| title | date | tags | ||
|---|---|---|---|---|
day17-带你认识存储-数据库 |
2023-01-15 04:59:38 -0800 |
|

这是我参与「第三届青训营 - 后端场」笔记创作活动的的第17篇笔记。PC端阅读效果更佳,点击文末:阅读原文即可。

存储系统和数据库系统往往是后端服务的最后一环,提供数据存储、查询能力。本课程会先用模拟案例导入,介绍存储系统、数据库系统的特点,然后解析多个主流产品,最后分享存储和数据库结合新技术演进的方向。主要包含以下内容:
-
模拟案例
-
存储 & 数据库简介
-
主流产品剖析
-
新技术演进
01.经典案例
- 一条数据从产生, 到数据流动,最后持久化的全生命周期
02.存储&数据库简介
- 数据库和存储系统背景知识,它们是什么,有哪些特点?
03.主流产品剖析
- 主流的存储&数据库系统架构,经典产品剖析
04.新技术演进
- 老系统结合新技术,如何持续演进走向新生?
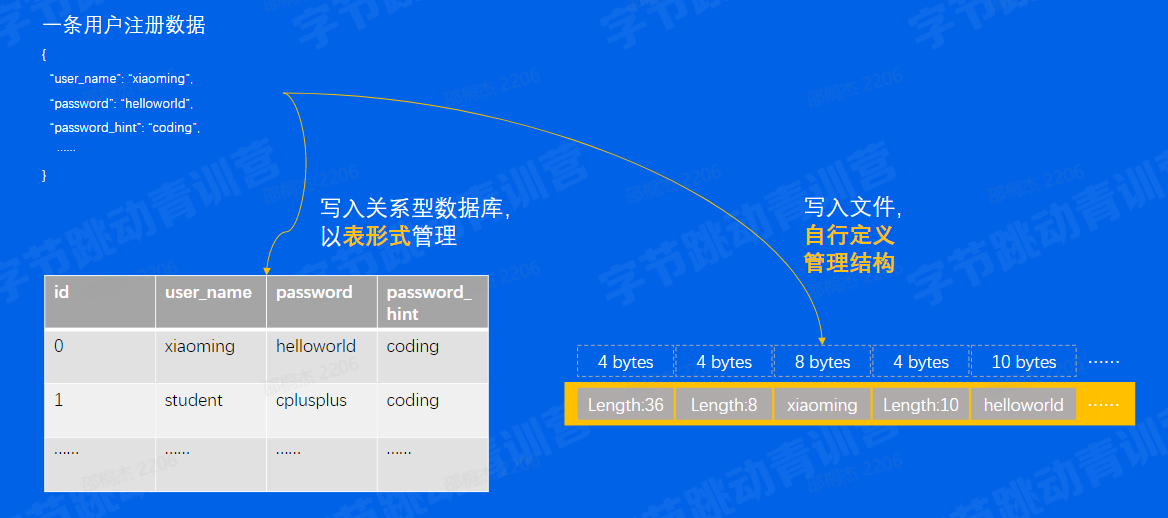
某天,小明同学下载了一个新的APP。因为第一次登陆,所以进入APP后需要注册一个新的账号

于是小明同学三下五除二地填好了资料,按下了「注册」按钮
就这样,数据就从无到有地产生了,并且在数十/数百毫秒内向APP的后端服务器飞奔而去.....
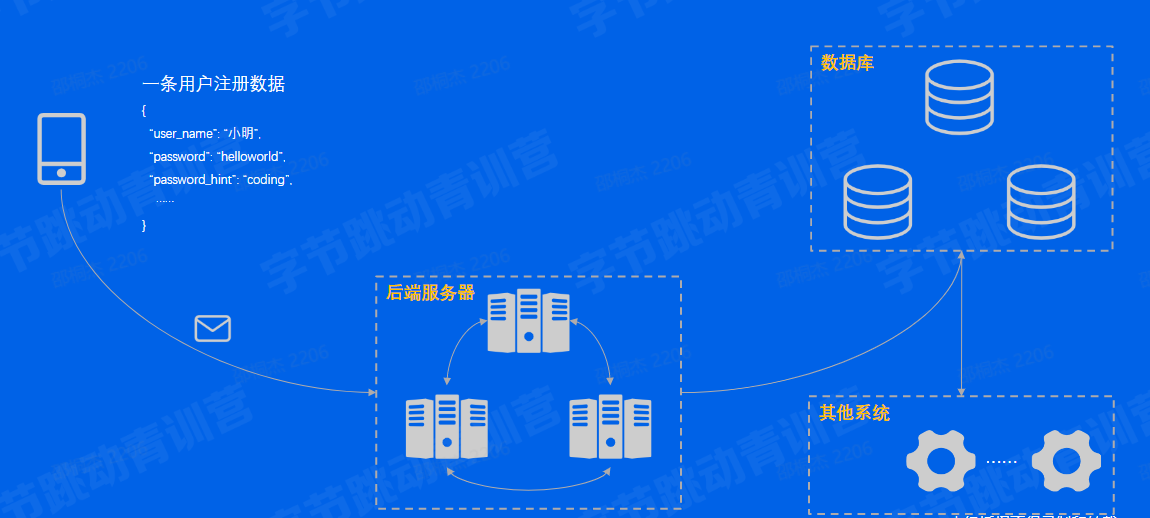

- 数据库怎么保证数据不丢?
- 数据库怎么处理多人同时修改的问题?
- 为什么用数据库,除了数据库还能存到别的存储系统吗?
- 数据库只能处理结构化数据吗?
- 有哪些操作数据库的方式,要用什么编程语言?
什么是存储系统,什么是数据库系统?
Q:什么是存储系统?
A:一个提供了读写、控制类接口,能够安全有效地把数据持久化的软件,就可以称为存储系统。
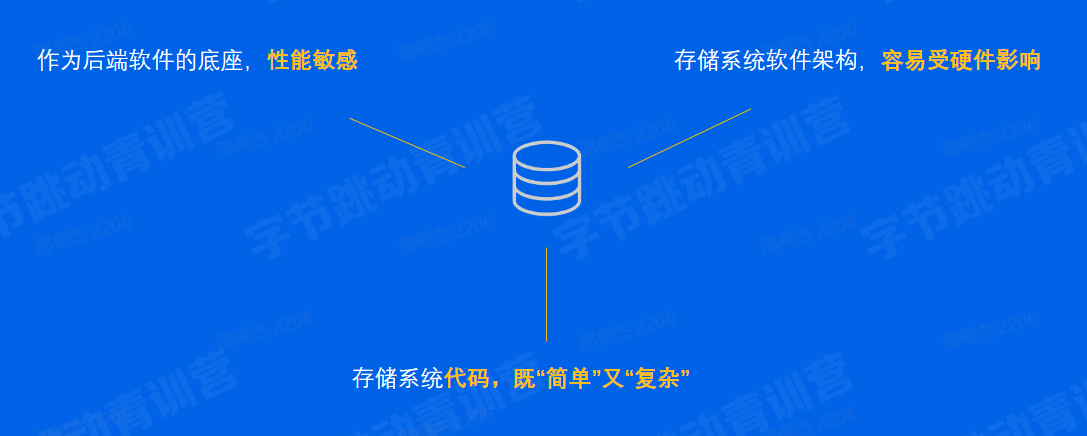
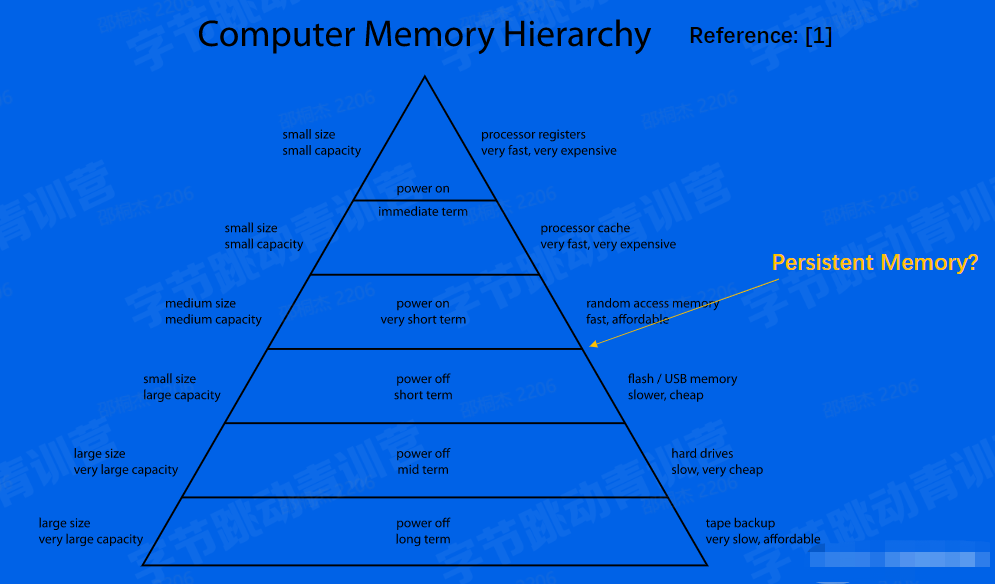
- 「缓存」很重要,贯穿整个存储体系
- 「拷贝」很昂贵,应该尽量减少
- 硬件设备五花八门,需要有抽象统一的接入层
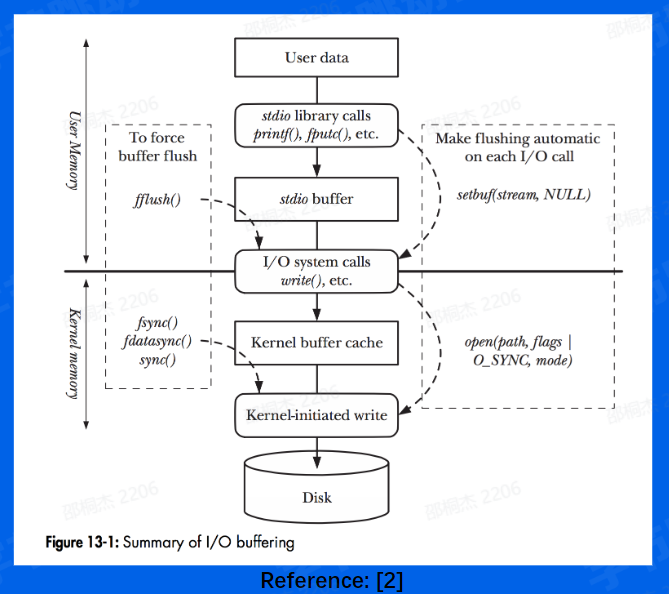

关系( Relation)又是什么?

关系型数据库是存储系统,但是在存储之外,又发展出其他能力
- 结构化数据友好
- 支持事务(ACID)
- 支持复杂查询语言
非关系型数据库也是存储系统,但是一 般不要求严格的结构化
- 半结构化数据友好
- 可能支持事务(ACID)
- 可能支持复杂查询语言
| 结构化数据管理 | 事务能力 | 复杂查询能力 |
|---|---|---|
 |
 |
 |

单机存储 = 单个计算机节点上的存储软件系统,一般不涉及网络交互。
Linux经典哲学:一切皆文件
-
文件系统的管理单元:文件
-
文件系统接口:文件系统繁多,如Ext2/3/4, sysfs, rootfs等 ,但都遵循VFS的统一抽象接口
-
Linux文件系统的两大数据结构:
Index Node&Directory Entry

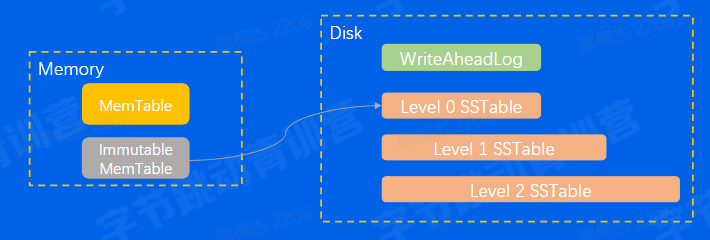
常见使用方式: put(k, v) & get(k)
常见数据结构: LSM-Tree, 某种程度上牺牲读性能,追求写入性能
拳头产品: RocksDB
分布式存储 = 在单机存储基础上实现了分布式协议,涉及大量网络交互
HDFS:堪称大数据时代的基石
时代背景:专用的高级硬件很贵,同时数据存量很大,要求超高吞吐
HDFS核心特点:
- 支持海量数据存储
- 高容错性
- 弱POSIX语义
- 使用普通x86服务器,性价比高

Ceph:开源分布式存储系统里的「万金油」
Ceph的核心特点:
- 一套系统支持对象接口、块接口、文件接口,但是一切皆对象
- 数据写入采用主备复制模型
- 数据分布模型采用
CRUSH(HASH +权重+随机抽签)算法

单机数据库 = 单个计算机节点上的数据库系统
事务在单机内执行,也可能通过网络交互实现分布式事务
商业产品Oracle称王,开源产品MySQL & PostgreSQL称霸
关系型数据库的通用组件:
- Query Engine--负责解析query,生成查询计划
- Txn Manager--负责事务并发管理
- Lock Manager --负 责锁相关的策略
- Storage Engine--负责组织内存/磁盘数据结构
- Replication--负责主备同步
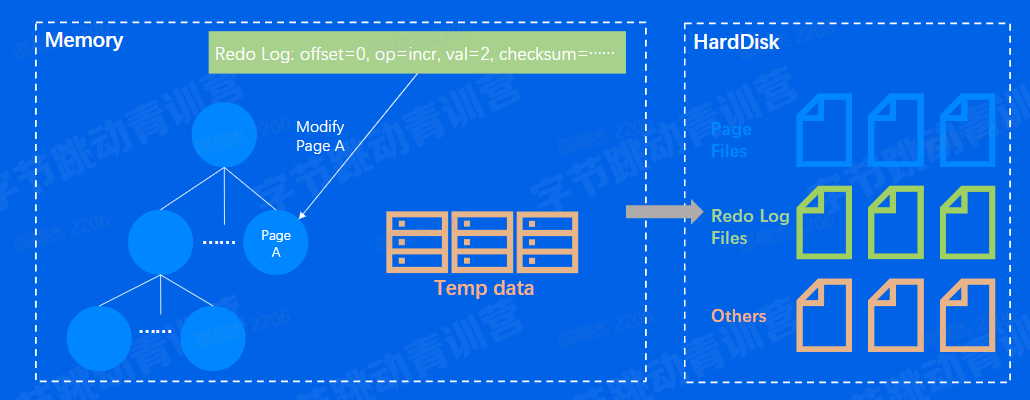
关键内存数据结构:B-Tree、 B+ -Tree、LRU List等
关键磁盘数据结构:WriteAheadLog(RedoLog)、Page
MongoDB、Redis、Elasticsearch三足鼎立
- 关系型数据库一般直接使用SQL交互,而非关系型数据库交互方式各不相同
- 非关系型数据库的数据结构千奇百怪,没有关系约束后,schema相对灵活
- 不管是否关系型数据库,大家都在尝试支持SQL(子集)和“事务”


痛点:单机数据库遇到了哪些问题&挑战,需要我们引入分布式架构来解决?容量,弹性,性价比
| 解决容量问题 | 解决弹性问题 | 解决性价比问题 |
|---|---|---|
 |
 |
 |


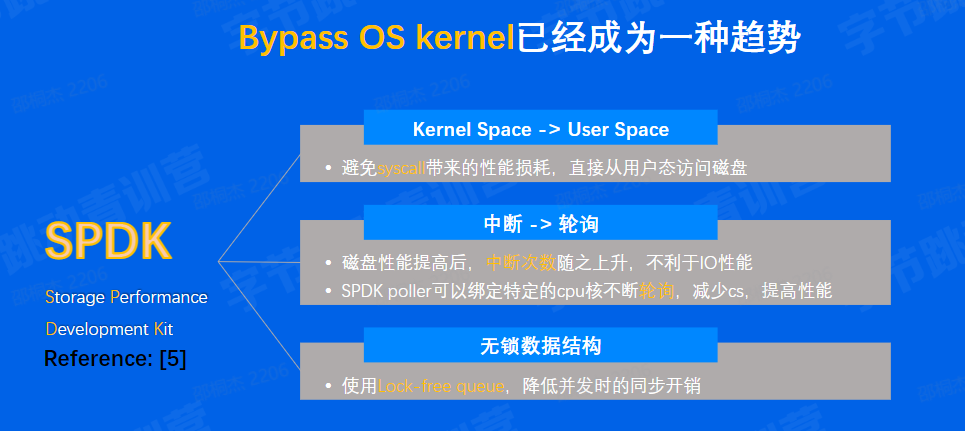
| SPDK | AI & Storage | 高性能硬件 |
|---|---|---|
 |
 |
 |
存储系统
- 块存储:存储软件栈里的底层系统,接口过于朴素
- 文件存储:日常使用最广泛的存储系统,接口十分友好,实现五花八门
- 对象存储:公有云上的王牌产品,immutable语义加持
- key-value存储:形式最灵活,存在大量的开源/黑盒产品
数据库系统
- 关系型数据库:基于关系和关系代数构建的,一般支持事务和sql访问,使用体验友好的存储产品
- 非关系型数据库:结构灵活,访问方式灵活,针对不同场景有不同的针对性产品
分布式架构
- 数据分布策略:觉得了数据怎么分布到集群的多个物理节点,是否均匀,是否能做到高性能
- 数据复制协议:影响IO路径的性能、机器故障场景的除了方式
- 分布式事务算法:多个数据库节点协同保障一个事务的ACID特性的算法,通常基于2pc设计
在存储&数据库领域,硬件反推软件产品变革十分常见。
实现一个(分布式)key-value 存储系统
作业要求:
- 基于本地文件系统实现,支持常用的 put(k, v)、get(k, v)、scan_by_prefix(prefix) 接口
- 支持存储 server 独立进程部署,支持跨进程或者网络访问
- IO 操作做到低时延
*可选: 支持扩展成分布式架构,多台存储 server 组成一个分布式 key-value 存储系统,并保证全局的数据一致性。