|
| 1 | +# Elasticsearch cache |
| 2 | + |
| 3 | +Source: <https://www.elastic.co/blog/elasticsearch-caching-deep-dive-boosting-query-speed-one-cache-at-a-time> |
| 4 | + |
| 5 | +Elasticsearch is a heavy user of various caches, but in this post we'll only be focusing on: |
| 6 | + |
| 7 | +- Page cache (sometimes called the filesystem cache). |
| 8 | +- Shard-level request cache. |
| 9 | +- Query cache. |
| 10 | + |
| 11 | +## 1. Page cache |
| 12 | + |
| 13 | +The basic idea of the page cache is to put data into the available memory after reading it from disk, so that the next read is returned from the memory and getting the data does not require a disk seek. All of this is completely transparent to the application, which is issuing the same system calls, but the operating system has the ability to use the page cache instead of reading from disk. |
| 14 | + |
| 15 | +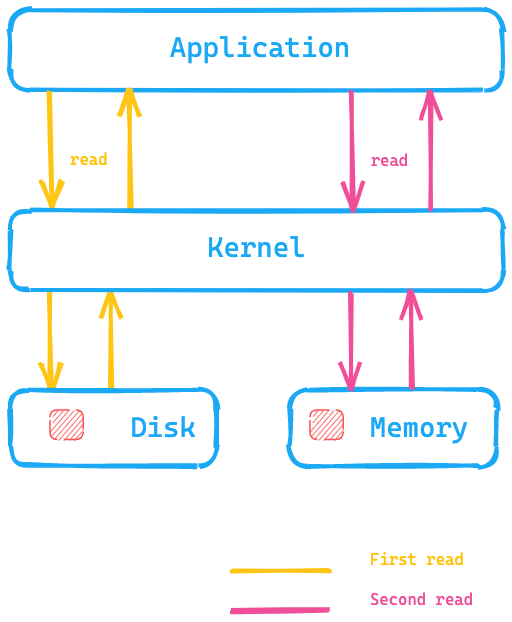 |
| 16 | + |
| 17 | +Instead of accessing data on-disk, the page cache can be much faster to access data. This is one of the reasons why the recommendation for Elasticsearch memory is generally not more than half of your total available memory — so the other half can be used for the page cache. This also means that no memory is wasted; rather, it’s reused for the page cache. |
| 18 | + |
| 19 | +How does data expire out of the cache? If the data itself is changed, the page cache marks that data as dirty and it will be released from the page cache. As segments with Elasticsearch and Lucene are only written once, this mechanism fits very well the way data is stored. Segments are read-only after the initial write, so a change of data might be a merge or the addition of new data. In that case, a new disk access is needed. The other possibility is the memory getting filled up |
| 20 | + |
| 21 | +One last thing about Elasticsearch here. You can configure Elasticsearch to [preload data into the page cache](https://www.elastic.co/guide/en/elasticsearch/reference/7.11/preload-data-to-file-system-cache.html) via the index settings. Consider this an expert setting and be careful with this setting in order to ensure that the page cache does not get thrashed consistently. |
| 22 | + |
| 23 | +## 2. Shard-level request cache |
| 24 | + |
| 25 | +When a search request is run against an index or against many indices, each involved shard runs the search locally and returns its local results to the coordinating node, which combines these shard-level results into a global result set. |
| 26 | + |
| 27 | +The shard-level request cache module caches the local results on each shard. This allows frequently used (and potentially heavy) search requests to return results almost instantly. The requests cache is a very good fit for the logging use case, where only the most recent index is being actively updated — results from older indices will be served directly from the cache. |
| 28 | + |
| 29 | +The goal of this cache is to reduce the need for Elasticsearch to **re-execute expensive computations for queries that are run often on the same data**. |
| 30 | + |
| 31 | +As the cache stores the query results, it must also handle eviction to ensure that it doesn't grow indefinitely and consume too much memory. Some key points on cache eviction: |
| 32 | + |
| 33 | +- Memory Management: The size of the cache is determined by the available memory. When the cache reaches its memory limit, older entries are evicted to make room for newer ones. |
| 34 | +- Cache Invalidation: If data changes, such as when documents are indexed or deleted, the results stored in the cache may no longer be valid. In such cases, Elasticsearch will evict the cache to ensure that the next query retrieves fresh data. |
| 35 | + |
| 36 | +Key characteristics: |
| 37 | + |
| 38 | +- Shard-Specific: This cache is stored at the **shard level**, which means each shard in an index has its own independent cache. |
| 39 | +- Cache Results: The cache stores the results of the **query itself**, not the documents or the data. This allows Elasticsearch to avoid re-running the query execution if the same query is run again. |
| 40 | +- Query-Level Caching: The cache is specifically useful when identical queries (in terms of filters, aggregations, and other parameters) are executed multiple times. This is common in applications where certain queries are run frequently, such as filtering on specific fields or aggregating over specific values. |
| 41 | + |
| 42 | +## 3. Query cache |
| 43 | + |
| 44 | +The page cache caches data independent of how much of this data is really read from a query. The shard-level query cache caches data when a similar query is used. The query cache is even more granular and can **cache data that is reused between different queries**. |
| 45 | + |
| 46 | +Let’s imagine we search across logs. Three different users might be browsing this month’s data. However, each user uses a different search term: |
| 47 | + |
| 48 | +- User1 searched for “failure” |
| 49 | +- User2 searched for “Exception” |
| 50 | +- User3 searched for “pcre2_get_error_message” |
| 51 | + |
| 52 | +Every search returns different results, and yet they are within the same time frame. This is where the query cache comes in: it is able to cache just that part of a query. The basic idea is to cache information hitting the disk and only search in those products. Your query is probably looking like this: |
| 53 | + |
| 54 | +```json |
| 55 | +GET logs-*/_search |
| 56 | +{ |
| 57 | + "query": { |
| 58 | + "bool": { |
| 59 | + "must": [ |
| 60 | + { |
| 61 | + "match": { |
| 62 | + "message": "pcre2_get_error_message" |
| 63 | + } |
| 64 | + } |
| 65 | + ], |
| 66 | + "filter": [ |
| 67 | + { |
| 68 | + "range": { |
| 69 | + "@timestamp": { |
| 70 | + "gte": "2021-02-01", |
| 71 | + "lt": "2021-03-01" |
| 72 | + } |
| 73 | + } |
| 74 | + } |
| 75 | + ] |
| 76 | + } |
| 77 | + } |
| 78 | +} |
| 79 | +``` |
| 80 | + |
| 81 | +For every query the filter part stays the same. This is a highly simplified view of what the data looks like in an inverted index. Each time stamp is mapped to a document id. |
| 82 | + |
| 83 | +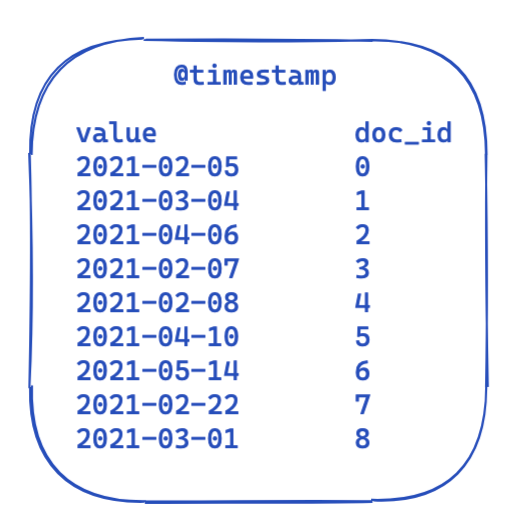 |
| 84 | + |
| 85 | +So, how can this be optimized and reused across queries? This is where bit sets (also called bit arrays) come into play. A bit set is basically an array where each bit represents a document. We can create a dedicated bit set for this particular @timestamp filter covering a single month. A 0 means that the document is outside of this range, whereas a 1 means it is inside. The resulting bit set would look like this: |
| 86 | + |
| 87 | +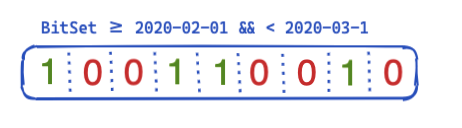 |
| 88 | + |
| 89 | +After creating this bit set on a per-segment base (meaning it would need to be recreated after a merge or whenever a new segment gets created), the next query does not need to do any disk access to rule out four documents before even running the filter. Bit sets have a couple of interesting properties. First they can be combined. If you have two filters and two bit sets, you can easily figure the documents where both bits are set — or merge an OR query together. Another interesting aspect of bit sets is compression. You need one bit per document per filter by default. However, by using not fixed bit sets but another implementation like roaring bitmaps you can reduce the memory requirements. |
0 commit comments