- 1.哪些经典的GAN模型跨过了周期,在AIGC时代继续落地使用?
- 2.GAN的核心思想?
- 3.面试常问的经典GAN模型?
- 4.生成对抗网络GAN与传统神经网络有何不同?
- 5.GAN和Stable Diffusion有哪些差异?
- 6.什么是GAN模型的Mode collapse(模式坍塌)问题?有哪些解决方法?
GAN作为传统深度学习时代的主流生成式模型,在AIGC时代到来后,终于“退居二线”,成为Stable Diffusion模型的得力助手。Rocky认为这是GAN最好也是最合适的落地方式,所以Rocky持续梳理总结了在AIGC时代继续繁荣的GAN模型,为大家指明GAN快速学习入门的新路线:
- GAN优化:原生GAN、DCGAN、CGAN、WGAN、LSGAN等
- 图像生成:bigGAN、GigaGAN等
- 图像风格迁移:CycleGAN、StyleGAN、StyleGAN2等
- 图像编辑:Pix2Pix、GauGAN、GauGAN2、DragGAN等
- 图像超分辨率重建:SRGAN、ESRGAN、Real-ESRGAN、AuraSR等
- 图像修复/人脸修复:GFPGAN等
2014年,Ian Goodfellow第一次提出了GAN的概念。Yann LeCun曾经说过:“生成对抗网络及其变种已经成为最近10年以来机器学习领域最为重要的思想之一”。GAN的提出让生成式模型重新站在了深度学习这个浪潮的璀璨舞台上,与判别式模型开始谈笑风生。
GAN由生成器$G$和判别器$D$组成。其中,生成器主要负责生成相应的样本数据,输入一般是由高斯分布随机采样得到的噪声$Z$。而判别器的主要职责是区分生成器生成的样本与$gt(GroundTruth)$样本,输入一般是$gt$样本与相应的生成样本,我们想要的是对$gt$样本输出的置信度越接近$1$越好,而对生成样本输出的置信度越接近$0$越好。与一般神经网络不同的是,GAN在训练时要同时训练生成器与判别器,所以其训练难度是比较大的。
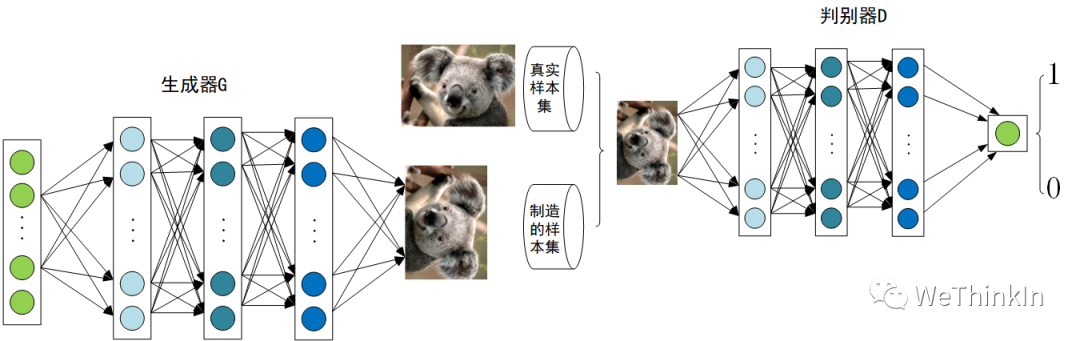
在提出GAN的第一篇论文中,生成器被比喻为印假钞票的犯罪分子,判别器则被当作警察。犯罪分子努力让印出的假钞看起来逼真,警察则不断提升对于假钞的辨识能力。二者互相博弈,随着时间的进行,都会越来越强。在图像生成任务中也是如此,生成器不断生成尽可能逼真的假图像。判别器则判断图像是$gt$图像,还是生成的图像。二者不断博弈优化,最终生成器生成的图像使得判别器完全无法判别真假。
GAN的对抗思想主要由其目标函数实现。具体公式如下所示:
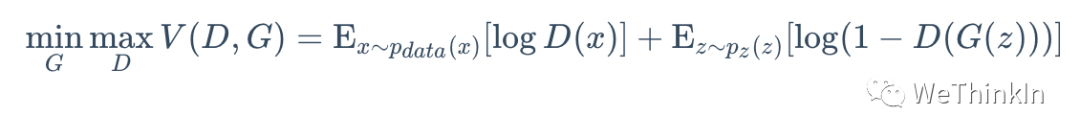
上面这个公式看似复杂,其实不然。跳出细节来看,整个公式的核心逻辑其实就是一个min-max问题,深度学习数学应用的边界扩展到这里,GAN便开始发光了。
接着我们再切入细节。我们可以分两部分开看这个公式,即判别器最小化角度与生成器最大化角度。在判别器角度,我们希望最大化这个目标函数,因为在公示第一部分,其表示$gt$样本$(x ~Pdata)$输入判别器后输出的置信度,当然是越接近$1$越好。而公式的第二部分表示生成器输出的生成样本$(G(z))$再输入判别器中进行进行二分类判别,其输出的置信度当然是越接近$0$越好,所以$1 - D(G(z))$越接近$1$越好。
在生成器角度,我们想要最小化判别器目标函数的最大值。判别器目标函数的最大值代表的是真实数据分布与生成数据分布的JS散度,JS散度可以度量分布的相似性,两个分布越接近,JS散度越小(JS散度是在初始GAN论文中被提出,实际应用中会发现有不足的地方,后来的论文陆续提出了很多的新损失函数来进行优化)
写到这里,大家应该就明白GAN的对抗思想了,下面是初始GAN论文中判别器与生成器损失函数的具体设置以及训练的具体流程:

在图中可以看出,将判别器损失函数离散化,其与交叉熵的形式一致,我们也可以说判别器的目标是最小化交叉熵损失。
- 原始GAN及其训练逻辑
- DCGAN
- CGAN
- WGAN
- LSGAN
- PixPix系列
- CysleGAN
- SRGAN系列
生成对抗网络(GAN)的定义
- 生成对抗网络(Generative Adversarial Network,GAN)是一种深度学习架构,由生成器(Generator)和判别器(Discriminator)两个部分组成。
- 生成器的主要任务是学习数据的分布,并生成尽可能逼真的数据来欺骗判别器。例如,它可以学习人脸图像的数据分布,然后生成新的人脸图像。生成器接收一个随机噪声向量(通常是低维的)作为输入,通过一系列的神经网络层(如全连接层、卷积层等)将这个噪声转化为生成的数据样本。
- 判别器则用于区分真实数据和生成器生成的数据。它接收真实数据和生成数据作为输入,输出一个概率值,表示输入的数据是真实数据的概率。例如,对于一张图像,判别器会判断它是真实拍摄的人脸图像还是生成器生成的人脸图像,输出一个介于0到1之间的概率。
- 这两个部分在训练过程中相互对抗、相互学习。生成器试图让生成的数据尽可能地骗过判别器,而判别器则试图更好地分辨真实数据和生成数据,随着训练的进行,生成器生成的数据越来越逼真。
GAN与传统神经网络的不同点
- 网络结构
- 传统神经网络:通常是一个前馈网络(如多层感知机)或递归网络(如RNN、LSTM),主要用于完成分类、回归等任务。例如,在图像分类任务中,传统神经网络输入一张图像,通过一系列的卷积层和全连接层,最终输出图像所属的类别。它的结构相对比较单一,目的是学习输入到输出的映射关系。
- GAN:具有双模块结构,由生成器和判别器组成。这两个模块之间存在对抗关系,它们的训练过程是相互关联的。生成器的输出作为判别器的输入的一部分,两个模块的参数是交替更新的,而不是像传统神经网络那样只更新一个网络的参数。
- 训练目标
- 传统神经网络:训练目标比较直接。在监督学习的情况下,例如分类任务,训练目标是最小化预测类别与真实类别之间的交叉熵损失;在回归任务中,训练目标可能是最小化预测值与真实值之间的均方误差等。目标是使网络输出尽可能准确地符合给定的标签或目标值。
- GAN:训练目标是达到纳什均衡(Nash equilibrium)。生成器的目标是最小化生成数据被判别器识别为假数据的概率,即最大化判别器将生成数据判断为真实数据的概率;判别器的目标是最大化区分真实数据和生成数据的能力。这种对抗性的训练目标使得GAN的训练过程更加复杂和动态。
- 数据学习方式
- 传统神经网络:在监督学习中,依赖于带有标签的训练数据来学习输入和输出之间的映射关系。例如,在训练一个文本情感分类器时,需要大量的文本及其对应的情感标签(如正面、负面)来训练网络。在无监督学习的情况下,传统神经网络可能会学习数据的聚类等特征,但学习方式相对比较固定。
- GAN:通过生成器和判别器的对抗来学习数据的分布。生成器在没有直接看到真实数据标签的情况下,通过判别器的反馈来不断调整生成的数据,使其更接近真实数据的分布。例如,在生成手写数字图像的GAN中,生成器通过不断尝试生成能骗过判别器的手写数字图像,来学习真实手写数字图像的分布。
- 应用场景
- 传统神经网络:广泛应用于分类、回归、聚类、预测等领域。例如,在语音识别中,用于将语音信号转换为文本;在推荐系统中,用于预测用户对物品的喜好程度等。
- GAN:主要用于生成数据,如生成图像、音频、文本等。可以用于数据扩充,例如在医疗图像数据较少的情况下,通过GAN生成更多的类似图像来扩充数据集;还可以用于图像风格转换,如将真实照片转换为油画风格的图像等。
GAN(生成对抗网络)和Stable Diffusion(稳定扩散模型)都是AIGC、传统深度学习、自动驾驶领域的核心模型之一,其核心差异体现在模型架构、训练机制、生成质量及应用场景等方面。以下是Rocky总结的详细对比:
| 维度 | GAN | Stable Diffusion |
|---|---|---|
| 生成原理 | 基于对抗训练:生成器(G)与判别器(D)通过博弈优化生成结果。 | 基于扩散过程:通过逐步去噪(从高斯噪声到目标图像)生成数据,结合潜在空间压缩技术。 |
| 训练稳定性 | 训练不稳定,易出现模式崩溃(生成单一结果)和梯度消失问题。 | 训练更稳定,优化目标为最小化噪声预测误差,收敛性较好。 |
| 生成步骤 | 单步生成(直接输出图像)。 | 多步迭代(通常20-50步),逐步修正噪声生成图像。 |
-
GAN的局限性
- 多样性不足:易受训练数据分布限制,生成结果可能重复或缺乏创新(如StyleGAN生成人脸时细节固定)。
- 高分辨率挑战:生成大尺寸图像需复杂架构(如ProGAN逐层训练),资源消耗大。
- 可控性依赖潜在空间:通过调整潜在向量(如StyleGAN的W空间)控制生成,但语义编辑灵活性较低。
-
Stable Diffusion的优势
- 高保真与多样性:扩散过程允许生成更复杂、多样的图像(如复杂场景融合)。
- 文本条件生成:通过CLIP等模型将文本嵌入扩散过程,实现精准的文本到图像控制(如生成“戴墨镜的柯基”)。
- 分辨率扩展性:利用潜在空间(如64x64压缩)降低计算量,结合超分模型生成4K图像。
| 类别 | GAN | Stable Diffusion |
|---|---|---|
| 核心组件 | 生成器(卷积网络)+ 判别器(分类网络)。 | VAE编码器(压缩图像到潜在空间)+ U-Net(噪声预测)+ CLIP(文本条件嵌入)。 |
| 计算资源 | 推理速度快(单步生成),但训练需平衡G/D网络,调参复杂。 | 训练资源高(需多步反向传播),但推理可通过蒸馏技术加速(如Consistency Models)。 |
| 显存占用 | 低(如StyleGAN-T生成512x512图像仅需0.1秒)。 | 较高(默认模型需4GB显存生成512x512图像)。 |
-
GAN的适用场景
- 快速生成:实时应用(如游戏角色生成、滤镜效果)。
- 小数据集优化:在有限数据下(如医学图像)表现优于扩散模型。
- 特定领域:人脸生成(StyleGAN)、图像风格迁移(CycleGAN)。
-
Stable Diffusion的适用场景
- 复杂条件生成:文本到图像(DALL·E 3)、图像修复(Inpainting)。
- 高质量艺术创作:支持LoRA、ControlNet插件,细化控制构图与风格。
- 数据增强:生成合成数据集提升下游任务性能(如《Stable Diffusion for Data Augmentation》)。
模式坍塌(Mode Collapse) 是GAN训练中的常见问题,指生成器(Generator)仅能生成有限种类的样本,无法覆盖真实数据的所有分布模式。例如,训练生成人脸时,生成器可能反复生成同一张人脸,而忽略其他特征(如不同肤色、年龄、表情等)。
核心成因:
- 生成器与判别器的对抗失衡:生成器找到能欺骗判别器的“捷径”,反复生成同一类样本。
- 优化目标局限性:传统GAN的JS散度(Jensen-Shannon Divergence)在分布不重叠时无法提供有效梯度。
- 数据多样性不足:真实数据包含复杂多模式,但生成器倾向于简化输出以最小化损失。
场景:使用GAN生成MNIST手写数字(0-9),但生成器仅能输出数字“1”。
问题表现:
- 生成样本多样性极低,重复生成相似笔画的“1”;
- 判别器快速将“1”识别为假样本,但生成器无法跳出局部最优解。
解决方法:采用WGAN-GP(Wasserstein GAN with Gradient Penalty)。 - 效果对比:
- 传统GAN:生成样本仅包含“1”;
- WGAN-GP:生成样本覆盖0-9所有数字,多样性显著提升。
- Wasserstein GAN(WGAN):
- 用Wasserstein距离替代JS散度,解决梯度消失问题。
- 添加梯度惩罚(Gradient Penalty)约束判别器的Lipschitz连续性。
- Unrolled GAN:
- 生成器优化时考虑判别器的多步更新,避免短期欺骗策略。
- Self-Attention GAN(SAGAN):
- 引入自注意力机制,增强全局依赖建模能力,生成复杂结构。
- Mini-batch Discrimination:
- 判别器评估整个批次的样本相似度,鼓励生成多样性。
- MAD-GAN:
- 使用多个生成器,每个生成器负责不同模式,通过竞争提升多样性。
- 问题:生成艺术画作时,模式坍塌导致画风单一(如仅生成抽象派作品)。
- 解决方法:SAGAN + Mini-batch Discrimination。
- 效果:生成多种风格(抽象派、写实派、印象派),满足个性化需求。
- 问题:数据增强时,生成图像缺乏多样性(如仅生成同一角度的车辆图片)。
- 解决方法:WGAN-GP + 多模型集成。
- 效果:生成多视角、多光照条件的图像,提升分类模型鲁棒性。
- 问题:合成极端场景(如暴雨夜间的行人)时,模式坍塌导致场景重复。
- 解决方法:Unrolled GAN + 梯度惩罚。
- 效果:生成多样化极端场景(暴雨、暴雪、夜间),提升感知模型泛化能力。
- 核心逻辑:模式坍塌源于生成器与判别器的对抗失衡,需从损失函数、架构设计、数据多样性多角度突破。
- 回答框架:
- 定义与成因:简明解释模式坍塌的现象与数学根源(如JS散度缺陷)。
- 解决方法:结合代码片段说明WGAN-GP、Mini-batch Discrimination等技术的实现。
- 领域应用:按AIGC、传统深度学习、自动驾驶分述痛点与解决方案。
- 加分点:
- 对比不同方法的适用场景(如WGAN-GP适合数据分布复杂,SAGAN适合结构生成)。
- 强调实际工程中的调参经验(如梯度惩罚系数λ的选择)。
- 提及新兴技术(如扩散模型对GAN的替代趋势,但GAN在实时性上仍有优势)。
通过以上结构化分析,可展现对GAN理论深度与工程落地的全面理解,契合AI算法岗对问题拆解与跨领域迁移能力的要求。