|
| 1 | +# Log structured merge (LSM) tree |
| 2 | + |
| 3 | +Source: |
| 4 | + |
| 5 | +- <https://www.geeksforgeeks.org/dsa/introduction-to-log-structured-merge-lsm-tree/> |
| 6 | +- <https://www.youtube.com/watch?v=I6jB0nM9SKU> |
| 7 | +- <https://system.farmerboy95.com/ByteByteGo/lsm-tree/> |
| 8 | +- <https://docs.yugabyte.com/stable/architecture/docdb/lsm-sst/> |
| 9 | + |
| 10 | +LSM Trees are the data structure underlying many highly scalable NoSQL distributed key-value type databases such as Amazon's DynamoDB, Cassandra, and ScyllaDB. |
| 11 | + |
| 12 | +A simple version of LSM Trees comprises 2 levels of tree-like data structure: |
| 13 | + |
| 14 | +- Memtable and resides completely in memory (let's say T0) |
| 15 | +- SStables stored in disk (Let's say T1) |
| 16 | +- Typically in LSMs there is a third component - WAL (Write ahead log) |
| 17 | + |
| 18 | +.png>) |
| 19 | + |
| 20 | +## 1. Comparison to B-tree |
| 21 | + |
| 22 | +Most traditional databases (for example, MySQL, PostgreSQL, Oracle) have a [B-tree](https://en.wikipedia.org/wiki/B-tree)-based storage system |
| 23 | + |
| 24 | +- Write operations (insert, update, delete) are more expensive in a B-tree, requiring random writes and in-place node splitting and rebalancing. In LSM-based storage, data is added to the memtable and written onto a SST file as a batch. |
| 25 | +- The append-only nature of LSM makes it more efficient for concurrent write operations. |
| 26 | + |
| 27 | +## 2. Memtable |
| 28 | + |
| 29 | +All new write operations (inserts, updates, and deletes) are written as key-value pairs to an in-memory data structure called a memtable, which is essentially a sorted map or tree. The key-value pairs are stored in sorted order based on the keys. When the memtable reaches a certain size, it is made immutable, which means no new writes can be accepted into that memtable. |
| 30 | + |
| 31 | +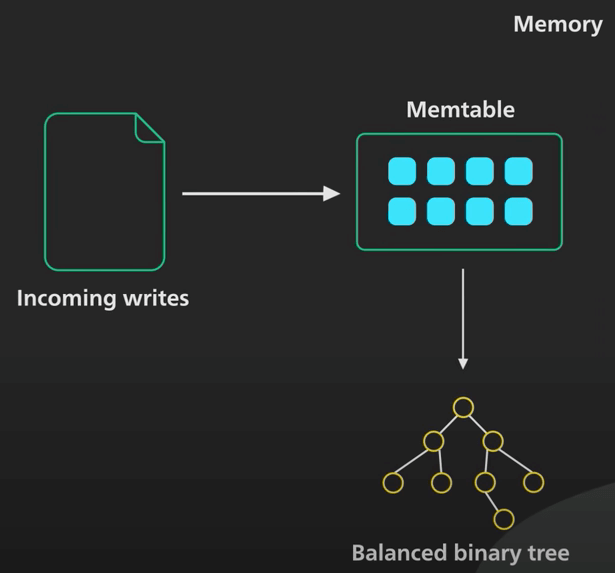 |
| 32 | + |
| 33 | +## 3. Flush to SST |
| 34 | + |
| 35 | +The immutable memtable is then flushed to disk as an SST (Sorted String Table) file. This process involves writing the key-value pairs from the memtable to disk in a sorted order, creating an SST file |
| 36 | + |
| 37 | +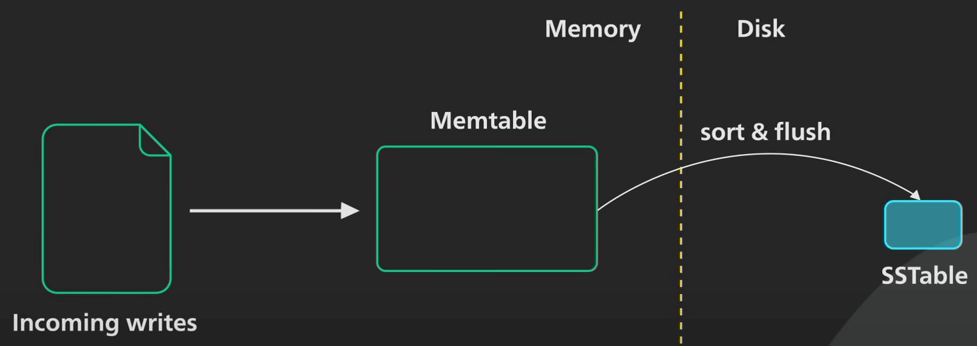 |
| 38 | + |
| 39 | +## 4. SST (Sorted String Table) |
| 40 | + |
| 41 | +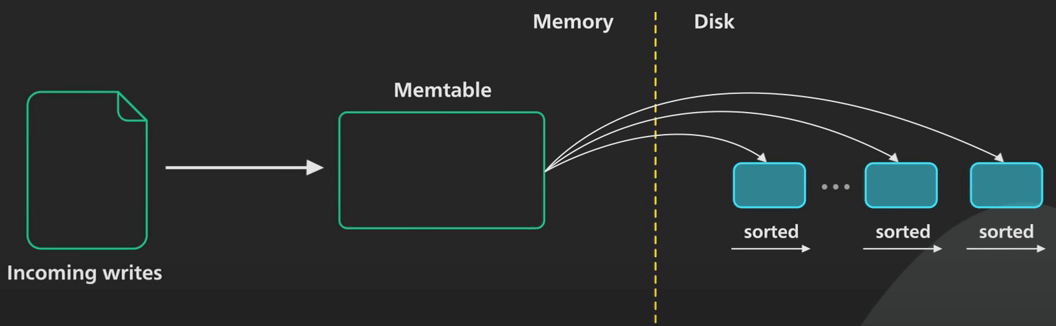 |
| 42 | + |
| 43 | +- Each SST file is an immutable, sorted file containing key-value pairs |
| 44 | +- The data is organized into data blocks, which are compressed using configurable compression algorithms (for example, Snappy, Zlib). |
| 45 | +- Index blocks provide a mapping between key ranges and the corresponding data blocks, enabling efficient lookup of key-value pairs. |
| 46 | +- Filter blocks containing **bloom filters** allow for quickly determining if a key might exist in an SST file or not, skipping entire files during lookups. |
| 47 | + - A bloom filter is a space-efficient data structure that helps quickly determine whether a key might exist in that file or not, avoiding unnecessary disk reads. |
| 48 | +- The footer section of an SST file contains metadata about the file, such as the number of entries, compression algorithms used, and pointers to the index and filter blocks. |
| 49 | + |
| 50 | +## 5. Write path |
| 51 | + |
| 52 | +- When new data is written to the LSM system, it is first inserted into the active memtable. |
| 53 | +- As the memtable fills up, it is made immutable and written to disk as an SST files. |
| 54 | +- Each SST file is sorted by key and contains a series of key-value pairs organized into data blocks, along with index and filter blocks for efficient lookups. |
| 55 | + |
| 56 | +## 6. Read path |
| 57 | + |
| 58 | +- To read a key, the LSM tree first checks the memtable for the most recent value. |
| 59 | +- If not found, it checks the SST files and finds the key or determines that it doesn't exist. During this process, LSM uses the index and filter blocks in the SST files to efficiently locate the relevant data blocks containing the key-value pairs. |
| 60 | + |
| 61 | +## 7. Delete path |
| 62 | + |
| 63 | +Rather than immediately removing the key from SSTs, the delete operation marks a key as deleted using a tombstone marker, indicating that the key should be ignored in future reads. The actual deletion happens during compaction, when tombstones are removed along with the data they mark as deleted. |
| 64 | + |
| 65 | +## 8. Compaction |
| 66 | + |
| 67 | +- As data accumulates in SSTs, a process called compaction merges and sorts the SST files with overlapping key ranges producing a new set of SST files. |
| 68 | +- The merge process during compaction helps to organize and sort the data, maintaining a consistent on-disk format and reclaiming space from obsolete data versions. |
| 69 | +- There are two types of compaction: Size Tiered Compaction and Level Based Compaction. |
| 70 | + |
| 71 | +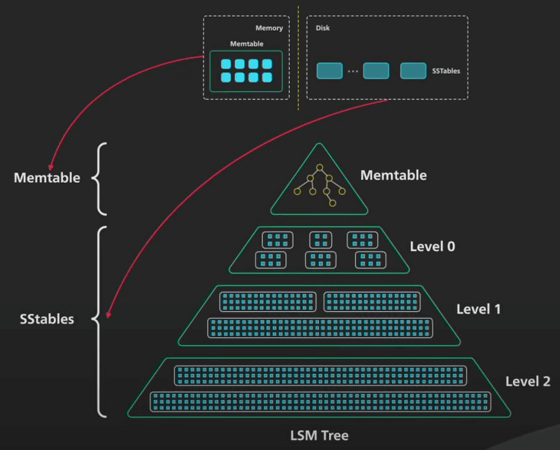 |
| 72 | + |
| 73 | +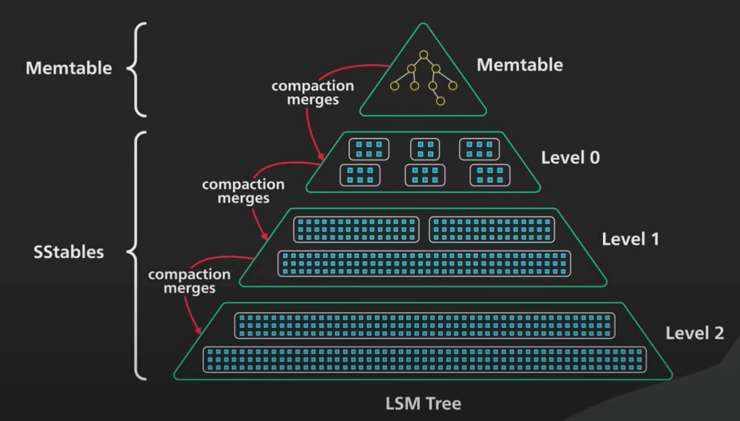 |
| 74 | + |
| 75 | +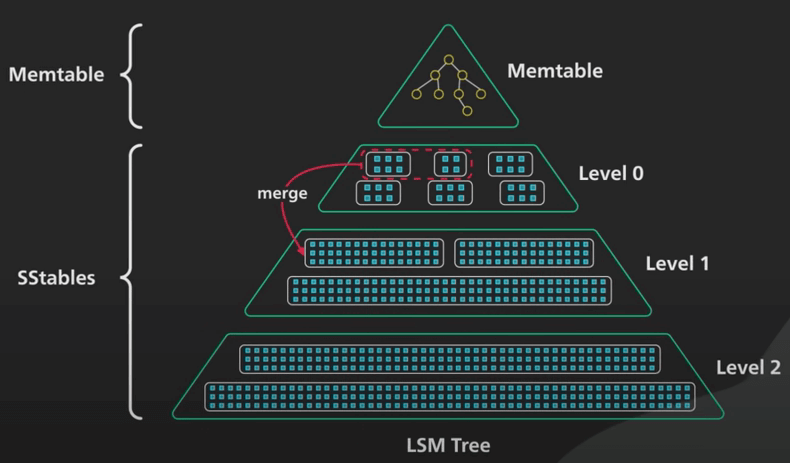 |
0 commit comments