- 1.图像中低频信息和高频信息的定义
- 2.色深的概念
- 3.RAW图像和RGB图像的区别?
- 4.常用的色彩空间格式
- 5.什么是图像畸变?
- 6.什么是信噪比
- 7.透明图和常规图像的区别是什么?
- 8.什么是图像的位数?
- 9.什么是图像的DPI?
- 1.介绍一下图像二值化的原理
- 2.图像膨胀腐蚀的相关概念
- 3.高斯滤波的相关概念
- 4.边缘检测的相关概念
- 5.图像高/低通滤波的相关概念
- 6.常用空间平滑技术
- 7.仿射变换和透视变换的概念?
- 8.图像噪声的种类?
- 9.有哪些常用的图像去噪算法?
- 10.有哪些常用的图像频域信息分离方法?
- 11.有哪些常用一阶微分梯度算子?
- 12.拉普拉斯算子的相关概念
- 13.中值滤波与均值滤波的相关概念
- 14.介绍一下图像形态学扩张的原理
- 15.AIGC时代有哪些主流的图像插值算法?各自的优缺点是什么?
- 1.模型训练时常用的插值算法?
- 2.常用图像预处理操作?
- 3.有哪些常用的图像质量评价指标?
- 4.RGB图像转为灰度图的方法?
- 5.Python中OpenCV和PIL的区别?
- 6.OpenCV读取图像的格式?
- 7.什么是FID图像评估指标?
- 8.什么是SSIM图像评估指标?
- 9.什么是PSNR图像评估指标?
低频信息(低频分量):表示图像中灰度值变化缓慢的区域,对应着图像中大块平坦的区域。
高频信息(高频分量):表示图像中灰度值变化剧烈的区域,对应着图像的边缘(轮廓)、噪声(之所以说噪声也是高频分量,是因为图像噪声在大部分情况下都是高频的)以及细节部分。
低频分量主要对整幅图像强度的综合度量。高频分量主要对图像边缘和轮廓的度量(人眼对高频分量比较敏感)。
傅立叶变换角度理解:从傅立叶变换的角度,我们可以将图像从灰度分布转化为频率分布。图像进行傅立叶变换之后得到的频谱图,就是图像梯度的分布图。具体来说,傅立叶频谱图上我们能看到明暗不一的亮点,实际上就是图像上某一点与领域点差异的强弱,即梯度的大小。如果一幅图像的各个位置的强度大小相等,则图像只存在低频分量。从图像的频谱图上看,只有一个主峰,且位于频率为零的位置。如果一幅图像的各个位置的强度变化剧烈,则图像不仅存在低频分量,同时也存在多种高频分量。从图像的频谱上看,不仅有一个主峰,同时也存在多个旁峰。图像中的低频分量就是图像中梯度较小的部分,高频分量则相反。
色深(Color Depth)指的是色彩的深度,即精细度。在数字图像中,最小的单元是像素,在RGB三通道图像中,每个像素都由R,G,B三个通道组成,通常是24位的二进制位格式来表示。这表示颜色的2进制位数,就代表了色深。
RAW格式: 从相机传感器端获取的原始数字格式的数据, 又称为Bayer格式. 每个像素信息只有RGB中的某个颜色信息, 且每4个像素中有2个像素为G信息,1个R信息,1个B信息, 即GRBG格式。
RGB格式: RGB格式是由RAW数据插值计算后获取的、每个像素均包含了RGB三种颜色的信息。
深度学习中常用的色彩空间格式:RGB,RGBA,HSV,HLS,Lab,YCbCr,YUV等。

RGB色彩空间以Red(红)、Green(绿)、Blue(蓝)三种基本色为基础,进行不同程度的叠加,产生丰富而广泛的颜色,所以俗称三基色模式。
RGBA是代表Red(红)、Green(绿)、Blue(蓝)和Alpha(透明度)的色彩空间。
HSV色彩空间(Hue-色调、Saturation-饱和度、Value-亮度)将亮度从色彩中分解出来,在图像增强算法中用途很广。
HLS色彩空间,三个分量分别是色相(H)、亮度(L)、饱和度(S)。
Lab色彩空间是由CIE(国际照明委员会)制定的一种色彩模式。自然界中任何一点色都可以在Lab空间中表达出来,它的色彩空间比RGB空间还要大。
YCbCr进行了图像子采样,是视频图像和数字图像中常用的色彩空间。在通用的图像压缩算法中(如JPEG算法),首要的步骤就是将图像的颜色空间转换为YCbCr空间。
YUV色彩空间与RGB编码方式(色域)不同。RGB使用红、绿、蓝三原色来表示颜色。而YUV使用亮度、色度来表示颜色。
使用摄像头时,可能会出现图像边缘线条弯曲的情况,尤其是边缘部分是直线时,这种现象更为明显。比如摄像头显示画面中的门框、电线杆、墙面棱角、吊顶线等出现在边缘时,可能会有比较明显的弯曲现象,这种现象就叫做畸变。
畸变是指光学系统对物体所成的像相对于物体本身而言的失真程度,是光学透镜的固有特性,其直接原因是因为镜头的边缘部分和中心部分的放大倍率不一样导致。畸变并不影响像的清晰程度,只改变物体的成像形状,畸变是一种普遍存在的光学现象。

信噪比(SNR)是用来衡量信号强度与噪声强度相对大小的指标。在图像处理中,信号通常指的是有用的图像信息,而噪声则是无用的或干扰图像的成分。信噪比高表示图像中的有用信息远多于噪声,信噪比低则表示图像中噪声较多。
信噪比的计算通常表示为信号功率与噪声功率之比,常用的计算公式如下:
$$ \mathrm{SNR}=10\log_{10}\left(\frac{P_{\mathrm{signal}}}{P_{\mathrm{noise}}}\right) $$ 其中,P_signal是信号的功率,P_noise 是噪声的功率。信噪比的单位是分贝(dB)。
在图像处理中,信噪比也可以通过像素值的均方差来计算:
$$ \mathrm{SNR}=10\log_{10}\left(\frac{\mu_{\mathrm{signal}}^2}{\sigma_{\mathrm{noise}}^2}\right) $$ 其中,μ_signal是图像信号的平均值,σ_noise 是噪声的标准差。
- 图像质量评估:高信噪比表示图像质量好,因为图像中有用信息占比高,噪声少。
- 图像去噪:去噪算法的效果可以通过信噪比来评估,去噪后图像的信噪比越高,说明去噪效果越好。
- 图像增强:在图像增强处理中,提高信噪比是一个重要目标,以确保增强后的图像清晰度和细节保留。
透明图像与常规图像的主要区别在于它们的颜色信息中是否包含透明度(即 Alpha 通道)。这种区别在视觉效果和文件结构上都有明显的体现。
-
透明图像:透明图像包含 Alpha 通道,除了红色(Red)、绿色(Green)、蓝色(Blue)这三个基本颜色通道外,Alpha 通道用于存储每个像素的透明度信息。透明度通常以 0(完全透明)到 255(完全不透明)的范围表示。常见的支持透明度的图像格式有 PNG、GIF 和 WebP。
- 例子:一张 PNG 图像中某些部分是完全透明的,因此在浏览器或图片查看器中查看时,这些部分可能会显示为背景颜色或背景图像,而非实际颜色。
-
常规图像:普通图像没有 Alpha 通道,只包含 RGB(红、绿、蓝)三个颜色通道,每个像素都是完全不透明的。常见的图像格式如 JPEG、BMP 通常不支持透明度。
- 例子:一张 JPEG 图像是完全不透明的,每个像素都有其特定的颜色。如果你将这种图像放在网页上,它会遮挡住所有在其下方的内容。
-
透明图像:
- 可以显示部分透明或完全透明的区域,这样图像就可以与背景或其他元素自然地融合。
- 适用于图标、标志或需要与不同背景组合的图像。
-
常规图像:
- 所有像素都是不透明的,不管在什么背景下显示,图像的内容都会完全覆盖其下方的背景。
- 适合用于照片或不需要透明效果的图像。
-
支持透明度的格式:如 PNG、GIF、WebP。
- PNG 是最常见的支持透明度的格式,适用于需要无损压缩的高质量图像。
- GIF 也支持透明度,但通常只支持单一透明度级别(即完全透明或完全不透明)。
- WebP 是一种现代图像格式,支持透明度并且通常比 PNG 更高效。
-
不支持透明度的格式:如 JPEG、BMP。
- JPEG 是一种常见的图像格式,适用于照片等需要有损压缩的小文件。
- BMP 是一种老式的无压缩图像格式,不支持透明度。
-
透明图像:
- 由于包含额外的 Alpha 通道,通常文件大小会比同样分辨率的普通图像更大,特别是在 PNG 格式下。
- 文件大小可能会根据透明区域的复杂程度而变化。
-
常规图像:
- 通常文件大小较小,尤其是在使用 JPEG 格式进行有损压缩时。
-
透明图像:
- 常用于需要与背景结合的图像,如网站图标、LOGO、UI元素等。
- 适合需要部分透明效果或不规则边缘的图像,比如水印、剪贴画等。
-
常规图像:
- 更适合用于照片、壁纸、封面等不需要透明度的场景。
-
透明图像 (PNG):
- 如果你将一张透明的 PNG 图像放在一个有颜色的背景上,你会看到背景透过图像的透明区域显示出来。
-
普通图像 (JPEG):
- 如果你将一张 JPEG 图像放在同样的背景上,整个图像区域都是不透明的,背景会被完全覆盖。
图像的位数(bit depth) 是一个非常重要的概念,它指的是图像中每个像素所使用的二进制位数(bit)来表示颜色或灰度值。位数越高,每个像素可以表达的颜色或灰度级别就越多,图像的色彩表现力也越丰富。
根据图像的位数,图像可以分为以下几种常见类型:
- 每个像素1位:1位图像每个像素只能用1个二进制位来表示,因此它只能表示2种状态:0或1。
- 颜色表示:通常是黑白图像。0表示黑色,1表示白色。
- 应用场景:这种图像常用于简单的图形设计或文本图像(如条形码、QR码)。
- 每个像素8位:8位图像每个像素有8个二进制位,因此可以表示 (2^8 = 256) 种颜色或灰度级别。
- 灰度图像:在灰度图像中,8位图像表示从0(黑色)到255(白色)之间的256个灰度级别。
- 应用场景:常用于单通道灰度图像,或具有256种颜色的彩色图像(通常为调色板图像,使用特定的颜色表)。
- 每个像素24位:24位图像每个像素有24个二进制位,通常分为三个8位的部分,每个部分表示一个颜色通道:红色(Red)、绿色(Green)和蓝色(Blue)。
- 颜色表示:每个通道的8位可以表示256种颜色,因此总共可以表示 (256 \times 256 \times 256 = 16,777,216) 种颜色,即通常所说的“真彩色”。
- 应用场景:这种图像被广泛用于显示器、摄影、网页设计等需要丰富颜色表现的场景。
- 每个像素32位:32位图像在24位图像的基础上,增加了8位的透明度通道(Alpha通道),即RGBA模式。
- 透明度表示:Alpha通道用来表示像素的透明度,0表示完全透明,255表示完全不透明。
- 应用场景:用于需要处理透明图像的场景,比如图像合成、视频编辑、图形设计等。
- 更高位数:48位图像通常意味着每个通道有16位(即总共有3个通道×16位=48位),而64位图像则通常用于高动态范围(HDR)图像,每个通道有16位或32位。
- 高色深:这种图像可以表示更丰富的颜色梯度,非常适合需要高度精确颜色表现的专业图形设计、医学成像或科学数据可视化等领域。
- 颜色范围(Color Range):随着图像位数的增加,图像可以表现的颜色或灰度范围变得更广。例如,8位图像的每个通道只能表示256种颜色,而16位图像的每个通道可以表示65536种颜色。
- 色带效应(Banding Effect):低位数图像在颜色渐变区域可能出现色带效应(即明显的颜色分界线),这是因为颜色过渡不够平滑。高位数图像可以减少这种效应,提供更平滑的色彩渐变。
- 文件大小:图像的位数越高,每个像素所需的存储空间也就越大,因此图像文件的大小也会随之增加。例如,同样大小的图像,32位图像比24位图像的文件大小要大得多。
- 计算和处理复杂度:高位数图像在处理和计算时需要更多的资源,特别是在图像编辑、渲染等涉及大量像素操作的场景中。
DPI 是英文 Dots Per Inch 的缩写,中文称为每英寸点数或每英寸像素数。它是用于衡量图像分辨率和打印质量的一个指标,表示在一英寸长度内包含的点(像素)数量。
- 物理意义:DPI 描述了图像在物理尺寸下的清晰度和细节程度。高 DPI 表示图像在单位长度内有更多的像素,细节更丰富。
- 与 PPI 的区别:PPI(Pixels Per Inch) 通常用于显示设备,表示屏幕每英寸的像素数。尽管在某些情况下,DPI 和 PPI 可以互换使用,但严格来说,DPI 更侧重于打印分辨率,而 PPI 侧重于屏幕分辨率。
- 高 DPI:在打印过程中,较高的 DPI(如 300 DPI 或更高)意味着打印出的图像更清晰、细节更丰富,适用于高质量的照片和专业印刷品。
- 低 DPI:较低的 DPI(如 72 DPI 或 96 DPI)适用于屏幕显示或大幅面印刷品,因为观看距离较远,对细节的要求较低。
-
物理尺寸计算:图像的物理尺寸(以英寸为单位)可以通过图像的像素尺寸除以 DPI 计算。
$$\text{物理尺寸(英寸)} = \frac{\text{像素尺寸(像素)}}{\text{DPI}}$$ -
示例:如果一幅图像的宽度为 3000 像素,DPI 为 300,那么打印出来的物理宽度为:
$$\frac{3000 \text{ 像素}}{300 \text{ DPI}} = 10 \text{ 英寸}$$
- 高质量印刷品:杂志、画册、摄影作品等通常要求图像达到 300 DPI 以上,以确保打印质量。
- 普通文档打印:一般办公文档、草稿等可使用 150 DPI 至 200 DPI。
- 大型广告牌:由于观看距离远,可以使用较低的 DPI(如 30 DPI 至 72 DPI),但仍能获得良好的视觉效果。
- 扫描仪设置:扫描仪的 DPI 设置决定了数字化图像的分辨率。扫描照片或高细节文档时,可能需要 600 DPI 或更高。
- 数字存档:对于需要长期保存的文件,较高的 DPI 可以确保细节完整,便于日后查看和打印。
- 相机输出:数码相机拍摄的照片通常以像素为单位,但在导出或打印时,需要指定 DPI。
- 图像编辑软件:在处理和导出图像时,设置正确的 DPI 有助于在不同媒介上获得期望的显示效果。
- 误解:提高图像的 DPI 会增加文件大小。
- 事实:DPI 是图像的元数据,不影响图像的像素总数和文件大小。文件大小主要由像素尺寸和压缩率决定。
- 误解:增加图像的 DPI 可以让其在屏幕上显示得更清晰。
- 事实:屏幕显示主要取决于图像的像素尺寸和屏幕的 PPI。调整 DPI 不会改变屏幕上的显示效果。
- 误解:改变图像的 DPI 会提升或降低图像质量。
- 事实:如果不重新采样图像,仅改变 DPI 不会影响图像质量。图像质量取决于像素数量和内容细节。
图像的二值化是将灰度图像转换为只有两种像素值(通常是 0 和 255)的二值图像的过程。二值化的目的是简化图像数据,使后续处理(如边缘检测、形状分析)更加高效。二值化过程通常基于一个阈值(threshold)来决定每个像素的类别。
-
输入图像:
- 通常是灰度图像,每个像素的值在 0 到 255 之间(8 位图像)。
- 例如,一个像素值为 0 表示纯黑,255 表示纯白,中间值表示灰度级别。
-
输出图像:
- 每个像素的值只有两种可能:0(黑色) 或 255(白色)。
-
阈值操作:
- 对每个像素值
$I(x, y)$ 进行判断:
- 对每个像素值
其中
- 选用一个固定阈值
$T$ 。 - 优点:简单易用,计算量低。
- 缺点:对光照变化敏感,适用于背景均匀的图像。
import cv2
import numpy as np
# 读取灰度图像
img = cv2.imread('image.jpg', cv2.IMREAD_GRAYSCALE)
# 固定阈值法
_, binary = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
cv2.imshow('Binary Image', binary)
cv2.waitKey(0)
cv2.destroyAllWindows()- 根据图像局部的像素值动态确定阈值。
- 优点:适用于背景光照不均匀的情况。
- 两种常用方法:
- 均值法:阈值是邻域像素的平均值。
- 高斯加权法:阈值是邻域像素的加权平均值(权重由高斯分布决定)。
# 自适应阈值法
adaptive_binary = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2)- 自动计算全局阈值
$T$ ,最大化前景和背景之间的类间方差。 - 优点:无需手动设置阈值,适用于双峰直方图。
- 缺点:对多峰图像表现较差。
# Otsu 阈值法
_, otsu_binary = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)- 结合局部和全局特性,动态调整阈值。
- 用于复杂场景和不均匀光照。
选择适当的阈值
-
固定阈值:
- 手动设定,如
$T = 127$ 。 - 适用于背景亮度均匀的图像。
- 手动设定,如
-
直方图分析:
- 通过观察图像灰度直方图,选择双峰之间的分割点。
-
Otsu 方法:
- 自动计算阈值,使前景和背景的类间方差最大。
-
局部方法:
- 动态根据图像局部特性确定阈值。
- 对比度: 前景与背景的区分是否明显。
- 噪声处理: 是否存在孤立噪声点。
- 目标完整性: 前景目标是否被正确分割。
整体上,图像二值化在AIGC、传统深度学习以及自动驾驶领域都广泛应用。
- OCR(光学字符识别):
- 通过二值化提取文字区域。
- 边缘检测:
- 提前简化图像数据。
- 物体检测:
- 二值化后的图像便于轮廓提取。
- 医学影像处理:
- 用于分割特定区域。
假设灰度图像如下:
- 假设
$T = 120$ ,结果为:
- 简化图像数据: 降低计算复杂度。
- 突出目标区域: 明确前景与背景的界限。
- 易于后续处理: 便于形态学、轮廓检测等操作。
- 对光照和噪声敏感,尤其是全局阈值法。
- 无法处理多目标或多峰分布图像。

图像的膨胀(dilation)和腐蚀(erosion)是两种基本的形态学运算,主要用来寻找图像中的极大区域和极小区域。
膨胀类似于“领域扩张”,将图像的高亮区域或白色部分进行扩张,其运行结果图比原图的高亮区域更大。
腐蚀类似于“领域被蚕食”,将图像中的高亮区域或白色部分进行缩减细化,其运行结果图比原图的高亮区域更小。
图像为什么要滤波呢?一是为了消除图像在数字化过程中产生或者混入的噪声。二是为了提取图片对象的特征作为图像识别的特征模式。
什么是高斯噪声?首先,噪声在图像当中常表现为引起较强视觉效果的孤立像素点或像素块。简单来说,噪声的出现会给图像带来干扰,让图像变得不清楚。 高斯噪声就是它的概率密度函数服从高斯分布(即正态分布)的一类噪声。如果一个噪声,它的幅度分布服从高斯分布,而它的功率谱密度又是均匀分布的,则称它为高斯白噪声。
高斯滤波是一种线性平滑滤波,可以用来消除高斯噪声。其公式如下所示

高斯滤波过程: 假设高斯核:
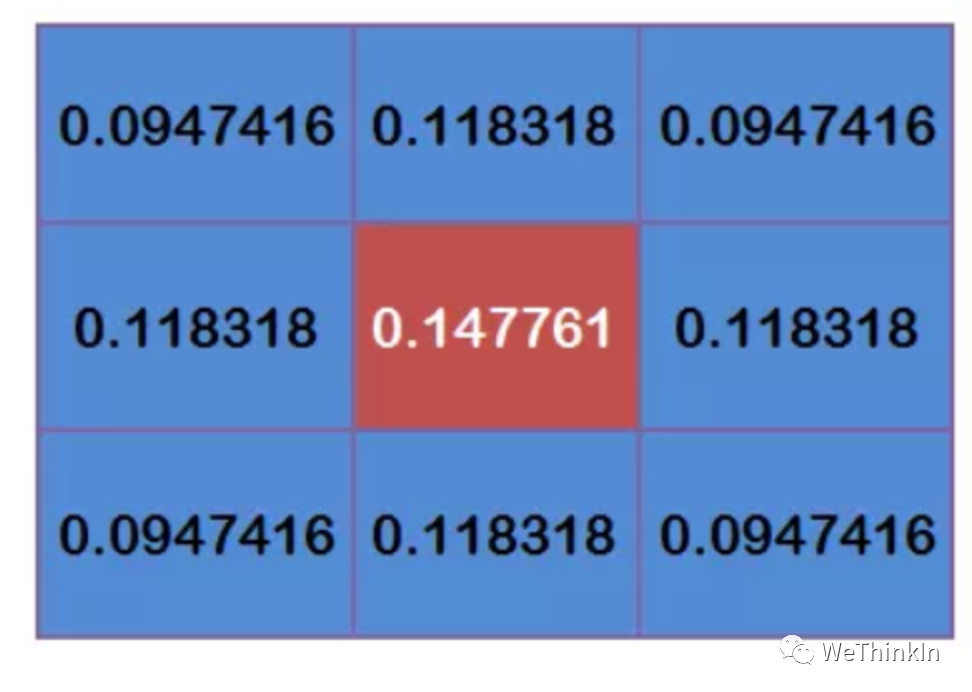
那么高斯滤波计算过程就如下所示:

将这9个值加起来,就是中心点的高斯滤波的值。对所有点重复这个过程,就得到了高斯模糊后的图像。
二维高斯滤波能否分解为一维操作?可以进行分解,二维高斯滤波分解为两次一维高斯滤波,高斯二维公式可以推导为X轴与Y轴上的一维高斯公式。即使用一维高斯核先对图像逐行滤波,再对中间结果逐列滤波。
图像边缘是图像最基本的特征,指图像局部特征的不连续性。图像特征信息的突变处称之为边缘,例如灰度级的突变,颜色的突变,纹理结构的突变等。边缘是一个区域的结束,也是另一个区域的开始,利用该特征可以分割图像。
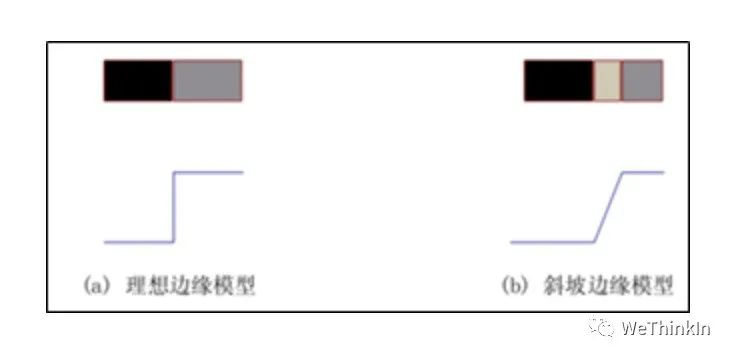
当我们看到一个有边缘的物体时,首先感受到的就是边缘。
上图(a)是一个理想的边缘所具备的特性。每个灰度级跃变到一个垂直的台阶上。而实际上,在图像采集系统的性能、采样率和获取图像的照明条件等因素的影响,得到的边缘往往是模糊的,边缘被模拟成具有“斜坡面”的剖面,如上图(b)所示,在这个模型中,模糊的边缘变得“宽”了,而清晰的边缘变得“窄”了。
图像的边缘有方向和幅度两种属性。边缘通常可以通过一阶导数或二阶导数检测得到。一阶导数是以最大值作为对应的边缘的位置,而二阶导数则以过零点作为对应边缘的位置。
常用的一阶导数边缘算子:Roberts算子、Sobel算子和Prewitt算子。
常用的二阶导数边缘算子:Laplacian 算子,此类算子对噪声敏感。
其他边缘算子:前面两类均是通过微分算子来检测图像边缘,还有一种就是Canny算子,其是在满足一定约束条件下推导出来的边缘检测最优化算子。
滤波操作是一种非常实用的图像数据预处理方法。滤波是一个信号处理领域的概念,而图像本身也可以看成是一个二维的信号,其中像素点数值的高低代表信号的强弱。
其中图像信息可以分为高频和低频两个维度:
高频:图像中灰度变化剧烈的点,一般是图像轮廓或者是噪声。
低频:图像中平坦的、变化不大的点,也就是图像中的大部分区域。
根据图像的高频与低频的特征,我们可以设计相应的高通与低通滤波器,高通滤波器可以检测保留图像中尖锐的、变化明显的地方。而低通滤波器可以让图像变得更光滑,去除图像中的噪声。
常见的低通滤波器有:线性的均值滤波器、高斯滤波器、非线性的双边滤波器、中值滤波器。
常见的高通滤波器有:Canny算子、Sobel算子、拉普拉斯算子等边缘滤波算子。
空间平滑(模糊)技术是广泛应用于图像处理以降低图像噪声的技术。 空间平滑技术可以分为两大类:局部平滑(Local Smoothing)和非局部平滑(Non-local Smoothing) 局部平滑方法利用附近的像素来平滑每个像素。通过设计不同的加权机制,产生了很多经典的局部平滑方法,例如高斯Smoothing,中值Smoothing,均值Smooyhing等。
而非局部平滑方法不限于附近的像素,而是使用图像全局中普遍存在的冗余信息进行去噪。具体来说,以较大的图像块为单位在图像中寻找相似区域,再对这些区域求平均,并对中心图像块进行替换,能够较好地去掉图像中的噪声。在平均操作中,可以使用高斯,中位数以及均值等对相似图像块进行加权。
仿射变换是对图片进行平移,缩放,倾斜和旋转等操作,是一种二维坐标到二维坐标之间的线性变换。它保持了二维图形的“平直性”(直线经过变换之后依然是直线)和“平行性”(二维图形之间的相对位置关系保持不变,平行线依然是平行线,且直线上点的位置顺序不变)。
透视变换是将图片投影到一个新的视平面,也称作投影映射。它是将二维图片投影到三维空间,再投回另一个二维空间的映射操作。
仿射变换和透视变换的最大区别:一个平行四边形,经过仿射变换后依然是平行四边形;而经过透视变换后只是一个四边形(不再平行了)。
- 高斯噪声
- 脉冲噪声
- 泊松噪声
- 乘性噪声
- 瑞利噪声
- 伽马噪声
- 指数噪声
- 均匀噪声
- 椒盐噪声
- 散粒噪声
- 泊松噪声
- 白盒对抗噪声
- 黑盒查询对抗噪声
- 黑盒迁移噪声
- 物理对抗噪声
- 空间域去噪:均值滤波器,中值滤波器,低通滤波器,高斯滤波,双边滤波,引导滤波,NLM(Non-Local means)算法等。
- 频域去噪:小波变换,傅里叶变换,离散余弦变换,形态学滤波等。
可以使用频域滤波器如小波变换,傅里叶变换,余弦变换,形态学滤波等方法将图像高低频信息分离。
想要得到一张图像的梯度,要在图像的每个像素点处计算偏导数。因此一张图像$f$在$(x,y)$位置处的$x$和$y$方向上的梯度大小$g_{x}$和$g_{y}$分别计算为:
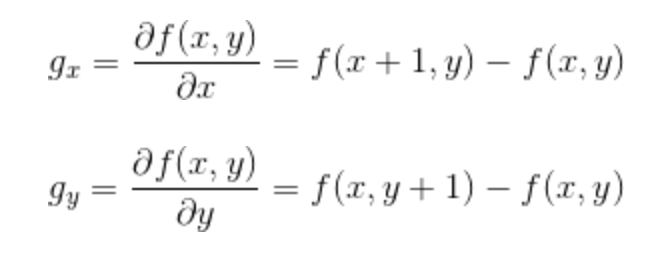
上述两个公式对所有的$x$和$y$的计算值可用下面的一维模版对$f(x,y)$的滤波得到。
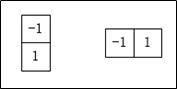
用于计算梯度偏导数的滤波器模版,通常称之为梯度算子、边缘算子和边缘检测子等。
Roberts算子
Roberts算子又称为交叉微分算法,它是基于交叉差分的梯度算法,通过局部差分计算检测边缘线条。常用来处理具有陡峭的低噪声图像,当图像边缘接近于正45度或负45度时,该算法处理效果更理想。其缺点是对边缘的定位不太准确,提取的边缘线条较粗。
Roberts算子的模板分为水平方向和垂直方向,如下式所示,从其模板可以看出,Roberts算子能较好的增强正负45度的图像边缘。
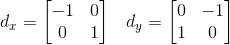
例如,下面给出Roberts算子的模板,在像素点$P5$处$x$和$y$方向上的梯度大小$g_{x}$和$g_{y}$分别计算为:


下图是Roberts算子的运行结果:

Prewitt算子
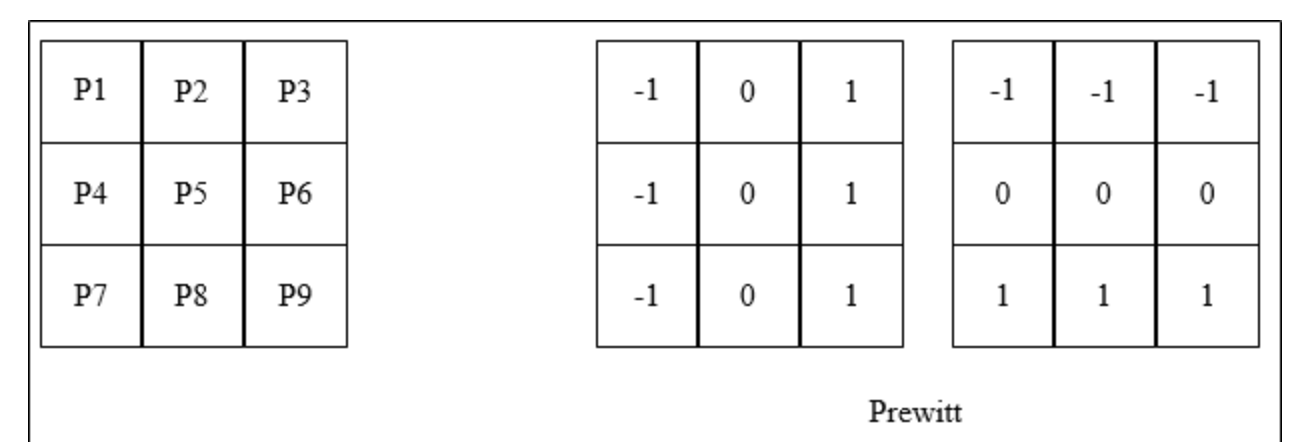
Prewitt算子是一种图像边缘检测的微分算子,其原理是利用特定区域内像素灰度值产生的差分实现边缘检测。由于Prewitt算子采用$3\times3$卷积模板对区域内的像素值进行计算,而Robert算子的模板为$2\times2$,故Prewitt算子的边缘检测结果在水平方向和垂直方向均比Robert算子更加明显。Prewitt算子适合用来识别噪声较多、灰度渐变的图像,其计算公式如下所示:

例如,下面给出Prewitt算子的模板,在像素点$P5$处$x$和$y$方向上的梯度大小$g_{x}$和$g_{y}$分别计算为:
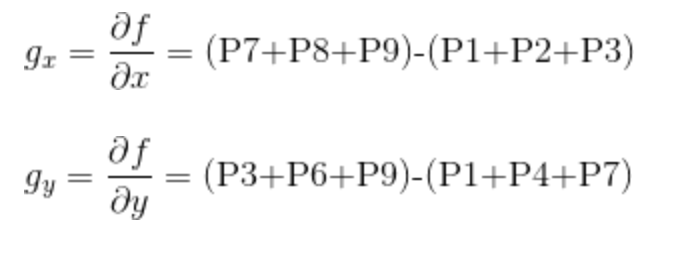
Prewitt算子运行结果如下:

Sobel算子
Sobel算子是一种用于边缘检测的离散微分算子,它结合了高斯平滑和微分求导。该算子用于计算图像明暗程度近似值,根据图像边缘旁边明暗程度把该区域内超过某个数的特定点记为边缘。Sobel算子在Prewitt算子的基础上增加了权重的概念,认为相邻点的距离远近对当前像素点的影响是不同的,距离越近的像素点对应当前像素的影响越大,从而实现图像锐化并突出边缘轮廓。
Sobel算子根据像素点上下、左右邻点灰度加权差,在边缘处达到极值这一现象检测边缘。对噪声具有平滑作用,提供较为精确的边缘方向信息。因为Sobel算子结合了高斯平滑和微分求导(分化),因此结果会具有更多的抗噪性,当对精度要求不是很高时,Sobel算子是一种较为常用的边缘检测方法。
Sobel算子的边缘定位更准确,常用于噪声较多、灰度渐变的图像。其算法模板如下面的公式所示,其中$d_{x}$表示水平方向,$d_{y}$表示垂直方向。
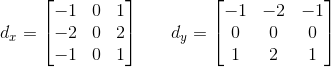
例如,下面给出Sobel算子的模板,在像素点$P5$处$x$和$y$方向上的梯度大小$g_{x}$和

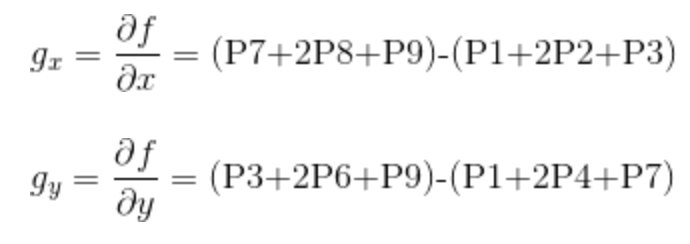
sobel算子的效果如下:

Roberts算子
Roberts算子利用局部差分算子寻找边缘,边缘定位精度较高,但容易丢失一部分边缘,不具备抑制噪声的能力。该算子对具有陡峭边缘且含噪声少的图像效果较好,尤其是边缘正负45度较多的图像,但定位准确率较差。
Sobel算子
Sobel算子考虑了综合因素,对噪声较多的图像处理效果更好,Sobel 算子边缘定位效果不错,但检测出的边缘容易出现多像素宽度。
Prewitt算子
Prewitt算子对灰度渐变的图像边缘提取效果较好,而没有考虑相邻点的距离远近对当前像素点的影响,与Sobel 算子类似,不同的是在平滑部分的权重大小有些差异。
拉普拉斯算子是一个二阶算子,比起一阶微分算子,二阶微分算子的边缘定位能力更强,锐化效果更好。
使用二阶微分算子的基本方法是定义一种二阶微分的离散形式,然后根据这个形式生成一个滤波模版,与图像进行卷积。
滤波器分各向同性滤波器和各向异性滤波器。各向同性滤波器与图像进行卷积时,图像旋转后响应不变,说明滤波器模版自身是对称的。如果是各向异性滤波器,当原图旋转90度时,原图某一点能检测出细节(突变)的,但是现在却检测不出来了,这说明滤波器不是对称的。由于拉普拉斯算子是最简单的各向同性微分算子,它具有旋转不变形。
对于二维图像$f(x,y)$,二阶微分最简单的定义(拉普拉斯算子定义):
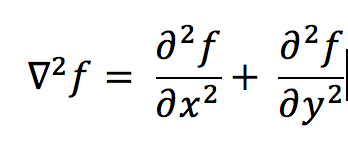
对于任意阶微分算子都是线性算子,所以二阶微分算子和后面的一阶微分算子都可以用生成模版然后卷积的方式得出结果。
根据前面对二阶微分的定义有:

根据上面的定义,与拉普拉斯算子的定义相结合,我们可以得到:
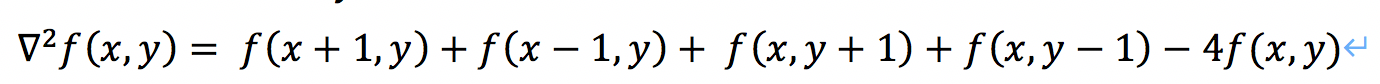
也就是一个点的拉普拉斯的算子计算结果是上下左右的灰度和减去本身灰度的四倍。同样,可以根据二阶微分的不同定义,所有符号相反,也就是上式所有灰度值全加上负号,就是-1,-1,-1,-1,4。但是我们要注意,符号改变,锐化的时候与原图的加或减应当相对变化。上面是四临接的拉普拉斯算子,将这个算子旋转45度后与原算子相架,就变成了八邻域的算子了,也就是一个像素周围一圈8个像素的和与中间像素8倍的差,作为拉普拉斯计算结果。
因为要强调图像中突变(细节),所以平滑灰度的区域,无响应,即模版系数的和为0,也是二阶微分的必备条件。
最后的锐化公式:
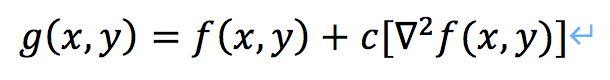
其中,$g$是输出,$f$为原始图像,$c$是系数,用来对细节添加的多少进行调节。
我们接下来用更加形象的图像来解释拉普拉斯算子的有效性。
在边缘部分,像素值出现”跳跃“或者较大的变化。下图(a)中灰度值的”跃升”表示边缘的存在。如果使用一阶微分求导我们可以更加清晰的看到边缘”跃升”的存在(这里显示为高峰值)图(b)。
如果在边缘部分求二阶导数会出现什么情况呢,图(c)所示。
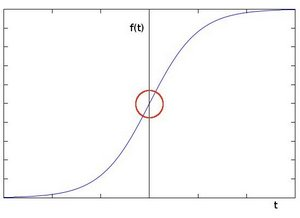
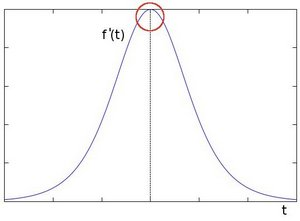
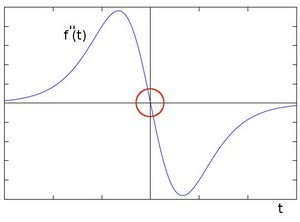
我们会发现在一阶导数的极值位置,二阶导数为0。所以我们也可以用这个特点来作为检测图像边缘的方法。但是,二阶导数的0值不仅仅出现在边缘(它们也可能出现在无意义的位置),但是我们可以过滤掉这些点。
为了更适合于数字图像处理,我们如上面的式子所示,将其表示成了离散形式。为了更好的进行变成,我们也可以将其表示成模版的形式:
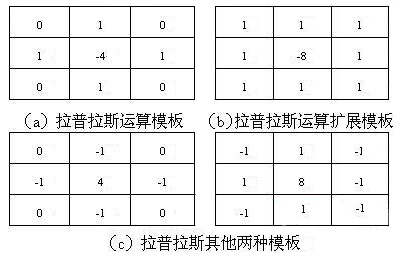
上图(a)表示离散拉普阿拉斯算子的模版,(b)表示其扩展模版,(c)则分别表示其他两种拉普拉斯的实现模版。
从模版形式中容易看出,如果在图像中一个较暗的区域中出现了一个亮点,那么用拉普拉斯运算就会使这个亮点变得更亮。因为图像中的边缘就是那些灰度发生跳变的区域,所以拉普拉斯锐化模板在边缘检测中很有用。
一般增强技术对于陡峭的边缘和缓慢变化的边缘很难确定其边缘线的位置。但此算子却可用二次微分正峰和负峰之间的过零点来确定,对孤立点或端点更为敏感,因此特别适用于以突出图像中的孤立点、孤立线或线端点为目的的场合。同梯度算子一样,拉普拉斯算子也会增强图像中的噪声,有时用拉普拉斯算子进行边缘检测时,可将图像先进行平滑处理。
图像锐化处理的作用是使灰度反差增强,从而使模糊图像变得更加清晰。图像模糊的实质就是图像受到平均运算或积分运算,因此可以对图像进行逆运算,如微分运算能够突出图像细节,使图像变得更为清晰。由于拉普拉斯是一种微分算子,它的应用可增强图像中灰度突变的区域,减弱灰度的缓慢变化区域。因此,锐化处理可选择拉普拉斯算子对原图像进行处理,产生描述灰度突变的图像,再将拉普拉斯图像与原始图像叠加而产生锐化图像。
这种简单的锐化方法既可以产生拉普拉斯锐化处理的效果,同时又能保留背景信息,将原始图像叠加到拉普拉斯变换的处理结果中去,可以使图像中的各灰度值得到保留,使灰度突变处的对比度得到增强,最终结果是在保留图像背景的前提下,突现出图像中小的细节信息。但其缺点是对图像中的某些边缘产生双重响应。
最后我们来看看拉普拉斯算子的效果:


均值滤波也称为线性滤波,其采用的主要方法为邻域平均法。线性滤波的基本原理是用均值代替原图像中的各个像素值,即对待处理的当前像素点$(x,y)$,选择一个模板,该模板由其近邻的若干像素组成,求模板中所有像素的均值,再把该均值赋予当前像素点$(x,y)$,作为处理后图像在该点上的灰度值$g(x,y)$,即$g(x,y)=\frac{1}{m} \Sigma f(x,y)$,
中值滤波是一种非线性平滑技术,它将每一像素点的灰度值设置为该点某邻域窗口内的所有像素点灰度值的中值。具体实现过程如下:
- 通过从图像中的某个采样窗口取出奇数个数据进行排序。
- 用排序后的中值作为当前像素点的灰度值。
- 在图像处理中,中值滤波常用来保护边缘信息,是经典的平滑噪声的方法,该方法法对消除椒盐噪音非常有效,在光学测量条纹图象的相位分析处理方法中有特殊作用,但在条纹中心分析方法中作用不大。
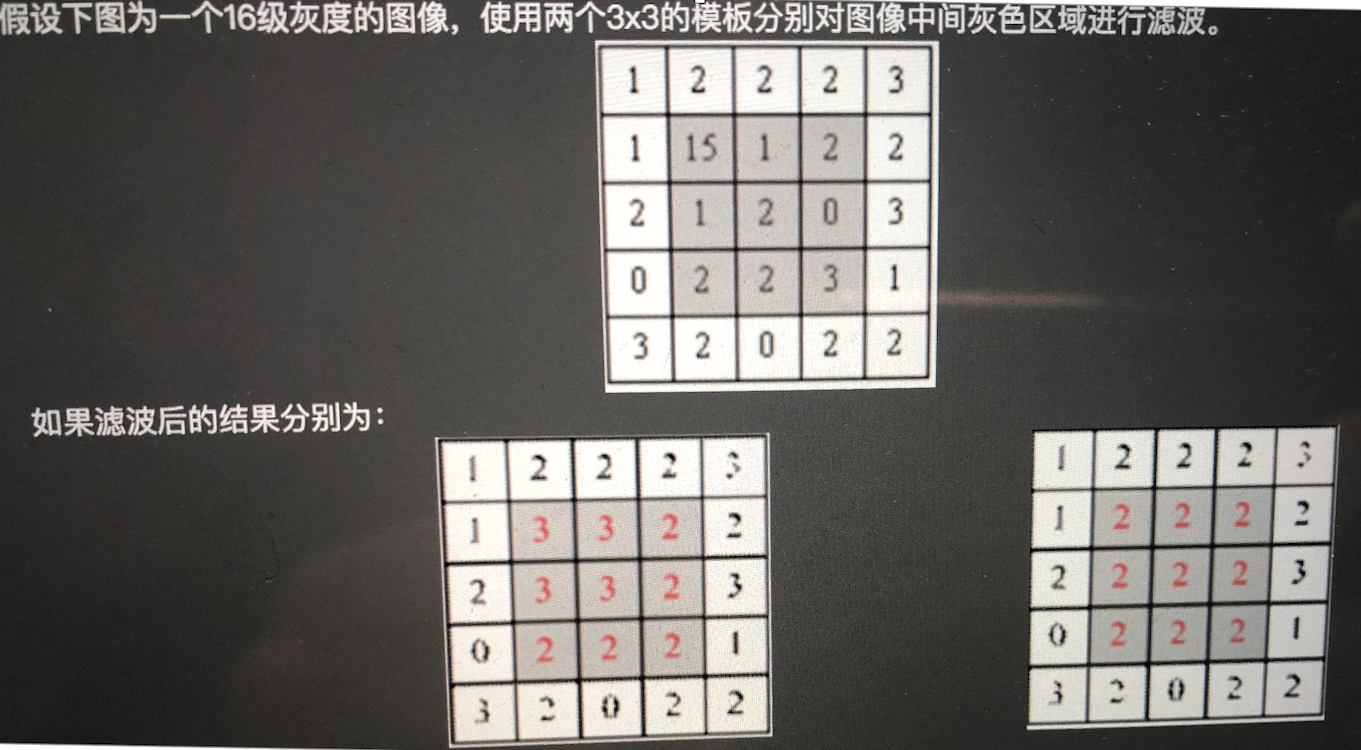
扩张(Dilation)是图像形态学处理中的一种基本操作,用于扩大图像中的前景。它主要作用是填补图像中的小空洞、连接相邻的目标区域、增强目标边界,常用于二值图像的预处理步骤,如降噪、边缘增强等。
扩张操作的本质是以结构元素为模板,将原图像的目标区域(前景)进行膨胀。结构元素(Kernel)是一个小的矩形、椭圆或任意形状的模板,用于决定扩张的具体方式。
- 滑动窗口:
- 结构元素从图像的左上角开始滑动,每次覆盖一个局部区域。
- 检查覆盖区域:
- 如果局部区域与结构元素对应的任意像素有前景像素(值为 1 或非零),那么扩张结果中的对应像素就设置为前景像素。
- 填充结果:
- 重复上述过程直到处理完整幅图像。
设:
- 输入图像
$A$ 是二值图像(值为 0 表示背景,1 表示前景)。 - 结构元素
$B$ 是定义了形态学操作的模板。
扩张的公式为:
其中:
-
$B_z$ 是结构元素$B$ 平移到$z$ 位置后的区域。 -
$A \oplus B$ 表示扩张的结果。
简单来说,扩张的结果是在
- 扩张会将前景像素膨胀,填补目标内部的小空隙。
- 如果相邻区域的距离小于结构元素的尺寸,扩张可以将它们连接起来。
- 扩张会增加目标区域的边界,使得目标更加突出。
常见的结构元素形状有:
-
矩形(常用):例如
$3 \times 3$ 、$5 \times 5$ 。 - 椭圆: 用于处理非规则形状的目标。
- 十字形: 仅操作十字交叉点的像素。
- 结构元素越大,扩张效果越明显(更大范围的膨胀)。
- 结构元素的大小和形状决定了扩张操作的具体效果。
- 结构元素的参考点通常是中心点,但也可以是任意位置。
扩张结果中,原来孤立的前景像素被“扩张”到邻近区域,目标区域的边界变厚。
以下代码演示了如何在 Python 中使用 OpenCV 实现扩张操作:
import cv2
import numpy as np
# 创建一个简单的二值图像
img = np.array([[0, 0, 0, 0, 0],
[0, 1, 0, 0, 0],
[0, 0, 1, 0, 0],
[0, 0, 0, 0, 0]], dtype=np.uint8)
# 定义结构元素(3x3 矩形)
kernel = np.ones((3, 3), np.uint8)
# 扩张操作
dilated = cv2.dilate(img, kernel, iterations=1)
print("原图:\n", img)
print("扩张结果:\n", dilated)扩张是图像形态学的一种操作,通常与腐蚀 (Erosion) 配合使用:
- 扩张 (Dilation): 扩大前景,填补空洞,增强目标。
- 腐蚀 (Erosion): 减少前景,去除噪声,减小目标。
扩张和腐蚀的组合形成其他形态学操作:
- 开运算(Opening):腐蚀 + 扩张(去噪)。
- 闭运算(Closing):扩张 + 腐蚀(填补)。
- 降噪:
- 配合腐蚀操作,扩张可以消除小的孤立噪声点。
- 目标增强:
- 扩张操作增强前景目标,使目标更容易检测。
- 形状分析:
- 在连通域检测或边界提取之前使用扩张。
- 分割后处理:
- 在分割后的二值图像中修复目标区域。
图像插值算法是AI领域的基础技术,用于在图像缩放、旋转、超分辨率重建等任务中填补缺失像素值。以下是Rocky总结的几种主流算法的原理、优缺点及其在AIGC、传统深度学习和自动驾驶领域的应用分析:
- 原理:
直接取距离目标像素最近的已知像素值作为插值结果。例如,目标坐标为(2.3, 3.7),则取最近的(2,4)或(2,3)的像素值。 - 优点:
- 计算量极小,适合实时性要求高的场景(如嵌入式设备);
- 算法简单,实现容易。
- 缺点:
- 锯齿和马赛克现象严重,图像质量低(如图像放大后边缘不连续);
- 忽略相邻像素的关联性,高频信息丢失明显。
- 实际案例:
在低功耗设备(如无人机图传)中,实时显示视频流时采用最近邻插值,牺牲画质换取速度。
- 原理:
在水平和垂直方向分别进行线性插值,利用周围4个邻近像素的加权平均值计算目标像素值。 - 优点:
- 计算复杂度适中,图像边缘比最近邻平滑,无明显锯齿;
- 适用于多数常规图像处理任务(如普通图像放大)。
- 缺点:
- 高频细节模糊(低通滤波效应),导致边缘不锐利;
- 无法捕捉像素间的梯度变化(如纹理细节)。
- 实际案例:
传统图像编辑软件(如Photoshop)默认采用双线性插值进行缩放,平衡速度与质量。
- 原理:
基于16个邻近像素的灰度值及梯度变化率,使用三次多项式计算插值,同时考虑像素值和一阶导数信息。 - 优点:
- 输出图像边缘更平滑,细节保留优于双线性插值;
- 适合高精度图像处理(如医学影像重建)。
- 缺点:
- 计算复杂度高,耗时约为双线性的4倍;
- 仍可能损失部分高频信息。
- 实际案例:
超分辨率算法ESRGAN中,双三次插值用于预处理低分辨率图像,生成初始高分辨率输入。
- 原理:
通过检测图像边缘方向(如梯度变化),沿边缘方向进行插值,避免跨边缘模糊。例如中兴微电子的新专利,结合方向可靠性和像素关联性优化插值结果。 - 优点:
- 显著减少边缘模糊,保留高频细节;
- 在复杂纹理区域表现优异(如文字、建筑边缘)。
- 缺点:
- 计算复杂,需额外边缘检测步骤;
- 对噪声敏感,可能引入伪影。
- 实际案例:
智能监控系统中,基于边缘插值增强车牌识别清晰度,提升OCR准确率。
- 图像生成与编辑:
- 扩散模型(如Stable Diffusion)在生成高分辨率图像时,双三次插值用于中间特征图的上采样,平衡生成速度与质量;
- 基于边缘的插值用于修复生成图像中的模糊边缘(如发丝、纹理细节)。
- 数据增强:
合成数据生成时(如启数光轮的AIGS技术),插值算法用于模拟不同光照、视角下的图像变体,提升模型泛化性。
- 超分辨率重建:
- ESRGAN等模型依赖双三次插值预处理,结合深度学习恢复高频细节;
- 基于学习的插值方法(如Sub-pixel CNN)直接端到端优化插值过程,减少人工设计偏差。
- 医学影像处理:
双三次插值用于MRI图像重建,保留病灶边缘信息,辅助诊断。
- 多传感器融合:
- 激光雷达点云与摄像头图像的配准时,双线性插值用于对齐不同分辨率的空间数据;
- 基于边缘的插值优化BEV(鸟瞰图)中的道路标线重建,提升感知精度。
- 仿真数据生成:
启数光轮等公司通过插值算法合成极端场景数据(如暴雨、夜间驾驶),解决长尾问题。
模型训练时Resize图像常用的插值算法有:最近邻插值,双线性插值以及双三次插值等。
最近邻插值:没考虑其他相邻像素点的影响,因而重新采样后灰度值有明显的不连续性,图像质量损失较大,存在马赛克和锯齿现象。
双线性插值:也叫一阶插值,它是利用了待求像素点在源图像中4个最近邻像素之间的相关性,通过两次线性插值得到待求像素点的值。
双三次插值:也叫立方卷积插值,它是利用了待求像素点在源图像中相邻的16个像素点的值,即这16个像素点的加权平均。
一般先对数据进行归一化(Normalization)处理【0,1】,再进行标准化(Standardization)操作,用大数定理将数据转化为一个标准正态分布,最后再进行一些数据增强处理。
归一化后,可以提升模型精度。不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。 标准化后,可以加速模型收敛。最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
- 峰值信噪比(Peak-Signal to Noise Ratio,PSNR)
- 均方误差(Mean Square Error,MSE)
- MAE(Mean Absolute Error,MSE)
- 信噪比SNR(Signal to Noise Ratio,SNR)
- 信息保真度准则(Information Fidelity Criterion,IFC)
- 视觉信息保真度(Visual Information Fidelity,VIF)
- 结构相似度(Structure Similaruty,SSIM)
- RGB任选一通道作为灰度图
- RGB中最大值最为灰度图
- RGB的均值作为灰度图
- RGB的加权均值作为灰度图
- 在读取图片时,OpenCV按照BGR的色彩模式渲染通道,而PIL按照RGB的色彩模式渲染通道。
- OpenCV性能较优,可以作为算法与工程的必备模块。
通常其他图像读取函数读取图片的时候是按RGB格式读取,但在OpenCV在读取图片时,是按BGR读取的。
- 定义
FID通过计算真实图像与生成图像的特征向量之间的距离的距离来评价图像的相似度。
特征向量:由预训练的图像特征提取网络获得。
- 公式
其中,$||.||$ 表示矩阵的二范数;
- 计算步骤和python代码

- 定义
SSIM全称为Structural Similarity,用于评估真实图像和生成图像的相似度指标。该指标基于滑动窗口,计算窗口子指标(亮度
与FID的差异:FID更偏向于对高度抽象的特征向量进行评价,而SSIM是对图像本身进行评价。如果生成图像与真实图像仅有失真(雾气,雨水,镜头模糊等)的影响,则两个评价指标双高;但如果生成图像是真实图像的同类图(同为大理石花纹的桌子,但两个花纹大相径庭),那么FID一般还是很高,SSIM则很低。
- 公式
其中,
- 计算步骤和python代码

- 定义
PSNR全称为Peak Signal-to-Noise,峰值信噪比。它通过比较处理后的图像与原始图像之间的差异,即最大像素值和平均噪音的比值,来评价图像的相似性,其单位是分贝(dB)。
与SSIM的关系:PSNR的评价结果一般与SSIM的结果成正向关系。
与FID的关系:PSNR低,FID高可以说明生成的图像在满足特征的情况下具有一定的多样性。
- 公式
其中,
- 计算步骤和python代码

在生成式模型的训练中,正则化技术是一种常用的方法,用于增强模型的泛化能力,防止过拟合,以及在一些情况下,帮助模型更稳定和可靠地训练。正则化对生成式模型的主要作用包括:
生成式模型,特别是参数众多的模型(如Stable Diffusion、GAN和VAE),容易在训练数据上过度拟合,从而导致模型在未见过的数据上性能下降。通过使用正则化技术,如L1或L2正则化(权重衰减),可以惩罚模型权重的大值,从而限制模型复杂度,帮助模型在保留训练数据重要特性的同时,防止过分依赖特定训练样本的噪声或非代表性特征。
在生成对抗网络(GAN)等生成式模型中,训练过程中的稳定性是一个重要问题。正则化技术,如梯度惩罚(gradient penalty)和梯度裁剪(gradient clipping),可以防止梯度爆炸或消失,从而帮助模型更稳定地训练。这些技术通过控制权重更新的幅度,确保训练过程中的数值稳定性。
正则化技术有助于改善生成式模型的收敛性,特别是在对抗性的训练环境中。例如,在GANs中,使用梯度惩罚或Batch Normalization可以帮助生成器和判别器更均衡地训练,避免一方过早地主导训练过程,从而促进整个模型的稳健收敛。
尤其在GAN中,模式坍塌(mode collapse)是一个常见的问题,其中生成器倾向于生成非常相似的输出样本,忽视输入的多样性。这意味着生成器无法覆盖到数据分布的多样性,仅在潜在空间中的某个点或几个点上“坍塌”。通过应用正则化技术,如Mini-batch discrimination或使用dropout,可以鼓励生成器探索更多的数据分布,从而提高生成样本的多样性。
在视觉大模型中,梯度消失或爆炸(Gradient Vanishing/Exploding)是常见问题,特别是在训练复杂的生成式模型时。正则化技术,如Batch Normalization和Layer Normalization,通过规范化中间层的输出,帮助控制梯度的规模,从而避免这两种问题,使训练过程更加稳定。
生成式模型可能对训练数据中的噪声过于敏感,导致生成的图像或数据质量低下。通过应用正则化,如Dropout或添加一定量的噪声,模型可以对不重要的输入变化更鲁棒,从而提高生成数据的质量和稳健性。
正则化技术在生成式模型中的运用有助于优化模型性能,提高模型的泛化能力和输出质量,同时确保训练过程的稳定性和效率。这些技术是设计和训练高效、可靠生成式模型的重要组成部分。
在SD 3发布后,AI绘画领域也正式进入了Transformer时代。
基于Transformer架构与基于U-Net(CNN)架构相比,一个较大的优势是具备很强的Scaling能力,通过增加模型参数量、训练数据量以及计算资源可以稳定的提升AI绘画大模型的生成能力和泛化性能。SD 3论文中也选择了不同参数规模(设置网络深度为15、18、21、30、38,当网络深度为38时,也就是SD 3的8B参数量模型)的MM-DiT架构进行实验。
经过实验后,整体上的结论是MM-DiT架构表现出了比较好的Scaling能力,当模型参数量持续增加时,模型性能稳步提升。
总的来说,SD 3论文中的整个实验过程也完全证明了Scaling Law在AI绘画领域依旧成立,特别是在基于DiT架构的AI绘画大模型上。Rocky判断未来在工业界、学术界、应用界以及竞赛界,AI绘画领域的Scaling Law的价值会持续凸显与放大。
随着图像生成AI的发展,如Stable Diffusion和Midjourney,能够根据自然语言生成“高品质”的图像。然而,“高品质”图像的定义和评价并不简单,目前有多种评价指标来衡量图像的质量和相关性。
FID是用于评估生成图像与真实图像相似度的量化指标。它使用Inception网络将生成图像和真实图像转换为特征向量,假设这些特征向量的分布为高斯分布,并计算其均值和协方差矩阵。通过测量这两个高斯分布之间的“距离”来评估相似性,值越小,图像质量越高。
CLIP Score通过学习自然语言和图像对之间的语义关系来评估图像和文本的匹配度。它将自然语言和图像分别转换为特征向量,然后计算它们之间的余弦相似度。CLIP Score越高,图像和文本对之间的相关性越高。
Inception Score评估生成图像的质量和多样性。它使用Inception网络对生成图像进行分类,正确分类结果越集中,质量越高。同时,当生成图像被分类为不同标签时,多样性越大。IS综合考虑了图像的质量和多样性,得分越高表示质量和多样性越好。
论文链接:2502.10663v1
文本到图像 (T2I) 生成模型在根据文本描述创建多样化、高质量图像的能力方面发展迅速。这些模型在机器学习应用中具有数据增强的巨大潜力,特别是在收集真实世界数据成本高昂或不切实际的情况下。然而,合成数据用于训练的有效性关键取决于其真实性。REAL 框架
REAL 框架通过三个互补维度评估 T2I 生成图像中的真实性:
此维度侧重于对象细粒度视觉属性(例如颜色、纹理和形状)的正确性。该框架通过以下方式验证这些属性是否符合现实世界的预期:
- 从知识来源(例如,维基百科)提取对象属性
- 提出关于这些属性的具体问题(例如,“尾巴是棕色到黑色,边缘是淡黄色吗?”)
- 使用视觉问题回答 (VQA) 模型来检查属性是否被正确描绘
例如,在评估“金背地松鼠”的图像时,该框架会检查描绘的松鼠是否具有正确的颜色模式、身体比例以及权威来源中描述的独特特征。
此维度评估图像中对象之间关系的自然主义质量。该框架:
- 从文本提示中识别主体、关系和对象
- 形成问题以验证关系的呈现和真实性
- 使用 VQA 模型来回答这些问题
例如,在评估“狗拉马”时,该框架首先会检查狗和马是否都存在,然后验证它们的关系是否被真实地描绘出来。
此维度确定生成的图像是否符合所请求的视觉风格,特别是区分照片写实风格和插图风格。该方法包括:
- 在照片和插图的数据集上微调 CLIP 模型
- 使用此模型对生成的图像的视觉风格进行分类
- 将分类的风格与提示中要求的风格进行比较

REAL 框架代表了 T2I 生成模型评估方面的一项重大进步,它将焦点从单纯的文本-图像对齐转移到图像现实主义的关键维度。通过提供与人类判断非常吻合的现实主义的多维度评估,REAL 能够实现更有效的数据增强策略,并为模型选择和改进提供有价值的见解。