- 1.卷积有什么特点
- 2.不同层次的卷积都提取什么类型的特征
- 3.卷积核大小如何选取
- 4.卷积感受野的相关概念
- 5.网络每一层是否只能用一种尺寸的卷积核
- 6.1*1卷积的作用
- 7.转置卷积的作用
- 8.空洞卷积的作用
- 9.什么是转置卷积的棋盘效应
- 10.什么是有效感受野
- 11.分组卷积的相关知识
- 12.什么是可变形卷积?
- 13.什么是3D卷积?
- 14.分析一下卷积层的时间复杂度和空间复杂度
- 15.AIGC时代一共有多少种主流卷积类型?
- 16.卷积神经网络的本质是什么?
卷积主要有三大特点:
-
局部连接。比起全连接,局部连接会大大减少网络的参数。在二维图像中,局部像素的关联性很强,设计局部连接保证了卷积网络对图像局部特征的强响应能力。
-
权值共享。参数共享也能减少整体参数量,增强了网络训练的效率。一个卷积核的参数权重被整张图片共享,不会因为图像内位置的不同而改变卷积核内的参数权重。
-
下采样。下采样能逐渐降低图像分辨率,实现了数据的降维,并使浅层的局部特征组合成为深层的特征。下采样还能使计算资源耗费变少,加速模型训练,也能有效控制过拟合。
-
浅层卷积
$\rightarrow$ 提取边缘特征 -
中层卷积
$\rightarrow$ 提取局部特征 -
深层卷积
$\rightarrow$ 提取全局特征
最常用的是

不过大卷积核(
目标检测和目标跟踪很多模型都会用到RPN层,anchor是RPN层的基础,而感受野(receptive field,RF)是anchor的基础。
感受野的作用:
-
一般来说感受野越大越好,比如分类任务中最后卷积层的感受野要大于输入图像。
-
感受野足够大时,被忽略的信息就较少。
-
目标检测任务中设置anchor要对齐感受野,anchor太大或者偏离感受野会对性能产生一定的影响。
感受野计算:
增大感受野的方法:
-
使用空洞卷积
-
使用池化层
-
增大卷积核
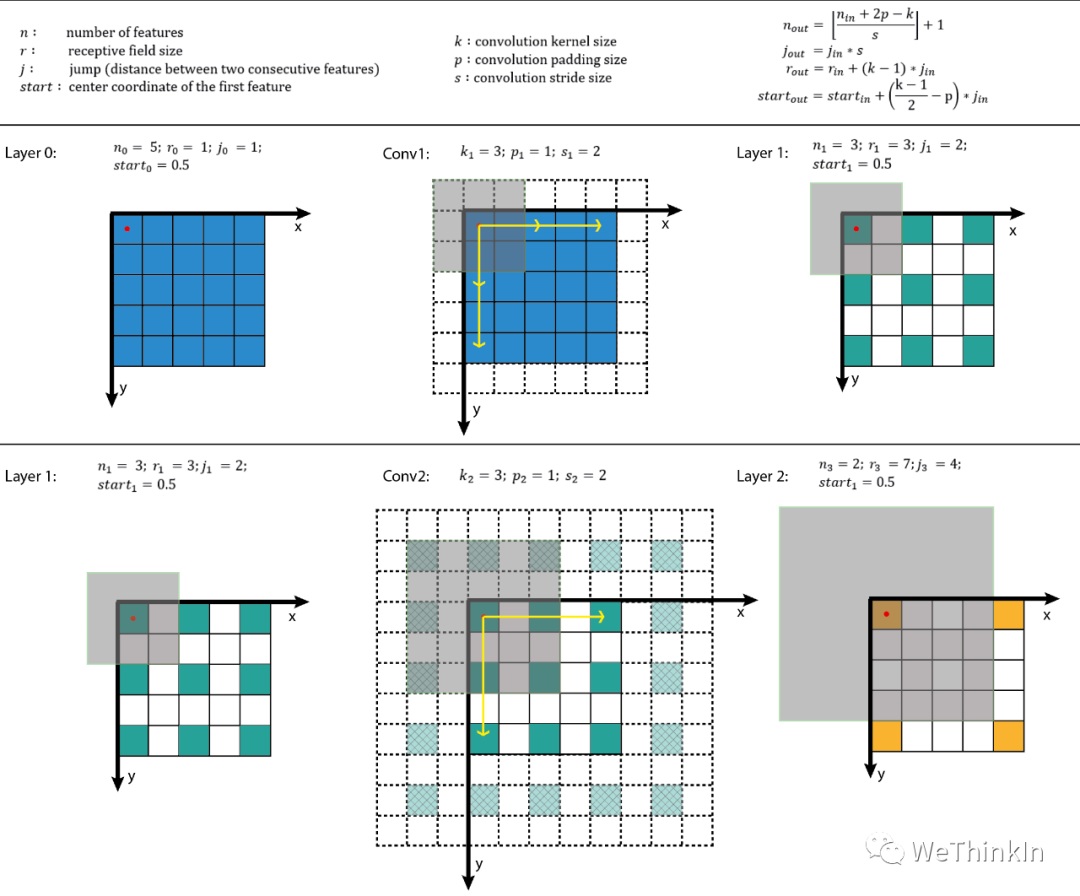
常规的神经网络一般每层仅用一个尺寸的卷积核,但同一层的特征图可以分别使用多个不同尺寸的卷积核,以获得不同尺度的特征,再把这些特征结合起来,得到的特征往往比使用单一尺寸卷积核的要好,如GoogLeNet 、Inception系列的网络,均是每层使用了多个不同的卷积核结构。如下图所示,输入的特征图在同一层分别经过
-
实现特征信息的交互与整合。
-
对特征图通道数进行升维和降维,降维时可以减少参数量。
-
$1*1$ 卷积+ 激活函数$\rightarrow$ 增加非线性,提升网络表达能力。


转置卷积通过训练过程学习到最优的上采样方式,来代替传统的插值上采样方法,以提升图像分割,图像融合,GAN等特定任务的性能。
转置卷积并不是卷积的反向操作,从信息论的角度看,卷积运算是不可逆的。转置卷积可以将输出的特征图尺寸恢复卷积前的特征图尺寸,但不恢复原始数值。
转置卷积的计算公式:
我们设卷积核尺寸为
(1)当
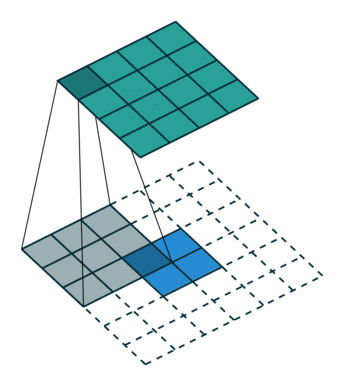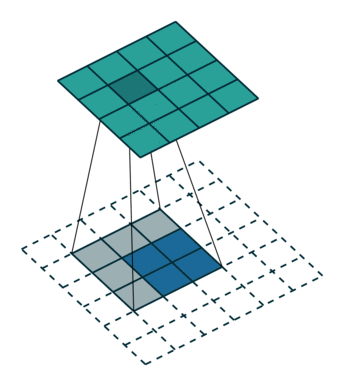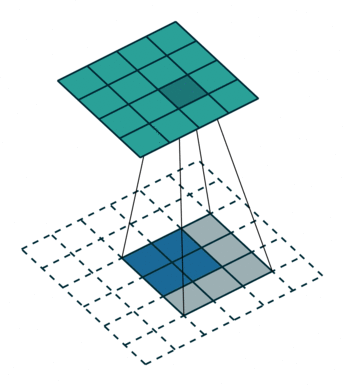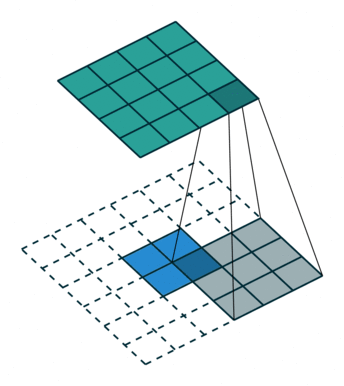
输入特征图在进行转置卷积操作时相当于进行了
输出特征图的尺寸 =
(2)当
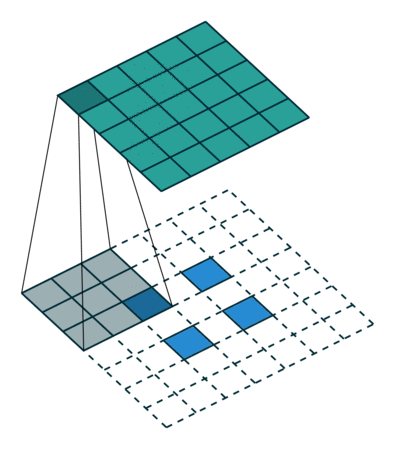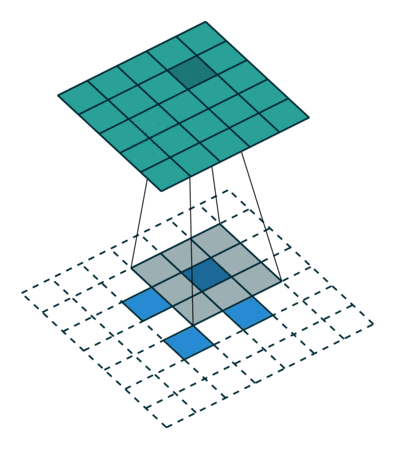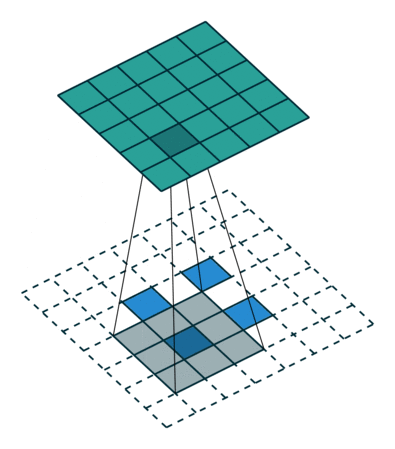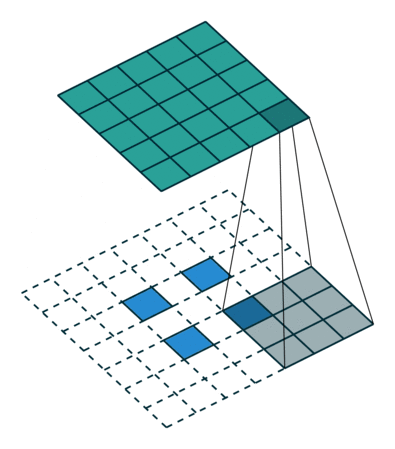
输入特征图在进行转置卷积操作时相当于进行了
输出特征图的尺寸 =
空洞卷积的作用是在不进行池化操作损失信息的情况下,增大感受野,让每个卷积输出都包含较大范围的信息。
空洞卷积有一个参数可以设置dilation rate,其在卷积核中填充dilation rate个0,因此,当设置不同dilation rate时,感受野就会不一样,也获取了多尺度信息。
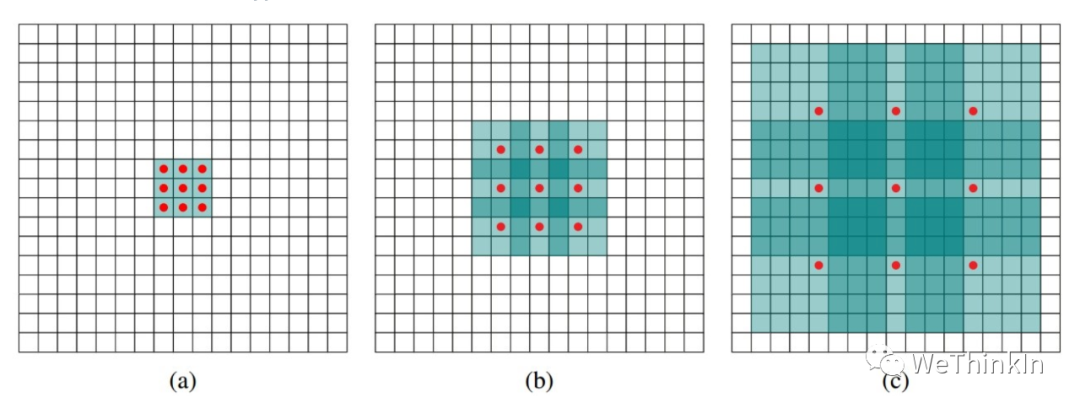
(a) 图对应

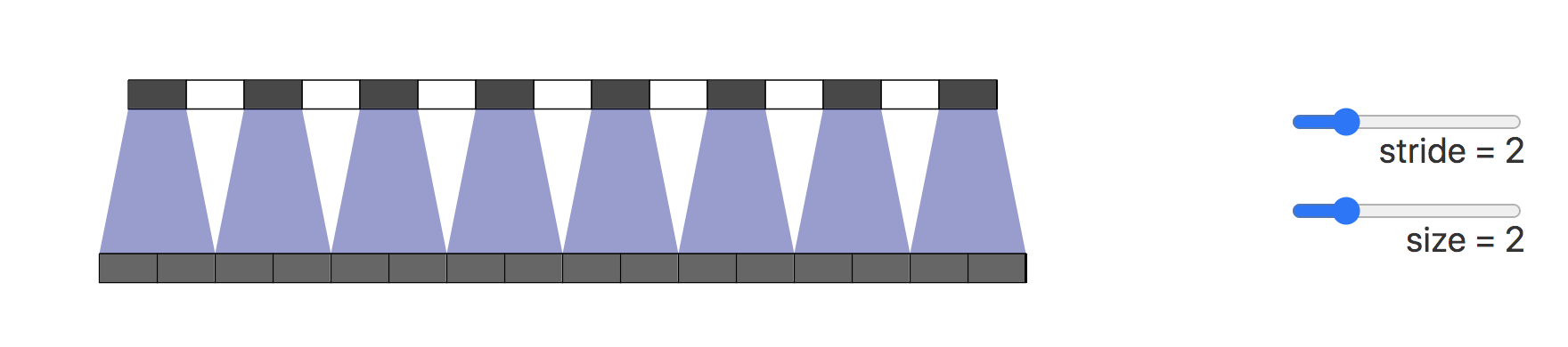
造成棋盘效应的原因是转置卷积的不均匀重叠(uneven overlap)。这种重叠会造成图像中某个部位的颜色比其他部位更深。
在下图展示了棋盘效应的形成过程,深色部分代表了不均匀重叠:
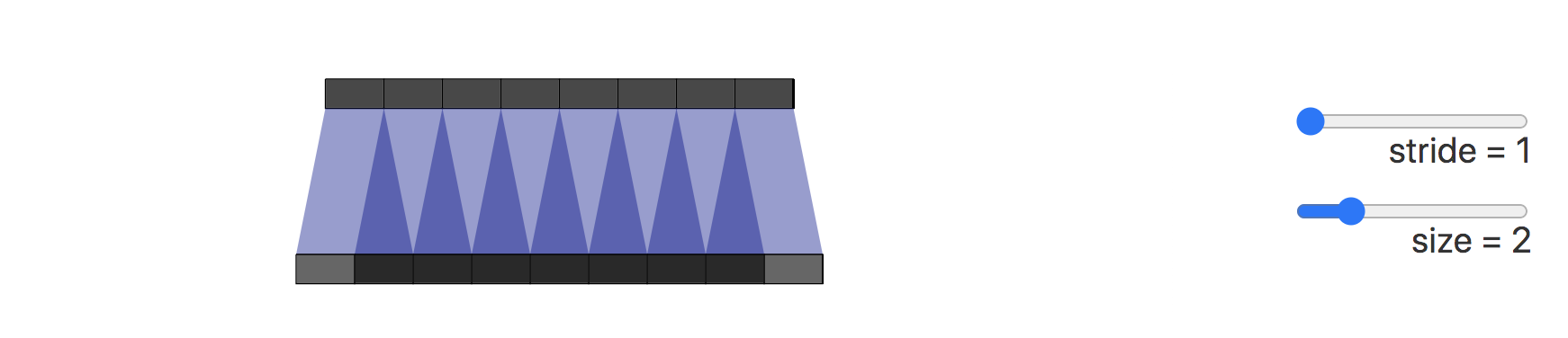
接下来我们将卷积步长改为2,可以看到输出图像上的所有像素从输入图像中接收到同样多的信息,它们都从输入图像中接收到一个像素的信息,这样就不存在转置卷带来的重叠区域。
我们也可以直接进行插值Resize操作,然后再进行卷积操作来消除棋盘效应。这种方式在超分辨率重建场景中比较常见。例如使用双线性插值和近邻插值等方法来进行上采样。
感受野的相关知识在上面的第四节中中介绍过。
我们接着再看看有效感受野(effective receptive field, ERF)的相关知识。
一般而言,feature map上有效感受野要小于实际感受野。其有效性,以中心点为基准,类似高斯分布向边缘递减。
总的来说,感受野主要描述feature map中的最大信息量,有效感受野则主要描述信息的有效性。
分组卷积(Group Convolution)最早出现在AlexNet网络中,分组卷积被用来切分网络,使其能在多个GPU上并行运行。

普通卷积进行运算的时候,如果输入feature map尺寸是
分组卷积的主要对输入的feature map进行分组,然后每组分别进行卷积。如果输入feature map尺寸是
分组卷积的作用:
-
分组卷积可以减少参数量。
-
分组卷积可以看成是稀疏操作,有时可以在较少参数量的情况下获得更好的效果(相当于正则化操作)。
-
当分组数量等于输入feature map通道数量,输出feature map数量也等于输入feature map数量时,分组卷积就成了Depthwise卷积,可以使参数量进一步缩减。
可变形卷积(Deformable Convolution)是一种改进传统卷积神经网络(CNN)能力的新型卷积方法,旨在解决CNN在建模几何变换方面的固有限制。传统的卷积操作在固定的几何结构上进行采样,这使得它们在面对不同对象的尺度、姿态、视角和部分变形时表现不佳。
可变形卷积通过在标准卷积的采样网格位置上添加2D偏移量,使得卷积核能够在自由形式的采样位置上进行操作。这些偏移量通过前面的特征图生成,并通过额外的卷积层进行学习,从而使得变形是基于输入特征局部和自适应的。
如下图所示:
- 输入特征图(Input Feature Map):传统卷积在输入特征图上以固定网格采样。
- 卷积核(Conv):在标准卷积中,卷积核在特征图上滑动,生成输出特征图。
- 偏移场(Offset Field):在可变形卷积中,偏移量由前一层特征图生成,并与卷积核一起应用于输入特征图。
- 输出特征图(Output Feature Map):最终生成的输出特征图具有更强的适应性,能够更好地捕捉图像中的几何变换。


标准卷积(a)和可变形卷积(b)中固定感受野和自适应感受野的示意图如上图所示。
3D卷积(3D Convolution)是一种用于处理三维数据的卷积运算。与我们常见的2D卷积不同,3D卷积不仅在图像的宽和高两个空间维度上滑动,还在第三个维度上滑动,通常是时间或深度维度。因此,3D卷积通常用于处理如视频、医学影像(如MRI或CT扫描)或任何具有时间、深度信息的三维数据。
要理解3D卷积的原理,我们可以从2D卷积入手。假设我们有一个2D卷积核(kernel),它在图像上滑动,生成一个特征图(Feature Map)。这个过程可以类比为在图片上用滤镜移动,提取特定的特征,例如边缘、纹理等。
现在,想象一下,我们不仅在图像的宽度和高度方向滑动卷积核,还在第三个维度上滑动,这个维度可以是时间(如视频中的帧)、深度(如CT扫描中的层)、或者颜色通道的组合。
-
输入数据:
- 3D卷积的输入通常是一个三维特征,例如一个视频可以表示为
(帧数, 高度, 宽度),或一个立体图像(如3D医疗图像)表示为(深度, 高度, 宽度)。
- 3D卷积的输入通常是一个三维特征,例如一个视频可以表示为
-
卷积核(Filter/Kernels):
- 3D卷积核是一个三维的小块。例如,一个
$3\times3\times3$ 的卷积核在三个维度上分别有3个单元。 - 卷积核在输入数据的三个维度上滑动,在每一个位置进行点积运算(每个元素相乘再整体相加),生成一个输出值。
- 3D卷积核是一个三维的小块。例如,一个
-
输出特征图:
- 输出特征也是一个三维特征图,它记录了卷积核在输入数据上每个位置滑动时的运算结果。输出的深度由输入数据的深度和卷积核的深度决定。
想象一下,我们在制作巧克力,模具就是我们的卷积核。我们有一个厚厚的巧克力板(3D输入数据),你要在这块板上用模具压出不同形状的巧克力(输出特征图)。
-
2D卷积:就像在一块平面的巧克力上用模具压出形状,我们只能在平面上移动模具(左右、上下),每次我们都会得到一个平面巧克力的形状。
-
3D卷积:现在我们不仅可以在平面上移动模具,还可以把模具往巧克力的厚度方向压进去。这样,我们每次压出的是一个立体的巧克力块。这块立体巧克力反映了我们在厚度方向(如时间、深度)上也进行了一次处理。
-
AI视频领域:
- 在AI视频领域中,3D卷积的作用非常明显,Sora、CogVideoX等主流AI视频大模型中都用到了3D卷积。视频数据通常是多个连续的帧序列,通过在时间维度上进行卷积,AI视频模型可以捕捉到动作的动态特征。
-
医学影像:
- 在医学影像中,如MRI或CT扫描,3D卷积可以在扫描的多个切片上滑动,以捕捉人体内部结构的三维特征,这对于诊断和分析非常重要。
-
人体姿态估计:
- 3D卷积可以用于从多帧图像中提取人体的姿态,帮助模型理解姿态变化和动作。
3D卷积的输入通常是一个四维张量,形状为 (D, H, W, C),其中:
D是深度(例如视频中的帧数或医学图像中的切片数)。H是高度。W是宽度。C是通道数(例如,RGB图像的通道数为3)。
假设我们有一个输入张量 X,其形状为 (D_in, H_in, W_in, C_in),其中 C_in 是输入的通道数。我们还有一个卷积核 W,其形状为 (D_k, H_k, W_k, C_in, C_out),其中 C_out 是输出的通道数。
-
滑动卷积核:
- 卷积核
W在输入张量X上按步长(stride)滑动。在每个位置,卷积核的每个元素与对应位置的输入数据相乘,并将这些乘积相加得到一个输出值。
- 卷积核
-
点积运算:
-
在每个滑动位置,对输入张量与卷积核进行点积运算。具体地,对于某个位置
(i, j, k)的输出值,计算公式为:$$Y(i, j, k, m) = \sum_{d=0}^{D_k-1} \sum_{h=0}^{H_k-1} \sum_{w=0}^{W_k-1} \sum_{c=0}^{C_in-1} X(i+d, j+h, k+w, c) \cdot W(d, h, w, c, m)$$ 其中:
-
Y(i, j, k, m)是输出张量在位置(i, j, k)和通道m上的值。 -
X(i+d, j+h, k+w, c)是输入张量X在位置(i+d, j+h, k+w)和通道c上的值。 -
W(d, h, w, c, m)是卷积核W在位置(d, h, w)和输入通道c、输出通道m上的权重。
-
-
-
应用偏置:
-
对于每个输出通道,可以添加一个偏置
b[m],使得最终的输出为:$$Y(i, j, k, m) = Y(i, j, k, m) + b[m]$$
-
-
输出张量:
- 经过上述操作后,得到的输出张量
Y的形状为(D_out, H_out, W_out, C_out),其中D_out、H_out和W_out分别是深度、高度和宽度方向上的输出尺寸。
- 经过上述操作后,得到的输出张量
假设我们有一个输入张量 X,其形状为 (4, 4, 4, 1),即深度、高度、宽度均为4,且有一个输入通道。我们有一个卷积核 W,其形状为 (2, 2, 2, 1, 1),即大小为2x2x2的立方体卷积核,有1个输入通道和1个输出通道。步长为1,无填充(padding)。
-
卷积核在输入张量上滑动:
- 卷积核首先覆盖输入张量的前2x2x2部分,与这部分的输入数据进行点积运算,得到一个输出值。
- 然后,卷积核滑动到下一个位置,重复上述过程,直到覆盖所有可能的位置。
-
计算每个位置的输出:
-
例如,对于第一个位置(顶点)上的输出值,计算公式为:
$$Y(0, 0, 0, 0) = X(0, 0, 0, 0) \cdot W(0, 0, 0, 0, 0) + X(0, 0, 1, 0) \cdot W(0, 0, 1, 0, 0) + \ldots + X(1, 1, 1, 0) \cdot W(1, 1, 1, 0, 0)$$
-
-
得到最终输出:
- 经过所有位置的计算后,得到的输出张量
Y的形状为(3, 3, 3, 1)。
- 经过所有位置的计算后,得到的输出张量
优点:
- 能够捕捉到输入数据的三维特征,尤其适合处理视频数据和3D图像数据。
- 能够捕捉时间维度(或深度维度)的变化,适用于动态特征提取。
缺点:
- 计算复杂度更高,训练时间更长。
- 需要更多的内存和计算资源。
1. 时间复杂度(计算量)
时间复杂度衡量卷积层的计算资源消耗,通常用**浮点运算次数(FLOPs)**表示。
公式:
其中:
-
$K$ :卷积核尺寸(假设为正方形核) -
$C_{\text{in}}$ :输入通道数 -
$C_{\text{out}}$ :输出通道数 -
$H_{\text{out}}, W_{\text{out}}$ :输出特征图的高度和宽度
注:乘法和加法各计1次运算,因此系数为2。
2. 空间复杂度(参数量与内存占用)
空间复杂度包含两部分:
-
参数量:模型存储的权重参数数量
$$\text{Params} = K^2 \times C_{\text{in}} \times C_{\text{out}}$$ -
激活内存:前向传播中特征图的存储需求
$$\text{Memory} = C_{\text{out}} \times H_{\text{out}} \times W_{\text{out}} \times \text{bytes-per-element}$$ (通常每个元素为4字节的float32类型)
案例:手机端图像分类模型
假设输入为RGB图像(3×224×224),使用一个卷积层:
- 卷积核:3×3,输出通道64,步长1,padding=1
- 输出尺寸:64×224×224
复杂度计算:
-
时间复杂度:
$$2 \times 3^2 \times 3 \times 64 \times 224 \times 224 = 1.73 \times 10^9 , \text{FLOPs}$$ -
参数量:
$$3^2 \times 3 \times 64 = 1,728 , \text{参数}$$ -
激活内存:
$$64 \times 224 \times 224 \times 4 , \text{Bytes} = 12.58 , \text{MB}$$
优化对比:
若改用深度可分离卷积(Depthwise Separable Convolution):
- 参数量降至
$3^2 \times 3 + 3 \times 64 = 27 + 192 = 219$ - FLOPs降至
$3^2 \times 3 \times 224^2 + 3 \times 64 \times 224^2 = 0.13 \times 10^9 , \text{FLOPs}$ 计算量减少约13倍,适用于移动端部署。
我们都知道,卷积是AI领域的核心模块之一,通过不同结构的卷积核提取输入数据的多层次特征。以下是Rocky总结的常见卷积类型及其在AIGC、传统深度学习、自动驾驶中的应用:
-
原理:使用固定大小的滑动窗口(如3×3、5×5)逐区域计算加权和,提取局部特征。
-
公式:
$$y(i,j) = \sum_{m}\sum_{n} x(i+m, j+n) \cdot k(m,n)$$ -
案例:图像分类任务中,CNN通过多层标准卷积提取边缘→纹理→物体部件等特征。
-
应用:
- AIGC:Stable Diffusion的基础卷积层生成图像细节。
- 传统深度学习:ResNet、VGG等模型的核心操作。
- 自动驾驶:摄像头图像中的车辆/行人检测。
- 原理:拆分标准卷积为深度卷积(逐通道) + 1×1卷积(通道融合),减少计算量。
-
计算量对比:
标准卷积:$D_K \times D_K \times M \times N$ 深度可分离:$D_K \times D_K \times M + M \times N$ ($D_K$ 为卷积核尺寸,$M$ 输入通道,$N$ 输出通道) - 案例:MobileNet通过此卷积在手机端实时运行图像分类。
-
应用:
- AIGC:轻量化文本生成模型部署到移动端。
- 传统深度学习:移动端/嵌入式设备模型优化。
- 自动驾驶:车载芯片实时处理多摄像头输入。
- 原理:在卷积核元素间插入空洞(间隔),扩大感受野且不增加参数量。
# PyTorch示例(空洞率=2) nn.Conv2d(in_channels, out_channels, kernel_size=3, dilation=2)
- 案例:DeepLab系列使用空洞卷积保持高分辨率特征图,提升语义分割精度。
- 应用:
- AIGC:高清图像生成时捕捉长程依赖(如头发纹理)。
- 传统深度学习:视频动作识别中建模时序跨度。
- 自动驾驶:LiDAR点云中的大范围障碍物检测。
- 原理:通过填充和步长实现上采样,重建高分辨率特征图。
- 操作示例:输入2×2 → 转置卷积(kernel=3, stride=2)→ 输出5×5。
- 案例:GAN生成器将低维噪声转换为高清图像。
- 应用:
- AIGC:图像超分辨率重建、风格迁移。
- 传统深度学习:U-Net解码器恢复医学影像细节。
- 自动驾驶:BEV(鸟瞰图)特征解码生成道路拓扑。
- 原理:将输入通道分组,每组独立卷积后拼接结果,减少计算量。
# ResNeXt的分组卷积(组数=32) nn.Conv2d(64, 128, kernel_size=3, groups=32)
- 案例:ResNeXt通过分组卷积提升模型容量而不显著增加计算量。
- 应用:
- AIGC:多任务生成模型(如同时生成图像和描述)。
- 传统深度学习:大规模分类模型加速训练。
- 自动驾驶:多传感器(摄像头+雷达)特征分组处理。
- 原理:通过偏移量学习动态调整卷积核采样位置,适应不规则形状。
# 可变形卷积层 from torchvision.ops import DeformConv2d DeformConv2d(in_channels, out_channels, kernel_size=3)
- 案例:DCN(可变形卷积网络)提升COCO数据集目标检测AP 3%~5%。
- 应用:
- AIGC:生成非刚性物体(如衣服褶皱、流体)。
- 传统深度学习:复杂场景下的实例分割。
- 自动驾驶:处理遮挡或形变的行人/车辆检测。
- 原理:在三维空间(长、宽、时间/深度)滑动,提取时空特征。
# 视频处理中的3D卷积 nn.Conv3d(in_channels, out_channels, kernel_size=(3,3,3))
- 案例:C3D网络分析视频中的动作时序特征。
- 应用:
- AIGC:视频生成(如动态纹理合成)。
- 传统深度学习:CT/MRI医学影像分析。
- 自动驾驶:多帧LiDAR序列处理预测运动轨迹。
- 原理:仅融合通道信息,不改变空间尺寸,用于升维/降维。
# Inception模块中的1×1卷积 nn.Conv2d(256, 128, kernel_size=1)
- 案例:SqueezeNet通过1×1卷积压缩参数,模型体积减少50倍。
- 应用:
- AIGC:StyleGAN中的风格向量通道调制。
- 传统深度学习:ResNet瓶颈层减少计算量。
- 自动驾驶:多模态特征通道融合(图像+点云)。
- 原理:根据输入动态生成卷积核权重,增强模型适应性。
# 动态卷积示例 weights = generate_weights(x) # 输入相关 output = dynamic_conv(x, weights)
- 案例:CondConv在ImageNet分类任务中提升精度1.2%。
- 应用:
- AIGC:个性化图像生成(根据用户输入调整风格)。
- 传统深度学习:小样本学习动态适配新类别。
- 自动驾驶:动态调整卷积核以适应不同天气条件。
| 卷积类型 | 核心作用 | AIGC应用 | 传统深度学习应用 | 自动驾驶应用 |
|---|---|---|---|---|
| 标准卷积 | 基础特征提取 | 图像生成 | ResNet分类 | 目标检测 |
| 深度可分离卷积 | 轻量化计算 | 移动端生成模型 | MobileNet | 实时多摄像头处理 |
| 空洞卷积 | 扩大感受野 | 高清细节生成 | DeepLab分割 | 大范围障碍物检测 |
| 转置卷积 | 上采样重建 | GAN生成器 | U-Net解码器 | BEV地图生成 |
| 分组卷积 | 多分支特征学习 | 多任务生成模型 | ResNeXt | 多传感器融合 |
| 可变形卷积 | 适应不规则形状 | 非刚性物体生成 | DCN检测 | 遮挡目标检测 |
| 3D卷积 | 时空建模 | 视频生成 | C3D动作识别 | LiDAR序列分析 |
| 1×1卷积 | 通道维度调整 | 风格调制 | 通道压缩 | 多模态特征融合 |
| 动态卷积 | 输入自适应计算 | 个性化生成 | CondConv | 环境自适应模型 |
Rocky总结的核心答案:卷积神经网络的本质是——利用具有“局部连接”、“权值共享”和“空间/时序层次化特征提取”能力的卷积操作,高效地从网格化数据(如图像、视频、音频频谱图)中自动学习具有平移不变性的层次化特征表示。
-
核心操作:卷积 (Convolution)
- 数学上: 本质是滤波器(Kernel/Filter) 在输入数据(如图像)上滑动,进行局部区域的点积运算。滤波器是一组可学习的权重参数。
- 直观上: 想象用一个带小窗口(滤波器)的放大镜在图片上移动。在每个位置,窗口只看到图片的一小块(局部区域),计算这个小块与窗口内部图案(滤波器权重)的匹配程度。匹配程度高,输出值就大。
- 作用: 检测输入数据中的局部模式,如边缘、角点、纹理、基本形状等。
-
关键特性:
- 局部连接 (Local Connectivity):
- 是什么: 输出特征图上的一个像素点(神经元),只与输入数据中对应位置附近的一个小区域(感受野)内的输入值相连,而不是与整个输入相连(像全连接层那样)。
- 为什么是本质: 这完美契合了图像等数据的特性——像素点的重要性主要取决于其邻近像素,远处的像素影响很小。极大减少了参数量和计算量,让处理高分辨率图像成为可能。
- 权值共享 (Parameter Sharing):
- 是什么: 同一个滤波器在整个输入数据上滑动并重复使用相同的权重参数。无论滤波器滑到图像的哪个位置,它都在检测相同的模式(比如垂直边缘)。
- 为什么是本质:
- 进一步显著减少参数量: 一个滤波器只有
Kernel_Width * Kernel_Height * Input_Channels个参数,无论输入图像有多大。 - 赋予平移不变性 (Translation Invariance): 这是CNN最强大的特性之一!无论目标物体(如猫)出现在图像的左上角还是右下角,只要用于检测“猫耳朵”或“猫胡须”的滤波器学到了这个模式,它就能在图像的任何位置将其检测出来。模型学会了关注“有什么特征”,而不是“特征具体在哪个绝对坐标位置”。
- 进一步显著减少参数量: 一个滤波器只有
- 层次化特征提取 (Hierarchical Feature Learning):
- 是什么: CNN通常由多个卷积层堆叠而成。浅层卷积层学习低级、简单的特征(边缘、角点、颜色斑点)。这些低级特征被输入到下一层。深层卷积层组合低级特征,学习中级特征(纹理、基本部件如眼睛、轮子)。更深层则组合中级特征,学习高级、抽象、语义化的特征(整个物体如人脸、汽车、特定场景)。
- 为什么是本质: 这种由简单到复杂、由局部到全局的层次化结构,模拟了人类视觉系统处理信息的方式(V1 -> V2 -> V4 -> IT区),使得CNN能够理解图像中复杂的结构和语义信息。
- 对网格化数据的天然适配:
- 是什么: CNN特别擅长处理具有规则网格结构的数据,如图像(2D像素网格)、视频(2D空间+1D时间网格)、语音(1D时间序列或2D频谱图)。
- 为什么是本质: 卷积操作的滑动特性天然利用了数据点在空间或时间上的邻近性和结构关系。
- 局部连接 (Local Connectivity):
想象我们要设计一个程序,通过指纹图像识别不同的人。指纹的核心是脊线(Ridge)和谷线(Valley)构成的独特纹理模式。
-
低级特征检测(浅层卷积):
- 使用第一个卷积层,滤波器就像一个小型“边缘探测器”。它在指纹图像上滑动。
- 当它滑过脊线和谷线交界的地方(即脊线边缘)时,由于像素值变化剧烈(暗变亮或亮变暗),滤波器的点积运算会输出一个高响应值(表明检测到了边缘)。
- 这个滤波器在整个图像上共享权重,所以无论脊线边缘出现在指纹的哪个位置(中心还是边缘),它都能被检测到(平移不变性)。
- 这一层输出一个“边缘激活图”,亮的地方表示检测到了脊线边缘。
-
中级特征检测(中层卷积):
- 第二层卷积接收第一层的“边缘激活图”作为输入。
- 它的滤波器更大一些,可以覆盖第一层输出的一个小区域(即原始图像中更大的区域)。
- 这一层的滤波器学习识别由多个边缘片段构成的基本纹理单元,比如一小段弯曲的脊线、一个短的分叉点、或者一个小环。
- 同样,这些检测脊线分叉、小环的滤波器在整个图像上权值共享,无论这些特征出现在哪里都能被检测到。
-
高级特征与识别(深层卷积 + 全连接):
- 更深层的卷积层组合中层检测到的纹理单元(分叉、环、端点),学习识别更复杂的指纹特征,如一个完整的“斗型纹”、“箕型纹”的核心区域,或者一个显著的“三角区”。
- 最后,这些高级的、抽象的特征图会被展平,送入全连接层。
- 全连接层学习这些高级特征的特定组合模式,每种模式对应一个特定的人(或指纹ID)。它判断检测到的斗型核心、三角区位置、脊线流向等特征组合是否与数据库中张三的指纹模式高度匹配。
在这个过程中,CNN的本质体现得淋漓尽致:
- 卷积操作: 逐层滑动滤波器,检测局部模式。
- 局部连接 & 权值共享: 每个特征检测器只关注一小块区域,且同一模式检测器(如边缘、分叉点检测器)在整个指纹上复用,大大降低了计算量和参数量。
- 平移不变性: 无论指纹图像在输入时是居中还是稍微偏移,只要脊线模式相同,CNN都能正确识别张三,因为检测关键特征的滤波器在图像任何位置都有效。
- 层次化特征: 从边缘(低级) -> 分叉/环(中级) -> 斗型/三角区(高级) -> 个体指纹模式(语义级),逐步抽象。
-
AIGC (生成式人工智能):
- 应用场景: 图像生成(Stable Diffusion, DALL-E)、视频生成(Sora)、音乐生成(频谱图)、图像超分辨率、图像修复、风格迁移。
- CNN本质的应用:
- 核心骨干: 大多数生成模型(如GAN的判别器/生成器、Diffusion Model的U-Net)深度依赖CNN(或其变体如ConvNeXt)作为特征提取器。
- 空间特征理解: 在图像/视频生成中,CNN编码器负责理解输入文本描述或噪声图像的空间结构和语义内容(低级纹理到高级物体)。解码器(通常是转置卷积)则利用学到的层次化特征在空间上“绘制”出符合语义和结构的像素,从粗糙轮廓到精细细节。
- 平移不变性 & 局部性: 确保生成的物体可以合理地出现在画面的不同位置,并且局部细节(如毛发、砖缝)是连贯的。
- 案例: Stable Diffusion 的 U-Net 使用CNN层处理图像潜空间表示,在去噪过程中逐步恢复图像的层次化结构(从模糊的全局结构到清晰的局部细节),同时条件机制(如文本嵌入)通过交叉注意力引导CNN特征生成符合描述的特定内容。
-
传统深度学习 (计算机视觉为主):
- 应用场景: 图像分类(ResNet, ViT虽流行但CNN仍是基础)、目标检测(YOLO, Faster R-CNN)、语义分割(U-Net, DeepLab)、人脸识别、图像描述生成(CNN + RNN/LSTM)。
- CNN本质的应用:
- 基石模型: CNN是计算机视觉领域近十年爆发的核心驱动力。ImageNet竞赛的优胜者(AlexNet, VGG, GoogLeNet, ResNet)都是CNN架构的演进。
- 高效特征提取: 利用局部连接、权值共享和层次化结构,CNN能从海量图像数据中高效地自动学习强大的视觉特征表示,替代了手工设计特征(如SIFT, HOG)。
- 平移不变性: 这是CV任务的关键需求。CNN天然保证检测到的物体(如猫、车)在图像中发生平移时,仍能被正确识别。
- 层次化理解: 从像素级边缘到物体级语义,CNN的特征图天然适合不同粒度的任务:分类(高级特征)、检测(中级特征定位+高级特征分类)、分割(需要保留空间信息的各级特征)。
- 案例: YOLO目标检测器。其骨干网络(如DarkNet)是CNN,负责从输入图像提取层次化特征图。不同尺度的特征图用于检测不同大小的物体(浅层特征图分辨率高,利于检测小物体;深层特征图语义强,利于检测大物体)。检测头利用这些特征图上的卷积操作,直接在网格单元上预测边界框和类别。
-
自动驾驶:
- 应用场景: 环境感知(摄像头/激光雷达目标检测、分割、车道线检测)、可行驶区域分割、传感器融合(图像+雷达/激光雷达)、端到端驾驶(输入图像直接输出控制指令)。
- CNN本质的应用:
- 感知的核心: 基于摄像头的感知系统几乎完全建立在CNN(及其3D/时序扩展)之上。处理激光雷达点云(投影为2D俯视图或多视图)也常用CNN。
- 处理高维空间数据: 摄像头图像是2D网格,激光雷达投影图也是2D网格。CNN的局部连接和权值共享特性使其成为处理这些高分辨率、高维度传感器数据的首选架构,能在有限的车载计算资源下高效运行。
- 平移不变性 & 空间理解: 对自动驾驶至关重要!无论车辆、行人、交通标志出现在视野中的哪个位置(左/右/远/近),CNN都能可靠地检测和识别它们。CNN强大的空间特征提取能力对于理解道路结构(车道线、路沿)、可行驶区域至关重要。
- 层次化特征用于不同任务: 低级特征(边缘)用于车道线检测;中级特征(车轮、车窗)用于车辆检测;高级特征(整个车辆、行人轮廓)用于目标分类和跟踪。多任务学习常共享CNN骨干提取的丰富特征。
- 时序/3D扩展: 处理视频流(时序信息)使用3D卷积或CNN+RNN,在空间卷积基础上增加时间维度,检测运动物体。处理原始点云使用3D稀疏卷积或投影后2D卷积。
- 案例: Tesla的HydraNet。它使用一个大型共享的CNN骨干网络(如ResNet变体)同时处理多个摄像头输入。骨干网络提取丰富的空间特征。然后,多个不同的任务特定“头”(也是CNN结构)连接到骨干的不同层次特征上,并行执行各种感知任务(车辆检测、行人检测、车道线分割、交通灯识别、深度估计等)。CNN的效率和层次化特征提取能力是实现这种高效多任务感知系统的关键。
卷积神经网络的本质优势在于其利用卷积操作,通过局部连接、权值共享实现了参数效率和计算效率,并赋予了模型关键的平移不变性。其层次化堆叠的结构使其能够从数据中自动学习从低级到高级的抽象特征表示,特别适合于处理具有空间或时序局部相关性和网格结构的数据(图像、视频、语音、点云等)。
在AIGC领域,CNN是理解和生成空间内容(图像、视频)的骨干,实现从文本到像素的精确空间映射和细节合成。在传统深度学习(CV) 领域,CNN是基石,彻底革新了特征提取方式,推动了图像理解任务的飞跃。在自动驾驶领域,CNN是环境感知系统的核心引擎,高效处理高维传感器数据,实现对周围世界可靠的空间理解,是行车安全的关键保障。理解CNN的本质,是驾驭现代AI,尤其在视觉相关领域,不可或缺的基础。