Traditional characters often get converted to their old variants for example
春 -> tokenizes to 旾
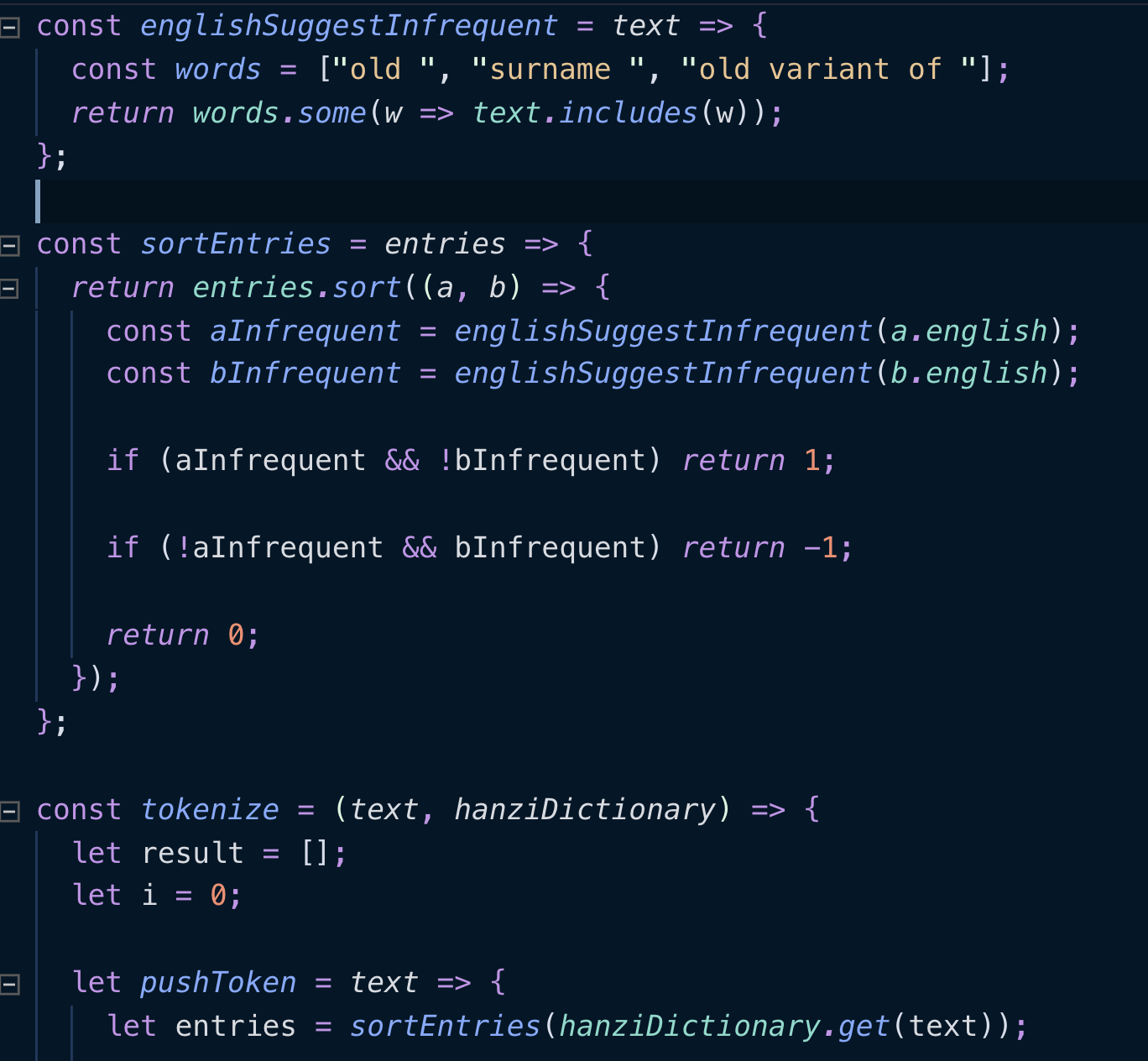
I have an old version of this code atm but I just want to let you know I am going to add some basic sorting so old variants are not used as the top match.
I could bring my code up to date and do a PR if you would like.
I will split the sorting so surnames go above old variants
https://github.com/yishn/chinese-tokenizer/blob/master/src/main.js#L44
Cheers for this project btw! 😄
Traditional characters often get converted to their old variants for example
春 -> tokenizes to 旾
I have an old version of this code atm but I just want to let you know I am going to add some basic sorting so old variants are not used as the top match.
I could bring my code up to date and do a PR if you would like.
I will split the sorting so surnames go above old variants
https://github.com/yishn/chinese-tokenizer/blob/master/src/main.js#L44
Cheers for this project btw! 😄