
조회하고자 하는 데이터가 많을 때, 이를 모두 조회하는 것은 시간도 오래걸릴 뿐더러 한 페이지에 모두 띄우는 건 거의 불가능할 것이다. 따라서 이를 페이지를 나누어서 조회하는 것을 페이지네이션이라고 한다.
JPA에서는 페이지네이션을 간편하게 사용할 수 있게 Pageable 이라는 인터페이스를 제공한다.
@GetMapping("")
Page<Itinerary> getAll(Pageable pageable){
}위와 같이 Pageable을 쿼리 파라미터로 받는다.
JPA Repository
@Override
Page<Itinerary> findAll(Pageable pageable);위 와 같이 JpaRepository에서 Pageable만 넣어 주면된다.
QueryDSL
List<Itinerary> content = queryFactory
.from(qItinerary)
.offset(pageable.getOffset()) // 페이지 번호
.limit(pageable.getPageSize()) // 페이지 사이즈
.fetch();
return content;queryDSL에서 사용시에는 다음과 같이 pageable에서 offset과 pageSize를 불러와서 지정해주면 된다.
http://localhost:8080?page=0&size=1
다음과 같이 page와 size를 쿼리 파라미터에 담은 요청을 남기면
요청한 페이지의 사이즈만큼 데이터를 요청해서 가져온다.
queryDSL의 쿼리에서 예상할 수 있듯이 Page를 offset으로 size를 limit으로 지정하여 원하는 부분부터 원하는 양의 데이터를 조회한다.
쿼리 예시)
select * from table
order by id
limit 10
offset 10000000; public Pageable resolveArgument(MethodParameter methodParameter, @Nullable ModelAndViewContainer mavContainer, NativeWebRequest webRequest, @Nullable WebDataBinderFactory binderFactory) {
String page = webRequest.getParameter(this.getParameterNameToUse(this.getPageParameterName(), methodParameter));
String pageSize = webRequest.getParameter(this.getParameterNameToUse(this.getSizeParameterName(), methodParameter));
Sort sort = this.sortResolver.resolveArgument(methodParameter, mavContainer, webRequest, binderFactory);
Pageable pageable = this.getPageable(methodParameter, page, pageSize);
if (!sort.isSorted()) {
return pageable;
} else {
return (Pageable)(pageable.isPaged() ? PageRequest.of(pageable.getPageNumber(), pageable.getPageSize(), sort) : Pageable.unpaged(sort));
}
}위 PageableHandlerMethodArgumentResolver 클래스가 Pageable 인터페이스를 구현하게 된다.
이 코드를 보면 request에서 getPageParameterName()과 getSizeParameterName()을 통해 쿼리 파라미터를 가져온다. 위 함수들은 상위 클래스에서 각각 "page" 와 "size"로 지정되어 있고, 이를 properties에서 변경도 가능하다.
지금까지 설명한 것 같이 offset과 limit을 통해 조회하는 것이 offset 방식이다.
offset문제의 가장 큰 문제점은 offset이 커질 수록 속도가 느려진다는 점이다. MySQL은 B+Tree 알고리즘을 사용해서 데이터를 조회하는데 offset에 해당하는 값까지 순차적으로 탐색하기 때문에 offset이 커질 수록 속도가 느려진다.
B+Tree 예시
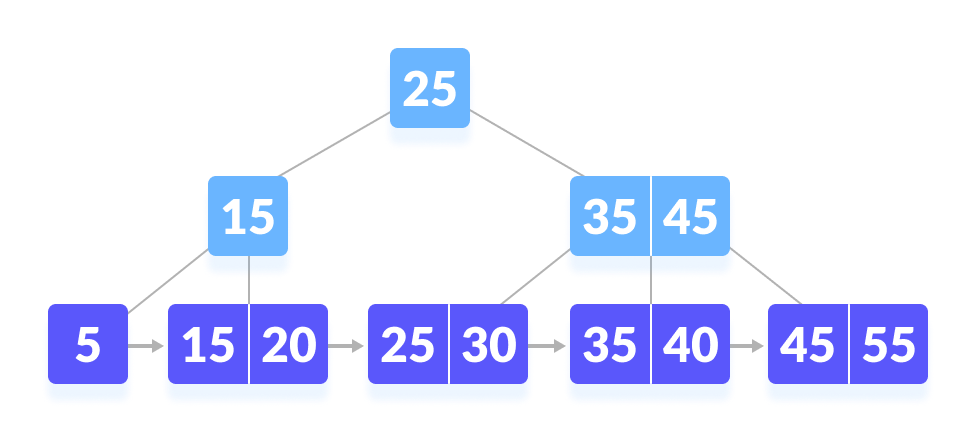
이런 구조 이기 때문에 특정 원소에 배열처럼 바로 접근이 불가능해서 offset이 커질 수록 시간을 소요하게 된다.
이 문제는 글이 빠르게 늘어나는 인기 커뮤니티의 게시판을 생각하면 이해하기 쉽다.
1번 페이지의 내용을 천천히 보고 2번페이지로 넘어갔을 때, size만큼의 글이 새로 생성되었다면 1번페이지에 있던 모든 내용이 2번페이지에서 조회될 것이다.
이렇게 사용자가 페이지를 넘겼음에도 중복된 데이터를 보게 되는 문제가 발생한다.
offset을 사용하지 않고 Where절을 사용해서 페이징을 구현한 방식이다.
첫 조회
SELECT * FROM table LIMIT 10; //10개 조회이후 조회
SELECT * FROM table WHERE id >10 LIMIT 10; // 이전 조회한것 마지막부터 10개 조회
SELECT * FROM table WHERE id >20 LIMIT 10; // 이전 조회한것 마지막부터 10개 조회이 방식을 통해 조회할 경우 각 부분마다의 속도가 거의 차이가 없이 빠르게 조회할 수 있다.
처음에는 offset방식과 뭐가 다른지 이해하지 못했다. offset를 통해 10부터 10개 가져오는 것과 where을 통해 10부터 10개를 가져오는 것은 동일하지 않나? 생각했다.
하지만 Cursor방식이 빠른 이유는 바로 Index에 있다. offset은 그저 순서가 offset부터 시작하기 때문에 offset을 찾기 위해 순차적으로 찾아야 한다. 하지만 where를 통해 조회하면 인덱스를 통해 조건에 맞는 시작 부분을 빠르게 찾을 수 있다.
따라서 조건에 들어가는 컬럼은 무조건 인덱스 설정이 되어 있어야 Cursor방식에 의미가 있다.
속도 비교
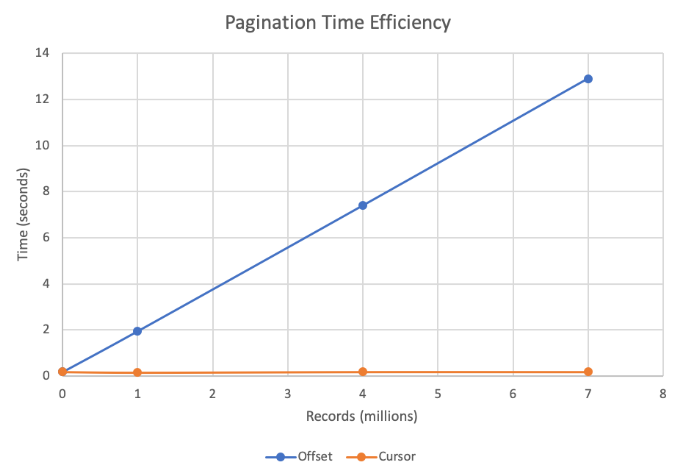
이미지 출처 : https://velog.io/@ygreenb/Paginationoffset-vs-cursor
row가 많으면 많을 수록 뒤에 내용을 조회할 수록 Offset방식과 Cursor 방식의 속도차이는 점점 커진다. 따라서 Cursor 방식을 사용하면 Offset문제에서 발생한 속도문제를 해결할 수 있다.
Cursor방식은 마지막으로 조회했던 것에 마지막 데이터부터 조회를 시작하기 때문에 앞서 예시를 들었던 게시판과 같은 데이터 중복 문제가 발생하지 않는다.
커버링 인덱스란 SQL 쿼리문에 들어가는 모든 컬럼이 인덱스화 되어있어서 원하는 데이터를 인덱스에서만 추출할 수 있는 것을 이야기한다. 인덱스에서만 데이터를 추출한다면 당연하게도 그냥 조회하는 것보다 훨씬 빠르다.
커버링 인덱스가 되었는 지를 EXPLAIN을 통해서 확인할 수 있다.
EXPLAIN SELECT id FROM itinerary limit 3;위와 같이 EXPLAIN후 실행할 쿼리를 작성하면 쿼리 계획이 나오는데

Extra컬럼에 Using Index라고 나오면 커버링 인덱스가 된것이다.
EXPLAIN SELECT * FROM itinerary limit 3;다음과 같이 쿼리를 실행하면 Extra에 아무것도 나오지 않는다. 조건에 쓰이는 컬럼만 인덱스가 되어야하는 것이 아닌 조회되는 모든 컬럼에도 인덱스화 되어 있어야 커버링 인덱스가 제대로 동작하기 때문에 첫번째 id만 조회하는 쿼리는 커버링인덱스, 전체 조회는 커버링 인덱스가 안되는 것이다.
조건에 들어가지도 않는데 왜 차이가 생길까?
일반적으로 인덱스를 이용해 조회되는 쿼리에서 가장 큰 성능 저하를 일으키는 부분은 인덱스를 검색하고 대상이 되는 row의 나머지 칼럼값을 읽기 위해 데이터 블록에 접근하는 시간 때문이다. 따라서 조건에 만족하는 값을 찾고 그 컬럼은 인덱스에서 못찾으니 다시 데이터 블록에서 찾아야하기 때문에 시간이 걸린다.
모든 컬럼에 인덱스를 하는 건 메모리의 문제뿐만 아니라 삽입,삭제, 수정 등 조회를 제외한 모든 성능에 안좋은 영향을 끼칠 것이다.
id와 같이 인덱스화 되어있는 컬럼만을 조회한 후에 자신 테이블과 Join을 통해 나머지 값을 불러오는 방식이 있을 수 있다.
SELECT i.* FROM itinerary i join (SELECT id FROM itinerary limit 3) s on i.id = s.id;아래와 같이 where을 사용해서 Cursor방식을 사용하고 커버링 인덱스를 통해 성능을 최적화할 수 있다.
SELECT i.* FROM itinerary i
JOIN (SELECT id FROM itinerary where id > 10 limit 10) s
on i.id = s.id; https://devlog-wjdrbs96.tistory.com/414
https://jaehoney.tistory.com/234
https://velog.io/@ddongh1122/MySQL-%ED%8E%98%EC%9D%B4%EC%A7%95-%EC%84%B1%EB%8A%A5-%EA%B0%9C%EC%84%A0