|
| 1 | +# USE method |
| 2 | + |
| 3 | +Source: <https://www.brendangregg.com/usemethod.html> |
| 4 | + |
| 5 | +## 1. Summary |
| 6 | + |
| 7 | +> [!important] |
| 8 | +> For every resource, check utilization, saturation, and errors. |
| 9 | +
|
| 10 | +Terminology definitions: |
| 11 | +- resource: all physical server functional components (CPUs, disks, busses, ...). |
| 12 | +- utilization: the average time that the resource was busy servicing work. |
| 13 | +- saturation: the degree to which the resource has extra work which it can't service, often queued |
| 14 | +- errors: the count of error events. |
| 15 | + |
| 16 | +The metrics are usually expressed in the following terms: |
| 17 | +- utilization: as a percent over a time interval. eg, "one disk is running at 90% utilization". |
| 18 | +- saturation: as a queue length. eg, "the CPUs have an average run queue length of four". |
| 19 | +- errors: scalar counts. eg, "this network interface has had fifty late collisions". |
| 20 | + |
| 21 | +A burst of high utilization can cause saturation and performance issues, even though utilization is low when averaged over a long interval. |
| 22 | + |
| 23 | +## 2. Resource list |
| 24 | + |
| 25 | +- CPUs: sockets, cores, hardware threads (virtual CPUs) |
| 26 | +- Memory: capacity |
| 27 | +- Network interfaces |
| 28 | +- Storage devices: I/O, capacity |
| 29 | +- Controllers: storage, network cards |
| 30 | +- Interconnects: CPUs, memory, I/O |
| 31 | + |
| 32 | +The USE Method is most effective for resources that suffer performance degradation under high utilization or saturation, leading to a bottleneck. Caches improve performance under high utilization. |
| 33 | + |
| 34 | +## 3. Suggested Interpretations |
| 35 | + |
| 36 | +The USE Method helps you identify which metrics to use. After learning how to read them from the operating system, your next task is to interpret their current values. |
| 37 | + |
| 38 | +The following are some general suggestions for interpreting metric types: |
| 39 | + |
| 40 | +- **Utilization**: 100% utilization is usually a sign of a bottleneck (check saturation and its effect to confirm). High utilization (eg, beyond 70%) can begin to be a problem for a couple of reasons: |
| 41 | + - When utilization is measured over a relatively long time period (multiple seconds or minutes), a total utilization of, say, 70% can hide short bursts of 100% utilization. |
| 42 | + - Some system resources, such as hard disks, cannot be interrupted during an operation, even for higher-priority work. Once their utilization is over 70%, queueing delays can become more frequent and noticeable. Compare this to CPUs, which can be interrupted ("preempted") at almost any moment. |
| 43 | +- **Saturation**: any degree of saturation can be a problem (non-zero). This may be measured as the length of a wait queue, or time spent waiting on the queue. |
| 44 | +- **Errors**: non-zero error counters are worth investigating, especially if they are still increasing while performance is poor. |
| 45 | + |
| 46 | +## 4. Strategy |
| 47 | + |
| 48 | +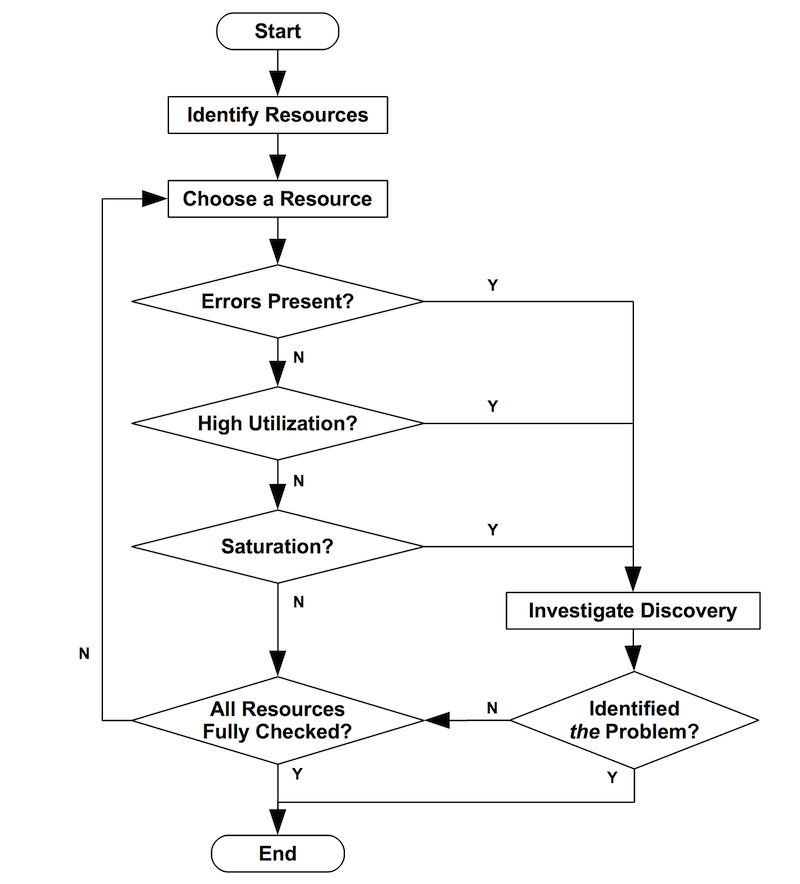 |
0 commit comments