|
| 1 | +# Life of a Sample in Thanos, and How to Configure it |
| 2 | + |
| 3 | +Source: |
| 4 | + |
| 5 | +- <https://thanos.io/blog/2023-11-20-life-of-a-sample-part-1/> |
| 6 | +- <https://thanos.io/blog/2023-11-20-life-of-a-sample-part-2/> |
| 7 | + |
| 8 | +> I only note the main idea what I think worth to be noted. For detail, check out the original posts. |
| 9 | +
|
| 10 | +## 1. Sending sample to Thanos |
| 11 | + |
| 12 | +- Thanos Receive exposes a remote-write endpoint that Prometheus servers can use to transmit metrics. The only prerequisite on the client side is to configure the remote write endpoint on each Prometheus server, a feature natively supported by Prometheus. |
| 13 | +- The remote-write protocol is based on POST request. The payload consists of a protobuf message containing a list of time-series samples and labels. Generally, a payload contains at most one sample per time series and spans numerous time series. Metrics are typically scraped every 15 seconds, with a maximum remote write delay of 5 seconds to minimize latency, from scraping to query availability on the receiver. |
| 14 | +- Each [remote write](https://prometheus.io/docs/practices/remote_write/) destination starts a queue which reads from the write-ahead log (WAL), writes the samples into an in memory queue owned by a shard, which then sends a request to the configured endpoint. The flow of data looks like: |
| 15 | + - Once samples are extracted from the WAL, they are aggregated into parallel queues (shards) as remote-write payloads. |
| 16 | + - When a queue reaches its limit or a maximum timeout is reached, the remote-write client stops reading the WAL and dispatches the data. |
| 17 | + - The cycle continues. The parallelism is defined by the number of shards, their number is dynamically optimized. |
| 18 | + |
| 19 | +```text |
| 20 | + |--> queue (shard_1) --> remote endpoint |
| 21 | +WAL --|--> queue (shard_...) --> remote endpoint |
| 22 | + |--> queue (shard_n) --> remote endpoint |
| 23 | +``` |
| 24 | + |
| 25 | +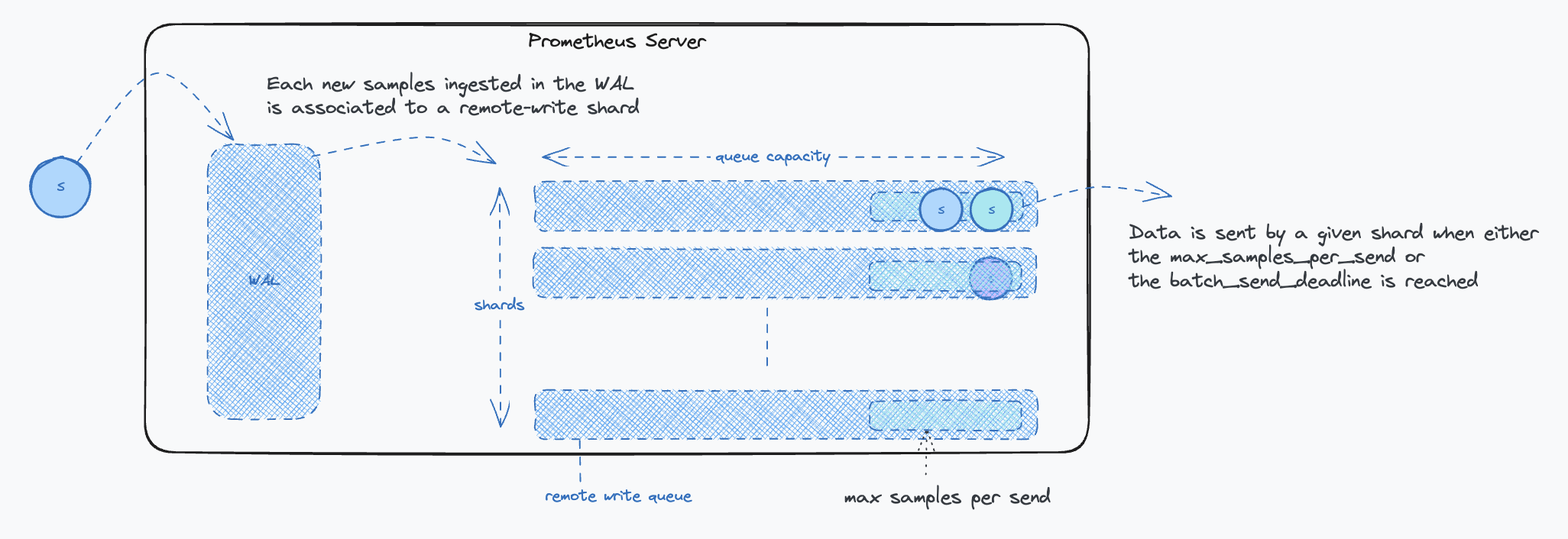 |
| 26 | + |
| 27 | +- Key points to consider: |
| 28 | + - **The send deadline setting**: `batch_send_deadline` should be set to around 5s to minimize latency. This timeframe strikes a balance between minimizing latency and avoiding excessive request frequency that could burden the Receiver. While a 5-second delay might seem substantial in critical alert scenarios, it is generally acceptable considering the typical resolution time for most issues. |
| 29 | + - The backoff settings: The `min_backoff` should ideally be no less than 250 milliseconds, and the max_backoff should be at least 10 seconds. These settings help prevent Receiver overload, particularly in situations like system restarts, by controlling the rate of data sending. |
| 30 | +- In scenarios where you have limited control over client configurations, it becomes essential to shield the Receive component from potential misuse or overload. The Receive component includes several configuration options designed for this purpose. |
| 31 | + |
| 32 | +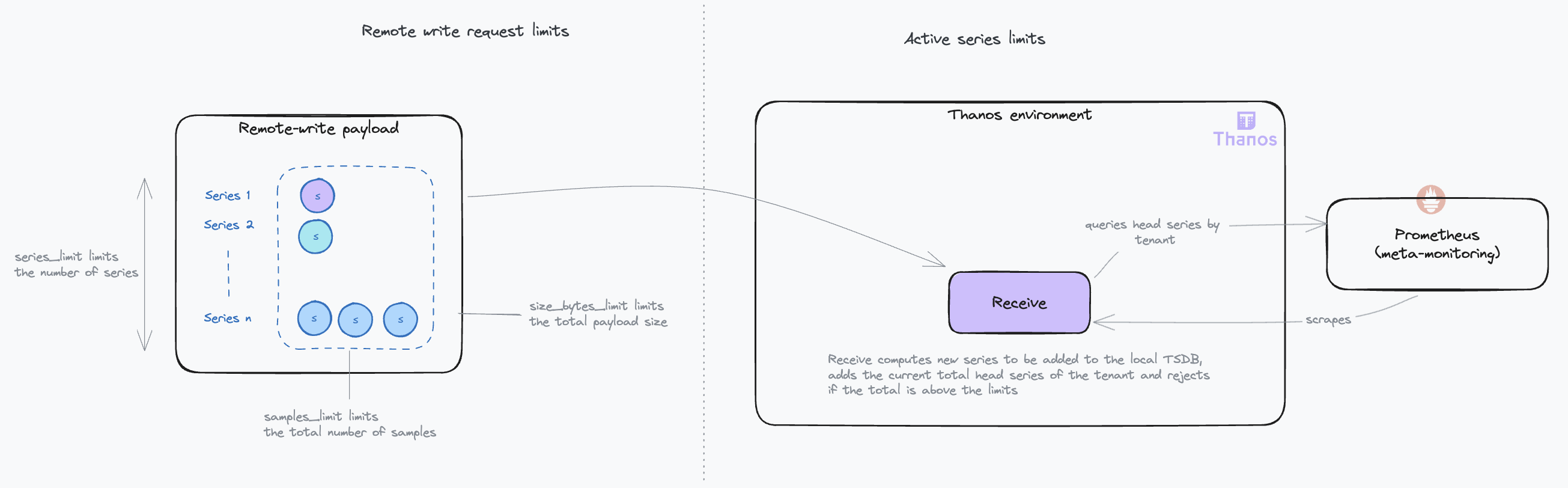 |
| 33 | + |
| 34 | +- Keys to consider: |
| 35 | + - **Series and samples limits**: Typically, with a standard target scrape interval of 15 seconds and a maximum remote write delay of 5 seconds, the `series_limit` and `samples_limit` tend to be functionally equivalent. However, in scenarios where the remote writer is recovering from downtime, the `samples_limit` may become more restrictive, as the payload might include multiple samples for the same series. |
| 36 | + - **Handling request limits**: If a request exceeds these limits, the system responds with a 413 (Entity Too Large) HTTP error. |
| 37 | + - **Active series limiting**: The limitation on active series persists as long as the count remains above the set threshold in the Receivers’ TSDBs. Active series represent the number of time series currently stored in the TSDB’s (Time Series Database) head block. The head block is the in-memory portion of the TSDB where incoming samples are temporarily stored before being compacted into persistent on-disk blocks. The head block is typically compacted every two hours. This is when stale series are removed, and the active series count decreases. Requests reaching this limit are rejected with a 429 (Too Many Requests) HTTP code, triggering retries. |
| 38 | + |
| 39 | +## 2. Receiving samples with high availability and durability |
| 40 | + |
| 41 | +- The need for multiple receive instances: Relying on a single instance of Thanos Receive is not sufficient for two main reasons: |
| 42 | + - Scalability: As your metrics grow, so does the need to scale your infrastructure. |
| 43 | + - Reliability: If a single Receive instance falls, it disrupts metric collection, affecting rule evaluation and alerting. Furthermore, during downtime, Prometheus servers will buffer data in their Write-Ahead Log (WAL). If the outage exceeds the WAL’s retention duration (default is 2 hours), this can lead to data loss. |
| 44 | +- To achieve high availability, it is necessary to deploy multiple Receive replicas -> crucial to maintain consistency in sample ingestion (samples from a given time series should always be ingested by the same Receive instance) -> uses a hashring. |
| 45 | + - When clients send data, they connect to any Receive instance, which then routes the data to the correct instances based on the hashring. This is why the Receive component is also known as the IngestorRouter. |
| 46 | + - There're two possible hashrings: |
| 47 | + - **hashmod**: This algorithm distributes time series by hashing labels modulo the number of instances. The downside is that scaling operations on the hashring cause a high churn of time series on the nodes, requiring each node to flush its TSDB head and upload its recent blocks on the object storage. During this operation that can last a few minutes, the receivers cannot ingest data, causing a downtime. This is especially critical if you are running big Receive nodes. The more data they have, the longer the downtime. |
| 48 | + - **ketama**: an implementation of a consistent hashing algorithm. It means that during scaling operations, most of the time series will remain attached to the same nodes. No TSDB operation or data upload is needed before operating into the new configuration. As a result, the downtime is minimal, just the time for the nodes to agree on the new hashring. As a downside, it can be less efficient in evenly distributing the load compared to hashmod. |
| 49 | + |
| 50 | +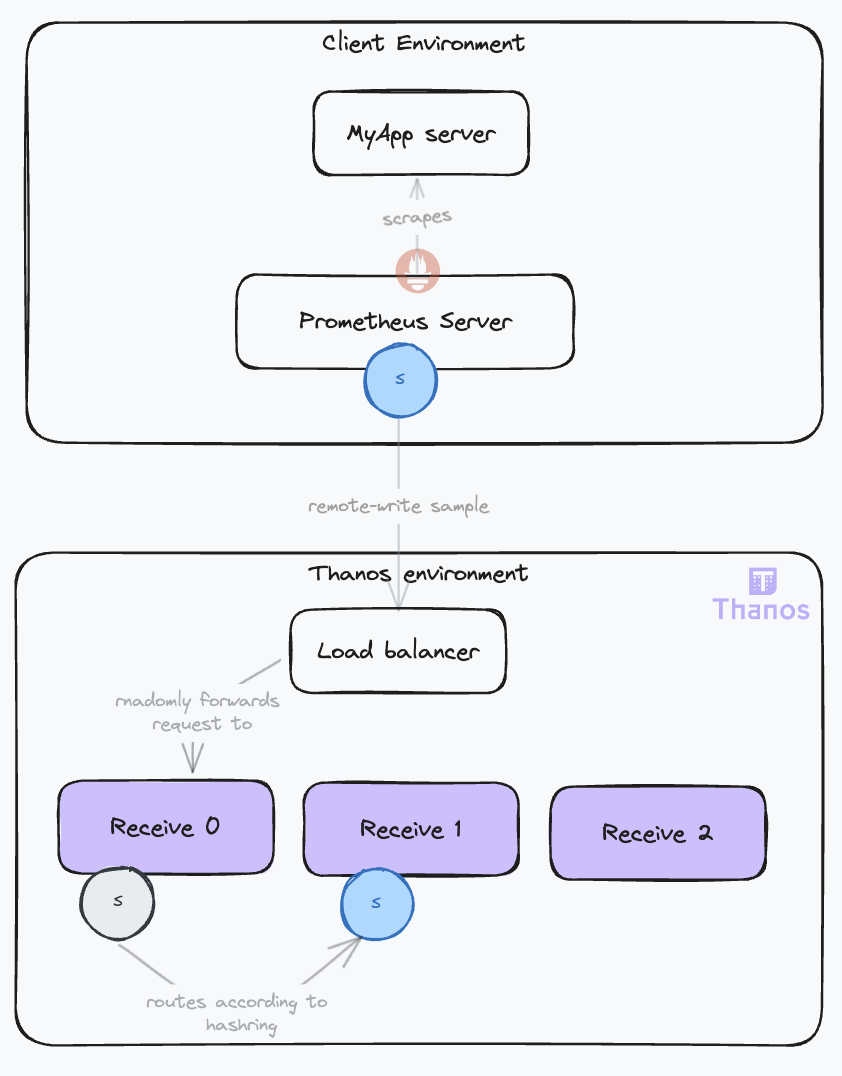 |
| 51 | + |
| 52 | +- Keys to consider: |
| 53 | + - If you load is stable for the foreseeable future -> hashmod. Otherwise -> ketama. |
| 54 | + - The case for small Receive nodes -> hashmod. |
| 55 | + - Protecting the nodes after recovery: recommend using the `receive.limits-config` flag to limit the amount of data that can be received. |
| 56 | +- For clients requiring high data durability, the `--receive.replication-factor` flag ensures data duplication across multiple receivers. |
| 57 | +- A new deployment topology was proposed, separating the router and ingestor roles. The hashring configuration is read by the routers, which will direct each time series to the appropriate ingestor and its replicas. This role separation provides some important benefits. |
| 58 | + |
| 59 | +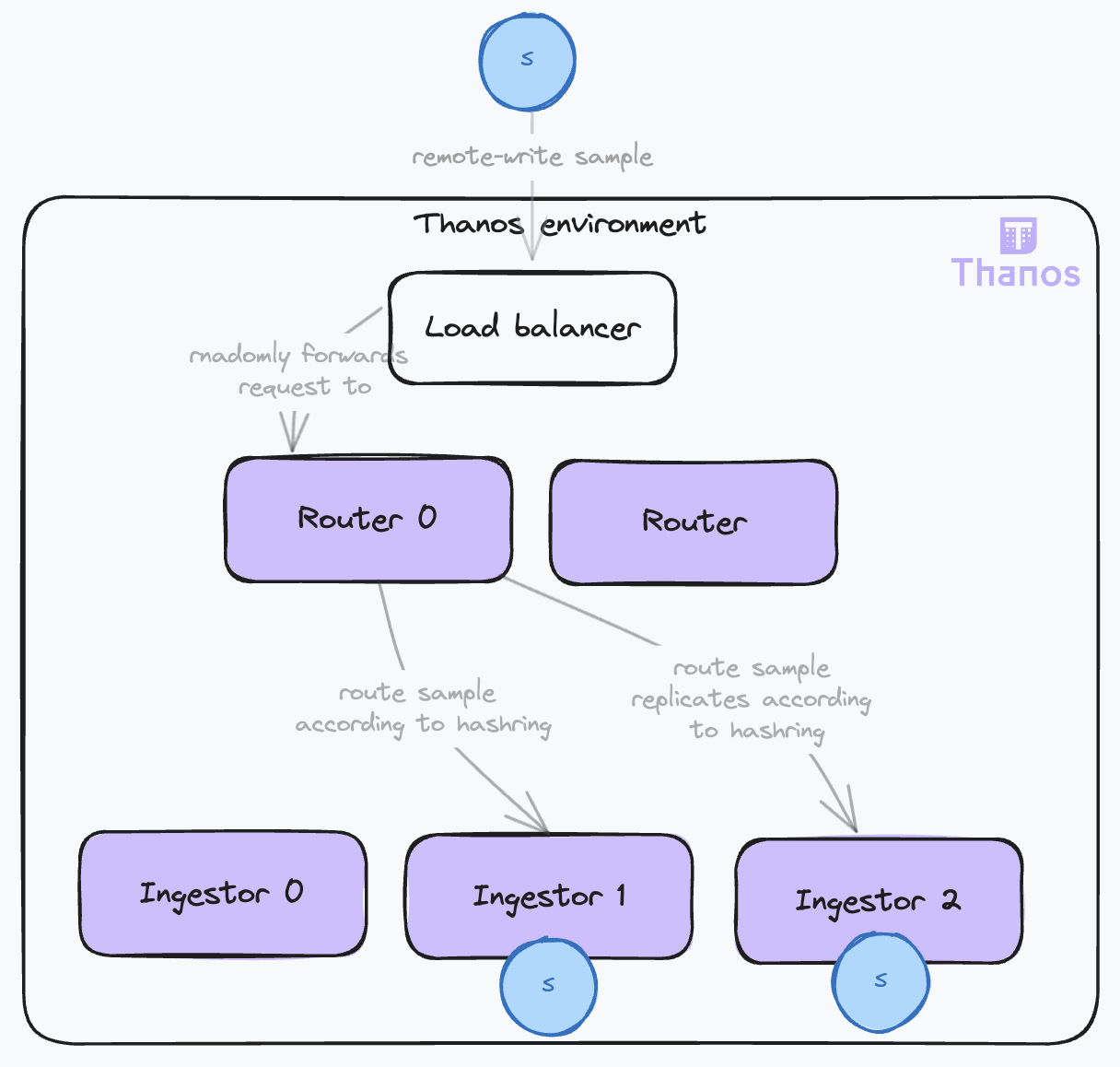 |
| 60 | + |
| 61 | +- To enhance reliability in data ingestion, Thanos Receive supports out-of-order samples. Samples are ingested into the Receiver’s TSDB, which has strict requirements for the order of timestamps: |
| 62 | + - Samples are expected to have increasing timestamps for a given time series. |
| 63 | + - A new sample cannot be more than 1 hour older than the most recent sample of any time series in the TSDB. |
| 64 | +- Support for out-of-order samples has been implemented for the TSDB. This feature can be enabled with the `tsdb.out-of-order.time-window` flag on the Receiver. The downsides are: |
| 65 | + - An increase in the TSDB’s memory usage, proportional to the number of out-of-order samples. |
| 66 | + - The TSDB will produce blocks with overlapping time periods, which the compactor must handle. Ensure the `--compact.enable-vertical-compaction` flag is enabled on the compactor to manage these overlapping blocks. We will cover this in more detail in the next article. |
| 67 | +- Additionally, consider setting the `tsdb.too-far-in-future.time-window` flag to a value higher than the default 0s to account for possible clock drifts between clients and the Receiver. |
| 68 | + |
| 69 | +## 3. Preparing Samples for Object Storage: Building Chunks and Blocks |
| 70 | + |
| 71 | +// wip |
0 commit comments