X$ and $Y$ cannot co-occur in a row)
-
-
-Given mostly clean data (probabilistic view),
- * algorithms to find likely rules (e.g., association rule mining)
- * outlier and anomaly detection
-
-Given labeled dirty data or user feedback,
- * supervised and active learning to learn and revise rules
- * supervised learning to learn repairs (e.g., spell checking)
-
-
-
-
-
-Further reading: Ilyas, Ihab F., and Xu Chu. [Data cleaning](https://dl.acm.org/doi/book/10.1145/3310205). Morgan & Claypool, 2019.
-
-----
-## Excursion: Association rule mining
-
-
-
-* Sale 1: Bread, Milk
-* Sale 2: Bread, Diaper, Beer, Eggs
-* Sale 3: Milk, Diaper, Beer, Coke
-* Sale 4: Bread, Milk, Diaper, Beer
-* Sale 5: Bread, Milk, Diaper, Coke
-
-Rules
-* {Diaper, Beer} -> Milk (40% support, 66% confidence)
-* Milk -> {Diaper, Beer} (40% support, 50% confidence)
-* {Diaper, Beer} -> Bread (40% support, 66% confidence)
-
-*(also useful tool for exploratory data analysis)*
-
-
-
-
-Further readings: Standard algorithms and many variations, see [Wikipedia](https://en.wikipedia.org/wiki/Association_rule_learning)
-
-
-----
-## Discussion: Data Quality Rules
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
----
-
-# Drift
-
-*Why does my model begin to perform poorly over time?*
-
-
-
-
-
-
-
-
-
-
-
-----
-## Types of Drift
-
-
-
-
-
-Gama et al., *A survey on concept drift adaptation*. ACM Computing Surveys Vol. 46, Issue 4 (2014)
-
-----
-
-## Drift & Model Decay
-
-
-
-**Concept drift** (or concept shift)
- * properties to predict change over time (e.g., what is credit card fraud)
- * model has not learned the relevant concepts
- * over time: different expected outputs for same inputs
-
-**Data drift** (or covariate shift, virtual drift, distribution shift, or population drift)
- * characteristics of input data changes (e.g., customers with face masks)
- * input data differs from training data
- * over time: predictions less confident, further from training data
-
-**Upstream data changes**
- * external changes in data pipeline (e.g., format changes in weather service)
- * model interprets input data incorrectly
- * over time: abrupt changes due to faulty inputs
-
-**How do we fix these drifts?**
-
-
-Notes:
- * fix1: retrain with new training data or relabeled old training data
- * fix2: retrain with new data
- * fix3: fix pipeline, retrain entirely
-
-----
-## On Terminology
-
-Concept and data drift are separate concepts
-
-In practice and literature not always clearly distinguished
-
-Colloquially encompasses all forms of model degradations and environment changes
-
-Define term for target audience
-
-
-
-
-----
-## Breakout: Drift in the Inventory System
-
-*What kind of drift might be expected?*
-
-As a group, tagging members, write plausible examples in `#lecture`:
-
-> * Concept Drift:
-> * Data Drift:
-> * Upstream data changes:
-
-
-
-
-
-
-
-
-
-----
-## Watch for Degradation in Prediction Accuracy
-
-
-
-
-
-Image source: Joel Thomas and Clemens Mewald. [Productionizing Machine Learning: From Deployment to Drift Detection](https://databricks.com/blog/2019/09/18/productionizing-machine-learning-from-deployment-to-drift-detection.html). Databricks Blog, 2019
-
-
-
-----
-## Indicators of Concept Drift
-
-*How to detect concept drift in production?*
-
-
-
-----
-## Indicators of Concept Drift
-
-Model degradations observed with telemetry
-
-Telemetry indicates different outputs over time for similar inputs
-
-Relabeling training data changes labels
-
-Interpretable ML models indicate rules that no longer fit
-
-*(many papers on this topic, typically on statistical detection)*
-
-----
-## Indicators of Data Drift
-
-*How to detect data drift in production?*
-
-
-
-----
-## Indicators of Data Drift
-
-Model degradations observed with telemetry
-
-Distance between input distribution and training distribution increases
-
-Average confidence of model predictions declines
-
-Relabeling of training data retains stable labels
-
-
-----
-## Detecting Data Drift
-
-* Compare distributions over time (e.g., t-test)
-* Detect both sudden jumps and gradual changes
-* Distributions can be manually specified or learned (see invariant detection)
-
-
-
-
-
-
-
-
-----
-## Data Distribution Analysis
-
-Plot distributions of features (histograms, density plots, kernel density estimation)
- - Identify which features drift
-
-Define distance function between inputs and identify distance to closest training data (e.g., energy distance, see also kNN)
-
-Anomaly detection and "out of distribution" detection
-
-Compare distribution of output labels
-
-----
-## Data Distribution Analysis Example
-
-https://rpubs.com/ablythe/520912
-
-
-----
-## Microsoft Azure Data Drift Dashboard
-
-
-
-
-Image source and further readings: [Detect data drift (preview) on models deployed to Azure Kubernetes Service (AKS)](https://docs.microsoft.com/en-us/azure/machine-learning/how-to-monitor-datasets?tabs=python)
-
-
-----
-## Dealing with Drift
-
-Regularly retrain model on recent data
- - Use evaluation in production to detect decaying model performance
-
-Involve humans when increasing inconsistencies detected
- - Monitoring thresholds, automation
-
-Monitoring, monitoring, monitoring!
-
-
-
-----
-## Breakout: Drift in the Inventory System
-
-*What kind of monitoring for previously listed drift in Inventory scenario?*
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
----
-# Data Quality is a System-Wide Concern
-
-
-
-
-----
-
-> "Everyone wants to do the model work, not the data work"
-
-
-Sambasivan, N., Kapania, S., Highfill, H., Akrong, D., Paritosh, P., & Aroyo, L. M. (2021, May). “[Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI](https://dl.acm.org/doi/abs/10.1145/3411764.3445518). In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems (pp. 1-15).
-
-----
-## Data flows across components
-
-
-
-
-
-----
-## Data Quality is a System-Wide Concern
-
-Data flows across components, e.g., from user interface into database to crowd-sourced labeling team into ML pipeline
-
-Documentation at the interfaces is important
-
-Humans interacting with the system
-* Entering data, labeling data
-* Observed with sensors/telemetry
-* Incentives, power structures, recognition
-
-Organizational practices
-* Value, attention, and resources given to data quality
-
-----
-## Data Quality Documentation
-
-
-
-Teams rarely document expectations of data quantity or quality
-
-Data quality tests are rare, but some teams adopt defensive monitoring
-* Local tests about assumed structure and distribution of data
-* Identify drift early and reach out to producing teams
-
-Several ideas for documenting distributions, including [Datasheets](https://dl.acm.org/doi/fullHtml/10.1145/3458723) and [Dataset Nutrition Label](https://arxiv.org/abs/1805.03677)
-* Mostly focused on static datasets, describing origin, consideration, labeling procedure, and distributions; [Example](https://dl.acm.org/doi/10.1145/3458723#sec-supp)
-
-
-
-
-🗎 Gebru, Timnit, et al. "[Datasheets for datasets](https://dl.acm.org/doi/fullHtml/10.1145/3458723)." Communications of the ACM 64, no. 12 (2021). -🗎 Nahar, Nadia, et al. “[Collaboration Challenges in Building ML-Enabled Systems: Communication, Documentation, Engineering, and Process](https://arxiv.org/abs/2110.10234).” In Pro. ICSE, 2022. - - ----- -## Common Data Cascades - -
-
-
-**Physical world brittleness**
-* Idealized data, ignoring realities and change of real-world data
-* Static data, one time learning mindset, no planning for evolution
-
-**Inadequate domain expertise**
-* Not understand. data and its context
-* Involving experts only late for trouble shooting
-
-
-**Conflicting reward systems**
-* Missing incentives for data quality
-* Not recognizing data quality importance, discard as technicality
-* Missing data literacy with partners
-
-**Poor (cross-org.) documentation**
-* Conflicts at team/organization boundary
-* Undetected drift
-
-
-
-
-
-Sambasivan, N., et al. (2021). “[Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI](https://dl.acm.org/doi/abs/10.1145/3411764.3445518). In Proc. Conference on Human Factors in Computing Systems.
-
-
-
-
-----
-## Discussion: Possible Data Cascades?
-
-* Interacting with physical world brittleness
-* Inadequate domain expertise
-* Conflicting reward systems
-* Poor (cross-organizational) documentation
-
-
-
-
-
-
-
-----
-## Ethics and Politics of Data
-
-> Raw data is an oxymoron
-
-
-
-----
-## Incentives for Data Quality? Valuing Data Work?
-
-
-
-
-
-
-
----
-# Summary
-
-* Data from many sources, often inaccurate, imprecise, inconsistent, incomplete, ... -- many different forms of data quality problems
-* Many mechanisms for enforcing consistency and cleaning
- * Data schema ensures format consistency
- * Data quality rules ensure invariants across data points
-* Concept and data drift are key challenges -- monitor
-* Data quality is a system-level concern
- * Data quality at the interface between components
- * Documentation and monitoring often poor
- * Involves organizational structures, incentives, ethics, ...
-
-----
-## Further Readings
-
-
-
-* Schelter, S., Lange, D., Schmidt, P., Celikel, M., Biessmann, F. and Grafberger, A., 2018. Automating large-scale data quality verification. Proceedings of the VLDB Endowment, 11(12), pp.1781-1794.
-* Polyzotis, Neoklis, Martin Zinkevich, Sudip Roy, Eric Breck, and Steven Whang. "Data validation for machine learning." Proceedings of Machine Learning and Systems 1 (2019): 334-347.
-* Polyzotis, Neoklis, Sudip Roy, Steven Euijong Whang, and Martin Zinkevich. 2017. “Data Management Challenges in Production Machine Learning.” In Proceedings of the 2017 ACM International Conference on Management of Data, 1723–26. ACM.
-* Theo Rekatsinas, Ihab Ilyas, and Chris Ré, “HoloClean - Weakly Supervised Data Repairing.” Blog, 2017.
-* Ilyas, Ihab F., and Xu Chu. Data cleaning. Morgan & Claypool, 2019.
-* Moreno-Torres, Jose G., Troy Raeder, Rocío Alaiz-Rodríguez, Nitesh V. Chawla, and Francisco Herrera. "A unifying view on dataset shift in classification." Pattern recognition 45, no. 1 (2012): 521-530.
-* Vogelsang, Andreas, and Markus Borg. "Requirements Engineering for Machine Learning: Perspectives from Data Scientists." In Proc. of the 6th International Workshop on Artificial Intelligence for Requirements Engineering (AIRE), 2019.
-* Humbatova, Nargiz, Gunel Jahangirova, Gabriele Bavota, Vincenzo Riccio, Andrea Stocco, and Paolo Tonella. "Taxonomy of real faults in deep learning systems." In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering, pp. 1110-1121. 2020.
-
-
-
diff --git a/lectures/11_dataquality/defectcost.jpg b/lectures/11_dataquality/defectcost.jpg
deleted file mode 100644
index f6dc5588..00000000
Binary files a/lectures/11_dataquality/defectcost.jpg and /dev/null differ
diff --git a/lectures/11_dataquality/dirty-data-example.jpg b/lectures/11_dataquality/dirty-data-example.jpg
deleted file mode 100644
index 56f03660..00000000
Binary files a/lectures/11_dataquality/dirty-data-example.jpg and /dev/null differ
diff --git a/lectures/11_dataquality/drift-ui-expanded.png b/lectures/11_dataquality/drift-ui-expanded.png
deleted file mode 100644
index 8fc3c03d..00000000
Binary files a/lectures/11_dataquality/drift-ui-expanded.png and /dev/null differ
diff --git a/lectures/11_dataquality/drifts.png b/lectures/11_dataquality/drifts.png
deleted file mode 100644
index cb188dc0..00000000
Binary files a/lectures/11_dataquality/drifts.png and /dev/null differ
diff --git a/lectures/11_dataquality/errors_chicago.jpg b/lectures/11_dataquality/errors_chicago.jpg
deleted file mode 100644
index 5b377982..00000000
Binary files a/lectures/11_dataquality/errors_chicago.jpg and /dev/null differ
diff --git a/lectures/11_dataquality/everybody-data.jpeg b/lectures/11_dataquality/everybody-data.jpeg
deleted file mode 100644
index 192bffab..00000000
Binary files a/lectures/11_dataquality/everybody-data.jpeg and /dev/null differ
diff --git a/lectures/11_dataquality/gigo.jpg b/lectures/11_dataquality/gigo.jpg
deleted file mode 100644
index 10bb955c..00000000
Binary files a/lectures/11_dataquality/gigo.jpg and /dev/null differ
diff --git a/lectures/11_dataquality/greatexpectations.png b/lectures/11_dataquality/greatexpectations.png
deleted file mode 100644
index ea9a8811..00000000
Binary files a/lectures/11_dataquality/greatexpectations.png and /dev/null differ
diff --git a/lectures/11_dataquality/holoclean.jpg b/lectures/11_dataquality/holoclean.jpg
deleted file mode 100644
index 7ea1c8f4..00000000
Binary files a/lectures/11_dataquality/holoclean.jpg and /dev/null differ
diff --git a/lectures/11_dataquality/model_drift.jpg b/lectures/11_dataquality/model_drift.jpg
deleted file mode 100644
index 47857a0e..00000000
Binary files a/lectures/11_dataquality/model_drift.jpg and /dev/null differ
diff --git a/lectures/11_dataquality/noSQL.jpeg b/lectures/11_dataquality/noSQL.jpeg
deleted file mode 100644
index 7d5ce6b5..00000000
Binary files a/lectures/11_dataquality/noSQL.jpeg and /dev/null differ
diff --git a/lectures/11_dataquality/qualityproblems.png b/lectures/11_dataquality/qualityproblems.png
deleted file mode 100644
index e3e7e9a0..00000000
Binary files a/lectures/11_dataquality/qualityproblems.png and /dev/null differ
diff --git a/lectures/11_dataquality/shipment-delivery-receipt.jpg b/lectures/11_dataquality/shipment-delivery-receipt.jpg
deleted file mode 100644
index 6ff1940a..00000000
Binary files a/lectures/11_dataquality/shipment-delivery-receipt.jpg and /dev/null differ
diff --git a/lectures/11_dataquality/system.svg b/lectures/11_dataquality/system.svg
deleted file mode 100644
index 9d3cfe66..00000000
--- a/lectures/11_dataquality/system.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/11_dataquality/timeseries.png b/lectures/11_dataquality/timeseries.png
deleted file mode 100644
index e9d5d4bb..00000000
Binary files a/lectures/11_dataquality/timeseries.png and /dev/null differ
diff --git a/lectures/11_dataquality/transcriptionarchitecture2.svg b/lectures/11_dataquality/transcriptionarchitecture2.svg
deleted file mode 100644
index 212a40f7..00000000
--- a/lectures/11_dataquality/transcriptionarchitecture2.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/11_dataquality/twodist.png b/lectures/11_dataquality/twodist.png
deleted file mode 100644
index 824de1b6..00000000
Binary files a/lectures/11_dataquality/twodist.png and /dev/null differ
diff --git a/lectures/11_dataquality/warehouse.jpg b/lectures/11_dataquality/warehouse.jpg
deleted file mode 100644
index 762addb8..00000000
Binary files a/lectures/11_dataquality/warehouse.jpg and /dev/null differ
diff --git a/lectures/12_pipelinequality/ci.png b/lectures/12_pipelinequality/ci.png
deleted file mode 100644
index e686e50f..00000000
Binary files a/lectures/12_pipelinequality/ci.png and /dev/null differ
diff --git a/lectures/12_pipelinequality/client-code-backend.svg b/lectures/12_pipelinequality/client-code-backend.svg
deleted file mode 100644
index a6f7980c..00000000
--- a/lectures/12_pipelinequality/client-code-backend.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/12_pipelinequality/coverage.png b/lectures/12_pipelinequality/coverage.png
deleted file mode 100644
index 35f64927..00000000
Binary files a/lectures/12_pipelinequality/coverage.png and /dev/null differ
diff --git a/lectures/12_pipelinequality/driver-code-backend.svg b/lectures/12_pipelinequality/driver-code-backend.svg
deleted file mode 100644
index 0e4ed85b..00000000
--- a/lectures/12_pipelinequality/driver-code-backend.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/12_pipelinequality/driver-code-stub.svg b/lectures/12_pipelinequality/driver-code-stub.svg
deleted file mode 100644
index 7d3b444c..00000000
--- a/lectures/12_pipelinequality/driver-code-stub.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/12_pipelinequality/driver-stubs-interface.svg b/lectures/12_pipelinequality/driver-stubs-interface.svg
deleted file mode 100644
index 60e25ba3..00000000
--- a/lectures/12_pipelinequality/driver-stubs-interface.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/12_pipelinequality/manualtesting.jpg b/lectures/12_pipelinequality/manualtesting.jpg
deleted file mode 100644
index 02379513..00000000
Binary files a/lectures/12_pipelinequality/manualtesting.jpg and /dev/null differ
diff --git a/lectures/12_pipelinequality/mlflow-web-ui.png b/lectures/12_pipelinequality/mlflow-web-ui.png
deleted file mode 100644
index 82e3e39a..00000000
Binary files a/lectures/12_pipelinequality/mlflow-web-ui.png and /dev/null differ
diff --git a/lectures/12_pipelinequality/mltestingandmonitoring.png b/lectures/12_pipelinequality/mltestingandmonitoring.png
deleted file mode 100644
index 1b00ab01..00000000
Binary files a/lectures/12_pipelinequality/mltestingandmonitoring.png and /dev/null differ
diff --git a/lectures/12_pipelinequality/notebook-example.png b/lectures/12_pipelinequality/notebook-example.png
deleted file mode 100644
index 2b614ce0..00000000
Binary files a/lectures/12_pipelinequality/notebook-example.png and /dev/null differ
diff --git a/lectures/12_pipelinequality/notebookinproduction.png b/lectures/12_pipelinequality/notebookinproduction.png
deleted file mode 100644
index fe12e5aa..00000000
Binary files a/lectures/12_pipelinequality/notebookinproduction.png and /dev/null differ
diff --git a/lectures/12_pipelinequality/pipeline-connections.svg b/lectures/12_pipelinequality/pipeline-connections.svg
deleted file mode 100644
index 9fe37f55..00000000
--- a/lectures/12_pipelinequality/pipeline-connections.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/12_pipelinequality/pipeline.svg b/lectures/12_pipelinequality/pipeline.svg
deleted file mode 100644
index 5195af76..00000000
--- a/lectures/12_pipelinequality/pipeline.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/12_pipelinequality/pipelinequality.md b/lectures/12_pipelinequality/pipelinequality.md
deleted file mode 100644
index 10de0c9a..00000000
--- a/lectures/12_pipelinequality/pipelinequality.md
+++ /dev/null
@@ -1,1520 +0,0 @@
----
-author: Christian Kaestner and Eunsuk Kang
-title: "MLiP: Automating and Testing ML Pipelines"
-semester: Spring 2023
-footer: "Machine Learning in Production/AI Engineering • Christian Kaestner & Eunsuk Kang, Carnegie Mellon University • Spring 2023"
-license: Creative Commons Attribution 4.0 International (CC BY 4.0)
----
-
-
-
-## Machine Learning in Production
-
-
-# Automating and Testing ML Pipelines
-
-
-
-
----
-## Infrastructure Quality...
-
-
-
-
-
-
-----
-## Readings
-
-Required reading: Eric Breck, Shanqing Cai, Eric Nielsen, Michael Salib, D. Sculley. [The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction](https://research.google.com/pubs/archive/46555.pdf). Proceedings of IEEE Big Data (2017)
-
-Recommended readings:
-* O'Leary, Katie, and Makoto Uchida. "[Common problems with Creating Machine Learning Pipelines from Existing Code](https://research.google/pubs/pub48984.pdf)." Proc. Conference on Machine Learning and Systems (MLSys) (2020).
-
-----
-
-# Learning Goals
-
-* Decompose an ML pipeline into testable functions
-* Implement and automate tests for all parts of the ML pipeline
-* Understand testing opportunities beyond functional correctness
-* Describe the different testing levels and testing opportunities at each level
-* Automate test execution with continuous integration
-
-
----
-# ML Pipelines
-
-
-
-
-All steps to create (and deploy) the model
-
-----
-## Common ML Pipeline
-
-
-
-Note:
-Computational notebook
-
-Containing all code, often also dead experimental code
-
-----
-## Notebooks as Production Pipeline?
-
-[](https://tanzu.vmware.com/content/blog/how-data-scientists-can-tame-jupyter-notebooks-for-use-in-production-systems)
-
-Parameterize and use `nbconvert`?
-
-
-----
-## Real Pipelines can be Complex
-
-
-
-
-
-----
-## Real Pipelines can be Complex
-
-Large arguments of data
-
-Distributed data storage
-
-Distributed processing and learning
-
-Special hardware needs
-
-Fault tolerance
-
-Humans in the loop
-
-
-
-----
-## Possible Mistakes in ML Pipelines
-
-
-
-
-Danger of "silent" mistakes in many phases
-
-**Examples?**
-
-----
-## Possible Mistakes in ML Pipelines
-
-Danger of "silent" mistakes in many phases:
-
-* Dropped data after format changes
-* Failure to push updated model into production
-* Incorrect feature extraction
-* Use of stale dataset, wrong data source
-* Data source no longer available (e.g web API)
-* Telemetry server overloaded
-* Negative feedback (telemtr.) no longer sent from app
-* Use of old model learning code, stale hyperparameter
-* Data format changes between ML pipeline steps
-
-----
-## Pipeline Thinking
-
-After exploration and prototyping build robust pipeline
-
-One-off model creation -> repeatable automateable process
-
-Enables updates, supports experimentation
-
-Explicit interfaces with other parts of the system (data sources, labeling infrastructure, training infrastructure, deployment, ...)
-
-**Design for change**
-
-
-----
-## Building Robust Pipeline Automation
-
-* Support experimentation and evolution
- * Automate
- * Design for change
- * Design for observability
- * Testing the pipeline for robustness
-* Thinking in pipelines, not models
-* Integrating the Pipeline with other Components
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
----
-# Pipeline Testability and Modularity
-
-
-
-----
-## Pipelines are Code
-
-From experimental notebook code to production code
-
-Each stage as a function or module
-
-Well tested in isolation and together
-
-Robust to changes in inputs (automatically adapt or crash, no silent mistakes)
-
-Use good engineering practices (version control, documentation, testing, naming, code review)
-
-
-
-----
-## Sequential Data Science Code in Notebooks
-
-
-
-```python
-# typical data science code from a notebook
-df = pd.read_csv('data.csv', parse_dates=True)
-
-
-# data cleaning
-# ...
-
-
-# feature engineering
-df['month'] = pd.to_datetime(df['datetime']).dt.month
-df['dayofweek']= pd.to_datetime(df['datetime']).dt.dayofweek
-df['delivery_count'] = boxcox(df['delivery_count'], 0.4)
-df.drop(['datetime'], axis=1, inplace=True)
-
-
-dummies = pd.get_dummies(df, columns = ['month', 'weather', 'dayofweek'])
-dummies = dummies.drop(['month_1', 'hour_0', 'weather_1'], axis=1)
-
-
-X = dummies.drop(['delivery_count'], axis=1)
-y = pd.Series(df['delivery_count'])
-
-
-X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
-
-
-# training and evaluation
-lr = LinearRegression()
-lr.fit(X_train, y_train)
-
-
-print(lr.score(X_train, y_train))
-print(lr.score(X_test, y_test))
-```
-
-
-
-**How to test??**
-
-----
-## Pipeline restructed into separate function
-
-
-
-```python
-def encode_day_of_week(df):
- if 'datetime' not in df.columns: raise ValueError("Column datetime missing")
- if df.datetime.dtype != 'object': raise ValueError("Invalid type for column datetime")
- df['dayofweek']= pd.to_datetime(df['datetime']).dt.day_name()
- df = pd.get_dummies(df, columns = ['dayofweek'])
- return df
-
-
-# ...
-
-
-def prepare_data(df):
- df = clean_data(df)
-
-
- df = encode_day_of_week(df)
- df = encode_month(df)
- df = encode_weather(df)
- df.drop(['datetime'], axis=1, inplace=True)
- return (df.drop(['delivery_count'], axis=1),
- encode_count(pd.Series(df['delivery_count'])))
-
-
-def learn(X, y):
- lr = LinearRegression()
- lr.fit(X, y)
- return lr
-
-
-def pipeline():
- train = pd.read_csv('train.csv', parse_dates=True)
- test = pd.read_csv('test.csv', parse_dates=True)
- X_train, y_train = prepare_data(train)
- X_test, y_test = prepare_data(test)
- model = learn(X_train, y_train)
- accuracy = eval(model, X_test, y_test)
- return model, accuracy
-```
-
-
-
-
-
-----
-## Orchestrating Functions
-
-```python
-def pipeline():
- train = pd.read_csv('train.csv', parse_dates=True)
- test = pd.read_csv('test.csv', parse_dates=True)
- X_train, y_train = prepare_data(train)
- X_test, y_test = prepare_data(test)
- model = learn(X_train, y_train)
- accuracy = eval(model, X_test, y_test)
- return model, accuracy
-```
-
-Dataflow frameworks like [Luigi](https://github.com/spotify/luigi), [DVC](https://dvc.org/), [Airflow](https://airflow.apache.org/), [d6tflow](https://github.com/d6t/d6tflow), and [Ploomber](https://ploomber.io/) support distribution, fault tolerance, monitoring, ...
-
-Hosted versions like [DataBricks](https://databricks.com/) and [AWS SageMaker Pipelines](https://aws.amazon.com/sagemaker/pipelines/)
-
-
-----
-## Test the Modules
-
-```python
-def encode_day_of_week(df):
- if 'datetime' not in df.columns: raise ValueError("Column datetime missing")
- if df.datetime.dtype != 'object': raise ValueError("Invalid type for column datetime")
- df['dayofweek']= pd.to_datetime(df['datetime']).dt.day_name()
- df = pd.get_dummies(df, columns = ['dayofweek'])
- return df
-```
-
-```python
-def test_day_of_week_encoding():
- df = pd.DataFrame({'datetime': ['2020-01-01','2020-01-02','2020-01-08'], 'delivery_count': [1, 2, 3]})
- encoded = encode_day_of_week(df)
- assert "dayofweek_Wednesday" in encoded.columns
- assert (encoded["dayofweek_Wednesday"] == [1, 0, 1]).all()
-
-# more tests...
-```
-
-
-
-
-
-
-
-
-
-
-
-----
-## Subtle Bugs in Data Wrangling Code
-
-
-```python
-df['Join_year'] = df.Joined.dropna().map(
- lambda x: x.split(',')[1].split(' ')[1])
-```
-```python
-df.loc[idx_nan_age,'Age'].loc[idx_nan_age] =
- df['Title'].loc[idx_nan_age].map(map_means)
-```
-```python
-df["Weight"].astype(str).astype(int)
-```
-
-
-----
-## Subtle Bugs in Data Wrangling Code (continued)
-
-```python
-df['Reviws'] = df['Reviews'].apply(int)
-```
-```python
-df["Release Clause"] =
- df["Release Clause"].replace(regex=['k'], value='000')
-df["Release Clause"] =
- df["Release Clause"].astype(str).astype(float)
-```
-
-Notes:
-
-1 attempting to remove na values from column, not table
-
-2 loc[] called twice, resulting in assignment to temporary column only
-
-3 astype() is not an in-place operation
-
-4 typo in column name
-
-5&6 modeling problem (k vs K)
-
-
-
-
-----
-## Modularity fosters Testability
-
-Breaking code into functions/modules
-
-Supports reuse, separate development, and testing
-
-Can test individual parts
-
-
-
----
-# Excursion: Test Automation
-
-----
-## From Manual Testing to Continuous Integration
-
-
-
-
-
-
-
-
-----
-## Anatomy of a Unit Test
-
-```java
-import org.junit.Test;
-import static org.junit.Assert.assertEquals;
-
-public class AdjacencyListTest {
- @Test
- public void testSanityTest(){
- // set up
- Graph g1 = new AdjacencyListGraph(10);
- Vertex s1 = new Vertex("A");
- Vertex s2 = new Vertex("B");
- // check expected results (oracle)
- assertEquals(true, g1.addVertex(s1));
- assertEquals(true, g1.addVertex(s2));
- assertEquals(true, g1.addEdge(s1, s2));
- assertEquals(s2, g1.getNeighbors(s1)[0]);
- }
-
- // use abstraction, e.g. common setups
- private int helperMethod…
-}
-```
-
-----
-## Ingredients to a Test
-
-Specification
-
-Controlled environment
-
-Test inputs (calls and parameters)
-
-Expected outputs/behavior (oracle)
-
-
-----
-## Unit Testing Pitfalls
-
-
-Working code, failing tests
-
-"Works on my machine"
-
-Tests break frequently
-
-**How to avoid?**
-
-
-----
-## Testable Code
-
-Think about testing when writing code
-
-Unit testing encourages you to write testable code
-
-Separate parts of the code to make them independently testable
-
-Abstract functionality behind interface, make it replaceable
-
-Bonus: Test-Driven Development is a design and development method in which you *always* write tests *before* writing code
-
-
-
-
-----
-## Build systems & Continuous Integration
-
-Automate all build, analysis, test, and deployment steps from a command line call
-
-Ensure all dependencies and configurations are defined
-
-Ideally reproducible and incremental
-
-Distribute work for large jobs
-
-Track results
-
-**Key CI benefit: Tests are regularly executed, part of process**
-
-----
-
-
-
-
-----
-## Tracking Build Quality
-
-Track quality indicators over time, e.g.,
-* Build time
-* Coverage
-* Static analysis warnings
-* Performance results
-* Model quality measures
-* Number of TODOs in source code
-
-
-
-----
-## Coverage
-
-
-
-
-
-----
-[](https://blog.octo.com/en/jenkins-quality-dashboard-ios-development/)
-
-
-
-Source: https://blog.octo.com/en/jenkins-quality-dashboard-ios-development/
-
-
-----
-## Tracking Model Qualities
-
-Many tools: MLFlow, ModelDB, Neptune, TensorBoard, Weights & Biases, Comet.ml, ...
-
-
-
-----
-## ModelDB Example
-
-```python
-from verta import Client
-client = Client("http://localhost:3000")
-
-proj = client.set_project("My first ModelDB project")
-expt = client.set_experiment("Default Experiment")
-
-# log a training run
-run = client.set_experiment_run("First Run")
-run.log_hyperparameters({"regularization" : 0.5})
-model1 = # ... model training code goes here
-run.log_metric('accuracy', accuracy(model1, validationData))
-```
-
-
-
-
-
-
-
-
----
-# Testing Maturity
-
-
-
-
-Eric Breck, Shanqing Cai, Eric Nielsen, Michael Salib, D. Sculley. [The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction](https://research.google.com/pubs/archive/46555.pdf). Proceedings of IEEE Big Data (2017)
-
-
-----
-
-
-
-
-Source: Eric Breck, Shanqing Cai, Eric Nielsen, Michael Salib, D. Sculley. [The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction](https://research.google.com/pubs/archive/46555.pdf). Proceedings of IEEE Big Data (2017)
-
-
-
-----
-## Data Tests
-
-1. Feature expectations are captured in a schema.
-2. All features are beneficial.
-3. No feature’s cost is too much.
-4. Features adhere to meta-level requirements.
-5. The data pipeline has appropriate privacy controls.
-6. New features can be added quickly.
-7. All input feature code is tested.
-
-
-
-Eric Breck, Shanqing Cai, Eric Nielsen, Michael Salib, D. Sculley. [The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction](https://research.google.com/pubs/archive/46555.pdf). Proceedings of IEEE Big Data (2017)
-
-----
-## Tests for Model Development
-
-1. Model specs are reviewed and submitted.
-2. Offline and online metrics correlate.
-3. All hyperparameters have been tuned.
-4. The impact of model staleness is known.
-5. A simpler model is not better.
-6. Model quality is sufficient on important data slices.
-7. The model is tested for considerations of inclusion.
-
-
-
-Eric Breck, Shanqing Cai, Eric Nielsen, Michael Salib, D. Sculley. [The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction](https://research.google.com/pubs/archive/46555.pdf). Proceedings of IEEE Big Data (2017)
-
-----
-## ML Infrastructure Tests
-
-1. Training is reproducible.
-2. Model specs are unit tested.
-3. The ML pipeline is Integration tested.
-4. Model quality is validated before serving.
-5. The model is debuggable.
-6. Models are canaried before serving.
-7. Serving models can be rolled back.
-
-
-
-
-Eric Breck, Shanqing Cai, Eric Nielsen, Michael Salib, D. Sculley. [The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction](https://research.google.com/pubs/archive/46555.pdf). Proceedings of IEEE Big Data (2017)
-
-----
-## Monitoring Tests
-
-1. Dependency changes result in notification.
-2. Data invariants hold for inputs.
-3. Training and serving are not skewed.
-4. Models are not too stale.
-5. Models are numerically stable.
-6. Computing performance has not regressed.
-7. Prediction quality has not regressed.
-
-
-
-
-Eric Breck, Shanqing Cai, Eric Nielsen, Michael Salib, D. Sculley. [The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction](https://research.google.com/pubs/archive/46555.pdf). Proceedings of IEEE Big Data (2017)
-
-
-----
-
-## Case Study: Covid-19 Detection
-
-
-
-(from S20 midterm; assume cloud or hybrid deployment)
-----
-## Breakout Groups
-
-* In the Smartphone Covid Detection scenario
-* Discuss in groups:
- * Back left: data tests
- * Back right: model dev. tests
- * Front right: infrastructure tests
- * Front left: monitoring tests
-* For 8 min, discuss some of the listed point in the context of the Covid-detection scenario: what would you do?
-* In `#lecture`, tagging group members, suggest what top 2 tests to implement and how
-
-
-
-
----
-# Minimizing and Stubbing Dependencies
-
-
-
-
-----
-## How to unit test component with dependency on other code?
-
-
-
-----
-## How to Test Parts of a System?
-
-
-
-
-```python
-# original implementation hardcodes external API
-def clean_gender(df):
- def clean(row):
- if pd.isnull(row['gender']):
- row['gender'] = gender_api_client.predict(row['firstname'], row['lastname'], row['location'])
- return row
- return df.apply(clean, axis=1)
-```
-
-
-----
-## Automating Test Execution
-
-
-
-
-```python
-def test_do_not_overwrite_gender():
- df = pd.DataFrame({'firstname': ['John', 'Jane', 'Jim'],
- 'lastname': ['Doe', 'Doe', 'Doe'],
- 'location': ['Pittsburgh, PA', 'Rome, Italy', 'Paris, PA '],
- 'gender': [np.nan, 'F', np.nan]})
- out = clean_gender(df, model_stub)
- assert(out['gender'] ==['M', 'F', 'M']).all()
-```
-
-----
-## Decoupling from Dependencies
-
-
-```java
-def clean_gender(df, model):
- def clean(row):
- if pd.isnull(row['gender']):
- row['gender'] = model(row['firstname'],
- row['lastname'],
- row['location'])
- return row
- return df.apply(clean, axis=1)
-```
-
-Replace concrete API with an interface that caller can parameterize
-
-----
-## Stubbing the Dependency
-
-
-
-```python
-def test_do_not_overwrite_gender():
- def model_stub(first, last, location):
- return 'M'
-
- df = pd.DataFrame({'firstname': ['John', 'Jane', 'Jim'], 'lastname': ['Doe', 'Doe', 'Doe'], 'location': ['Pittsburgh, PA', 'Rome, Italy', 'Paris, PA '], 'gender': [np.nan, 'F', np.nan]})
- out = clean_gender(df, model_stub)
- assert(out['gender'] ==['M', 'F', 'M']).all()
-```
-
-
-
-----
-## General Testing Strategy: Decoupling Code Under Test
-
-
-
-
-(Mocking frameworks provide infrastructure for expressing such tests compactly.)
-
-
-
-
-
----
-# Testing Error Handling / Infrastructure Robustness
-
-----
-
-
-
-----
-## General Error Handling Strategies
-
-Avoid silent errors
-
-Recover locally if possible, propagate error if necessary -- fail entire task if needed
-
-Explicitly handle exceptional conditions and mistakes
-
-Test correct error handling
-
-If logging only, is anybody analyzing log files?
-
-
-----
-## Test for Expected Exceptions
-
-
-```python
-def test_invalid_day_of_week_data():
- df = pd.DataFrame({'datetime_us': ['01/01/2020'],
- 'delivery_count': [1]})
- with pytest.raises(ValueError):
- encode_day_of_week(df)
-```
-
-
-----
-## Test for Expected Exceptions
-
-
-```python
-def test_learning_fails_with_missing_data():
- df = pd.DataFrame({})
- with pytest.raises(NoDataError):
- learn(df)
-```
-
-
-----
-## Test Recovery Mechanisms with Stub
-
-Use stubs to inject artificial faults
-
-```python
-## testing retry mechanism
-from retry.api import retry_call
-import pytest
-
-# stub of a network connection, sometimes failing
-class FailedConnection(Connection):
- remaining_failures = 0
- def __init__(self, failures):
- self.remaining_failures = failures
- def get(self, url):
- print(self.remaining_failures)
- self.remaining_failures -= 1
- if self.remaining_failures >= 0:
- raise TimeoutError('fail')
- return "success"
-
-# function to be tested, with recovery mechanism
-def get_data(connection, value):
- def get(): return connection.get('https://replicate.npmjs.com/registry/'+value)
- return retry_call(get,
- exceptions = TimeoutError, tries=3, delay=0.1, backoff=2)
-
-# 3 tests for no problem, recoverable problem, and not recoverable
-def test_no_problem_case():
- connection = FailedConnection(0)
- assert get_data(connection, '') == 'success'
-
-def test_successful_recovery():
- connection = FailedConnection(2)
- assert get_data(connection, '') == 'success'
-
-def test_exception_if_unable_to_recover():
- connection = FailedConnection(10)
- with pytest.raises(TimeoutError):
- get_data(connection, '')
-```
-
-----
-## Test Error Handling throughout Pipeline
-
-Is invalid data rejected / repaired?
-
-Are missing data updates raising errors?
-
-Are unavailable APIs triggering errors?
-
-Are failing deployments reported?
-
-----
-## Log Error Occurrence
-
-Even when reported or mitigated, log the issue
-
-Allows later analysis of frequency and patterns
-
-Monitoring systems can raise alarms for anomalies
-
-
-----
-## Example: Error Logging
-
-```python
-from prometheus_client import Counter
-connection_timeout_counter = Counter(
- 'connection_retry_total',
- 'Retry attempts on failed connections')
-
-class RetryLogger():
- def warning(self, fmt, error, delay):
- connection_timeout_counter.inc()
-
-retry_logger = RetryLogger()
-
-def get_data(connection, value):
- def get(): return connection.get('https://replicate.npmjs.com/registry/'+value)
- return retry_call(get,
- exceptions = TimeoutError, tries=3, delay=0.1, backoff=2,
- logger = retry_logger)
-```
-
-
-
-----
-## Test Monitoring
-
-* Inject/simulate faulty behavior
-* Mock out notification service used by monitoring
-* Assert notification
-
-```java
-class MyNotificationService extends NotificationService {
- public boolean receivedNotification = false;
- public void sendNotification(String msg) {
- receivedNotification = true; }
-}
-@Test void test() {
- Server s = getServer();
- MyNotificationService n = new MyNotificationService();
- Monitor m = new Monitor(s, n);
- s.stop();
- s.request(); s.request();
- wait();
- assert(n.receivedNotification);
-}
-```
-
-----
-## Test Monitoring in Production
-
-Like fire drills (manual tests may be okay!)
-
-Manual tests in production, repeat regularly
-
-Actually take down service or trigger wrong signal to monitor
-
-----
-## Chaos Testing
-
-
-
-
-
-
-http://principlesofchaos.org
-
-Notes: Chaos Engineering is the discipline of experimenting on a distributed system in order to build confidence in the system’s capability to withstand turbulent conditions in production. Pioneered at Netflix
-
-----
-## Chaos Testing Argument
-
-* Distributed systems are simply too complex to comprehensively predict
- * experiment to learn how it behaves in the presence of faults
-* Base corrective actions on experimental results because they reflect real risks and actual events
-*
-* Experimentation != testing -- Observe behavior rather then expect specific results
-* Simulate real-world problem in production (e.g., take down server, inject latency)
-* *Minimize blast radius:* Contain experiment scope
-
-----
-## Netflix's Simian Army
-
-
-
-* Chaos Monkey: randomly disable production instances
-* Latency Monkey: induces artificial delays in our RESTful client-server communication layer
-* Conformity Monkey: finds instances that don’t adhere to best-practices and shuts them down
-* Doctor Monkey: monitors external signs of health to detect unhealthy instances
-* Janitor Monkey: ensures cloud environment is running free of clutter and waste
-* Security Monkey: finds security violations or vulnerabilities, and terminates the offending instances
-* 10–18 Monkey: detects problems in instances serving customers in multiple geographic regions
-* Chaos Gorilla is similar to Chaos Monkey, but simulates an outage of an entire Amazon availability zone.
-
-
-
-
-----
-## Chaos Toolkit
-
-* Infrastructure for chaos experiments
-* Driver for various infrastructure and failure cases
-* Domain specific language for experiment definitions
-
-```js
-{
- "version": "1.0.0",
- "title": "What is the impact of an expired certificate on our application chain?",
- "description": "If a certificate expires, we should gracefully deal with the issue.",
- "tags": ["tls"],
- "steady-state-hypothesis": {
- "title": "Application responds",
- "probes": [
- {
- "type": "probe",
- "name": "the-astre-service-must-be-running",
- "tolerance": true,
- "provider": {
- "type": "python",
- "module": "os.path",
- "func": "exists",
- "arguments": {
- "path": "astre.pid"
- }
- }
- },
- {
- "type": "probe",
- "name": "the-sunset-service-must-be-running",
- "tolerance": true,
- "provider": {
- "type": "python",
- "module": "os.path",
- "func": "exists",
- "arguments": {
- "path": "sunset.pid"
- }
- }
- },
- {
- "type": "probe",
- "name": "we-can-request-sunset",
- "tolerance": 200,
- "provider": {
- "type": "http",
- "timeout": 3,
- "verify_tls": false,
- "url": "https://localhost:8443/city/Paris"
- }
- }
- ]
- },
- "method": [
- {
- "type": "action",
- "name": "swap-to-expired-cert",
- "provider": {
- "type": "process",
- "path": "cp",
- "arguments": "expired-cert.pem cert.pem"
- }
- },
- {
- "type": "probe",
- "name": "read-tls-cert-expiry-date",
- "provider": {
- "type": "process",
- "path": "openssl",
- "arguments": "x509 -enddate -noout -in cert.pem"
- }
- },
- {
- "type": "action",
- "name": "restart-astre-service-to-pick-up-certificate",
- "provider": {
- "type": "process",
- "path": "pkill",
- "arguments": "--echo -HUP -F astre.pid"
- }
- },
- {
- "type": "action",
- "name": "restart-sunset-service-to-pick-up-certificate",
- "provider": {
- "type": "process",
- "path": "pkill",
- "arguments": "--echo -HUP -F sunset.pid"
- },
- "pauses": {
- "after": 1
- }
- }
- ],
- "rollbacks": [
- {
- "type": "action",
- "name": "swap-to-vald-cert",
- "provider": {
- "type": "process",
- "path": "cp",
- "arguments": "valid-cert.pem cert.pem"
- }
- },
- {
- "ref": "restart-astre-service-to-pick-up-certificate"
- },
- {
- "ref": "restart-sunset-service-to-pick-up-certificate"
- }
- ]
-}
-```
-
-
-
-http://principlesofchaos.org, https://github.com/chaostoolkit, https://github.com/Netflix/SimianArmy
-
-----
-## Chaos Experiments for ML Infrastructure?
-
-
-
-
-Note: Fault injection in production for testing in production. Requires monitoring and explicit experiments.
-
-
-
-
-
-
-
----
-# Where to Focus Testing?
-
-
-
-----
-## Testing in ML Pipelines
-
-Usually assume ML libraries already tested (pandas, sklearn, etc)
-
-Focus on custom code
-- data quality checks
-- data wrangling (feature engineering)
-- training setup
-- interaction with other components
-
-Consider tests of latency, throughput, memory, ...
-
-----
-## Testing Data Quality Checks
-
-Test correct detection of problems
-
-```python
-def test_invalid_day_of_week_data():
- ...
-```
-
-Test correct error handling or repair of detected problems
-
-```python
-def test_fill_missing_gender():
- ...
-def test_exception_for_missing_data():
- ...
-```
-
-----
-## Test Data Wrangling Code
-
-```python
-num = data.Size.replace(r'[kM]+$', '', regex=True).
- astype(float)
-factor = data.Size.str.extract(r'[\d\.]+([KM]+)',
- expand =False)
-factor = factor.replace(['k','M'], [10**3, 10**6]).fillna(1)
-data['Size'] = num*factor.astype(int)
-```
-```python
-data["Size"]= data["Size"].
- replace(regex =['k'], value='000')
-data["Size"]= data["Size"].
- replace(regex =['M'], value='000000')
-data["Size"]= data["Size"].astype(str). astype(float)
-```
-
-Note: both attempts are broken:
-
-* Variant A, returns 10 for “10k”
-* Variant B, returns 100.5000000 for “100.5M”
-
-----
-## Test Model Training Setup?
-
-Execute training with small sample data
-
-Ensure shape of model and data as expected (e.g., tensor dimensions)
-
-----
-## Test Interactions with Other Components
-
-Test error handling for detecting connection/data problems
-* loading training data
-* feature server
-* uploading serialized model
-* A/B testing infrastructure
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
----
-# Integration and system tests
-
-
-
-
-Notes:
-
-Software is developed in units that are later assembled. Accordingly we can distinguish different levels of testing.
-
-Unit Testing - A unit is the "smallest" piece of software that a developer creates. It is typically the work of one programmer and is stored in a single file. Different programming languages have different units: In C++ and Java the unit is the class; in C the unit is the function; in less structured languages like Basic and COBOL the unit may be the entire program.
-
-Integration Testing - In integration we assemble units together into subsystems and finally into systems. It is possible for units to function perfectly in isolation but to fail when integrated. For example because they share an area of the computer memory or because the order of invocation of the different methods is not the one anticipated by the different programmers or because there is a mismatch in the data types. Etc.
-
-System Testing - A system consists of all of the software (and possibly hardware, user manuals, training materials, etc.) that make up the product delivered to the customer. System testing focuses on defects that arise at this highest level of integration. Typically system testing includes many types of testing: functionality, usability, security, internationalization and localization, reliability and availability, capacity, performance, backup and recovery, portability, and many more.
-
-Acceptance Testing - Acceptance testing is defined as that testing, which when completed successfully, will result in the customer accepting the software and giving us their money. From the customer's point of view, they would generally like the most exhaustive acceptance testing possible (equivalent to the level of system testing). From the vendor's point of view, we would generally like the minimum level of testing possible that would result in money changing hands.
-Typical strategic questions that should be addressed before acceptance testing are: Who defines the level of the acceptance testing? Who creates the test scripts? Who executes the tests? What is the pass/fail criteria for the acceptance test? When and how do we get paid?
-
-
-----
-## Integration and system tests
-
-Test larger units of behavior
-
-Often based on use cases or user stories -- customer perspective
-
-```java
-@Test void gameTest() {
- Poker game = new Poker();
- Player p = new Player();
- Player q = new Player();
- game.shuffle(seed)
- game.add(p);
- game.add(q);
- game.deal();
- p.bet(100);
- q.bet(100);
- p.call();
- q.fold();
- assert(game.winner() == p);
-}
-
-```
-
-
-
-----
-## Integration tests
-
-Test combined behavior of multiple functions
-
-```java
-def test_cleaning_with_feature_eng() {
- d = load_test_data();
- cd = clean(d);
- f = feature3.encode(cd);
- assert(no_missing_values(f["m"]));
- assert(max(f["m"]) <= 1.0);
-}
-
-```
-
-
-
-----
-## Test Integration of Components
-
-```javascript
-// making predictions with an ensemble of models
-function predict_price(data, models, timeoutms) {
- // send asynchronous REST requests all models
- const requests = models.map(model => rpc(model, data, {timeout: timeoutms}).then(parseResult).catch(e => -1))
- // collect all answers and return average if at least two models succeeded
- return Promise.all(requests).then(predictions => {
- const success = predictions.filter(v => v >= 0)
- if (success.length < 2) throw new Error("Too many models failed")
- return success.reduce((a, b) => a + b, 0) / success.length
- })
-}
-
-// test ensemble of models
-const timeout = 500, M1 = "http://localhost:3000/predict", ...
-beforeAll(() => {
- // launch model 1 API at address M1
- // launch model 2 API at address M2
- // launch model API with timeout at address M3
-}
-afterAll(() => { /* shut down all model APIs */ }
-
-test("success despite timeout", async () => {
- const start = performance.now();
- const val = await predict_price(input, [M1, M2, M3], timeout)
- expect(performance.now() - start).toBeLessThan(2 * timeout)
- expect(val).toBeGreaterThan(0)
-})
-
-test("fail on too many timeouts", async () => {
- const start = performance.now();
- const val = await predict_price(input, [M1, M3, M3], timeout)
- expect(performance.now() - start).toBeLessThan(2 * timeout)
- expect(val).toThrow()
-})
-```
-
-----
-## End-To-End Test of Entire Pipeline
-
-```python
-def test_pipeline():
- train = pd.read_csv('pipelinetest_training.csv', parse_dates=True)
- test = pd.read_csv('pipelinetest_test.csv', parse_dates=True)
- X_train, y_train = prepare_data(train)
- X_test, y_test = prepare_data(test)
- model = learn(X_train, y_train)
- accuracy = eval(model, X_test, y_test)
- assert accuracy > 0.9
-```
-
-
-----
-## System Testing from a User Perspective
-
-Test the product as a whole, not just components
-
-Click through user interface, achieve task (often manually performed)
-
-Derived from requirements (use cases, user stories)
-
-Testing in production
-
-----
-## The V-Model of Testing
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
----
-# Code Review and Static Analysis
-
-----
-## Code Review
-
-Manual inspection of code
-- Looking for problems and possible improvements
-- Possibly following checklists
-- Individually or as group
-
-Modern code review: Incremental review at checking
-- Review individual changes before merging
-- Pull requests on GitHub
-- Not very effective at finding bugs, but many other benefits: knowledge transfer, code imporvement, shared code ownership, improving testing
-
-----
-
-
-
-----
-## Subtle Bugs in Data Wrangling Code
-
-```python
-df['Join_year'] = df.Joined.dropna().map(
- lambda x: x.split(',')[1].split(' ')[1])
-```
-```python
-df.loc[idx_nan_age,'Age'].loc[idx_nan_age] =
- df['Title'].loc[idx_nan_age].map(map_means)
-```
-```python
-df["Weight"].astype(str).astype(int)
-```
-```python
-df['Reviws'] = df['Reviews'].apply(int)
-```
-
-Notes: We did code review earlier together
-
-----
-## Static Analysis, Code Linting
-
-Automatic detection of problematic patterns based on code structure
-
-```java
-if (user.jobTitle = "manager") {
- ...
-}
-```
-
-```javascript
-function fn() {
- x = 1;
- return x;
- x = 3;
-}
-```
-
-
-----
-## Static Analysis for Data Science Code
-
-* Lots of research
-* Style issues in Python
-* Shape analysis of tensors in deep learning
-* Analysis of flow of datasets to detect data leakage
-* ...
-
-
-Examples:
-* Yang, Chenyang, et al.. "Data Leakage in Notebooks: Static Detection and Better Processes." Proc. ASE (2022).
-* Lagouvardos, S. et al. (2020). Static analysis of shape in TensorFlow programs. In Proc. ECOOP.
-* Wang, Jiawei, et al. "Better code, better sharing: on the need of analyzing jupyter notebooks." In Proc. ICSE-NIER. 2020.
-
-
-----
-## Process Integration: Static Analysis Warnings during Code Review
-
-
-
-
-
-
-Sadowski, Caitlin, Edward Aftandilian, Alex Eagle, Liam Miller-Cushon, and Ciera Jaspan. "Lessons from building static analysis tools at google." Communications of the ACM 61, no. 4 (2018): 58-66.
-
-Note: Social engineering to force developers to pay attention. Also possible with integration in pull requests on GitHub.
-
-
-
-----
-## Bonus: Data Linter at Google
-
-
-**Miscoding**
- * Number, date, time as string
- * Enum as real
- * Tokenizable string (long strings, all unique)
- * Zip code as number
-
-
-**Outliers and scaling**
- * Unnormalized feature (varies widely)
- * Tailed distributions
- * Uncommon sign
-
-**Packaging**
- * Duplicate rows
- * Empty/missing data
-
-
-Further readings: Hynes, Nick, D. Sculley, and Michael Terry. [The data linter: Lightweight, automated sanity checking for ML data sets](http://learningsys.org/nips17/assets/papers/paper_19.pdf). NIPS MLSys Workshop. 2017.
-
-
-
-
-
-
-
-
----
-# Summary
-
-* Beyond model and data quality: Quality of the infrastructure matters, danger of silent mistakes
-* Automate pipelines to foster testing, evolution, and experimentation
-* Many SE techniques for test automation, testing robustness, test adequacy, testing in production useful for infrastructure quality
-
-----
-## Further Readings
-
-
-
-* 🗎 O'Leary, Katie, and Makoto Uchida. "[Common problems with Creating Machine Learning Pipelines from Existing Code](https://research.google/pubs/pub48984.pdf)." Proc. Third Conference on Machine Learning and Systems (MLSys) (2020).
-* 🗎 Eric Breck, Shanqing Cai, Eric Nielsen, Michael Salib, D. Sculley. The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction. Proceedings of IEEE Big Data (2017)
-* 📰 Zinkevich, Martin. [Rules of Machine Learning: Best Practices for ML Engineering](https://developers.google.com/machine-learning/guides/rules-of-ml/). Google Blog Post, 2017
-* 🗎 Serban, Alex, Koen van der Blom, Holger Hoos, and Joost Visser. "[Adoption and Effects of Software Engineering Best Practices in Machine Learning](https://arxiv.org/pdf/2007.14130)." In Proc. ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (2020).
-
-
-
diff --git a/lectures/12_pipelinequality/review_github.png b/lectures/12_pipelinequality/review_github.png
deleted file mode 100644
index 523142ce..00000000
Binary files a/lectures/12_pipelinequality/review_github.png and /dev/null differ
diff --git a/lectures/12_pipelinequality/simiamarmy.jpg b/lectures/12_pipelinequality/simiamarmy.jpg
deleted file mode 100644
index 2db32a78..00000000
Binary files a/lectures/12_pipelinequality/simiamarmy.jpg and /dev/null differ
diff --git a/lectures/12_pipelinequality/staticanalysis_codereview.png b/lectures/12_pipelinequality/staticanalysis_codereview.png
deleted file mode 100644
index 98616bee..00000000
Binary files a/lectures/12_pipelinequality/staticanalysis_codereview.png and /dev/null differ
diff --git a/lectures/12_pipelinequality/unit-integration-system-testing.svg b/lectures/12_pipelinequality/unit-integration-system-testing.svg
deleted file mode 100644
index daf0d8dc..00000000
--- a/lectures/12_pipelinequality/unit-integration-system-testing.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/12_pipelinequality/vmodel.svg b/lectures/12_pipelinequality/vmodel.svg
deleted file mode 100644
index b5d6207e..00000000
--- a/lectures/12_pipelinequality/vmodel.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/13_dataatscale/apigateway.svg b/lectures/13_dataatscale/apigateway.svg
deleted file mode 100644
index 25a35378..00000000
--- a/lectures/13_dataatscale/apigateway.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/13_dataatscale/bluescreen.png b/lectures/13_dataatscale/bluescreen.png
deleted file mode 100644
index 1fd3f77d..00000000
Binary files a/lectures/13_dataatscale/bluescreen.png and /dev/null differ
diff --git a/lectures/13_dataatscale/dataatscale.md b/lectures/13_dataatscale/dataatscale.md
deleted file mode 100644
index c1bf1077..00000000
--- a/lectures/13_dataatscale/dataatscale.md
+++ /dev/null
@@ -1,1041 +0,0 @@
----
-author: Christian Kaestner and Eunsuk Kang
-title: "MLiP: Scaling Data Storage and Data Processing"
-semester: Spring 2023
-footer: "Machine Learning in Production/AI Engineering • Christian Kaestner & Eunsuk Kang, Carnegie Mellon University • Spring 2023"
-license: Creative Commons Attribution 4.0 International (CC BY 4.0)
----
-
-
-
-## Machine Learning in Production
-
-# Scaling Data Storage and Data Processing
-
-
----
-## Design and operations
-
-
-
-
-
-----
-## Readings
-
-Required reading: 🕮 Nathan Marz. Big Data: Principles and best practices of scalable realtime data systems. Simon and Schuster, 2015. Chapter 1: A new paradigm for Big Data
-
-Suggested watching: Molham Aref. [Business Systems with Machine Learning](https://www.youtube.com/watch?v=_bvrzYOA8dY). Guest lecture, 2020.
-
-Suggested reading: Martin Kleppmann. [Designing Data-Intensive Applications](https://dataintensive.net/). OReilly. 2017.
-
-----
-
-# Learning Goals
-
-* Organize different data management solutions and their tradeoffs
-* Understand the scalability challenges involved in large-scale machine learning and specifically deep learning
-* Explain the tradeoffs between batch processing and stream processing and the lambda architecture
-* Recommend and justify a design and corresponding technologies for a given system
-
----
-# Case Study
-
-
-
-
-Notes:
-* Discuss possible architecture and when to predict (and update)
-* in may 2017: 500M users, uploading 1.2billion photos per day (14k/sec)
-* in Jun 2019 1 billion users
-
-----
-
-## Adding capacity
-
-
-
-*Stories of catastrophic success?*
-
----
-
-# Data Management and Processing in ML-Enabled Systems
-
-----
-## Kinds of Data
-
-* Training data
-* Input data
-* Telemetry data
-* (Models)
-
-*all potentially with huge total volumes and high throughput*
-
-*need strategies for storage and processing*
-
-----
-## Data Management and Processing in ML-Enabled Systems
-
-Store, clean, and update training data
-
-Learning process reads training data, writes model
-
-Prediction task (inference) on demand or precomputed
-
-Individual requests (low/high volume) or large datasets?
-
-*Often both learning and inference data heavy, high volume tasks*
-
-----
-## Scaling Computations
-
-
-Efficent Algorithms
-
-Faster Machines
-
-More Machines
-
-
-----
-## Distributed Everything
-
-Distributed data cleaning
-
-Distributed feature extraction
-
-Distributed learning
-
-Distributed large prediction tasks
-
-Incremental predictions
-
-Distributed logging and telemetry
-
-
-
-----
-## Reliability and Scalability Challenges in AI-Enabled Systems?
-
-
-
-
-
-----
-## Distributed Systems and AI-Enabled Systems
-
-* Learning tasks can take substantial resources
-* Datasets too large to fit on single machine
-* Nontrivial inference time, many many users
-* Large amounts of telemetry
-* Experimentation at scale
-* Models in safety critical parts
-* Mobile computing, edge computing, cyber-physical systems
-
-----
-## Reminder: T-Shaped People
-
-
-
-
-
-Go deeper with: Martin Kleppmann. [Designing Data-Intensive Applications](https://dataintensive.net/). OReilly. 2017.
-
----
-# Excursion: Distributed Deep Learning with the Parameter Server Architecture
-
-
-Li, Mu, et al. "[Scaling distributed machine learning with the parameter server](https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-li_mu.pdf)." OSDI, 2014.
-
-----
-## Recall: Backpropagation
-
-
-
-
-----
-## Training at Scale is Challenging
-
-Already 2012 at Google: 1TB-1PB of training data, $10^9-10^{12}$ parameters
-
-Need distributed training; learning is often a sequential problem
-
-Just exchanging model parameters requires substantial network bandwidth
-
-Fault tolerance essential (like batch processing), add/remove nodes
-
-Tradeoff between convergence rate and system efficiency
-
-
-Li, Mu, et al. "[Scaling distributed machine learning with the parameter server](https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-li_mu.pdf)." OSDI, 2014.
-
-----
-## Distributed Gradient Descent
-
-[](https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-li_mu.pdf)
-
-
-----
-## Parameter Server Architecture
-
-[](https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-li_mu.pdf)
-
-
-Note:
-Multiple parameter servers that each only contain a subset of the parameters, and multiple workers that each require only a subset of each
-
-Ship only relevant subsets of mathematical vectors and matrices, batch communication
-
-Resolve conflicts when multiple updates need to be integrated (sequential, eventually, bounded delay)
-
-Run more than one learning algorithm simulaneously
-
-----
-## SysML Conference
-
-
-Increasing interest in the systems aspects of machine learning
-
-e.g., building large scale and robust learning infrastructure
-
-https://mlsys.org/
-
-
-
-
-
-
-
-
-
-
-
-
-
----
-# Data Storage Basics
-
-Relational vs document storage
-
-1:n and n:m relations
-
-Storage and retrieval, indexes
-
-Query languages and optimization
-
-----
-## Relational Data Models
-
-
-
-**Photos:**
-
-|photo_id|user_id|path|upload_date|size|camera_id|camera_setting|
-|-|-|-|-|-|-|-|
-|133422131|54351|/st/u211/1U6uFl47Fy.jpg|2021-12-03T09:18:32.124Z|5.7|663|ƒ/1.8; 1/120; 4.44mm; ISO271|
-|133422132|13221| /st/u11b/MFxlL1FY8V.jpg |2021-12-03T09:18:32.129Z|3.1|1844|ƒ/2, 1/15, 3.64mm, ISO1250|
-|133422133|54351|/st/x81/ITzhcSmv9s.jpg|2021-12-03T09:18:32.131Z|4.8|663|ƒ/1.8; 1/120; 4.44mm; ISO48|
-
-
-
-**Users:**
-
-
-| user_id |account_name|photos_total|last_login|
-|-|-|-|-|
-|54351| ckaestne | 5124 | 2021-12-08T12:27:48.497Z |
-|13221| eva.burk |3|2021-12-21T01:51:54.713Z|
-
-
-
-**Cameras:**
-
-
-| camera_id |manufacturer|print_name|
-|-|-|-|
-|663| Google | Google Pixel 5 |
-|1844|Motorola|Motorola MotoG3|
-
-
-
-```sql
-select p.photo_id, p.path, u.photos_total
-from photos p, users u
-where u.user_id=p.user_id and u.account_name = "ckaestne"
-```
-
-
-
-----
-
-## Document Data Models
-
-
-```js
-{
- "_id": 133422131,
- "path": "/st/u211/1U6uFl47Fy.jpg",
- "upload_date": "2021-12-03T09:18:32.124Z",
- "user": {
- "account_name": "ckaestne",
- "account_id": "a/54351"
- },
- "size": "5.7",
- "camera": {
- "manufacturer": "Google",
- "print_name": "Google Pixel 5",
- "settings": "ƒ/1.8; 1/120; 4.44mm; ISO271"
- }
-}
-
-```
-
-```js
-db.getCollection('photos').find( { "user.account_name": "ckaestne"})
-```
-
-----
-## Log files, unstructured data
-
-```text
-02:49:12 127.0.0.1 GET /img13.jpg 200
-02:49:35 127.0.0.1 GET /img27.jpg 200
-03:52:36 127.0.0.1 GET /main.css 200
-04:17:03 127.0.0.1 GET /img13.jpg 200
-05:04:54 127.0.0.1 GET /img34.jpg 200
-05:38:07 127.0.0.1 GET /img27.jpg 200
-05:44:24 127.0.0.1 GET /img13.jpg 200
-06:08:19 127.0.0.1 GET /img13.jpg 200
-```
-
-
-----
-## Tradeoffs
-
-
-
-----
-## Data Encoding
-
-Plain text (csv, logs)
-
-Semi-structured, schema-free (JSON, XML)
-
-Schema-based encoding (relational, Avro, ...)
-
-Compact encodings (protobuffer, ...)
-
----
-# Distributed Data Storage
-
-----
-## Replication vs Partitioning
-
-
-
-----
-## Partitioning
-
-
-Divide data:
-
-* *Horizontal partitioning:* Different rows in different tables; e.g., movies by decade, hashing often used
-* *Vertical partitioning:* Different columns in different tables; e.g., movie title vs. all actors
-
-**Tradeoffs?**
-
-
-
-
-
-
-
-
-----
-## Replication with Leaders and Followers
-
-
-
-
-
-----
-## Replication Strategies: Leaders and Followers
-
-Write to leader, propagated synchronously or async.
-
-Read from any follower
-
-Elect new leader on leader outage; catchup on follower outage
-
-Built in model of many databases (MySQL, MongoDB, ...)
-
-**Benefits and Drawbacks?**
-
-
-----
-## Recall: Google File System
-
-
-
-
-
-Ghemawat, Sanjay, Howard Gobioff, and Shun-Tak Leung. "[The Google file system.](https://ai.google/research/pubs/pub51.pdf)" ACM SIGOPS operating systems review. Vol. 37. No. 5. ACM, 2003.
-
-
-----
-## Multi-Leader Replication
-
-Scale write access, add redundancy
-
-Requires coordination among leaders
-* Resolution of write conflicts
-
-Offline leaders (e.g. apps), collaborative editing
-
-
-
-----
-## Leaderless Replication
-
-Client writes to multiple replica, propagate from there
-
-Read from multiple replica (quorum required)
-* Repair on reads, background repair process
-
-Versioning of entries (clock problem)
-
-*e.g. Amazon Dynamo, Cassandra, Voldemort*
-
-----
-## Transactions
-
-Multiple operations conducted as one, all or nothing
-
-Avoids problems such as
-* dirty reads
-* dirty writes
-
-Various strategies, including locking and optimistic+rollback
-
-Overhead in distributed setting
-
----
-# Data Processing (Overview)
-
-* Services (online)
- * Responding to client requests as they come in
- * Evaluate: Response time
-* Batch processing (offline)
- * Computations run on large amounts of data
- * Takes minutes to days; typically scheduled periodically
- * Evaluate: Throughput
-* Stream processing (near real time)
- * Processes input events, not responding to requests
- * Shortly after events are issued
-
----
-# Microservices
-
-----
-## Microservices
-
-
-
-
-
-Figure based on Christopher Meiklejohn. [Dynamic Reduction: Optimizing Service-level Fault Injection Testing With Service Encapsulation](http://christophermeiklejohn.com/filibuster/2021/10/14/filibuster-4.html). Blog Post 2021
-
-----
-## Microservices
-
-
-
-Independent, cohesive services
- * Each specialized for one task
- * Each with own data storage
- * Each independently scalable through multiple instances + load balancer
-
-Remote procedure calls
-
-Different teams can work on different services independently (even in different languages)
-
-But: Substantial complexity from distributed system nature: various network failures,
- latency from remote calls, ...
-
-*Avoid microservice complexity unless really needed for scalability*
-
-
-
-----
-## API Gateway Pattern
-
-Central entry point, authentication, routing, updates, ...
-
-
-
-
-
-
----
-# Batch Processing
-
-----
-## Large Jobs
-
-* Analyzing TB of data, typically distributed storage
-* Filtering, sorting, aggregating
-* Producing reports, models, ...
-
-```sh
-cat /var/log/nginx/access.log |
- awk '{print $7}' |
- sort |
- uniq -c |
- sort -r -n |
- head -n 5
-```
-----
-[](mapreduce.svg)
-
-
-----
-## Distributed Batch Processing
-
-Process data locally at storage
-
-Aggregate results as needed
-
-Separate pluming from job logic
-
-*MapReduce* as common framework
-
-
-----
-## MapReduce -- Functional Programming Style
-
-Similar to shell commands: Immutable inputs, new outputs, avoid side effects
-
-Jobs can be repeated (e.g., on crashes)
-
-Easy rollback
-
-Multiple jobs in parallel (e.g., experimentation)
-
-----
-## Machine Learning and MapReduce
-
-
-
-Notes: Useful for big learning jobs, but also for feature extraction
-
-----
-## Dataflow Engines (Spark, Tez, Flink, ...)
-
-Single job, rather than subjobs
-
-More flexible than just map and reduce
-
-Multiple stages with explicit dataflow between them
-
-Often in-memory data
-
-Pluming and distribution logic separated
-
-----
-## Key Design Principle: Data Locality
-
-> Moving Computation is Cheaper than Moving Data -- [Hadoop Documentation](https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#aMoving_Computation_is_Cheaper_than_Moving_Data)
-
-Data often large and distributed, code small
-
-Avoid transfering large amounts of data
-
-Perform computation where data is stored (distributed)
-
-Transfer only results as needed
-
-*"The map reduce way"*
-
-
-
----
-# Stream Processing
-
-Event-based systems, message passing style, publish subscribe
-
-----
-## Stream Processing (e.g., Kafka)
-
-
-
-----
-## Messaging Systems
-
-Multiple producers send messages to topic
-
-Multiple consumers can read messages
-
--> Decoupling of producers and consumers
-
-Message buffering if producers faster than consumers
-
-Typically some persistency to recover from failures
-
-Messages removed after consumption or after timeout
-
-Various error handling strategies (acknowledgements, redelivery, ...)
-
-----
-## Common Designs
-
-Like shell programs: Read from stream, produce output in other stream. -> loose coupling
-
-
-
-
-
-----
-## Stream Queries
-
-Processing one event at a time independently
-
-vs incremental analysis over all messages up to that point
-
-vs floating window analysis across recent messages
-
-Works well with probabilistic analyses
-
-----
-## Consumers
-
-Multiple consumers share topic for scaling and load balancing
-
-Multiple consumers read same message for different work
-
-Partitioning possible
-
-----
-## Design Questions
-
-Message loss important? (at-least-once processing)
-
-Can messages be processed repeatedly (at-most-once processing)
-
-Is the message order important?
-
-Are messages still needed after they are consumed?
-
-----
-## Stream Processing and AI-enabled Systems?
-
-
-
-Notes: Process data as it arrives, prepare data for learning tasks,
-use models to annotate data, analytics
-
-----
-## Event Sourcing
-
-* Append only databases
-* Record edit events, never mutate data
-* Compute current state from all past events, can reconstruct old state
-* For efficiency, take state snapshots
-* *Similar to traditional database logs, but persistent*
-
-```text
-addPhoto(id=133422131, user=54351, path="/st/u211/1U6uFl47Fy.jpg", date="2021-12-03T09:18:32.124Z")
-updatePhotoData(id=133422131, user=54351, title="Sunset")
-replacePhoto(id=133422131, user=54351, path="/st/x594/vipxBMFlLF.jpg", operation="/filter/palma")
-deletePhoto(id=133422131, user=54351)
-```
-
-----
-## Benefits of Immutability (Event Sourcing)
-
-
-
-* All history is stored, recoverable
-* Versioning easy by storing id of latest record
-* Can compute multiple views
-* Compare *git*
-
-> *On a shopping website, a customer may add an item to their cart and then
-remove it again. Although the second event cancels out the first event [...], it may be useful to know for analytics purposes that the
-customer was considering a particular item but then decided against it. Perhaps they
-will choose to buy it in the future, or perhaps they found a substitute. This information is recorded in an event log, but would be lost in a database [...].*
-
-
-
-
-
-Source: Greg Young. [CQRS and Event Sourcing](https://www.youtube.com/watch?v=JHGkaShoyNs). Code on the Beach 2014 via Martin Kleppmann. Designing Data-Intensive Applications. OReilly. 2017.
-
-----
-## Drawbacks of Immutable Data
-
-
-
-Notes:
-* Storage overhead, extra complexity of deriving state
-* Frequent changes may create massive data overhead
-* Some sensitive data may need to be deleted (e.g., privacy, security)
-
----
-# The Lambda Architecture
-
-----
-## 3 Layer Storage Architecture
-
-
-* Batch layer: best accuracy, all data, recompute periodically
-* Speed layer: stream processing, incremental updates, possibly approximated
-* Serving layer: provide results of batch and speed layers to clients
-
-Assumes append-only data
-
-Supports tasks with widely varying latency
-
-Balance latency, throughput and fault tolerance
-
-----
-## Lambda Architecture and Machine Learning
-
-
-
-
-
-* Learn accurate model in batch job
-* Learn incremental model in stream processor
-
-----
-## Data Lake
-
-Trend to store all events in raw form (no consistent schema)
-
-May be useful later
-
-Data storage is comparably cheap
-
-
-
-----
-## Data Lake
-
-Trend to store all events in raw form (no consistent schema)
-
-May be useful later
-
-Data storage is comparably cheap
-
-Bet: *Yet unknown future value of data is greater than storage costs*
-
-----
-## Reasoning about Dataflows
-
-Many data sources, many outputs, many copies
-
-Which data is derived from what other data and how?
-
-Is it reproducible? Are old versions archived?
-
-How do you get the right data to the right place in the right format?
-
-**Plan and document data flows**
-
-----
-
-
-
-
-----
-
-[](https://youtu.be/_bvrzYOA8dY?t=1452)
-
-
-Molham Aref "[Business Systems with Machine Learning](https://www.youtube.com/watch?v=_bvrzYOA8dY)"
-
----
-# Breakout: Vimeo Videos
-
-As a group, discuss and post in `#lecture`, tagging group members:
-* How to distribute storage:
-* How to design scalable copy-right protection solution:
-* How to design scalable analytics (views, ratings, ...):
-
-[](https://vimeo.com/about)
-
----
-# Excursion: ETL Tools
-
-Extract, tranform, load
-
-**The data engineer's toolbox**
-
-----
-## Data Warehousing (OLAP)
-
-Large denormalized databases with materialized views for large scale reporting queries
-* e.g. sales database, queries for sales trends by region
-
-Read-only except for batch updates: Data from OLTP systems loaded periodically, e.g. over night
-
-
-
-
-Note: Image source: https://commons.wikimedia.org/wiki/File:Data_Warehouse_Feeding_Data_Mart.jpg
-
-----
-## ETL: Extract, Transform, Load
-
-* Transfer data between data sources, often OLTP -> OLAP system
-* Many tools and pipelines
- - Extract data from multiple sources (logs, JSON, databases), snapshotting
- - Transform: cleaning, (de)normalization, transcoding, sorting, joining
- - Loading in batches into database, staging
-* Automation, parallelization, reporting, data quality checking, monitoring, profiling, recovery
-* Many commercial tools
-
-
-Examples of tools in [several](https://www.softwaretestinghelp.com/best-etl-tools/) [lists](https://www.scrapehero.com/best-data-management-etl-tools/)
-
-----
-[](https://www.xplenty.com/)
-
-----
-
-[](https://youtu.be/_bvrzYOA8dY?t=1452)
-
-
-Molham Aref "[Business Systems with Machine Learning](https://www.youtube.com/watch?v=_bvrzYOA8dY)"
-
-
-
----
-# Complexity of Distributed Systems
-
-----
-
-
-
-----
-## Common Distributed System Issues
-
-* Systems may crash
-* Messages take time
-* Messages may get lost
-* Messages may arrive out of order
-* Messages may arrive multiple times
-* Messages may get manipulated along the way
-* Bandwidth limits
-* Coordination overhead
-* Network partition
-* ...
-
-----
-## Types of failure behaviors
-
-* Fail-stop
-* Other halting failures
-* Communication failures
- * Send/receive omissions
- * Network partitions
- * Message corruption
-* Data corruption
-* Performance failures
- * High packet loss rate
- * Low throughput, High latency
-* Byzantine failures
-
-----
-## Common Assumptions about Failures
-
-* Behavior of others is fail-stop
-* Network is reliable
-* Network is semi-reliable but asynchronous
-* Network is lossy but messages are not corrupt
-* Network failures are transitive
-* Failures are independent
-* Local data is not corrupt
-* Failures are reliably detectable
-* Failures are unreliably detectable
-
-----
-## Strategies to Handle Failures
-
-* Timeouts, retry, backup services
-* Detect crashed machines (ping/echo, heartbeat)
-* Redundant + first/voting
-* Transactions
-*
-* Do lost messages matter?
-* Effect of resending message?
-
-----
-## Test Error Handling
-
-* Recall: Testing with stubs
-* Recall: Chaos experiments
-
-
-
-
-
-
-
----
-# Performance Planning and Analysis
-
-----
-## Performance Planning and Analysis
-
-Ideally architectural planning upfront
- * Identify key components and their interactions
- * Estimate performance parameters
- * Simulate system behavior (e.g., queuing theory)
-
-Existing system: Analyze performance bottlenecks
- * Profiling of individual components
- * Performance testing (stress testing, load testing, etc)
- * Performance monitoring of distributed systems
-
-----
-## Performance Analysis
-
-What is the average waiting?
-
-How many customers are waiting on average?
-
-How long is the average service time?
-
-What are the chances of one or more servers being idle?
-
-What is the average utilization of the servers?
-
--> Early analysis of different designs for bottlenecks
-
--> Capacity planning
-
-----
-## Queuing Theory
-
-
-
-Queuing theory deals with the analysis of lines where customers wait to receive a service
-* Waiting at Quiznos
-* Waiting to check-in at an airport
-* Kept on hold at a call center
-* Streaming video over the net
-* Requesting a web service
-
-A queue is formed when request for services outpace the ability of the server(s) to service them immediately
- * Requests arrive faster than they can be processed (unstable queue)
- * Requests do not arrive faster than they can be processed but their processing is delayed by some time (stable queue)
-
-Queues exist because infinite capacity is infinitely expensive and excessive capacity is excessively expensive
-
-
-
-----
-## Queuing Theory
-
-
-
-
-----
-## Analysis Steps (roughly)
-
-Identify system abstraction to analyze (typically architectural level, e.g. services, but also protocols, datastructures and components, parallel processes, networks)
-
-Model connections and dependencies
-
-Estimate latency and capacity per component (measurement and testing, prior systems, estimates, …)
-
-Run simulation/analysis to gather performance curves
-
-Evaluate sensitivity of simulation/analysis to various parameters (‘what-if questions’)
-
-----
-## Simulation (e.g., JMT)
-
-
-
-
-
-
-G.Serazzi Ed. Performance Evaluation Modelling with JMT: learning by examples. Politecnico di Milano - DEI, TR 2008.09, 366 pp., June 2008
-
-----
-## Profiling
-
-Mostly used during development phase in single components
-
-
-
-
-----
-## Performance Testing
-
-* Load testing: Assure handling of maximum expected load
-* Scalability testing: Test with increasing load
-* Soak/spike testing: Overload application for some time, observe stability
-* Stress testing: Overwhelm system resources, test graceful failure + recovery
-*
-* Observe (1) latency, (2) throughput, (3) resource use
-* All automateable; tools like JMeter
-
-----
-## Performance Monitoring of Distr. Systems
-
-[](distprofiler.png)
-
-
-
-Source: https://blog.appdynamics.com/tag/fiserv/
-
-----
-## Performance Monitoring of Distributed Systems
-
-* Instrumentation of (Service) APIs
-* Load of various servers
-* Typically measures: latency, traffic, errors, saturation
-*
-* Monitoring long-term trends
-* Alerting
-* Automated releases/rollbacks
-* Canary testing and A/B testing
-
-
-
-
-
----
-
-# Summary
-
-* Large amounts of data (training, inference, telemetry, models)
-* Distributed storage and computation for scalability
-* Common design patterns (e.g., batch processing, stream processing, lambda architecture)
-* Design considerations: mutable vs immutable data
-* Distributed computing also in machine learning
-* Lots of tooling for data extraction, transformation, processing
-* Many challenges through distribution: failures, debugging, performance, ...
-
-
-Recommended reading: Martin Kleppmann. [Designing Data-Intensive Applications](https://dataintensive.net/). OReilly. 2017.
-
-
-
-
-----
-
-## Further Readings
-
-
-
-* Molham Aref "[Business Systems with Machine Learning](https://www.youtube.com/watch?v=_bvrzYOA8dY)" Invited Talk 2020
-* Sawadogo, Pegdwendé, and Jérôme Darmont. "[On data lake architectures and metadata management](https://hal.archives-ouvertes.fr/hal-03114365/)." Journal of Intelligent Information Systems 56, no. 1 (2021): 97-120.
-* Warren, James, and Nathan Marz. [Big Data: Principles and best practices of scalable realtime data systems](https://bookshop.org/books/big-data-principles-and-best-practices-of-scalable-realtime-data-systems/9781617290343). Manning, 2015.
-* Smith, Jeffrey. [Machine Learning Systems: Designs that Scale](https://bookshop.org/books/machine-learning-systems-designs-that-scale/9781617293337). Manning, 2018.
-* Polyzotis, Neoklis, Sudip Roy, Steven Euijong Whang, and Martin Zinkevich. 2017. “[Data Management Challenges in Production Machine Learning](https://dl.acm.org/doi/pdf/10.1145/3035918.3054782).” In Proceedings of the 2017 ACM International Conference on Management of Data, 1723–26. ACM.
-
-
\ No newline at end of file
diff --git a/lectures/13_dataatscale/datawarehouse.jpg b/lectures/13_dataatscale/datawarehouse.jpg
deleted file mode 100644
index 946ffcb4..00000000
Binary files a/lectures/13_dataatscale/datawarehouse.jpg and /dev/null differ
diff --git a/lectures/13_dataatscale/distprofiler.png b/lectures/13_dataatscale/distprofiler.png
deleted file mode 100644
index 66a0dfab..00000000
Binary files a/lectures/13_dataatscale/distprofiler.png and /dev/null differ
diff --git a/lectures/13_dataatscale/etleverywhere.png b/lectures/13_dataatscale/etleverywhere.png
deleted file mode 100644
index 96234cc8..00000000
Binary files a/lectures/13_dataatscale/etleverywhere.png and /dev/null differ
diff --git a/lectures/13_dataatscale/gfs.png b/lectures/13_dataatscale/gfs.png
deleted file mode 100644
index b60e059d..00000000
Binary files a/lectures/13_dataatscale/gfs.png and /dev/null differ
diff --git a/lectures/13_dataatscale/gphotos.png b/lectures/13_dataatscale/gphotos.png
deleted file mode 100644
index 585309d3..00000000
Binary files a/lectures/13_dataatscale/gphotos.png and /dev/null differ
diff --git a/lectures/13_dataatscale/horizonalpartition.svg b/lectures/13_dataatscale/horizonalpartition.svg
deleted file mode 100644
index 78172554..00000000
--- a/lectures/13_dataatscale/horizonalpartition.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/13_dataatscale/jmt1.png b/lectures/13_dataatscale/jmt1.png
deleted file mode 100644
index 185010b2..00000000
Binary files a/lectures/13_dataatscale/jmt1.png and /dev/null differ
diff --git a/lectures/13_dataatscale/lambda.svg b/lectures/13_dataatscale/lambda.svg
deleted file mode 100644
index 241033f1..00000000
--- a/lectures/13_dataatscale/lambda.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/13_dataatscale/leaderfollowerreplication.svg b/lectures/13_dataatscale/leaderfollowerreplication.svg
deleted file mode 100644
index 86704fa8..00000000
--- a/lectures/13_dataatscale/leaderfollowerreplication.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/13_dataatscale/mapreduce.svg b/lectures/13_dataatscale/mapreduce.svg
deleted file mode 100644
index 230a66d2..00000000
--- a/lectures/13_dataatscale/mapreduce.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/13_dataatscale/microservice.svg b/lectures/13_dataatscale/microservice.svg
deleted file mode 100644
index 09cdf95d..00000000
--- a/lectures/13_dataatscale/microservice.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/13_dataatscale/mlperceptron.svg b/lectures/13_dataatscale/mlperceptron.svg
deleted file mode 100644
index 69feea0c..00000000
--- a/lectures/13_dataatscale/mlperceptron.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/13_dataatscale/parameterserver.png b/lectures/13_dataatscale/parameterserver.png
deleted file mode 100644
index 2cc17a72..00000000
Binary files a/lectures/13_dataatscale/parameterserver.png and /dev/null differ
diff --git a/lectures/13_dataatscale/parameterserver2.png b/lectures/13_dataatscale/parameterserver2.png
deleted file mode 100644
index 98c77f1c..00000000
Binary files a/lectures/13_dataatscale/parameterserver2.png and /dev/null differ
diff --git a/lectures/13_dataatscale/profiler.jpg b/lectures/13_dataatscale/profiler.jpg
deleted file mode 100644
index ca87d36a..00000000
Binary files a/lectures/13_dataatscale/profiler.jpg and /dev/null differ
diff --git a/lectures/13_dataatscale/queuingth.png b/lectures/13_dataatscale/queuingth.png
deleted file mode 100644
index 4125ec1e..00000000
Binary files a/lectures/13_dataatscale/queuingth.png and /dev/null differ
diff --git a/lectures/13_dataatscale/stream-dataflow.svg b/lectures/13_dataatscale/stream-dataflow.svg
deleted file mode 100644
index 19f22a93..00000000
--- a/lectures/13_dataatscale/stream-dataflow.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/13_dataatscale/stream.svg b/lectures/13_dataatscale/stream.svg
deleted file mode 100644
index 601451b2..00000000
--- a/lectures/13_dataatscale/stream.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/13_dataatscale/tshaped.png b/lectures/13_dataatscale/tshaped.png
deleted file mode 100644
index e4b6d35b..00000000
Binary files a/lectures/13_dataatscale/tshaped.png and /dev/null differ
diff --git a/lectures/13_dataatscale/vimeo.png b/lectures/13_dataatscale/vimeo.png
deleted file mode 100644
index 88a8b401..00000000
Binary files a/lectures/13_dataatscale/vimeo.png and /dev/null differ
diff --git a/lectures/13_dataatscale/xplenty.png b/lectures/13_dataatscale/xplenty.png
deleted file mode 100644
index 2b30d2fd..00000000
Binary files a/lectures/13_dataatscale/xplenty.png and /dev/null differ
diff --git a/lectures/14_operations/Kubernetes.png b/lectures/14_operations/Kubernetes.png
deleted file mode 100644
index a446a7a5..00000000
Binary files a/lectures/14_operations/Kubernetes.png and /dev/null differ
diff --git a/lectures/14_operations/classicreleasepipeline.png b/lectures/14_operations/classicreleasepipeline.png
deleted file mode 100644
index 49cbd071..00000000
Binary files a/lectures/14_operations/classicreleasepipeline.png and /dev/null differ
diff --git a/lectures/14_operations/continuous_delivery.gif b/lectures/14_operations/continuous_delivery.gif
deleted file mode 100644
index 30a22de7..00000000
Binary files a/lectures/14_operations/continuous_delivery.gif and /dev/null differ
diff --git a/lectures/14_operations/devops.png b/lectures/14_operations/devops.png
deleted file mode 100644
index 3abb34d2..00000000
Binary files a/lectures/14_operations/devops.png and /dev/null differ
diff --git a/lectures/14_operations/devops_meme.jpg b/lectures/14_operations/devops_meme.jpg
deleted file mode 100644
index ac3b1911..00000000
Binary files a/lectures/14_operations/devops_meme.jpg and /dev/null differ
diff --git a/lectures/14_operations/devops_tools.jpg b/lectures/14_operations/devops_tools.jpg
deleted file mode 100644
index 4140b6d4..00000000
Binary files a/lectures/14_operations/devops_tools.jpg and /dev/null differ
diff --git a/lectures/14_operations/docker_logo.png b/lectures/14_operations/docker_logo.png
deleted file mode 100644
index c08509fe..00000000
Binary files a/lectures/14_operations/docker_logo.png and /dev/null differ
diff --git a/lectures/14_operations/facebookpipeline.png b/lectures/14_operations/facebookpipeline.png
deleted file mode 100644
index 3415f13e..00000000
Binary files a/lectures/14_operations/facebookpipeline.png and /dev/null differ
diff --git a/lectures/14_operations/lfai-landscape.png b/lectures/14_operations/lfai-landscape.png
deleted file mode 100644
index f7fbfbaf..00000000
Binary files a/lectures/14_operations/lfai-landscape.png and /dev/null differ
diff --git a/lectures/14_operations/operations.md b/lectures/14_operations/operations.md
deleted file mode 100644
index 6423af45..00000000
--- a/lectures/14_operations/operations.md
+++ /dev/null
@@ -1,826 +0,0 @@
----
-author: Christian Kaestner and Eunsuk Kang
-title: "MLiP: Planning for Operations"
-semester: Spring 2023
-footer: "Machine Learning in Production/AI Engineering • Christian Kaestner & Eunsuk Kang, Carnegie Mellon University • Spring 2023"
-license: Creative Commons Attribution 4.0 International (CC BY 4.0)
----
-
-
-
-## Machine Learning in Production
-
-
-# Planning for Operations
-
-
----
-## Operations
-
-
-
-
-
-
-----
-## Readings
-
-Required reading: Shankar, Shreya, Rolando Garcia, Joseph M. Hellerstein, and Aditya G. Parameswaran. "[Operationalizing machine learning: An interview study](https://arxiv.org/abs/2209.09125)." arXiv preprint arXiv:2209.09125 (2022).
-
-Recommended readings:
-* O'Leary, Katie, and Makoto Uchida. "[Common problems with Creating Machine Learning Pipelines from Existing Code](https://research.google/pubs/pub48984.pdf)." Proc. Conference on Machine Learning and Systems (MLSys) (2020).
-
-----
-
-# Learning Goals
-
-
-* Deploy a service for models using container infrastructure
-* Automate common configuration management tasks
-* Devise a monitoring strategy and suggest suitable components for implementing it
-* Diagnose common operations problems
-* Understand the typical concerns and concepts of MLOps
-
-
----
-## Running Example: Blogging Platform with Spam Filter
-
-
-
-
-
----
-# "Operations"
-
-----
-## Operations
-
-
-
-Provision and monitor the system in production, respond to problems
-
-Avoid downtime, scale with users, manage operating costs
-
-Heavy focus on infrastructure
-
-Traditionally sysadmin and hardware skills
-
-
-
-
-
-
-
-
-----
-## Service Level Objectives
-
-Quality requirements in operations, such as
-* maximum latency
-* minimum system throughput
-* targeted availability/error rate
-* time to deploy an update
-* durability for storage
-
-Each with typical measures
-
-For the system as a whole or individual services
-
-----
-## Example Service Level Objectives?
-
-
-
-
-
-----
-## Operators on a Team
-
-Operators cannot work in isolation
-
-Rely on developers for software quality and performance
-
-Negotiate service level agreements and budget (e.g., 99.9% vs 99.99% availability)
-
-Risk management role (not risk avoidance)
-
-----
-## Operations and ML
-
-ML has distinct workloads and hardware requirements
-
-Deep learning often pushes scale boundaries
-
-Regular updates or learning in production
-
-
-----
-## Common Themes
-
-Observability is essential
-
-Release management and automated deployments
-
-Infrastructure as code and virtualization
-
-Scaling deployments
-
-Incident response planning
-
-
-
-
----
-# Dev vs. Ops
-
-
-
-----
-## Common Release Problems?
-
-
-
-----
-## Common Release Problems?
-
-
-
-----
-## Common Release Problems (Examples)
-
-* Missing dependencies
-* Different compiler versions or library versions
-* Different local utilities (e.g. unix grep vs mac grep)
-* Database problems
-* OS differences
-* Too slow in real settings
-* Difficult to roll back changes
-* Source from many different repositories
-* Obscure hardware? Cloud? Enough memory?
-
-----
-
-## Developers
-
-
-* Coding
-* Testing, static analysis, reviews
-* Continuous integration
-* Bug tracking
-* Running local tests and scalability experiments
-* ...
-
-
-## Operations
-
-* Allocating hardware resources
-* Managing OS updates
-* Monitoring performance
-* Monitoring crashes
-* Managing load spikes, …
-* Tuning database performance
-* Running distributed at scale
-* Rolling back releases
-* ...
-
-
-
-QA responsibilities in both roles
-
-----
-
-## Quality Assurance does not stop in Dev
-
-* Ensuring product builds correctly (e.g., reproducible builds)
-* Ensuring scalability under real-world loads
-* Supporting environment constraints from real systems (hardware, software, OS)
-* Efficiency with given infrastructure
-* Monitoring (server, database, Dr. Watson, etc)
-* Bottlenecks, crash-prone components, … (possibly thousands of crash reports per day/minute)
-
-
----
-# DevOps
-
-
-----
-## Key ideas and principles
-
-* Better coordinate between developers and operations (collaborative)
-* Key goal: Reduce friction bringing changes from development into production
-* Considering the *entire tool chain* into production (holistic)
-* Documentation and versioning of all dependencies and configurations ("configuration as code")
-* Heavy automation, e.g., continuous delivery, monitoring
-* Small iterations, incremental and continuous releases
-*
-* Buzz word!
-----
-
-
-
-----
-## Common Practices
-
-All configurations in version control
-
-Test and deploy in containers
-
-Automated testing, testing, testing, ...
-
-Monitoring, orchestration, and automated actions in practice
-
-Microservice architectures
-
-Release frequently
-
-----
-## Heavy tooling and automation
-
-[](devops_tools.jpg)
-
-----
-## Heavy tooling and automation -- Examples
-
-* Infrastructure as code — Ansible, Terraform, Puppet, Chef
-* CI/CD — Jenkins, TeamCity, GitLab, Shippable, Bamboo, Azure DevOps
-* Test automation — Selenium, Cucumber, Apache JMeter
-* Containerization — Docker, Rocket, Unik
-* Orchestration — Kubernetes, Swarm, Mesos
-* Software deployment — Elastic Beanstalk, Octopus, Vamp
-* Measurement — Datadog, DynaTrace, Kibana, NewRelic, ServiceNow
-
-
-
-
-
-
----
-# Continuous Delivery
-
-----
-## Manual Release Pipelines
-
-
-
-
-
-Source: https://www.slideshare.net/jmcgarr/continuous-delivery-at-netflix-and-beyond
-
-----
-
-## Continuous Integr.
-
-* Automate tests after commit
-* Independent test infrastructure
-
-## Continuous Delivery
-
-* Full automation from commit to deployable container
-* Heavy focus on testing, reproducibility and rapid feedback, creates transparency
-
-
-## Continuous Deployment
-
-* Full automation from commit to deployment
-* Empower developers, quick to production
-* Encourage experimentation and fast incremental changes
-* Commonly integrated with monitoring and canary releases
-
-
-----
-## Automate Everything
-
-
-----
-## Example: Facebook Tests for Mobile Apps
-
-* Unit tests (white box)
-* Static analysis (null pointer warnings, memory leaks, ...)
-* Build tests (compilation succeeds)
-* Snapshot tests (screenshot comparison, pixel by pixel)
-* Integration tests (black box, in simulators)
-* Performance tests (resource usage)
-* Capacity and conformance tests (custom)
-
-
-Further readings: Rossi, Chuck, Elisa Shibley, Shi Su, Kent Beck, Tony Savor, and Michael Stumm. [Continuous deployment of mobile software at facebook (showcase)](https://research.fb.com/wp-content/uploads/2017/02/fse-rossi.pdf). In Proceedings of the 2016 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering, pp. 12-23. ACM, 2016.
-
-----
-## Release Challenges for Mobile Apps
-
-* Large downloads
-* Download time at user discretion
-* Different versions in production
-* Pull support for old releases?
-*
-* Server side releases silent and quick, consistent
-*
-* -> App as container, most content + layout from server
-
-----
-## Real-world pipelines are complex
-
-[](facebookpipeline.png)
-
-
-
-
-
-
-
-
-
-
----
-
-# Containers and Configuration Management
-----
-## Containers
-
-
-* Lightweight virtual machine
-* Contains entire runnable software, incl. all dependencies and configurations
-* Used in development and production
-* Sub-second launch time
-* Explicit control over shared disks and network connections
-
-
-
-
-
-----
-## Docker Example
-
-```docker
-FROM ubuntu:latest
-MAINTAINER ...
-RUN apt-get update -y
-RUN apt-get install -y python-pip python-dev build-essential
-COPY . /app
-WORKDIR /app
-RUN pip install -r requirements.txt
-ENTRYPOINT ["python"]
-CMD ["app.py"]
-```
-
-
-Source: http://containertutorials.com/docker-compose/flask-simple-app.html
-
-----
-## Common configuration management questions
-
-What runs where?
-
-How are machines connected?
-
-What (environment) parameters does software X require?
-
-How to update dependency X everywhere?
-
-How to scale service X?
-
-----
-## Ansible Examples
-
-* Software provisioning, configuration mgmt., and deployment tool
-* Apply scripts to many servers
-
-
-```ini
-[webservers]
-web1.company.org
-web2.company.org
-web3.company.org
-
-[dbservers]
-db1.company.org
-db2.company.org
-
-[replication_servers]
-...
-```
-
-```yml
-# This role deploys the mongod processes and sets up the replication set.
-- name: create data directory for mongodb
- file: path={{ mongodb_datadir_prefix }}/mongo-{{ inventory_hostname }} state=directory owner=mongod group=mongod
- delegate_to: '{{ item }}'
- with_items: groups.replication_servers
-
-- name: create log directory for mongodb
- file: path=/var/log/mongo state=directory owner=mongod group=mongod
-
-- name: Create the mongodb startup file
- template: src=mongod.j2 dest=/etc/init.d/mongod-{{ inventory_hostname }} mode=0655
- delegate_to: '{{ item }}'
- with_items: groups.replication_servers
-
-
-- name: Create the mongodb configuration file
- template: src=mongod.conf.j2 dest=/etc/mongod-{{ inventory_hostname }}.conf
- delegate_to: '{{ item }}'
- with_items: groups.replication_servers
-
-- name: Copy the keyfile for authentication
- copy: src=secret dest={{ mongodb_datadir_prefix }}/secret owner=mongod group=mongod mode=0400
-
-- name: Start the mongodb service
- command: creates=/var/lock/subsys/mongod-{{ inventory_hostname }} /etc/init.d/mongod-{{ inventory_hostname }} start
- delegate_to: '{{ item }}'
- with_items: groups.replication_servers
-
-- name: Create the file to initialize the mongod replica set
- template: src=repset_init.j2 dest=/tmp/repset_init.js
-
-- name: Pause for a while
- pause: seconds=20
-
-- name: Initialize the replication set
- shell: /usr/bin/mongo --port "{{ mongod_port }}" /tmp/repset_init.js
-```
-
-
-----
-## Puppet Example
-
-Declarative specification, can be applied to many machines
-
-```puppet
-$doc_root = "/var/www/example"
-
-exec { 'apt-get update':
- command => '/usr/bin/apt-get update'
-}
-
-package { 'apache2':
- ensure => "installed",
- require => Exec['apt-get update']
-}
-
-file { $doc_root:
- ensure => "directory",
- owner => "www-data",
- group => "www-data",
- mode => 644
-}
-
-file { "$doc_root/index.html":
- ensure => "present",
- source => "puppet:///modules/main/index.html",
- require => File[$doc_root]
-}
-
-file { "/etc/apache2/sites-available/000-default.conf":
- ensure => "present",
- content => template("main/vhost.erb"),
- notify => Service['apache2'],
- require => Package['apache2']
-}
-
-service { 'apache2':
- ensure => running,
- enable => true
-}
-```
-
-Note: source: https://www.digitalocean.com/community/tutorials/configuration-management-101-writing-puppet-manifests
-
-----
-## Container Orchestration with Kubernetes
-
-Manages which container to deploy to which machine
-
-Launches and kills containers depending on load
-
-Manage updates and routing
-
-Automated restart, replacement, replication, scaling
-
-Kubernetis master controls many nodes
-
-*Substantial complexity and learning curve*
-
-----
-
-
-
-
-
-CC BY-SA 4.0 [Khtan66](https://en.wikipedia.org/wiki/Kubernetes#/media/File:Kubernetes.png)
-----
-## Monitoring
-
-* Monitor server health
-* Monitor service health
-* Monitor telemetry (see past lecture)
-* Collect and analyze measures or log files
-* Dashboards and triggering automated decisions
-*
-* Many tools, e.g., Grafana as dashboard, Prometheus for metrics, Loki + ElasticSearch for logs
-* Push and pull models
-
-----
-
-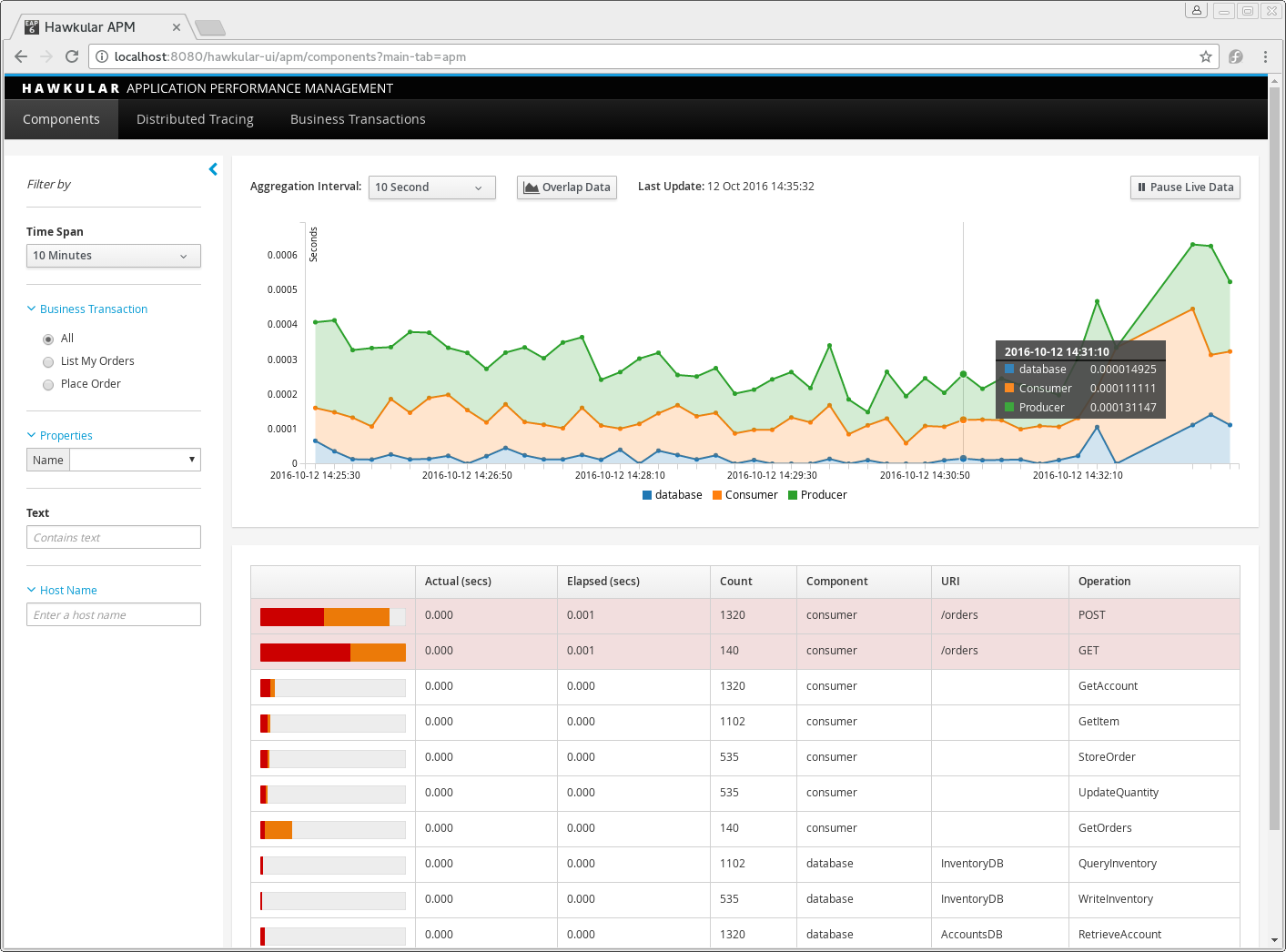
-
-
-https://www.hawkular.org/hawkular-apm/
-
-
-
-
----
-## The DevOps Mindset
-
-* Consider the entire process and tool chain holistically
-* Automation, automation, automation
-* Elastic infrastructure
-* Document, test, and version everything
-* Iterate and release frequently
-* Emphasize observability
-* Shared goals and responsibilities
-
-
-
-
-
----
-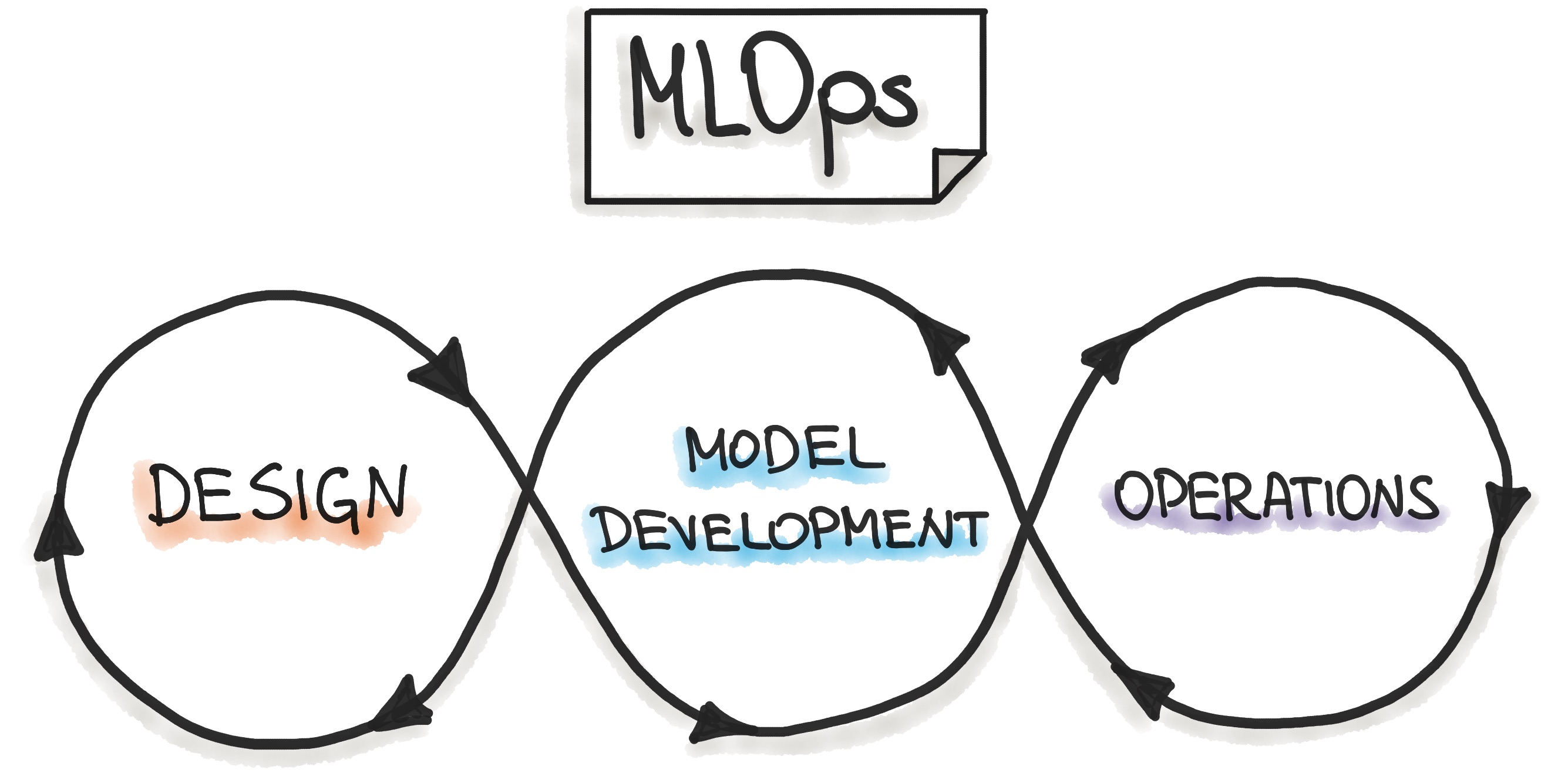
-
-
-
-https://ml-ops.org/
-
-----
-## On Terminology
-
-* Many vague buzzwords, often not clearly defined
-* **MLOps:** Collaboration and communication between data scientists and operators, e.g.,
- - Automate model deployment
- - Model training and versioning infrastructure
- - Model deployment and monitoring
-* **AIOps:** Using AI/ML to make operations decision, e.g. in a data center
-* **DataOps:** Data analytics, often business setting and reporting
- - Infrastructure to collect data (ETL) and support reporting
- - Combines agile, DevOps, Lean Manufacturing ideas
-
-
-
-
-----
-## MLOps Overview
-
-Integrate ML artifacts into software release process, unify process (i.e., DevOps extension)
-
-Automated data and model validation (continuous deployment)
-
-
-Continuous deployment for ML models: from experimenting in notebooks to quick feedback in production
-
-Versioning of models and datasets (more later)
-
-Monitoring in production (discussed earlier)
-
-
-
-Further reading: [MLOps principles
-](https://ml-ops.org/content/mlops-principles.html)
-
-----
-## Tooling Landscape LF AI
-
-[](https://landscape.lfai.foundation/)
-
-
-Linux Foundation AI Initiative
-
-
-----
-## MLOps Goals and Principles
-
-Like DevOps: Automation, testing, holistic, observability, teamwork
-
-Supporting frequent experimentation, rapid prototyping, and constant iteration
-
-3V: Velocity, Validation, Versioning
-
-
-
-----
-## MLOps Tools -- Examples
-
-* Model registry, versioning and metadata: MLFlow, Neptune, ModelDB, WandB, ...
-* Model monitoring: Fiddler, Hydrosphere
-* Data pipeline automation and workflows: DVC, Kubeflow, Airflow
-* Model packaging and deployment: BentoML, Cortex
-* Distributed learning and deployment: Dask, Ray, ...
-* Feature store: Feast, Tecton
-* Integrated platforms: Sagemaker, Valohai, ...
-* Data validation: Cerberus, Great Expectations, ...
-
-Long list: https://github.com/kelvins/awesome-mlops
-
-
-----
-## MLOps Common Goals
-
-Enable experimentation with data and models, small incremental changes; hide complexity from data scientists
-
-Automate (nuanced) model validation (like CI) and integrate with testing in production (monitoring)
-
-Dynamic view of constantly evolving training and test data; invest in data validation
-
-Version data, models; track experiment results
-
-
-
-----
-## Recall: DevOps Mindset
-
-* Consider the entire process and tool chain holistically
-* Automation, automation, automation
-* Elastic infrastructure
-* Document, test, and version everything
-* Iterate and release frequently
-* Emphasize observability
-* Shared goals and responsibilities
-
-
-----
-## Breakout: MLOps Goals
-
-For the blog spam filter scenario, consider DevOps and MLOps infrastructure (CI, CD, containers, config. mgmt, monitoring, model registry, pipeline automation, feature store, data validation, ...)
-
-As a group, tagging group members, post to `#lecture`:
-> * Which DevOps or MLOps goals to prioritize?
-> * Which tools to try?
-
-
-
----
-# Incident Response Planning
-
-----
-## Mistakes will Happen. Be Prepared
-
-Even with careful anticipation and mitigation, mistakes will happen
-
-Anticipated or not
-
-ML as unreliable component raises risks
-
-
-Design mitigations help avoid anticipated mistakes
-
-Incident response plan prepares for unanticipated or unmitigated mistakes
-
-----
-## Incident Response Plan
-
-* Provide contact channel for problem reports
-* Have expert on call
-* Design process for anticipated problems, e.g., rollback, reboot, takedown
-* Prepare for recovery
-* Proactively collect telemetry
-* Investigate incidents
-* Plan public communication (responsibilities)
-
-----
-## Incident Resp. Plan for Blog's Spam Filter?
-
-
-
----
-# Excursion: Organizational Culture
-
-
-
-
-----
-## Organizational Culture
-
-*“this is how we always did things”*
-
-Implicit and explicit assumptions and rules guiding behavior
-
-Often grounded in history, very difficult to change
-
-Examples:
-* Move fast and break things
-* Privacy first
-* Development opportunities for all employees
-
-
-----
-
-
-
-
-Source: Bonkers World
-
-
-----
-## Organizational Culture
-
-
-
-
-
-
-----
-## Levels of Organizational Culture
-
-
-Artifacts -- What we see
-* Behaviors, systems, processes, policies
-
-Espoused Values -- What we say
-* Ideals, goals, values, aspirations
-
-Basic assumptions -- What we believe
-* Underlying assumptions, "old ways of doing things", unconsciously taken for granted
-
-
-Iceberg models: Only artifacts and espoused values visible, but practices driven by invisible basic assumptions
-
-
-----
-## Culture Change
-
-Changing organizational culture is very difficult
-
-Top down: espoused values, management buy in, incentives
-
-Bottom up: activism, show value, spread
-
-
-**Examples of success of failure stories?**
-
-----
-## MLOps Culture
-
-Dev with Ops instead of Dev vs Ops
-
-A culture of collaboration, joint goals, joint responsibilities
-
-Artifacts: Joint tools, processes
-
-Underlying assumptions: Devs provide production-ready code; Ops focus on value, automation is good, observability is important, ...
-
-----
-## Resistance to DevOps Culture?
-
-From "us vs them" to blameless culture -- How?
-
-Introduction of new tools and processes -- Disruptive? Costly? Competing with current tasks? Who wants to write tests?
-
-Future benefits from rapid feedback and telemetry -- Unrealistic?
-
-Automation and shifting responsibilities -- Hiring freeze and layoffs?
-
-Past experience with poor adoption -- All costs, no benefits? Compliance only?
-
-
-----
-## Successful DevOps Adoption
-
-Need supportive management; typically driven by advocacy of individuals, convincing colleagues and management
-
-Education to generate buy-in
-
-Experts and consultants can help with initial costly transition
-
-Demonstrate benefits on small project, promote afterward
-
-Focus on key bottlenecks, over perfect adoption (e.g., prioritize experimentation, test automation, rapid feedback with telemetry)
-
-
-Luz, Welder Pinheiro, Gustavo Pinto, and Rodrigo Bonifácio. “[Adopting DevOps in the real world: A theory, a model, and a case study](http://gustavopinto.org/lost+found/jss2019.pdf).” Journal of Systems and Software 157 (2019): 110384.
-
-
----
-# Summary
-
-* Plan for change, plan for operations
-* Operations requirements: service level objectives
-* DevOps integrations development and operations tasks with joint goals and tools
- * Heavy automation
- * Continuous integration and continuous delivery
- * Containers and configuration management
- * Monitoring
-* MLOps extends this to operating pipelines and deploying models
-* Organizational culture is slow and difficult to change
-
-----
-## Further Reading
-
-
-
-* Shankar, Shreya, Rolando Garcia, Joseph M. Hellerstein, and Aditya G. Parameswaran. "[Operationalizing machine learning: An interview study](https://arxiv.org/abs/2209.09125)." arXiv preprint arXiv:2209.09125 (2022).
-* https://ml-ops.org/
-* Beyer, Betsy, Chris Jones, Jennifer Petoff, and Niall Richard Murphy. [Site reliability engineering: How Google runs production systems](https://sre.google/sre-book/table-of-contents/). O’Reilly, 2016.
-* Kim, Gene, Jez Humble, Patrick Debois, John Willis, and Nicole Forsgren. [The DevOps Handbook: How to Create World-Class Agility, Reliability, & Security in Technology Organizations](https://bookshop.org/books/the-devops-handbook-how-to-create-world-class-agility-reliability-security-in-technology-organizations/9781950508402). IT Revolution, 2nd ed, 2021.
-* Treveil, Mark, Nicolas Omont, Clément Stenac, Kenji Lefevre, Du Phan, Joachim Zentici, Adrien Lavoillotte, Makoto Miyazaki, and Lynn Heidmann. [Introducing MLOps: How to Scale Machine Learning in the Enterprise](https://bookshop.org/books/introducing-mlops-how-to-scale-machine-learning-in-the-enterprise/9781492083290). O’Reilly, 2020.
-* Luz, Welder Pinheiro, Gustavo Pinto, and Rodrigo Bonifácio. “[Adopting DevOps in the real world: A theory, a model, and a case study](http://gustavopinto.org/lost+found/jss2019.pdf).” Journal of Systems and Software 157 (2019): 110384.
-* Schein, Edgar H. *Organizational culture and leadership*. 5th ed. John Wiley & Sons, 2016.
-
\ No newline at end of file
diff --git a/lectures/14_operations/orgchart.png b/lectures/14_operations/orgchart.png
deleted file mode 100644
index 6df71aa3..00000000
Binary files a/lectures/14_operations/orgchart.png and /dev/null differ
diff --git a/lectures/14_operations/orgculture.jpg b/lectures/14_operations/orgculture.jpg
deleted file mode 100644
index 71b95468..00000000
Binary files a/lectures/14_operations/orgculture.jpg and /dev/null differ
diff --git a/lectures/14_operations/srebook.jpg b/lectures/14_operations/srebook.jpg
deleted file mode 100644
index cc6e1f24..00000000
Binary files a/lectures/14_operations/srebook.jpg and /dev/null differ
diff --git a/lectures/14_operations/substack.png b/lectures/14_operations/substack.png
deleted file mode 100644
index 276871f3..00000000
Binary files a/lectures/14_operations/substack.png and /dev/null differ
diff --git a/lectures/15_process/accuracy-improvements.png b/lectures/15_process/accuracy-improvements.png
deleted file mode 100644
index 455cb820..00000000
Binary files a/lectures/15_process/accuracy-improvements.png and /dev/null differ
diff --git a/lectures/15_process/combinedprocess1.png b/lectures/15_process/combinedprocess1.png
deleted file mode 100644
index e240816d..00000000
Binary files a/lectures/15_process/combinedprocess1.png and /dev/null differ
diff --git a/lectures/15_process/combinedprocess2.png b/lectures/15_process/combinedprocess2.png
deleted file mode 100644
index 61872865..00000000
Binary files a/lectures/15_process/combinedprocess2.png and /dev/null differ
diff --git a/lectures/15_process/combinedprocess5.svg b/lectures/15_process/combinedprocess5.svg
deleted file mode 100644
index 25207d46..00000000
--- a/lectures/15_process/combinedprocess5.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/15_process/components.png b/lectures/15_process/components.png
deleted file mode 100644
index ebe25114..00000000
Binary files a/lectures/15_process/components.png and /dev/null differ
diff --git a/lectures/15_process/crispdm.png b/lectures/15_process/crispdm.png
deleted file mode 100644
index bf0e4547..00000000
Binary files a/lectures/15_process/crispdm.png and /dev/null differ
diff --git a/lectures/15_process/data-science-process.jpg b/lectures/15_process/data-science-process.jpg
deleted file mode 100644
index aca8d96f..00000000
Binary files a/lectures/15_process/data-science-process.jpg and /dev/null differ
diff --git a/lectures/15_process/debt.png b/lectures/15_process/debt.png
deleted file mode 100644
index 47dbe67a..00000000
Binary files a/lectures/15_process/debt.png and /dev/null differ
diff --git a/lectures/15_process/defectcost.jpg b/lectures/15_process/defectcost.jpg
deleted file mode 100644
index f6dc5588..00000000
Binary files a/lectures/15_process/defectcost.jpg and /dev/null differ
diff --git a/lectures/15_process/developers-processes.jpeg b/lectures/15_process/developers-processes.jpeg
deleted file mode 100644
index 3628a947..00000000
Binary files a/lectures/15_process/developers-processes.jpeg and /dev/null differ
diff --git a/lectures/15_process/dodprocess.jpg b/lectures/15_process/dodprocess.jpg
deleted file mode 100644
index 08860d39..00000000
Binary files a/lectures/15_process/dodprocess.jpg and /dev/null differ
diff --git a/lectures/15_process/facebook1.jpeg b/lectures/15_process/facebook1.jpeg
deleted file mode 100644
index cf395b73..00000000
Binary files a/lectures/15_process/facebook1.jpeg and /dev/null differ
diff --git a/lectures/15_process/facebook2.jpeg b/lectures/15_process/facebook2.jpeg
deleted file mode 100644
index 5245a62f..00000000
Binary files a/lectures/15_process/facebook2.jpeg and /dev/null differ
diff --git a/lectures/15_process/healthcare.gov-crash.png b/lectures/15_process/healthcare.gov-crash.png
deleted file mode 100644
index f382e769..00000000
Binary files a/lectures/15_process/healthcare.gov-crash.png and /dev/null differ
diff --git a/lectures/15_process/notebook-example.png b/lectures/15_process/notebook-example.png
deleted file mode 100644
index 2b614ce0..00000000
Binary files a/lectures/15_process/notebook-example.png and /dev/null differ
diff --git a/lectures/15_process/process.md b/lectures/15_process/process.md
deleted file mode 100644
index f31a2cd3..00000000
--- a/lectures/15_process/process.md
+++ /dev/null
@@ -1,801 +0,0 @@
----
-author: Christian Kaestner
-title: "MLiP: Process and Technical Debt"
-semester: Spring 2023
-footer: "Machine Learning in Production/AI Engineering • Christian Kaestner & Eunsuk Kang, Carnegie Mellon University • Spring 2023"
-license: Creative Commons Attribution 4.0 International (CC BY 4.0)
----
-
-
-
-## Machine Learning in Production
-
-# Process and Technical Debt
-
-
-
-
----
-## Process...
-
-
-
-
-
-----
-
-## Readings
-
-
-
-Required Reading:
-* Sculley, David, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, Michael Young, Jean-Francois Crespo, and Dan Dennison. "[Hidden technical debt in machine learning systems](http://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf)." In Advances in neural information processing systems, pp. 2503-2511. 2015.
-
-Suggested Readings:
-* Fowler and Highsmith. [The Agile Manifesto](http://agilemanifesto.org/)
-* Steve McConnell. Software project survival guide. Chapter 3
-* Kruchten, Philippe, Robert L. Nord, and Ipek Ozkaya. "[Technical debt: From metaphor to theory and practice](https://resources.sei.cmu.edu/asset_files/WhitePaper/2012_019_001_58818.pdf)." IEEE Software 29, no. 6 (2012): 18-21.
-
-
-
-----
-
-## Learning Goals
-
-
-
-
-* Overview of common data science workflows (e.g., CRISP-DM)
- * Importance of iteration and experimentation
- * Role of computational notebooks in supporting data science workflows
-* Overview of software engineering processes and lifecycles: costs and benefits of process, common process models, role of iteration and experimentation
-* Contrasting data science and software engineering processes, goals and conflicts
-* Integrating data science and software engineering workflows in process model for engineering AI-enabled systems with ML and non-ML components; contrasting different kinds of AI-enabled systems with data science trajectories
-* Overview of technical debt as metaphor for process management; common sources of technical debt in AI-enabled systems
-
-
-
----
-## Case Study: Real-Estate Website
-
-
-
-
-
-----
-## ML Component: Predicting Real Estate Value
-
-Given a large database of house sales and statistical/demographic data from public records, predict the sales price of a house.
-
-
-$f(size, rooms, tax, neighborhood, ...) \rightarrow price$
-
-
-
-
-
-----
-## What's your process?
-
-**Q. What steps would you take to build this component?**
-
-
-
-----
-## Exploratory Questions
-
-* What exactly are we trying to model and predict?
-* What types of data do we need?
-* What type of model works the best for this problem?
-* What are the right metrics to evaluate the model performance?
-* What is the user actually interested in seeing?
-* Will this product actually help with the organizational goals?
-* ...
-
----
-# Data Science: Iteration and Exploration
-
-
-----
-## Data Science is Iterative and Exploratory
-
-
-
-
-
-Source: Guo. "[Data Science Workflow: Overview and Challenges](https://cacm.acm.org/blogs/blog-cacm/169199-data-science-workflow-overview-and-challenges/fulltext)." Blog@CACM, Oct 2013
-
-
-----
-## Data Science is Iterative and Exploratory
-
-
-
-
-
-
-
-Martínez-Plumed et al. "[CRISP-DM Twenty Years Later: From Data Mining Processes to Data Science Trajectories](https://research-information.bris.ac.uk/files/220614618/TKDE_Data_Science_Trajectories_PF.pdf)." IEEE Transactions on Knowledge and Data Engineering (2019).
-
-----
-## Data Science is Iterative and Exploratory
-
-[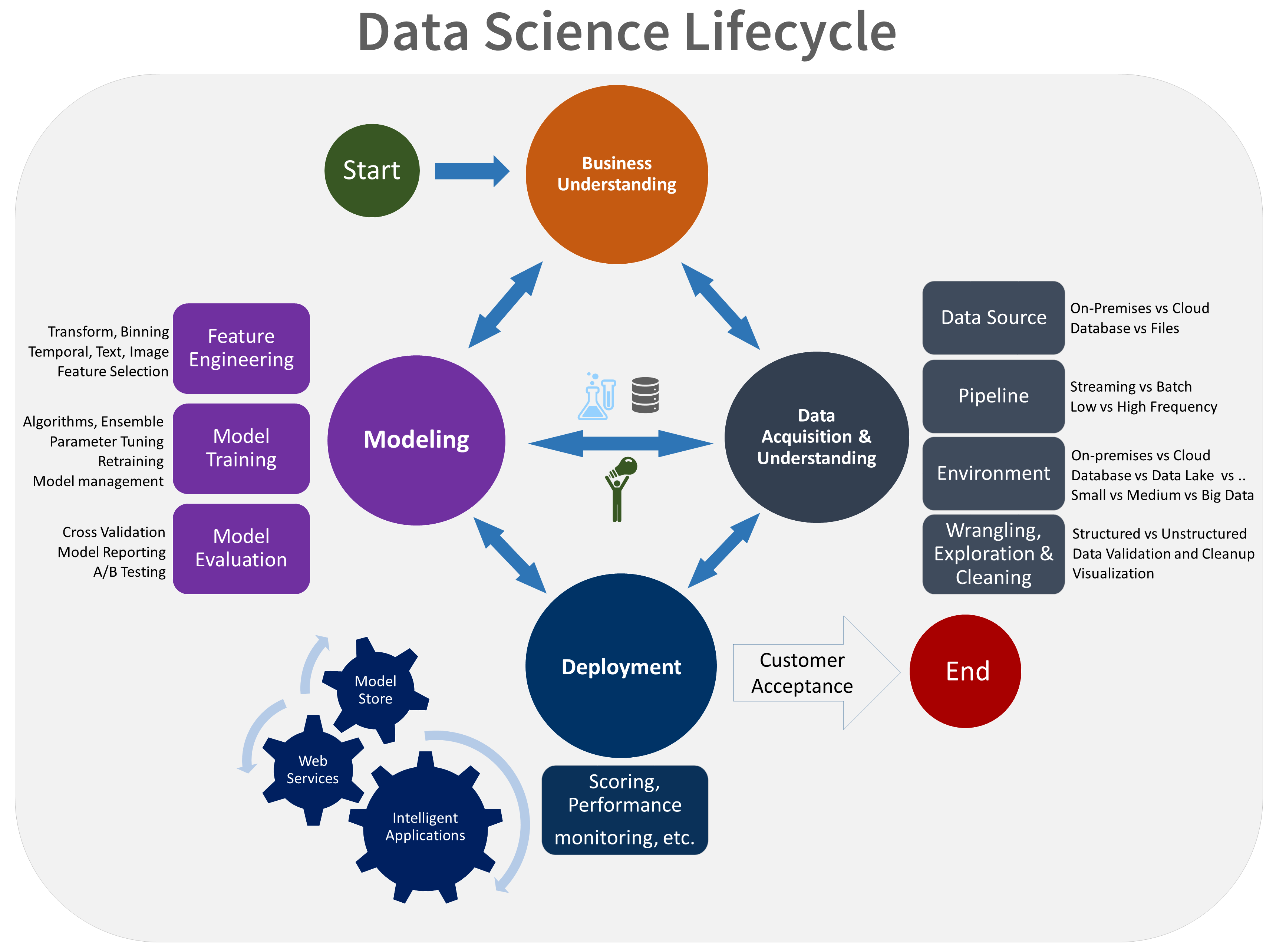](https://docs.microsoft.com/en-us/azure/machine-learning/team-data-science-process/media/overview/tdsp-lifecycle2.png)
-
-
-
-Microsoft Azure Team, "[What is the Team Data Science Process?](https://docs.microsoft.com/en-us/azure/machine-learning/team-data-science-process/overview)" Microsoft Doc., Jan 2020
-
-
-
-----
-## Data Science is Iterative and Exploratory
-
-[](accuracy-improvements.png)
-
-
-
-Source: Patel, Kayur, James Fogarty, James A. Landay, and Beverly Harrison. "[Investigating statistical machine learning as a tool for software development](http://www.kayur.org/papers/chi2008.pdf)." In Proc. CHI, 2008.
-
-Notes:
-This figure shows the result from a controlled experiment in which participants had 2 sessions of 2h each to build a model. Whenever the participants evaluated a model in the process, the accuracy is recorded. These plots show the accuracy improvements over time, showing how data scientists make incremental improvements through frequent iteration.
-
-
-
-----
-## Data Science is Iterative and Exploratory
-
-
-Science mindset: start with rough goal, no clear specification, unclear whether possible
-
-Heuristics and experience to guide the process
-
-Try and error, refine iteratively, hypothesis testing
-
-Go back to data collection and cleaning if needed, revise goals
-
-
-----
-## Share Experience?
-
-
-
-
-----
-## Different Trajectories
-
-
-
-
-
-
-
-Martínez-Plumed et al. "[CRISP-DM Twenty Years Later: From Data Mining Processes to Data Science Trajectories](https://research-information.bris.ac.uk/files/220614618/TKDE_Data_Science_Trajectories_PF.pdf)." IEEE Transactions on Knowledge and Data Engineering (2019).
-
-----
-## Different Trajectories
-
-
-
-
-
-From: Martínez-Plumed et al. "[CRISP-DM Twenty Years Later: From Data Mining Processes to Data Science Trajectories](https://research-information.bris.ac.uk/files/220614618/TKDE_Data_Science_Trajectories_PF.pdf)." IEEE Transactions on Knowledge and Data Engineering (2019).
-
-Notes:
-
-* A product to recommend trips connecting tourist attractions in a town may be based on location tracking data collected by navigation and mapping apps. To build such a project, one might start with a concrete goal in mind and explore whether enough user location history data is available or can be acquired. One would then go through traditional data preparation and modeling stages before exploring how to best present the results to users.
-* An insurance company tries to improve their model to score the risk of drivers based on their behavior and sensors in their cars. Here an existing product is to be refined and a better understanding of the business case is needed before diving into the data exploration and modeling. The team might spend significant time in exploring new data sources that may provide new insights and may debate the cost and benefits of this data or data gathering strategy (e.g., installing sensors in customer cars).
-* A credit card company may want to sell data about what kind of products different people (nationalities) tend to buy at different times and days in different locations to other companies (retailers, restaurants). They may explore existing data without yet knowing what kind of data may be of interest to what kind of customers. They may actively search for interesting narratives in the data, posing questions such as “Ever wondered when the French buy their food?” or “Which places the Germans flock to on their holidays?” in promotional material.
-
-
-----
-## Computational Notebooks
-
-
-
-
-
-* Origins in "literate programming", interleaving text and code, treating programs as literature (Knuth'84)
-* First notebook in Wolfram Mathematica 1.0 in 1988
-* Document with text and code cells, showing execution results under cells
-* Code of cells is executed, per cell, in a kernel
-* Many notebook implementations and supported languages, Python + Jupyter currently most popular
-
-
-
-
-
-
-
-
-
-
-Notes:
-* See also https://en.wikipedia.org/wiki/Literate_programming
-* Demo with public notebook, e.g., https://colab.research.google.com/notebooks/mlcc/intro_to_pandas.ipynb
-
-----
-## Notebooks Support Iteration and Exploration
-
-Quick feedback, similar to REPL
-
-Visual feedback including figures and tables
-
-Incremental computation: reexecuting individual cells
-
-Quick and easy: copy paste, no abstraction needed
-
-Easy to share: document includes text, code, and results
-
-----
-## Brief Discussion: Notebook Limitations and Drawbacks?
-
-
-
-
-
-
----
-
-# Software Engineering Process
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-----
-
-## Software Process
-
-> “The set of activities and associated results that produce a software product”
-
-> A structured, systematic way of carrying out these activities
-
-**Q. Examples?**
-
-Notes:
-
-Writing down all requirements
-Require approval for all changes to requirements
-Use version control for all changes
-Track all reported bugs
-Review requirements and code
-Break down development into smaller tasks and schedule and monitor them
-Planning and conducting quality assurance
-Have daily status meetings
-Use Docker containers to push code between developers and operation
-
-----
-## Developers dislike processes
-
-
-
-
-----
-
-
-
-----
-
-
-
-----
-## Developers' view of processes
-
-
-
-
-Notes: Complicated processes like these are often what people associate with "process". Software process is needed, but does not
-need to be complicated.
-
-----
-## What developers want
-
-
-
-
-Notes: Visualization following McConnell, Steve. Software project survival guide. Pearson Education, 1998.
-
-----
-## What developers want
-
-
-
-
-Notes: Idea: spent most of the time on coding, accept a little rework
-
-----
-## What developers think of processes
-
-
-
-
-Notes: negative view of process. pure overhead, reduces productive
-work, limits creativity
-
-----
-## What eventually happens anyway
-
-
-
-
-Notes: Real experience if little attention is payed to process: increasingly complicated, increasing rework; attempts to rescue by introducing process
-
-----
-## Survival Mode
-
-Missed deadlines -> "solo development mode" to meet own deadlines
-
-Ignore integration work
-
-Stop interacting with testers, technical writers, managers, ...
-
--> Results in further project delays, added costs, poor product quality...
-
-
-
-McConnell, Steve. Software project survival guide. Pearson Education, 1998.
-
-----
-## Example of Process Problems?
-
-
-
-Notes:
-Collect examples of what could go wrong:
-
-Change Control: Mid-project informal agreement to changes suggested by customer or manager. Project scope expands 25-50%
-Quality Assurance: Late detection of requirements and design issues. Test-debug-reimplement cycle limits development of new features. Release with known defects.
-Defect Tracking: Bug reports collected informally, forgotten
-System Integration: Integration of independently developed components at the very end of the project. Interfaces out of sync.
-Source Code Control: Accidentally overwritten changes, lost work.
-Scheduling: When project is behind, developers are asked weekly for new estimates.
-
-
-----
-## Example: Helthcare.gov
-
-
-
-* Launched Oct, 2013; high demand (5x expected) causes site crash
-* UI incomplete (e.g., missing drop-down menu); missing/incomplete
-insurance data; log-in system also crashed for IT technicians
-* On 1st day, 6 users managed to register
-* Initial budget: 93.7M USD; Final cost: 1.7B
-
-
-----
-## Example: Helthcare.gov
-
-
-* Lack of experience: _"...and project managers had little knowledge on
- the amount of work required and typical product development
- processes"_
-* Lack of leadership: _"...no formal division of responsibilities in
-place...a lack of communication when key decisions were made"_
-* Schedule pressure: _"...employees were pressured to launch on
- time regardless of completion or the amount (and results) of testing"_
-
-
-[The Failed Launch Of www.HealthCare.gov](https://d3.harvard.edu/platform-rctom/submission/the-failed-launch-of-www-healthcare-gov/)
-
-
-
-
-
-
-
-
-
-
-
-
-
-----
-*Hypothesis: Process increases flexibility and efficiency + Upfront investment for later greater returns*
-
-
-
-
-Notes: ideal setting of little process investment upfront
-
-----
-
-
-Notes: Empirically well established rule: Bugs are increasingly expensive to fix the larger the distance between the phase where they are created vs where they are corrected.
-
-
-
----
-# Software Process Models
-
-
-----
-
-## Ad-hoc Processes
-
-1. Discuss the software that needs to be written
-2. Write some code
-3. Test the code to identify the defects
-4. Debug to find causes of defects
-5. Fix the defects
-6. If not done, return to step 1
-
-
-----
-## Waterfall Model
-
-
-
-
-Understand requirements, plan & design before coding, test & deploy
-
-Notes: Although dated, the key idea is still essential -- think and plan before implementing. Not all requirements and design can be made upfront, but planning is usually helpful.
-
-----
-## Problems with Waterfall?
-
-
-
-----
-## Risk First: Spiral Model
-
-
-
-
-Incremental prototypes, starting with most risky components
-
-----
-## Constant iteration: Agile
-
-
-
-
-* Constant interactions with customers, constant replanning
-* Scrum: Break into _sprints_; daily meetings, sprint reviews, planning
-
-
-(Image CC BY-SA 4.0, Lakeworks)
-
-
-----
-## Selecting Process Models
-
-Individually, vote in slack:
-[1] Ad-hoc
-[2] Waterfall
-[3] Spiral
-[4] Agile
-
-and write a short justification in `#lecture`
-
-
-
-
-
-
-
----
-# Data Science vs Software Engineering
-
-
-----
-## Discussion: Iteration in Notebook vs Agile?
-
-
-[](accuracy-improvements.png)
-
-
-
-
-(CC BY-SA 4.0, Lakeworks)
-
-
-Note: There is similarity in that there is an iterative process,
-but the idea is different and the process model seems mostly orthogonal
-to iteration in data science.
-The spiral model prioritizes risk, especially when it is not clear
-whether a model is feasible. One can do similar things in model development, seeing whether it is feasible with data at hand at all and build an early
-prototype, but it is not clear that an initial okay model can be improved
-incrementally into a great one later.
-Agile can work with vague and changing requirements, but that again seems
-to be a rather orthogonal concern. Requirements on the product are not so
-much unclear or changing (the goal is often clear), but it's not clear
-whether and how a model can solve it.
-
-----
-## Poor Software Engineering Practices in Notebooks?
-
-
-
-
-*
-* Little abstraction
-* Global state
-* No testing
-* Heavy copy and paste
-* Little documentation
-* Poor version control
-* Out of order execution
-* Poor development features (vs IDE)
-
-
-
-----
-## Understanding Data Scientist Workflows
-
-Instead of blindly recommended "SE Best Practices" understand context
-
-Documentation and testing not a priority in exploratory phase
-
-Help with transitioning into practice
-* From notebooks to pipelines
-* Support maintenance and iteration once deployed
-* Provide infrastructure and tools
-
-----
-## Data Science Practices by Software Eng.
-
-
-
-* Many software engineers get involved in data science without explicit training
-* Copying from public examples, little reading of documentation
-* Lack of data visualization/exploration/understanding, no focus on data quality
-* Strong preference for code editors, non-GUI tools
-* Improve model by adding more data or changing models, rarely feature engineering or debugging
-* Lack of awareness about overfitting/bias problems, single focus on accuracy, no monitoring
-* More system thinking about the product and its needs
-
-
-
-
-
-Yang, Qian, Jina Suh, Nan-Chen Chen, and Gonzalo Ramos. "[Grounding interactive machine learning tool design in how non-experts actually build models](http://www.audentia-gestion.fr/MICROSOFT/Machine_Teaching_DIS_18.pdf)." In *Proceedings of the 2018 Designing Interactive Systems Conference*, pp. 573-584. 2018.
-
-----
-
-
-
----
-# Integrated Process for AI-Enabled Systems
-
-----
-
-
-
-
-Figure from Dogru, Ali H., and Murat M. Tanik. “A process model for component-oriented software engineering.” IEEE Software 20, no. 2 (2003): 34–41.
-
-----
-
-
-
-----
-## Recall: ML models are system components
-
-
-
-
-----
-
-
-
-----
-
-
-
-----
-
-
-
-----
-## Process for AI-Enabled Systems
-
-
-
-
-* Integrate Software Engineering and Data Science processes
-* Establish system-level requirements (e.g., user needs, safety, fairness)
-* Inform data science modeling with system requirements (e.g., privacy, fairness)
-* Try risky parts first (most likely include ML components; ~spiral)
-* Incrementally develop prototypes, incorporate user feedback (~agile)
-* Provide flexibility to iterate and improve
-* Design system with characteristics of AI component (e.g., UI design, safeguards)
-* Plan for testing throughout the process and in production
-* Manage project understanding both software engineering and data science workflows
-*
-* __No existing "best practices" or workflow models__
-
-
-
-----
-## Trajectories
-
-Not every project follows the same development process, e.g.
-* Small ML addition: Product first, add ML feature later
-* Research only: Explore feasibility before thinking about a product
-* Data science first: Model as central component of potential product, build system around it
-
-Different focus on system requirements, qualities, and upfront planning
-
-Manage interdisciplinary teams and different expectations
-
-
-
----
-# Technical debt
-
-
-[](https://www.monkeyuser.com/2018/tech-debt/)
-
-
-----
-## Technical Debt Metaphor
-
-Analogy to financial debt
-+ Make a decision for an immediate benefit (e.g., release now)
-+ Accepting later cost (loss of productivity, higher maintenance and operating cost, rework)
-+ Debt accumulates and can suffocate project
-
-Ideally, a deliberate decision (short term tactical or long term strategic)
-
-Ideally, track debt and plan for paying it down later
-
-**Q. Examples?**
-
-----
-
-
-
-Source: Martin Fowler 2009, https://martinfowler.com/bliki/TechnicalDebtQuadrant.html
-
-----
-## Technical Debt: Examples
-
-Prudent & deliberate: Skip using a CI platform
-* Reason for debt: Short deadline; test the product viability with
- alpha users using a prototype
-* Debt payback: Refactoring effort to integrate the system into CI
-
-Reckless & inadvertent: Forget to encrypt user credentials in DB
-* Reason for debt: Lack of in-house security expertise
-* Debt payback: Security vulnerabilities & fallouts from an attack
- (loss of data);
- effort to retrofit security into the system
-
-----
-## Breakout: Technical Debt from ML
-
-As a group in `#lecture`, tagging members: Post two plausible examples technical debt in housing price prediction system:
- 1. Deliberate, prudent:
- 2. Reckless, inadvertent:
-
-
-
-
-
-Sculley, David, et al. [Hidden technical debt in machine learning systems](http://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf). Advances in Neural Information Processing Systems. 2015.
-
-----
-
-## Technical Debt through Notebooks?
-
-> Jupyter Notebooks are a gift from God to those who work with data. They allow us to do quick experiments with Julia, Python, R, and more -- [John Paul Ada](https://towardsdatascience.com/no-hassle-machine-learning-experiments-with-azure-notebooks-e1a22e8782c3)
-
-
-
-
-Notes: Discuss benefits and drawbacks of Jupyter style notebooks
-
-----
-
-## ML and Technical Debt
-
-**Often reckless and inadvertent in inexperienced teams**
-
-ML can seem like an easy addition, but it may cause long-term costs
-
-Needs to be maintained, evolved, and debugged
-
-Goals may change, environment may change, some changes are subtle
-
-----
-## Example problems: ML and Technical Debt
-
-- Systems and models are tangled and changing one has cascading effects on the other
-- Untested, brittle infrastructure; manual deployment
-- Unstable data dependencies, replication crisis
-- Data drift and feedback loops
-- Magic constants and dead experimental code paths
-
-
-Further reading: Sculley, David, et al. [Hidden technical debt in machine learning systems](http://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf). Advances in Neural Information Processing Systems. 2015.
-
-
-----
-## Controlling Technical Debt from ML Components
-
-
-
-
-----
-## Controlling Technical Debt from ML Components
-
-
-
-* Avoid AI when not needed
-* Understand and document requirements, design for mistakes
-* Build reliable and maintainable pipelines, infrastructure, good engineering practices
-* Test infrastructure, system testing, testing and monitoring in production
-* Test and monitor data quality
-* Understand and model data dependencies, feedback loops, ...
-* Document design intent and system architecture
-* Strong interdisciplinary teams with joint responsibilities
-* Document and track technical debt
-* ...
-
-
-
-----
-
-
-
----
-# Summary
-
-Data scientists and software engineers follow different processes
-
-ML projects need to consider process needs of both
-
-Iteration and upfront planning are both important, process models codify good practices
-
-Deliberate technical debt can be good, too much debt can suffocate a project
-
-Easy to amount (reckless) technical debt with machine learning
-
----
-## Further Reading
-
-
-
-* 🗎 Sculley, David, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, Michael Young, Jean-Francois Crespo, and Dan Dennison. "[Hidden technical debt in machine learning systems](http://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf)." In Advances in neural information processing systems, pp. 2503-2511. 2015.
-* 🗎 Studer, Stefan, Thanh Binh Bui, Christian Drescher, Alexander Hanuschkin, Ludwig Winkler, Steven Peters, and Klaus-Robert Mueller. "[Towards CRISP-ML (Q): A Machine Learning Process Model with Quality Assurance Methodology](https://arxiv.org/abs/2003.05155)." arXiv preprint arXiv:2003.05155 (2020).
-* 🗎 Martínez-Plumed, Fernando, et al. "[CRISP-DM Twenty Years Later: From Data Mining Processes to Data Science Trajectories](https://research-information.bris.ac.uk/files/220614618/TKDE_Data_Science_Trajectories_PF.pdf)." IEEE Transactions on Knowledge and Data Engineering (2019).
-* 📰 Kaestner, Christian. [On the process for building software with ML components](https://ckaestne.medium.com/on-the-process-for-building-software-with-ml-components-c54bdb86db24). Blog Post, 2020
-
-
-
-
-----
-## Further Reading 2
-
-
-
-* 🗎 Patel, Kayur, James Fogarty, James A. Landay, and Beverly Harrison. "[Investigating statistical machine learning as a tool for software development](http://www.kayur.org/papers/chi2008.pdf)." In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pp. 667-676. 2008.
-* 🗎 Yang, Qian, Jina Suh, Nan-Chen Chen, and Gonzalo Ramos. "[Grounding interactive machine learning tool design in how non-experts actually build models](http://www.audentia-gestion.fr/MICROSOFT/Machine_Teaching_DIS_18.pdf)." In *Proceedings of the 2018 Designing Interactive Systems Conference*, pp. 573-584. 2018.
-* 📰 Fowler and Highsmith. [The Agile Manifesto](http://agilemanifesto.org/)
-* 🕮 Steve McConnell. Software project survival guide. Chapter 3
-* 🕮 Pfleeger and Atlee. Software Engineering: Theory and Practice. Chapter 2
-* 🗎 Kruchten, Philippe, Robert L. Nord, and Ipek Ozkaya. "[Technical debt: From metaphor to theory and practice](https://resources.sei.cmu.edu/asset_files/WhitePaper/2012_019_001_58818.pdf)." IEEE Software 29, no. 6 (2012): 18-21.
-
diff --git a/lectures/15_process/process1.png b/lectures/15_process/process1.png
deleted file mode 100644
index 17088cd0..00000000
Binary files a/lectures/15_process/process1.png and /dev/null differ
diff --git a/lectures/15_process/process2.png b/lectures/15_process/process2.png
deleted file mode 100644
index 93281149..00000000
Binary files a/lectures/15_process/process2.png and /dev/null differ
diff --git a/lectures/15_process/process3.png b/lectures/15_process/process3.png
deleted file mode 100644
index 47aa2950..00000000
Binary files a/lectures/15_process/process3.png and /dev/null differ
diff --git a/lectures/15_process/process4.png b/lectures/15_process/process4.png
deleted file mode 100644
index 4113b23d..00000000
Binary files a/lectures/15_process/process4.png and /dev/null differ
diff --git a/lectures/15_process/process5.png b/lectures/15_process/process5.png
deleted file mode 100644
index df824f31..00000000
Binary files a/lectures/15_process/process5.png and /dev/null differ
diff --git a/lectures/15_process/scrum.svg b/lectures/15_process/scrum.svg
deleted file mode 100644
index a8149ac1..00000000
--- a/lectures/15_process/scrum.svg
+++ /dev/null
@@ -1,383 +0,0 @@
-
-
-
diff --git a/lectures/15_process/spiral_model.svg b/lectures/15_process/spiral_model.svg
deleted file mode 100644
index 14ea98b8..00000000
--- a/lectures/15_process/spiral_model.svg
+++ /dev/null
@@ -1,434 +0,0 @@
-
-
-
-
diff --git a/lectures/15_process/techDebtQuadrant.png b/lectures/15_process/techDebtQuadrant.png
deleted file mode 100644
index d298c812..00000000
Binary files a/lectures/15_process/techDebtQuadrant.png and /dev/null differ
diff --git a/lectures/15_process/trajectories.png b/lectures/15_process/trajectories.png
deleted file mode 100644
index 3c2d0847..00000000
Binary files a/lectures/15_process/trajectories.png and /dev/null differ
diff --git a/lectures/15_process/transcriptionarchitecture2.svg b/lectures/15_process/transcriptionarchitecture2.svg
deleted file mode 100644
index 212a40f7..00000000
--- a/lectures/15_process/transcriptionarchitecture2.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/15_process/zillow.png b/lectures/15_process/zillow.png
deleted file mode 100644
index d3522d64..00000000
Binary files a/lectures/15_process/zillow.png and /dev/null differ
diff --git a/lectures/15_process/zillow_main.png b/lectures/15_process/zillow_main.png
deleted file mode 100644
index 67a83fea..00000000
Binary files a/lectures/15_process/zillow_main.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/Martin_Shkreli_2016.jpg b/lectures/16_intro_ethics_fairness/Martin_Shkreli_2016.jpg
deleted file mode 100644
index 72ba7ffa..00000000
Binary files a/lectures/16_intro_ethics_fairness/Martin_Shkreli_2016.jpg and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/Social-media-driving.png b/lectures/16_intro_ethics_fairness/Social-media-driving.png
deleted file mode 100644
index 7456657d..00000000
Binary files a/lectures/16_intro_ethics_fairness/Social-media-driving.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/amazon-hiring.png b/lectures/16_intro_ethics_fairness/amazon-hiring.png
deleted file mode 100644
index 94822f89..00000000
Binary files a/lectures/16_intro_ethics_fairness/amazon-hiring.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/bing-translate-bias.png b/lectures/16_intro_ethics_fairness/bing-translate-bias.png
deleted file mode 100644
index cc09f011..00000000
Binary files a/lectures/16_intro_ethics_fairness/bing-translate-bias.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/ceo.png b/lectures/16_intro_ethics_fairness/ceo.png
deleted file mode 100644
index edccbe99..00000000
Binary files a/lectures/16_intro_ethics_fairness/ceo.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/college-admission.jpg b/lectures/16_intro_ethics_fairness/college-admission.jpg
deleted file mode 100644
index 44b03d35..00000000
Binary files a/lectures/16_intro_ethics_fairness/college-admission.jpg and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/crime-map.jpg b/lectures/16_intro_ethics_fairness/crime-map.jpg
deleted file mode 100644
index b5c6b5ab..00000000
Binary files a/lectures/16_intro_ethics_fairness/crime-map.jpg and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/dont-be-evil.png b/lectures/16_intro_ethics_fairness/dont-be-evil.png
deleted file mode 100644
index 8e01d9d8..00000000
Binary files a/lectures/16_intro_ethics_fairness/dont-be-evil.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/eej2.jpeg b/lectures/16_intro_ethics_fairness/eej2.jpeg
deleted file mode 100644
index 2354a176..00000000
Binary files a/lectures/16_intro_ethics_fairness/eej2.jpeg and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/examples/amazon-hiring.png b/lectures/16_intro_ethics_fairness/examples/amazon-hiring.png
deleted file mode 100644
index 94822f89..00000000
Binary files a/lectures/16_intro_ethics_fairness/examples/amazon-hiring.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/examples/crime-map.jpg b/lectures/16_intro_ethics_fairness/examples/crime-map.jpg
deleted file mode 100644
index b5c6b5ab..00000000
Binary files a/lectures/16_intro_ethics_fairness/examples/crime-map.jpg and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/examples/freelancing.png b/lectures/16_intro_ethics_fairness/examples/freelancing.png
deleted file mode 100644
index b6ac942b..00000000
Binary files a/lectures/16_intro_ethics_fairness/examples/freelancing.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/examples/gender-detection.png b/lectures/16_intro_ethics_fairness/examples/gender-detection.png
deleted file mode 100644
index d02b1d8c..00000000
Binary files a/lectures/16_intro_ethics_fairness/examples/gender-detection.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/examples/online-ad.png b/lectures/16_intro_ethics_fairness/examples/online-ad.png
deleted file mode 100644
index 933c5627..00000000
Binary files a/lectures/16_intro_ethics_fairness/examples/online-ad.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/examples/recidivism-bias.jpeg b/lectures/16_intro_ethics_fairness/examples/recidivism-bias.jpeg
deleted file mode 100644
index 00b9cb86..00000000
Binary files a/lectures/16_intro_ethics_fairness/examples/recidivism-bias.jpeg and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/examples/recidivism-propublica.png b/lectures/16_intro_ethics_fairness/examples/recidivism-propublica.png
deleted file mode 100644
index 5e871c64..00000000
Binary files a/lectures/16_intro_ethics_fairness/examples/recidivism-propublica.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/examples/shirley-card.jpg b/lectures/16_intro_ethics_fairness/examples/shirley-card.jpg
deleted file mode 100644
index d0e1fc47..00000000
Binary files a/lectures/16_intro_ethics_fairness/examples/shirley-card.jpg and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/examples/shirley-card.png b/lectures/16_intro_ethics_fairness/examples/shirley-card.png
deleted file mode 100644
index 48e700a4..00000000
Binary files a/lectures/16_intro_ethics_fairness/examples/shirley-card.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/examples/xing-bias.jpeg b/lectures/16_intro_ethics_fairness/examples/xing-bias.jpeg
deleted file mode 100644
index 9debb5c4..00000000
Binary files a/lectures/16_intro_ethics_fairness/examples/xing-bias.jpeg and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/fake-news.jpg b/lectures/16_intro_ethics_fairness/fake-news.jpg
deleted file mode 100644
index 45b46957..00000000
Binary files a/lectures/16_intro_ethics_fairness/fake-news.jpg and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/feedbackloop.svg b/lectures/16_intro_ethics_fairness/feedbackloop.svg
deleted file mode 100644
index 66334f7c..00000000
--- a/lectures/16_intro_ethics_fairness/feedbackloop.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/16_intro_ethics_fairness/gender-bias.png b/lectures/16_intro_ethics_fairness/gender-bias.png
deleted file mode 100644
index 7e875de5..00000000
Binary files a/lectures/16_intro_ethics_fairness/gender-bias.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/gender-detection.png b/lectures/16_intro_ethics_fairness/gender-detection.png
deleted file mode 100644
index d02b1d8c..00000000
Binary files a/lectures/16_intro_ethics_fairness/gender-detection.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/google-translate-bias.png b/lectures/16_intro_ethics_fairness/google-translate-bias.png
deleted file mode 100644
index a9d54cf8..00000000
Binary files a/lectures/16_intro_ethics_fairness/google-translate-bias.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/harms-table.png b/lectures/16_intro_ethics_fairness/harms-table.png
deleted file mode 100644
index 4074d948..00000000
Binary files a/lectures/16_intro_ethics_fairness/harms-table.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/infinitescroll.png b/lectures/16_intro_ethics_fairness/infinitescroll.png
deleted file mode 100644
index a4b9a66c..00000000
Binary files a/lectures/16_intro_ethics_fairness/infinitescroll.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/intro-ethics-fairness.md b/lectures/16_intro_ethics_fairness/intro-ethics-fairness.md
deleted file mode 100644
index cf3dbd4a..00000000
--- a/lectures/16_intro_ethics_fairness/intro-ethics-fairness.md
+++ /dev/null
@@ -1,645 +0,0 @@
----
-author: Eunsuk Kang & Christian Kaestner
-title: "MLiP: Intro to Ethics and Fairness"
-semester: Spring 2023
-footer: "Machine Learning in Production/AI Engineering • Christian Kaestner & Eunsuk Kang, Carnegie Mellon University • Spring 2023"
-license: Creative Commons Attribution 4.0 International (CC BY 4.0)
----
-
-
-
-## Machine Learning in Production
-
-# Responsible ML Engineering
-
-(Intro to Ethics and Fairness)
-
-
-
-
-
-
-
----
-
-
-
-----
-## Changing directions...
-
-
-
-
-
-
-----
-# Readings
-
-R. Caplan, J. Donovan, L. Hanson, J.
-Matthews. "Algorithmic Accountability: A Primer", Data & Society
-(2018).
-
-
-
-----
-# Learning Goals
-
-* Review the importance of ethical considerations in designing AI-enabled systems
-* Recall basic strategies to reason about ethical challenges
-* Diagnose potential ethical issues in a given system
-* Understand the types of harm that can be caused by ML
-* Understand the sources of bias in ML
-
----
-# Overview
-
-Many interrelated issues:
-* Ethics
-* Fairness
-* Justice
-* Discrimination
-* Safety
-* Privacy
-* Security
-* Transparency
-* Accountability
-
-*Each is a deep and nuanced research topic. We focus on survey of some key issues.*
-
-
-
-
-
-
-----
-
-
-
-
-
-
-
-
-
-*In 2015, Shkreli received widespread criticism [...] obtained the manufacturing license for the antiparasitic drug Daraprim and raised its price from USD 13.5 to 750 per pill [...] referred to by the media as "the most hated man in America" and "Pharma Bro".* -- [Wikipedia](https://en.wikipedia.org/wiki/Martin_Shkreli)
-
-"*I could have raised it higher and made more profits for our shareholders. Which is my primary duty.*" -- Martin Shkreli
-
-
-
-
-Note: Image source: https://en.wikipedia.org/wiki/Martin_Shkreli#/media/File:Martin_Shkreli_2016.jpg
-
-
-----
-## Terminology
-
-**Legal** = in accordance to societal laws
- - systematic body of rules governing society; set through government
- - punishment for violation
-
-**Ethical** = following moral principles of tradition, group, or individual
- - branch of philosophy, science of a standard human conduct
- - professional ethics = rules codified by professional organization
- - no legal binding, no enforcement beyond "shame"
- - high ethical standards may yield long term benefits through image and staff loyalty
-
-
-
-
-----
-## With a few lines of code...
-
-Developers have substantial power in shaping products
-
-Small design decisions can have substantial impact (safety, security,
-discrimination, ...) -- not always deliberate
-
-Our view: We have both **legal & ethical** responsibilities to anticipate mistakes,
-think through their consequences, and build in mitigations!
-
-
-
-
-
-
-
-
-
-
-
-----
-## Example: Social Media
-
-
-
-
-*What is the (real) organizational objective of the company?*
-
-----
-## Optimizing for Organizational Objective
-
-
-
-How do we maximize the user engagement? Examples:
- - Infinite scroll: Encourage non-stop, continual use
- - Personal recommendations: Suggest news feed to increase engagement
- - Push notifications: Notify disengaged users to return to the app
-
-
-
-
-
-
-
-----
-## Addiction
-
-
-
-
-* 210M people worldwide addicted to social media
-* 71% of Americans sleep next to a mobile device
-* ~1000 people injured **per day** due to distracted driving (USA)
-
-
-
-https://www.flurry.com/blog/mobile-addicts-multiply-across-the-globe/;
-https://www.cdc.gov/motorvehiclesafety/Distracted_Driving/index.html
-
-----
-## Mental Health
-
-
-
-
-* 35% of US teenagers with low social-emotional well-being have been bullied on social media.
-* 70% of teens feel excluded when using social media.
-
-
-https://leftronic.com/social-media-addiction-statistics
-
-----
-## Disinformation & Polarization
-
-
-
-
-----
-## Discrimination
-
-[](https://twitter.com/bascule/status/1307440596668182528)
-
-
-----
-## Who's to blame?
-
-
-
-
-*Are these companies intentionally trying to cause harm? If not,
- what are the root causes of the problem?*
-
-
-----
-## Liability?
-
-> THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
-
-Note: Software companies have usually gotten away with claiming no liability for their products
-
-----
-## Some Challenges
-
-
-
-
-
-*Misalignment between organizational goals & societal values*
- * Financial incentives often dominate other goals ("grow or die")
-
-*Hardly any regulation*
- * Little legal consequences for causing negative impact (with some exceptions)
- * Poor understanding of socio-technical systems by policy makers
-
-
-
-*Engineering challenges, at system- & ML-level*
- * Difficult to clearly define or measure ethical values
- * Difficult to anticipate all possible usage contexts
- * Difficult to anticipate impact of feedback loops
- * Difficult to prevent malicious actors from abusing the system
- * Difficult to interpret output of ML and make ethical decisions
-
-
-
-**These problems have existed before, but they are being
- rapidly exacerbated by the widespread use of ML**
-
-
-
-
-
-----
-## Responsible Engineering Matters
-
-Engineers have substantial power in shaping products and outcomes
-
-Serious individual and societal harms possible from (a) negligence and (b) malicious designs
-* Safety, mental health, weapons
-* Security, privacy
-* Manipulation, addiction, surveilance, polarization
-* Job loss, deskilling
-* Discrimination
-
-----
-## Buzzword or real progress?
-
-
-
-
-
-----
-## Responsible Engineering in this Course
-
-
-Key areas of concern
-* Fairness
-* Safety
-* Security and privacy
-* Transparency and accountability
-
-Technical infrastructure concepts
-* Interpretability and explainability
-* Versioning, provenance, reproducibility
-
-
-
-
----
-# Fairness
-
-----
-## Legally protected classes (US)
-
-
-
-- Race ([Civil Rights Act of 1964](https://en.wikipedia.org/wiki/Civil_Rights_Act_of_1964))
-- Religion ([Civil Rights Act of 1964](https://en.wikipedia.org/wiki/Civil_Rights_Act_of_1964))
-- National origin ([Civil Rights Act of 1964](https://en.wikipedia.org/wiki/Civil_Rights_Act_of_1964))
-- Sex, sexual orientation, and gender identity ([Equal Pay Act of 1963](https://en.wikipedia.org/wiki/Equal_Pay_Act_of_1963), [Civil Rights Act of 1964](https://en.wikipedia.org/wiki/Civil_Rights_Act_of_1964), and [Bostock v. Clayton](https://en.wikipedia.org/wiki/Bostock_v._Clayton_County))
-- Age (40 and over, [Age Discrimination in Employment Act of 1967](https://en.wikipedia.org/wiki/Age_Discrimination_in_Employment_Act_of_1967))
-- Pregnancy ([Pregnancy Discrimination Act of 1978](https://en.wikipedia.org/wiki/Pregnancy_Discrimination_Act))
-- Familial status (preference for or against having children, [Civil Rights Act of 1968](https://en.wikipedia.org/wiki/Civil_Rights_Act_of_1968))
-- Disability status ([Rehabilitation Act of 1973](https://en.wikipedia.org/wiki/Rehabilitation_Act_of_1973); [Americans with Disabilities Act of 1990](https://en.wikipedia.org/wiki/Americans_with_Disabilities_Act_of_1990))
-- Veteran status ([Vietnam Era Veterans’ Readjustment Assistance Act of 1974](https://en.wikipedia.org/wiki/Vietnam_Era_Veterans'_Readjustment_Assistance_Act); [Uniformed Services Employment and Reemployment Rights Act of 1994](https://en.wikipedia.org/wiki/Uniformed_Services_Employment_and_Re-employment_Rights_Act_of_1994))
-- Genetic information ([Genetic Information Nondiscrimination Act of 2008](https://en.wikipedia.org/wiki/Genetic_Information_Nondiscrimination_Act))
-
-
-
-
-
-https://en.wikipedia.org/wiki/Protected_group
-----
-## Regulated domains (US)
-
-* Credit (Equal Credit Opportunity Act)
-* Education (Civil Rights Act of 1964; Education Amendments of 1972)
-* Employment (Civil Rights Act of 1964)
-* Housing (Fair Housing Act)
-* ‘Public Accommodation’ (Civil Rights Act of 1964)
-
-Extends to marketing and advertising; not limited to final decision
-
-
-Barocas, Solon and Moritz Hardt. "[Fairness in machine learning](https://mrtz.org/nips17/#/)." NIPS Tutorial 1 (2017).
-
-
-----
-## What is fair?
-
-> Fairness discourse asks questions about how to treat people and whether treating different groups of people differently is ethical. If two groups of people are systematically treated differently, this is often considered unfair.
-
-----
-## Dividing a Pie?
-
-
-
-
-* Equal slices for everybody
-* Bigger slices for active bakers
-* Bigger slices for inexperienced/new members (e.g., children)
-* Bigger slices for hungry people
-* More pie for everybody, bake more
-
-*(Not everybody contributed equally during baking, not everybody is equally hungry)*
-
-
-
-
-
-
-
-
-
-----
-## Preview: Equality vs Equity vs Justice
-
-
-
-
-----
-## Types of Harm on Society
-
-__Harms of allocation__: Withhold opportunities or resources
-
-__Harms of representation__: Reinforce stereotypes, subordination along
- the lines of identity
-
-
-
-Kate Crawford. “The Trouble With Bias”, NeurIPS Keynote (2017).
-
-----
-## Harms of Allocation
-
-* Withhold opportunities or resources
-* Poor quality of service, degraded user experience for certain groups
-
-
-
-
-
-
-_Gender Shades: Intersectional Accuracy Disparities in
-Commercial Gender Classification_, Buolamwini & Gebru, ACM FAT* (2018).
-
-----
-## Harms of Representation
-
-* Over/under-representation of certain groups in organizations
-* Reinforcement of stereotypes
-
-
-
-
-
-
-_Discrimination in Online Ad Delivery_, Latanya Sweeney, SSRN (2013).
-
-----
-## Identifying harms
-
-
-
-
-* Multiple types of harms can be caused by a product!
-* Think about your system objectives & identify potential harms.
-
-
-
-_Challenges of incorporating algorithmic fairness into practice_, FAT* Tutorial (2019).
-
-----
-## Not all discrimination is harmful
-
-
-
-
-* Loan lending: Gender discrimination is illegal.
-* Medical diagnosis: Gender-specific diagnosis may be desirable.
-* The problem is _unjustified_ differentiation; i.e., discriminating on factors that should not matter
-* Discrimination is a __domain-specific__ concept (i.e., world vs machine)
-
-----
-## Role of Requirements Engineering
-
-* Identify system goals
-* Identify legal constraints
-* Identify stakeholders and fairness concerns
-* Analyze risks with regard to discrimination and fairness
-* Analyze possible feedback loops (world vs machine)
-* Negotiate tradeoffs with stakeholders
-* Set requirements/constraints for data and model
-* Plan mitigations in the system (beyond the model)
-* Design incident response plan
-* Set expectations for offline and online assurance and monitoring
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
----
-# Sources of Bias
-
-----
-## Where does the bias come from?
-
-
-
-
-
-
-_Semantics derived automatically from language corpora contain
-human-like biases_, Caliskan et al., Science (2017).
-
-----
-## Where does the bias come from?
-
-
-
-
-----
-## Sources of Bias
-
-* Historial bias
-* Tainted examples
-* Skewed sample
-* Limited features
-* Sample size disparity
-* Proxies
-
-
-
-_Big Data's Disparate Impact_, Barocas & Selbst California Law Review (2016).
-
-----
-## Historical Bias
-
-*Data reflects past biases, not intended outcomes*
-
-
-
-
-*Should the algorithm reflect the reality?*
-
-Note: "An example of this type of bias can be found in a 2018 image search
-result where searching for women CEOs ultimately resulted in fewer female CEO images due
-to the fact that only 5% of Fortune 500 CEOs were woman—which would cause the search
-results to be biased towards male CEOs. These search results were of course reflecting
-the reality, but whether or not the search algorithms should reflect this reality is an issue worth
-considering."
-
-----
-## Correcting Historical Bias?
-
-
-> "Big Data processes codify the past. They do not invent the future. Doing that requires moral imagination, and that’s something only humans can provide. " -- Cathy O'Neil in [Weapons of Math Destruction](https://cmu.primo.exlibrisgroup.com/permalink/01CMU_INST/6lpsnm/alma991016462699704436)
-
-> "Through user studies, the [image search] team learned that many users
-were uncomfortable with the idea of the company “manipulating” search results, viewing this behavior as unethical." -- observation from interviews by Ken Holstein
-
-
-
-----
-## Tainted Labels
-
-*Bias in dataset labels assigned (directly or indirectly) by humans*
-
-
-
-
-Example: Hiring decision dataset -- labels assigned by (possibly biased) experts or derived from past (possibly biased) hiring decisions
-
-----
-## Skewed Sample
-
-*Bias in how and what data is collected*
-
-
-
-
-Crime prediction: Where to analyze crime? What is considered crime? Actually a random/representative sample?
-
-Recall: Raw data is an oxymoron
-
-----
-## Limited Features
-
-*Features that are less informative/reliable for certain subpopulations*
-
-
-
-
-* Graduate admissions: Letters of recommendation equally reliable for international applicants?
-* Employee performance review: "Leave of absence" acceptable feature if parental leave is gender skewed?
-
-
-Note:
-Decisions may be based on features that are predictive and accurate for a large part of the target distribution, but not so for some other parts of the distribution.
-For example, a system ranking applications for graduate school admissions may heavily rely on letters of recommendation and be well calibrated for applicants who can request letters from mentors familiar with the culture and jargon of such letters in the US, but may work poorly for international applicants from countries where such letters are not common or where such letters express support with different jargon. To reduce bias, we should be carefully reviewing all features and analyze whether they may be less predictive for certain subpopulations.
-
-----
-## Sample Size Disparity
-
-*Limited training data for some subpopulations*
-
-
-
-
-* Biased sampling process: "Shirley Card" used for Kodak color calibration, using mostly Caucasian models
-* Small subpopulations: Sikhs small minority in US (0.2%) barely represented in a random sample
-
-----
-## Sample Size Disparity
-
-Without intervention:
-* Models biased toward populations more represented in target distribution (e.g., Caucasian skin tones)
-* ... biased towards population that are easier to sample (e.g., people self-selecting to post to Instagram)
-* ... may ignore small minority populations as noise
-
-Typically requires deliberate sampling strategy, intentional oversampling
-
-
-----
-## Proxies
-
-*Features correlate with protected attribute, remain after removal*
-
-
-
-
-
-* Example: Neighborhood as a proxy for race
-* Extracurricular activities as proxy for gender and social class (e.g., “cheerleading”, “peer-mentor for ...”, “sailing team”, “classical music”)
-
-
-----
-## Feedback Loops reinforce Bias
-
-
-
-
-
-
-> "Big Data processes codify the past. They do not invent the future. Doing that requires moral imagination, and that’s something only humans can provide. " -- Cathy O'Neil in [Weapons of Math Destruction](https://cmu.primo.exlibrisgroup.com/permalink/01CMU_INST/6lpsnm/alma991016462699704436)
-
-----
-## Breakout: College Admission
-
-
-
-
-Scenario: Evaluate applications & identify students likely to succeed
-
-Features: GPA, GRE/SAT, gender, race, undergrad institute, alumni
- connections, household income, hometown, transcript, etc.
-
-----
-## Breakout: College Admission
-
-Scenario: Evaluate applications & identify students who are
-likely to succeed
-
-Features: GPA, GRE/SAT, gender, race, undergrad institute, alumni
- connections, household income, hometown, transcript, etc.
-
-As a group, post to `#lecture` tagging members:
- * **Possible harms:** Allocation of resources? Quality of service? Stereotyping? Denigration? Over-/Under-representation?
- * **Sources of bias:** Skewed sample? Tainted labels? Historical bias? Limited features?
- Sample size disparity? Proxies?
-
----
-# Next lectures
-
-1. Measuring and Improving Fairness at the Model Level
-
-2. Fairness is a System-Wide Concern
-
-
-
----
-# Summary
-
-
-* Many interrelated issues: ethics, fairness, justice, safety, security, ...
-* Both legal & ethical dimensions
-* Challenges with developing ethical systems / developing systems responsibly
-* Large potential for damage: Harm of allocation & harm of representation
-* Sources of bias in ML: Skewed sample, tainted labels, limited features, sample size, disparity, proxies
-
-----
-## Further Readings
-
-
-
-- 🕮 O’Neil, Cathy. [Weapons of math destruction: How big data increases inequality and threatens democracy](https://bookshop.org/books/weapons-of-math-destruction-how-big-data-increases-inequality-and-threatens-democracy/9780553418835). Crown Publishing, 2017.
-- 🗎 Barocas, Solon, and Andrew D. Selbst. “[Big data’s disparate impact](http://www.californialawreview.org/wp-content/uploads/2016/06/2Barocas-Selbst.pdf).” Calif. L. Rev. 104 (2016): 671.
-- 🗎 Mehrabi, Ninareh, Fred Morstatter, Nripsuta Saxena, Kristina Lerman, and Aram Galstyan. “[A survey on bias and fairness in machine learning](https://arxiv.org/abs/1908.09635).” ACM Computing Surveys (CSUR) 54, no. 6 (2021): 1–35.
-- 🗎 Bietti, Elettra. “[From ethics washing to ethics bashing: a view on tech ethics from within moral philosophy](https://dl.acm.org/doi/pdf/10.1145/3351095.3372860).” In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, pp. 210–219. 2020.
-
-
-
diff --git a/lectures/16_intro_ethics_fairness/mark-zuckerberg.png b/lectures/16_intro_ethics_fairness/mark-zuckerberg.png
deleted file mode 100644
index 05cb03dd..00000000
Binary files a/lectures/16_intro_ethics_fairness/mark-zuckerberg.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/neighborhoods.png b/lectures/16_intro_ethics_fairness/neighborhoods.png
deleted file mode 100644
index fe0a0d6e..00000000
Binary files a/lectures/16_intro_ethics_fairness/neighborhoods.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/online-ad.png b/lectures/16_intro_ethics_fairness/online-ad.png
deleted file mode 100644
index 933c5627..00000000
Binary files a/lectures/16_intro_ethics_fairness/online-ad.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/performance-review.jpg b/lectures/16_intro_ethics_fairness/performance-review.jpg
deleted file mode 100644
index 34323bd4..00000000
Binary files a/lectures/16_intro_ethics_fairness/performance-review.jpg and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/responsibleai.png b/lectures/16_intro_ethics_fairness/responsibleai.png
deleted file mode 100644
index 1b3ec1f5..00000000
Binary files a/lectures/16_intro_ethics_fairness/responsibleai.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/shirley-card.jpg b/lectures/16_intro_ethics_fairness/shirley-card.jpg
deleted file mode 100644
index d0e1fc47..00000000
Binary files a/lectures/16_intro_ethics_fairness/shirley-card.jpg and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/teen-suicide-rate.png b/lectures/16_intro_ethics_fairness/teen-suicide-rate.png
deleted file mode 100644
index 0e04315e..00000000
Binary files a/lectures/16_intro_ethics_fairness/teen-suicide-rate.png and /dev/null differ
diff --git a/lectures/16_intro_ethics_fairness/twitter-cropping.png b/lectures/16_intro_ethics_fairness/twitter-cropping.png
deleted file mode 100644
index c5abdf0b..00000000
Binary files a/lectures/16_intro_ethics_fairness/twitter-cropping.png and /dev/null differ
diff --git a/lectures/17_fairness_measures/appraisal.png b/lectures/17_fairness_measures/appraisal.png
deleted file mode 100644
index cd497f63..00000000
Binary files a/lectures/17_fairness_measures/appraisal.png and /dev/null differ
diff --git a/lectures/17_fairness_measures/cancer-stats.png b/lectures/17_fairness_measures/cancer-stats.png
deleted file mode 100644
index 6a0f1ad5..00000000
Binary files a/lectures/17_fairness_measures/cancer-stats.png and /dev/null differ
diff --git a/lectures/17_fairness_measures/confusion-matrix.jpg b/lectures/17_fairness_measures/confusion-matrix.jpg
deleted file mode 100644
index 5f743cd5..00000000
Binary files a/lectures/17_fairness_measures/confusion-matrix.jpg and /dev/null differ
diff --git a/lectures/17_fairness_measures/eej2.jpeg b/lectures/17_fairness_measures/eej2.jpeg
deleted file mode 100644
index 2354a176..00000000
Binary files a/lectures/17_fairness_measures/eej2.jpeg and /dev/null differ
diff --git a/lectures/17_fairness_measures/fairness-papers.jpeg b/lectures/17_fairness_measures/fairness-papers.jpeg
deleted file mode 100644
index ee144f5d..00000000
Binary files a/lectures/17_fairness_measures/fairness-papers.jpeg and /dev/null differ
diff --git a/lectures/17_fairness_measures/gender-bias.png b/lectures/17_fairness_measures/gender-bias.png
deleted file mode 100644
index 7e875de5..00000000
Binary files a/lectures/17_fairness_measures/gender-bias.png and /dev/null differ
diff --git a/lectures/17_fairness_measures/justice.jpeg b/lectures/17_fairness_measures/justice.jpeg
deleted file mode 100644
index e3193d49..00000000
Binary files a/lectures/17_fairness_measures/justice.jpeg and /dev/null differ
diff --git a/lectures/17_fairness_measures/manymetrics.png b/lectures/17_fairness_measures/manymetrics.png
deleted file mode 100644
index 4764e070..00000000
Binary files a/lectures/17_fairness_measures/manymetrics.png and /dev/null differ
diff --git a/lectures/17_fairness_measures/model_fairness.md b/lectures/17_fairness_measures/model_fairness.md
deleted file mode 100644
index 05074c45..00000000
--- a/lectures/17_fairness_measures/model_fairness.md
+++ /dev/null
@@ -1,552 +0,0 @@
----
-author: Christian Kaestner and Eunsuk Kang
-title: "MLiP: Measuring Fairness"
-semester: Spring 2023
-footer: "Machine Learning in Production/AI Engineering • Christian Kaestner, Carnegie Mellon University • Spring 2023"
-license: Creative Commons Attribution 4.0 International (CC BY 4.0)
----
-
-
-
-## Machine Learning in Production
-
-
-# Measuring Fairness
-
-
----
-## Diving into Fairness...
-
-
-
-
-
-
-----
-## Reading
-
-
-
-Required:
-- Nina Grgic-Hlaca, Elissa M. Redmiles, Krishna P. Gummadi, and Adrian Weller.
-[Human Perceptions of Fairness in Algorithmic Decision Making:
-A Case Study of Criminal Risk Prediction](https://dl.acm.org/doi/pdf/10.1145/3178876.3186138)
-In WWW, 2018.
-
-Recommended:
-- Ian Foster, Rayid Ghani, Ron S. Jarmin, Frauke Kreuter and Julia Lane. [Big Data and Social Science: Data Science Methods and Tools for Research and Practice](https://textbook.coleridgeinitiative.org/). Chapter 11, 2nd ed, 2020
-- Solon Barocas and Moritz Hardt and Arvind Narayanan. [Fairness and Machine Learning](http://www.fairmlbook.org). 2019 (incomplete book)
-- Pessach, Dana, and Erez Shmueli. "[A Review on Fairness in Machine Learning](https://dl.acm.org/doi/full/10.1145/3494672)." ACM Computing Surveys (CSUR) 55, no. 3 (2022): 1-44.
-
-
-
----
-# Learning Goals
-
-* Understand different definitions of fairness
-* Discuss methods for measuring fairness
-* Outline interventions to improve fairness at the model level
-
----
-## Real change, or lip service?
-
-
-
-
-
-https://www.nytimes.com/2023/03/23/business/tiktok-screen-time.html
-
----
-# Fairness: Definitions
-
-How do we measure the fairness of an ML model?
-
-----
-### Fairness is still an actively studied & disputed concept!
-
-
-
-
-Source: Mortiz Hardt, https://fairmlclass.github.io/
-
-----
-## Fairness: Definitions
-
-* Anti-classification (fairness through blindness)
-* Group fairness (independence)
-* Equalized odds (separation)
-* ...and numerous others and variations!
-
-
----
-# Running Example: Mortgage Applications
-
-* Large loans repayed over long periods, large loss on default
-* Home ownership is key path to build generational wealth
-* Past decisions often discriminatory (redlining)
-* Replace biased human decisions by objective and more accurate ML model
- - income, other debt, home value
- - past debt and payment behavior (credit score)
-
-----
-## Recall: What is fair?
-
-> Fairness discourse asks questions about how to treat people and whether treating different groups of people differently is ethical. If two groups of people are systematically treated differently, this is often considered unfair.
-
-----
-## Recall: What is fair?
-
-
-
-
-----
-## What is fair in mortgage applications?
-
-1. Distribute loans equally across all groups of protected attribute(s)
- (e.g., ethnicity)
-2. Prioritize those who are more likely to pay back (e.g., higher
- income, good credit history)
-
-
-
-----
-## Redlining
-
-
-
-
-
-
-
-
-Withold services (e.g., mortgage, education, retail) from people in neighborhoods
-deemed "risky"
-
-Map of Philadelphia, 1936, Home Owners' Loan Corps. (HOLC)
-* Classification based on estimated "riskiness" of loans
-
-
-----
-## Past bias, different starting positions
-
-
-
-
-Source: Federal Reserve’s [Survey of Consumer Finances](https://www.federalreserve.gov/econres/scfindex.htm)
-
----
-# Anti-classification
-
-* __Anti-classification (fairness through blindness)__
-* Group fairness (independence)
-* Equalized odds (separation)
-* ...and numerous others and variations!
-
-----
-## Anti-Classification
-
-
-
-
-
-* Also called _fairness through blindness_ or _fairness through unawareness_
-* Ignore certain sensitive attributes when making a decision
-* Example: Remove gender and race from mortgage model
-
-----
-## Anti-Classification: Example
-
-
-
-
-"After Ms. Horton removed all signs of Blackness, a second appraisal valued a Jacksonville home owned by her and her husband, Alex Horton, at 40 percent higher."
-
-
-https://www.nytimes.com/2022/03/21/realestate/remote-home-appraisals-racial-bias.html
-
-----
-## Anti-Classification
-
-
-
-
-*Easy to implement, but any limitations?*
-
-----
-## Recall: Proxies
-
-*Features correlate with protected attributes*
-
-
-
-----
-## Recall: Not all discrimination is harmful
-
-
-
-
-* Loan lending: Gender and racial discrimination is illegal.
-* Medical diagnosis: Gender/race-specific diagnosis may be desirable.
-* Discrimination is a __domain-specific__ concept!
-
-----
-## Anti-Classification
-
-
-
-
-* Ignore certain sensitive attributes when making a decision
-* Advantage: Easy to implement and test
-* Limitations
- * Sensitive attributes may be correlated with other features
- * Some ML tasks need sensitive attributes (e.g., medical diagnosis)
-
-----
-## Ensuring Anti-Classification
-
-How to train models that are fair w.r.t. anti-classification?
-
-
-
-----
-## Ensuring Anti-Classification
-
-How to train models that are fair w.r.t. anti-classification?
-
---> Simply remove features for protected attributes from training and inference data
-
---> Null/randomize protected attribute during inference
-
-*(does not account for correlated attributes, is not required to)*
-
-----
-## Testing Anti-Classification
-
-How do we test that a classifier achieves anti-classification?
-
-
-
-----
-## Testing Anti-Classification
-
-Straightforward invariant for classifier $f$ and protected attribute $p$:
-
-$\forall x. f(x[p\leftarrow 0]) = f(x[p\leftarrow 1])$
-
-*(does not account for correlated attributes, is not required to)*
-
-Test with *any* test data, e.g., purely random data or existing test data
-
-Any single inconsistency shows that the protected attribute was used. Can also report percentage of inconsistencies.
-
-
-See for example: Galhotra, Sainyam, Yuriy Brun, and Alexandra Meliou. "[Fairness testing: testing software for discrimination](http://people.cs.umass.edu/brun/pubs/pubs/Galhotra17fse.pdf)." In Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering, pp. 498-510. 2017.
-
-
-----
-## Anti-Classification Discussion
-
-*Testing of anti-classification barely needed, because easy to ensure by constructing during training or inference!*
-
-Anti-classification is a good starting point to think about protected attributes
-
-Useful baseline for comparison
-
-Easy to implement, but only effective if (1) no proxies among features
-and (2) protected attributes add no predictive power
-
----
-# Group fairness
-
-* Anti-classification (fairness through blindness)
-* __Group fairness (independence)__
-* Equalized odds (separation)
-* ...and numerous others and variations!
-
-----
-## Group fairness
-
-Key idea: Compare outcomes across two groups
-* Similar rates of accepted loans across racial/gender groups?
-* Similar chance of being hired/promoted between gender groups?
-* Similar rates of (predicted) recidivism across racial groups?
-
-Outcomes matter, not accuracy!
-
-----
-## Disparate impact vs. disparate treatment
-
-Disparate treatment: Practices or rules that treat a certain protected
-group(s) differently from others
-* e.g., Apply different mortgage rules for people from different backgrounds
-
-Disparate impact: Neutral rules, but outcome is worse for
- one or more protected groups
-* Same rules are applied, but certain groups have a harder time
- obtaining mortgage in a particular neighborhood
-
-----
-## Group fairness in discrimination law
-
-Relates to *disparate impact* and the four-fifth rule
-
-Can sue organizations for discrimination if they
-* mostly reject job applications from one minority group (identified by protected classes) and hire mostly from another
-* reject most loans from one minority group and more frequently accept applicants from another
-
-
-----
-## Notations
-
-* $X$: Feature set (e.g., age, race, education, region, income, etc.,)
-* $A \in X$: Sensitive attribute (e.g., gender)
-* $R$: Regression score (e.g., predicted likelihood of on-time loan payment)
-* $Y'$: Classifier output
- * $Y' = 1$ if and only if $R > T$ for some threshold $T$
- * e.g., Grant the loan ($Y' = 1$) if the likelihood of paying back > 80%
-* $Y$: Target variable being predicted ($Y = 1$ if the person actually
- pays back on time)
-
-[Setting classification thresholds: Loan lending example](https://research.google.com/bigpicture/attacking-discrimination-in-ml)
-
-
-
-----
-## Group Fairness
-
-$P[Y' = 1 | A = a] = P[Y' = 1 | A = b]$
-
-* Also called _independence_ or _demographic parity_
-* Mathematically, $Y' \perp A$
- * Prediction ($Y'$) must be independent of the sensitive attribute ($A$)
-* Examples:
- * The predicted rate of recidivism is the same across all races
- * Both women and men have the equal probability of being promoted
- * i.e., P[promote = 1 | gender = M] = P[promote = 1 | gender = F]
-
-----
-## Group Fairness Limitations
-
-What are limitations of group fairness?
-
-
-
-----
-## Group Fairness Limitations
-
-* Ignores possible correlation between $Y$ and $A$
- * Rules out perfect predictor $Y' = Y$ when $Y$ & $A$ are correlated!
-* Permits abuse and laziness: Can be satisfied by randomly assigning a positive outcome ($Y' = 1$) to protected groups
- * e.g., Randomly promote people (regardless of their
- job performance) to match the rate across all groups
-
-----
-## Adjusting Thresholds for Group Fairness
-
-Select different classification thresholds ($t_0$, $t_1$) for different groups (A = 0, A = 1) to achieve group fairness, such that
-$P[R > t_0 | A = 0] = P[R > t_1 | A = 1]$
-
-
-
-Example: Mortgage application
- * R: Likelihood of paying back the loan on time
- * Suppose: With a uniform threshold used (i.e., R = 80%), group fairness is not achieved
- * P[R > 0.8 | A = 0] = 0.4, P[R > 0.8 | A = 1] = 0.7
- * Adjust thresholds to achieve group fairness
- * P[R > 0.6 | A = 0] = P[R > 0.8 | A = 1]
-* Wouldn't group A = 1 argue it's unfair? When does this type of adjustment make sense?
-
-
-
-----
-## Testing Group Fairness
-
-*How would you test whether a classifier achieves group fairness?*
-
-
-
-----
-## Testing Group Fairness
-
-Collect realistic, representative data (not randomly generated!)
-* Use existing validation/test data
-* Monitor production data
-* (Somehow) generate realistic test data, e.g. from probability distribution of population
-
-Separately measure the rate of positive predictions
-* e.g., P[promoted = 1 | gender = M], P[promoted = 1 | gender = F] = ?
-
-Report issue if the rates differ beyond some threshold $\epsilon$ across
-groups
-
-
----
-# Equalized odds
-
-* Anti-classification (fairness through blindness)
-* Group fairness (independence)
-* **Equalized odds (separation)**
-* ...and numerous others and variations!
-
-----
-## Equalized odds
-
-Key idea: Focus on accuracy (not outcomes) across two groups
-
-* Similar default rates on accepted loans across racial/gender groups?
-* Similar rate of "bad hires" and "missed stars" between gender groups?
-* Similar accuracy of predicted recidivism vs actual recidivism across racial groups?
-
-Accuracy matters, not outcomes!
-
-----
-## Equalized odds in discrimination law
-
-Relates to *disparate treatment*
-
-Typically, lawsuits claim that protected attributes (e.g., race, gender) were used in decisions even though they were irrelevant
-* e.g., fired over complaint because of being Latino, whereas other White employees were not fired with similar complaints
-
-Must prove that the defendant had *intention* to discriminate
-* Often difficult: Relying on shifting justifications, inconsistent application of rules, or explicit remarks overheard or documented
-
-----
-## Equalized odds
-
-$P[Y'=1∣Y=0,A=a] = P[Y'=1∣Y=0,A=b]$
-$P[Y'=0∣Y=1,A=a] = P[Y'=0∣Y=1,A=b]$
-
-Statistical property of *separation*: $Y' \perp A | Y$
- * Prediction must be independent of the sensitive attribute
- _conditional_ on the target variable
-
-----
-## Review: Confusion Matrix
-
-
-
-
-Can we explain separation in terms of model errors?
-* $P[Y'=1∣Y=0,A=a] = P[Y'=1∣Y=0,A=b]$
-* $P[Y'=0∣Y=1,A=a] = P[Y'=0∣Y=1,A=b]$
-
-----
-## Separation
-
-$P[Y'=1∣Y=0,A=a] = P[Y'=1∣Y=0,A=b]$ (FPR parity)
-
-$P[Y'=0∣Y=1,A=a] = P[Y'=0∣Y=1,A=b]$ (FNR parity)
-
-* $Y' \perp A | Y$: Prediction must be independent of the sensitive attribute
- _conditional_ on the target variable
-* i.e., All groups are susceptible to the same false positive/negative rates
-* Example: Y': Promotion decision, A: Gender of applicant: Y: Actual job performance
-
-----
-## Testing Separation
-
-Requires realistic representative test data (telemetry or representative test data, not random)
-
-Separately measure false positive and false negative rates
- * e..g, for FNR, compare P[promoted = 0 | female, good employee] vs P[promoted = 0 | male, good employee]
-
-
-*How is this different from testing group fairness?*
-
----
-# Breakout: Cancer Prognosis
-
-
-
-In groups, post to `#lecture` tagging members:
-
-* Does the model meet anti-classification fairness w.r.t. gender?
-* Does the model meet group fairness?
-* Does the model meet equalized odds?
-* Is the model fair enough to use?
-
-
----
-# Other fairness measures
-
-* Anti-classification (fairness through blindness)
-* Group fairness (independence)
-* Equalized odds (separation)**
-* **...and numerous others and variations!**
-
-----
-
-
-
-----
-## Many measures
-
-Many measures proposed
-
-Some specialized for tasks (e.g., ranking, NLP)
-
-Some consider downstream utility of various outcomes
-
-Most are similar to the three discussed
-* Comparing different measures in the error matrix (e.g., false positive rate, lift)
-
-
-
-
-
-
-
----
-# Outlook: Building Fair ML-Based Products
-
-**Next lecture:** Fairness is a *system-wide* concern
-
-* Identifying and negotiating fairness requirements
-* Fairness beyond model predictions (product design, mitigations, data collection)
-* Fairness in process and teamwork, barriers and responsibilities
-* Documenting fairness at the interface
-* Monitoring
-* Promoting best practices
-
-
-
-
-
-
----
-# Summary
-
-* Three definitions of fairness: Anti-classification, group fairness, equalized odds
-* Tradeoffs between fairness criteria
- * What is the goal?
- * Key: how to deal with unequal starting positions
-* Improving fairness of a model
- * In all *pipeline stages*: data collection, data cleaning, training, inference, evaluation
-
-----
-## Further Readings
-
-- 🕮 Ian Foster, Rayid Ghani, Ron S. Jarmin, Frauke Kreuter and Julia Lane. [Big Data and Social Science: Data Science Methods and Tools for Research and Practice](https://textbook.coleridgeinitiative.org/). Chapter 11, 2nd ed, 2020
-- 🕮 Solon Barocas and Moritz Hardt and Arvind Narayanan. [Fairness and Machine Learning](http://www.fairmlbook.org). 2019 (incomplete book)
-- 🗎 Pessach, Dana, and Erez Shmueli. "[A Review on Fairness in Machine Learning](https://dl.acm.org/doi/full/10.1145/3494672)." ACM Computing Surveys (CSUR) 55, no. 3 (2022): 1-44.
-
-
-
diff --git a/lectures/17_fairness_measures/mortgage.png b/lectures/17_fairness_measures/mortgage.png
deleted file mode 100644
index 8a774d3a..00000000
Binary files a/lectures/17_fairness_measures/mortgage.png and /dev/null differ
diff --git a/lectures/17_fairness_measures/neighborhoods.png b/lectures/17_fairness_measures/neighborhoods.png
deleted file mode 100644
index fe0a0d6e..00000000
Binary files a/lectures/17_fairness_measures/neighborhoods.png and /dev/null differ
diff --git a/lectures/17_fairness_measures/redlining.jpeg b/lectures/17_fairness_measures/redlining.jpeg
deleted file mode 100644
index fe9439e6..00000000
Binary files a/lectures/17_fairness_measures/redlining.jpeg and /dev/null differ
diff --git a/lectures/17_fairness_measures/tiktok.jpg b/lectures/17_fairness_measures/tiktok.jpg
deleted file mode 100644
index db32ab93..00000000
Binary files a/lectures/17_fairness_measures/tiktok.jpg and /dev/null differ
diff --git a/lectures/18_system_fairness/aequitas-report.png b/lectures/18_system_fairness/aequitas-report.png
deleted file mode 100644
index d11913d5..00000000
Binary files a/lectures/18_system_fairness/aequitas-report.png and /dev/null differ
diff --git a/lectures/18_system_fairness/aequitas.png b/lectures/18_system_fairness/aequitas.png
deleted file mode 100644
index 2281bb6f..00000000
Binary files a/lectures/18_system_fairness/aequitas.png and /dev/null differ
diff --git a/lectures/18_system_fairness/apes.png b/lectures/18_system_fairness/apes.png
deleted file mode 100644
index 8e0a6f16..00000000
Binary files a/lectures/18_system_fairness/apes.png and /dev/null differ
diff --git a/lectures/18_system_fairness/atm.gif b/lectures/18_system_fairness/atm.gif
deleted file mode 100644
index c966f66c..00000000
Binary files a/lectures/18_system_fairness/atm.gif and /dev/null differ
diff --git a/lectures/18_system_fairness/blood-pressure-monitor.jpg b/lectures/18_system_fairness/blood-pressure-monitor.jpg
deleted file mode 100644
index 2ec3a2fa..00000000
Binary files a/lectures/18_system_fairness/blood-pressure-monitor.jpg and /dev/null differ
diff --git a/lectures/18_system_fairness/bongo.gif b/lectures/18_system_fairness/bongo.gif
deleted file mode 100644
index 598a9abf..00000000
Binary files a/lectures/18_system_fairness/bongo.gif and /dev/null differ
diff --git a/lectures/18_system_fairness/ceo.png b/lectures/18_system_fairness/ceo.png
deleted file mode 100644
index edccbe99..00000000
Binary files a/lectures/18_system_fairness/ceo.png and /dev/null differ
diff --git a/lectures/18_system_fairness/college-admission.jpg b/lectures/18_system_fairness/college-admission.jpg
deleted file mode 100644
index 44b03d35..00000000
Binary files a/lectures/18_system_fairness/college-admission.jpg and /dev/null differ
diff --git a/lectures/18_system_fairness/compas-metrics.png b/lectures/18_system_fairness/compas-metrics.png
deleted file mode 100644
index 99cb488d..00000000
Binary files a/lectures/18_system_fairness/compas-metrics.png and /dev/null differ
diff --git a/lectures/18_system_fairness/component.svg b/lectures/18_system_fairness/component.svg
deleted file mode 100644
index 9e488f32..00000000
--- a/lectures/18_system_fairness/component.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/18_system_fairness/data-bias-stage.png b/lectures/18_system_fairness/data-bias-stage.png
deleted file mode 100644
index 0c317711..00000000
Binary files a/lectures/18_system_fairness/data-bias-stage.png and /dev/null differ
diff --git a/lectures/18_system_fairness/datasheet.png b/lectures/18_system_fairness/datasheet.png
deleted file mode 100644
index 6292f6d4..00000000
Binary files a/lectures/18_system_fairness/datasheet.png and /dev/null differ
diff --git a/lectures/18_system_fairness/eej1.jpg b/lectures/18_system_fairness/eej1.jpg
deleted file mode 100644
index 4b38ccf0..00000000
Binary files a/lectures/18_system_fairness/eej1.jpg and /dev/null differ
diff --git a/lectures/18_system_fairness/eej2.jpeg b/lectures/18_system_fairness/eej2.jpeg
deleted file mode 100644
index 2354a176..00000000
Binary files a/lectures/18_system_fairness/eej2.jpeg and /dev/null differ
diff --git a/lectures/18_system_fairness/facial-dataset.png b/lectures/18_system_fairness/facial-dataset.png
deleted file mode 100644
index 2e9a7a76..00000000
Binary files a/lectures/18_system_fairness/facial-dataset.png and /dev/null differ
diff --git a/lectures/18_system_fairness/fairness-accuracy.jpeg b/lectures/18_system_fairness/fairness-accuracy.jpeg
deleted file mode 100644
index 7e6dccc9..00000000
Binary files a/lectures/18_system_fairness/fairness-accuracy.jpeg and /dev/null differ
diff --git a/lectures/18_system_fairness/fairness-lifecycle.jpg b/lectures/18_system_fairness/fairness-lifecycle.jpg
deleted file mode 100644
index 4ea3d720..00000000
Binary files a/lectures/18_system_fairness/fairness-lifecycle.jpg and /dev/null differ
diff --git a/lectures/18_system_fairness/fairness-longterm.png b/lectures/18_system_fairness/fairness-longterm.png
deleted file mode 100644
index f95bca5f..00000000
Binary files a/lectures/18_system_fairness/fairness-longterm.png and /dev/null differ
diff --git a/lectures/18_system_fairness/fairness_tree.png b/lectures/18_system_fairness/fairness_tree.png
deleted file mode 100644
index 74e3c01d..00000000
Binary files a/lectures/18_system_fairness/fairness_tree.png and /dev/null differ
diff --git a/lectures/18_system_fairness/feedbackloop.svg b/lectures/18_system_fairness/feedbackloop.svg
deleted file mode 100644
index 66334f7c..00000000
--- a/lectures/18_system_fairness/feedbackloop.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/18_system_fairness/freelancing.png b/lectures/18_system_fairness/freelancing.png
deleted file mode 100644
index b6ac942b..00000000
Binary files a/lectures/18_system_fairness/freelancing.png and /dev/null differ
diff --git a/lectures/18_system_fairness/hiring.png b/lectures/18_system_fairness/hiring.png
deleted file mode 100644
index 2c9a71ec..00000000
Binary files a/lectures/18_system_fairness/hiring.png and /dev/null differ
diff --git a/lectures/18_system_fairness/loanprofit.png b/lectures/18_system_fairness/loanprofit.png
deleted file mode 100644
index 50180f67..00000000
Binary files a/lectures/18_system_fairness/loanprofit.png and /dev/null differ
diff --git a/lectures/18_system_fairness/model_drift.jpg b/lectures/18_system_fairness/model_drift.jpg
deleted file mode 100644
index 47857a0e..00000000
Binary files a/lectures/18_system_fairness/model_drift.jpg and /dev/null differ
diff --git a/lectures/18_system_fairness/modelcards.png b/lectures/18_system_fairness/modelcards.png
deleted file mode 100644
index e54afe1c..00000000
Binary files a/lectures/18_system_fairness/modelcards.png and /dev/null differ
diff --git a/lectures/18_system_fairness/recidivism-propublica.png b/lectures/18_system_fairness/recidivism-propublica.png
deleted file mode 100644
index d5af3318..00000000
Binary files a/lectures/18_system_fairness/recidivism-propublica.png and /dev/null differ
diff --git a/lectures/18_system_fairness/system_fairness.md b/lectures/18_system_fairness/system_fairness.md
deleted file mode 100644
index c714d549..00000000
--- a/lectures/18_system_fairness/system_fairness.md
+++ /dev/null
@@ -1,1189 +0,0 @@
----
-author: Christian Kaestner and Eunsuk Kang
-title: "MLiP: Improving Fairness"
-semester: Spring 2023
-footer: "Machine Learning in Production/AI Engineering • Christian Kaestner & Eunsuk Kang, Carnegie Mellon University • Spring 2023"
-license: Creative Commons Attribution 4.0 International (CC BY 4.0)
----
-
-
-
-## Machine Learning in Production
-
-
-# Building Fair Products
-
-
----
-## From Fairness Concepts to Fair Products
-
-
-
-
-
-
-----
-## Reading
-
-Required reading:
-* Holstein, Kenneth, Jennifer Wortman Vaughan, Hal
-Daumé III, Miro Dudik, and Hanna
-Wallach. "[Improving fairness in machine learning systems: What do industry practitioners need?](http://users.umiacs.umd.edu/~hal/docs/daume19fairness.pdf)"
-In Proceedings of the 2019 CHI Conference on Human Factors in
-Computing Systems, pp. 1-16. 2019.
-
-Recommended reading:
-* 🗎 Metcalf, Jacob, and Emanuel Moss. "[Owning ethics: Corporate logics, silicon valley, and the institutionalization of ethics](https://datasociety.net/wp-content/uploads/2019/09/Owning-Ethics-PDF-version-2.pdf)." *Social Research: An International Quarterly* 86, no. 2 (2019): 449-476.
-
-----
-## Learning Goals
-
-* Understand the role of requirements engineering in selecting ML
-fairness criteria
-* Understand the process of constructing datasets for fairness
-* Document models and datasets to communicate fairness concerns
-* Consider the potential impact of feedback loops on AI-based systems
- and need for continuous monitoring
-* Consider achieving fairness in AI-based systems as an activity throughout the entire development cycle
-
----
-## A few words about I4
-
-* Pick a tool & write a blog post about it
- * Must have engineering aspect for building ML **systems**
- * Out of scope: Purely model-centric tools (e.g., better ML libraries)
-* Use case in the context of movie recommendation, but no need to be
-about your specific system
-* If the tool is from the previous semester, discuss different
-features/capabilities
-* Can also compare different tools (strengths & limitations)
-* Think of it as a learning experience! Pick a new tool that you haven't used before
-
-
----
-## Today: Fairness as a System Quality
-
-Fairness can be measured for a model
-
-... but we really care whether the system, as it interacts with the environment, is fair/safe/secure
-
-... does the system cause harm?
-
-
-
-
-----
-## Fair ML Pipeline Process
-
-Fairness must be considered throughout the entire lifecycle!
-
-
-
-
-
-
-_Fairness-aware Machine Learning_, Bennett et al., WSDM Tutorial (2019).
-
-
-----
-## Fairness Problems are System-Wide Challenges
-
-* **Requirements engineering challenges:** How to identify fairness concerns, fairness metric, design data collection and labeling
-* **Human-computer-interaction design challenges:** How to present results to users, fairly collect data from users, design mitigations
-* **Quality assurance challenges:** Evaluate the entire system for fairness, continuously assure in production
-* **Process integration challenges:** Incorprorate fairness work in development process
-* **Education and documentation challenges:** Create awareness, foster interdisciplinary collaboration
-
-
----
-# Understanding System-Level Goals for Fairness
-
-i.e., Requirements engineering
-
-
-----
-## Recall: Fairness metrics
-
-* Anti-classification (fairness through blindness)
-* Group fairness (independence)
-* Equalized odds (separation)
-* ...and numerous others and variations!
-
-**But which one makes most sense for my product?**
-
-----
-## Identifying Fairness Goals is a Requirements Engineering Problem
-
-
-
-* What is the goal of the system? What benefits does it provide and to
- whom?
-
-* Who are the stakeholders of the system? What are the stakeholders’ views or expectations on fairness and where do they conflict? Are we trying to achieve fairness based on equality or equity?
-
-* What subpopulations (including minority groups) may be using or be affected by the system? What types of harms can the system cause with discrimination?
-
-* Does fairness undermine any other goals of the system (e.g., accuracy, profits, time to release)?
-
-* Are there legal anti-discrimination requirements to consider? Are
- there societal expectations about ethics w.r.t. to this product? What is the activist position?
-
-* ...
-
-
-
-
-
-----
-## 1. Identify Protected Attributes
-
-Against which groups might we discriminate? What attributes identify them directly or indirectly?
-
-Requires understanding of target population and subpopulations
-
-Use anti-discrimination law as starting point, but do not end there
-* Socio-economic status? Body height? Weight? Hair style? Eye color? Sports team preferences?
-* Protected attributes for non-humans? Animals, inanimate objects?
-
-Involve stakeholders, consult lawyers, read research, ask experts, ...
-
-
-----
-## Protected attributes are not always obvious
-
-
-
-
-**Q. Other examples?**
-
-----
-## 2. Analyze Potential Harms
-
-Anticipate harms from unfair decisions
-* Harms of allocation, harms of representation?
-* How do biased model predictions contribute to system behavior?
-
-Consider how automation can amplify harm
-
-Overcome blind spots within teams
-* Systematically consider consequences of bias
-* Consider safety engineering techniques (e.g., FTA)
-* Assemble diverse teams, use personas, crowdsource audits
-
-
-----
-## Example: Judgment Call Game
-
-
-
-Card "Game" by Microsoft Research
-
-Participants write "Product reviews" from different perspectives
-* encourage thinking about consequences
-* enforce persona-like role taking
-
-
-
-
-
-
-
-
-----
-## Example: Judgment Call Game
-
-
-
-
-
-
-
-
-
-
-
-[Judgment Call the Game: Using Value Sensitive Design and Design
-Fiction to Surface Ethical Concerns Related to Technology](https://dl.acm.org/doi/10.1145/3322276.3323697)
-
-----
-## 3. Negotiate Fairness Goals/Measures
-
-* Negotiate with stakeholders to determine fairness requirement for
-the product: What is the suitable notion of fairness for the
-product? Equality or equity?
-* Map the requirements to model-level (model) specifications: Anti-classification? Group fairness? Equalized odds?
-* Negotiation can be challenging!
- * Conflicts with other system goals (accuracy, profits...)
- * Conflicts among different beliefs, values, political views, etc.,
- * Will often need to accept some (perceived) unfairness
-
-----
-## Recall: What is fair?
-
-> Fairness discourse asks questions about how to treat people and whether treating different groups of people differently is ethical. If two groups of people are systematically treated differently, this is often considered unfair.
-
-
-----
-## Intuitive Justice
-
-Research on what post people perceive as fair/just (psychology)
-
-When rewards depend on inputs and participants can chose contributions: Most people find it fair to split rewards proportional to inputs
-* *Which fairness measure does this relate to?*
-
-Most people agree that for a decision to be fair, personal characteristics that do not influence the reward, such as gender or age, should not be considered when dividing the rewards.
-* *Which fairness measure does this relate to?*
-
-----
-## Key issue: Unequal starting positions
-
-Not everybody starts from an equal footing -- individual and group differences
-* Some differences are inert, e.g., younger people have (on average) less experience
-* Some differences come from past behavior/decisions, e.g., whether to attend college
-* Some past decisions and opportunities are influenced by past injustices, e.g., redlining creating generational wealth differences
-
-Individual and group differences not always clearly attributable, e.g., nature vs nurture discussion
-
-----
-## Unequal starting position
-
-
-
-Fair or not? Should we account for unequal starting positions?
-* Tom is lazier than Bob. He should get less pie.
-* People in Egypt have on average a much longer work week (53h) than people in Germany (35h). They have less time to bake and should get more pie.
-* Disabled people are always exhausted quickly. They should get less pie, because they contribute less.
-* Men are on average more violent than women. This should be reflected in recidivism prediction.
-* Employees with a PhD should earn higher wages than those with a bachelor's degree, because they decided to invest in more schooling.
-* Students from poor neighborhoods should receive extra resources at school, because they get less help at home.
-* Poverty is a moral failing. Poor people are less deserving of pie.
-
-
-
-----
-## Dealing with unequal starting positions
-
-Equality (minimize disparate treatment):
-* Treat everybody equally, regardless of starting position
-* Focus on meritocracy, strive for fair opportunities
-* Equalized-odds-style fairness; equality of opportunity
-
-Equity (minimize disparate impact):
-* Compensate for different starting positions
-* Lift disadvantaged group, affirmative action
-* Strive for similar outcomes (distributive justice)
-* Group-fairness-style fairness; equality of outcomes
-
-----
-## Equality vs Equity
-
-
-
-
-----
-## Equality vs Equity
-
-
-
-
-----
-## Justice
-
-Aspirational third option, that avoids a choice between equality and equity
-
-Fundamentally removes initial imbalance or removes need for decision
-
-Typically rethinks entire societal system in which the imbalance existed, beyond the scope of the ML product
-
-----
-## Choosing Equality vs Equity
-
-Each rooted in long history in law and philosophy
-
-Typically incompatible, cannot achieve both
-
-Designers need to decide
-
-Problem dependent and goal dependent
-
-What differences are associated with merits and which with systemic disadvantages of certain groups? Can we agree on the degree a group is disadvantaged?
-
-
-----
-## Punitive vs Assistive Decisions
-
-* If the decision is **punitive** in nature:
- * Harm is caused when a group is given an unwarranted penalty
- * e.g. decide whom to deny bail based on risk of recidivism
- * Heuristic: Use a fairness metric (equalized odds) based on false positive rates
-* If the decision is **assistive** in nature:
- * Harm is caused when a group in need is denied assistance
- * e.g., decide who should receive a loan or a food subsidy
- * Heuristic: Use a fairness metric based on false negative rates
-
-----
-## Fairness Tree
-
-
-
-
-
-
-Ian Foster, Rayid Ghani, Ron S. Jarmin, Frauke Kreuter and Julia Lane. [Big Data and Social Science: Data Science Methods and Tools for Research and Practice](https://textbook.coleridgeinitiative.org/). Chapter 11, 2nd ed, 2020
-
-
-----
-## Trade-offs in Fairness vs Accuracy
-
-
-
-
-
-
-
-
-
-Fairness imposes constraints, limits what models can be learned
-
-**But:** Arguably, unfair predictions are not desirable!
-
-Determine how much compromise in accuracy or fairness is acceptable to
- your stakeholders
-
-
-
-
-
-[Fairness Constraints: Mechanisms for Fair Classification.](https://proceedings.mlr.press/v54/zafar17a.html) Zafar et
-al. (AISTATS 2017).
-
-----
-## Fairness, Accuracy, and Profits
-
-
-
-
-
-Interactive visualization: https://research.google.com/bigpicture/attacking-discrimination-in-ml/
-
-----
-## Fairness, Accuracy, and Profits
-
-Fairness can conflict with accuracy goals
-
-Fairness can conflict with organizational goals (profits, usability)
-
-Fairer products may attract more customers
-
-Unfair products may receive bad press, reputation damage
-
-Improving fairness through better data can benefit everybody
-
-
-
-----
-## Discussion: Fairness Goal for Mortgage Applications?
-
-
-
-----
-## Discussion: Fairness Goal for Mortgage Applications?
-
-Disparate impact considerations seem to prevail -- group fairness
-
-Need to justify strong differences in outcomes
-
-Can also sue over disparate treatment if bank indicates that protected attribute was reason for decision
-
-
-
-
-
-
-
-
-
-
-
-----
-## Breakout: Fairness Goal for College Admission?
-
-
-
-
-Post as a group in #lecture:
-* What kind of harm can be caused?
-* Fairness goal: Equality or equity?
-* Model: Anti-classification, group fairness, or equalized odds (with FPR/FNR)?
-
-----
-## Discussion: Fairness Goal for College Admission?
-
-Very limited scope of *affirmative action*: Contentious topic,
-subject of multiple legal cases, banned in many states
-* Supporters: Promote representation, counteract historical bias
-* Opponents: Discriminate against certain racial groups
-
-Most forms of group fairness are likely illegal
-
-In practice: Anti-classification
-
-
-----
-## Discussion: Fairness Goal for Hiring Decisions?
-
-
-
-
-* What kind of harm can be caused?
-* What do we want to achieve? Equality or equity?
-* Anti-classification, group fairness, or equalized odds (FPR/FNR)?
-
-----
-## Law: "Four-fifth rule" (or "80% rule")
-
-
-* Group fairness with a threshold: $\frac{P[R = 1 | A = a]}{P[R = 1 | A = b]} \geq 0.8$
-* Selection rate for a protected group (e.g., $A = a$) <
-80% of highest rate => selection procedure considered as having "adverse
-impact"
-* Guideline adopted by Federal agencies (Department of Justice, Equal
-Employment Opportunity Commission, etc.,) in 1978
-* If violated, must justify business necessity (i.e., the selection procedure is
-essential to the safe & efficient operation)
-* Example: Hiring 50% of male applicants vs 20% female applicants hired
- (0.2/0.5 = 0.4) -- Is there a business justification for hiring men at a higher rate?
-
-
-----
-## Recidivism Revisited
-
-
-
-
-* COMPAS system, developed by Northpointe: Used by judges in
- sentencing decisions across multiple states (incl. PA)
-
-
-
-
-[ProPublica article](https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing)
-
-
-----
-## Which fairness definition?
-
-
-
-
-* ProPublica: COMPAS violates equalized odds w/ FPR & FNR
-* Northpointe: COMPAS is fair because it has similar FDRs
- * FDR = FP / (FP + TP) = 1 - Precision; FPR = FP / (FP + TN)
-* __Q. So is COMPAS both fair & unfair at the same time?__
-
-
-[Figure from Big Data and Social Science, Ch. 11](https://textbook.coleridgeinitiative.org/chap-bias.html#ref-angwin2016b)
-
-
-----
-## Fairness Definitions: Pitfalls
-
-
-
-
-* "Impossibility Theorem": Can't satisfy multiple fairness criteria
-* Easy to pick some definition & claim that the model is fair
- * But does a "fair" model really help reduce harm in the long term?
-* Instead of just focusing on building a "fair"' model, can we understand &
- address the root causes of bias?
-
-
-
-A. Chouldechova [Fair prediction with disparate impact: A study of bias in recidivism prediction instruments](https://arxiv.org/pdf/1703.00056.pdf)
-
-
-
-
-
-
-
----
-# Dataset Construction for Fairness
-
-
-----
-## Flexibility in Data Collection
-
-* Data science education often assumes data as given
-* In industry, we often have control over data collection and curation (65%)
-* Most address fairness issues by collecting more data (73%)
- * Carefully review data collection procedures, sampling bias, how
- trustworthy labels are
- * **Often high-leverage point to improve fairness!**
-
-
-
-
-[Challenges of incorporating algorithmic fairness into practice](https://www.youtube.com/watch?v=UicKZv93SOY),
-FAT* Tutorial, 2019 ([slides](https://bit.ly/2UaOmTG))
-
-----
-## Data Bias
-
-
-
-
-* Bias can be introduced at any stage of the data pipeline!
-
-
-
-Bennett et al., [Fairness-aware Machine Learning](https://sites.google.com/view/wsdm19-fairness-tutorial), WSDM Tutorial (2019).
-
-
-----
-## Types of Data Bias
-
-* __Population bias__
-* __Historical bias__
-* __Behavioral bias__
-* Content production bias
-* Linking bias
-* Temporal bias
-
-
-
-_Social Data: Biases, Methodological Pitfalls, and Ethical
-Boundaries_, Olteanu et al., Frontiers in Big Data (2016).
-
-----
-## Population Bias
-
-
-
-
-* Differences in demographics between dataset vs target population
-* May result in degraded services for certain groups
-
-
-Merler, Ratha, Feris, and Smith. [Diversity in Faces](https://arxiv.org/abs/1901.10436)
-
-----
-## Historical Bias
-
-
-
-
-* Dataset matches the reality, but certain groups are under- or
-over-represented due to historical reasons
-
-----
-## Behavioral Bias
-
-
-
-
-* Differences in user behavior across platforms or social contexts
-* Example: Freelancing platforms (Fiverr vs TaskRabbit)
- * Bias against certain minority groups on different platforms
-
-
-
-_Bias in Online Freelance Marketplaces_, Hannak et al., CSCW (2017).
-
-----
-## Fairness-Aware Data Collection
-
-* Address population bias
-
- * Does the dataset reflect the demographics in the target
- population?
- * If not, collect more data to achieve this
-* Address under- & over-representation issues
-
- * Ensure sufficient amount of data for all groups to avoid being
- treated as "outliers" by ML
- * Also avoid over-representation of certain groups (e.g.,
- remove historical data)
-
-
-_Fairness-aware Machine Learning_, Bennett et al., WSDM Tutorial (2019).
-
-----
-## Fairness-Aware Data Collection
-
-* Data augmentation: Synthesize data for minority groups to reduce under-representation
-
- * Observed: "He is a doctor" -> synthesize "She is a doctor"
-* Model auditing for better data collection
-
- * Evaluate accuracy across different groups
- * Collect more data for groups with highest error rates
-
-
-_Fairness-aware Machine Learning_, Bennett et al., WSDM Tutorial (2019).
-
-----
-## Example Audit Tool: Aequitas
-
-
-
-----
-## Example Audit Tool: Aequitas
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-----
-## Documentation for Fairness: Data Sheets
-
-
-
-
-* Common practice in the electronics industry, medicine
-* Purpose, provenance, creation, __composition__, distribution
- * "Does the dataset relate to people?"
- * "Does the dataset identify any subpopulations (e.g., by age)?"
-
-
-
-_Datasheets for Dataset_, Gebru et al., (2019). https://arxiv.org/abs/1803.09010
-
-----
-## Model Cards
-
-See also: https://modelcards.withgoogle.com/about
-
-
-
-
-
-
-Mitchell, Margaret, et al. "[Model cards for model reporting](https://www.seas.upenn.edu/~cis399/files/lecture/l22/reading2.pdf)." In Proceedings of the Conference on fairness, accountability, and transparency, pp. 220-229. 2019.
-
-
-----
-## Dataset Exploration
-
-
-
-
-[Google What-If Tool](https://pair-code.github.io/what-if-tool/demos/compas.html)
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
----
-# Anticipate Feedback Loops
-
-----
-## Feedback Loops
-
-
-
-
-----
-## Feedback Loops in Mortgage Applications?
-
-
-
-----
-## Feedback Loops go through the Environment
-
-
-
-
-
-
-----
-## Analyze the World vs the Machine
-
-
-
-
-*State and check assumptions!*
-
-
-----
-## Analyze the World vs the Machine
-
-How do outputs affect change in the real world, how does this (indirectly) influence inputs?
-
-Can we decouple inputs from outputs? Can telemetry be trusted?
-
-Interventions through system (re)design:
-* Focus data collection on less influenced inputs
-* Compensate for bias from feedback loops in ML pipeline
-* Do not build the system in the first place
-
-
-----
-## Long-term Impact of ML
-
-* ML systems make multiple decisions over time, influence the
-behaviors of populations in the real world
-* *But* most models are built & optimized assuming that the world is
-static
-* Difficult to estimate the impact of ML over time
- * Need to reason about the system dynamics (world vs machine)
- * e.g., what's the effect of a mortgage lending policy on a population?
-
-----
-## Long-term Impact & Fairness
-
-
-
-Deploying an ML model with a fairness criterion does NOT guarantee
- improvement in equality/equity over time
-
-Even if a model appears to promote fairness in
-short term, it may result harm over long term
-
-
-
-
-
-
-
-
-
-[Fairness is not static: deeper understanding of long term fairness via simulation studies](https://dl.acm.org/doi/abs/10.1145/3351095.3372878),
-in FAT* 2020.
-
-
-----
-## Prepare for Feedback Loops
-
-We will likely not anticipate all feedback loops...
-
-... but we can anticipate that unknown feedback loops exist
-
--> Monitoring!
-
-
-
-
----
-# Monitoring
-
-
-----
-## Monitoring & Auditing
-
-* Operationalize fairness measure in production with telemetry
-* Continuously monitor for:
-
- - Mismatch between training data, test data, and instances encountered in deployment
- - Data shifts: May suggest needs to adjust fairness metric/thresholds
- - User reports & complaints: Log and audit system decisions
- perceived to be unfair by users
-* Invite diverse stakeholders to audit system for biases
-
-
-----
-## Monitoring & Auditing
-
-
-
-
-* Continuosly monitor the fairness metric (e.g., error rates for
-different sub-populations)
-* Re-train model with recent data or adjust classification thresholds
- if needed
-
-
-----
-## Preparing for Problems
-
-Prepare an *incidence response plan* for fairness issues
-* What can be shut down/reverted on short notice?
-* Who does what?
-* Who talks to the press? To affected parties? What do they need to know?
-
-Provide users with a path to *appeal decisions*
-* Provide feedback mechanism to complain about unfairness
-* Human review? Human override?
-
-
-
-
-
----
-# Fairness beyond the Model
-
-----
-## Bias Mitigation through System Design
-
-
-
-Examples of mitigations around the model?
-
-----
-## 1. Avoid Unnecessary Distinctions
-
-
-
-
-*Image captioning gender biased?*
-
-
-----
-## 1. Avoid Unnecessary Distinctions
-
-
-
-
-
-"Doctor/nurse applying blood pressure monitor" -> "Healthcare worker applying blood pressure monitor"
-
-
-----
-## 1. Avoid Unnecessary Distinctions
-
-Is the distinction actually necessary? Is there a more general class to unify them?
-
-Aligns with notion of *justice* to remove the problem from the system
-
-
-----
-## 2. Suppress Potentially Problem Outputs
-
-
-
-
-*How to fix?*
-
-
-----
-## 2. Suppress Potentially Problem Outputs
-
-Anticipate problems or react to reports
-
-Postprocessing, filtering, safeguards
-* Suppress entire output classes
-* Hardcoded rules or other models (e.g., toxicity detection)
-
-May degrade system quality for some use cases
-
-See mitigating mistakes generally
-
-----
-## 3. Design Fail-Soft Strategy
-
-Example: Plagiarism detector
-
-
-
-**A: Cheating detected! This incident has been reported.**
-
-
-
-**B: This answer seems to perfect. Would you like another exercise?**
-
-
-
-
-
-HCI principle: Fail-soft interfaces avoid calling out directly; communicate friendly and constructively to allow saving face
-
-Especially relevant if system unreliable or biased
-
-
-----
-## 4. Keep Humans in the Loop
-
-
-
-
-
-TV subtitles: Humans check transcripts, especially with heavy dialects
-
-----
-## 4. Keep Humans in the Loop
-
-Recall: Automate vs prompt vs augment
-
-Involve humans to correct for mistakes and bias
-
-But, model often introduced to avoid bias in human decision
-
-But, challenging human-interaction design to keep humans engaged and alert; human monitors possibly biased too, making it worse
-
-**Does a human have a fair chance to detect and correct bias?** Enough information? Enough context? Enough time? Unbiased human decision?
-
-----
-## Predictive Policing Example
-
-> "officers expressed skepticism
-about the software and during ride alongs showed no intention of using it"
-
-> "the officer discounted the software since it showed what he already
-knew, while he ignored those predictions that he did not understand"
-
-Does the system just lend credibility to a biased human process?
-
-
-Lally, Nick. "[“It makes almost no difference which algorithm you use”: on the modularity of predictive policing](http://www.nicklally.com/wp-content/uploads/2016/09/lallyModularityPP.pdf)." Urban Geography (2021): 1-19.
-
-
-
-
-
----
-# Process Integration
-
-----
-## Fairness in Practice today
-
-Lots of attention in academia and media
-
-Lofty statements by big companies, mostly aspirational
-
-Strong push by few invested engineers (internal activists)
-
-Some dedicated teams, mostly in Big Tech, mostly research focused
-
-Little institutional support, no broad practices
-
-----
-## Barriers to Fairness Work
-
-
-
-
-----
-## Barriers to Fairness Work
-
-1. Rarely an organizational priority, mostly reactive (media pressure, regulators)
- * Limited resources for proactive work
- * Fairness work rarely required as deliverable, low priority, ignorable
- * No accountability for actually completing fairness work, unclear responsibilities
-
-
-*What to do?*
-
-----
-## Barriers to Fairness Work
-
-2. Fairness work seen as ambiguous and too complicated for available resources (esp. outside Big Tech)
- * Academic discussions and metrics too removed from real problems
- * Fairness research evolves too fast
- * Media attention keeps shifting, cannot keep up
- * Too political
-
-*What to do?*
-
-
-----
-## Barriers to Fairness Work
-
-3. Most fairness work done by volunteers outside official job functions
- * Rarely rewarded in performance evaluations, promotions
- * Activists seen as troublemakers
- * Reliance on personal networks among interested parties
-
-*What to do?*
-
-
-----
-## Barriers to Fairness Work
-
-4. Impact of fairness work difficult to quantify, making it hard to justify resource investment
- * Does it improve sales? Did it avoid PR disaster? Missing counterfactuals
- * Fairness rarely monitored over time
- * Fairness rarely a key performance indicator of product
- * Fairness requires long-term perspective (feedback loops, rare disasters), but organizations focus on short-term goals
-
-*What to do?*
-
-
-----
-## Barriers to Fairness Work
-
-5. Technical challenges
- * Data privacy policies restrict data access for fairness analysis
- * Bureaucracy
- * Distinguishing unimportant user complains from systemic bias issues, debugging bias issues
-
-6. Fairness concerns are project specific, hard to transfer actionable insights and tools across teams
-
-*What to do?*
-
-
-----
-## Improving Process Integration -- Aspirations
-
-Integrate proactive practices in development processes -- both model and system level!
-
-Move from individuals to institutional processes distributing the work
-
-Hold the entire organization accountable for taking fairness seriously
-
-*How?*
-
-
-
-
-----
-## Improving Process Integration -- Examples
-
-1. Mandatory discussion of discrimination risks, protected attributes, and fairness goals in *requirements documents*
-2. Required fairness reporting in addition to accuracy in automated *model evaluation*
-3. Required internal/external fairness audit before *release*
-4. Required fairness monitoring, oversight infrastructure in *operation*
-
-----
-## Improving Process Integration -- Examples
-
-5. Instituting fairness measures as *key performance indicators* of products
-6. Assign clear responsibilities of who does what
-7. Identify measurable fairness improvements, recognize in performance evaluations
-
-*How to avoid pushback against bureaucracy?*
-
-----
-## Affect Culture Change
-
-Buy-in from management is crucial
-
-Show that fairness work is taken seriously through action (funding, hiring, audits, policies), not just lofty mission statements
-
-Reported success strategies:
-1. Frame fairness work as financial profitable, avoiding rework and reputation cost
-2. Demonstrate concrete, quantified evidence of benefits of fairness work
-3. Continuous internal activism and education initiatives
-4. External pressure from customers and regulators
-
-
-----
-## Assigning Responsibilities
-
-Hire/educate T-shaped professionals
-
-Have dedicated fairness expert(s) consulting with teams, performing/guiding audits, etc
-
-Not everybody will be a fairness expert, but ensure base-level awareness on when to seek help
-
-
-----
-## Aspirations
-
-
-
-> "They imagined that organizational leadership would understand, support, and engage deeply with responsible AI concerns, which would be contextualized within their organizational context. Responsible AI would be prioritized as part of the high-level organizational mission and then translated into actionable goals down at the individual levels through established processes. Respondents wanted the spread of information to go through well-established channels so that people know where to look and how to share information."
-
-
-
-
-From Rakova, Bogdana, Jingying Yang, Henriette Cramer, and Rumman Chowdhury. "Where responsible AI meets reality: Practitioner perspectives on enablers for shifting organizational practices." Proceedings of the ACM on Human-Computer Interaction 5, no. CSCW1 (2021): 1-23.
-
-----
-## Burnout is a Real Danger
-
-Unsupported fairness work is frustrating and often ineffective
-
-> “However famous the company is, it’s not worth being in a work situation where you don’t feel like your entire company, or at least a significant part of your company, is trying to do this with you. Your job is not to be paid lots of money to point out problems. Your job is to help them make their product better. And if you don’t believe in the product, then don’t work there.” -- Rumman Chowdhury via [Melissa Heikkilä](https://www.technologyreview.com/2022/11/01/1062474/how-to-survive-as-an-ai-ethicist/)
-
-
-
-
-
-
-
----
-# Best Practices
-
-----
-## Best Practices
-
-**Best practices are emerging and evolving**
-
-Start early, be proactive
-
-Scrutinize data collection and labeling
-
-Invest in requirements engineering and design
-
-Invest in education
-
-Assign clear responsibilities, demonstrate leadership buy-in
-
-----
-## Many Tutorials, Checklists, Recommendations
-
-Tutorials (fairness notions, sources of bias, process recom.):
-* [Fairness in Machine Learning](https://vimeo.com/248490141), [Fairness-Aware Machine Learning in Practice](https://sites.google.com/view/fairness-tutorial)
-* [Challenges of Incorporating Algorithmic Fairness into Industry Practice](https://www.microsoft.com/en-us/research/video/fat-2019-translation-tutorial-challenges-of-incorporating-algorithmic-fairness-into-industry-practice/)
-
-Checklist:
-* Microsoft’s [AI Fairness Checklist](https://www.microsoft.com/en-us/research/project/ai-fairness-checklist/): concrete questions, concrete steps throughout all stages, including deployment and monitoring
-
-
-
-
-
-
-
-
-
-
-
-
-
----
-# Summary
-
-* Requirements engineering for fair ML systems
- * Identify potential harms, protected attributes
- * Negotiate conflicting fairness goals, tradeoffs
- * Consider societal implications
-* Apply fair data collection practices
-* Anticipate feedback loops
-* Operationalize & monitor for fairness metrics
-* Design fair systems beyond the model, mitigate bias outside the model
-* Integrate fairness work in process and culture
-
-
-----
-## Further Readings
-
-
-
-- 🗎 Rakova, Bogdana, Jingying Yang, Henriette Cramer, and Rumman Chowdhury. "[Where responsible AI meets reality: Practitioner perspectives on enablers for shifting organizational practices](https://arxiv.org/abs/2006.12358)." *Proceedings of the ACM on Human-Computer Interaction* 5, no. CSCW1 (2021): 1-23.
-- 🗎 Mitchell, Margaret, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. "[Model cards for model reporting](https://arxiv.org/abs/1810.03993)." In *Proceedings of the conference on fairness, accountability, and transparency*, pp. 220-229. 2019.
-- 🗎 Boyd, Karen L. "[Datasheets for Datasets help ML Engineers Notice and Understand Ethical Issues in Training Data](http://karenboyd.org/Datasheets_Help_CSCW.pdf)." Proceedings of the ACM on Human-Computer Interaction 5, no. CSCW2 (2021): 1-27.
-- 🗎 Bietti, Elettra. "[From ethics washing to ethics bashing: a view on tech ethics from within moral philosophy](https://dl.acm.org/doi/pdf/10.1145/3351095.3372860)." In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, pp. 210-219. 2020.
-- 🗎 Madaio, Michael A., Luke Stark, Jennifer Wortman Vaughan, and Hanna Wallach. "[Co-Designing Checklists to Understand Organizational Challenges and Opportunities around Fairness in AI](http://www.jennwv.com/papers/checklists.pdf)." In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, pp. 1-14. 2020.
-- 🗎 Hopkins, Aspen, and Serena Booth. "[Machine Learning Practices Outside Big Tech: How Resource Constraints Challenge Responsible Development](http://www.slbooth.com/papers/AIES-2021_Hopkins_and_Booth.pdf)." In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society (AIES ’21) (2021).
-- 🗎 Metcalf, Jacob, and Emanuel Moss. "[Owning ethics: Corporate logics, silicon valley, and the institutionalization of ethics](https://datasociety.net/wp-content/uploads/2019/09/Owning-Ethics-PDF-version-2.pdf)." *Social Research: An International Quarterly* 86, no. 2 (2019): 449-476.
-
-
diff --git a/lectures/18_system_fairness/temi.png b/lectures/18_system_fairness/temi.png
deleted file mode 100644
index 29ce2dd5..00000000
Binary files a/lectures/18_system_fairness/temi.png and /dev/null differ
diff --git a/lectures/18_system_fairness/user-review1.png b/lectures/18_system_fairness/user-review1.png
deleted file mode 100644
index 291a81c6..00000000
Binary files a/lectures/18_system_fairness/user-review1.png and /dev/null differ
diff --git a/lectures/18_system_fairness/user-review2.png b/lectures/18_system_fairness/user-review2.png
deleted file mode 100644
index 80fadfdb..00000000
Binary files a/lectures/18_system_fairness/user-review2.png and /dev/null differ
diff --git a/lectures/18_system_fairness/what-if-tool.png b/lectures/18_system_fairness/what-if-tool.png
deleted file mode 100644
index af3da32f..00000000
Binary files a/lectures/18_system_fairness/what-if-tool.png and /dev/null differ
diff --git a/lectures/18_system_fairness/worldvsmachine.svg b/lectures/18_system_fairness/worldvsmachine.svg
deleted file mode 100644
index d1ecb609..00000000
--- a/lectures/18_system_fairness/worldvsmachine.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/19_explainability/accuracy_explainability.png b/lectures/19_explainability/accuracy_explainability.png
deleted file mode 100644
index a4a6c35b..00000000
Binary files a/lectures/19_explainability/accuracy_explainability.png and /dev/null differ
diff --git a/lectures/19_explainability/adversarialexample.png b/lectures/19_explainability/adversarialexample.png
deleted file mode 100644
index ba5abb74..00000000
Binary files a/lectures/19_explainability/adversarialexample.png and /dev/null differ
diff --git a/lectures/19_explainability/badges.png b/lectures/19_explainability/badges.png
deleted file mode 100644
index 59f50d73..00000000
Binary files a/lectures/19_explainability/badges.png and /dev/null differ
diff --git a/lectures/19_explainability/cancerdialog.png b/lectures/19_explainability/cancerdialog.png
deleted file mode 100644
index 63619a7d..00000000
Binary files a/lectures/19_explainability/cancerdialog.png and /dev/null differ
diff --git a/lectures/19_explainability/cancerpred.png b/lectures/19_explainability/cancerpred.png
deleted file mode 100644
index 5ebc2552..00000000
Binary files a/lectures/19_explainability/cancerpred.png and /dev/null differ
diff --git a/lectures/19_explainability/cat.png b/lectures/19_explainability/cat.png
deleted file mode 100644
index 6743b764..00000000
Binary files a/lectures/19_explainability/cat.png and /dev/null differ
diff --git a/lectures/19_explainability/cheyneylibrary.jpeg b/lectures/19_explainability/cheyneylibrary.jpeg
deleted file mode 100644
index ad0113b0..00000000
Binary files a/lectures/19_explainability/cheyneylibrary.jpeg and /dev/null differ
diff --git a/lectures/19_explainability/compas_screenshot.png b/lectures/19_explainability/compas_screenshot.png
deleted file mode 100644
index 79cb7e83..00000000
Binary files a/lectures/19_explainability/compas_screenshot.png and /dev/null differ
diff --git a/lectures/19_explainability/conceptbottleneck.png b/lectures/19_explainability/conceptbottleneck.png
deleted file mode 100644
index f493139c..00000000
Binary files a/lectures/19_explainability/conceptbottleneck.png and /dev/null differ
diff --git a/lectures/19_explainability/emeter.png b/lectures/19_explainability/emeter.png
deleted file mode 100644
index 11b2ef77..00000000
Binary files a/lectures/19_explainability/emeter.png and /dev/null differ
diff --git a/lectures/19_explainability/expl_confidence.png b/lectures/19_explainability/expl_confidence.png
deleted file mode 100644
index a107a3e8..00000000
Binary files a/lectures/19_explainability/expl_confidence.png and /dev/null differ
diff --git a/lectures/19_explainability/explainability.md b/lectures/19_explainability/explainability.md
deleted file mode 100644
index 9a2b4d0b..00000000
--- a/lectures/19_explainability/explainability.md
+++ /dev/null
@@ -1,1461 +0,0 @@
----
-author: Christian Kaestner and Eunsuk Kang
-title: "MLiP: Explainability and Interpretability"
-semester: Spring 2023
-footer: "Machine Learning in Production/AI Engineering • Christian Kaestner & Eunsuk Kang, Carnegie Mellon University • Spring 2023"
-license: Creative Commons Attribution 4.0 International (CC BY 4.0)
----
-
-
-
-## Machine Learning in Production
-
-
-# Explainability and Interpretability
-
-
----
-## Explainability as Building Block in Responsible Engineering
-
-
-
-
-
-
-----
-## "Readings"
-
-Required one of:
-* 🎧 Data Skeptic Podcast Episode “[Black Boxes are not Required](https://dataskeptic.com/blog/episodes/2020/black-boxes-are-not-required)” with Cynthia Rudin (32min)
-* 🗎 Rudin, Cynthia. "[Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead](https://arxiv.org/abs/1811.10154)." Nature Machine Intelligence 1, no. 5 (2019): 206-215.
-
-Recommended supplementary reading:
-* 🕮 Christoph Molnar. "[Interpretable Machine Learning: A Guide for Making Black Box Models Explainable](https://christophm.github.io/interpretable-ml-book/)." 2019
-
-----
-# Learning Goals
-
-* Understand the importance of and use cases for interpretability
-* Explain the tradeoffs between inherently interpretable models and post-hoc explanations
-* Measure interpretability of a model
-* Select and apply techniques to debug/provide explanations for data, models and model predictions
-* Eventuate when to use interpretable models rather than ex-post explanations
-
----
-# Motivating Examples
-
-
-----
-
-
-
-
-
-----
-
-
-
-
-
-Image: Gong, Yuan, and Christian Poellabauer. "[An overview of vulnerabilities of voice controlled systems](https://arxiv.org/pdf/1803.09156.pdf)." arXiv preprint arXiv:1803.09156 (2018).
-
-----
-## Detecting Anomalous Commits
-
-[](nodejs-unusual-commit.png)
-
-
-
-Goyal, Raman, Gabriel Ferreira, Christian Kästner, and James Herbsleb. "[Identifying unusual commits on GitHub](https://www.cs.cmu.edu/~ckaestne/pdf/jsep17.pdf)." Journal of Software: Evolution and Process 30, no. 1 (2018): e1893.
-
-----
-## Is this recidivism model fair?
-
-```fortran
-IF age between 18–20 and sex is male THEN
- predict arrest
-ELSE IF age between 21–23 and 2–3 prior offenses THEN
- predict arrest
-ELSE IF more than three priors THEN
- predict arrest
-ELSE
- predict no arrest
-```
-
-
-
-Rudin, Cynthia. "[Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead](https://arxiv.org/abs/1811.10154)." Nature Machine Intelligence 1, no. 5 (2019): 206-215.
-
-----
-## How to interpret the results?
-
-
-
-
-
-Image source (CC BY-NC-ND 4.0): Christin, Angèle. (2017). Algorithms in practice: Comparing web journalism and criminal justice. Big Data & Society. 4.
-
-----
-## How to consider seriousness of the crime?
-
-
-
-
-
-Rudin, Cynthia, and Berk Ustun. "[Optimized scoring systems: Toward trust in machine learning for healthcare and criminal justice](https://users.cs.duke.edu/~cynthia/docs/WagnerPrizeCurrent.pdf)." Interfaces 48, no. 5 (2018): 449-466.
-
-----
-## What factors go into predicting stroke risk?
-
-
-
-
-
-Rudin, Cynthia, and Berk Ustun. "[Optimized scoring systems: Toward trust in machine learning for healthcare and criminal justice](https://users.cs.duke.edu/~cynthia/docs/WagnerPrizeCurrent.pdf)." Interfaces 48, no. 5 (2018): 449-466.
-
-----
-## Is there an actual problem? How to find out?
-
-
-
-----
-
-
-
-----
-
-
-
-----
-
-
-----
-## Explaining Decisions
-
-Cat? Dog? Lion? -- Confidence? Why?
-
-
-
-
-----
-## What's happening here?
-
-
-
-
-
-----
-## Explaining Decisions
-
-[](slacknotifications.jpg)
-
-
-----
-## Explainability in ML
-
-Explain how the model made a decision
- - Rules, cutoffs, reasoning?
- - What are the relevant factors?
- - Why those rules/cutoffs?
-
-Challenging because models too complex and based on data
- - Can we understand the rules?
- - Can we understand why these rules?
-
-
-
-
-
----
-# Why Explainability?
-
-----
-## Why Explainability?
-
-
-
-----
-## Debugging
-
-
-
-* Why did the system make a wrong prediction in this case?
-* What does it actually learn?
-* What data makes it better?
-* How reliable/robust is it?
-* How much does second model rely on outputs of first?
-* Understanding edge cases
-
-
-
-
-
-
-
-**Debugging is the most common use in practice** (Bhatt et al. "Explainable machine learning in deployment." In Proc. FAccT. 2020.)
-
-
-----
-## Auditing
-
-* Understand safety implications
-* Ensure predictions use objective criteria and reasonable rules
-* Inspect fairness properties
-* Reason about biases and feedback loops
-* Validate "learned specifications/requirements" with stakeholders
-
-```fortran
-IF age between 18–20 and sex is male THEN predict arrest
-ELSE IF age between 21–23 and 2–3 prior offenses THEN predict arrest
-ELSE IF more than three priors THEN predict arrest
-ELSE predict no arrest
-```
-
-----
-## Trust
-
-
-
-More accepting a prediction if clear how it is made, e.g.,
- * Model reasoning matches intuition; reasoning meets fairness criteria
- * Features are difficult to manipulate
- * Confidence that the model generalizes beyond target distribution
-
-
-
-
-
-
-
-
-Conceptual model of trust: R. C. Mayer, J. H. Davis, and F. D. Schoorman. An integrative model of organizational trust. Academy
-of Management Review, 20(3):709–734, July 1995.
-
-
-
-----
-## Actionable Insights to Improve Outcomes
-
-> "What can I do to get the loan?"
-
-> "How can I change my message to get more attention on Twitter?"
-
-> "Why is my message considered as spam?"
-
-----
-## Regulation / Legal Requirements
-
-
-> The EU General Data Protection Regulation extends the automated decision-making rights [...] to provide a legally disputed form of a **right to an explanation**: "[the data subject should have] the right ... to obtain an explanation of the decision reached"
-
-
-
-> US Equal Credit Opportunity Act requires to notify applicants of action taken with specific reasons: "The statement of reasons for adverse action required by paragraph (a)(2)(i) of this section must be specific and indicate the principal reason(s) for the adverse action."
-
-
-
-See also https://en.wikipedia.org/wiki/Right_to_explanation
-
-----
-## Curiosity, learning, discovery, science
-
-
-
-
-----
-## Curiosity, learning, discovery, science
-
-
-
-
-
-----
-## Settings where Interpretability is *not* Important?
-
-
-
-Notes:
-* Model has no significant impact (e.g., exploration, hobby)
-* Problem is well studied? e.g optical character recognition
-* Security by obscurity? -- avoid gaming
-
-
-
-
-----
-## Exercise: Debugging a Model
-
-Consider the following debugging challenges. In groups discuss how you would debug the problem. In 3 min report back to the class.
-
-
-*Algorithm bad at recognizing some signs in some conditions:*
-
-
-*Graduate appl. system seems to rank applicants from HBCUs low:*
-
-
-
-
-
-Left Image: CC BY-SA 4.0, Adrian Rosebrock
-
-
-
-
-
-
-
-
-
----
-# Defining Interpretability
-
-
-Christoph Molnar. "[Interpretable Machine Learning: A Guide for Making Black Box Models Explainable](https://christophm.github.io/interpretable-ml-book/)." 2019
-----
-## Interpretability Definitions
-
-Two common approaches:
-
-> Interpretability is the degree to which a human can understand the cause of a decision
-
-> Interpretability is the degree to which a human can consistently predict the model’s result.
-
-(No mathematical definition)
-
-
-**How would you measure interpretability?**
-----
-## Explanation
-
-Understanding a single prediction for a given input
-
-> Your loan application has been *declined*. If your *savings account* had had more than $100 your loan application would be *accepted*.
-
-Answer **why** questions, such as
- * Why was the loan rejected? (justification)
- * Why did the treatment not work for the patient? (debugging)
- * Why is turnover higher among women? (general science question)
-
-**How would you measure explanation quality?**
-
-----
-## Intrinsic interpretability vs Post-hoc explanation?
-
-
-Models simple enough to understand
-(e.g., short decision trees, sparse linear models)
-
-
-
-Explanation of opaque model, local or global
-
-> Your loan application has been *declined*. If your *savings account* had more than $100 your loan application would be *accepted*.
-
-
-
-----
-## On Terminology
-
-Rudin's terminology and this lecture:
- - Interpretable models: Intrinsily interpretable models
- - Explainability: Post-hoc explanations
-
-Interpretability: property of a model
-
-Explainability: ability to explain the workings/predictions of a model
-
-Explanation: justification of a single prediction
-
-Transparency: The user is aware that a model is used / how it works
-
-*These terms are often used inconsistently or interchangeble*
-
-
-
-
-
-
-
-
-
-
-
-
----
-# Understanding a Model
-
-Levels of explanations:
-
-* **Understanding a model**
-* Explaining a prediction
-* Understanding the data
-
-----
-## Inherently Interpretable: Sparse Linear Models
-
-$f(x) = \alpha + \beta_1 x_1 + ... + \beta_n x_n$
-
-Truthful explanations, easy to understand for humans
-
-Easy to derive contrastive explanation and feature importance
-
-Requires feature selection/regularization to minimize to few important features (e.g. Lasso); possibly restricting possible parameter values
-
-----
-## Score card: Sparse linear model with "round" coefficients
-
-
-
-
-----
-## Inherently Interpretable: Shallow Decision Trees
-
-Easy to interpret up to a size
-
-Possible to derive counterfactuals and feature importance
-
-Unstable with small changes to training data
-
-
-```fortran
-IF age between 18–20 and sex is male THEN predict arrest
-ELSE IF age between 21–23 and 2–3 prior offenses THEN predict arrest
-ELSE IF more than three priors THEN predict arrest
-ELSE predict no arrest
-```
-
-----
-## Not all Linear Models and Decision Trees are Inherently Interpretable
-
-* Models can be very big, many parameters (factors, decisions)
-* Nonlinear interactions possibly hard to grasp
-* Tool support can help (views)
-* Random forests, ensembles no longer easily interpretable
-
-
-
-```
-173554.681081086 * root + 318523.818532818 * heuristicUnit + -103411.870761673 * eq + -24600.5000000002 * heuristicVsids +
--11816.7857142856 * heuristicVmtf + -33557.8961038976 * heuristic + -95375.3513513509 * heuristicUnit * satPreproYes +
-3990.79729729646 * transExt * satPreproYes + -136928.416666666 * eq * heuristicUnit + 12309.4990990994 * eq * satPreproYes +
-33925.0833333346 * eq * heuristic + -643.428571428088 * backprop * heuristicVsids + -11876.2857142853 * backprop *
-heuristicUnit + 1620.24242424222 * eq * backprop + -7205.2500000002 * eq * heuristicBerkmin + -2 * Num1 * Num2 + 10 * Num3 * Num4
-```
-
-
-
-Notes: Example of a performance influence model from http://www.fosd.de/SPLConqueror/ -- not the worst in terms of interpretability, but certainly not small or well formated or easy to approach.
-
-
-----
-## Inherently Interpretable: Decision Rules
-
-*if-then rules mined from data*
-
-easy to interpret if few and simple rules
-
-
-see [association rule mining](https://en.wikipedia.org/wiki/Association_rule_mining):
-```text
-{Diaper, Beer} -> Milk (40% support, 66% confidence)
-Milk -> {Diaper, Beer} (40% support, 50% confidence)
-{Diaper, Beer} -> Bread (40% support, 66% confidence)
-```
-
-
-----
-## Research in Inherently Interpretable Models
-
-Several approaches to learn sparse constrained models (e.g., fit score cards, simple if-then-else rules)
-
-Often heavy emphasis on feature engineering and domain-specificity
-
-Possibly computationally expensive
-
-
-
-Rudin, Cynthia. "[Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead](https://arxiv.org/abs/1811.10154)." Nature Machine Intelligence 1, no. 5 (2019): 206-215.
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-----
-## Post-Hoc Model Explanation: Global Surrogates
-
-1. Select dataset X (previous training set or new dataset from same distribution)
-2. Collect model predictions for every value: $y_i=f(x_i)$
-3. Train *inherently interpretable* model $g$ on (X,Y)
-4. Interpret surrogate model $g$
-
-
-Can measure how well $g$ fits $f$ with common model quality measures, typically $R^2$
-
-**Advantages? Disadvantages?**
-
-Notes:
-Flexible, intuitive, easy approach, easy to compare quality of surrogate model with validation data ($R^2$).
-But: Insights not based on real model; unclear how well a good surrogate model needs to fit the original model; surrogate may not be equally good for all subsets of the data; illusion of interpretability.
-Why not use surrogate model to begin with?
-
-
-----
-## Advantages and Disadvantages of Surrogates?
-
-
-
-
-----
-## Advantages and Disadvantages of Surrogates?
-
-* short, contrastive explanations possible
-* useful for debugging
-* easy to use; works on lots of different problems
-* explanations may use different features than original model
-*
-* explanation not necessarily truthful
-* explanations may be unstable
-* likely not sufficient for compliance scenario
-
-
-----
-## Post-Hoc Model Explanation: Feature Importance
-
-
-
-
-
-
-
-Source:
-Christoph Molnar. "[Interpretable Machine Learning](https://christophm.github.io/interpretable-ml-book/)." 2019
-
-----
-## Feature Importance
-
-* Permute a feature's values in validation data -> hide it for prediction
-* Measure influence on accuracy
-* -> This evaluates feature's influence without retraining the model
-*
-* Highly compressed, *global* insights
-* Effect for feature + interactions
-* Can only be computed on labeled data, depends on model accuracy, randomness from permutation
-* May produce unrealistic inputs when correlations exist
-
-(Can be evaluated both on training and validation data)
-
-
-Note: Training vs validation is not an obvious answer and both cases can be made, see Molnar's book. Feature importance on the training data indicates which features the model has learned to use for predictions.
-
-
-
-
-
-
-
-----
-## Post-Hoc Model Explanation: Partial Dependence Plot (PDP)
-
-
-
-
-
-
-Source:
-Christoph Molnar. "[Interpretable Machine Learning](https://christophm.github.io/interpretable-ml-book/)." 2019
-
-Note: bike rental data in DC
-
-----
-## Partial Dependence Plot
-
-* Computes marginal effect of feature on predicted outcome
-* Identifies relationship between feature and outcome (linear, monotonous, complex, ...)
-*
-* Intuitive, easy interpretation
-* Assumes no correlation among features
-
-
-
-----
-## Partial Dependence Plot for Interactions
-
-
-
-
-
-
-Probability of cancer; source:
-Christoph Molnar. "[Interpretable Machine Learning](https://christophm.github.io/interpretable-ml-book/)." 2019
-
-
-----
-## Concept Bottleneck Models
-
-
-
-Hybrid/partially interpretable model
-
-Force models to learn features, not final predictions. Use inherently interpretable model on those features
-
-Requries to label features in training data
-
-
-
-
-
-
-
-
-
-Koh, Pang Wei, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. "[Concept bottleneck models](http://proceedings.mlr.press/v119/koh20a/koh20a.pdf)." In Proc. ICML, 2020.
-
-----
-## Summary: Understanding a Model
-
-Understanding of the whole model, not individual predictions!
-
-Some models inherently interpretable:
-* Sparse linear models
-* Shallow decision trees
-
-Ex-post explanations for opaque models:
-* Global surrogate models
-* Feature importance, partial dependence plots
-* Many more in the literature
-
-
-
-
-
-
----
-# Explaining a Prediction
-
-
-Levels of explanations:
-
-* Understanding a model
-* **Explaining a prediction**
-* Understanding the data
-
-
-----
-## Understanding Predictions from Inherently Interpretable Models is easy
-
-Derive key influence factors or decisions from model parameters
-
-Derive contrastive counterfacturals from models
-
-**Examples:** Predict arrest for 18 year old male with 1 prior:
-
-```fortran
-IF age between 18–20 and sex is male THEN predict arrest
-ELSE IF age between 21–23 and 2–3 prior offenses THEN predict arrest
-ELSE IF more than three priors THEN predict arrest
-ELSE predict no arrest
-```
-
-
-----
-## Posthoc Prediction Explanation: Feature Influences
-
-*Which features were most influential for a specific prediction?*
-
-
-
-
-
-
-
-Source: https://github.com/marcotcr/lime
-
-----
-## Feature Influences in Images
-
-
-
-
-
-Source: https://github.com/marcotcr/lime
-
-----
-## Feature Importance vs Feature Influence
-
-
-
-Feature importance is global for the entire model (all predictions)
-
-
-
-
-
-
-Feature influence is for a single prediction
-
-
-
-
-
-----
-## Feature Infl. with Local Surrogates (LIME)
-
-*Create an inherently interpretable model (e.g. sparse linear model) for the area around a prediction*
-
-Lime approach:
-* Create random samples in the area around the data point of interest
-* Collect model predictions with $f$ for each sample
-* Learn surrogate model $g$, weighing samples by distance
-* Interpret surrogate model $g$
-
-
-Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. "["Why should I trust you?" Explaining the predictions of any classifier](http://dust.ess.uci.edu/ppr/ppr_RSG16.pdf)." In Proc International Conference on Knowledge Discovery and Data Mining, pp. 1135-1144. 2016.
-
-----
-
-
-
-
-
-
-Source:
-Christoph Molnar. "[Interpretable Machine Learning: A Guide for Making Black Box Models Explainable](https://christophm.github.io/interpretable-ml-book/)." 2019
-
-Note: Model distinguishes blue from gray area. Surrogate model learns only a while line for the nearest decision boundary, which may be good enough for local explanations.
-
-
-----
-## LIME Example
-
-
-
-
-Source: Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. "["Why should I trust you?" Explaining the predictions of any classifier](http://dust.ess.uci.edu/ppr/ppr_RSG16.pdf)." In Proc. KDD. 2016.
-
-----
-## Advantages and Disadvantages of Local Surrogates?
-
-
-
-
-----
-## Posthoc Prediction Explanation: Shapley Values / SHAP
-
-
-
-* Game-theoretic foundation for local explanations (1953)
-* Explains contribution of feature, over predictions with different feature subsets
- - *"The Shapley value is the average marginal contribution of a feature value across all possible coalitions"*
-* Solid theory ensures fair mapping of influence to features
-* Requires heavy computation, usually only approximations feasible
-* Explanations contain all features (ie. not sparse)
-**Currently, most common local method used in practice**
-
-
-
-
-
-Lundberg, Scott M., and Su-In Lee. "[A unified approach to interpreting model predictions](https://proceedings.neurips.cc/paper/2017/file/8a20a8621978632d76c43dfd28b67767-Paper.pdf)." In Advances in neural information processing systems, pp. 4765-4774. 2017.
-
-
-
-
-
-
-
-
-
-
-
-
-
-----
-## Counterfactual Explanations
-
-*if X had not occured, Y would not have happened*
-
-> Your loan application has been *declined*. If your *savings account* had had more than $100 your loan application would be *accepted*.
-
-
--> Smallest change to feature values that result in given output
-
-
-
-----
-## Multiple Counterfactuals
-
-
-
-
-
-Often long or multiple explanations
-
-> Your loan application has been *declined*. If your *savings account* ...
-
-> Your loan application has been *declined*. If your lived in ...
-
-Report all or select "best" (e.g. shortest, most actionable, likely values)
-
-
-*(Rashomon effect)*
-
-
-
-
-
-
-
-
-----
-## Searching for Counterfactuals?
-
-
-
-----
-## Searching for Counterfactuals
-
-Random search (with growing distance) possible, but inefficient
-
-Many search heuristics, e.g. hill climbing or Nelder–Mead, may use gradient of model if available
-
-Can incorporate distance in loss function
-
-$$L(x,x^\prime,y^\prime,\lambda)=\lambda\cdot(\hat{f}(x^\prime)-y^\prime)^2+d(x,x^\prime)$$
-
-
-(similar to finding adversarial examples)
-
-
-----
-
-
-
-----
-## Discussion: Counterfactuals
-
-* Easy interpretation, can report both alternative instance or required change
-* No access to model or data required, easy to implement
-*
-* Often many possible explanations (Rashomon effect), requires selection/ranking
-* May require changes to many features, not all feasible
-* May not find counterfactual within given distance
-* Large search spaces, especially with high-cardinality categorical features
-
-----
-## Actionable Counterfactuals
-
-*Example: Denied loan application*
-
-* Customer wants feedback of how to get the loan approved
-* Some suggestions are more actionable than others, e.g.,
- * Easier to change income than gender
- * Cannot change past, but can wait
-* In distance function, not all features may be weighted equally
-
-----
-## Similarity
-
-
-
-* k-Nearest Neighbors inherently interpretable (assuming intutive distance function)
-* Attempts to build inherently interpretable image classification models based on similarity of fragments
-
-
-
-
-
-
-
-
-
-Chen, Chaofan, Oscar Li, Daniel Tao, Alina Barnett, Cynthia Rudin, and Jonathan K. Su. "This looks like that: deep learning for interpretable image recognition." In NeurIPS (2019).
-
-
-
-----
-## Summary: Understanding a Prediction
-
-Understanding a single predictions, not the model as a whole
-
-Explaining influences, providing counterfactuals and sufficient conditions, showing similar instances
-
-Easy on inherently interpretable models
-
-Ex-post explanations for opaque models:
-* Feature influences (LIME, SHAP, attention maps)
-* Searching for Cunterfactuals
-* Similarity, knn
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
----
-# Understanding the Data
-
-
-Levels of explanations:
-
-* Understanding a model
-* Explaining a prediction
-* **Understanding the data**
-
-
-
-----
-## Prototypes and Criticisms
-
-* *Prototype* is a data instance that is representative of all the data
-* *Criticism* is a data instance not well represented by the prototypes
-
-
-
-
-
-Source:
-Christoph Molnar. "[Interpretable Machine Learning](https://christophm.github.io/interpretable-ml-book/)." 2019
-
-----
-## Example: Prototypes and Criticisms?
-
-
-
-
-
-----
-## Example: Prototypes and Criticisms
-
-
-
-
-
-Source:
-Christoph Molnar. "[Interpretable Machine Learning](https://christophm.github.io/interpretable-ml-book/)." 2019
-
-----
-## Example: Prototypes and Criticisms
-
-
-
-
-
-Source:
-Christoph Molnar. "[Interpretable Machine Learning](https://christophm.github.io/interpretable-ml-book/)." 2019
-
-Note: The number of digits is different in each set since the search was conducted globally, not per group.
-
-
-----
-## Methods: Prototypes and Criticisms
-
-Clustering of data (ala k-means)
- * k-medoids returns actual instances as centers for each cluster
- * MMD-critic identifies both prototypes and criticisms
- * see book for details
-
-Identify globally or per class
-
-----
-## Discussion: Prototypes and Criticisms
-
-* Easy to inspect data, useful for debugging outliers
-* Generalizes to different kinds of data and problems
-* Easy to implement algorithm
-*
-* Need to choose number of prototypes and criticism upfront
-* Uses all features, not just features important for prediction
-
-
-
-----
-## Influential Instance
-
-**Data debugging:** *What data most influenced the training?*
-
-
-
-
-
-Source:
-Christoph Molnar. "[Interpretable Machine Learning](https://christophm.github.io/interpretable-ml-book/)." 2019
-
-----
-## Influential Instances
-
-**Data debugging:** *What data most influenced the training? Is the model skewed by few outliers?*
-
-Approach:
-* Given training data with $n$ instances...
-* ... train model $f$ with all $n$ instances
-* ... train model $g$ with $n-1$ instances
-* If $f$ and $g$ differ significantly, omitted instance was influential
- - Difference can be measured e.g. in accuracy or difference in parameters
-
-Note: Instead of understanding a single model, comparing multiple models trained on different data
-
-
-----
-## Influential Instances Discussion
-
-Retraining for every data point is simple but expensive
-
-For some class of models, influence of data points can be computed without retraining (e.g., logistic regression), see book for details
-
-Hard to generalize to taking out multiple instances together
-
-Useful model-agnostic debugging tool for models and data
-
-
-
-Christoph Molnar. "[Interpretable Machine Learning: A Guide for Making Black Box Models Explainable](https://christophm.github.io/interpretable-ml-book/)." 2019
-
-----
-## Three Concepts
-
-**Feature importance:** How much does the model rely on a feature, across all predictions?
-
-**Feature influence:** How much does a specific prediction rely on a feature?
-
-**Influential instance:** How much does the model rely on a single training data instance?
-
-----
-## Summary: Understanding the Data
-
-Understand the characteristics of the data used to train the model
-
-Many data exploration and data debugging techniques:
-* Criticisms and prototypes
-* Influential instances
-* many others...
-
-
-
-
-
-
-
-
-
-
-
----
-## Breakout: Debugging with Explanations
-
-
-
-In groups, discuss which explainability approaches may help and why. Tagging group members, write to `#lecture`.
-
-
-*Algorithm bad at recognizing some signs in some conditions:*
-
-
-*Graduate appl. system seems to rank applicants from HBCUs low:*
-
-
-
-
-
-
-Left Image: CC BY-SA 4.0, Adrian Rosebrock
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
----
-# Explanations and User Interaction Design
-
-
-
-[People + AI Guidebook](https://pair.withgoogle.com/research/), Google
-
-
-
-----
-## How to Present Explanations?
-
-
-
-
-
-
-Kulesza, T., Burnett, M., Wong, W-K. & Stumpf, S.. Principles of
-s Explanatory Debugging to personalize interactive machine learning. In: Proc. IUI, 2015
-
-
-
-
-
-
-----
-
-
-
-
-
-
-
-
-
-
-Tell the user when a lack of data might mean they’ll need to use their own judgment. Don’t be afraid to admit when a lack of data could affect the quality of the AI recommendations.
-
-
-
-
-Source:
-[People + AI Guidebook](https://pair.withgoogle.com/research/), Google
-
-
-----
-
-
-
-
-
-Give the user details about why a prediction was made in a high stakes scenario. Here, the user is exercising after an injury and needs confidence in the app’s recommendation.
-
-
-Source:
-[People + AI Guidebook](https://pair.withgoogle.com/research/), Google
-
-
-
-----
-
-
-
-
-**Example each?**
-
-
-Source: [People + AI Guidebook](https://pair.withgoogle.com/research/), Google
-
-
-
-
-
-
-
-
-
-
-
-
-
----
-# Beyond "Just" Explaining the Model
-
-
-
-Cai, Carrie J., Samantha Winter, David Steiner, Lauren Wilcox, and Michael Terry. ""Hello AI": Uncovering the Onboarding Needs of Medical Practitioners for Human-AI Collaborative Decision-Making." Proceedings of the ACM on Human-computer Interaction 3, no. CSCW (2019): 1-24.
-
-----
-## Setting Cancer Imaging -- What explanations do radiologists want?
-
-
-
-* *Past attempts often not successful at bringing tools into production. Radiologists do not trust them. Why?*
-* [Wizard of oz study](https://en.wikipedia.org/wiki/Wizard_of_Oz_experiment) to elicit requirements
-
-----
-
-
-
-
-----
-
-
-----
-## Radiologists' questions
-
-
-* How does it perform compared to human experts?
-* "What is difficult for the AI to know? Where is it too sensitive? What criteria is it good at recognizing or not good at recognizing?"
-* What data (volume, types, diversity) was the model trained on?
-* "Does the AI have access to information that I don’t have? Does it have access to ancillary studies?" Is all used data shown in the UI?
-* What kind of things is the AI looking for? What is it capable of learning? ("Maybe light and dark? Maybe colors? Maybe shapes, lines?", "Does it take into consideration the relationship between gland and stroma? Nuclear relationship?")
-* "Does it have a bias a certain way?" (compared to colleagues)
-
-
-
-----
-## Radiologists' questions
-
-* Capabilities and limitations: performance, strength, limitations; e.g. how does it handle well-known edge cases
-* Functionality: What data used for predictions, how much context, how data is used
-* Medical point-of-view: calibration, how liberal/conservative when grading cancer severity
-* Design objectives: Designed for few false positives or false negatives? Tuned to compensate for human error?
-* Other considerations: legal liability, impact on workflow, cost of use
-
-
-Further details: [Paper, Table 1](https://dl.acm.org/doi/pdf/10.1145/3359206)
-
-
-----
-## Insights
-
-AI literacy important for trust
-
-Be transparent about data used
-
-Describe training data and capabilities
-
-Give mental model, examples, human-relatable test cases
-
-Communicate the AI’s point-of-view and design goal
-
-
-
-
-Cai, Carrie J., Samantha Winter, David Steiner, Lauren Wilcox, and Michael Terry. ""Hello AI": Uncovering the Onboarding Needs of Medical Practitioners for Human-AI Collaborative Decision-Making." Proceedings of the ACM on Human-computer Interaction 3, no. CSCW (2019): 1-24.
-
-
-
----
-# The Dark Side of Explanations
-
-----
-## Many explanations are wrong
-
-Approximations of black-box models, often unstable
-
-Explanations necessarily partial, social
-
-Often multiple explanations possible (Rashomon effect)
-
-Possible to use inherently interpretable models instead?
-
-When explanation desired/required: What quality is needed/acceptable?
-
-----
-## Explanations foster Trust
-
-Users are less likely to question the model when explanations provided
-* Even if explanations are unreliable
-* Even if explanations are nonsensical/incomprehensible
-
-**Danger of overtrust and intentional manipulation**
-
-
-Stumpf, Simone, Adrian Bussone, and Dympna O’sullivan. "Explanations considered harmful? user interactions with machine learning systems." In Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems (CHI). 2016.
-
-----
-
-
-
-Springer, Aaron, Victoria Hollis, and Steve Whittaker. "Dice in the black box: User experiences with an inscrutable algorithm." In 2017 AAAI Spring Symposium Series. 2017.
-
-----
-
-
-(a) Rationale, (b) Stating the prediction, (c) Numerical internal values
-
-Observation: Both experts and non-experts overtrust numerical explanations, even when inscrutable.
-
-
-Ehsan, Upol, Samir Passi, Q. Vera Liao, Larry Chan, I. Lee, Michael Muller, and Mark O. Riedl. "The who in explainable AI: how AI background shapes perceptions of AI explanations." arXiv preprint arXiv:2107.13509 (2021).
-
-
-
----
-# "Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead."
-
-
-----
-## Accuracy vs Explainability Conflict?
-
-
-
-
-
-Graphic from the DARPA XAI BAA (Explainable Artificial Intelligence)
-
-----
-## Faithfulness of Ex-Post Explanations
-
-
-
-----
-## CORELS’ model for recidivism risk prediction
-
-```fortran
-IF age between 18–20 and sex is male THEN predict arrest
-ELSE IF age between 21–23 and 2–3 prior offenses THEN predict arrest
-ELSE IF more than three priors THEN predict arrest
-ELSE predict no arrest
-```
-
-Simple, interpretable model with comparable accuracy to proprietary COMPAS model
-
-
-
-Rudin, Cynthia. "Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead." Nature Machine Intelligence 1.5 (2019): 206-215. ([Preprint](https://arxiv.org/abs/1811.10154))
-
-
-
-----
-## "Stop explaining ..."
-
-
-
-Hypotheses:
-* It is a myth that there is necessarily a trade-off between accuracy and interpretability (when having meaningful features)
-* Explainable ML methods provide explanations that are not faithful to what the original model computes
-* Explanations often do not make sense, or do not provide enough detail to understand what the black box is doing
-* Black box models are often not compatible with situations where information outside the database needs to be combined with a risk assessment
-* Black box models with explanations can lead to an overly complicated decision pathway that is ripe for human error
-
-
-
-
-
-Rudin, Cynthia. "Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead." Nature Machine Intelligence 1.5 (2019): 206-215. ([Preprint](https://arxiv.org/abs/1811.10154))
-
-----
-## Prefer Interpretable Models over Post-Hoc Explanations
-
-
-* Interpretable models provide faithful explanations
- * post-hoc explanations may provide limited insights or illusion of understanding
- * interpretable models can be audited
-* Inherently interpretable models in many cases have similar accuracy
-* Larger focus on feature engineering, more effort, but insights into when and *why* the model works
-* Less research on interpretable models and some methods computationally expensive
-
-----
-## ProPublica Controversy
-
-
-
-
-Notes: "ProPublica’s linear model was not truly an
-“explanation” for COMPAS, and they should not have concluded that their explanation model uses the same
-important features as the black box it was approximating."
-----
-## ProPublica Controversy
-
-
-```fortran
-IF age between 18–20 and sex is male THEN
- predict arrest
-ELSE IF age between 21–23 and 2–3 prior offenses THEN
- predict arrest
-ELSE IF more than three priors THEN
- predict arrest
-ELSE
- predict no arrest
-```
-
-
-
-Rudin, Cynthia. "[Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead](https://arxiv.org/abs/1811.10154)." Nature Machine Intelligence 1, no. 5 (2019): 206-215.
-
-
-----
-## Drawbacks of Interpretable Models
-
-Intellectual property protection harder
- - may need to sell model, not license as service
- - who owns the models and who is responsible for their mistakes?
-
-Gaming possible; "security by obscurity" not a defense
-
-Expensive to build (feature engineering effort, debugging, computational costs)
-
-Limited to fewer factors, may discover fewer patterns, lower accuracy
-
-
-
-
----
-# Summary
-
-
-
-* Interpretability useful for many scenarios: user feedback, debugging, fairness audits, science, ...
-* Defining and measuring interpretability
- * Explaining the model
- * Explaining predictions
- * Understanding the data
-* Inherently interpretable models: sparse regressions, shallow decision trees
-* Providing ex-post explanations of opaque models: global and local surrogates, dependence plots and feature importance, anchors, counterfactual explanations, criticisms, and influential instances
-* Consider implications on user interface design
-* Gaming and manipulation with explanations
-
-
-
-----
-## Further Readings
-
-
-
-
-* Christoph Molnar. “[Interpretable Machine Learning: A Guide for Making Black Box Models Explainable](https://christophm.github.io/interpretable-ml-book/).” 2019
-* Google PAIR. [People + AI Guidebook](https://pair.withgoogle.com/guidebook/). 2019.
-* Cai, Carrie J., Samantha Winter, David Steiner, Lauren Wilcox, and Michael Terry. “[”Hello AI”: Uncovering the Onboarding Needs of Medical Practitioners for Human-AI Collaborative Decision-Making](https://dl.acm.org/doi/abs/10.1145/3359206).” Proceedings of the ACM on Human-computer Interaction 3, no. CSCW (2019): 1–24.
-* Kulesza, Todd, Margaret Burnett, Weng-Keen Wong, and Simone Stumpf. “[Principles of explanatory debugging to personalize interactive machine learning](https://core.ac.uk/download/pdf/190821828.pdf).” In Proceedings of the 20th International Conference on Intelligent User Interfaces, pp. 126–137. 2015.
-* Amershi, Saleema, Max Chickering, Steven M. Drucker, Bongshin Lee, Patrice Simard, and Jina Suh. “[Modeltracker: Redesigning performance analysis tools for machine learning](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.697.1689&rep=rep1&type=pdf).” In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, pp. 337–346. 2015.
-
-
\ No newline at end of file
diff --git a/lectures/19_explainability/explanationexperimentgame.png b/lectures/19_explainability/explanationexperimentgame.png
deleted file mode 100644
index 83cf10c8..00000000
Binary files a/lectures/19_explainability/explanationexperimentgame.png and /dev/null differ
diff --git a/lectures/19_explainability/expldebugging.png b/lectures/19_explainability/expldebugging.png
deleted file mode 100644
index 99492e84..00000000
Binary files a/lectures/19_explainability/expldebugging.png and /dev/null differ
diff --git a/lectures/19_explainability/featureimportance.png b/lectures/19_explainability/featureimportance.png
deleted file mode 100644
index cf9c0620..00000000
Binary files a/lectures/19_explainability/featureimportance.png and /dev/null differ
diff --git a/lectures/19_explainability/gun.png b/lectures/19_explainability/gun.png
deleted file mode 100644
index d14bdf4c..00000000
Binary files a/lectures/19_explainability/gun.png and /dev/null differ
diff --git a/lectures/19_explainability/influentialinstance.png b/lectures/19_explainability/influentialinstance.png
deleted file mode 100644
index 9da24ed7..00000000
Binary files a/lectures/19_explainability/influentialinstance.png and /dev/null differ
diff --git a/lectures/19_explainability/lime1.png b/lectures/19_explainability/lime1.png
deleted file mode 100644
index ee185d18..00000000
Binary files a/lectures/19_explainability/lime1.png and /dev/null differ
diff --git a/lectures/19_explainability/lime2.png b/lectures/19_explainability/lime2.png
deleted file mode 100644
index 63bc05a5..00000000
Binary files a/lectures/19_explainability/lime2.png and /dev/null differ
diff --git a/lectures/19_explainability/lime_cat.png b/lectures/19_explainability/lime_cat.png
deleted file mode 100644
index 17a7391b..00000000
Binary files a/lectures/19_explainability/lime_cat.png and /dev/null differ
diff --git a/lectures/19_explainability/lime_wolf.png b/lectures/19_explainability/lime_wolf.png
deleted file mode 100644
index fe2426fe..00000000
Binary files a/lectures/19_explainability/lime_wolf.png and /dev/null differ
diff --git a/lectures/19_explainability/mlperceptron.svg b/lectures/19_explainability/mlperceptron.svg
deleted file mode 100644
index 69feea0c..00000000
--- a/lectures/19_explainability/mlperceptron.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/19_explainability/nodejs-unusual-commit.png b/lectures/19_explainability/nodejs-unusual-commit.png
deleted file mode 100644
index af195477..00000000
Binary files a/lectures/19_explainability/nodejs-unusual-commit.png and /dev/null differ
diff --git a/lectures/19_explainability/pdp.png b/lectures/19_explainability/pdp.png
deleted file mode 100644
index 67ba194c..00000000
Binary files a/lectures/19_explainability/pdp.png and /dev/null differ
diff --git a/lectures/19_explainability/pdp2.png b/lectures/19_explainability/pdp2.png
deleted file mode 100644
index 716e9d52..00000000
Binary files a/lectures/19_explainability/pdp2.png and /dev/null differ
diff --git a/lectures/19_explainability/prototype-digits.png b/lectures/19_explainability/prototype-digits.png
deleted file mode 100644
index 0dce4668..00000000
Binary files a/lectures/19_explainability/prototype-digits.png and /dev/null differ
diff --git a/lectures/19_explainability/prototype-dogs.png b/lectures/19_explainability/prototype-dogs.png
deleted file mode 100644
index a8fdb02c..00000000
Binary files a/lectures/19_explainability/prototype-dogs.png and /dev/null differ
diff --git a/lectures/19_explainability/prototypes.png b/lectures/19_explainability/prototypes.png
deleted file mode 100644
index 492dbcdf..00000000
Binary files a/lectures/19_explainability/prototypes.png and /dev/null differ
diff --git a/lectures/19_explainability/prototypes_without.png b/lectures/19_explainability/prototypes_without.png
deleted file mode 100644
index e14fbf8f..00000000
Binary files a/lectures/19_explainability/prototypes_without.png and /dev/null differ
diff --git a/lectures/19_explainability/rashomon.jpg b/lectures/19_explainability/rashomon.jpg
deleted file mode 100644
index b8494521..00000000
Binary files a/lectures/19_explainability/rashomon.jpg and /dev/null differ
diff --git a/lectures/19_explainability/recidivism-propublica.png b/lectures/19_explainability/recidivism-propublica.png
deleted file mode 100644
index 5e871c64..00000000
Binary files a/lectures/19_explainability/recidivism-propublica.png and /dev/null differ
diff --git a/lectures/19_explainability/recidivism_scoring.png b/lectures/19_explainability/recidivism_scoring.png
deleted file mode 100644
index 82d5d818..00000000
Binary files a/lectures/19_explainability/recidivism_scoring.png and /dev/null differ
diff --git a/lectures/19_explainability/robotnose.png b/lectures/19_explainability/robotnose.png
deleted file mode 100644
index 55d025fd..00000000
Binary files a/lectures/19_explainability/robotnose.png and /dev/null differ
diff --git a/lectures/19_explainability/scoring.png b/lectures/19_explainability/scoring.png
deleted file mode 100644
index 37528717..00000000
Binary files a/lectures/19_explainability/scoring.png and /dev/null differ
diff --git a/lectures/19_explainability/slacknotifications.jpg b/lectures/19_explainability/slacknotifications.jpg
deleted file mode 100644
index 93543229..00000000
Binary files a/lectures/19_explainability/slacknotifications.jpg and /dev/null differ
diff --git a/lectures/19_explainability/stanford.png b/lectures/19_explainability/stanford.png
deleted file mode 100644
index 549cd647..00000000
Binary files a/lectures/19_explainability/stanford.png and /dev/null differ
diff --git a/lectures/19_explainability/stanfordalgorithm.png b/lectures/19_explainability/stanfordalgorithm.png
deleted file mode 100644
index a7b13bc1..00000000
Binary files a/lectures/19_explainability/stanfordalgorithm.png and /dev/null differ
diff --git a/lectures/19_explainability/stopsign.jpg b/lectures/19_explainability/stopsign.jpg
deleted file mode 100644
index cb76fe96..00000000
Binary files a/lectures/19_explainability/stopsign.jpg and /dev/null differ
diff --git a/lectures/19_explainability/thislookslikethat.png b/lectures/19_explainability/thislookslikethat.png
deleted file mode 100644
index b8455993..00000000
Binary files a/lectures/19_explainability/thislookslikethat.png and /dev/null differ
diff --git a/lectures/19_explainability/trust.png b/lectures/19_explainability/trust.png
deleted file mode 100644
index 3b4da1e0..00000000
Binary files a/lectures/19_explainability/trust.png and /dev/null differ
diff --git a/lectures/19_explainability/wizardofoz.jpg b/lectures/19_explainability/wizardofoz.jpg
deleted file mode 100644
index d3c3aa21..00000000
Binary files a/lectures/19_explainability/wizardofoz.jpg and /dev/null differ
diff --git a/lectures/20_transparency/airegulation.png b/lectures/20_transparency/airegulation.png
deleted file mode 100644
index 4bde739b..00000000
Binary files a/lectures/20_transparency/airegulation.png and /dev/null differ
diff --git a/lectures/20_transparency/bigdog.png b/lectures/20_transparency/bigdog.png
deleted file mode 100644
index 35653be8..00000000
Binary files a/lectures/20_transparency/bigdog.png and /dev/null differ
diff --git a/lectures/20_transparency/course-aligned.jpg b/lectures/20_transparency/course-aligned.jpg
deleted file mode 100644
index 0054a2f6..00000000
Binary files a/lectures/20_transparency/course-aligned.jpg and /dev/null differ
diff --git a/lectures/20_transparency/course-unaligned.jpg b/lectures/20_transparency/course-unaligned.jpg
deleted file mode 100644
index ed0c840b..00000000
Binary files a/lectures/20_transparency/course-unaligned.jpg and /dev/null differ
diff --git a/lectures/20_transparency/facebook.png b/lectures/20_transparency/facebook.png
deleted file mode 100644
index fd9bd21c..00000000
Binary files a/lectures/20_transparency/facebook.png and /dev/null differ
diff --git a/lectures/20_transparency/faceswap.png b/lectures/20_transparency/faceswap.png
deleted file mode 100644
index 8fc09c0b..00000000
Binary files a/lectures/20_transparency/faceswap.png and /dev/null differ
diff --git a/lectures/20_transparency/illusionofcontrol.png b/lectures/20_transparency/illusionofcontrol.png
deleted file mode 100644
index c22159f1..00000000
Binary files a/lectures/20_transparency/illusionofcontrol.png and /dev/null differ
diff --git a/lectures/20_transparency/npr_facialrecognition.png b/lectures/20_transparency/npr_facialrecognition.png
deleted file mode 100644
index eb31a7f0..00000000
Binary files a/lectures/20_transparency/npr_facialrecognition.png and /dev/null differ
diff --git a/lectures/20_transparency/responsibleai.png b/lectures/20_transparency/responsibleai.png
deleted file mode 100644
index 1b3ec1f5..00000000
Binary files a/lectures/20_transparency/responsibleai.png and /dev/null differ
diff --git a/lectures/20_transparency/stackoverflow.png b/lectures/20_transparency/stackoverflow.png
deleted file mode 100644
index 9db6ea59..00000000
Binary files a/lectures/20_transparency/stackoverflow.png and /dev/null differ
diff --git a/lectures/20_transparency/surveillance.png b/lectures/20_transparency/surveillance.png
deleted file mode 100644
index 6cbdceec..00000000
Binary files a/lectures/20_transparency/surveillance.png and /dev/null differ
diff --git a/lectures/20_transparency/teen-suicide-rate.png b/lectures/20_transparency/teen-suicide-rate.png
deleted file mode 100644
index 0e04315e..00000000
Binary files a/lectures/20_transparency/teen-suicide-rate.png and /dev/null differ
diff --git a/lectures/20_transparency/transparency.md b/lectures/20_transparency/transparency.md
deleted file mode 100644
index 650b8706..00000000
--- a/lectures/20_transparency/transparency.md
+++ /dev/null
@@ -1,462 +0,0 @@
----
-author: Christian Kaestner and Eunsuk Kang
-title: "MLiP: Transparency and Accountability"
-semester: Fall 2023
-footer: "Machine Learning in Production/AI Engineering • Christian Kaestner & Eunsuk Kang, Carnegie Mellon University • Spring 2023"
-license: Creative Commons Attribution 4.0 International (CC BY 4.0)
----
-
-
-
-## Machine Learning in Production
-
-
-# Transparency and Accountability
-
-
-
----
-## More Explainability, Policy, and Politics
-
-
-
-
-
-
-----
-## Readings
-
-Required reading:
-* Google PAIR. People + AI Guidebook. Chapter: [Explainability and Trust](https://pair.withgoogle.com/chapter/explainability-trust/). 2019.
-
-Recommendedr hoeading:
-* Metcalf, Jacob, and Emanuel Moss. "[Owning ethics: Corporate logics, silicon valley, and the institutionalization of ethics](https://datasociety.net/wp-content/uploads/2019/09/Owning-Ethics-PDF-version-2.pdf)." *Social Research: An International Quarterly* 86, no. 2 (2019): 449-476.
-
----
-# Learning Goals
-
-* Explain key concepts of transparency and trust
-* Discuss whether and when transparency can be abused to game the system
-* Design a system to include human oversight
-* Understand common concepts and discussions of accountability/culpability
-* Critique regulation and self-regulation approaches in ethical machine learning
-
-
-
----
-# Transparency
-
-Transparency: users know that algorithm exists / users know how the algorithm works
-
-----
-
-
-
-
-----
-## Case Study: Facebook's Feed Curation
-
-
-
-
-
-
-
-Eslami, Motahhare, et al. [I always assumed that I wasn't really that close to [her]: Reasoning about Invisible Algorithms in News Feeds](http://eslamim2.web.engr.illinois.edu/publications/Eslami_Algorithms_CHI15.pdf). In Proc. CHI, 2015.
-
-
-
-----
-## Case Study: Facebook's Feed Curation
-
-
-* 62% of interviewees were not aware of curation algorithm
-* Surprise and anger when learning about curation
-
-> "Participants were most upset when close friends and
-family were not shown in their feeds [...] participants often attributed missing stories to their friends’ decisions to exclude them rather than to Facebook News Feed algorithm."
-
-* Learning about algorithm did not change satisfaction level
-* More active engagement, more feeling of control
-
-
-
-
-Eslami, Motahhare, et al. [I always assumed that I wasn't really that close to [her]: Reasoning about Invisible Algorithms in News Feeds](http://eslamim2.web.engr.illinois.edu/publications/Eslami_Algorithms_CHI15.pdf). In Proc. CHI, 2015.
-
-----
-## The Dark Side of Transparency
-
-* Users may feel influence and control, even with placebo controls
-* Companies give vague generic explanations to appease regulators
-
-
-
-
-
-
-Vaccaro, Kristen, Dylan Huang, Motahhare Eslami, Christian Sandvig, Kevin Hamilton, and Karrie Karahalios. "The illusion of control: Placebo effects of control settings." In Proc CHI, 2018.
-
-
-
-----
-## Appropriate Level of Algorithmic Transparency
-
-IP/Trade Secrets/Fairness/Perceptions/Ethics?
-
-How to design? How much control to give?
-
-
-
-
-
-
-
-
-
-
----
-# Gaming/Attacking the Model with Explanations?
-
-*Does providing an explanation allow customers to 'hack' the system?*
-
-* Loan applications?
-* Apple FaceID?
-* Recidivism?
-* Auto grading?
-* Cancer diagnosis?
-* Spam detection?
-
-
-----
-## Gaming the Model with Explanations?
-
-
-
-
-
-----
-## Constructive Alignment in Teaching
-
-
-
-
-
-
-see also Claus Brabrand. [Teaching Teaching & Understanding Understanding](https://www.youtube.com/watch?v=w6rx-GBBwVg&t=148s). Youtube 2009
-
-
-
-----
-## Gaming the Model with Explanations?
-
-* A model prone to gaming uses weak proxy features
-* Protections requires to make the model hard to observe (e.g., expensive to query predictions)
-* Protecting models akin to "security by obscurity"
-* *Good models rely on hard facts that relate causally to the outcome <- hard to game*
-
-
-```haskell
-IF age between 18–20 and sex is male THEN predict arrest
-ELSE IF age between 21–23 and 2–3 prior offenses THEN predict arrest
-ELSE IF more than three priors THEN predict arrest
-ELSE predict no arrest
-```
-
-
-
----
-# Human Oversight and Appeals
-
-----
-## Human Oversight and Appeals
-
-* Unavoidable that ML models will make mistakes
-* Users knowing about the model may not be comforting
-* Inability to appeal a decision can be deeply frustrating
-
-
-
-----
-## Capacity to keep humans in the loop?
-
-ML used because human decisions as a bottleneck
-
-ML used because human decisions biased and inconsistent
-
-**Do we have the capacity to handle complaints/appeals?**
-
-**Wouldn't reintroducing humans bring back biases and inconsistencies?**
-
-----
-## Designing Human Oversight
-
-Consider the entire system and consequences of mistakes
-
-Deliberately design mitigation strategies for handling mistakes
-
-Consider keeping humans in the loop, balancing harms and costs
- * Provide pathways to appeal/complain? Respond to complains?
- * Review mechanisms? Can humans override tool decision?
- * Tracking telemetry, investigating common mistakes?
- * Audit model and decision process rather than appeal individual outcomes?
-
-
----
-# Accountability and Culpability
-
-*Who is held accountable if things go wrong?*
-
-----
-## On Terminology
-
-* accountability, responsibility, liability, and culpability all overlap in common use
-* often about assigning *blame* -- responsible for fixing or liable for paying for damages
-* liability, culpability have *legal* connotation
-* responsibility tends to describe *ethical* aspirations
-* accountability often defined as oversight relationship, where actor is accountable to some "forum" that can impose penalties
-* see also legal vs ethical earlier
-
-
-
-----
-## On Terminology
-
-Academic definition of accountability:
-
-> A relationship between an **actor** and a **forum**,
-in which the actor has an obligation to explain
-and to justify his or her conduct, the forum can
-pose questions and pass judgement, and the
-actor **may face consequences**.
-
-That is accountability implies some oversight with ability to penalize
-
-
-
-Wieringa, Maranke. "[What to account for when accounting for algorithms: a systematic literature review on algorithmic accountability](https://dl.acm.org/doi/abs/10.1145/3351095.3372833)." In *Proceedings of the Conference on Fairness, Accountability, and Transparency*, pp. 1-18. 2020.
-
-
-
-
-----
-## Who is responsible?
-
-
-
-
-----
-## Who is responsible?
-
-
-
-----
-## Who is responsible?
-
-
-
-----
-## Who is responsible?
-
-[](https://github.com/deepfakes/faceswap)
-
-----
-## Faceswap's README "FaceSwap has ethical uses"
-
-
-
-> [...] as is so often the way with new technology emerging on the internet, it was immediately used to create inappropriate content.
-
-> [...] it was the first AI code that anyone could download, run and learn by experimentation without having a Ph.D. in math, computer theory, psychology, and more. Before "deepfakes" these techniques were like black magic, only practiced by those who could understand all of the inner workings as described in esoteric and endlessly complicated books and papers.
-
-> [...] the release of this code opened up a fantastic learning opportunity.
-
-> Are there some out there doing horrible things with similar software? Yes. And because of this, the developers have been following strict ethical standards. Many of us don't even use it to create videos, we just tinker with the code to see what it does. [...]
-
-> FaceSwap is not for creating inappropriate content.
-> FaceSwap is not for changing faces without consent or with the intent of hiding its use.
-> FaceSwap is not for any illicit, unethical, or questionable purposes. [...]
-
-
-
-----
-
-> THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
-
-Note: Software engineers got (mostly) away with declaring not to be liable
-
-----
-## Easy to Blame "The Algorithm" / "The Data" / "Software"
-
-> "Just a bug, things happen, nothing we could have done"
-
-- But system was designed by humans
-- But humans did not anticipate possible mistakes, did not design to mitigate mistakes
-- But humans made decisions about what quality was good enough
-- But humans designed/ignored the development process
-- But humans gave/sold poor quality software to other humans
-- But humans used the software without understanding it
-- ...
-
-----
-
-
-
-Results from the [2018 StackOverflow Survey](https://insights.stackoverflow.com/survey/2018/#technology-and-society)
-
-----
-## What to do?
-
-* Responsible organizations embed risk analysis, quality control, and ethical considerations into their process
-* Establish and communicate policies defining responsibilities
-* Work from aspirations toward culture change: baseline awareness + experts
-* Document tradeoffs and decisions (e.g., datasheets, model cards)
-* Continuous learning
-* Consider controlling/restricting how software may be used, whether it should be built at all
-* And... follow the law
-* Get started with existing guidelines, e.g., in [AI Ethics Guidelines](https://algorithmwatch.org/en/ai-ethics-guidelines-global-inventory/)
-
-
-
----
-# (Self-)Regulation and Policy
-
-----
-
-
-
-----
-
-
-----
-## Policy Discussion and Frameing
-
-* Corporate pitch: "Responsible AI" ([Microsoft](https://www.microsoft.com/en-us/ai/responsible-ai), [Google](https://ai.google/responsibilities/responsible-ai-practices/), [Accenture](https://www.accenture.com/_acnmedia/pdf-92/accenture-afs-responsible-ai.pdf))
-* Counterpoint: Ochigame ["The Invention of 'Ethical AI': How Big Tech Manipulates Academia to Avoid Regulation"](https://theintercept.com/2019/12/20/mit-ethical-ai-artificial-intelligence/), The Intercept 2019
- - "*The discourse of “ethical AI” was aligned strategically with a Silicon Valley effort seeking to avoid legally enforceable restrictions of controversial technologies.*"
-
-**Self-regulation vs government regulation? Assuring safety vs fostering innovation?**
-
-----
-
-
-
-----
-
-
-
-
-----
-# "Wishful Worries"
-
-We are distracted with worries about fairness and safety of hypothetical systems
-
-Most systems fail because they didn't work in the first place; don't actually solve a problem or address impossible tasks
-
-Wouldn't help even if they solved the given problem (e.g., predictive policing?)
-
-
-
-
-Raji, Inioluwa Deborah, I. Elizabeth Kumar, Aaron Horowitz, and Andrew Selbst. "The fallacy of AI functionality." In 2022 ACM Conference on Fairness, Accountability, and Transparency, pp. 959-972. 2022.
-
-
-----
-[](https://www.forbes.com/sites/cognitiveworld/2020/03/01/this-is-the-year-of-ai-regulations/#1ea2a84d7a81)
-
-
-----
-## “Accelerating America’s Leadership in Artificial Intelligence”
-
-> “the policy of the United States Government [is] to sustain and enhance the scientific, technological, and economic leadership position of the United States in AI.” -- [White House Executive Order Feb. 2019](https://www.whitehouse.gov/articles/accelerating-americas-leadership-in-artificial-intelligence/)
-
-Tone: "When in doubt, the government should not regulate AI."
-
-Note:
-* 3. Setting AI Governance Standards: "*foster public trust in AI systems by establishing guidance for AI development. [...] help Federal regulatory agencies develop and maintain approaches for the safe and trustworthy creation and adoption of new AI technologies. [...] NIST to lead the development of appropriate technical standards for reliable, robust, trustworthy, secure, portable, and interoperable AI systems.*"
-
-----
-## Jan 13 2020 Draft Rules for Private Sector AI
-
-
-
-* *Public Trust in AI*: Overarching theme: reliable, robust, trustworthy AI
-* *Public participation:* public oversight in AI regulation
-* *Scientific Integrity and Information Quality:* science-backed regulation
-* *Risk Assessment and Management:* risk-based regulation
-* *Benefits and Costs:* regulation costs may not outweigh benefits
-* *Flexibility:* accommodate rapid growth and change
-* *Disclosure and Transparency:* context-based transparency regulation
-* *Safety and Security:* private sector resilience
-
-
-[Draft: Guidance for Regulation of Artificial Intelligence Applications](https://www.whitehouse.gov/wp-content/uploads/2020/01/Draft-OMB-Memo-on-Regulation-of-AI-1-7-19.pdf)
-
-
-----
-## Other Regulations
-
-* *China:* policy ensures state control of Chinese companies and over valuable data, including storage of data on Chinese users within the country and mandatory national standards for AI
-* *EU:* Ethics Guidelines for Trustworthy Artificial Intelligence; Policy and investment recommendations for trustworthy Artificial Intelligence; draft regulatory framework for high-risk AI applications, including procedures for testing, record-keeping, certification, ...
-* *UK:* Guidance on responsible design and implementation of AI systems and data ethics
-
-
-
-Source: https://en.wikipedia.org/wiki/Regulation_of_artificial_intelligence
-
-
-----
-## Call for Transparent and Audited Models
-
-
-
-> "no black box should be deployed
-when there exists an interpretable model with the same level of performance"
-
-For high-stakes decisions
-* ... with government involvement (recidivism, policing, city planning, ...)
-* ... in medicine
-* ... with discrimination concerns (hiring, loans, housing, ...)
-* ... that influence society and discourse? (algorithmic content amplifications, targeted advertisement, ...)
-
-*Regulate possible conflict: Intellectual property vs public welfare*
-
-
-
-
-
-Rudin, Cynthia. "Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead." Nature Machine Intelligence 1.5 (2019): 206-215. ([Preprint](https://arxiv.org/abs/1811.10154))
-
-
-
-
-----
-## Criticism: Ethics Washing, Ethics Bashing, Regulatory Capture
-
-
-
-
-
----
-# Summary
-
-* Transparency goes beyond explaining predictions
-* Plan for mistakes and human oversight
-* Accountability and culpability are hard to capture, little regulation
-* Be a responsible engineer, adopt a culture of responsibility
-* Regulations may be coming
-
-----
-## Further Readings
-
-
-
-* Jacovi, Alon, Ana Marasović, Tim Miller, and Yoav Goldberg. [Formalizing trust in artificial intelligence: Prerequisites, causes and goals of human trust in AI](https://arxiv.org/abs/2010.07487). In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, pp. 624–635. 2021.
-* Eslami, Motahhare, Aimee Rickman, Kristen Vaccaro, Amirhossein Aleyasen, Andy Vuong, Karrie Karahalios, Kevin Hamilton, and Christian Sandvig. [I always assumed that I wasn’t really that close to her: Reasoning about Invisible Algorithms in News Feeds](http://social.cs.uiuc.edu/papers/pdfs/Eslami_Algorithms_CHI15.pdf). In Proceedings of the 33rd annual ACM conference on human factors in computing systems, pp. 153–162. ACM, 2015.
-* Rakova, Bogdana, Jingying Yang, Henriette Cramer, and Rumman Chowdhury. “[Where responsible AI meets reality: Practitioner perspectives on enablers for shifting organizational practices](https://arxiv.org/abs/2006.12358).” Proceedings of the ACM on Human-Computer Interaction 5, no. CSCW1 (2021): 1–23.
-* Greene, Daniel, Anna Lauren Hoffmann, and Luke Stark. "[Better, nicer, clearer, fairer: A critical assessment of the movement for ethical artificial intelligence and machine learning](https://core.ac.uk/download/pdf/211327327.pdf)." In *Proceedings of the 52nd Hawaii International Conference on System Sciences* (2019).
-* Metcalf, Jacob, and Emanuel Moss. "[Owning ethics: Corporate logics, silicon valley, and the institutionalization of ethics](https://datasociety.net/wp-content/uploads/2019/09/Owning-Ethics-PDF-version-2.pdf)." *Social Research: An International Quarterly* 86, no. 2 (2019): 449-476.
-* Raji, Inioluwa Deborah, I. Elizabeth Kumar, Aaron Horowitz, and Andrew Selbst. "[The fallacy of AI functionality](https://dl.acm.org/doi/abs/10.1145/3531146.3533158)." In 2022 ACM Conference on Fairness, Accountability, and Transparency, pp. 959-972. 2022.
-
-
-
\ No newline at end of file
diff --git a/lectures/21_provenance/2phase-prediction.svg b/lectures/21_provenance/2phase-prediction.svg
deleted file mode 100644
index f9b92a94..00000000
--- a/lectures/21_provenance/2phase-prediction.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/21_provenance/apollo.png b/lectures/21_provenance/apollo.png
deleted file mode 100644
index 03609231..00000000
Binary files a/lectures/21_provenance/apollo.png and /dev/null differ
diff --git a/lectures/21_provenance/creditcard-provenance.svg b/lectures/21_provenance/creditcard-provenance.svg
deleted file mode 100644
index f7ee80d3..00000000
--- a/lectures/21_provenance/creditcard-provenance.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/21_provenance/ensemble.svg b/lectures/21_provenance/ensemble.svg
deleted file mode 100644
index 7be898f2..00000000
--- a/lectures/21_provenance/ensemble.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/21_provenance/imgcaptioningml-blame.png b/lectures/21_provenance/imgcaptioningml-blame.png
deleted file mode 100644
index cab2ea9c..00000000
Binary files a/lectures/21_provenance/imgcaptioningml-blame.png and /dev/null differ
diff --git a/lectures/21_provenance/imgcaptioningml-decomposed.png b/lectures/21_provenance/imgcaptioningml-decomposed.png
deleted file mode 100644
index 08ad0a58..00000000
Binary files a/lectures/21_provenance/imgcaptioningml-decomposed.png and /dev/null differ
diff --git a/lectures/21_provenance/imgcaptioningml-nonmonotonic.png b/lectures/21_provenance/imgcaptioningml-nonmonotonic.png
deleted file mode 100644
index 73e32cee..00000000
Binary files a/lectures/21_provenance/imgcaptioningml-nonmonotonic.png and /dev/null differ
diff --git a/lectures/21_provenance/memgen-provenance.svg b/lectures/21_provenance/memgen-provenance.svg
deleted file mode 100644
index e16cbc9d..00000000
--- a/lectures/21_provenance/memgen-provenance.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/21_provenance/mlflow-web-ui.png b/lectures/21_provenance/mlflow-web-ui.png
deleted file mode 100644
index 82e3e39a..00000000
Binary files a/lectures/21_provenance/mlflow-web-ui.png and /dev/null differ
diff --git a/lectures/21_provenance/overrides.svg b/lectures/21_provenance/overrides.svg
deleted file mode 100644
index 04c7c08e..00000000
--- a/lectures/21_provenance/overrides.svg
+++ /dev/null
@@ -1 +0,0 @@
-
diff --git a/lectures/21_provenance/partitioncontext.svg b/lectures/21_provenance/partitioncontext.svg
deleted file mode 100644
index 34c8a3c2..00000000
--- a/lectures/21_provenance/partitioncontext.svg
+++ /dev/null
@@ -1 +0,0 @@
-
diff --git a/lectures/21_provenance/pipeline-versioning.svg b/lectures/21_provenance/pipeline-versioning.svg
deleted file mode 100644
index b5c09b30..00000000
--- a/lectures/21_provenance/pipeline-versioning.svg
+++ /dev/null
@@ -1 +0,0 @@
-
\ No newline at end of file
diff --git a/lectures/21_provenance/provenance.md b/lectures/21_provenance/provenance.md
deleted file mode 100644
index 2b3da0c3..00000000
--- a/lectures/21_provenance/provenance.md
+++ /dev/null
@@ -1,765 +0,0 @@
----
-author: Christian Kaestner & Eunsuk Kang
-title: "MLiP: Versioning, Provenance, and Reproducability"
-semester: Fall 2023
-footer: "Machine Learning in Production/AI Engineering • Christian Kaestner & Eunsuk Kang, Carnegie Mellon University • Spring 2023"
-license: Creative Commons Attribution 4.0 International (CC BY 4.0)
----
-
-
-
-## Machine Learning in Production
-
-
-# Versioning, Provenance, and Reproducability
-
-
-
----
-## More Foundational Technology for Responsible Engineering
-
-
-
-
-
-
-----
-## Readings
-
-
-Required readings
-
-* 🕮 Hulten, Geoff. "[Building Intelligent Systems: A Guide to Machine Learning Engineering.](https://www.buildingintelligentsystems.com/)" Apress, 2018, Chapter 21 (Organizing Intelligence).
-* 🗎 Halevy, Alon, Flip Korn, Natalya F. Noy, Christopher Olston, Neoklis Polyzotis, Sudip Roy, and Steven Euijong Whang. [Goods: Organizing google's datasets](http://research.google.com/pubs/archive/45390.pdf). In Proceedings of the 2016 International Conference on Management of Data, pp. 795-806. ACM, 2016.
-
----
-
-# Learning Goals
-
-* Judge the importance of data provenance, reproducibility and explainability for a given system
-* Create documentation for data dependencies and provenance in a given system
-* Propose versioning strategies for data and models
-* Design and test systems for reproducibility
-
----
-
-# Case Study: Credit Scoring
-
-----
-
-
-----
-
-
-
-----
-
-
-
-
-----
-
-## Debugging?
-
-What went wrong? Where? How to fix?
-
-
-
-----
-
-## Debugging Questions beyond Interpretability
-
-* Can we reproduce the problem?
-* What were the inputs to the model?
-* Which exact model version was used?
-* What data was the model trained with?
-* What pipeline code was the model trained with?
-* Where does the data come from? How was it processed/extracted?
-* Were other models involved? Which version? Based on which data?
-* What parts of the input are responsible for the (wrong) answer? How can we fix the model?
-
-
-
-----
-## Model Chaining: Automatic meme generator
-
-
-
-
-*Version all models involved!*
-
-
-Example adapted from Jon Peck. [Chaining machine learning models in production with Algorithmia](https://algorithmia.com/blog/chaining-machine-learning-models-in-production-with-algorithmia). Algorithmia blog, 2019
-
-----
-## Complex Model Composition: ML Models for Feature Extraction
-
-
-
-
-
-
-Image: Peng, Zi, Jinqiu Yang, Tse-Hsun Chen, and Lei Ma. "A first look at the integration of machine learning models in complex autonomous driving systems: a case study on Apollo." In Proc. FSE. 2020.
-
-
-Note: see also Zong, W., Zhang, C., Wang, Z., Zhu, J., & Chen, Q. (2018). [Architecture design and implementation of an autonomous vehicle](https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8340798). IEEE access, 6, 21956-21970.
-
-
-----
-
-## Breakout Discussion: Movie Predictions
-
-
-
-> Assume you are receiving complains that a child gets many recommendations about R-rated movies
-
-In a group, discuss how you could address this in your own system and post to `#lecture`, tagging team members:
-
-* How could you identify the problematic recommendation(s)?
-* How could you identify the model that caused the prediction?
-* How could you identify the training code and data that learned the model?
-* How could you identify what training data or infrastructure code "caused" the recommendations?
-
-
-
-
-
-K.G Orphanides. [Children's YouTube is still churning out blood, suicide and cannibalism](https://www.wired.co.uk/article/youtube-for-kids-videos-problems-algorithm-recommend). Wired UK, 2018;
-Kristie Bertucci. [16 NSFW Movies Streaming on Netflix](https://www.gadgetreview.com/16-nsfw-movies-streaming-on-netflix). Gadget Reviews, 2020
-
-
-
----
-
-# Provenance Tracking
-
-*Historical record of data and its origin*
-
-----
-
-## Data Provenance
-
-
-* Track origin of all data
- - Collected where?
- - Modified by whom, when, why?
- - Extracted from what other data or model or algorithm?
-* ML models often based on data drived from many sources through many steps, including other models
-
-
-
-
-
-
-----
-## Excursion: Provenance Tracking in Databases
-
-Whenever value is changed, record:
- - who changed it
- - time of change
- - history of previous values
- - possibly also justifcation of why
-
-Embedded as feature in some databases or implemented in business logic
-
-Possibly signing with cryptographic methods
-
-
-----
-
-## Tracking Data Lineage
-
-Document all data sources
-
-Identify all model dependencies and flows
-
-Ideally model all data and processing code
-
-Avoid "visibility debt"
-
-(Advanced: Use infrastructure to automatically capture/infer dependencies and flows as in [Goods](http://research.google.com/pubs/archive/45390.pdf))
-
-
-
-----
-## Feature Provenance
-
-How are features extracted from raw data?
- - during training
- - during inference
-
-Has feature extraction changed since the model was trained?
-
-Recommendation: Modularize and version feature extraction code
-
-**Example?**
-
-----
-## Advanced Practice: Feature Store
-
-Stores feature extraction code as functions, versioned
-
-Catalog features to encourage reuse
-
-Compute and cache features centrally
-
-Use same feature used in training and inference code
-
-Advanced: Immutable features -- never change existing features, just add new ones (e.g., creditscore, creditscore2, creditscore3)
-
-
-----
-## Model Provenance
-
-How was the model trained?
-
-What data? What library? What hyperparameter? What code?
-
-Ensemble of multiple models?
-
-----
-
-
-
-----
-## In Real Systems: Tracking Provenance Across Multiple Models
-
-
-
-
-
-
-
-Example adapted from Jon Peck. [Chaining machine learning models in production with Algorithmia](https://algorithmia.com/blog/chaining-machine-learning-models-in-production-with-algorithmia). Algorithmia blog, 2019
-----
-## Complex Model Composition: ML Models for Feature Extraction
-
-
-
-
-
-Image: Peng, Zi, Jinqiu Yang, Tse-Hsun Chen, and Lei Ma. "A first look at the integration of machine learning models in complex autonomous driving systems: a case study on Apollo." In Proc. FSE. 2020.
-
-----
-## Summary: Provenance
-
-Data provenance
-
-Feature provenance
-
-Model provenance
-
-
-
-
-
-
----
-# Practical Data and Model Versioning
-
-----
-## How to Version Large Datasets?
-
-
-
-(movie ratings, movie metadata, user data?)
-
-----
-## Recall: Event Sourcing
-
-* Append only databases
-* Record edit events, never mutate data
-* Compute current state from all past events, can reconstruct old state
-* For efficiency, take state snapshots
-* Similar to traditional database logs
-
-```text
-createUser(id=5, name="Christian", dpt="SCS")
-updateUser(id=5, dpt="ISR")
-deleteUser(id=5)
-```
-
-----
-## Versioning Strategies for Datasets
-
-1. Store copies of entire datasets (like Git), identify by checksum
-2. Store deltas between datasets (like Mercurial)
-3. Offsets in append-only database (like Kafka), identify by offset
-4. History of individual database records (e.g. S3 bucket versions)
- - some databases specifically track provenance (who has changed what entry when and how)
- - specialized data science tools eg [Hangar](https://github.com/tensorwerk/hangar-py) for tensor data
-5. Version pipeline to recreate derived datasets ("views", different formats)
- - e.g. version data before or after cleaning?
-
-
-----
-## Aside: Git Internals
-
-
-
-
-
-Scott Chacon and Ben Straub. [Pro Git](https://git-scm.com/book/en/v2/Git-Internals-Git-References). 2014
-
-----
-## Versioning Models
-
-
-
-----
-## Versioning Models
-
-Usually no meaningful delta/compression, version as binary objects
-
-Any system to track versions of blobs
-
-----
-## Versioning Pipelines
-
-
-
-
-Associate model version with pipeline code version, data version, and hyperparameters!
-
-----
-## Versioning Dependencies
-
-Pipelines depend on many frameworks and libraries
-
-Ensure reproducible builds
- - Declare versioned dependencies from stable repository (e.g. requirements.txt + pip)
- - Avoid floating versions
- - Optionally: commit all dependencies to repository ("vendoring")
-
-Optionally: Version entire environment (e.g. Docker container)
-
-
-Test build/pipeline on independent machine (container, CI server, ...)
-
-
-
-----
-## ML Versioning Tools (MLOps)
-
-Tracking data, pipeline, and model versions
-
-Modeling pipelines: inputs and outputs and their versions
- - automatically tracks how data is used and transformed
-
-Often tracking also metadata about versions
- - Accuracy
- - Training time
- - ...
-
-
-----
-## Example: DVC
-
-```sh
-dvc add images
-dvc run -d images -o model.p cnn.py
-dvc remote add myrepo s3://mybucket
-dvc push
-```
-
-* Tracks models and datasets, built on Git
-* Splits learning into steps, incrementalization
-* Orchestrates learning in cloud resources
-
-
-https://dvc.org/
-
-----
-## DVC Example
-
-```yaml
-stages:
- features:
- cmd: jupyter nbconvert --execute featurize.ipynb
- deps:
- - data/clean
- params:
- - levels.no
- outs:
- - features
- metrics:
- - performance.json
- training:
- desc: Train model with Python
- cmd:
- - pip install -r requirements.txt
- - python train.py --out ${model_file}
- deps:
- - requirements.txt
- - train.py
- - features
- outs:
- - ${model_file}:
- desc: My model description
- plots:
- - logs.csv:
- x: epoch
- x_label: Epoch
- meta: 'For deployment'
- # User metadata and comments are supported
-```
-
-
-
-----
-## Experiment Tracking
-
-Log information within pipelines: hyperparameters used, evaluation results, and model files
-
-
-
-
-Many tools: MLflow, ModelDB, Neptune, TensorBoard, Weights & Biases, Comet.ml, ...
-
-Note: Image from
-Matei Zaharia. [Introducing MLflow: an Open Source Machine Learning Platform](https://databricks.com/blog/2018/06/05/introducing-mlflow-an-open-source-machine-learning-platform.html), 2018
-
-
-
-----
-## ModelDB Example
-
-```python
-from verta import Client
-client = Client("http://localhost:3000")
-
-proj = client.set_project("My first ModelDB project")
-expt = client.set_experiment("Default Experiment")
-
-# log the first run
-run = client.set_experiment_run("First Run")
-run.log_hyperparameters({"regularization" : 0.5})
-run.log_dataset_version("training_and_testing_data", dataset_version)
-model1 = # ... model training code goes here
-run.log_metric('accuracy', accuracy(model1, validationData))
-run.log_model(model1)
-
-# log the second run
-run = client.set_experiment_run("Second Run")
-run.log_hyperparameters({"regularization" : 0.8})
-run.log_dataset_version("training_and_testing_data", dataset_version)
-model2 = # ... model training code goes here
-run.log_metric('accuracy', accuracy(model2, validationData))
-run.log_model(model2)
-```
-
-----
-## Google's Goods
-
-Automatically derive data dependencies from system log files
-
-Track metadata for each table
-
-No manual tracking/dependency declarations needed
-
-Requires homogeneous infrastructure
-
-Similar systems for tracking inside databases, MapReduce, Sparks, etc.
-
-
-----
-## From Model Versioning to Deployment
-
-Decide which model version to run where
- - automated deployment and rollback (cf. canary releases)
- - Kubernetis, Cortex, BentoML, ...
-
-Track which prediction has been performed with which model version (logging)
-
-
-
-----
-
-## Logging and Audit Traces
-
-
-**Key goal:** If a customer complains about an interaction, can we reproduce the prediction with the right model? Can we debug the model's pipeline and data? Can we reproduce the model?
-
-* Version everything
-* Record every model evaluation with model version
-* Append only, backed up
-
-
-
-```
-