- 1.FP32,FP16以及Int8的区别?
- 2.GPU显存占用和GPU利用率的定义
- 3.神经网络的显存占用分析
- 4.算法模型部署逻辑?
- 5.影响模型inference速度的因素?
- 6.减小模型内存占用有哪些办法?
- 7.有哪些经典的轻量化网络?
- 8.AI模型的参数量如何计算?
- 9.模型FLOPs怎么算?
- 10.什么是异构计算?
- 11.端侧静态多Batch和动态多Batch的区别
- 12.bfloat16精度和float16精度的区别?
- 13.AI推理系统介绍
- 14.在AI领域中模型一共有多少种主流部署形式?
- 15.Jenkins的介绍
- 16.介绍一下模型性能优化与模型部署之间的关系
- 17.介绍一下MoE技术
- 18.什么是GPU内存带宽?
- 19.如何将AI模型缓存到内存中,这么做有什么好处?
- 20.什么是AI领域的延迟和吞吐量?
- 21.英伟达显卡中Volatile-GPU-Util代表什么含义?
- 22.有哪些设计高效CNN架构的方法与经验?
- 23.英伟达的GPU架构是什么样的?
- 24.轻量级模型部署经验分享
- 25.Int8和FP8有哪些区别?
- 26.AI模型在端侧部署时有哪些维度需要考虑?
- 27.AI模型的轻量化效果评价指标有哪些?
- 28.介绍一下NF4精度的特点
- 29.大模型常见模型文件格式简介
- 30.safetensors模型文件的使用
- 31.GGUF模型文件的组成
- 32.diffusion和diffusers模型的相互转换
常规精度一般使用FP32(32位浮点,单精度)占用4个字节,共32位;低精度则使用FP16(半精度浮点)占用2个字节,共16位,INT8(8位的定点整数)八位整型,占用1个字节等。
混合精度(Mixed precision)指使用FP32和FP16。 使用FP16 可以减少模型一半内存,但有些参数必须采用FP32才能保持模型性能。
虽然INT8精度低,但是数据量小、能耗低,计算速度相对更快,更符合端侧运算的特点。
不同精度进行量化的归程中,量化误差不可避免。
在模型训练阶段,梯度的更新往往是很微小的,需要相对较高的精度,一般要用到FP32以上。在inference的阶段,精度要求没有那么高,一般F16或者INT8就足够了,精度影响不会很大。同时低精度的模型占用空间更小了,有利于部署在端侧设备中。
GPU在训练时有两个重要指标可以查看,即显存占用和GPU利用率。
显存指的是GPU的空间,即内存大小。显存可以用来放模型,数据等。
GPU 利用率主要的统计方式为:在采样周期内,GPU 上有 kernel 执行的时间百分比。可以简单理解为GPU计算单元的使用率。
Float32 是在深度学习中最常用的数值类型,称为单精度浮点数,每一个单精度浮点数占用4Byte的显存。
在整个神经网络训练周期中,在GPU上的显存占用主要包括:数据,模型参数,模型输出等。
数据侧:举个🌰,一个323128128的四维矩阵,其占用的显存 = 323128128*4 /1000 / 1000 = 6.3M
模型侧:占用显存的层包括卷积层,全连接层,BN层,梯度,优化器的参数等。
输出侧:占用的显存包括网络每一层计算出来的feature map以及对应的梯度等。
我在之前专门沉淀了一篇关于算法模型部署逻辑的文章,大家可以直接进行阅读取用:
- FLOPs(模型总的加乘运算)
- MAC(内存访问成本)
- 并行度(模型inference时操作的并行度越高,速度越快)
- 计算平台(GPU,AI协处理器,CPU等)
- 模型剪枝
- 模型蒸馏
- 模型量化
- 模型结构调整
- SqueezeNet
- MobileNet
- ShuffleNet
- Xception
- GhostNet
不管是AIGC、传统深度学习还是自动驾驶领域,计算 AI 模型的参数量(参数个数)是评估模型复杂度的常用指标。参数量指的是 模型中所有可学习参数(权重和偏置) 的数量。Rocky总结了通用AI模型参数量计算方法,在不同类型的神经网络中,计算参数量的方法略有不同。下面是详细的计算方法:
不同类型神经网络参数量的计算方法:
- 全连接层:输入特征数 × 输出特征数 + 输出特征数。
- 卷积层:卷积核高度 × 卷积核宽度 × 输入通道数 × 输出通道数 + 输出通道数。
- 循环神经网络:需要考虑输入、隐藏单元和门结构。
- Transformer 模型:关注多头自注意力机制和前馈网络。
- 权重参数:每一层的神经元与下一层的神经元之间的连接权重。
- 偏置参数:每个神经元(节点)对应的偏置值(bias)。
一般公式为:
其中:
- 输入特征数:上一层的输出通道或神经元数。
- 输出特征数:当前层的通道或神经元数。
- ( + \text{输出特征数} ):是因为每个输出单元都有一个对应的偏置参数。
全连接层的参数量由输入和输出的神经元数决定。
公式:
示例:假设输入特征为 512,输出特征为 256。
卷积层的参数量取决于卷积核的大小、输入通道数和输出通道数。
公式:
-
卷积核高度 × 卷积核宽度:卷积核的尺寸,例如
$3 \times 3$ 。 - 输入通道数:前一层的特征图通道数。
- 输出通道数:当前层的特征图通道数。
- +1:表示偏置参数。
示例:输入通道数为 3,输出通道数为 64,卷积核大小为
循环神经网络的参数量与输入特征、隐藏单元数和门控结构有关。
-
RNN:
$$ \text{参数量} = \text{输入特征数} \times \text{隐藏单元数} + \text{隐藏单元数} \times \text{隐藏单元数} + \text{隐藏单元数} $$
-
LSTM/GRU(由于有多个门结构):
$$ \text{参数量} = 4 \times \left( \text{输入特征数} \times \text{隐藏单元数} + \text{隐藏单元数} \times \text{隐藏单元数} + \text{隐藏单元数} \right) $$
示例:输入特征数为 128,隐藏单元数为 256。
-
对于 RNN:
$$ \text{参数量} = 128 \times 256 + 256 \times 256 + 256 = 98304 + 65536 + 256 = 164096 $$
-
对于 LSTM:
$$ \text{参数量} = 4 \times (128 \times 256 + 256 \times 256 + 256) = 4 \times 164096 = 656384 $$
Transformer 由多个自注意力机制(Multi-Head Attention) 和 前馈网络(Feedforward Layer) 组成。
-
多头自注意力机制: 每个注意力头有 ( Q, K, V ) 三个矩阵,参数量为:
$$ \text{参数量} = 3 \times (\text{输入特征数} \times \text{注意力头的特征数}) \times \text{注意力头数} $$
-
前馈网络: 包含两层全连接层,参数量为:
$$ \text{参数量} = 2 \times (\text{输入特征数} \times \text{隐藏特征数} + \text{隐藏特征数}) $$
在实际项目中,可以使用代码自动计算模型的参数量。以下是 PyTorch 的示例:
import torch
import torch.nn as nn
# 定义一个简单模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3)
self.fc1 = nn.Linear(16 * 6 * 6, 120)
self.fc2 = nn.Linear(120, 10)
def forward(self, x):
x = self.conv1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = self.fc2(x)
return x
model = SimpleCNN()
# 计算参数量
total_params = sum(p.numel() for p in model.parameters())
print(f"模型的参数量: {total_params}")输出:
模型的参数量: 14366
同样,我们假设卷积核的尺寸是$K\times K$,有$C$个特征图作为输入,每个输出的特征图大小为$H \times W$,输出为$M$个特征图。
由于在模型中卷积一般占计算量的比重是最高的,我们依旧以卷积的计算量为例进行分析:
FLOPS(全大写):是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
FLOPs(s小写):是floating point operations的缩写(s表示复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
针对模型的计算量应该指的是FLOPs。
在上述情况下,卷积神经网络一次前向传播需要的乘法运算次数为:
同时,所要进行的加法计算次数分为考虑偏置和不考虑偏置:
(1)考虑偏置的情况:
为了得到输出的特征图的一个未知的像素,我们需要进行
所以总的加法计算量如下:
所以总的卷积运算计算量(乘法+加法):
(2)不考虑偏置的情况:
总的卷积计算量:
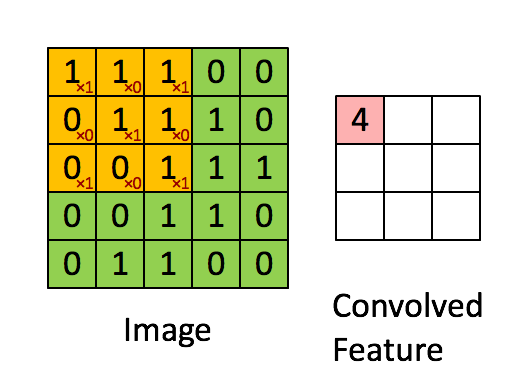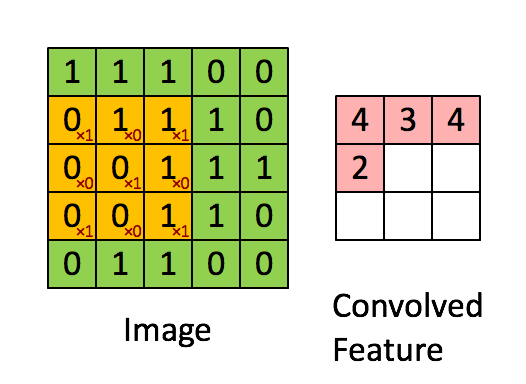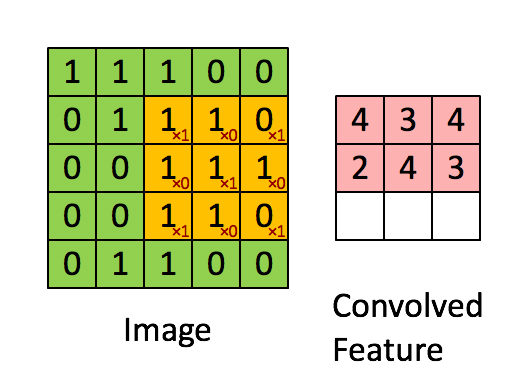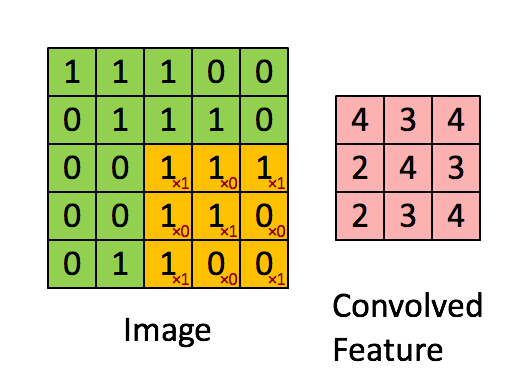
首先,异构现象是指不同计算平台之间,由于硬件结构(包括计算核心和内存),指令集和底层软件实现等方面的不同而有着不同的特性。
异构计算是指联合使用两个或者多个不同的计算平台,并进行协同运算。比如CPU和GPU的异构计算,TPU和GPU的异构计算以及TPU/GPU/CPU的异构计算等等。
当设置静态多Batch后,如Batch=6,那么之后不管是输入2Batch还是4Batch,都会按照6Batch的预设开始申请资源。
而动态多Batch不用预设Batch数,会根据实际场景中的真实输入Batch数来优化资源的申请,提高端侧实际效率。
由于动态多Batch的高性能,通常Inference耗时和内存占用会比静态多Batch时要大。
定义与结构: BFLOAT16是一种16位宽的浮点数格式,由Google针对Tensor Processing Units (TPUs)开发,特别适用于AI算法应用。它的结构如下:
- 1位符号位
- 8位指数
- 7位尾数
这种格式与标准的32位浮点数(FP32)共享相同的指数范围,但尾数精度较低。这意味着BFLOAT16在表示大范围数值时与FP32相近,但在表示精度上有所折衷。
优点:
- 较大的动态范围:与Float16相比,BFLOAT16能够表示更大范围的数值,这归功于它更大的指数范围。这对于深度学习中的梯度和归一化运算非常重要,因为这些操作可能涉及广泛的数值范围。
- 与FP32兼容性好:由于指数位与FP32相同,BFLOAT16可以无损地转换为FP32,这简化了混合精度训练的实现,同时减少了转换过程中的精度损失。
缺点:
- 较低的数值精度:因为尾数位只有7位,相比于Float16的10位尾数,BFLOAT16在表示精确数值时的能力较弱。
定义与结构: Float16是IEEE定义的16位浮点数标准,结构如下:
- 1位符号位
- 5位指数
- 10位尾数
Float16提供了较FP32更低的精度和较小的数值范围,但在存储和计算效率上具有优势。
优点:
- 较高的数值精度:Float16的10位尾数提供了比BFLOAT16更高的精度,适合需要高精度计算的应用。
- 计算加速:在支持Float16运算的硬件上(如GPU),使用Float16可以显著加速计算过程,尤其是在AI模型训练和推理中。
缺点:
- 较小的动态范围:Float16的5位指数提供的动态范围较小,可能导致在一些AI训练场景中出现梯度消失或爆炸问题。
- 兼容性问题:Float16到FP32的转换可能会涉及更复杂的数值调整,可能导致精度损失。
- BFLOAT16:由于其较大的动态范围和与FP32的良好兼容性,非常适合用于AI模型的训练和推理,尤其是在Google的TPU上。
- Float16:适用于对计算精度要求较高的场景,并且在NVIDIA及其他厂商的GPU上得到了广泛支持,尤其适合于需要加速的AI算法任务。
推理系统是用于部署人工智能模型,执行推理预测任务的人工智能系统,类似传统 Web 服务或移动端应用系统的作用。通过推理系统,可以将深度学习模型部署到云端或者边缘端,并服务和处理用户的请求。模型训练过程好比是传统软件工程中的代码开发的过程,而开发完的代码势必要打包,部署给用户使用,那么推理系统就负责应对模型部署和服务生命周期中遇到的挑战和问题。
当推理系统将完成训练的模型进行部署和服务时,需要考虑设计和提供模型压缩(轻量化,剪枝、量化、蒸馏),负载均衡,请求调度,加速优化,多副本和生命周期管理等支持。相比深度学习框架等为训练而设计的系统,推理系统不仅关注低延迟,高吞吐,可靠性等设计目标,同时受到资源,服务等级协议,功耗等约束。
推理阶段不同于训练阶段,只需要执行前向传播过程,将输入样本计算为输出标签。
- 模型被部署为长期运行的服务 服务有明确对请求的低延迟(Low Latency)和高吞吐(High Throughput)需求。例如,互联网服务一般都有明确的响应时间延迟约束,保证用户体验,同时需要应对爆发增长的用户产生的高吞吐请求的响应需求。
- 推理有更苛刻的资源约束 更小的内存,更低的功耗等。例如,手机的资源要远小于数据中心的商用服务器。
- 推理不需要反向传播梯度下降 可以牺牲一定的数据精度。例如,模型本身不再被更新,可以通过量化,稀疏性等手段牺牲一定精度换取一定的性能提升。
- 部署的设备型号更加多样 需要多样的定制化的优化。例如,相比服务器端可以通过 Docker 等手段解决环境问题。移动端显得更为棘手,手机有多种多样的平台与操作系统,IOT 设备有不同的芯片和上层软件栈,需要工具与系统提供编译以减少用户适配代价。
AI领域发展至今,Rocky认为目前主要有三大核心方向,包括AIGC、传统深度学习以及自动驾驶。以下是这些领域中主流的模型部署形式:
a. 云端部署
- 特点:模型部署在云服务器上,用户通过API调用服务进行内容生成。
- 优势:可扩展,易于更新和维护,适合处理大量并发请求。
- 应用示例:OpenAI的GPT-4模型作为API服务提供,用户可以通过互联网调用模型生成文本。
b. 客户端部署
- 特点:模型部署在用户的设备上,如PC或移动设备。
- 优势:保护用户数据隐私,减少网络延迟。
- 应用示例:Adobe Photoshop的内容感知工具,可在用户设备上直接运行,不需数据上传到云端。
a. 云端部署
- 特点:模型部署在云服务器上,利用云计算的强大计算能力进行数据处理和模型推理。
- 优势:提供强大的计算资源,易于扩展,便于管理。
- 应用示例:在图像识别、语音识别等需要大规模数据处理的应用中,云端部署可以快速处理来自全球的请求。
b. 边缘部署
- 特点:模型直接部署在本地设备上,如智能手机、IoT设备或本地服务器。
- 优势:减少数据传输时间,提高响应速度,增强隐私保护。
- 应用示例:在移动应用中,如实时语言翻译和增强现实(AR),模型在本地设备上运行,以实现低延迟和离线功能。
a. 车载部署
- 特点:模型直接部署在车辆的计算平台上,处理来自车载传感器的数据。
- 优势:实时处理传感器数据,快速做出驾驶决策。
- 应用示例:自动驾驶汽车中的决策系统,如特斯拉Autopilot,需要在车辆内部快速处理来自摄像头、雷达和其他传感器的数据。
b. 云端部署
- 特点:某些控制功能和监控系统部署在云端控制中心。
- 优势:可以进行更复杂的数据分析,实时监控和调整车辆行为。
- 应用示例:远程监控和调度系统,可用于管理自动驾驶车队,例如在无人配送服务中进行调度和监控。
总之,AI模型的部署形式应根据具体的应用需求、数据敏感性、可用资源和所需的响应时间来决定。不同的部署策略具有各自的优势和限制,理解这些可以帮助我们选择最适合特定需求的部署方法。
Jenkins,原名为Hudson,是一个自由及开源的自动化工具,用于支持软件开发中的持续集成与持续部署。
开源的自动化工具: Jenkins是一个开放源代码软件,意味着任何人都可以查看它的源代码、对其进行修改和贡献。开源使得Jenkins能够免费提供,并确保其长期的发展和维护。
持续集成与持续部署的核心组件: Jenkins为开发团队提供了一个平台,使其能够自动化各种任务,例如代码构建、测试、部署等。这种自动化使得开发流程更为流畅,可以快速地发现和修复问题,从而加快软件的发布速度。
- 代码构建: Jenkins支持多种编程语言和构建工具,从Java的Maven或Gradle,到JavaScript的npm或yarn,再到Python的pip,Jenkins都能轻松应对。这种自动化构建不仅仅是为了编译源代码,它还确保了在每次代码提交后,项目都是可构建的,从而避免了“在我机器上可以运行”的问题。
- 测试自动化: 仅仅构建代码并不足够。我们还需要确保代码的质量和功能的正确性。通过Jenkins,我们可以轻松地在每次代码提交或定期的基础上运行测试用例,从单元测试到集成测试再到UI测试。
- 自动部署: 当代码被成功构建并通过所有测试后,下一步就是将其部署到目标环境中。不论是传统的物理服务器、虚拟机,还是现代的容器和云平台,Jenkins都可以与各种部署工具和平台集成,实现代码的自动部署。
在实际开发中,需要考虑如何快速有效部署开发完成的项目,无论是在边端还是云端,这时候就需要自动化工具的配合了
在AI行业中,模型性能优化与模型部署密切相关,两者相辅相成。性能优化旨在提高模型的训练效率、推理速度和整体性能,而成功的模型部署需要确保模型在实际应用环境中的高效运行。下面Rocky详细讨论一下模型性能优化和模型部署之间的关系。
1. 训练阶段的性能优化
- 数据并行和模型并行:使用多个GPU或分布式计算来加速训练过程。
- 混合精度训练:使用16位浮点数(FP16)和32位浮点数(FP32)混合进行训练,减少显存占用并加速计算。
- 高效的优化算法:使用优化算法如Adam、LAMB等,加速模型的收敛速度。
- 自动化超参数调优:使用自动化工具(如Optuna、Hyperopt)调优超参数,提高模型性能。
2. 推理阶段的性能优化
- 模型剪枝:移除不重要的神经元或权重,减少模型的计算量。
- 量化:将模型权重和激活函数从浮点数转换为整数,减少计算和存储需求。
- 蒸馏:通过一个大模型(教师模型)指导一个小模型(学生模型)进行训练,从而在保持性能的前提下减少模型复杂度。
- 编译优化:使用深度学习编译器(如TensorRT、TVM)对模型进行底层优化,提高推理速度。
1. 部署环境
- 云端部署:适用于需要大规模计算资源的应用,能够利用云计算的弹性和高性能。
- 边缘部署:适用于资源受限的设备,如移动设备、物联网设备等,需要特别的优化以确保高效运行。
- 本地部署:适用于隐私敏感或需要低延迟的应用,模型需要在本地设备上高效运行。
2. 部署过程中的挑战
- 计算资源受限:边缘设备和嵌入式设备的计算能力和存储资源有限,需要对模型进行优化。
- 实时性要求:许多应用要求低延迟和高吞吐量,模型必须能够快速响应。
- 能耗限制:移动设备和物联网设备对能耗有严格要求,模型需要在节能模式下高效运行。
- 兼容性:模型需要兼容不同的硬件和软件平台,如不同的操作系统、硬件加速器等。
-
模型性能优化助力部署:模型性能优化直接影响部署效果。通过剪枝、量化、蒸馏和编译优化等方法,可以大幅减少模型的计算量和存储需求,从而确保模型在边缘设备或嵌入式设备上的高效运行。
-
部署驱动模型性能优化:部署需求驱动性能优化。在决定部署环境和硬件平台时,需要根据实际应用场景进行针对性的性能优化。例如,在移动设备上部署模型时,需要重点考虑量化和低功耗优化;在云端部署时,则可以更多地利用分布式计算和高性能硬件。
-
互相迭代改进:性能优化和部署是一个迭代过程。在实际部署过程中,可能会遇到未预见的问题,如延迟高、内存不足等。这需要不断调整优化策略,重新训练和微调模型,确保部署效果满足应用需求。
-
硬件加速器的利用:优化策略应与部署硬件特性相匹配。对于GPU、TPU、FPGA等不同硬件加速器,需要采用相应的编译优化和模型调整策略,以充分利用硬件性能,提高推理效率。
-
自动化工具的使用:自动化工具在优化和部署中起到重要作用。自动化超参数调优、自动化编译和部署工具(如TensorFlow Serving、ONNX Runtime)可以显著简化工作流程,提高效率和部署效果。
Rocky认为,不管是在AIGC、传统深度学习还是自动驾驶领域,模型性能优化和模型部署之间存在紧密的联系,优化不仅提高了模型在训练和推理阶段的效率,还直接影响模型在实际应用中的部署效果。通过合理的优化策略和部署方法,可以确保AI模型在各种环境中高效、可靠地运行。随着技术的不断进步,模型性能优化和部署将变得更加智能化和自动化,为广泛应用AI技术提供更强有力的支持。
在AI领域中,MoE(Mixture of Experts,专家混合模型)是一种集成学习方法,它通过将多个子模型(通常称为“专家模型”)组合在一起,从而提高整体模型的性能。MoE的核心思想是使用一个门控网络(Gating Network)来决定每个输入样本应该由哪些专家模型来处理,或者说设置每个专家模型对输入样本的贡献程度。
MoE的工作原理可以分为以下几个步骤:
-
专家模型(Experts):这是多个子模型,每个模型擅长于处理某类特定的输入或任务。这些专家模型可以是同一种类型的模型(如多个神经网络)或不同类型的模型(如神经网络、决策树、支持向量机等)。
-
门控网络(Gating Network):这是一个单独的网络,用于根据输入数据来确定每个专家模型的权重。门控网络输出一组权重,这些权重表示每个专家模型对当前输入的贡献。
-
加权组合:将门控网络输出的权重与对应的专家模型输出进行加权平均,从而得到最终的预测结果。
假设我们有 ( K ) 个专家模型 ( E_i ) 和一个门控网络 ( G ):
- 对于一个输入 ( x ),每个专家 ( E_i ) 会给出一个预测 ( y_i )。
- 门控网络 ( G ) 会输出一组权重 ( \alpha_i )(满足 ( \sum_{i=1}^{K} \alpha_i = 1 )),这些权重用于加权各专家的输出。
- 最终输出 ( y ) 通过如下方式得到:
[ y = \sum_{i=1}^{K} \alpha_i \cdot y_i ]
- 灵活性:MoE允许不同的专家模型专注于不同的输入区域或任务,从而提高模型的泛化能力。
- 可解释性:通过分析门控网络的输出权重,可以理解哪些专家模型在不同的情况下起到了主要作用。
- 高效性:在计算资源有限的情况下,MoE可以通过启用少数几个专家模型来处理每个输入,从而提高计算效率。
- AIGC领域
- 传统深度学习领域
- 自动驾驶领域
Switch Transformer是谷歌提出的一种大规模语言模型,它利用了MoE的架构。其核心思想是:
- 每个Transformer层包含多个专家模型(子模型),但每个输入token只会选择少数几个专家进行计算。
- 通过门控网络决定每个token使用哪些专家,从而大幅度减少计算量并提高模型的可扩展性。
MoE(Mixture of Experts)是一种强大的机器学习方法,通过组合多个专家模型并利用门控网络动态地分配权重,能够有效提升模型的性能和灵活性。尽管实现复杂,但在处理大规模数据和复杂任务时,MoE展示出了巨大的潜力和优势。
GPU内存带宽(Memory Bandwidth)是指GPU从其内存 (vRAM)中读取或写入数据的速度,通常以每秒千兆字节(GB/s)为单位。这一指标非常重要,因为它直接影响到GPU在处理复杂计算任务时的数据传输效率,进而影响整体性能。
GPU内存带宽由以下几个部分组成:
- 时钟频率:内存的工作频率,通常以MHz或GHz为单位。更高的频率意味着更快的数据传输速度。
- 内存总线宽度:内存总线的宽度,通常以位(bits)为单位。常见的总线宽度有256位、384位等。总线越宽,数据传输能力越强。
- 内存类型:不同类型的显存(如GDDR5、GDDR6、HBM等)具有不同的性能和效率。新型内存通常具有更高的频率和更宽的总线。
内存带宽的计算公式为:
对于双倍数据速率(DDR)的内存,每个时钟周期传输两次数据,因此数据传输速率为2。
举个例子,如果一个GPU使用GDDR6显存,频率为1750 MHz,总线宽度为256位,那么它的内存带宽计算如下:
内存带宽对于GPU的性能至关重要,尤其是在以下应用场景中:
- 高性能计算(HPC):在进行科学计算、金融建模等高性能计算任务时,内存带宽影响数据的快速传输和处理。
- 图形渲染:复杂的图形渲染任务,如实时光线追踪(Ray Tracing),需要高带宽来处理大量的纹理和图像数据。
- AI领域(AIGC、传统深度学习、自动驾驶):训练和推理AI模型需要频繁访问大量数据,高内存带宽可以提高训练速度和推理效率。
Rocky认为我们通过理解和优化GPU内存带宽,可以显著提升计算任务的效率和性能,尤其在高要求的AI模型训练与推理任务中尤为重要。
在AI领域应用中,将AI模型缓存到内存中是一种提高模型推理性能的常见做法。缓存模型可以减少每次推理时模型加载的时间,尤其是在模型需要频繁访问或调用的场景中。下面Rocky将为大家演示如何将模型缓存到内存中,并在需要时加载到GPU进行推理,完成推理后再将其移回内存中的完整流程。
首先,我们需要将预训练的AI模型加载到CPU的内存中。这可以确保在不使用GPU推理时,AI模型不会占用宝贵的GPU显存资源。
import torch
# 假设模型已经保存为 WeThinkIn.pth
model = torch.load('WeThinkIn.pth', map_location=torch.device('cpu'))
model.eval() # 设置模型为评估模式当需要进行推理或计算时,可以将AI模型从CPU内存临时移动到GPU显存中来。这样做可以利用GPU的强大计算能力,提高AI模型的推理速度。
def load_model_to_gpu(model):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device) # 将模型加载到GPU
return model在GPU上进行模型的推理计算。
def perform_inference(model, input_data):
input_data = input_data.to(model.device) # 确保输入数据也在同一设备
with torch.no_grad(): # 确保在推理模式下不计算梯度
output = model(input_data)
return output推理计算完成后,可以选择将AI模型从GPU移回CP 内存,以释放GPU资源供其他任务使用。
def unload_model_from_gpu(model):
model.to('cpu') # 将模型移回 CPU
torch.cuda.empty_cache() # 清理 CUDA 缓存将上述功能整合到一起,形成一个可以按需动态管理AI模型资源的流程。
model = torch.load('WeThinkIn.pth', map_location='cpu')
model.eval()
# 当需要使用模型时
model = load_model_to_gpu(model)
input_data = torch.randn(1, 3, 224, 224) # 示例输入
output = perform_inference(model, input_data)
model = unload_model_from_gpu(model)- 内存管理: 这种动态加载和卸载模型需要仔细管理内存,避免内存泄露。
- 性能考虑: 频繁地在CPU和GPU之间移动模型可能会影响任务整体性能。如果模型使用频率非常高,我们需要重新考虑是否每次都将AI模型移回CPU。
- 资源共享: 在多任务并行处理的环境下,合理分配GPU资源尤为重要。
通过这样的策略,我们可以有效地利用有限的GPU显存资源,在保证性能的同时,也确保了显存资源的最大化利用。
在AI领域中,延迟(Latency)和吞吐量(Throughput)是两个关键的性能指标,它们在评估系统的效率和响应能力方面起着至关重要的作用。理解并优化这两个指标对于提升AI系统的响应速度和处理能力至关重要。通过在不同应用场景中合理平衡延迟和吞吐量,可以实现更高效和更可靠的AI系统。以下是Rocky对这两个概念的详细解释及其在AI领域中的应用。
延迟指的是从输入到输出所需的时间,通常表示为处理单个任务或请求所花费的时间。延迟可以分为以下几种类型:
- 网络延迟:数据在网络中传输的时间。
- 处理延迟:数据在系统中被处理所需的时间。
- 总延迟:包括所有类型延迟的总和,从请求发出到收到响应的总时间。
延迟通常以毫秒(ms)为单位测量。测量延迟的方法包括:
- Ping 测试:测量数据包在网络中的往返时间。
- Benchmarking:使用基准测试工具测量系统处理特定任务的时间。
在AI领域中,延迟主要用于评估AI模型的推理耗时,尤其是在实时应用中,如AIGC、传统深度学习、自动驾驶等方向中。低延迟对于用户体验和AI系统性能至关重要。
吞吐量指的是AI系统在单位时间内处理的任务或请求的数量,通常表示为每秒处理的任务数(tasks per second 或 queries per second)。吞吐量反映了AI系统的整体处理能力。
吞吐量通常以每秒处理的请求数量(RPS)或每秒处理的数据量(bps, MB/s)来表示。测量吞吐量的方法包括:
- Load Testing:在高负载下测试系统的最大处理能力。
- Stress Testing:测试系统在极限条件下的处理能力。
在AI领域中,吞吐量主要用于评估AI模型的训练和推理能力。高吞吐量意味着AI系统可以在单位时间内处理更多的数据或请求,这对于大规模数据处理和高并发请求的应用非常重要。
-
平衡:在AI系统设计中,延迟和吞吐量往往需要平衡。例如,在一些实时应用中,优先考虑低延迟可能会降低吞吐量,而在批处理任务中,优先考虑高吞吐量可能会增加延迟。
-
资源利用:高吞吐量通常意味着更高的资源利用率,但也可能导致资源争用,从而增加延迟。相反,低延迟系统可能会有较低的资源利用率,但能提供更快速的响应。
-
优化策略:根据具体应用的需求,AI系统可以通过优化硬件配置、调整算法、并行处理等方法来降低延迟和提高吞吐量。例如,使用更快的处理器和更高效的算法可以同时改善延迟和吞吐量。
-
图像分类模型:
- 延迟:测量单张图像从输入到分类结果输出的时间。
- 吞吐量:测量每秒钟可以处理的图像数量。
-
视频流处理:
- 延迟:测量每帧视频从捕获到显示所需的时间。
- 吞吐量:测量每秒可以处理的帧数。
-
自然语言处理(NLP):
- 延迟:测量从文本输入到生成翻译结果的时间。
- 吞吐量:测量每秒可以处理的句子数量。
在英伟达的显卡监控工具中,Volatile GPU Util 是一个重要的指标,用于显示GPU利用率的波动情况。它反映了在一个采样周期内GPU的使用百分比,这个百分比指示了GPU在这段时间内忙于执行计算任务的时间占比。
这个指标在AIGC、传统深度学习、自动驾驶领域都很重要,能够方便我们查看GPU的使用情况,测试排查GPU问题,筛选出高性能GPU来提升AI模型的训练推理效率,增强AI系统的整体性能。下面Rocky再给大家讲解一下Volatile GPU Util详细含义和用途:
-
瞬时利用率:
- Volatile GPU Util表示的是在特定采样周期内GPU的利用率,这个采样周期通常是非常短的(例如几秒钟),因此这个值是瞬时的而非累积的。GPU的利用率不等于GPU内计算单元干活的比例,GPU Util本质上只是反应了在采样时间段内,一个或多个内核(kernel)在GPU上执行的时间百分比,采样时间段取值1/6s~1s。
-
活动时间百分比:
- 这个值表示GPU在采样周期内有多少时间在执行计算任务。例如,50%的Volatile GPU Util表示在采样周期的一半时间里GPU是忙于计算任务的。
-
动态变化:
- 因为这个指标是瞬时的,它会随着时间的变化而波动,反映GPU利用率的动态变化情况。这对于实时监控GPU负载非常有帮助。
-
性能监控:
- AI行业开发者可以使用Volatile GPU Util来监控GPU的实时负载情况,以确定当前的计算任务是否充分利用了GPU资源。
-
瓶颈识别:
- 通过观察Volatile GPU Util,我们可以识别出是否存在GPU资源不足的问题。例如,如果利用率一直接近100%,说明GPU可能成为AI系统的瓶颈,任务可能受限于GPU的计算能力。
-
资源分配:
- 管理多个AI任务和资源的调度时,Volatile GPU Util可以帮助确定哪个AI任务在消耗大量GPU资源,从而更好地分配计算资源和优化性能。
-
优化和调试:
- AI行业开发者可以根据这个指标来优化代码和算法,以提高GPU的利用率。低利用率可能表明存在性能瓶颈或资源浪费的情况,需要进行优化。
在使用英伟达提供的 nvidia-smi 命令工具后,我们可以看到Volatile GPU Util的输出。例如:
$ nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce GTX 1080 Off | 00000000:01:00.0 Off | N/A |
| 30% 58C P2 42W / 180W | 0MiB / 8119MiB | 28% Default |
+-------------------------------+----------------------+----------------------+在这个示例中,GPU-Util 一栏显示 28%,这表示在当前采样周期内,这个GPU的利用率是28%。通过理解和监控Volatile GPU Util,我们可以更好地管理和优化GPU资源,确保AI系统的高效运行。
首先,我们在设计高效CNN架构之前,需要对CNN架构本身有一定的理解:
- CNN主要有网络深度和通道宽度两个核心参数,通常来说,网络越深越宽,性能越好。宽度代表通道(channel)的数量;网络深度代表layer的层数,比如resnet52 有52层网络。
- 网络深度的意义:CNN的网络层能够对输入图像数据进行逐层抽象,比如第一层学习到了图像边缘特征,第二层学习到了简单形状特征,第三层学习到了目标形状的特征,网络深度增加也提高了模型的特征提取和抽象的能力。
- 网络宽度的意义:网络的宽度(通道数)代表了滤波器(3 维)的数量,滤波器越多,对目标特征的提取能力越强,即让每一层网络学习到更加丰富的特征,比如不同方向、不同频率的纹理特征等。
了解了CNN的一些概念,我们可以开始设计高效CNN架构了,下面是一些设计经验与建议,也欢迎大家一起来补充:
- 分析模型的推理性能需要结合具体的推理平台(比如GPU、ARM CPU、NPU以及端侧芯片等)。
- 目前已知影响CNN模型推理性能的因素包括: 算子计算量FLOPs(参数量 Params)、卷积block的内存访问代价(访存带宽)、网络并行度等。在相同硬件平台、相同网络架构条件下, FLOPs加速比与推理时间加速比成正比。
- 建议对于轻量级网络设计应该评估直接metric(例如速度speed),而不是间接metric(例如FLOPs)。
- FLOPs低不等于latency低,尤其是在有加速功能的硬体(GPU、DSP与TPU)上不成立,得结合具硬件架构具体分析。
- 不同网络架构的CNN模型,即使是FLOPs相同,但其MAC也可能差异巨大。
- 在GPU上,Depthwise卷积算子实际上是使用了大量的低FLOPs、高数据读写量的操作。这些具有高数据读写量的操作,加上多数时候GPU芯片算力的瓶颈在于访存带宽,使得模型把大量的时间浪费在了从显存中读写数据上,导致GPU的算力没有得到“充分利用”。
- 在大多数的AI端侧硬件上,channel数为16的倍数比较有利高效计算。如海思351x系列芯片,当输入通道为4倍数和输出通道数为16倍数时,时间加速比会近似等于 FLOPs 加速比,有利于提供 NNIE 硬件计算利用率。
- 在低channel数的情况下 (如网络的前几层),在有加速功能的硬件(NPU芯片)上使用普通convolution通常会比separable convolution有效率。
- shufflenetv2论文提出的四个高效网络设计的实用指导思想: (1)同样大小的通道数可以最小化MAC(2)分组数太多的卷积会增加MAC(3)网络碎片化会降低并行度(4)逐元素的操作不可忽视。
- RepVGG论文指出GPU芯片上
$3\times 3$ 卷积非常快,其计算密度(理论运算量除以所用时间)可达$1\times 1$ 和$5\times 5$ 卷积的四倍。 - 如果想从解决梯度信息冗余问题入手,来提高模型推理效率,可参考CSPNet网络的构建思路。
- 如果想从解决DenseNet的密集连接带来的高内存访问成本和能耗问题入手,可参考VoVNet网络,其由OSA(One-Shot Aggregation,一次聚合)模块组成。
英伟达(NVIDIA)的GPU架构在计算机图形学、AI模型训练与推理、高性能计算等领域有广泛的应用。NVIDIA的GPU架构在计算性能、能效和功能性方面不断进化,每一代架构都带来了显著的改进和新特性。从最早的Tesla到最新的Ampere,并通过优化CUDA核心、引入Tensor核心和RT核心,同时采用先进的内存和互连技术,NVIDIA GPU提供了强大的计算能力和灵活的应用支持。
一个典型的NVIDIA GPU由多个基本组件组成,这些组件协同工作来执行高效的并行计算任务。主要组件包括:
SM是GPU的核心计算单元。每个SM包含多个CUDA核心(CUDA Cores),它们负责执行大多数计算任务。一个SM通常还包括以下单元:
- CUDA核心:用于执行整数和浮点数运算。
- 特殊功能单元(SFU):用于执行特殊函数,如三角函数和平方根。
- 纹理单元(Texture Units):用于纹理采样和过滤。
- 共享内存和寄存器文件:用于快速存储和访问中间计算结果。
全局内存是GPU上所有线程都可以访问的内存空间。它的访问速度相对较慢,但容量较大,通常用于存储输入数据和计算结果。
统一内存允许CPU和GPU共享相同的内存空间,简化了数据管理和传输。
L2缓存是一个共享缓存,位于全局内存和SM之间,用于加速数据访问,减少全局内存访问的延迟。
- 指令调度单元(Instruction Scheduler):负责将指令分发给CUDA核心和其他单元。
- 数据路径(Data Path):用于在不同的内存层次和计算单元之间传输数据。
下面是GPU和CPU架构的直观对比:

Tesla 架构是NVIDIA推出的首个大规模并行计算架构,标志着GPU从固定功能图形处理器向通用并行计算设备的转变。Tesla架构引入了CUDA核心,使得编程模型更加灵活。
Fermi 架构引入了许多关键改进,包括支持ECC内存、更大的寄存器文件、L1和L2 缓存、以及双精度浮点运算的增强。它还改进了并行计算能力,使得GPU更适合科学计算和工程应用。
Kepler 架构进一步提升了性能和能效,引入了动态并行性和 Hyper-Q 技术。动态并行性允许 GPU 在运行时生成新任务,Hyper-Q 则通过增加硬件工作队列的数量,显著提高了并行计算效率。
Maxwell 架构专注于能效的提升和性能优化,引入了统一内存和 NVLink 技术。统一内存简化了内存管理,NVLink 提供了高带宽的 CPU-GPU 以及 GPU-GPU 连接。
Pascal 架构是 Maxwell 架构的改进版,增加了对混合精度计算的支持,并引入了基于 HBM2 高带宽内存的新型 GPU。Pascal 架构显著提高了深度学习的计算效率。
Volta 架构引入了 Tensor 核心,这是一种专为深度学习设计的硬件单元,显著提升了训练和推理的性能。Volta 还改进了 CUDA 核心和 NVLink 技术,进一步增强了 GPU 的计算能力和数据传输性能。
Turing 架构引入了实时光线追踪(Ray Tracing)技术和专用的 RT 核心,以及用于 AI 加速的 Tensor 核心。这使得 Turing 架构在图形处理和深度学习应用中表现出色。
Ampere 架构是 NVIDIA 最新一代 GPU 架构,进一步提升了 Tensor 核心和 RT 核心的性能,并引入了第三代 NVLink 和 PCIe 4.0 支持。Ampere 架构在图形处理、深度学习和高性能计算方面均有显著提升。
以 Ampere 架构为例,详细介绍其关键特性和改进。
Ampere 架构中的 CUDA 核心经过优化,支持更高效的整数和浮点数运算。每个 SM 中包含更多的 CUDA 核心,提升了并行计算能力。
Ampere 架构中的第三代 Tensor 核心支持稀疏矩阵运算,进一步提升了深度学习训练和推理的效率。Tensor 核心能够高效处理混合精度计算,提供更高的计算吞吐量。
Ampere 架构中的第二代 RT 核心改进了光线追踪的性能,支持更加逼真的图像渲染和实时光影效果。RT 核心能够高效处理复杂的光线追踪计算,显著提升图形处理能力。
Ampere 架构支持第三代 NVLink 和 PCIe 4.0,提供更高的带宽和更低的延迟。NVLink 允许多个 GPU 之间高速互联,PCIe 4.0 提供更快的 CPU-GPU 数据传输速度。
Ampere 架构使用 GDDR6X 高带宽显存,提供更高的内存带宽和更低的延迟。这种新型显存能够支持更大规模的数据集和更高效的计算。
NVIDIA GPU 在多个领域有广泛的应用,包括但不限于:
- 深度学习:训练和推理深度神经网络,加速 AI 模型的开发和部署。
- 高性能计算(HPC):科学计算、气候模拟、金融建模等需要大规模并行计算的应用。
- 图形处理:实时渲染、图像处理、视频编码和解码。
- 游戏:高性能图形渲染、物理模拟和 AI 驱动的游戏功能。
- 数据中心:加速数据分析、数据库查询和大数据处理。
经典的轻量级模型包括mobilenet系列、MobileDets系列、shufflenet系列、cspnet系列、vovnet系列以及repvgg系列等,以下是一些部署经验:
- 低算力设备:比如手机移动端 cpu 硬件,可以考虑使用mobilenetv1(深度可分离卷机架构低 FLOPs)、低 FLOPs 和 低MAC的shuffletnetv2(channel_shuffle 算子在推理框架上可能不支持)。
- 专用 asic 硬件设备:比如npu 芯片(地平线 x3/x4 等、海思 3519、安霸cv22 等),目标检测问题可以考虑使用 cspnet 网络(减少重复梯度信息)、repvgg(直连架构部署简单,网络并行度高有利于发挥 GPU 算力,但量化后有精度下降的风险) 。
- 英伟达 gpu 硬件:比如 t4 芯片,可以考虑使用 repvgg 网络(类 vgg 卷积架构高并行度能带来高速度、单路架构省显存/内存)。
- MobileNet block (深度可分离卷积 block, depthwise separable convolution block)在有加速功能的硬件(比如 NPU 芯片)上比较没有效率。除非芯片厂商做了定制优化来提高深度可分离卷积 block 的计算效率,比如地平线机器人 x3 芯片对深度可分离卷积 block 做了定制优化。
-
INT8(8-bit Integer):
- INT8 是一种使用8位表示的整数数据类型。整数类型是定点数,没有小数部分,可以是有符号或无符号的。通常在AI领域中,INT8 表示的范围是 -128 到 127(有符号整数)。
- INT8 在AI领域中的应用主要集中在推理阶段,使用定点数代替浮点数可以显著降低内存占用和加速推理过程。
-
FP8(8-bit Floating Point):
- FP8 是一种使用8位表示的浮点数数据类型。与整数不同,浮点数可以表示非常小或非常大的值,通过使用指数和尾数的组合来表示。FP8 的典型表示法包括 1 位符号位、4 位指数位和 3 位尾数位。
- FP8 通常用于训练和推理中,以提供比 INT8 更广泛的动态范围和更精确的小数表示。
-
INT8:
- INT8 使用定点数表示法,表示范围是固定的。如果是有符号整数,范围为 -128 到 127。
- 由于它是整数类型,INT8 没有小数部分,这意味着它只能表示离散的整数值。
-
FP8:
- FP8 使用浮点数表示法,表示范围取决于指数的数量。由于 FP8 通常使用 4 位指数,它可以表示更广泛的动态范围,尽管精度较低。
- FP8 可以表示非常小的和非常大的数值,并且可以表示小数部分,但由于只有3位尾数,精度有限。
-
INT8:
- 推理阶段的优化:INT8 主要用于AI模型推理阶段的优化。在将模型转换为 INT8 时,通常需要进行量化(quantization)处理。这种量化通过缩小数值的表示范围和精度,使得模型更适合低功耗设备如移动设备或嵌入式系统。
- 性能和存储优势:INT8 可以显著减少内存占用和加快计算速度,尤其是在使用专用硬件(如 NVIDIA TensorRT、Intel DL Boost)时,推理速度可以显著提高。
-
FP8:
- 训练和推理中的使用:FP8 被提出作为在AI训练和推理中一种可能的低精度计算方案。相比 INT8,FP8 在表示动态范围上更有优势,因此在某些情况下可能比 INT8 更适合训练和推理。
- 平衡精度和性能:FP8 在精度和动态范围之间取得了平衡,适用于一些需要在精度和计算性能之间进行权衡的应用。FP8 尤其适合用于混合精度训练中,与 FP16 或 FP32 一起使用,以优化性能。
-
INT8:
- 优势:
- 内存占用小:只需要8位存储空间,极大地减少了内存使用。
- 计算速度快:适用于推理优化,在现有硬件上有良好的支持,特别是在移动设备和嵌入式系统中。
- 限制:
- 精度有限:由于没有小数部分,在处理需要精细数值的场景时可能不适用。
- 量化复杂:从 FP32 转换为 INT8 需要精细的量化策略,以减少精度损失。
- 优势:
-
FP8:
- 优势:
- 更广泛的动态范围:可以表示更大或更小的数值,适用于一些需要小数精度的场景。
- 混合精度训练:可以与其他浮点精度结合使用,平衡性能和精度。
- 限制:
- 精度仍然有限:虽然比 INT8 有小数表示,但由于只有3位尾数,精度在一些场景中可能不足。
- 目前支持有限:FP8 作为一种新兴的精度格式,目前在硬件支持和工具链上还不如 INT8 成熟。
- 优势:
不管是AIGC、传统深度学习还是自动驾驶领域,我们对AI模型进行端侧部署时,都需要从以下几个大的维度进行通盘考虑,这样才能对AI模型部署的成本与周期有所掌握:
- 模型压缩技术:为了实现高效的端侧部署,模型压缩技术至关重要。核心技术包括量化(Quantization)、剪枝(Pruning)、模型蒸馏(Knowledge Distillation)、高效模型架构设计、分块执行(Tiling Execution)等。
- 硬件加速技术:端侧设备通常配备有限的计算资源,因此充分利用设备的硬件加速能力尤为重要。硬件加速核心技术包括使用GPU加速、使用NPU(Neural Processing Unit)加速、使用FPGA和ASIC加速等。
- 推理优化框架技术:为了实现高效的推理,AI绘画模型的部署需要依赖一些经过优化的推理框架,这些框架能够针对不同硬件平台和操作系统进行优化。推理优化框架的核心技术包括:TensorFlow Lite、ONNX Runtime、PyTorch Mobile、MNN等。
- 跨平台支持技术:端侧部署的一个重要技术挑战是如何实现不同设备和操作系统上的兼容性。AI模型需要在Android、iOS、Linux等多个平台上运行,保证模型的跨平台一致性。跨平台支持核心技术包括:模型转换工具、多平台编译和适配、设备检测和动态加载等。
AI模型轻量化的效果评价指标主要用于衡量模型在资源使用效率、性能表现和实际应用适应性之间的平衡。下面是Rocky总结的主流轻量化效果评价指标及其适用场景:
- 模型文件大小:模型的总存储体积,通常以 MB(兆字节)或 GB(千兆字节)为单位。
- 参数数量(Parameter Count):模型的可训练参数总数,通常以百万(M)或十亿(B)级别表示。
- 存储成本:模型越小,占用的存储空间越少,更适合在资源受限的设备(如移动设备、物联网设备)上部署。
- 传输效率:在边缘设备与服务器之间传输模型时,小模型能够显著降低网络延迟。
-
比较模型轻量化前后的文件大小或参数数量的变化,例如:
$$ \text{压缩率} = \frac{\text{原始模型大小}}{\text{压缩后模型大小}} $$
-
示例:一个 100MB 的模型压缩到 20MB,压缩率为 5x。
- 延迟(Latency):单次推理所需的时间,通常以毫秒(ms)为单位。
- 吞吐量(Throughput):单位时间内模型能够处理的输入数量(例如 FPS 或样本/秒)。
- 实时性:延迟低的模型适合实时应用场景,如在线翻译、视频分析。
- 处理效率:吞吐量高的模型适合批量处理任务,例如大规模数据预测。
- 延迟:测量模型在给定硬件(如 CPU、GPU 或专用加速器)上的单次推理时间。
- 吞吐量:在一定时间窗口内运行模型,计算处理的输入数量。
- 示例:模型轻量化后推理速度提升了 3x,意味着延迟降低到 1/3。
- 功耗(Power Consumption):模型推理时所需的能量消耗,通常以瓦特(W)或焦耳(J)为单位。
- 能效比(Energy Efficiency Ratio):每单位功耗下模型处理的样本数量(如 FPS/W)。
- 设备续航:低功耗模型更适合部署在电池供电设备(如手机、无人机)上。
- 绿色计算:节能模型更符合环保要求,尤其在数据中心部署时可以降低运营成本。
- 使用硬件能耗监测工具,测量模型运行过程中的能耗,并比较轻量化前后的变化。
- 示例:轻量化后,模型每秒功耗从 20W 降低到 8W。
-
模型性能指标:
- 生成任务:图像生成质量、对话准确度等
- 分类任务:准确率(Accuracy)、召回率(Recall)、F1 分数等。
- 回归任务:均方误差(MSE)、均绝对误差(MAE)等。
- 检测任务:平均精度均值(mAP)。
- 分割任务:交并比(IoU)。
-
轻量化引起的精度变化:
$$ \Delta \text{Performance} = \text{轻量化前精度} - \text{轻量化后精度} $$
- 平衡点:评估轻量化后模型性能是否显著下降,以确保模型在目标任务中的实用性。
- 比较轻量化前后的模型在相同数据集上的性能表现。
- 示例:轻量化模型的分类准确率从 95% 下降到 94.5%,性能下降了 0.5%。
- 显存占用(GPU Memory Usage):模型推理时在 GPU 上占用的显存,通常以 MB 或 GB 为单位。
- RAM 使用量(CPU Memory Usage):模型推理时在 CPU 上占用的内存,通常以 MB 或 GB 为单位。
- 硬件适配性:轻量化模型应能够在低资源设备(如嵌入式系统)上运行。
- 并发能力:占用内存越少,单一硬件上同时运行的实例数越多。
- 使用监控工具(如 NVIDIA 的
nvidia-smi或 PyTorch/TensorFlow 的内存分配监控 API)测量内存占用。 - 示例:轻量化后显存占用从 6GB 降低到 2GB。
-
模型压缩比(Compression Ratio):
$$ \text{压缩比} = \frac{\text{原始模型大小}}{\text{压缩后模型大小}} $$
- 存储效率:高压缩比意味着模型占用的存储空间显著减少。
- 计算模型在量化、剪枝或知识蒸馏后的大小变化。
- 示例:一个 500MB 的模型压缩到 50MB,压缩比为 10x。
-
稀疏率(Sparsity Ratio):模型权重中为零的参数所占的比例。
$$ \text{稀疏率} = \frac{\text{零参数的数量}}{\text{总参数数量}} $$
- 计算效率:稀疏模型在部署到支持稀疏优化的硬件(如专用加速器)时,可以显著提升推理速度和降低功耗。
- 检查轻量化后的权重矩阵,计算零值权重的比例。
- 示例:模型稀疏率从 0% 增加到 50%。
- 模型兼容性:轻量化后的模型是否能直接运行在目标硬件(如移动设备、嵌入式设备)上。
- 转换成本:从开发框架到部署框架的转换复杂度(如从 PyTorch 转换到 TensorRT)。
- 工程效率:易部署的模型可以快速投入生产环境。
- 测试轻量化后的模型在目标硬件或框架(如 TensorRT、ONNX)上的兼容性。
- 响应时间(Response Time):模型在用户交互中的实际响应时间。
- 体验流畅度:在应用中(如手机或 AR/VR 环境),模型轻量化后是否对体验流畅性有所改善。
- 实际效果:轻量化的最终目标是提升用户体验,这往往比单纯的性能指标更重要。
- 测量轻量化模型在实际应用场景中的响应速度和流畅度。
- 示例:语音助手模型响应时间从 500ms 降低到 200ms。
- 任务迁移性能:轻量化模型在多个任务上的性能是否保持一致。
- 硬件适应性:模型是否能在多种硬件(如 GPU、TPU、CPU)上高效运行。
- 可扩展性:轻量化模型应具备更广泛的适应性,而不仅仅针对单一任务或设备优化。
- 在不同任务、设备上的性能测试,衡量其通用性。
- 示例:模型在移动设备上的推理速度提升 3x,同时在服务器上的精度几乎无损。
| 指标类别 | 具体指标 | 意义 |
|---|---|---|
| 资源效率 | 模型大小、内存使用、推理速度、能耗 | 衡量轻量化模型在资源受限设备上的表现。 |
| 性能表现 | 精度、稀疏率、压缩比 | 确保轻量化后模型的任务性能和计算效率的平衡。 |
| 适用性与体验 | 部署难易度、响应时间、任务迁移性能 | 评估轻量化模型在实际场景中的应用和适配能力。 |
NF4(Normalized Float 4-bit)是一种专门为深度学习模型设计的 4 位浮点数(4-bit floating-point)数值表示方式,旨在优化模型的存储和计算效率,同时尽量保持高精度。NF4 是目前低精度量化领域中的一种新兴方法,被广泛应用于大语言模型(LLMs)等参数量巨大的模型中。NF4精度具备以下优势:
- 存储高效:仅占用 4-bit,适合大规模模型。
- 性能稳定:在压缩显存占用的同时,精度损失较小。
- 硬件友好:针对推理和部署场景进行优化。
它是当前大模型量化的重要方向之一,结合工具(如 BitsAndBytes、DeepSpeed)和框架支持,可以大幅提升 AIGC 模型的运行效率。
- 参数规模的快速增长:AIGC大模型(如 GPT-4、Stable Diffusion 等)往往包含数百亿到数万亿参数,导致显存需求巨大。
- 存储和计算的瓶颈:传统的浮点表示(如 FP32、FP16)占用的存储空间较大,限制了硬件资源的利用率和训练规模。
- 低精度量化的潜力:研究表明,模型参数的分布存在冗余信息,可以通过低精度量化(如 INT8、4-bit)显著压缩存储需求,同时保持模型性能。
- 提供一种更加高效的表示方式,通过归一化的 4-bit 浮点格式,实现压缩存储和加速计算。
- 保留了浮点数的非线性分布特点(与 INT4 不同),更适合AIGC大模型中参数的动态范围。
NF4 是一种 4 位浮点数格式,其核心特性包括:
-
归一化值范围:
- NF4 的表示范围被归一化到一个动态区间,通常是通过归一化向量或权重块实现的。
- 对每组参数(例如一层权重矩阵)进行归一化,使参数值映射到 NF4 格式支持的动态范围内。
-
非线性量化:
- NF4 使用浮点表示方式的非线性分布,更适合参数中存在大值和小值的场景。
- 不同于线性量化(如 INT4),NF4 能较好地保留数值动态范围内的梯度信息。
-
4 位表示的压缩效果:
- 4 位表示将每个参数从 32-bit 或 16-bit 压缩到 4-bit,存储需求减少 8 倍或 4 倍。
- 在大型模型(如数百亿参数)中,这种压缩效果显著减少显存需求。
-
在模型量化时,将每一组参数向量(或矩阵)进行归一化,使它们的数值分布在一个统一的范围内。例如:
$$ x_{\text{normalized}} = \frac{x}{|x|} \cdot S $$
-
$|x|$ :参数向量的归一化因子(如 L2 范数)。 -
$S$ :归一化后数值的动态范围。
-
-
归一化的目的是确保所有参数在 NF4 表示范围内分布均匀,减少精度损失。
- NF4 的 4-bit 格式设计为:
- 1 位符号位(S):表示正数或负数。
- 3 位指数位(E):用于表示浮点数的动态范围,支持非线性表示。
- 这种设计使 NF4 能在 4 位的限制下,覆盖较大的动态范围,同时保留一定的数值精度。
-
在推理或训练中,从 NF4 格式解码回浮点数时,需要恢复归一化因子:
$$ x_{\text{recovered}} = x_{\text{NF4}} \cdot |x| $$
-
$|x|$ :在量化时保存的归一化因子,用于恢复 NF4 数据。
-
- 相比 INT4:
- INT4 是线性量化,不适合深度学习模型中权重和激活值的非线性分布。
- NF4 的浮点表示能够捕捉权重的动态范围。
- 相比 FP16 和 BF16:
- NF4 的存储成本更低,仅 4-bit,而 FP16 和 BF16 为 16-bit。
- NF4 将存储需求降低至原来的 1/8(相比 FP32)或 1/4(相比 FP16)。
- 特别适合大模型的推理和部署场景。
- NF4 在显著压缩存储需求的同时,能保持较高的模型推理性能,精度损失相较于 INT4 更小。
- 应用于 ChatGPT、GPT-4、PaLM 等大规模 Transformer 模型:
- 在推理阶段通过 NF4 减少显存占用,使得在单 GPU 上运行超大模型成为可能。
- 结合 Low-Rank Adaptation(LoRA)等技术,支持 4-bit 微调。
- 适用于生成类模型(如 DALL-E、Stable Diffusion):
- 减少显存和内存占用,便于在消费级设备上运行。
- 在边缘设备或资源有限的环境中,用 NF4 压缩模型权重,优化推理性能。
- 在极端条件下(如高精度依赖的任务),NF4 可能导致一定的性能下降。
- 需要额外的归一化处理,并在推理时恢复归一化因子。
- 低精度计算对硬件支持要求较高。
- 这是由 Hugging Face 推出的一种新型安全模型存储格式,特别关注模型安全性、隐私保护和快速加载。
- 它仅包含模型的权重参数,而不包括执行代码,这样可以减少模型文件大小,提高加载速度。
- 加载方式:使用 Hugging Face 提供的相关API来加载 .safetensors 文件,例如 safetensors.torch.load_file() 函数。
全称checkpoint,通过Dreambooth训练的模型,包含了模型参数,还包括优化器状态以及可能的训练元数据信息,使得用户可以无缝地恢复训练或执行推理
- 通常是一种通用的二进制格式文件,它可以用来存储任意类型的数据。
- 在机器学习领域,.bin 文件有时用于存储模型权重或其他二进制数据,但并不特指PyTorch的官方标准格式。
- 对于PyTorch而言,如果用户自己选择将模型权重以二进制格式保存,可能会使用 .bin 扩展名,加载时需要自定义逻辑读取和应用这些权重到模型结构中。
- 是 PyTorch 中用于保存模型状态的标准格式。
- 主要用于保存模型的 state_dict,包含了模型的所有可学习参数,或者整个模型(包括结构和参数)。
- 加载方式:使用 PyTorch 的 torch.load() 函数直接加载 .pth 文件,并通过调用 model.load_state_dict() 将加载的字典应用于模型实例。
GGUF文件全称是GPT-Generated Unified Format,是由Georgi Gerganov定义发布的一种大模型文件格式。Georgi Gerganov是著名开源项目llama.cpp的创始人。
GGUF是一种二进制格式文件的规范,原始的大模型预训练结果经过转换后变成GGUF格式可以更快地被载入使用,也会消耗更低的资源。原因在于GGUF采用了多种技术来保存大模型预训练结果,包括采用紧凑的二进制编码格式、优化的数据结构、内存映射等。
- 二进制格式:GGUF作为一种二进制格式,相较于文本格式的文件,可以更快地被读取和解析。二进制文件通常更紧凑,减少了读取和解析时所需的I/O操作和处理时间。
- 优化的数据结构:GGUF可能采用了特别优化的数据结构,这些结构为快速访问和加载模型数据提供了支持。例如,数据可能按照内存加载的需要进行组织,以减少加载时的处理。
- 内存映射(mmap)兼容性:如果GGUF支持内存映射(mmap),这允许直接从磁盘映射数据到内存地址空间,从而加快了数据的加载速度。这样,数据可以在不实际加载整个文件的情况下被访问,特别是对于大型模型非常有效。
- 高效的序列化和反序列化:GGUF可能使用高效的序列化和反序列化方法,这意味着模型数据可以快速转换为可用的格式。
- 少量的依赖和外部引用:如果GGUF格式设计为自包含,即所有需要的信息都存储在单个文件中,这将减少解析和加载模型时所需的外部文件查找和读取操作。
- 数据压缩:GGUF格式可能采用了有效的数据压缩技术,减少了文件大小,从而加速了读取过程。
- 优化的索引和访问机制:文件中数据的索引和访问机制可能经过优化,使得查找和加载所需的特定数据片段更加迅速。
Safetensors 是一种新的格式,用于安全地存储 Tensor(相比于 pickle),而且速度很快(零拷贝)。
安装
pip install safetensors
保存
import torch
from safetensors.torch import save_file
tensors = {
"embedding": torch.zeros((1, 2)),
"attention": torch.zeros((3, 4))
}
save_file(tensors, "model.safetensors")
加载
from safetensors import safe_open
tensors = {}
with safe_open("model.safetensors", framework="pt", device=0) as f:
for k in f.keys():
tensors[k] = f.get_tensor(k)
与ckpt的相互转换
import torch
import safetensors
from safetensors.torch import load_file, save_file
def ckpt2safetensors():
loaded = torch.load('xxx.ckpt')
if "state_dict" in loaded:
loaded = loaded["state_dict"]
safetensors.torch.save_file(loaded, 'xxx.safetensors')
def safetensors2ckpt():
data = safetensors.torch.load_file('xxx.safetensors.bk')
data["state_dict"] = data
torch.save(data, os.path.splitext('xxx.safetensors')[0] + '.ckpt')
GGUF支持多种数据类型,如整数、浮点数和字符串等。这些数据类型用于定义模型的不同方面,如结构、大小和参数。
一个GGUF文件包括文件头、元数据键值对和张量信息等。这些组成部分共同定义了模型的结构和行为。
GGUF支持小端和大端格式,确保了其在不同计算平台上的可用性。端序(Endianness)是指数据在计算机内存中的字节顺序排列方式,主要有两种类型:大端(Big-Endian)和小端(Little-Endian)。不同的计算平台可能采用不同的端序。例如,Intel的x86架构是小端的,而某些旧的IBM和网络协议通常是大端的。因此,文件格式如果能支持这两种端序,就可以确保数据在不同架构的计算机上正确读取和解释。
-
文件头 (Header)
- 作用:包含用于识别文件类型和版本的基本信息。
- 内容:
Magic Number:一个特定的数字或字符序列,用于标识文件格式。Version:文件格式的版本号,指明了文件遵循的具体规范或标准。
-
元数据键值对 (Metadata Key-Value Pairs)
- 作用:存储关于模型的额外信息,如作者、训练信息、模型描述等。
- 内容:
Key:一个字符串,标识元数据的名称。Value Type:数据类型,指明值的格式(如整数、浮点数、字符串等)。Value:具体的元数据内容。
-
张量计数 (Tensor Count)
- 作用:标识文件中包含的张量(Tensor)数量。
- 内容:
Count:一个整数,表示文件中张量的总数。
-
张量信息 (Tensor Info)
- 作用:描述每个张量的具体信息,包括形状、类型和数据位置。
- 内容:
Name:张量的名称。Dimensions:张量的维度信息。Type:张量数据的类型(如浮点数、整数等)。Offset:指明张量数据在文件中的位置。
-
对齐填充 (Alignment Padding)
- 作用:确保数据块在内存中正确对齐,有助于提高访问效率。
- 内容:
- 通常是一些填充字节,用于保证后续数据的内存对齐。
-
张量数据 (Tensor Data)
- 作用:存储模型的实际权重和参数。
- 内容:
Binary Data:模型的权重和参数的二进制表示。
-
端序标识 (Endianness)
- 作用:指示文件中数值数据的字节顺序(大端或小端)。
- 内容:
- 通常是一个标记,表明文件遵循的端序。
-
扩展信息 (Extension Information)
- 作用:允许文件格式未来扩展,以包含新的数据类型或结构。
- 内容:
- 可以是新加入的任何额外信息,为将来的格式升级预留空间。
整体来看,GGUF文件格式通过这些结构化的组件提供了一种高效、灵活且可扩展的方式来存储和处理机器学习模型。这种设计不仅有助于快速加载和处理模型,而且还支持未来技术的发展和新功能的添加。
diffusion模型:使用webui加载的safetensors模型,
路径:stable-diffusion-webui/models/Stable-diffusion
diffusers模型:使用stable diffuser pipeline加载的模型,目录结构如图:

diffusers
转换脚本路径:diffusers/scripts
diffusers-->diffusion:
python convert_diffusers_to_original_stable_diffusion.py --model_path model_dir --checkpoint_path path_to_ckpt.ckpt
其他参数:
--half:使用fp16数据格式
--use_safetensors:使用safetensors保存
diffusion-->diffusers:
python convert_original_stable_diffusion_to_diffusers.py --checkpoint_path path_to_ckpt.ckpt --dump_path model_dir --image_size 512 --prediction_type epsilon