The work stealing runtime is safer when it comes to handling exceptions through running Runnables through EC#execute than when using a different Executor. Throwing exceptions on the worker threads of a fixed thread pool results in the death of those threads, and depending on the configuration of the ThreadFactory, those same threads may or may not be replaced by new ones. Furthermore, throwing fatal exceptions in a Runnable on any other thread pool will not currently result in a graceful shutdown of an IOApp, because we have bespoke logic to handle this as part of the IOFiber runloop. Currently, this safety comes at a performance disadvantage for the work stealing runtime by having to suspend every submitted runnable in an IO.delay. I think I have a way of equalizing the exception handling between the work stealing thread pool and any other thread pool used as a compute pool for IO and improving the performance of the work stealing runtime as a normal execution context for running Runnables, but this essentially comes at a performance cost of other ExecutionContexts used as a compute pool.
Here is a sample application with a fixed thread pool that shows this behavior:
package cats.effect
package example
import cats.effect.unsafe.IORuntime
object Example extends IOApp.Simple {
override def runtime: IORuntime = {
import java.util.concurrent.atomic.AtomicInteger
import java.util.concurrent.Executors
import cats.effect.unsafe.IORuntimeConfig
import cats.effect.unsafe.Scheduler
import scala.concurrent.ExecutionContext
val (blocking, blockDown) = {
val threadCount = new AtomicInteger(0)
val executor = Executors.newCachedThreadPool { (r: Runnable) =>
val t = new Thread(r)
t.setName(s"io-blocking-${threadCount.getAndIncrement()}")
t.setDaemon(true)
t
}
(ExecutionContext.fromExecutor(executor), () => executor.shutdown())
}
val (scheduler, schedDown) = {
val executor = Executors.newSingleThreadScheduledExecutor { r =>
val t = new Thread(r)
t.setName("io-scheduler")
t.setDaemon(true)
t.setPriority(Thread.MAX_PRIORITY)
t
}
(Scheduler.fromScheduledExecutor(executor), () => executor.shutdown())
}
val (compute, compDown) = {
val threadCount = new AtomicInteger(0)
val executor = Executors.newFixedThreadPool(
8,
{ r =>
if (threadCount.get() >= 8) null
else {
val t = new Thread(r)
t.setName(s"io-compute-${threadCount.getAndIncrement()}")
t.setDaemon(true)
t
}
})
(ExecutionContext.fromExecutor(executor), () => executor.shutdown())
}
val cancelationCheckThreshold =
System.getProperty("cats.effect.cancelation.check.threshold", "512").toInt
new IORuntime(
compute,
blocking,
scheduler,
() => {
compDown()
blockDown()
schedDown()
},
IORuntimeConfig(
cancelationCheckThreshold,
System
.getProperty("cats.effect.auto.yield.threshold.multiplier", "2")
.toInt * cancelationCheckThreshold
)
)
}
def run: IO[Unit] =
IO.executionContext.flatMap { ec =>
IO {
for (_ <- 0 until 20) {
ec.execute(() => throw new RuntimeException("Boom!"))
}
}
} *> IO.never[Unit]
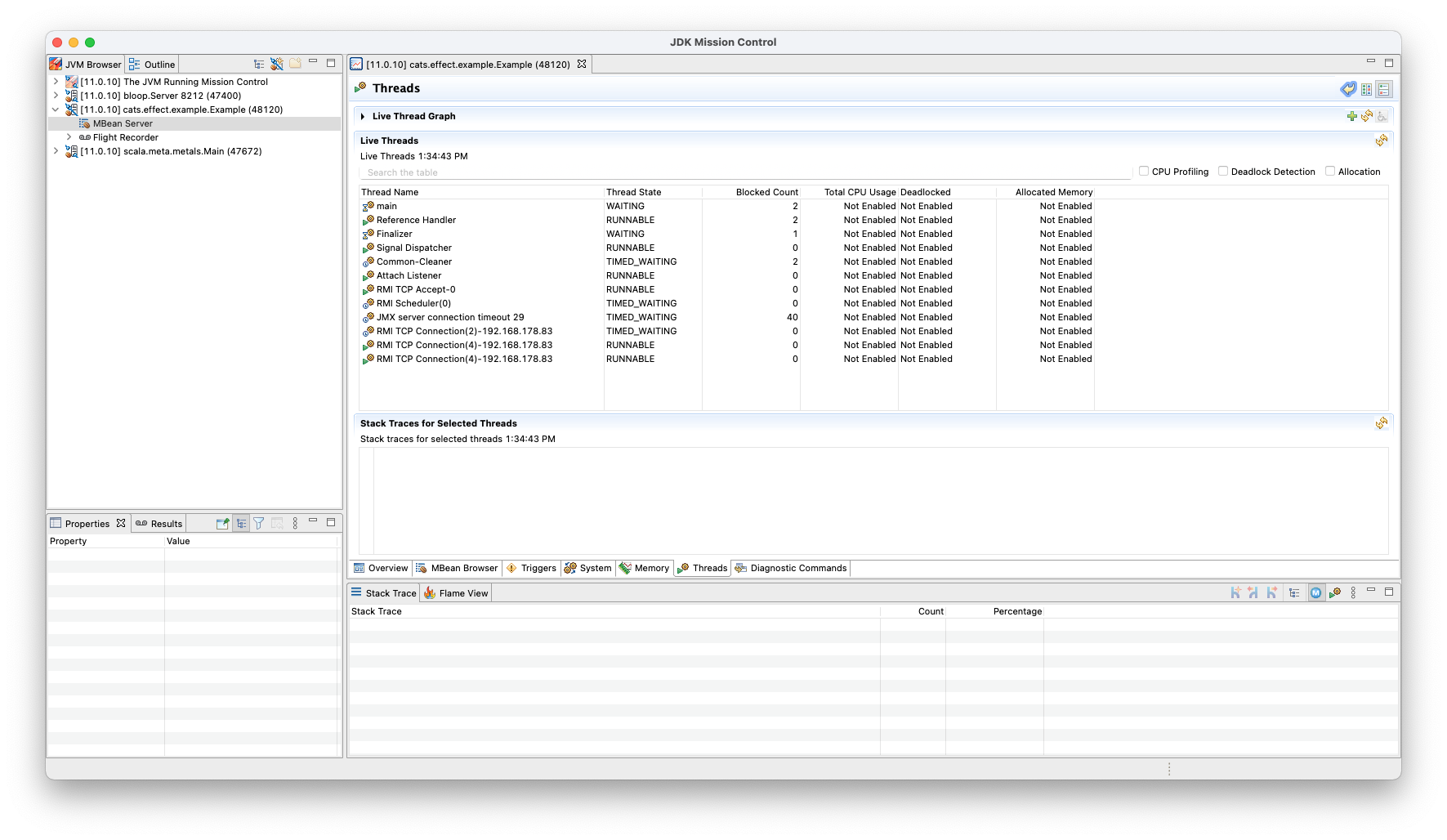
}Executing this application results in the following situation in JDK Misssion Control where all io-compute threads are dead:
The work stealing runtime is safer when it comes to handling exceptions through running
Runnables throughEC#executethan when using a differentExecutor. Throwing exceptions on the worker threads of a fixed thread pool results in the death of those threads, and depending on the configuration of theThreadFactory, those same threads may or may not be replaced by new ones. Furthermore, throwing fatal exceptions in aRunnableon any other thread pool will not currently result in a graceful shutdown of anIOApp, because we have bespoke logic to handle this as part of theIOFiberrunloop. Currently, this safety comes at a performance disadvantage for the work stealing runtime by having to suspend every submitted runnable in anIO.delay. I think I have a way of equalizing the exception handling between the work stealing thread pool and any other thread pool used as a compute pool for IO and improving the performance of the work stealing runtime as a normal execution context for runningRunnables, but this essentially comes at a performance cost of otherExecutionContexts used as a compute pool.Here is a sample application with a fixed thread pool that shows this behavior:
Executing this application results in the following situation in JDK Misssion Control where all

io-computethreads are dead: