diff --git "a/source/_posts/2025\346\230\245\345\244\217\345\255\243\345\274\200\346\272\220\346\223\215\344\275\234\347\263\273\347\273\237\350\256\255\347\273\203\350\220\245\347\254\254\344\270\200\351\230\266\346\256\265\346\200\273\347\273\223\346\212\245\345\221\212-1430329301Lsj.md" "b/source/_posts/2025\346\230\245\345\244\217\345\255\243\345\274\200\346\272\220\346\223\215\344\275\234\347\263\273\347\273\237\350\256\255\347\273\203\350\220\245\347\254\254\344\270\200\351\230\266\346\256\265\346\200\273\347\273\223\346\212\245\345\221\212-1430329301Lsj.md"
new file mode 100644
index 00000000000..b26de9c9dde
--- /dev/null
+++ "b/source/_posts/2025\346\230\245\345\244\217\345\255\243\345\274\200\346\272\220\346\223\215\344\275\234\347\263\273\347\273\237\350\256\255\347\273\203\350\220\245\347\254\254\344\270\200\351\230\266\346\256\265\346\200\273\347\273\223\346\212\245\345\221\212-1430329301Lsj.md"
@@ -0,0 +1,548 @@
+---
+title: <2025春夏季开源操作系统训练营第一阶段总结报告-1430329301Lsj>
+date: 2025-04-10 23:00:24
+tags:
+ - author:1430329301Lsj
+ - repo:https://github.com/LearningOS/2024a-rcore-1430329301Lsj
+---
+
+
+
+
+Rust速查表:[Rust Language Cheat Sheet](https://cheats.rs/)
+
+# Rust是什么
+
+- Rust可看作一个在语法层面(编译时)具有严格检查和限制的**C语言上位**。
+
+- 扩展了**面向对象**的便捷方法绑定。
+
+- 编译和运行方式类似于C/C++,可以`rustc xxx.rs`编译,`./xxx`运行。
+
+- 有约定的项目目录格式,可使用`Cargo`配置`toml`进行包管理、编译、运行、测试等等。
+
+- 包资源网站为`CratesIO`,见`src↑`。
+
+- 不支持运算符重载,支持多态。其中语句为:`表达式+;`,语句的值是`()`。
+
+ > **运算符重载**是指为自定义的类或结构体重新定义或赋予运算符(如+、-、*、/等)新的功能。它允许程序员对已有运算符赋予多重含义,使同一运算符作用于不同类型的数据时执行不同的操作。
+ >
+ > **特点:**
+ >
+ > 1. **扩展运算符功能**:让运算符不仅能作用于基本数据类型,也能作用于自定义类型
+ > 2. **语法简洁**:使自定义类型的操作像基本类型一样自然
+ > 3. **保持直观性**:重载后的运算符功能应与原意相符,避免滥用
+
+# Rust安装
+
+可使用编译器:VSCode + [rust-analyzer](https://marketplace.visualstudio.com/items?itemName=rust-lang.rust-analyzer),VIM,[RustRover](https://www.jetbrains.com/rust/)
+
+
+
+
+
+```
+curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
+```
+
+我最终选择使用rustRover来编译——jetBrain全家桶之一,与Pycham同源使用会比较顺手,且可以直接连接WSL:
+
+ +
+# Rust基础
+
+rust的编译与运行是分开的,是一种**预编译静态类型**语言。rust的源文件为`xx.rs`,最基础的编译为使用`rustc xx.rs`对代码进行编译。
+
+## 基础语法
+
+### Cargo
+
+Cargo是Rust的构建系统和包管理器:
+
+- 构建代码
+- 下载依赖库(代码所需的库叫做依赖)
+
+1.使用Cargo构建项目
+
+```
+$ cargo new the_project
+$ cd the_project
+```
+
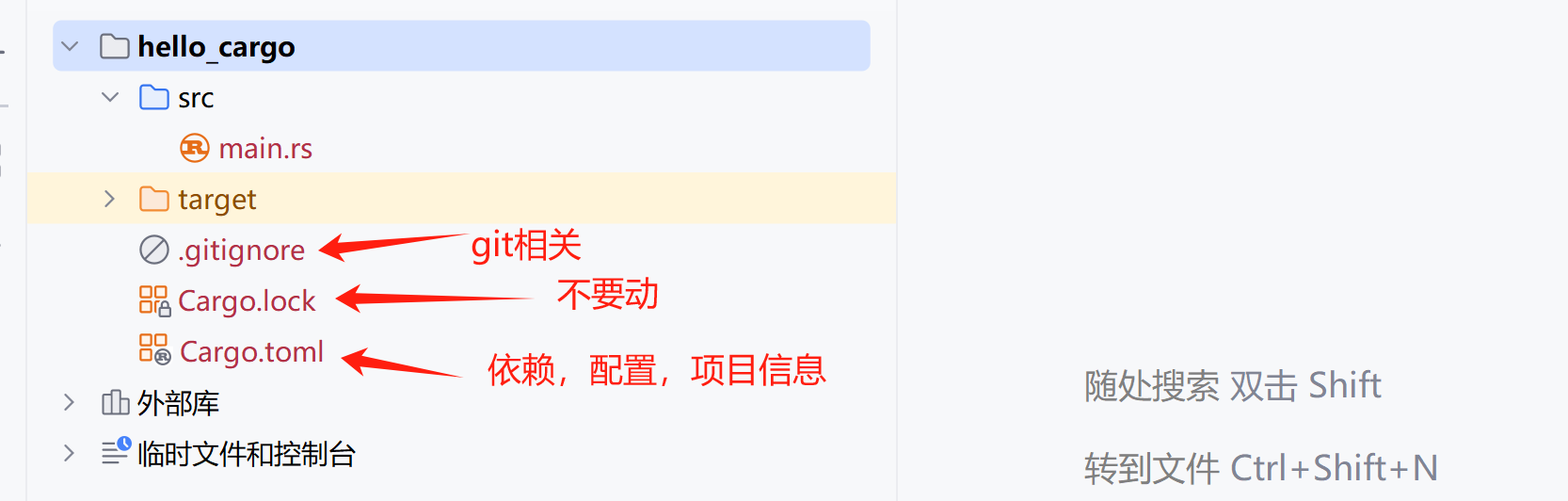
+在Linux终端输入上面的代码创建rust项目后,会生成如下的文件与目录:
+
+
+
+
+
+变量
+
+首先必须说明,Rust 是强类型语言,但具有自动判断变量类型的能力。这很容易让人与弱类型语言产生混淆。
+
+默认情况下,Rust 中的变量是不可变的,除非使用 mut 关键字声明为可变变量。
+
+```
+let a = 123; // 不可变变量
+let mut b = 10; // 可变变量
+```
+
+如果要声明变量,需要使用 **let** 关键字。例如:
+
+```
+let a = 123;
+```
+
+变量和常量还是有区别的。在 Rust 中,以下程序是合法的:
+
+```
+let a = 123; // 可以编译,但可能有警告,因为该变量没有被使用
+let a = 456;
+```
+
+但是如果 a 是常量就不合法:
+
+```
+const a: i32 = 123;
+let a = 456;
+```
+
+### 控制流
+
+**if 表达式**
+
+实例:
+
+```
+let number = 7;
+if number < 5 {
+ println!("小于 5");
+} else {
+ println!("大于等于 5");
+}
+```
+
+**loop 循环:** loop 是 Rust 中的无限循环,可以使用 break 退出循环。
+
+实例
+
+```
+let mut counter = 0;
+loop {
+ counter += 1;
+ if counter == 10 {
+ break;
+ }
+}
+```
+
+**while 循环**
+
+```
+let mut number = 3;
+while number != 0 {
+ println!("{}!", number);
+ number -= 1;
+}
+```
+
+**for 循环**
+
+```
+for number in 1..4 {
+ println!("{}!", number);
+}
+```
+
+
+
+### 结构体 (Structs)
+
+结构体用于创建自定义类型,字段可以包含多种数据类型。
+
+实例
+
+```
+struct User {
+ username: String,
+ email: String,
+ sign_in_count: u64,
+ active: bool,
+}
+
+let user1 = User {
+ username: String::from("someusername"),
+ email: String::from("someone@example.com"),
+ sign_in_count: 1,
+ active: true,
+};
+```
+
+
+
+### 枚举 (Enums)
+
+枚举允许定义可能的几种数据类型中的一种。
+
+```
+enum IpAddrKind {
+ V4,
+ V6,
+}
+
+let four = IpAddrKind::V4;
+let six = IpAddrKind::V6;
+```
+
+
+
+### 模式匹配 (match)
+
+match 是 Rust 中强大的控制流工具,类似于 switch 语句。
+
+```
+enum Coin {
+ Penny,
+ Nickel,
+ Dime,
+ Quarter,
+}
+
+fn value_in_cents(coin: Coin) -> u8 {
+ match coin {
+ Coin::Penny => 1,
+ Coin::Nickel => 5,
+ Coin::Dime => 10,
+ Coin::Quarter => 25,
+ }
+}
+```
+
+
+
+### 错误处理
+
+
+
+Rust 有两种主要的错误处理方式:**Result** 和 **Option**。
+
+
+
+**Result:**
+
+```
+enum Result {
+ Ok(T),
+ Err(E),
+}
+
+fn divide(a: i32, b: i32) -> Result {
+ if b == 0 {
+ Err(String::from("Division by zero"))
+ } else {
+ Ok(a / b)
+ }
+}
+```
+
+**Option:**
+
+```
+fn get_element(index: usize, vec: &Vec) -> Option {
+ if index < vec.len() {
+ Some(vec[index])
+ } else {
+ None
+ }
+}
+```
+
+
+
+### 所有权与借用的生命周期
+
+Rust 使用生命周期来确保引用的有效性。生命周期标注用 **'a** 等来表示,但常见的情况下,编译器会自动推导。
+
+```
+fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
+ if x.len() > y.len() {
+ x
+ } else {
+ y
+ }
+}
+```
+
+
+
+### 重影(Shadowing)
+
+重影的概念与其他面向对象语言里的"重写"(Override)或"重载"(Overload)是不一样的。重影就是刚才讲述的所谓"重新绑定",之所以加引号就是为了在没有介绍这个概念的时候代替一下概念。
+
+重影就是指变量的名称可以被重新使用的机制:
+
+```
+fn main() {
+ let x = 5;
+ let x = x + 1;
+ let x = x * 2;
+ println!("The value of x is: {}", x);
+}
+```
+
+## 数据类型
+
+### 整数型(Integer)
+
+整数型简称整型,按照比特位长度和有无符号分为以下种类:
+
+| 位长度 | 有符号 | 无符号 |
+| :------ | :----- | :----- |
+| 8-bit | i8 | u8 |
+| 16-bit | i16 | u16 |
+| 32-bit | i32 | u32 |
+| 64-bit | i64 | u64 |
+| 128-bit | i128 | u128 |
+| arch | isize | usize |
+
+isize 和 usize 两种整数类型是用来衡量数据大小的,它们的位长度取决于所运行的目标平台,如果是 32 位架构的处理器将使用 32 位位长度整型。
+
+### 浮点数型(Floating-Point)
+
+Rust 与其它语言一样支持 32 位浮点数(f32)和 64 位浮点数(f64)。默认情况下,64.0 将表示 64 位浮点数,因为现代计算机处理器对两种浮点数计算的速度几乎相同,但 64 位浮点数精度更高。
+
+```
+fn main() {
+ let x = 2.0; *// f64*
+ let y: f32 = 3.0; *// f32*
+}
+```
+
+### 布尔型
+
+布尔型用 bool 表示,值只能为 true 或 false。
+
+### 字符型
+
+字符型用 char 表示。
+
+Rust的 char 类型大小为 4 个字节,代表 Unicode标量值,这意味着它可以支持中文,日文和韩文字符等非英文字符甚至表情符号和零宽度空格在 Rust 中都是有效的 char 值。
+
+## 注释
+
+```
+// 这是第一种注释方式
+
+/* 这是第二种注释方式 */
+
+/*
+ * 多行注释
+ * 多行注释
+ * 多行注释
+ */
+```
+
+## 函数
+
+```rust
+fn <函数名> ( <参数> ) <函数体>
+```
+
+### 函数参数
+
+Rust 中定义函数如果需要具备参数必须声明参数名称和类型:
+
+```
+fn main() {
+ another_function(5, 6);
+}
+
+fn another_function(x: i32, y: i32) {
+ println!("x 的值为 : {}", x);
+ println!("y 的值为 : {}", y);
+}
+```
+
+### 函数返回值
+
+在函数体中,随时都可以以 return 关键字结束函数运行并返回一个类型合适的值。这也是最接近大多数开发者经验的做法:
+
+```
+fn add(a: i32, b: i32) -> i32 {
+ return a + b;
+}
+```
+
+但是 Rust 不支持自动返回值类型判断!如果没有明确声明函数返回值的类型,函数将被认为是"纯过程",不允许产生返回值,return 后面不能有返回值表达式。这样做的目的是为了让公开的函数能够形成可见的公报。
+
+# Rust特色
+
+## 所有权
+
+Rust 中的所有权是独特的内存管理机制,核心概念包括所有权 (ownership)、借用 (borrowing) 和引用 (reference)。
+
+**所有权规则:**
+
+- Rust 中的每个值都有一个所有者。
+- 每个值在任意时刻只能有一个所有者。
+- 当所有者超出作用域时,值会被删除。
+
+```
+let s1 = String::from("hello");
+let s2 = s1; // s1 的所有权被转移给了 s2
+// println!("{}", s1); // 此处编译会报错,因为 s1 已不再拥有该值
+```
+
+**借用和引用:** 借用允许引用数据而不获取所有权,通过 **&** 符号实现。
+
+```
+fn main() {
+ let s = String::from("hello");
+ let len = calculate_length(&s); // 借用
+ println!("The length of '{}' is {}.", s, len);
+}
+
+fn calculate_length(s: &String) -> usize {
+ s.len()
+}
+```
+
+
+
+## 组织管理
+
+Rust 中有三个重要的组织概念:箱、包、模块。
+
+### 箱(Crate)
+
+"箱"是二进制程序文件或者库文件,存在于"包"中。
+
+"箱"是树状结构的,它的树根是编译器开始运行时编译的源文件所编译的程序。
+
+注意:"二进制程序文件"不一定是"二进制可执行文件",只能确定是是包含目标机器语言的文件,文件格式随编译环境的不同而不同。
+
+### 包(Package)
+
+当我们使用 Cargo 执行 new 命令创建 Rust 工程时,工程目录下会建立一个 Cargo.toml 文件。工程的实质就是一个包,包必须由一个 Cargo.toml 文件来管理,该文件描述了包的基本信息以及依赖项。
+
+一个包最多包含一个库"箱",可以包含任意数量的二进制"箱",但是至少包含一个"箱"(不管是库还是二进制"箱")。
+
+当使用 cargo new 命令创建完包之后,src 目录下会生成一个 main.rs 源文件,Cargo 默认这个文件为二进制箱的根,编译之后的二进制箱将与包名相同。
+
+### 模块(Module)
+
+对于一个软件工程来说,我们往往按照所使用的编程语言的组织规范来进行组织,组织模块的主要结构往往是树。Java 组织功能模块的主要单位是类,而 JavaScript 组织模块的主要方式是 function。
+
+这些先进的语言的组织单位可以层层包含,就像文件系统的目录结构一样。Rust 中的组织单位是模块(Module)。
+
+## 宏
+
+Rust 宏(Macros)是一种在编译时生成代码的强大工具,它允许你在编写代码时创建自定义语法扩展。
+
+宏(Macro)是一种在代码中进行元编程(Metaprogramming)的技术,它允许在编译时生成代码,宏可以帮助简化代码,提高代码的可读性和可维护性,同时允许开发者在编译时执行一些代码生成的操作。
+
+宏在 Rust 中有两种类型:声明式宏(Declarative Macros)和过程宏(Procedural Macros)。
+
+本文主要介绍声明式宏。
+
+### 宏的定义
+
+在 Rust 中,使用 **macro_rules!** 关键字来定义声明式宏。
+
+```
+macro_rules! my_macro {
+ // 模式匹配和展开
+ ($arg:expr) => {
+ // 生成的代码
+ // 使用 $arg 来代替匹配到的表达式
+ };
+}
+```
+
+声明式宏使用 **macro_rules!** 关键字进行定义,它们被称为 **"macro_rules"** 宏。这种宏的定义是基于模式匹配的,可以匹配代码的结构并根据匹配的模式生成相应的代码。这样的宏在不引入新的语法结构的情况下,可以用来简化一些通用的代码模式。
+
+注意:
+
+- **模式匹配:**宏通过模式匹配来匹配传递给宏的代码片段,模式是宏规则的左侧部分,用于捕获不同的代码结构。
+- **规则:**宏规则是一组由 **$** 引导的模式和相应的展开代码,规则由分号分隔。
+- **宏的展开:**当宏被调用时,匹配的模式将被替换为相应的展开代码,展开代码是宏规则的右侧部分。
+
+```
+*// 宏的定义*
+macro_rules! vec {
+ *// 基本情况,空的情况*
+ () => {
+ Vec::new()
+ };
+
+ *// 递归情况,带有元素的情况*
+ ($($element:expr),+ $(,)?) => {
+ {
+ let mut temp_vec = Vec::new();
+ $(
+ temp_vec.push($element);
+ )+
+ temp_vec
+ }
+ };
+}
+
+fn main() {
+ *// 调用宏*
+ let my_vec = vec![1, 2, 3];
+ println!("{:?}", my_vec); *// 输出: [1, 2, 3]*
+
+ let empty_vec = vec![];
+ println!("{:?}", empty_vec); *// 输出: []*
+}
+```
+
+在这个例子中,**vec!** 宏使用了模式匹配,以及 **$($element:expr),+ $(,)?)** 这样的语法来捕获传递给宏的元素,并用它们创建一个 Vec。
+
+注意,$**(,)?)** 用于处理末尾的逗号,使得在不同的使用情境下都能正常工作。
+
+### 过程宏(Procedural Macros)
+
+过程宏是一种更为灵活和强大的宏,允许在编译时通过自定义代码生成过程来操作抽象语法树(AST)。过程宏在功能上更接近于函数,但是它们在编写和使用上更加复杂。
+
+过程宏的类型:
+
+- **派生宏(Derive Macros)**:用于自动实现trait(比如`Copy`、`Debug`)的宏。
+- **属性宏(Attribute Macros)**:用于在声明上附加额外的元数据,如`#[derive(Debug)]`。
+
+过程宏的实现通常需要使用 proc_macro 库提供的功能,例如 TokenStream 和 TokenTree,以便更直接地操纵源代码。
+
+## 智能指针
+
+智能指针(Smart pointers)是一种在 Rust 中常见的数据结构,它们提供了额外的功能和安全性保证,以帮助管理内存和数据。
+
+在 Rust 中,智能指针是一种封装了对动态分配内存的所有权和生命周期管理的数据类型。
+
+智能指针通常封装了一个原始指针,并提供了一些额外的功能,比如引用计数、所有权转移、生命周期管理等。
+
+在 Rust 中,标准库提供了几种常见的智能指针类型,例如 Box、Rc、Arc 和 RefCell。
+
+**智能指针的使用场景:**
+
+- 当需要在堆上分配内存时,使用 `Box`。
+- 当需要多处共享所有权时,使用 `Rc` 或 `Arc`。
+- 当需要内部可变性时,使用 `RefCell`。
+- 当需要线程安全的共享所有权时,使用 `Arc`。
+- 当需要互斥访问数据时,使用 `Mutex`。
+- 当需要读取-写入访问数据时,使用 `RwLock`。
+- 当需要解决循环引用问题时,使用 `Weak`。
+
+## 错误处理
+
+Rust 有一套独特的处理异常情况的机制,它并不像其它语言中的 try 机制那样简单。
+
+首先,程序中一般会出现两种错误:可恢复错误和不可恢复错误。
+
+可恢复错误的典型案例是文件访问错误,如果访问一个文件失败,有可能是因为它正在被占用,是正常的,我们可以通过等待来解决。
+
+但还有一种错误是由编程中无法解决的逻辑错误导致的,例如访问数组末尾以外的位置。
+
+大多数编程语言不区分这两种错误,并用 Exception (异常)类来表示错误。在 Rust 中没有 Exception。
+
+对于可恢复错误用 Result 类来处理,对于不可恢复错误使用 panic! 宏来处理。
+
+
\ No newline at end of file
diff --git "a/source/_posts/2025\346\230\245\345\244\217\345\255\243\345\274\200\346\272\220\346\223\215\344\275\234\347\263\273\347\273\237\350\256\255\347\273\203\350\220\245\347\254\254\344\272\214\351\230\266\346\256\265\346\200\273\347\273\223\346\212\245\345\221\212-1430329301Lsj.md" "b/source/_posts/2025\346\230\245\345\244\217\345\255\243\345\274\200\346\272\220\346\223\215\344\275\234\347\263\273\347\273\237\350\256\255\347\273\203\350\220\245\347\254\254\344\272\214\351\230\266\346\256\265\346\200\273\347\273\223\346\212\245\345\221\212-1430329301Lsj.md"
new file mode 100644
index 00000000000..b0bcf0e7578
--- /dev/null
+++ "b/source/_posts/2025\346\230\245\345\244\217\345\255\243\345\274\200\346\272\220\346\223\215\344\275\234\347\263\273\347\273\237\350\256\255\347\273\203\350\220\245\347\254\254\344\272\214\351\230\266\346\256\265\346\200\273\347\273\223\346\212\245\345\221\212-1430329301Lsj.md"
@@ -0,0 +1,110 @@
+---
+title: <2025春夏季开源操作系统训练营第二阶段总结报告-1430329301Lsj>
+date: 2025-05-05 00:06:33
+tags:
+ - author:1430329301Lsj
+ - repo:https://github.com/LearningOS/2024a-rcore-1430329301Lsj
+---
+
+# rcore第二阶段学习心得
+
+以下是针对 rCore 操作系统各个技术方向的详细扩展叙述:
+
+### **1. 应用程序与基本执行环境**
+rCore 的应用程序执行环境构建在硬件抽象层(HAL)之上,其核心依赖 **RustSBI** 提供的引导和硬件初始化服务。RustSBI 在启动阶段完成以下关键任务:初始化 CPU 核心、配置物理内存保护区域(如设置 PMP 寄存器)、启用时钟中断和外部设备中断(如 UART 串口)。应用程序以 **静态链接的 ELF 格式** 加载到内存中,内核解析 ELF 文件头获取代码段(`.text`)、数据段(`.data`)和未初始化数据段(`.bss`)的虚拟地址,并为其分配物理页帧,建立虚拟地址到物理地址的映射。
+
+用户程序运行在 **RISC-V U 模式(用户态)**,通过 `ecall` 指令触发特权级切换到 S 模式(监管态)执行系统调用。内核在初始化用户环境时,需配置用户栈空间(如分配 8KB 栈内存)并设置 **Trap 上下文**,确保异常处理时能正确保存和恢复寄存器状态。系统调用参数传递遵循 RISC-V ABI 规范:系统调用号存入 `a7`,参数依次存入 `a0-a6`,返回值通过 `a0` 返回。例如,`sys_write` 调用时,用户程序将文件描述符、缓冲区地址和长度分别存入 `a0`、`a1`、`a2`,内核通过 `a0` 返回实际写入的字节数。
+
+为确保安全性,内核通过 **内存保护机制** 阻止用户程序直接访问内核空间。例如,用户程序若尝试访问高于 `0x80000000` 的内核地址,将触发页错误异常(`scause=13`),内核根据异常类型终止进程或按需分配物理页。
+
+---
+
+### **2. 批处理系统**
+批处理系统的核心设计是 **顺序执行多个用户程序**,每个程序独占 CPU 直至完成。内核在编译阶段将多个应用程序的 ELF 文件链接到内核镜像中,并在固定物理地址(如 `0x80400000`)依次加载。程序加载时,内核执行以下步骤:
+1. **内存清零**:清除前一程序残留的数据,防止信息泄漏。
+2. **页表隔离**:为每个程序创建独立的页表,仅映射其代码段、数据段和用户栈,避免越界访问。
+3. **上下文初始化**:设置程序的入口地址(ELF 的 `entry` 字段)和初始栈指针(`sp` 指向用户栈顶部)。
+
+当程序主动调用 `sys_exit` 或发生致命错误(如非法指令)时,内核通过 `TaskManager` 切换到下一程序。任务切换的关键在于保存当前程序的 **任务上下文(TaskContext)**,包括 `ra`(返回地址)、`sp`(栈指针)和 `s0-s11`(保留寄存器),并通过汇编函数 `__switch` 切换到目标程序的上下文。批处理系统需确保 **原子性切换**,即在切换过程中屏蔽中断(通过 `sstatus.SIE` 位),防止时钟中断导致状态不一致。
+
+---
+
+### **3. 多道程序与分时多任务**
+分时多任务通过 **时间片轮转算法** 实现 CPU 资源共享。内核为每个任务维护一个 **任务控制块(TaskControlBlock, TCB)**,包含以下元数据:
+- **任务状态**:运行(Running)、就绪(Ready)、阻塞(Blocked)。
+- **时间片计数器**:记录剩余时间片长度(如 10ms)。
+- **优先级**:用于调度决策(如实时任务优先级高于普通任务)。
+- **上下文信息**:包括寄存器快照和页表地址(`satp` 值)。
+
+时钟中断(通过 `sie.STIE` 使能)触发调度器执行以下流程:
+1. 递减当前任务的时间片计数器,若归零则标记为就绪状态。
+2. 从就绪队列中选择下一个任务(如按优先级或轮询策略)。
+3. 调用 `__switch` 切换上下文,并更新 `satp` 以切换地址空间。
+
+**协作式调度** 依赖任务主动调用 `sys_yield`,适用于 I/O 密集型任务减少切换开销;**抢占式调度** 则通过中断强制切换,适合 CPU 密集型任务提升吞吐量。内核需处理 **临界区竞争**,例如在修改任务队列时关闭中断,防止并发修改导致数据结构损坏。
+
+---
+
+### **4. 地址空间**
+地址空间通过 **Sv39 分页机制** 实现虚拟内存管理,支持 512GB 的虚拟地址范围。虚拟地址被划分为三级页表索引(VPN[2]、VPN[1]、VPN[0]),每级页表包含 512 个条目(8 字节/条目)。内核维护 **全局页帧分配器**,按需分配物理页帧并更新页表条目(PTE)的权限位(如 `R/W/X` 和 `U` 位)。
+
+用户程序访问虚拟地址时,若触发缺页异常(`scause=12/13/15`),内核执行以下处理:
+1. 检查访问地址是否合法(如位于用户代码段或堆栈范围内)。
+2. 分配物理页帧,建立虚拟地址到物理地址的映射。
+3. 刷新 TLB(通过 `sfence.vma` 指令),确保后续访问使用新页表。
+
+内核自身采用 **恒等映射**(虚拟地址等于物理地址),简化直接内存访问(如操作外设寄存器)。用户程序通过动态映射访问特定设备(如 MMIO 区域),需在内核中注册设备内存范围并配置页表权限(如设置为不可执行)。
+
+---
+
+### **5. 进程与进程管理**
+进程是资源分配的基本单位,其控制块(PCB)包含以下信息:
+- **进程标识符(PID)**:唯一标识进程的整数。
+- **地址空间**:指向页表的指针(`satp` 值)和内存映射信息。
+- **文件描述符表**:记录打开的文件、管道或设备。
+- **父子关系**:父进程 PID 和子进程链表。
+
+**进程创建** 通过 `fork` 系统调用实现,内核复制父进程的地址空间(写时复制优化)和文件描述符表,并为子进程分配新的 PID。`exec` 系统调用则替换当前进程的地址空间,加载新程序的代码和数据。
+
+**进程调度** 基于状态机模型:
+- **运行 → 就绪**:时间片耗尽或被高优先级任务抢占。
+- **运行 → 阻塞**:等待 I/O 完成或信号量资源。
+- **阻塞 → 就绪**:资源可用或事件触发。
+
+进程退出时,内核回收其物理内存、关闭打开的文件,并通过 `waitpid` 通知父进程回收终止状态。若父进程已终止,子进程由 **init 进程** 接管以避免僵尸进程。
+
+---
+
+### **6. 文件系统与重定向**
+rCore 的虚拟文件系统(VFS)抽象了 **文件、目录和设备** 的统一接口,支持以下操作:
+- **文件读写**:通过 `File trait` 的 `read` 和 `write` 方法实现,具体由设备驱动(如 UART)或块设备(如 virtio-blk)完成。
+- **目录管理**:维护目录项(dentry)链表,支持 `mkdir` 和 `readdir` 操作。
+
+**重定向** 通过复制文件描述符实现。例如,执行 `echo hello > output.txt` 时,shell 进程执行以下步骤:
+1. 打开 `output.txt` 并获取文件描述符 `fd`。
+2. 调用 `sys_dup` 复制 `fd` 到标准输出(`fd=1`)。
+3. 子进程继承修改后的文件描述符表,`sys_write` 输出到文件而非控制台。
+
+文件系统通过 **页缓存** 优化性能,将频繁访问的数据缓存在内存中,减少磁盘 I/O 操作。索引节点(inode)记录文件的元数据(如大小、权限和物理块地址),并通过 **日志机制** 确保崩溃一致性。
+
+---
+
+### **7. 进程间通信(IPC)**
+IPC 机制包括以下实现方式:
+- **共享内存**:内核分配物理页帧,并映射到多个进程的地址空间。进程通过信号量或自旋锁同步访问。
+- **管道**:基于环形缓冲区的 FIFO 队列,内核维护 `pipe` 结构体记录读写位置和等待队列。`sys_pipe` 创建管道后返回两个文件描述符(读端和写端),进程通过 `read` 和 `write` 系统调用传输数据。
+- **信号**:内核为每个进程维护信号处理函数表。当进程收到信号(如 `SIGKILL`)时,内核修改其 Trap 上下文,强制跳转到注册的处理函数。信号处理完成后,通过 `sigreturn` 系统调用恢复原执行流程。
+
+**消息队列** 是另一种 IPC 方式,内核维护消息缓冲区,进程通过 `msgsnd` 和 `msgrcv` 发送/接收结构化数据,支持阻塞和非阻塞模式。
+
+---
+
+### **8. 并发机制**
+内核并发通过以下机制管理:
+- **自旋锁(SpinLock)**:通过原子指令(如 `amoswap`)实现忙等待,适用于短期临界区(如修改任务队列)。使用前需关闭中断(`sstatus.SIE = 0`),防止死锁。
+- **互斥锁(Mutex)**:在锁竞争时让出 CPU,将当前任务加入阻塞队列,切换其他任务执行。解锁时唤醒等待任务。
+- **条件变量(Condvar)**:与互斥锁配合使用,通过 `wait` 释放锁并阻塞,`notify` 唤醒等待任务。适用于生产者-消费者模型。
+
+用户态线程(协程)通过 **异步运行时** 实现,内核提供轻量级上下文切换(如 `swapcontext`)和非阻塞 I/O 系统调用(如 `read_async`)。Rust 的 `async/await` 语法糖将协程编译为状态机,运行时调度器根据事件(如 I/O 完成)切换协程执行。
+
+**内存安全** 通过 Rust 的所有权系统和 `Send`/`Sync` trait 保障。`Send` 允许数据跨线程转移所有权,`Sync` 允许数据被多线程共享引用。编译器静态检查数据竞争,确保并发代码的安全性
\ No newline at end of file
+
+# Rust基础
+
+rust的编译与运行是分开的,是一种**预编译静态类型**语言。rust的源文件为`xx.rs`,最基础的编译为使用`rustc xx.rs`对代码进行编译。
+
+## 基础语法
+
+### Cargo
+
+Cargo是Rust的构建系统和包管理器:
+
+- 构建代码
+- 下载依赖库(代码所需的库叫做依赖)
+
+1.使用Cargo构建项目
+
+```
+$ cargo new the_project
+$ cd the_project
+```
+
+在Linux终端输入上面的代码创建rust项目后,会生成如下的文件与目录:
+
+
+
+
+
+变量
+
+首先必须说明,Rust 是强类型语言,但具有自动判断变量类型的能力。这很容易让人与弱类型语言产生混淆。
+
+默认情况下,Rust 中的变量是不可变的,除非使用 mut 关键字声明为可变变量。
+
+```
+let a = 123; // 不可变变量
+let mut b = 10; // 可变变量
+```
+
+如果要声明变量,需要使用 **let** 关键字。例如:
+
+```
+let a = 123;
+```
+
+变量和常量还是有区别的。在 Rust 中,以下程序是合法的:
+
+```
+let a = 123; // 可以编译,但可能有警告,因为该变量没有被使用
+let a = 456;
+```
+
+但是如果 a 是常量就不合法:
+
+```
+const a: i32 = 123;
+let a = 456;
+```
+
+### 控制流
+
+**if 表达式**
+
+实例:
+
+```
+let number = 7;
+if number < 5 {
+ println!("小于 5");
+} else {
+ println!("大于等于 5");
+}
+```
+
+**loop 循环:** loop 是 Rust 中的无限循环,可以使用 break 退出循环。
+
+实例
+
+```
+let mut counter = 0;
+loop {
+ counter += 1;
+ if counter == 10 {
+ break;
+ }
+}
+```
+
+**while 循环**
+
+```
+let mut number = 3;
+while number != 0 {
+ println!("{}!", number);
+ number -= 1;
+}
+```
+
+**for 循环**
+
+```
+for number in 1..4 {
+ println!("{}!", number);
+}
+```
+
+
+
+### 结构体 (Structs)
+
+结构体用于创建自定义类型,字段可以包含多种数据类型。
+
+实例
+
+```
+struct User {
+ username: String,
+ email: String,
+ sign_in_count: u64,
+ active: bool,
+}
+
+let user1 = User {
+ username: String::from("someusername"),
+ email: String::from("someone@example.com"),
+ sign_in_count: 1,
+ active: true,
+};
+```
+
+
+
+### 枚举 (Enums)
+
+枚举允许定义可能的几种数据类型中的一种。
+
+```
+enum IpAddrKind {
+ V4,
+ V6,
+}
+
+let four = IpAddrKind::V4;
+let six = IpAddrKind::V6;
+```
+
+
+
+### 模式匹配 (match)
+
+match 是 Rust 中强大的控制流工具,类似于 switch 语句。
+
+```
+enum Coin {
+ Penny,
+ Nickel,
+ Dime,
+ Quarter,
+}
+
+fn value_in_cents(coin: Coin) -> u8 {
+ match coin {
+ Coin::Penny => 1,
+ Coin::Nickel => 5,
+ Coin::Dime => 10,
+ Coin::Quarter => 25,
+ }
+}
+```
+
+
+
+### 错误处理
+
+
+
+Rust 有两种主要的错误处理方式:**Result** 和 **Option**。
+
+
+
+**Result:**
+
+```
+enum Result {
+ Ok(T),
+ Err(E),
+}
+
+fn divide(a: i32, b: i32) -> Result {
+ if b == 0 {
+ Err(String::from("Division by zero"))
+ } else {
+ Ok(a / b)
+ }
+}
+```
+
+**Option:**
+
+```
+fn get_element(index: usize, vec: &Vec) -> Option {
+ if index < vec.len() {
+ Some(vec[index])
+ } else {
+ None
+ }
+}
+```
+
+
+
+### 所有权与借用的生命周期
+
+Rust 使用生命周期来确保引用的有效性。生命周期标注用 **'a** 等来表示,但常见的情况下,编译器会自动推导。
+
+```
+fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
+ if x.len() > y.len() {
+ x
+ } else {
+ y
+ }
+}
+```
+
+
+
+### 重影(Shadowing)
+
+重影的概念与其他面向对象语言里的"重写"(Override)或"重载"(Overload)是不一样的。重影就是刚才讲述的所谓"重新绑定",之所以加引号就是为了在没有介绍这个概念的时候代替一下概念。
+
+重影就是指变量的名称可以被重新使用的机制:
+
+```
+fn main() {
+ let x = 5;
+ let x = x + 1;
+ let x = x * 2;
+ println!("The value of x is: {}", x);
+}
+```
+
+## 数据类型
+
+### 整数型(Integer)
+
+整数型简称整型,按照比特位长度和有无符号分为以下种类:
+
+| 位长度 | 有符号 | 无符号 |
+| :------ | :----- | :----- |
+| 8-bit | i8 | u8 |
+| 16-bit | i16 | u16 |
+| 32-bit | i32 | u32 |
+| 64-bit | i64 | u64 |
+| 128-bit | i128 | u128 |
+| arch | isize | usize |
+
+isize 和 usize 两种整数类型是用来衡量数据大小的,它们的位长度取决于所运行的目标平台,如果是 32 位架构的处理器将使用 32 位位长度整型。
+
+### 浮点数型(Floating-Point)
+
+Rust 与其它语言一样支持 32 位浮点数(f32)和 64 位浮点数(f64)。默认情况下,64.0 将表示 64 位浮点数,因为现代计算机处理器对两种浮点数计算的速度几乎相同,但 64 位浮点数精度更高。
+
+```
+fn main() {
+ let x = 2.0; *// f64*
+ let y: f32 = 3.0; *// f32*
+}
+```
+
+### 布尔型
+
+布尔型用 bool 表示,值只能为 true 或 false。
+
+### 字符型
+
+字符型用 char 表示。
+
+Rust的 char 类型大小为 4 个字节,代表 Unicode标量值,这意味着它可以支持中文,日文和韩文字符等非英文字符甚至表情符号和零宽度空格在 Rust 中都是有效的 char 值。
+
+## 注释
+
+```
+// 这是第一种注释方式
+
+/* 这是第二种注释方式 */
+
+/*
+ * 多行注释
+ * 多行注释
+ * 多行注释
+ */
+```
+
+## 函数
+
+```rust
+fn <函数名> ( <参数> ) <函数体>
+```
+
+### 函数参数
+
+Rust 中定义函数如果需要具备参数必须声明参数名称和类型:
+
+```
+fn main() {
+ another_function(5, 6);
+}
+
+fn another_function(x: i32, y: i32) {
+ println!("x 的值为 : {}", x);
+ println!("y 的值为 : {}", y);
+}
+```
+
+### 函数返回值
+
+在函数体中,随时都可以以 return 关键字结束函数运行并返回一个类型合适的值。这也是最接近大多数开发者经验的做法:
+
+```
+fn add(a: i32, b: i32) -> i32 {
+ return a + b;
+}
+```
+
+但是 Rust 不支持自动返回值类型判断!如果没有明确声明函数返回值的类型,函数将被认为是"纯过程",不允许产生返回值,return 后面不能有返回值表达式。这样做的目的是为了让公开的函数能够形成可见的公报。
+
+# Rust特色
+
+## 所有权
+
+Rust 中的所有权是独特的内存管理机制,核心概念包括所有权 (ownership)、借用 (borrowing) 和引用 (reference)。
+
+**所有权规则:**
+
+- Rust 中的每个值都有一个所有者。
+- 每个值在任意时刻只能有一个所有者。
+- 当所有者超出作用域时,值会被删除。
+
+```
+let s1 = String::from("hello");
+let s2 = s1; // s1 的所有权被转移给了 s2
+// println!("{}", s1); // 此处编译会报错,因为 s1 已不再拥有该值
+```
+
+**借用和引用:** 借用允许引用数据而不获取所有权,通过 **&** 符号实现。
+
+```
+fn main() {
+ let s = String::from("hello");
+ let len = calculate_length(&s); // 借用
+ println!("The length of '{}' is {}.", s, len);
+}
+
+fn calculate_length(s: &String) -> usize {
+ s.len()
+}
+```
+
+
+
+## 组织管理
+
+Rust 中有三个重要的组织概念:箱、包、模块。
+
+### 箱(Crate)
+
+"箱"是二进制程序文件或者库文件,存在于"包"中。
+
+"箱"是树状结构的,它的树根是编译器开始运行时编译的源文件所编译的程序。
+
+注意:"二进制程序文件"不一定是"二进制可执行文件",只能确定是是包含目标机器语言的文件,文件格式随编译环境的不同而不同。
+
+### 包(Package)
+
+当我们使用 Cargo 执行 new 命令创建 Rust 工程时,工程目录下会建立一个 Cargo.toml 文件。工程的实质就是一个包,包必须由一个 Cargo.toml 文件来管理,该文件描述了包的基本信息以及依赖项。
+
+一个包最多包含一个库"箱",可以包含任意数量的二进制"箱",但是至少包含一个"箱"(不管是库还是二进制"箱")。
+
+当使用 cargo new 命令创建完包之后,src 目录下会生成一个 main.rs 源文件,Cargo 默认这个文件为二进制箱的根,编译之后的二进制箱将与包名相同。
+
+### 模块(Module)
+
+对于一个软件工程来说,我们往往按照所使用的编程语言的组织规范来进行组织,组织模块的主要结构往往是树。Java 组织功能模块的主要单位是类,而 JavaScript 组织模块的主要方式是 function。
+
+这些先进的语言的组织单位可以层层包含,就像文件系统的目录结构一样。Rust 中的组织单位是模块(Module)。
+
+## 宏
+
+Rust 宏(Macros)是一种在编译时生成代码的强大工具,它允许你在编写代码时创建自定义语法扩展。
+
+宏(Macro)是一种在代码中进行元编程(Metaprogramming)的技术,它允许在编译时生成代码,宏可以帮助简化代码,提高代码的可读性和可维护性,同时允许开发者在编译时执行一些代码生成的操作。
+
+宏在 Rust 中有两种类型:声明式宏(Declarative Macros)和过程宏(Procedural Macros)。
+
+本文主要介绍声明式宏。
+
+### 宏的定义
+
+在 Rust 中,使用 **macro_rules!** 关键字来定义声明式宏。
+
+```
+macro_rules! my_macro {
+ // 模式匹配和展开
+ ($arg:expr) => {
+ // 生成的代码
+ // 使用 $arg 来代替匹配到的表达式
+ };
+}
+```
+
+声明式宏使用 **macro_rules!** 关键字进行定义,它们被称为 **"macro_rules"** 宏。这种宏的定义是基于模式匹配的,可以匹配代码的结构并根据匹配的模式生成相应的代码。这样的宏在不引入新的语法结构的情况下,可以用来简化一些通用的代码模式。
+
+注意:
+
+- **模式匹配:**宏通过模式匹配来匹配传递给宏的代码片段,模式是宏规则的左侧部分,用于捕获不同的代码结构。
+- **规则:**宏规则是一组由 **$** 引导的模式和相应的展开代码,规则由分号分隔。
+- **宏的展开:**当宏被调用时,匹配的模式将被替换为相应的展开代码,展开代码是宏规则的右侧部分。
+
+```
+*// 宏的定义*
+macro_rules! vec {
+ *// 基本情况,空的情况*
+ () => {
+ Vec::new()
+ };
+
+ *// 递归情况,带有元素的情况*
+ ($($element:expr),+ $(,)?) => {
+ {
+ let mut temp_vec = Vec::new();
+ $(
+ temp_vec.push($element);
+ )+
+ temp_vec
+ }
+ };
+}
+
+fn main() {
+ *// 调用宏*
+ let my_vec = vec![1, 2, 3];
+ println!("{:?}", my_vec); *// 输出: [1, 2, 3]*
+
+ let empty_vec = vec![];
+ println!("{:?}", empty_vec); *// 输出: []*
+}
+```
+
+在这个例子中,**vec!** 宏使用了模式匹配,以及 **$($element:expr),+ $(,)?)** 这样的语法来捕获传递给宏的元素,并用它们创建一个 Vec。
+
+注意,$**(,)?)** 用于处理末尾的逗号,使得在不同的使用情境下都能正常工作。
+
+### 过程宏(Procedural Macros)
+
+过程宏是一种更为灵活和强大的宏,允许在编译时通过自定义代码生成过程来操作抽象语法树(AST)。过程宏在功能上更接近于函数,但是它们在编写和使用上更加复杂。
+
+过程宏的类型:
+
+- **派生宏(Derive Macros)**:用于自动实现trait(比如`Copy`、`Debug`)的宏。
+- **属性宏(Attribute Macros)**:用于在声明上附加额外的元数据,如`#[derive(Debug)]`。
+
+过程宏的实现通常需要使用 proc_macro 库提供的功能,例如 TokenStream 和 TokenTree,以便更直接地操纵源代码。
+
+## 智能指针
+
+智能指针(Smart pointers)是一种在 Rust 中常见的数据结构,它们提供了额外的功能和安全性保证,以帮助管理内存和数据。
+
+在 Rust 中,智能指针是一种封装了对动态分配内存的所有权和生命周期管理的数据类型。
+
+智能指针通常封装了一个原始指针,并提供了一些额外的功能,比如引用计数、所有权转移、生命周期管理等。
+
+在 Rust 中,标准库提供了几种常见的智能指针类型,例如 Box、Rc、Arc 和 RefCell。
+
+**智能指针的使用场景:**
+
+- 当需要在堆上分配内存时,使用 `Box`。
+- 当需要多处共享所有权时,使用 `Rc` 或 `Arc`。
+- 当需要内部可变性时,使用 `RefCell`。
+- 当需要线程安全的共享所有权时,使用 `Arc`。
+- 当需要互斥访问数据时,使用 `Mutex`。
+- 当需要读取-写入访问数据时,使用 `RwLock`。
+- 当需要解决循环引用问题时,使用 `Weak`。
+
+## 错误处理
+
+Rust 有一套独特的处理异常情况的机制,它并不像其它语言中的 try 机制那样简单。
+
+首先,程序中一般会出现两种错误:可恢复错误和不可恢复错误。
+
+可恢复错误的典型案例是文件访问错误,如果访问一个文件失败,有可能是因为它正在被占用,是正常的,我们可以通过等待来解决。
+
+但还有一种错误是由编程中无法解决的逻辑错误导致的,例如访问数组末尾以外的位置。
+
+大多数编程语言不区分这两种错误,并用 Exception (异常)类来表示错误。在 Rust 中没有 Exception。
+
+对于可恢复错误用 Result 类来处理,对于不可恢复错误使用 panic! 宏来处理。
+
+
\ No newline at end of file
diff --git "a/source/_posts/2025\346\230\245\345\244\217\345\255\243\345\274\200\346\272\220\346\223\215\344\275\234\347\263\273\347\273\237\350\256\255\347\273\203\350\220\245\347\254\254\344\272\214\351\230\266\346\256\265\346\200\273\347\273\223\346\212\245\345\221\212-1430329301Lsj.md" "b/source/_posts/2025\346\230\245\345\244\217\345\255\243\345\274\200\346\272\220\346\223\215\344\275\234\347\263\273\347\273\237\350\256\255\347\273\203\350\220\245\347\254\254\344\272\214\351\230\266\346\256\265\346\200\273\347\273\223\346\212\245\345\221\212-1430329301Lsj.md"
new file mode 100644
index 00000000000..b0bcf0e7578
--- /dev/null
+++ "b/source/_posts/2025\346\230\245\345\244\217\345\255\243\345\274\200\346\272\220\346\223\215\344\275\234\347\263\273\347\273\237\350\256\255\347\273\203\350\220\245\347\254\254\344\272\214\351\230\266\346\256\265\346\200\273\347\273\223\346\212\245\345\221\212-1430329301Lsj.md"
@@ -0,0 +1,110 @@
+---
+title: <2025春夏季开源操作系统训练营第二阶段总结报告-1430329301Lsj>
+date: 2025-05-05 00:06:33
+tags:
+ - author:1430329301Lsj
+ - repo:https://github.com/LearningOS/2024a-rcore-1430329301Lsj
+---
+
+# rcore第二阶段学习心得
+
+以下是针对 rCore 操作系统各个技术方向的详细扩展叙述:
+
+### **1. 应用程序与基本执行环境**
+rCore 的应用程序执行环境构建在硬件抽象层(HAL)之上,其核心依赖 **RustSBI** 提供的引导和硬件初始化服务。RustSBI 在启动阶段完成以下关键任务:初始化 CPU 核心、配置物理内存保护区域(如设置 PMP 寄存器)、启用时钟中断和外部设备中断(如 UART 串口)。应用程序以 **静态链接的 ELF 格式** 加载到内存中,内核解析 ELF 文件头获取代码段(`.text`)、数据段(`.data`)和未初始化数据段(`.bss`)的虚拟地址,并为其分配物理页帧,建立虚拟地址到物理地址的映射。
+
+用户程序运行在 **RISC-V U 模式(用户态)**,通过 `ecall` 指令触发特权级切换到 S 模式(监管态)执行系统调用。内核在初始化用户环境时,需配置用户栈空间(如分配 8KB 栈内存)并设置 **Trap 上下文**,确保异常处理时能正确保存和恢复寄存器状态。系统调用参数传递遵循 RISC-V ABI 规范:系统调用号存入 `a7`,参数依次存入 `a0-a6`,返回值通过 `a0` 返回。例如,`sys_write` 调用时,用户程序将文件描述符、缓冲区地址和长度分别存入 `a0`、`a1`、`a2`,内核通过 `a0` 返回实际写入的字节数。
+
+为确保安全性,内核通过 **内存保护机制** 阻止用户程序直接访问内核空间。例如,用户程序若尝试访问高于 `0x80000000` 的内核地址,将触发页错误异常(`scause=13`),内核根据异常类型终止进程或按需分配物理页。
+
+---
+
+### **2. 批处理系统**
+批处理系统的核心设计是 **顺序执行多个用户程序**,每个程序独占 CPU 直至完成。内核在编译阶段将多个应用程序的 ELF 文件链接到内核镜像中,并在固定物理地址(如 `0x80400000`)依次加载。程序加载时,内核执行以下步骤:
+1. **内存清零**:清除前一程序残留的数据,防止信息泄漏。
+2. **页表隔离**:为每个程序创建独立的页表,仅映射其代码段、数据段和用户栈,避免越界访问。
+3. **上下文初始化**:设置程序的入口地址(ELF 的 `entry` 字段)和初始栈指针(`sp` 指向用户栈顶部)。
+
+当程序主动调用 `sys_exit` 或发生致命错误(如非法指令)时,内核通过 `TaskManager` 切换到下一程序。任务切换的关键在于保存当前程序的 **任务上下文(TaskContext)**,包括 `ra`(返回地址)、`sp`(栈指针)和 `s0-s11`(保留寄存器),并通过汇编函数 `__switch` 切换到目标程序的上下文。批处理系统需确保 **原子性切换**,即在切换过程中屏蔽中断(通过 `sstatus.SIE` 位),防止时钟中断导致状态不一致。
+
+---
+
+### **3. 多道程序与分时多任务**
+分时多任务通过 **时间片轮转算法** 实现 CPU 资源共享。内核为每个任务维护一个 **任务控制块(TaskControlBlock, TCB)**,包含以下元数据:
+- **任务状态**:运行(Running)、就绪(Ready)、阻塞(Blocked)。
+- **时间片计数器**:记录剩余时间片长度(如 10ms)。
+- **优先级**:用于调度决策(如实时任务优先级高于普通任务)。
+- **上下文信息**:包括寄存器快照和页表地址(`satp` 值)。
+
+时钟中断(通过 `sie.STIE` 使能)触发调度器执行以下流程:
+1. 递减当前任务的时间片计数器,若归零则标记为就绪状态。
+2. 从就绪队列中选择下一个任务(如按优先级或轮询策略)。
+3. 调用 `__switch` 切换上下文,并更新 `satp` 以切换地址空间。
+
+**协作式调度** 依赖任务主动调用 `sys_yield`,适用于 I/O 密集型任务减少切换开销;**抢占式调度** 则通过中断强制切换,适合 CPU 密集型任务提升吞吐量。内核需处理 **临界区竞争**,例如在修改任务队列时关闭中断,防止并发修改导致数据结构损坏。
+
+---
+
+### **4. 地址空间**
+地址空间通过 **Sv39 分页机制** 实现虚拟内存管理,支持 512GB 的虚拟地址范围。虚拟地址被划分为三级页表索引(VPN[2]、VPN[1]、VPN[0]),每级页表包含 512 个条目(8 字节/条目)。内核维护 **全局页帧分配器**,按需分配物理页帧并更新页表条目(PTE)的权限位(如 `R/W/X` 和 `U` 位)。
+
+用户程序访问虚拟地址时,若触发缺页异常(`scause=12/13/15`),内核执行以下处理:
+1. 检查访问地址是否合法(如位于用户代码段或堆栈范围内)。
+2. 分配物理页帧,建立虚拟地址到物理地址的映射。
+3. 刷新 TLB(通过 `sfence.vma` 指令),确保后续访问使用新页表。
+
+内核自身采用 **恒等映射**(虚拟地址等于物理地址),简化直接内存访问(如操作外设寄存器)。用户程序通过动态映射访问特定设备(如 MMIO 区域),需在内核中注册设备内存范围并配置页表权限(如设置为不可执行)。
+
+---
+
+### **5. 进程与进程管理**
+进程是资源分配的基本单位,其控制块(PCB)包含以下信息:
+- **进程标识符(PID)**:唯一标识进程的整数。
+- **地址空间**:指向页表的指针(`satp` 值)和内存映射信息。
+- **文件描述符表**:记录打开的文件、管道或设备。
+- **父子关系**:父进程 PID 和子进程链表。
+
+**进程创建** 通过 `fork` 系统调用实现,内核复制父进程的地址空间(写时复制优化)和文件描述符表,并为子进程分配新的 PID。`exec` 系统调用则替换当前进程的地址空间,加载新程序的代码和数据。
+
+**进程调度** 基于状态机模型:
+- **运行 → 就绪**:时间片耗尽或被高优先级任务抢占。
+- **运行 → 阻塞**:等待 I/O 完成或信号量资源。
+- **阻塞 → 就绪**:资源可用或事件触发。
+
+进程退出时,内核回收其物理内存、关闭打开的文件,并通过 `waitpid` 通知父进程回收终止状态。若父进程已终止,子进程由 **init 进程** 接管以避免僵尸进程。
+
+---
+
+### **6. 文件系统与重定向**
+rCore 的虚拟文件系统(VFS)抽象了 **文件、目录和设备** 的统一接口,支持以下操作:
+- **文件读写**:通过 `File trait` 的 `read` 和 `write` 方法实现,具体由设备驱动(如 UART)或块设备(如 virtio-blk)完成。
+- **目录管理**:维护目录项(dentry)链表,支持 `mkdir` 和 `readdir` 操作。
+
+**重定向** 通过复制文件描述符实现。例如,执行 `echo hello > output.txt` 时,shell 进程执行以下步骤:
+1. 打开 `output.txt` 并获取文件描述符 `fd`。
+2. 调用 `sys_dup` 复制 `fd` 到标准输出(`fd=1`)。
+3. 子进程继承修改后的文件描述符表,`sys_write` 输出到文件而非控制台。
+
+文件系统通过 **页缓存** 优化性能,将频繁访问的数据缓存在内存中,减少磁盘 I/O 操作。索引节点(inode)记录文件的元数据(如大小、权限和物理块地址),并通过 **日志机制** 确保崩溃一致性。
+
+---
+
+### **7. 进程间通信(IPC)**
+IPC 机制包括以下实现方式:
+- **共享内存**:内核分配物理页帧,并映射到多个进程的地址空间。进程通过信号量或自旋锁同步访问。
+- **管道**:基于环形缓冲区的 FIFO 队列,内核维护 `pipe` 结构体记录读写位置和等待队列。`sys_pipe` 创建管道后返回两个文件描述符(读端和写端),进程通过 `read` 和 `write` 系统调用传输数据。
+- **信号**:内核为每个进程维护信号处理函数表。当进程收到信号(如 `SIGKILL`)时,内核修改其 Trap 上下文,强制跳转到注册的处理函数。信号处理完成后,通过 `sigreturn` 系统调用恢复原执行流程。
+
+**消息队列** 是另一种 IPC 方式,内核维护消息缓冲区,进程通过 `msgsnd` 和 `msgrcv` 发送/接收结构化数据,支持阻塞和非阻塞模式。
+
+---
+
+### **8. 并发机制**
+内核并发通过以下机制管理:
+- **自旋锁(SpinLock)**:通过原子指令(如 `amoswap`)实现忙等待,适用于短期临界区(如修改任务队列)。使用前需关闭中断(`sstatus.SIE = 0`),防止死锁。
+- **互斥锁(Mutex)**:在锁竞争时让出 CPU,将当前任务加入阻塞队列,切换其他任务执行。解锁时唤醒等待任务。
+- **条件变量(Condvar)**:与互斥锁配合使用,通过 `wait` 释放锁并阻塞,`notify` 唤醒等待任务。适用于生产者-消费者模型。
+
+用户态线程(协程)通过 **异步运行时** 实现,内核提供轻量级上下文切换(如 `swapcontext`)和非阻塞 I/O 系统调用(如 `read_async`)。Rust 的 `async/await` 语法糖将协程编译为状态机,运行时调度器根据事件(如 I/O 完成)切换协程执行。
+
+**内存安全** 通过 Rust 的所有权系统和 `Send`/`Sync` trait 保障。`Send` 允许数据跨线程转移所有权,`Sync` 允许数据被多线程共享引用。编译器静态检查数据竞争,确保并发代码的安全性
\ No newline at end of file