Performance Evaluation
For evaluation we generate a variety of synthetic workloads. Our hardware features an industry-standard 12-core Xeon E5-4650 CPU with 192 GB RAM.
Compared solutions: We mostly focus on Oak’s ZeroCopy (ZC) API. To quantify the benefit of zero-copying, we also run gets with the legacy API, to which we refer as Oak-Copy. For scans, we experiment with both the Set and Stream APIs. Since our goal is to offer Oak as an alternative to Java’s standard skiplist, our baseline is the JDK8 ConcurrentSkipListMap, which we call CSLM.
To isolate the impact of off-heap allocation from other algorithmic aspects, we also implement an off-heap variant of the CSLM, which we call CSLM-OffHeap. Note that whereas CSLM and Oak-Copy offer an object-based API, CSLM-OffHeap also exposes Oak’s ZC API. Internally, CSLM-OffHeap maintains a concurrent skiplist over an intermediate cell object. Each cell references a key buffer and a value buffer allocated in off-heap blocks through Oak’s memory manager.
Methodology:
The exercised key and value sizes are 100B and 1KB, respectively. In each experiment, a specific range of keys is accessed. Accessed keys are sampled uniformly at random from that range. The range is used to control the dataset size: Every experiment starts with an ingestion stage,which runs in a single thread and populates the KV-map with 50% of the unique keys in the range using putIfAbsent operations. It is followed by the sustained-rate stage, which runs the target workload for 30 seconds through one or more symmetric worker threads. Every data point is the median of 5 runs; the deviations among runs were all within 10%. In each experiment, all algorithms run with the same RAM budget. Oak and CSLM-OffHeap split the available memory between the off-heap pool and the heap, allocating the former with just enough resources to host the raw data. CSLM allocates all the available memory to heap.
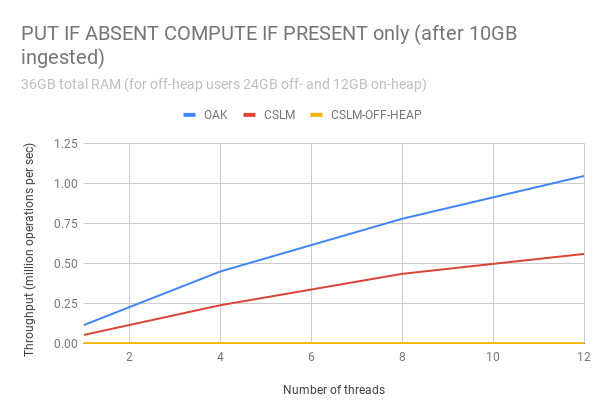
Scalability with parallelism benchmarks: In the following set of experiments, shown in Figure 4, we fix the available memory to 36GB and the ingested data set size to 10M KV-pairs. We measure the sustained-rate stage throughput for multiple workloads, while scaling the number of worker threads from 1 to 12. In this setting, the raw data is less than 35% of the available memory, so the GC effect in all algorithms is minor.
Figure 1 bellow depicts the results of a put-only workload. Oak is markedly faster than the alternatives already with one thread and continues to outperform CSLM by at least 2x with any number of threads. Moreover, whereas CSLM’s throughput flattens out with around 8 threads,Oak continues to improve all the way up to 12. CSLM-OffHeap scale as well as Oak does, suggesting that GC is the limiting factor for CSLM’s scalability. Moreover,Oak’s improvement over CSLM-OffHeap remains steady with the number of threads, suggesting that Oak’s advantage stems from factors that affect also the sequential execution speed, such as better locality, fewer Java objects (and consequently, less GC overhead), and fewer redirections.
Figure 1 (ingestion):

Figure 2 (putIfAbsentComputeIfPresent):