|
| 1 | +--- |
| 2 | +title: "蚂蚁 Flink 实时计算编译任务 Koupleless 架构改造" |
| 3 | +authorlink: "https://github.com/sofastack" |
| 4 | +description: "这次 Flink 编译任务,是 Koupleless 在新的实时计算场景中落地的成功探索,以一种新的方式使用类加载框架。在一个大基座上面运行 Job 类模块,流量触发运行,请求完即执行卸载,轻量快捷。" |
| 5 | +categories: "SOFAStack" |
| 6 | +tags: ["SOFAStack"] |
| 7 | +date: 2025-04-08T15:00:00+08:00 |
| 8 | +cover: "https://img.alicdn.com/imgextra/i3/O1CN01viEWkx1Y4LE2XPv2x_!!6000000003005-0-tps-900-383.jpg" |
| 9 | +--- |
| 10 | + |
| 11 | +# 蚂蚁 Flink 实时计算编译任务 Koupleless 架构改造 |
| 12 | + |
| 13 | +张冯君(远远) |
| 14 | + |
| 15 | +Koupleless PMC |
| 16 | + |
| 17 | +蚂蚁集团技术工程师 |
| 18 | + |
| 19 | +就职于蚂蚁集团中间件团队,参与维护与建设蚂蚁 SOFAArk 和 Koupleless 开源项目、内部 SOFAServerless 产品的研发和实践。 |
| 20 | + |
| 21 | +本文 **3488** 字,预计阅读 **11** 分钟 |
| 22 | + |
| 23 | +--- |
| 24 | + |
| 25 | +## 业务背景 |
| 26 | + |
| 27 | +基于开源 Apache Flink 打造的蚂蚁流式计算引擎在蚂蚁有着广泛的应用,基本覆盖蚂蚁所有实时业务。蚂蚁 Flink 实时计算服务的提交服务主要负责提交、重启、重置、停止作业等一系列运维操作。服务端在处理 Flink 作业提交请求的时候,需要对用户提交上来的 Java 代码或者 SQL 代码进行编译,将用户代码翻译成 Flink 引擎可以识别的执行计划,这部分逻辑需要依赖 Flink 引擎层的代码,同时服务端需要支持 Flink 多版本的编译,为保证不同编译请求的正确性、隔离性和安全性,采用了目前业界常用的进程模型来处理编译请求——服务端每收到一次编译请求,都起一个子进程来执行编译逻辑。 |
| 28 | + |
| 29 | +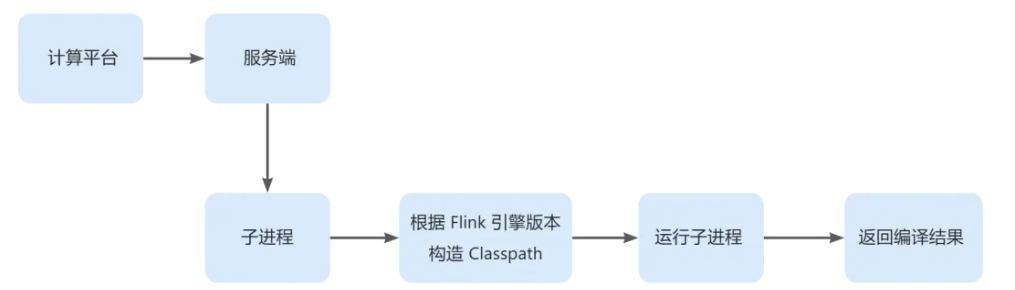 |
| 30 | + |
| 31 | +上图是一次编译请求的执行过程,这样的方式具有进程模型的固有缺陷: |
| 32 | + |
| 33 | +1. 响应速度慢:实际业务中大部分编译请求本身并不是很复杂的操作,但是启动子进程需要经历 VM 冷启动、字节码文件加载,以及 JIT 编译技术对解释执行的字节码进行优化,生成本地执行代码的过程还需加上 JVM 内部垃圾回收所耗费的时间。据统计实际平均请求耗时达到了 15s 及以上,严重影响用户提交任务的体验。 |
| 34 | +2. 资源消耗大:启动子进程需要更多内存,CPU 耗时更多,需要消耗大量的资源,导致服务端单机处理能力有限,系统稳定性差,极大影响整体的吞吐率。 |
| 35 | + |
| 36 | +实时计算团队对编译任务优化做了很多的探索,包括采用 CDS(*Class Data Sharing*)进程热启动、复用引擎类加载器的线程模型等方式,但都遇到了不同的资源消耗加大,资源不安全等问题,在生产上基本不可用,无法全量推开。 |
| 37 | + |
| 38 | +在进一步探索中,实时计算团队尝试将进程模型改造为线程模型,但面临核心问题:线程执行意味着共享 JVM,在需要支持不同 Flink 引擎版本、不同业务自定义 UDF 包的场景下,需要一个机制来为不同编译任务实现版本隔离、包隔离。并确保在运行时不同的编译任务互相不影响且结果正确。 |
| 39 | + |
| 40 | +Koupleless 开源以来,除了致力于多应用合并部署节省资源外,一直在进行轻量化模块研发的探索。其特性高度契合 Flink 编译场景: |
| 41 | + |
| 42 | +* 轻量化:适合依赖简单、逻辑简单,甚至是代码片段的应用,Flink 编译任务通常轻量级,流量触发运行,运行完即可结束。 |
| 43 | +* 原生隔离能力:Koupleless 进行合并部署的底层原理就是通过类加载隔离来实现多应用的代码隔离,这块的类隔离框架正好符合多 Flink 编译任务进行类隔离的诉求。 |
| 44 | + |
| 45 | +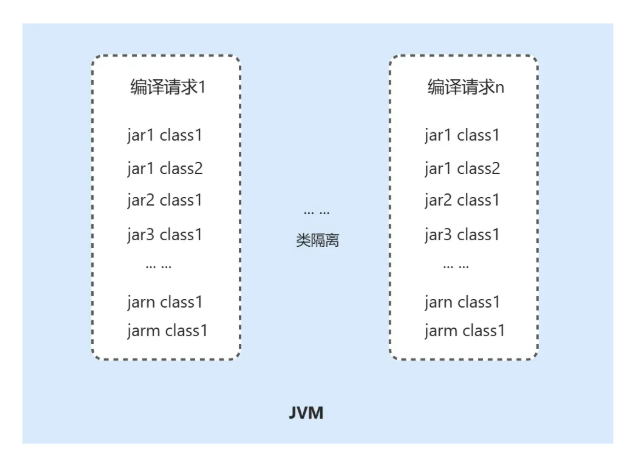 |
| 46 | + |
| 47 | +## 整体方案 |
| 48 | + |
| 49 | +读到这里默认大家对 Koupleless 类隔离框架有一定的了解(*不了解的话推荐阅读:[https://github.com/sofastack/sofa-ark](https://github.com/sofastack/sofa-ark)*,就不再赘述框架细节,直接分享在原类加载机制下,针对当前编译任务场景做了哪些架构升级的改造和技术特性的支持。 |
| 50 | + |
| 51 | +### 业务改造 |
| 52 | + |
| 53 | +Flink 提交作业的核心在于编译用户提交过来的代码,这个过程会解析提交请求,获取提交请求依赖的 Flink 引擎包,Connector/Backend 插件包,以及用户上传的 UDF 包,然后定义环境变量和 Classpath,启动子进程来编译用户代码,获取执行计划。Flink 编译任务改造前的进程模型流程: |
| 54 | + |
| 55 | +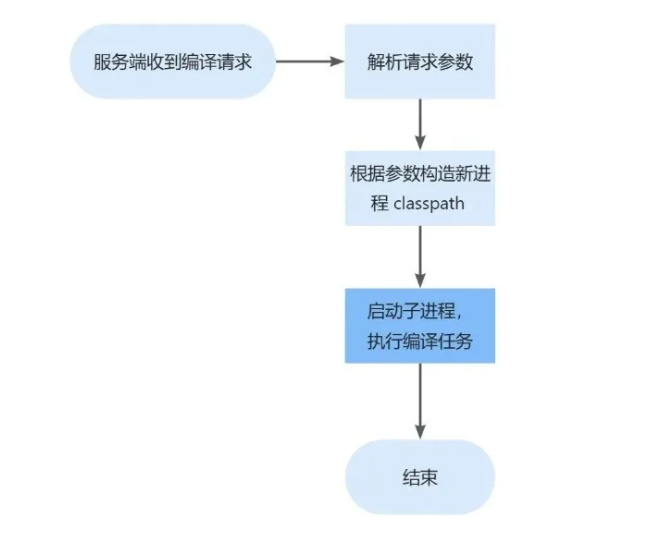 |
| 56 | + |
| 57 | +编译进程的核心在于正确的构造 Classpath,在进程模型下,很容易做到,而在线程模型下,则是需要保证 ClassLoader 的正确性,需要满足以下需求: |
| 58 | + |
| 59 | +1. 编译结果准确性:每次编译线程都应该获取正确完整的 ClassLoader,主要包括 Flink Lib 包的 ClassLoader,Flink Connector/Backend 插件的 ClassLoader,用户 UDF 的 ClassLoader。 |
| 60 | +2. 资源高效复用:编译请求需要尽可能复用通用 Flink Lib 包,Flink Connector/Backend 包等,以期达到最优的性能。 |
| 61 | +3. 多版本类隔离:不同的编译请求会依赖不同版本的引擎,需要对不同版本的 Flink 包进行类隔离,使得多个编译请求同时运行时互不影响。 |
| 62 | + |
| 63 | +基于以上诉求,我们设计出了一套**类加载的框架**: |
| 64 | + |
| 65 | +* 针对 Flink Lib,Flink Connector/Backend 的高频通用的 ClassLoader 会直接构建出来,常驻在内存中,可直接复用,生命周期和服务端进程一致; |
| 66 | +* 针对用户 UDF 代码,构建请求级别的 ClassLoader,生命周期和请求一致。 |
| 67 | + |
| 68 | +执行流程如下: |
| 69 | + |
| 70 | +1. 在接收到编译请求的时候,复用对应的 flink-lib,flink-connector/backend ClassLoader |
| 71 | +2. 基于请求依赖的 UDF 包,构建请求级别的 ClassLoader |
| 72 | +3. 启动线程执行编译逻辑,并且回收 UDF ClassLoader |
| 73 | + |
| 74 | +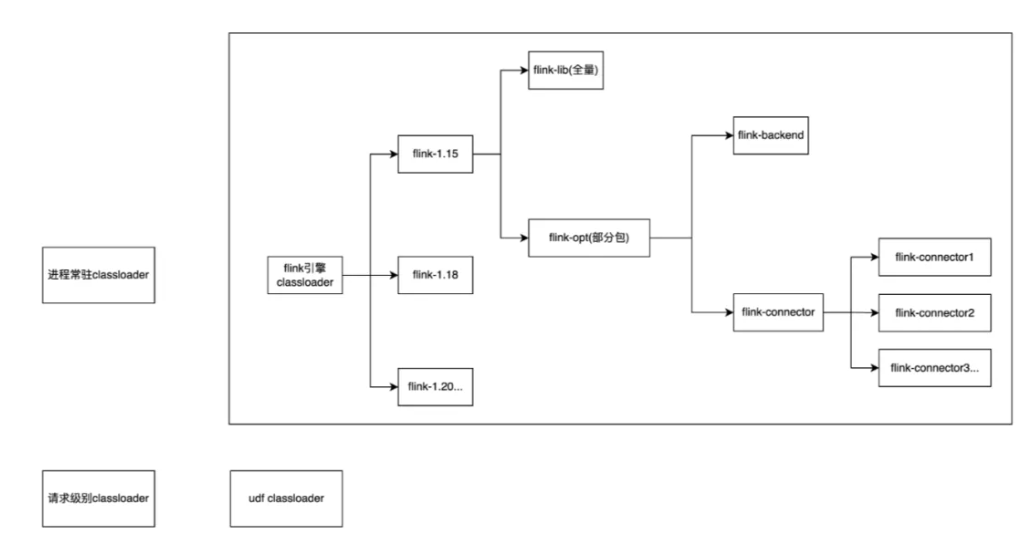 |
| 75 | + |
| 76 | +Flink 编译任务进行 Koupleless 改造后的线程模型: |
| 77 | + |
| 78 | +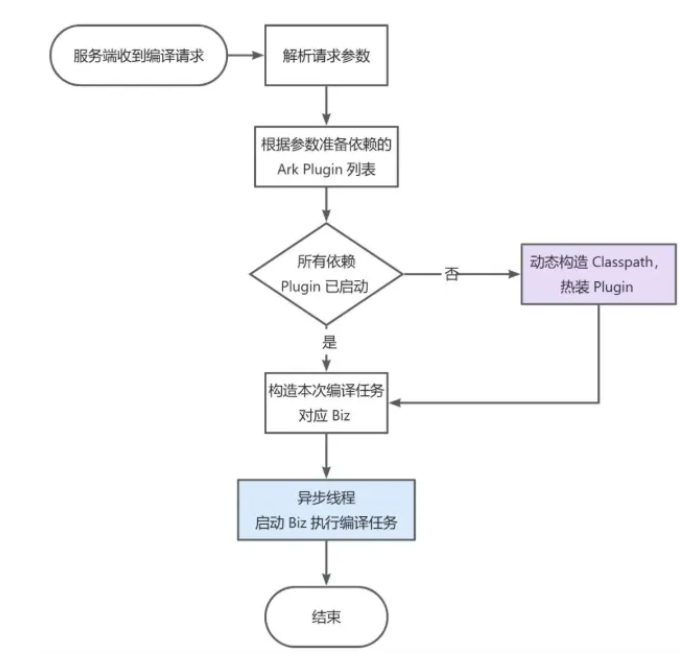 |
| 79 | + |
| 80 | +1. 服务端收到编译请求 |
| 81 | +2. 解析请求参数,得到依赖的 flink-lib 包版本、flink-opt 包版本、UDF 业务自定义包信息等 |
| 82 | +3. 根据参数准备本次编译任务需要的所有 Ark Plugin |
| 83 | +4. 若发现存在 Plugin 未安装,动态构造 Classpath 并启动 |
| 84 | +5. 所有 Plugin 准备完毕后,构造本地编译任务对应的 Biz |
| 85 | +6. 异步线程启动 Biz 执行编译任务 |
| 86 | + |
| 87 | +同时,为了尽可能复用和降低 Plugin、Biz 构建的开销,我们设计整个模式支持运行时动态构建 Plugin、Biz 及其 Classpath,而无需提前准备众多 Plugin FatJar,同时支持运行时动态按需加载 Plugin。 |
| 88 | + |
| 89 | + |
| 90 | + |
| 91 | +1. 引擎无关的能力放在 Container 层,也称基座层,实际上就是服务端进程原有的能力; |
| 92 | +2. 引擎相关的能力放在 Plugin 层,将引擎相关的包各自构造独立的 ClassLoader,抽象成 Plugin,实际上就是把上文所说的 flink-lib,flink-connector/backend 抽象成了 Ark Plugin 组件,编译请求来了之后会加载对应的 Plugin,并根据指定顺序来加载类,这一层可以实现 ClassLoader 的复用,注意这一层需要将每个版本的引擎的每个包都抽象成 Plugin,这样可以保证不同的编译请求可以复用正确的 Plugin; |
| 93 | +3. 具体的编译请求由 Biz 层处理,这里的 Biz 层实际上就是针对每一个编译请求,会启动一个新的线程,从 Plugin 层加载需要的 ClassLoader,并构造 Biz ClassLoader 来加载一些特定类,最后使用线程模型来启动编译请求对应的 main 函数,实现线程化编译。 |
| 94 | + |
| 95 | +在整个三层结构中,基座层几乎没有特殊的改造,核心设计优化聚焦于 Plugin 层与 Biz 层,设计了更灵活的 Plugin、Biz 构造方式。 |
| 96 | + |
| 97 | +由于无法预先得知编译请求需要的 Flink 引擎版本列表,需要提前在服务器中准备好所有版本的 Plugin 供请求来时直接使用,我们支持按需动态构建运行时 Plugin 并动态装载到 JVM 中,因此,我们无需为 Flink 各个 SDK 的所有版本提前构建完整的 Plugin FatJar,同时无需提前做所有版本 Plugin 的预热,只需要在请求到来时,检查所需 Plugin 是否已装载,若没有,按需装载即可。 |
| 98 | + |
| 99 | +为了稳定性和该模型的持续运行,我们建设了配套的线程回收逻辑和自愈流程。因为本方案使用了线程模型,不可避免的会存在少量资源泄漏问题,我们设计了一套线程回收逻辑: |
| 100 | + |
| 101 | +* 定时扫描内存中处于空闲状态的线程池; |
| 102 | +* 判断线程池对应的 ClassLoader,若线程池对应的 ClassLoader 是 Biz CalssLoader 或 Plugin CalssLoader,那么该线程池是编译期间构造的; |
| 103 | +* 此时追踪到对应的编译请求,若请求已经失效,直接强制回收线程池。 |
| 104 | + |
| 105 | +此外,为了解决编译线程缓慢的 Meta 增长问题,我们建设了 Meta 检测,超过一定阈值时触发 JVM 重启等自愈流程。 |
| 106 | + |
| 107 | +### 技术特性 |
| 108 | + |
| 109 | +**阶段一:动态装配 Plugin 及其 Classpath** |
| 110 | + |
| 111 | +在 Flink 编译任务中,业务依赖很复杂,不同编译请求可能依赖不同的 flink-lib、flink-opt、UDF 包等,为了编译的正确性需要类隔离,同时因 Flink 引擎包是所有编译任务都需要依赖的,因此对通用的包需要能共享且最大程度提高共享,降低隔离重复加载成本。在 Koupleless 类加载模型下,天然针对这一特性设计了 Plugin、Biz 的加载方案。 |
| 112 | + |
| 113 | +每个 Flink、UDF 包都对应一个 Plugin,为了不在服务启动时就加载全量 Plugin,我们支持了动态装配 Plugin 的特性(*目前暂无需要动态卸载的场景*),根据请求按需加载 Plugin。 |
| 114 | + |
| 115 | +同时由于版本很多,为每个包的每个版本都提前构建 Plugin FatJar 也是很大的工程,比如要 flink-version1-plugin、flink-version2-plugin、flink-opt1-plugin、flink-opt2-plugin 等等,我们更轻量化地支持了在运行时根据 Plugin 依赖的 Jar List 动态构造 Classpath 的能力。 |
| 116 | + |
| 117 | +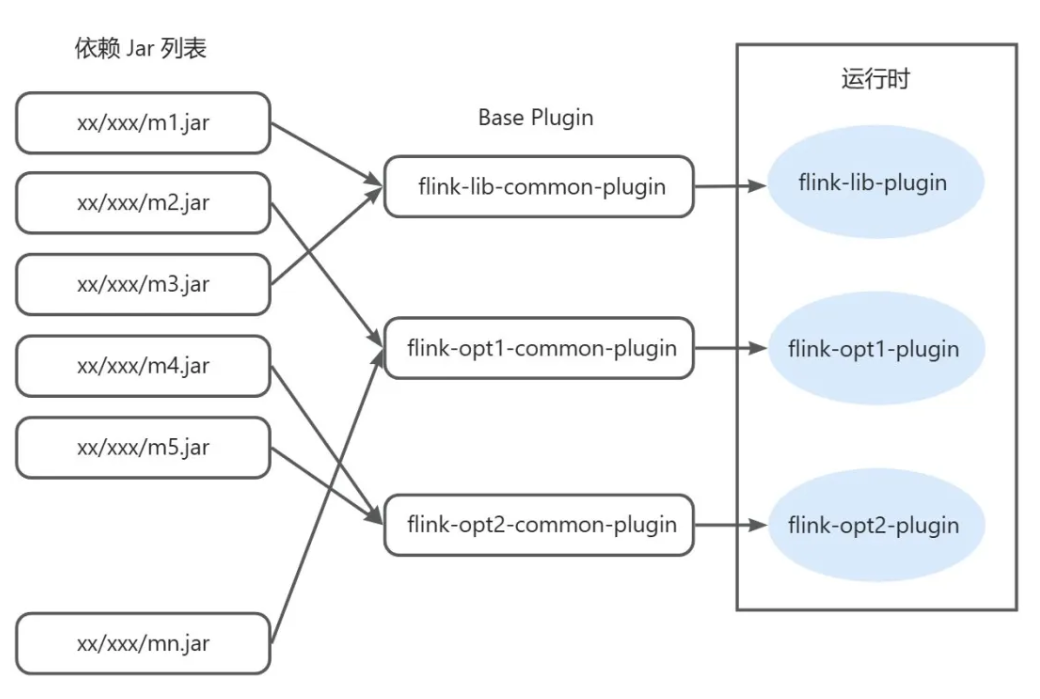 |
| 118 | + |
| 119 | +如 flink-version1-plugin classpath = common-plugin url + jar1 url + jar2 url + ... + jarN url 动态构成。这样的模式只需要提前构建最简单的 common-plugin 供所有 Flink、Opt Plugin 复用即可。 |
| 120 | + |
| 121 | +**阶段二:Biz 运行时只对依赖的 Plugin 可见** |
| 122 | + |
| 123 | +之前 Ark Container 中的所有 Plugin 对所有 Biz 可见,Biz 进行类加载时,会检索所有的运行时 Plugin Export 列表,查找 export 了当前 class/resource 的 Plugin 进行委托加载。实际 Flink 编译任务中,每次编译请求对应创建一个新 Biz,每次编译请求只会依赖部分指定版本的 Flink、Opt 包,即只依赖部分 Plugin,Biz 运行时进行类加载时只在这些依赖的 Plugin 中查找 Export 信息并进行委托加载。 |
| 124 | + |
| 125 | +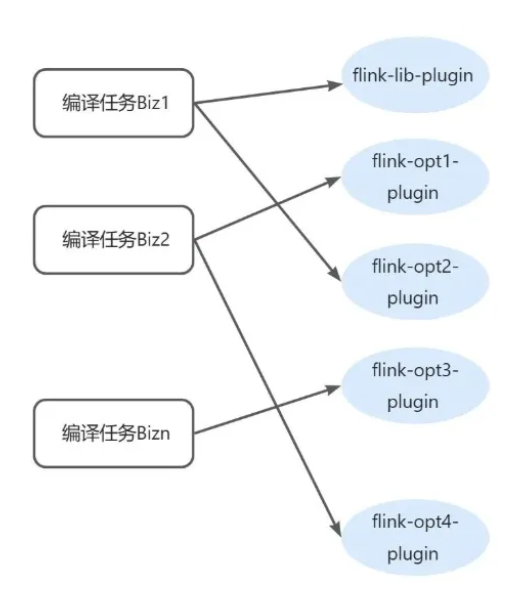 |
| 126 | + |
| 127 | +比如编译任务 Biz1 在进行类加载时,只从依赖的 flink-lib-plugin、flink-opt2-plugin 中委托加载,其余 Plugin 对该编译任务 Biz1 完全不可见。 |
| 128 | + |
| 129 | +### 结果 |
| 130 | + |
| 131 | +随机抽取一部分作业,直接测试进程模型和线程模型编译结果的一致性,直接比对生成的执行计划内容。 |
| 132 | + |
| 133 | + |
| 134 | + |
| 135 | +随机抽取一部分包含 UDF(*用户自定义依赖*)和不包含 UDF 的作业,直接使用线程模型编译,观察成功率,耗时,机器负载等指标。 |
| 136 | + |
| 137 | +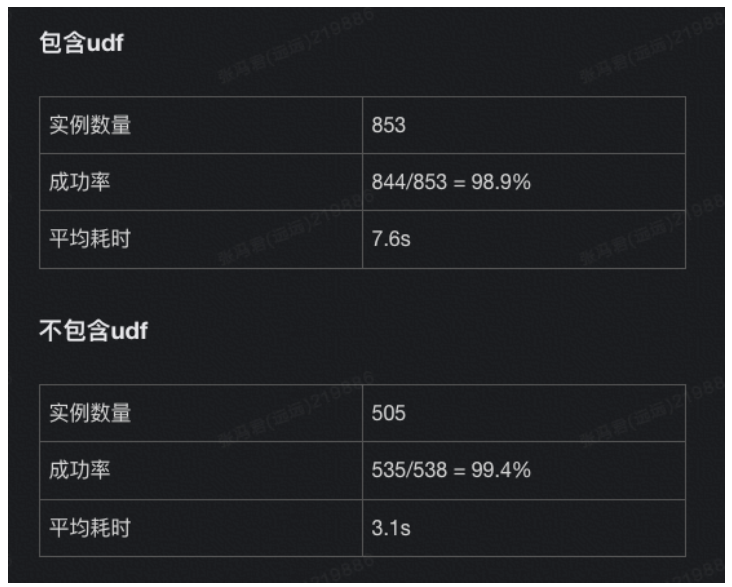 |
| 138 | + |
| 139 | +整体来说,Flink 编译任务使用线程模型编译从功能上来说,可以正确替代原来进程模型的能力,编译的结果一致,编译出来的执行计划一致。编译任务执行耗时从原来的平均 10s 多降低到 5.6s,平均降低 50%,吞吐从 5~10/min 个编译任务提升到 50/min 及以上,提升 5 倍及以上。 |
| 140 | + |
| 141 | +## 总结 |
| 142 | + |
| 143 | +这次 Flink 编译任务,是 Koupleless 在新的实时计算场景中落地的成功探索,以一种新的方式使用类加载框架。在一个大基座上面运行 Job 类模块,流量触发运行,请求完即执行卸载,轻量快捷。欢迎大家碰到相关场景时使用 Koupleless,一起探索 Koupleless 更多的使用场景吧~ |
| 144 | + |
| 145 | + |
0 commit comments