{kind=link}
This technology aims to differentiate between stressed and non-stressed outputs in response to stimuli (e.g., questions posed), with high stress seen as an indication of deception. In this work, we propose a deep learning-based psychological stress detection model using speech signals. With increasing demands for communication between humans and intelligent systems, automatic stress detection is becoming an interesting research topic. Stress can be reliably detected by measuring the level of specific hormones (e.g., cortisol), but this is not a convenient method for the detection of stress in human- machine interactions. The proposed algorithm first extracts Mel- filter bank coefficients using pre-processed speech data and then predicts the status of stress output using a binary decision criterion (i.e., stressed or unstressed) using CNN (Convolutional Neural Network) and dense fully connected layer networks.
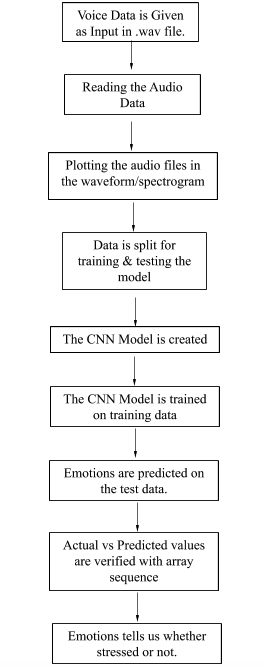
More than RNN we feel that CNN for voice classification works even better. And in our project we have used the Conv1d
To describe the process.. First import the necessary dependencies and your dataset The dataset either can be this one or you can upload your own dataset. Then we need to use Libross package of the python inorder to build up spectrograms and change the hertz scale of the audio input into mel-filter scale To know more about librosa "https://librosa.org/" So Mel-filter scale is a type of measurement scale which we use inorder to come into linear conclusions To know more about mel-filer scale "https://medium.com/analytics-vidhya/understanding-the-mel-spectrogram-fca2afa2ce53" From the outputted array passs into the built in CNN Structure and test it for validataion!!!