Platon.ai's goal is to develop an AI that efficiently collects and reads complex websites, accurately outputting data and knowledge. We have open-sourced the "efficient collection" component. We have also released a preview version that "reads and understands webpage structures and accurately outputs data," which will also be open-sourced in the near future.
Platon.ai's algorithm can transform web pages into data with 100% zero human intervention -- without the need for rules, and even without machine learning training. It is driven by unsupervised machine learning, similar to how humans read and understand the internet.
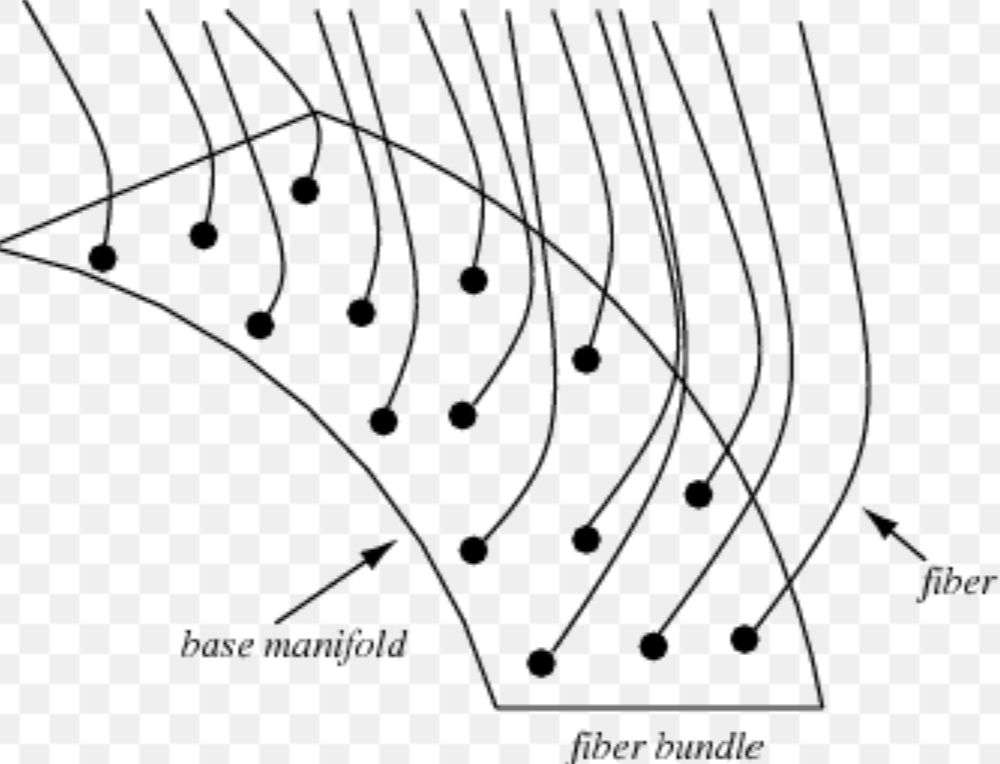
We calculate a series of features for each element on a webpage after rendering it in a browser, including visual, geometric, topological, and semantic features. A web page can be considered as a geometric graph composed of many rectangles with attributes, and when combined, it resembles a bundle of newspapers. The World Wide Web (WWW) can be viewed as a fiber bundle with a three-dimensional manifold as the base space.
You can download and try it:
// Given a portal url, automatically extract all the fields from out pages
java -jar exotic-standalone*.jar harvest https://www.hua.com/flower/ -diagnose -refresh
Furthermore, given any list page, we can evaluate the linked pages to detect which group of pages is generated by the same template, thus allowing the extraction of field values.
// Auto arrange the links in a webpage
java -jar exotic-standalone*.jar arrange https://www.hua.com/flower/
In this way, the problem of web page extraction that originally required manually writing several or even dozens of regular expressions or CSS PATHs can now be solved by simply telling the system the list page link, and web pages that meet this requirement account for the vast majority of web pages on the internet.
Finally, we have equipped the crawler system and data analysis system with an SQL engine, so we can monitor a website column and extract key data in real-time with just one SQL statement. In fact, with the SQL engine, the internet and local databases can almost be treated as the same (except for the longer response time of internet data).
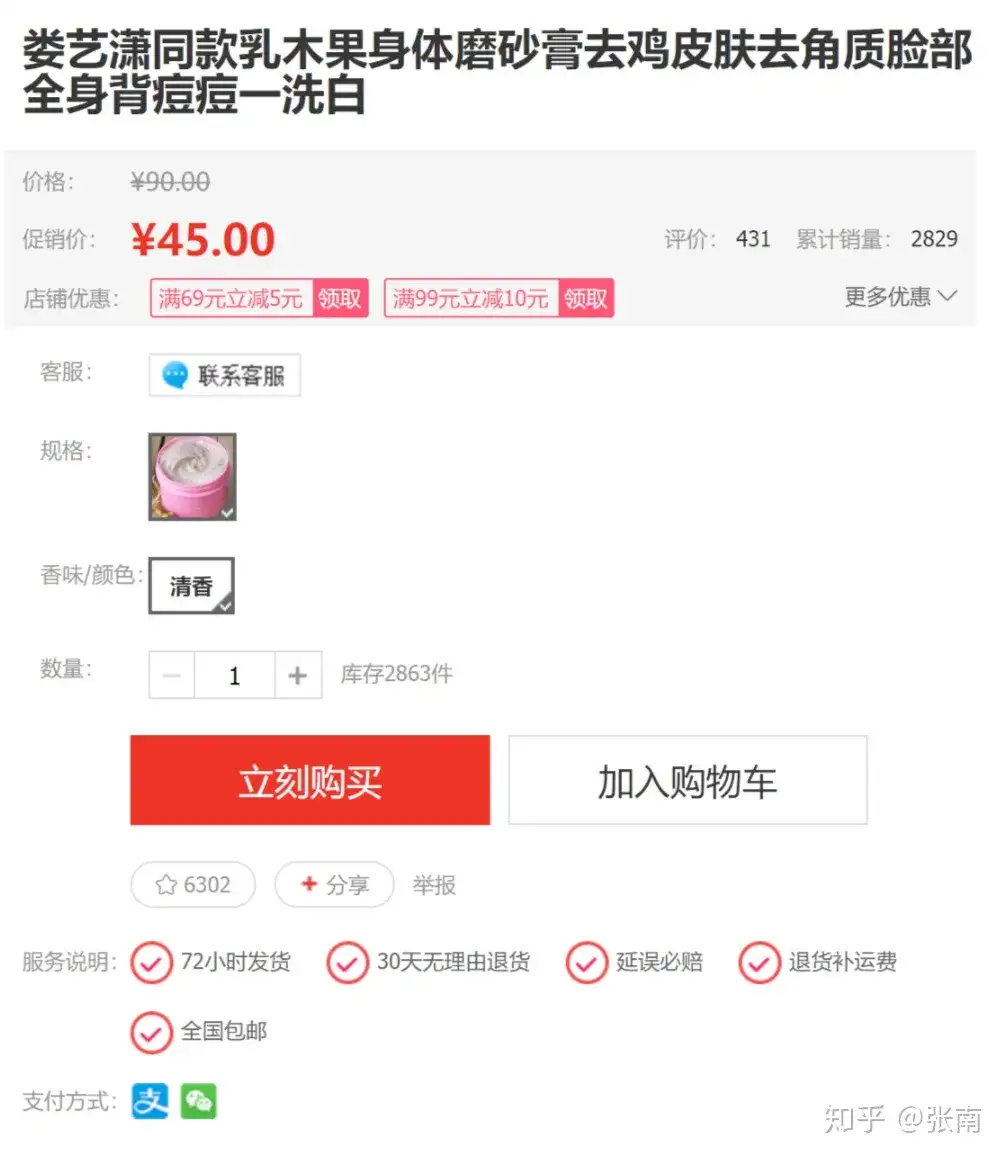
A typical web page section
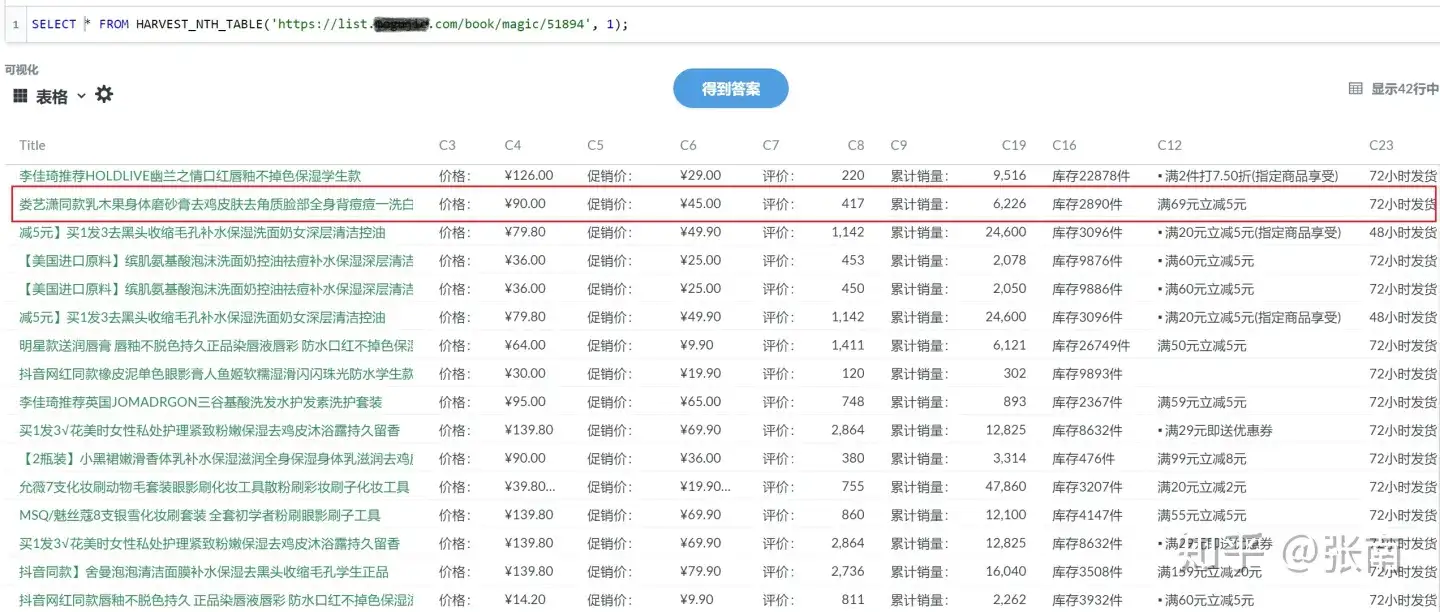
Data extracted using PulsarRPA's auto extraction technology
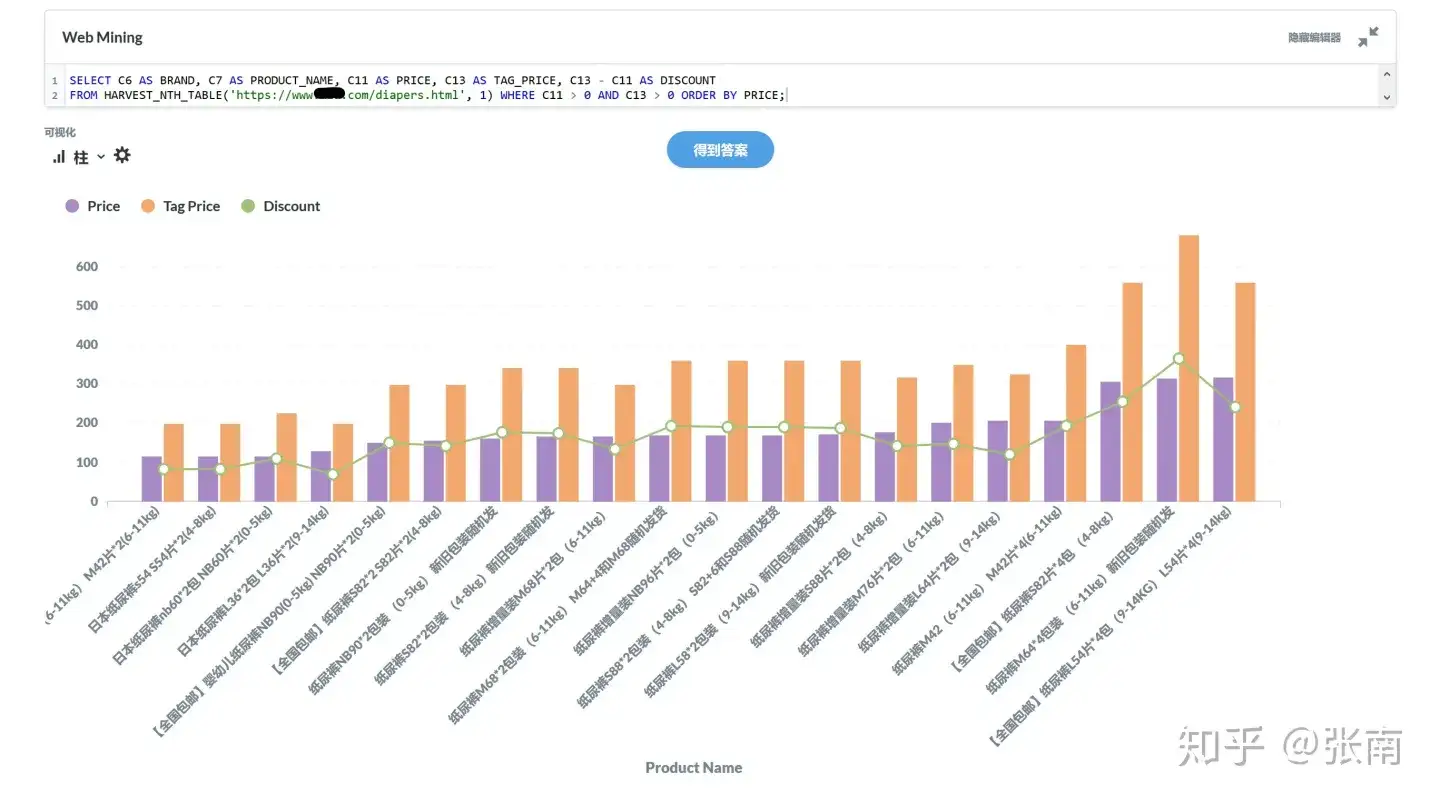
Using PulsarRPA's auto extraction technology and SQL to fully automate the transformation of the internet into charts
References:
- WebFormer: The Web-page Transformer for Structure Information Extraction | Proceedings of the ACM Web Conference 2022
- OpenCeres for extract knowledge graph from Web
- FreeDOM: A Transferable Neural Architecture for Structured Information Extraction on Web Documents
Related Articles: